背景
傳統的信息提取,通常是從文本中提取信息,相關技術也比較成熟。然而對于復雜領域,例如圖片,文檔等形式的數據,想要提取出高質量的、可信的數據難度就比較大了,這種任務也常稱為:視覺文檔理解(Visual Document Understanding, VDU),再次基礎上發展的視覺文檔(Visual Question Answer, VQA)。傳統的方法是基于OCR的范式,首先基于OCR引擎,將文檔中的數據提取出出來,轉成文本,有了文本之后就可以使用傳統的信息抽取方法處理,如果想結合數據位置信息,就將位置信息與文本一同在新的模型中做處理。這種方式的缺陷是:使用OCR的高計算成本,OCR模型對語言或文檔類型的不靈活性,OCR錯誤向后續過程傳播等。OCR驅動的VDU比較具有代表性的就是微軟的LayoutLM系列(v1,v2,v3)。隨著視覺模型的不斷進步,圖片與文本結合的多模態模型也在傳統的任務中取得了不斷地進步。OCR-Free范式的VDU技術也開始盛行,比較早的是2022年的一篇論文:OCR-free Document Understanding Transformer,一種端到端的文檔理解模型,簡稱為:Donut。
本文要介紹的TextMonkey是一種基于LLM的多模態大模型。我們先從,Donut看起。
Donut
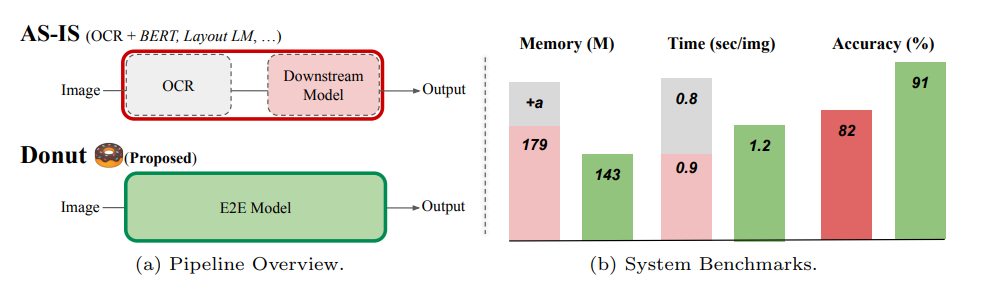
這個模型算是OCR-Free模型的鼻祖,模型也比較簡單,相比以往的處理方案,具有不錯的效果。數據處理的pipline如下:
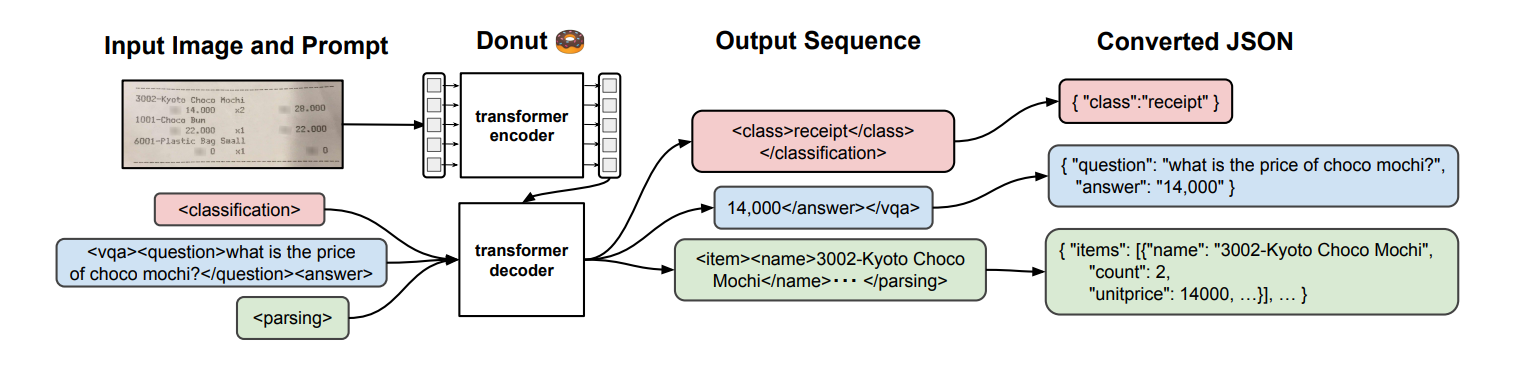
模型的主要結構由一個編碼器和一個解碼器構成。編碼器主要是Swin Transformer(2021年微軟研究院發表在ICCV上的一篇文章), 解碼器是一個自回歸的語言模型,使用的BART的解碼器模塊。此外模型的輸入也是有講究的,主要是作者受GPT-3的啟發,使用了prompt這種范式,在下游的任務中都增加了prompt,在結果輸出使用特殊的token作為標志,可以將生成的序列轉換成json格式的數據。模型在效果上和性能上優于傳統的模型,例如下圖:
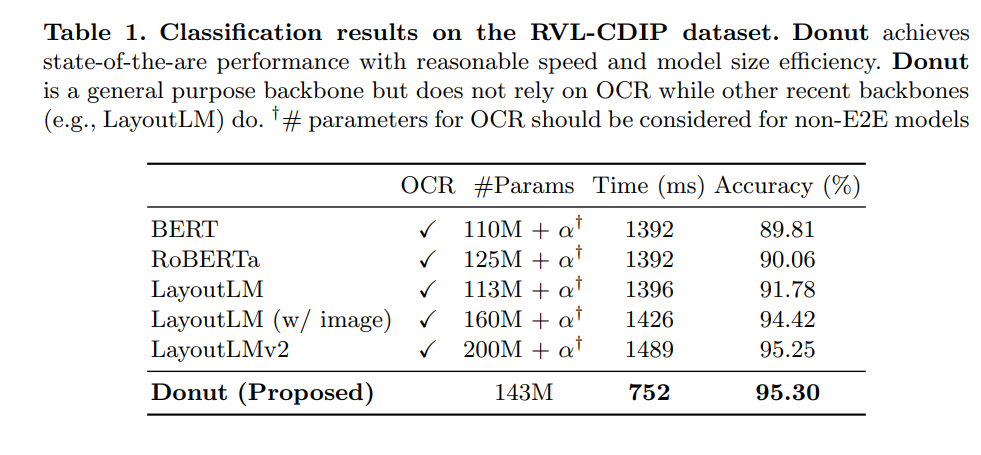
在文檔分類的數據上的效果如下:
在文檔信息提取上的效果如下:
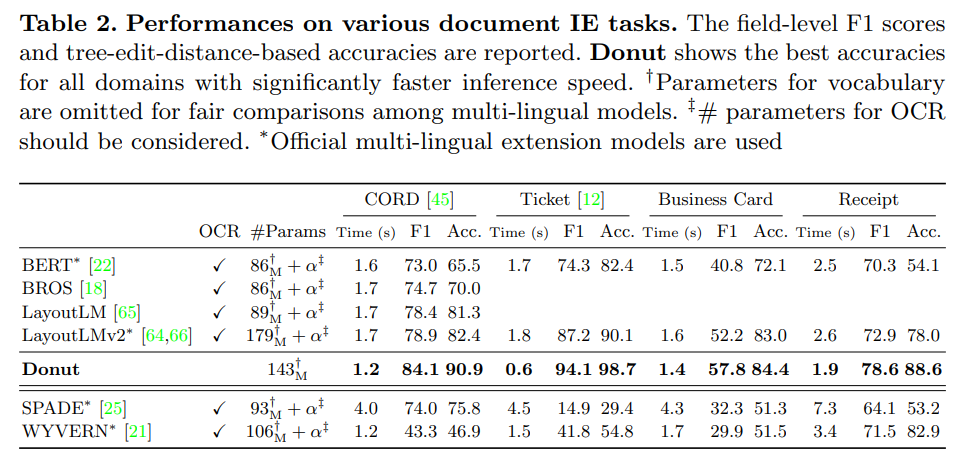
從上面的結果來看,使用這種基于視覺編碼的方式相比與傳統的方法是有一定效果的提升。在現如今大模型盛行的時代,大模型的生成、涌現、表達能力都異常突出,看看結合大模型的視覺問答效果怎么樣。下文就介紹今天的主角,由華中科技大學和金山共同推出的TextMonkey:TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
TextMoneky
TextMoneky實在Monkey(Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models)的基礎上進行了改進。Monkey已被計算機視覺頂會CVPR2024收錄,相關代碼也開源到github.
概述
TextMonkey在多個方面進行改進:通過采用零初始化的Shifted Window Attention,TextMonkey實現了更高輸入分辨率下的窗口間信息交互;通過使用相似性來過濾出重要的圖像特征,TextMonkey不僅能夠簡化輸入,還可以提高模型的性能。此外,通過擴展多個文本相關任務并將位置信息納入回答,TextMonkey增強了可解釋性并減少了幻覺。與此同時,TextMonkey在微調之后還可以具備APP Agent中理解用戶指令并點擊相應位置的能力,展現了其下游應用的巨大潛力。
方法論
TextMonkey的構造如下圖所示。
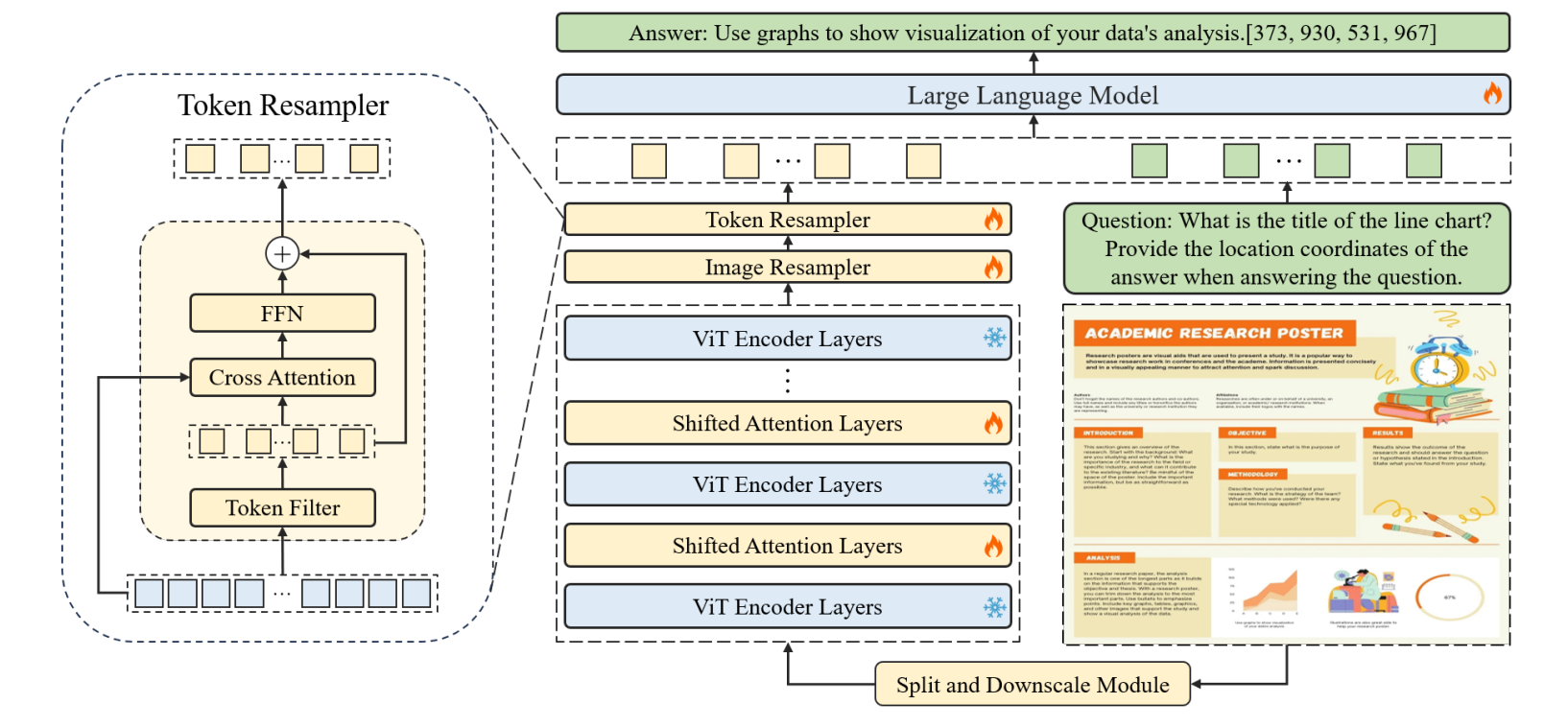
核心的模塊主要有三個:
-
Shifted Window Attention。現有的多模態大模型,如Monkey和LLaVA1.6,通過將圖像切分為小塊來提高輸入分辨率。然而這種裁剪策略可能會無意中分割相關單詞,導致語義不連貫。此外,這種分裂造成的空間分離也使得處理與文本位置相關的任務(如文本檢測)變得具有挑戰性。TextMonkey在繼承Monkey高效的圖像分辨率縮放功能的同時,采用滑動窗口注意力機制建立了塊與塊之間的上下文聯系。
-
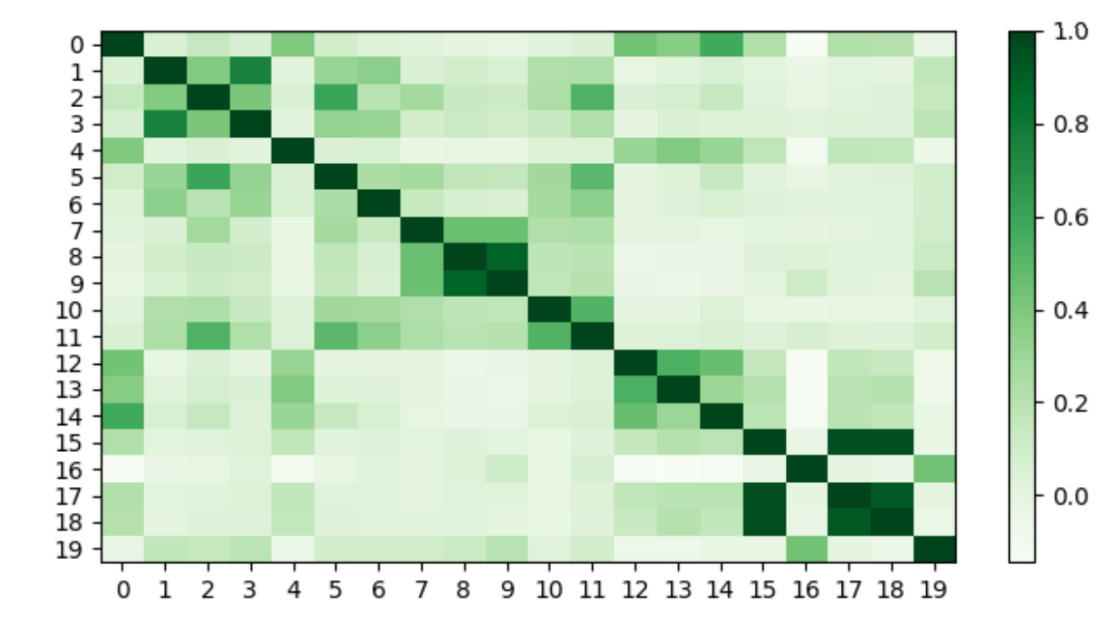
Token Resampler。目前的多模態大模型面臨著圖像token數目隨著輸入分辨率的增加而增加的挑戰。由于語言模型的輸入長度和訓練時間的限制,減少token的數量是很有必要的。在自然語言中,語言元素會存在一些冗余信息。那么可以自然的猜測在擴大圖像分辨率之后,視覺部分的token也會存在冗余。本文根據以往確定語言元素相似性的方法,對已經映射到語言空間的圖像token的相似性進行了度量:在圖像Resampler之后隨機選取20個有序特征,利用余弦相似性成對比較這些特征的相似性,得到的結果如圖2所示。顏色越深代表相似性越高,實驗發現每個圖片的token都有一個到幾個類似的token,圖片特征中存在冗余。同時,本文還觀察到某些令牌是高度獨特的,并且缺乏其他相似的token,如圖中的第四個token,這表明這個token是更為重要的。因此本文選用相似度來度量并識別獨特的視覺token。并提出Token Resampler來壓縮冗余視覺token。通過計算每個token與其他token的相似度,過濾得到最重要(相似度最低)的K個token。同時,為了避免直接丟棄其他token造成的信息丟失,這里還會利用過濾得到的K 個token作為查詢,并采用交叉注意力機制進一步融合所有特征。如下圖:
-
多任務訓練。TextMonkey支持讀出所有文本,文本檢測識別,輸出給定文本坐標,文本問答,具有位置感知的文本問答,圖像結構化等多個任務。TextMonkey在進行問答時不僅看可以給出答案,還能給出答案所在位置,進一步增強了模型的可解釋性。與此同時,在經過微調之后,TextMonkey還可以具備APP Agent中理解用戶指令并點擊相應位置的能力。
實驗分析
TextMonkey與現有的多模態大模型相比,表現出了優越的性能。如下圖:
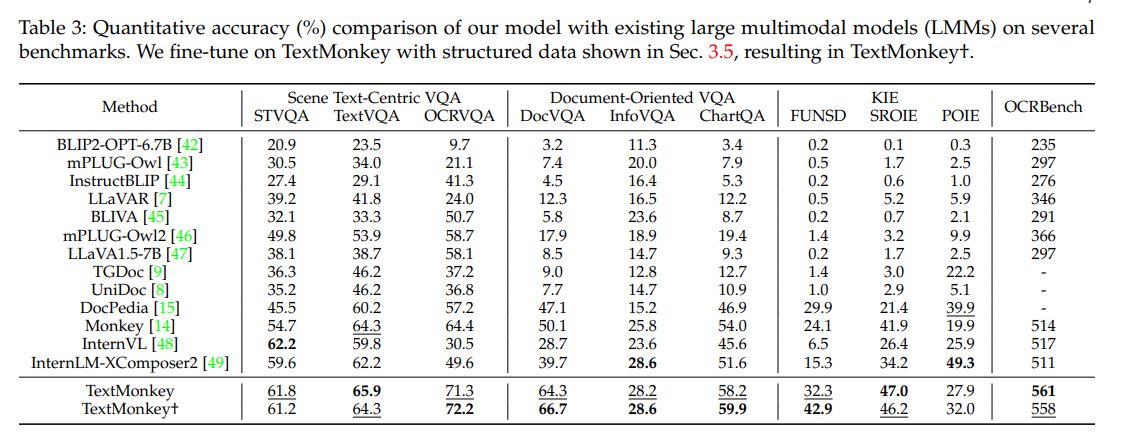
為了進一步驗證TextMonkey的有效性,作者在多個數據集上進行了測試,如下:
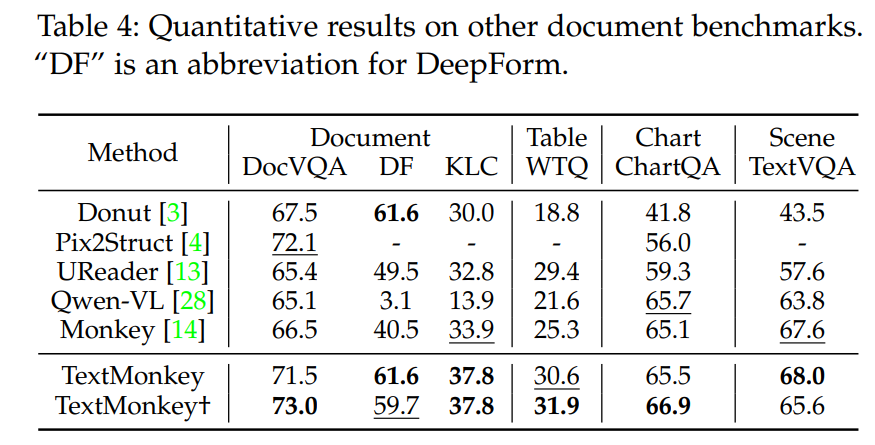
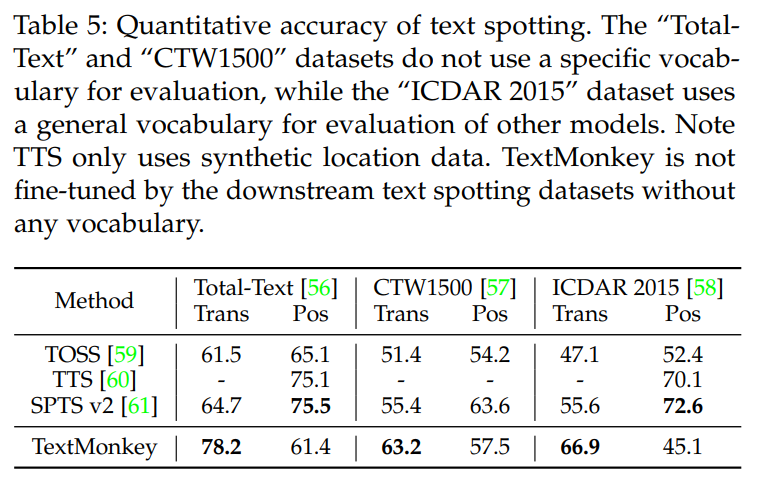
TextMonkey在Text Spotting數據集上相比于傳統OCR模型也取得了極具競爭力的效果,如下:
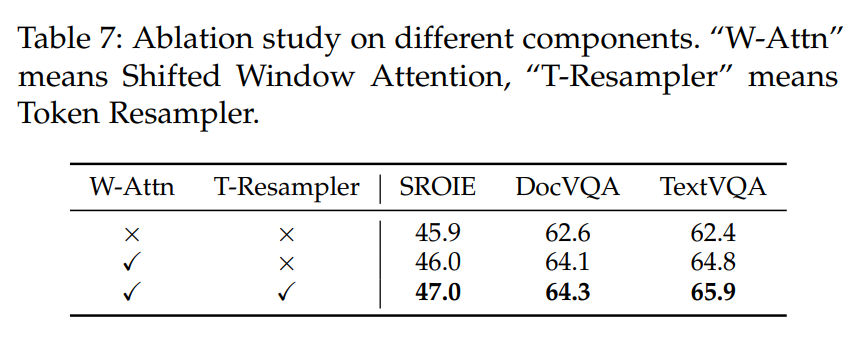
在消融實驗中也驗證了Shifted Window Attention和Token Resampler兩個模塊是有效的。如下圖:
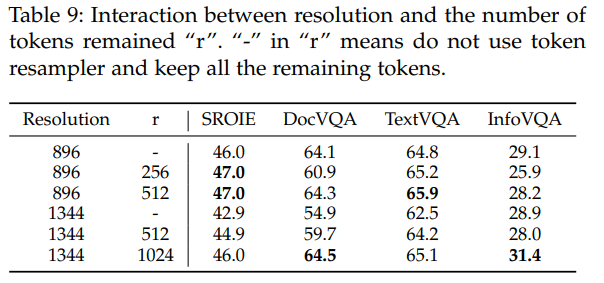
此外作者還做了一個實驗,當提高圖片的分辨率時,圖片對應的token會顯著增加,得到的關鍵信息也變得尤為困難,如下表,第1,4行,不壓縮token,分辨率從896提高的1344,模型的效果在4個數據集上效果下降。此外,在壓縮token上,選擇不同數量的Token也會對模型有一定的影響,這些都是需要考慮的。對比實驗如下:
案例使用
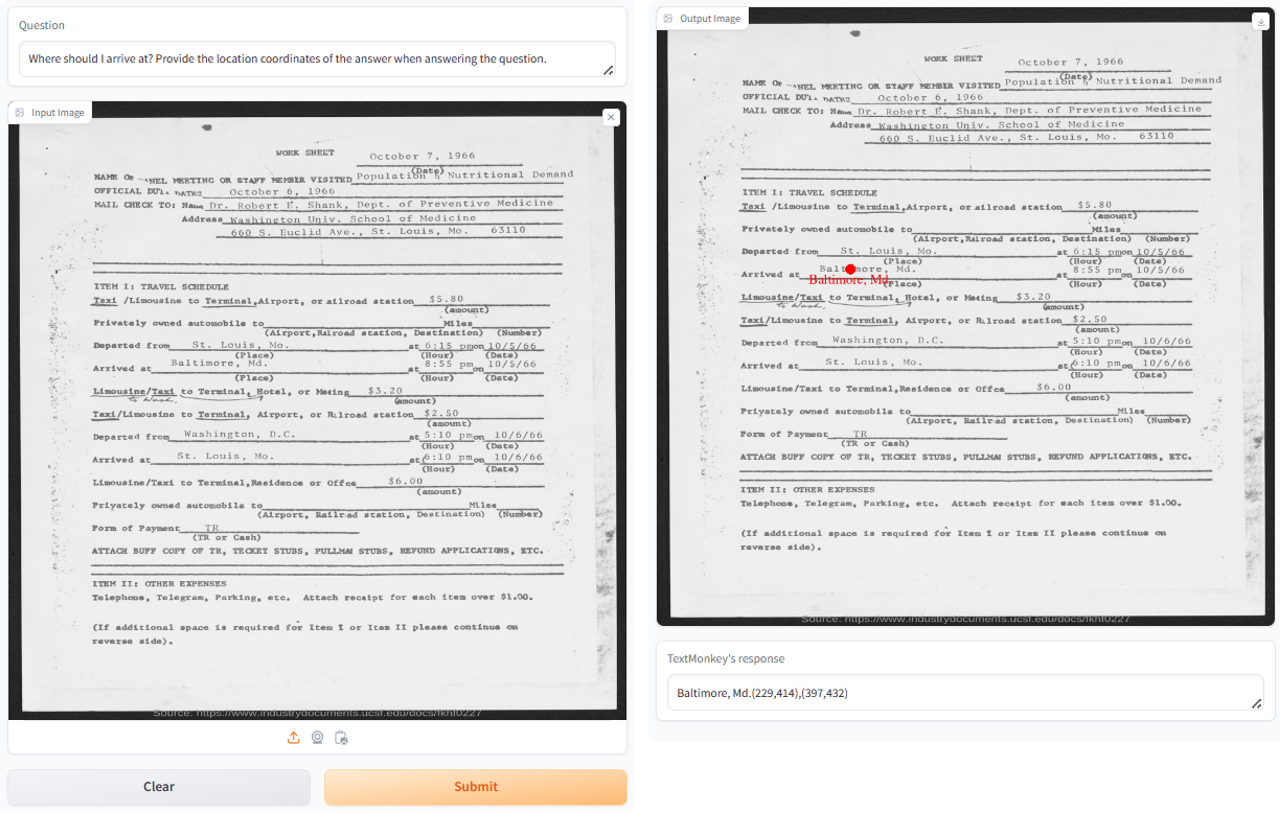
一些測試案例可以參考:TextMonkey:用于文檔理解的多模態大模型,取其中一個案例,TextMonkey在文字相當密集的情況下讀取輸入圖片中的所有文字并且給出圖片中文本的坐標。案例如下:


此外還有一個比較有意思的就是,TextMonkey還能幫助我們結構化圖表,表格以及文檔數據,通過將圖像內容轉化為Json格式的信息,方便記錄和提取。如下:
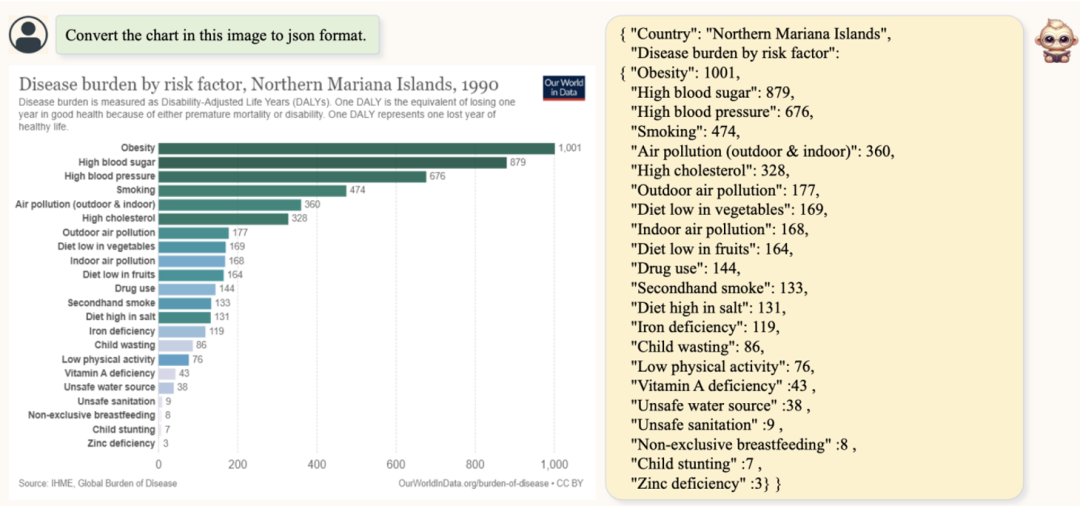
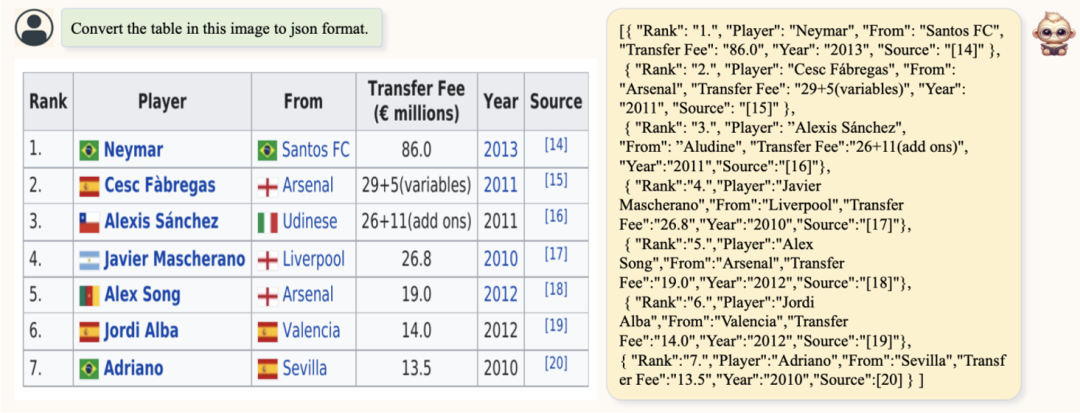
補充
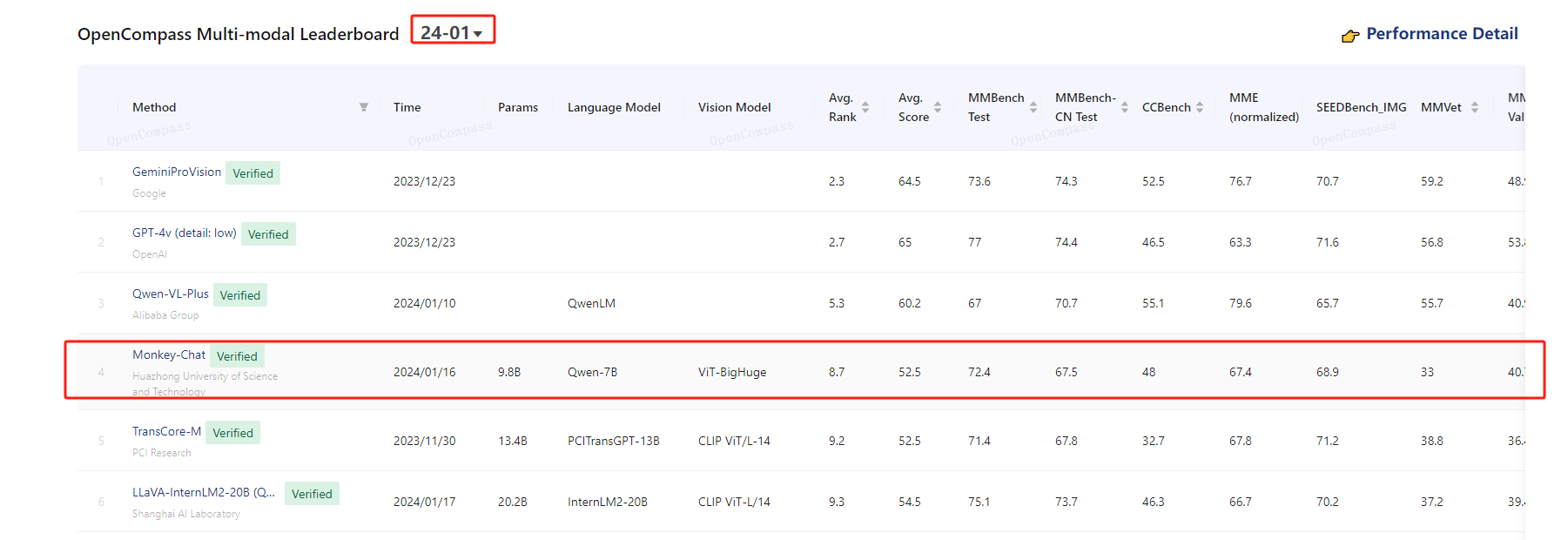
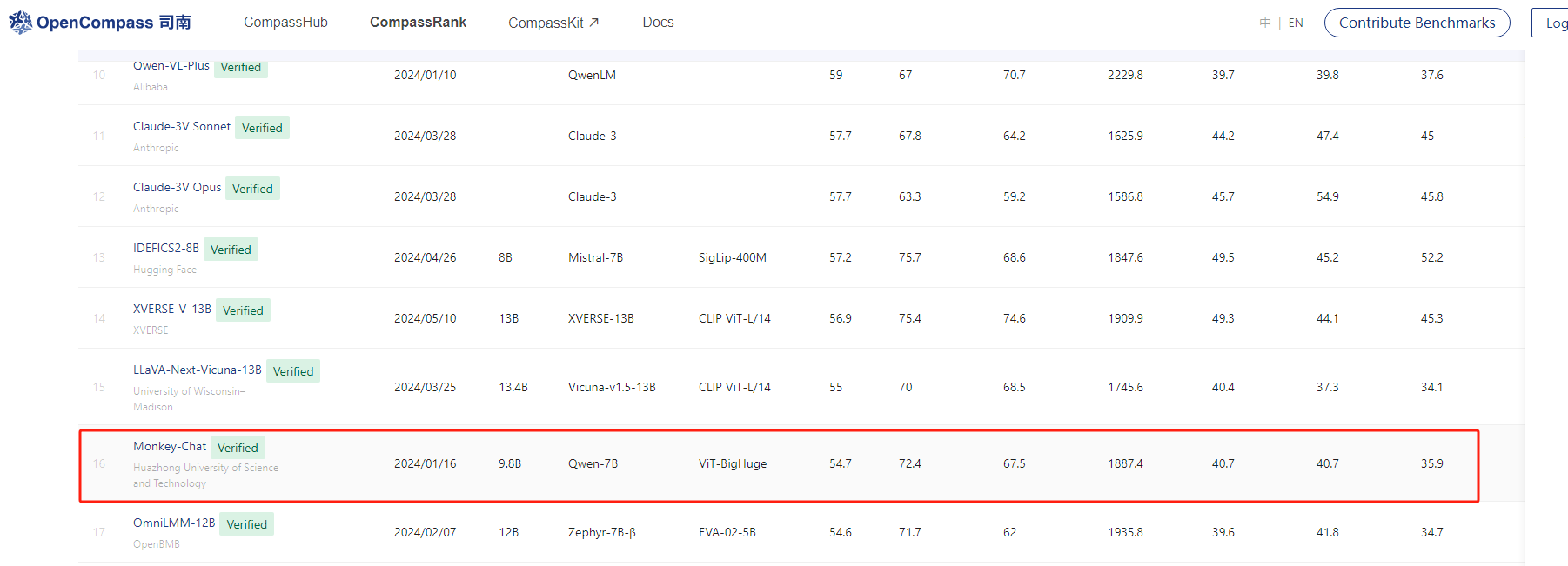
需要說明的是,TextMonkey基于的語言模型和視覺模型分別是:Qwen-7B ViT-BigHuge,模型參數在9.8B左右。截止發文,在模態大模型排行榜上,其在1月排名為第4,到如今5月掉到第16,說明了多模態大模型的卷的速度也是非常快的,排行榜地址:https://rank.opencompass.org.cn/leaderboard-multimodal/?m=24-05
總結
TextMonkey在Monkey的基礎上增強了其圖像間的跨窗口交互,在擴大分辨率的基礎上增強了視覺信息的語義連續性,有效緩解了視覺信息碎片化的問題;并通過提出過濾融合策略減少圖像特征長度,從而減少輸入到大語言模型中冗余的視覺token數量。論文的實驗說明,分辨率不是越大越好,不合理的提高模型分辨率策略有時會給模型帶來負面影響,如何合理地擴大分辨率才是一個更值得去思考的問題。此外,通過在問答中引入位置信息,TextMonkey增強了可解釋性并減少了幻覺。TextMonkey在多個文本相關的測試基準中處于國際領先,在OCRBench中超越其他開源多模態大模型。
對于這種OCR-Free的多模態大模型,總體看好。至于未來這些多模態大模型能否在工業領域落地,也還需要做進一步的考究。文中只介紹了該模型的大概內容,在實際的處理中還需要參考原文以及開源的代碼。

_語音識別)

apidoc 的安裝)
多任務高性能執行聚合)


來保序,對ARM和IA而言,RTE_WMB()的實現有何不同)
/PHP://偽協議繞過)


)




:窗口函數)

)
)