Java后端面試
經歷了兩個月的面試和準備,下面對常見的八股文進行總結。有些問題是網上看到的面經里提到的,有些是我真實面試過程遇到的。
異常
1、異常分為哪幾種?他們的父類是什么?
注意:所有異常對象的父類為Throwable
- Error及其子類:
- 一般指的是虛擬機的錯誤,是由java虛擬機生成并拋出,程序不能進行處理,所以也不加處理,例如OutOfMemoryError內存溢出。
- RuntimeException及其子類(運行時異常):
- 是由編程bug所致。如NullPointerException、ClassCastException、ArrayIndexOutOfBoundsException、ArithmeticException
- Exception及其子類中除了RuntimeException及其子類之外的其它異常(受檢型異常):
- 編譯器就能檢測的異常,JAVA 編譯器強制要求我們必需對出現的這些異常進行 try-catch或者throws,否則編譯不會通過。如IOException、ClassNotFoundException
2、受檢異常與非受檢異常的區別?
? 同上。
3、Error可以捕獲嗎?
可以。Throwable 的子類,都可以被 try-catch 語句捕獲,分為 Error 和 Exception。
4、棧溢出和堆溢出是什么?OOM可以捕獲嗎?什么情況可以捕獲?
棧溢出:棧幀堆積,超過設置的棧的大小。
OOM 作為一個 Error,在某些條件下是可以被 catch 的。僅針對我們可控的代碼,并且在 try 塊中,由于申請大段連續內存的情況下,觸發的 OOM,才是可以被 catch 的。當 catch 住 OOM 時,應該主動釋放一些可控的內存,做好內存管理,避免在后續的操作中,在其他操作中又觸發 OOM,導致崩潰。

集合
1、說說你對Java集合的理解
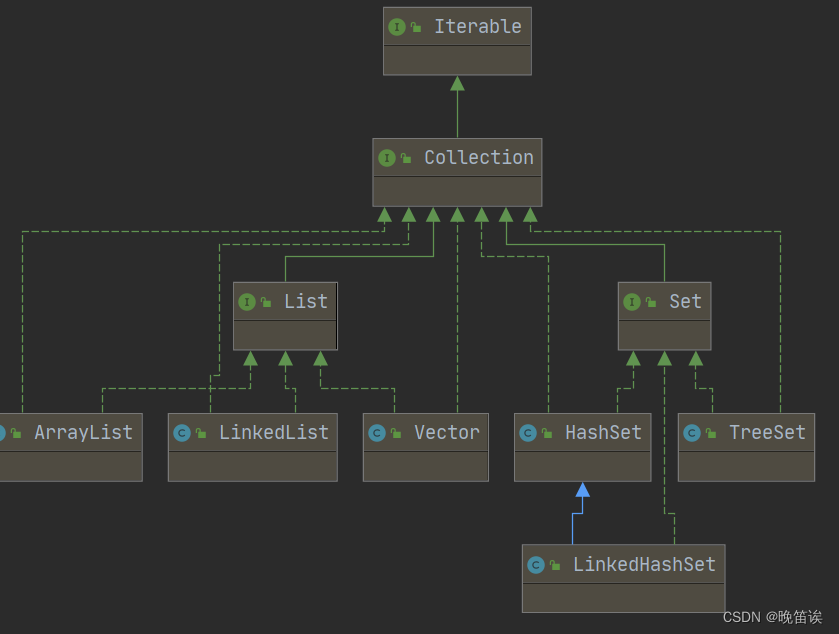

2、ArrayList和LinkedList的區別
底層實現不同,長度一個有限一個理論無限
ArrayList延遲初始化,第一次添加元素時才初始化容量,每次擴容1.5倍
3、它們都線程安全嗎?如何得到線程安全的List?
No。
- Vector
- Collections.synchronizedList()方法對非線程安全集合進行裝飾
- CopyOnWriteArrayList。讀寫分離,讀取時不加鎖,只是寫入、刪除、修改時加鎖。不能保證完全線程安全,適用于讀多寫少的場景。
4、CopyOnWriteArrayList用過嗎?優缺點?
能保證寫入線程安全,提高讀線程并發量。
缺點:讀寫線程數據一致性無法保證、寫時內存占用問題
5、Set是有序還是無序的?一定無序嗎?
Set接口有三個實現類:HashSet(無序)、LinkedHashSet(有 序)、TreeSet(有序)
6、TreeSet的底層實現
紅黑樹。
7、把你所知道的HashMap的所有知識都說一下?(包括底層實現、擴容機制、1.7與1.8的區別、長度為什么是2的n次冪)
1.7:數組 + 鏈表,元素大于 容量 * 0.75 時進行擴容
1.8:數組 + 鏈表 + 紅黑樹
8、保證線程安全的Map是什么?ConcurrentHashMap聊一下?(和HashMap答題類似,不過重點要回答的是為什么線程安全)
HashTable、ConcurrentHashMap
HashTable 加的鎖鎖住整張表、ConcurrentHashMap1.8后鎖住一個節點再CAS自旋
ConcurrentHashMap:
1.7:分段鎖segment
1.8:CAS、synchronized、volatile
9、ConcurrentHashMap每個Node節點中變量使用final和volatile修飾有什么用呢?
final:保證不可修改,讀取該變量不用考慮線程安全問題。
volatile:volatile來保證某個變量內存的改變對其他線程即時可見,在配合CAS可以實現不加鎖對并發操作的支持。get操作可以無鎖是由于Node的元素val和指針next是用volatile修飾的,在多線程環境下線程A修改結點的val或者新增節點的時候是對線程B可見的。
10、ConcurrentHashMap中synchronize和CAS是如何使用的
深入淺出ConcurrentHashMap詳解-CSDN博客
CAS:當hash定位的節點為空,則用CAS自旋寫入。
synchronize:當hash定位的節點非空,則用synchronize鎖住節點進行修改。
至于為什么修改不用CAS,我的理解是由于無法解決ABA問題。
反射
1、反射是什么?舉幾個例子?
Java基礎之反射_java反射-CSDN博客
2、通過反射可以拿到類中的變量信息嗎?
設計模式(一般與SpringAOP一同問)
多線程
1、線程實現的方式及其優缺點?
線程是調度的基本單位。
2、如何死鎖?(考察死鎖的條件)
3、如何加鎖?(Synchronize關鍵字和Reentrantlock)
ReentrantLock詳解-CSDN博客
Reentrantlock實現了Lock接口規范:
| 接口 | 作用 |
|---|---|
| void lock() | 獲取鎖,調用該方法當前線程會獲取鎖,當鎖獲得后,該方法返回。 |
| void lockInterruptibly() throws InterruptedException | 可中斷的獲取鎖,和lock()方法不同之處在于該方法會響應中斷,即在鎖的獲取中可以中斷當前線程 |
| boolean tryLock() | 嘗試非阻塞的獲取鎖,調用該方法后立即返回。如果能夠獲取到返回true,否則返回false。 |
| boolean tryLock(long time, TimeUnit unit) throws InterruptedException | 超時獲取鎖,當前線程在以下三種情況下會被返回: 當前線程在超時時間內獲取了鎖 當前線程在超時時間內被中斷 超時時間結束,返回false。 |
| Condition newCondition() | 獲取等待通知組件,該組件和當前的鎖綁定,當前線程只有獲取了鎖,才能調用該組件的await()方法,而調用后,當前線程將釋放鎖。 |
可重入鎖:
可重入鎖又名遞歸鎖,是指在同一個線程在外層方法獲取鎖的時候,再進入該線程的內層方法會自動獲取鎖(前提鎖對象得是同一個對象),不會因為之前已經獲取過還沒釋放而阻塞。Java中ReentrantLock和synchronized都是可重入鎖,可重入鎖的一個優點是可一定程度避免死鎖。在實際開發中,可重入鎖常常應用于遞歸操作、調用同一個類中的其他方法、鎖嵌套等場景中。
3.1、同步方法塊和同步方法的區別?(monitorenter、exit和ACC_SYNCHRONIZED)
同步方法塊:monitorenter 和 monitorexit兩個指令進行同步
同步方法:ACC_SYNCHRONIZED標志位進行同步
3.2、鎖升級過程?
關于 鎖的四種狀態與鎖升級過程 圖文詳解 - 牧小農 - 博客園 (cnblogs.com)
鎖有四種狀態:無鎖、偏向鎖、輕量鎖、重量鎖。
三種鎖的優缺點對比:
| 鎖 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 偏向鎖 | 加鎖和解鎖不需要額外的消耗,和執行非同步方法相比僅存在納秒級的差距 | 如果線程質檢存在鎖競爭,會帶來額外鎖撤銷的消耗 | 適用于只有一個線程訪問同步塊的場景 |
| 輕量級鎖 | 競爭的線程不會阻塞,提高了程序的響應速度 | 如果始終得不到鎖競爭的線程,使用自旋會消耗CPU資源 | 追求響應時間,同步塊執行速度非常快 |
| 重量級鎖 | 線程競爭不使用自旋,不會消耗CPU資源 | 線程阻塞,響應時間緩慢 | 追求吞吐量,同步塊執行速度較長 |
鎖升級過程:
- 初次執行到synchronized代碼塊的時候,鎖對象變成偏向鎖(通過CAS修改對象頭里的鎖標志位),字面意思是“偏向于第一個獲得它的線程”的鎖。
- 輕量級鎖是指當鎖是偏向鎖的時候,卻被另外的線程所訪問,此時偏向鎖就會升級為輕量級鎖,其他線程會通過自旋(關于自旋的介紹見文末)的形式嘗試獲取鎖,線程不會阻塞,從而提高性能。
- 輕量級鎖在長時間獲取不到鎖時會忙等,自旋超過10次(可修改)時,升級為重量級鎖。
3.3、ReentrantLock優缺點?
3.4、底層實現?(AQS、CAS)
3.5、CAS會存在什么問題?如何避免?
ABA問題。版本號
3.6、公平鎖和非公平鎖在AQS上是如何實現的?Synchronized是公平鎖還是非公平鎖?
3.7、synchronized原理
synchronized原理_synchronized可重入鎖原理-CSDN博客
原理:JVM提供的監視器monitor,synchronized對代碼塊加鎖需要依靠兩個指令 monitorenter 和 monitorexit,對方法加鎖依賴方法ACC_SYNCHRONIZED標志區。
synchronized鎖升級原理:
JDK1.6之前synchronize是標準的重量級鎖(悲觀鎖),JDK1.6之后進行了大幅度優化,支持鎖升級制度緩解加鎖和解鎖造成的性能浪費,鎖的狀態總共有四種,無鎖、偏向鎖、輕量級鎖和重量級鎖。隨著鎖的競爭,鎖可以從偏向鎖升級到輕量級鎖,再升級到重量級鎖,并且鎖只能升級不能降級。
4、線程池的理解
4.1、線程池工廠創建的4中方法?
阿里巴巴開發手冊上明確寫了不要這樣做,因為通過這種方式創建的線程池阻塞隊列太長,容易造成OOM
- newCachedThreadPool 創建可緩存的線程池
- newFixedThreadPool 創建定長的線程池
- newSingledThreadPool 創建單一線程池執行
- newScheduedThreadPool 創建一個定長的周期執行的線程池
4.2、任務加入的線程池的流程?

4.3、線程池的7個參數?拒絕策略?
// 本質ThreadPoolExecutor()
// 線程池的七大參數
public ThreadPoolExecutor(int corePoolSize, // 核心線程池大小int maximumPoolSize, // 最大核心線程池大小long keepAliveTime, // 非核心線程超時了沒有被使用就會釋放TimeUnit unit, // 超時單位BlockingQueue<Runnable> workQueue, // 阻塞隊列ThreadFactory threadFactory, // 線程工程創建線程,一般不用動RejectedExecutionHandler handler // 拒絕策略) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;
}拒絕策略:
new ThreadPoolExecutor.AbortPolicy() // 默認的拒絕策略,不處理,拋出異常
new ThreadPoolExecutor.CallerRunsPolicy() // 拒絕策略,哪來的去哪里
new ThreadPoolExecutor.DiscardPolicy() // 拒絕策略, 隊列滿了不會拋出異常
new ThreadPoolExecutor.DiscardOldestPolicy() // 拒絕策略,隊列滿了,嘗試去和最早的競爭,不會拋出異常
4.4、線程池中如何拿到線程的執行結果?
Callable類型的線程。
直接用Future接收線程返回值,或者提交Futuretask類型的線程任務。
// Future
Callable<String> callable = () -> {Thread.sleep(2000);return Thread.currentThread().getName();};Future<String> future = executor.submit(callable);System.out.println("-------------task1返回結果 : " + future.get());//FutureTaskFutureTask<String> futureTask = new FutureTask<String>(callable);executor.submit(futureTask);Future<String> future1 = executor.submit(callable);System.out.println("-------------futureTask返回結果 : " + futureTask.get());
4.6、線程池的大小該如何去設置?
IO密集型:2 * CPU核心數
CPU密集型:CPU核心數 + 1
4.5、核心工作線程是否會被回收?
線程池中有個allowCoreThreadTimeOut字段能夠描述是否回收核心工作線程,線程池默認是false表示不回收核心線程,我們可以使用allowCoreThreadTimeOut(true)方法來設置線程池回收核心線程。
4.6、線程池創建參數中keepAliveTime的作用
當線程池中的線程數量?于 corePoolSize 的時候,如果這時沒有新的任務 提交,核?線程外的線程不會?即銷毀,?是會等待,直到等待的時間超過了 keepAliveTime 才會被回收銷毀。
非核心線程空閑狀態下的存活時間。
5、你對ThreadLocal了解多少?
每個線程維持一份副本。增刪查改都是對副本操作。
關鍵就是Thread里的這倆變量
【高并發】一文帶你徹底搞懂ThreadLocal-云社區-華為云 (huaweicloud.com)
/* ThreadLocal values pertaining to this thread. This map is maintained* by the ThreadLocal class. */ThreadLocal.ThreadLocalMap threadLocals = null;/** InheritableThreadLocal values pertaining to this thread. This map is* maintained by the InheritableThreadLocal class.*/ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
注意:線程池創建的 ThreadLocal要在finally中?動remove,不然會有內存泄漏的風險。
6、為什么我們調? start() ?法時會執? run() ?法,為什么我們不能直接調? run() ?法。
new ?個 Thread,線程進?了新建狀態。調? start() ?法,會啟動?個線程并使線程進?了就緒狀態,當分配到時間?后就可以開始運?了。 start() 會執?線程的相應準備?作,然后?動 執? run() ?法的內容,這是真正的多線程?作。 但是,直接執? run() ?法,會把 run() ?法當成?個 main 線程下的普通?法去執?,并不會在某個線程中執?它,所以這并不是多線程?作。
7、Semophore介紹一下
synchronized 和 ReentrantLock 都是?次只允許?個線程訪問某個資源, Semaphore (信號量)可以指定多個線程同時訪問某個資源。
Semaphore semaphore = new Semaphore(3);
@Overridepublic void run() {try {// 獲取許可證,如果沒有許可證了,線程會阻塞semaphore.acquire();System.out.println("Thread " + id + " is accessing the shared resource.");Thread.sleep(1000); // 模擬訪問共享資源的時間System.out.println("Thread " + id + " has finished accessing the shared resource.");} catch (InterruptedException e) {e.printStackTrace();} finally {// 釋放許可證semaphore.release();}}
8、synchronized 和 ReentrantLock 的區別
相似點:
- 都是互斥鎖
不同點:
- 原理上:synchronized 是jdk提供的關鍵字,加鎖解鎖由JVM實現,內部使用監視器實現同步;ReentrantLock 是jdk提供的api,內部使用AQS實現,加鎖解鎖需要自己調用方法,更靈活。
- 公平性:synchronized 是非公平鎖;ReentrantLock 可以通過傳參創建公平鎖。
- 響應中斷:synchronized是不可中斷類型的鎖,除非加鎖的代碼中出現異常或正常執行完成;ReentrantLock 可以設置超時方法或者將lockInterruptibly()放到代碼塊中,調用interrupt方法進行中斷。
- 多條件喚醒:synchronized不能綁定; ReentrantLock通過綁定Condition結合await()/singal()方法實現線程的精確喚醒,而不是像synchronized通過Object類的wait()/notify()/notifyAll()方法要么隨機喚醒一個線程要么喚醒全部線程。
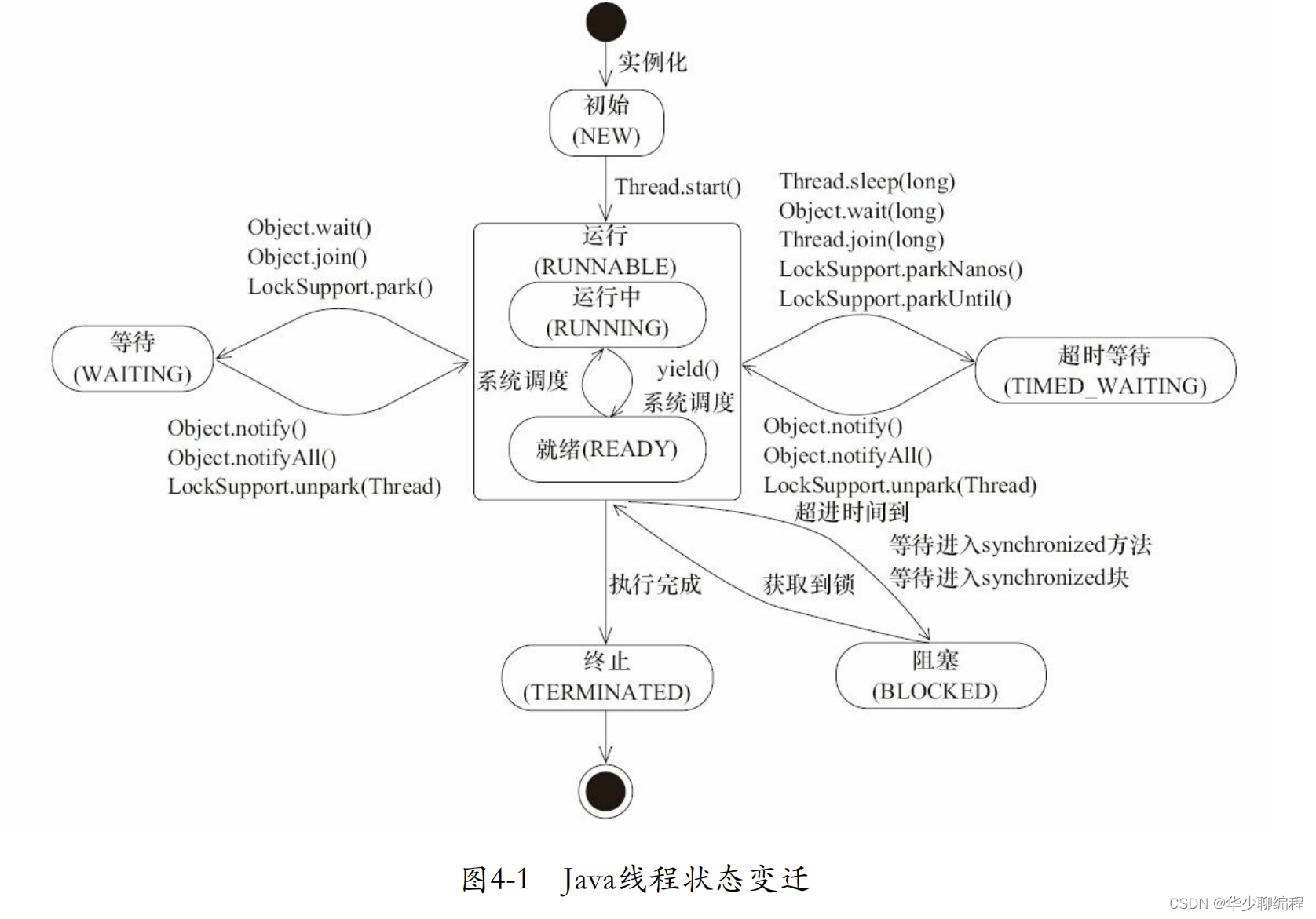
9、線程狀態轉換
線程狀態:
可以使用 jstack 命令查看,上面就有線程的狀態。
Java8新特性
1、Java8新特性你都用過哪些?
2、如何使用stream找出某一個字段值最大的數據?
int max = list.stream().max(Comparator.comparingInt(i -> i)).get();
JVM
1、JVM都分為哪些模塊?都有什么作用?
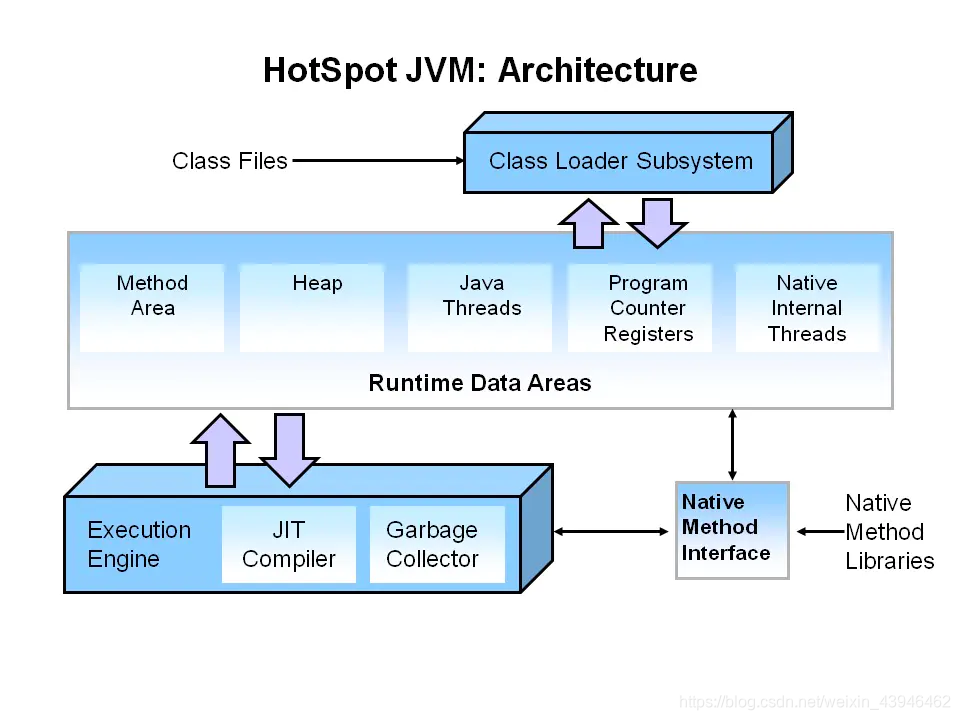
- Class loader(類加載器):根據給定的全限定名類名(如:java.lang.Object)來裝載class文件 到運行時數據區中的方法區。
- Execution engine(執行引擎):執行引擎也叫解釋器,負責解釋命令,交由操作系統執行;JIT編譯器。
- Native Interface(本地接口):與native libraries交互,是其它編程語言交互的接口。
- Runtime data area(運行時數據區域):這就是我們常說的JVM的內存,我們所有所寫的程序都被加載到這里,之后才開始運行。
2、類的加載過程是什么樣的?都涉及到哪些模塊?
- 加載
- 將字節碼文件加載到內存中
- 鏈接
- 驗證:保證加載的字節碼是合法、合理并符合規范的。
- 準備:為類的靜態變量分配內存,并將其初始化為默認值。
- 解析:將類、接口、字段和方法的符號引用轉為直接引用。
- 初始化
- 將靜態變量的賦值和靜態方法封裝為==()方法==,執行。
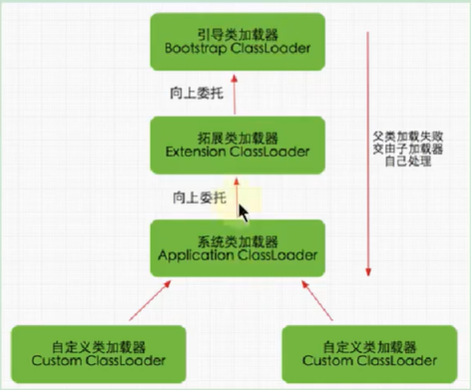
3、雙親委派與沙箱安全機制(這個我沒有被問到,但是我在回答過程中有提到,面試官沒有順著我的意思問…)
如果一個類加載器在接到加載類的請求時,它首先不會自己嘗試去加載這個類,而是把這個請求任務委托給父類加載器去完成,依次遞歸,如果父類加載器可以完成類加載任務,就成功返回。只有父類加載器無法完成此加載任務時,才自己去加載。
好處:(安全)
?
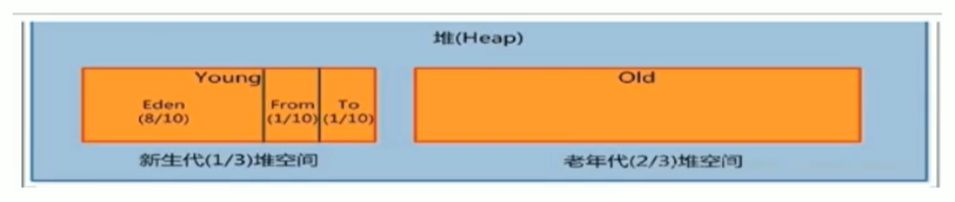
4、詳細說一下堆?(此處發現面試官想要問垃圾回收機制,可以有意提到一些自己熟悉的知識點)
所有的對象實例以及數組都應當在運行時分配在堆上。
垃圾回收,分代回收。
新生代、老年代
5、垃圾回收算法(不要遺漏分代回收)
-
標記:引用計數、可達性分析
-
清除:復制算法、標記-清除算法、標記-壓縮算法
-
分代:分代收集算法
6、為什么新生代用標記復制?老年代用標記刪除、壓縮?(考察是否理解緣由,而非死記硬背)
根據新生代和老年代的特點來回答。
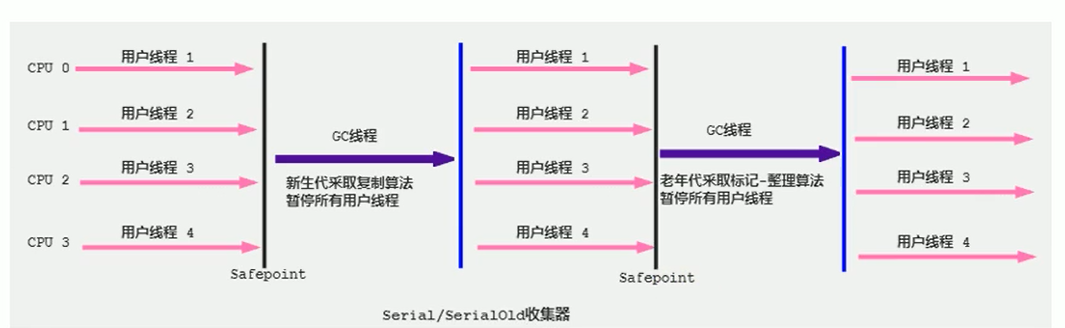
7、垃圾回收器你知道哪些?
-
Serial 收集器(串行收集器):回收時STW,簡單高效。一般單核CPU才使用。
-
ParNew 回收器(并行回收):復制算法、STW

-
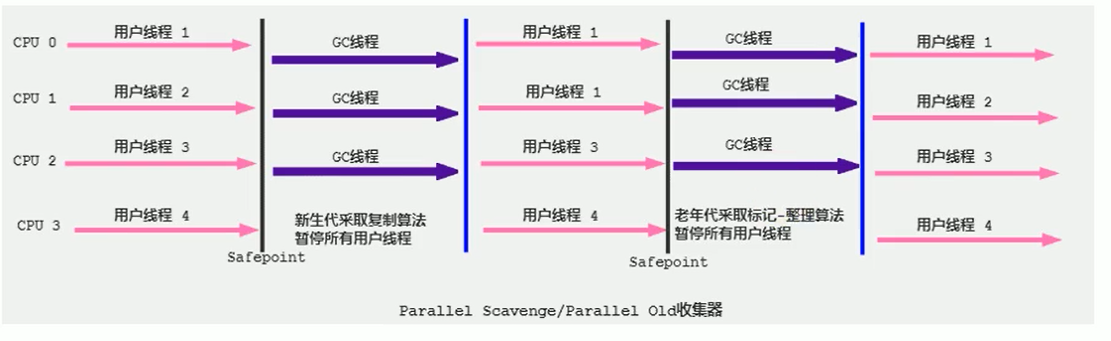
Parallel 回收器:復制算法、并行回收和STW,新生代采用Parallel Scavenge收集器(復制算法)、老年代采用Parallel Old收集器(標記-壓縮)
-
CMS:老年代,標記 - 清除
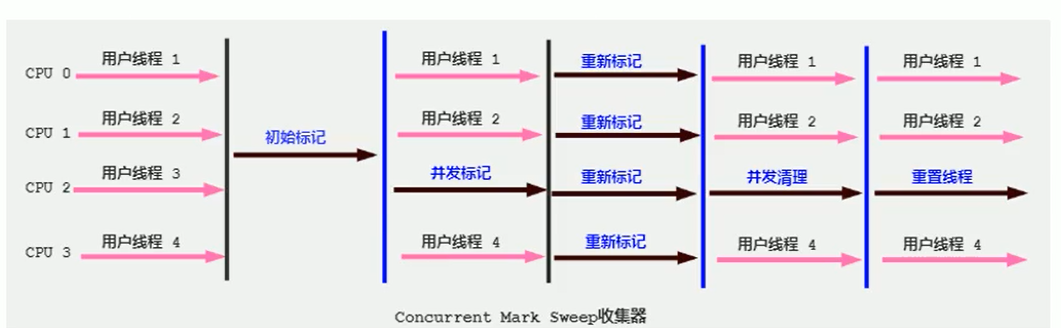
分為四個階段:初始標記、并發標記、重新標記和并發清除。初始標記和重新標記會STW,不過這兩段耗時是最短的。整體上低停頓。
缺點:
- 會產生內存碎片,FullGc時才會整理內存碎片。
- CMS 收集器會消耗CPU,程序吞吐量會下降。
- CMS 收集器無法處理浮動垃圾。在并發標記階段產生的垃圾只能在下一次CMS或FullGc時才能回收
8、如何進行JVM調優?
內存溢出問題:
-
通過gc日志和程序日志分析,OOM是什么原因引起的。
-
觀察參數是否有不合理的地方。
-
調整參數、增大內存再觀察。
-
導出內存快照分析是否有內存泄漏問題(要改代碼了)。
對于線上應用如果出現OOM,首先觀察JVM參數設置是否合理。比如堆內存一般設置為容器內存的80%,要給容器預留一些內存,元空間最好加上限制。然后繼續觀察GC日志,觀察老年代的大小變化。
9、觸發Full Gc的情況?
- 調用 System.gc()時,系統建議執行 Full GC,但是不必然執行
- 老年代空間不足
- 方法區空間不足(元空間)
- 通過 Minor GC 后進入老年代的平均大小大于老年代的可用內存
- 由 Eden 區、survivor space0(From Space)區向 survivor space1(To Space)區復制時,對象大小大于 To Space 可用內存,則把該對象轉存到老年代,且老年代的可用內存小于該對象大小
10、方法區存儲什么信息?
存儲已被虛擬機加載的類型信息、常量、靜態變量、即時編譯器編譯后的代碼緩存等。
?
框架 SSM
1、Spring的IOC和AOP說說你的理解?
2、AOP實現的兩種方式?
3、使用jdk代理和cglib的區別?
4、SpringBean的生命周期
實例化 -> 屬性賦值 -> 初始化 -> 銷毀
5、默認是單例模式,那原因知道嗎?
可以從單例的好處出發回答。
為了提高性能,少創建實例,垃圾回收,緩存快速獲取。
缺點:
所有的請求都共享一個bean實例,不能做到線程安全!
6、單例模式是線程安全的嗎?如果需要保證線程安全該如何做?
餓漢式:由JVM保證線程安全
懶漢式:雙重檢測,單例變量用volatile修飾、靜態內部類、枚舉實現。懶漢式有這三種方式線程安全。
7、Spring如何解決循環依賴?(三級緩存)
spring 循環依賴以及解決方案(吊打面試官)_循環依賴解決方案-CSDN博客
三級緩存。
核心:bean在沒有完全完成創建過程時,會在初始化階段提前把自己暴露到三級緩存中,雖然此時創建流程并未完成,但是其引用不會改變,可以優先滿足其他bean對其產生的依賴。
8、Spring中用到了什么設計模式?(接Java基礎,單例,工廠,原型,模版 jdbcTemplate,策略<多線程拒絕策略>)
9、SpringBoot的作用是什么?
10、SpringBoot如何做到自動配置?
三個注解:
@SpringBootApplication
@EnableAutoConfiguration
@Import(AutoConfigurationImportSelector.class)
// AutoConfigurationImportSelector 類實現了 ImportSelector接口,也就實現了這個接口中的 selectImports方法,該方法主要用于獲取所有符合條件的類的全限定類名,這些類需要被加載到 IoC 容器中。==核心:==自動讀取 META-INF/spring.factories 文件所有配置的類進行注入。
11、@Component、@Service、@Controller有什么區別?如果在Controller上使用@Service會怎么樣?
沒啥區別。
如果不使用springMVC時,三者使用其實是沒有什么差別的,但如果使用了springMVC,@Controller就被賦予了特殊的含義。
spring會遍歷上面掃描出來的所有bean,過濾出那些添加了注解@Controller的bean,將Controller中所有添加了注解@RequestMapping的方法解析出來封裝成RequestMappingInfo存儲到RequestMappingHandlerMapping中的mappingRegistry。后續請求到達時,會從mappingRegistry中查找能夠處理該請求的方法。
沒用SpringMVC,如果在Controller上使用@Service也是可以的。
12、Restful風格是什么?如何把@RestController換成@Controller會怎么樣?
單獨使? @Controller 不加 @ResponseBody 的話?般使?在要返回?個視圖的情況,這種情況 屬于??傳統的Spring MVC 的應?,對應于前后端不分離的情況。
前后端分離項目中:@RestController = @Controller +@ResponseBody
13、Mybatis中#和$的區別是什么?
14、Mybatis中解析sql是在那一層面完成的?
15、分頁是怎么實現,除了使用語句的方式?
16、spring事務的實現原理
在使用Spring框架的時候,可以有兩種實現方式,一種是編程式事務,另一種是聲明式事務。編程式事務需要用戶自定義代碼來控制事務的處理邏輯,類似于分布式事務中的TCC,聲明式事務通過@Transactional注解來實現。
聲明式事務@Transactional是AOP的一個核心體現,當一個方法添加@Transactional后,Spring會基于這個類生成一個代理對象,會將這個代理對象作為Bean,當使用這個代理對象的方法的時候,如果有事務處理,就會先把事務的自動提交給關閉,然后去執行具體的業務邏輯,如果業務邏輯執行沒問題,代理邏就會提交,如果出現任何異常就會回滾。當然,用戶也可以控制對哪些異常情況進行回滾。
注意事項:
- 不要在接口上聲明 @Transactional ,而要在具體類的方法上使用 @Transactional 注解,否則注解可能無效。
- 將 @Transactional 放置在類級的聲明中會使得所有方法都有事務。影響性能,推薦加在方法實現上。
- 使用了 @Transactional的方法,對同一個類里面的方法調用, @Transactional無效。比如有一個類Test,它的一個方法A,A再調用Test本類的方法B(不管B是否public還是private),但A沒有聲明注解事務,而B有。則外部調用A之后,B的事務是不會起作用的。(經常在這里出錯)
- 使用了 @Transactional 的方法, 只能是public, @Transactional注解的方法都是被外部其他類調用才有效,故只能是public。道理和上面的有關聯。故在 protected、private 或者 package-visible 的方法上使用 @Transactional 注解,它也不會報錯,但事務無效。
數據庫
1、MyIsam和Innodb的區別?
2、Innodb的事務隔離級別
可重復讀
3、如何實現事務?(MVCC)
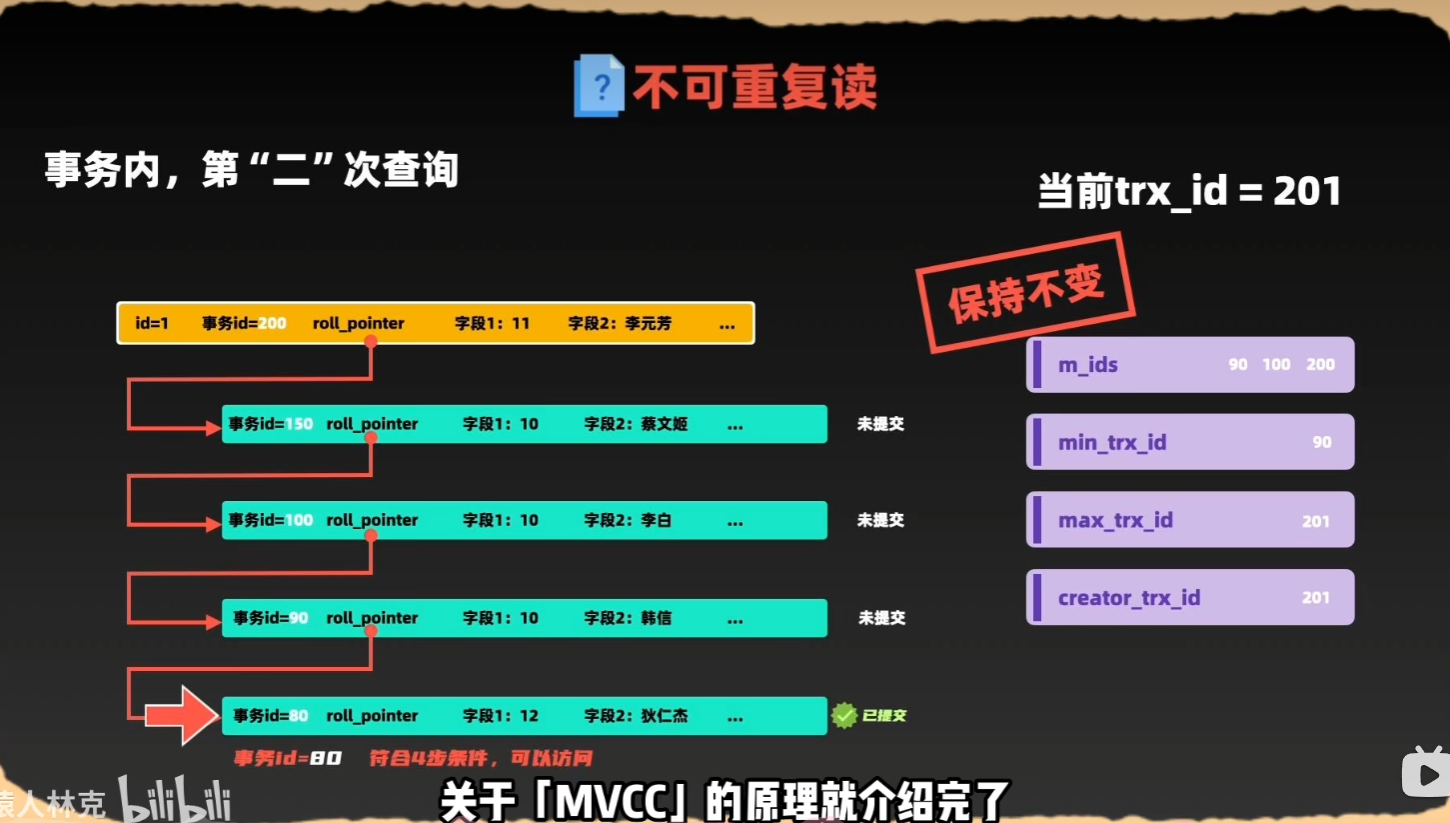
undo_log + read view
4、索引是越多越好嗎?為什么?
5、Innodb的索引和MyIsam的索引有什么區別?
6、索引是如何實現的?
7、為什么不用BTree而用B+Tree?
8、那使用索引中,索引失效、索引覆蓋都是什么意思?
索引失效:(無法依據索引使用二分查找)
- 在索引列上進行運算操作,索引將失效。
- 字符串類型字段使用時,不加引號,索引將失效。
- 頭部模糊匹配,索引失效。
- 用 or 分割開的條件,如果 or 其中一個條件的列沒有索引,那么涉及的索引都不會被用到。
- MySQL 評估使用索引比全表更慢,則不使用索引。
9、聯合索引該如何使用?ABC的聯合索引,查詢BC會走索引嗎?
10、Mysql查詢時如何根據索引查找?(考察頁、槽)
按頁讀取,進行查詢,再讀入另一頁
11、執行計劃有用過嗎?其中哪些字段需要注意?
12、優化sql的流程
- 觀察聯表數量是否太多。太多可以考慮數據冗余或者拆分為多次查詢。
- 分析是否用到索引。查看其執行計劃。
- 減少查詢的字段
13、剛才提到創建索引,你是如何考慮索引的創建的?
查詢、GROUP BY 、ORDER BY
14、分庫分表你們項目中有涉及到嗎?
有的。shardingJDBC
15、分表如何判斷所需要查詢的數據在哪一張表中?
通過分庫路由和分表路由決定
16、項目中有跨表執行數據操作嗎?具體怎么做的?
沒有。單表查的。沒有創建綁定表,不涉及聯表查詢。
如果要跨表查,可以通過綁定表減少聯表的組合數量。
17、優化limit
當limit偏移量非常大時,會很慢。慢的原因:在系統中需要進行分頁操作的時候,我們通常會使用LIMIT加上偏移量 的辦法實現,同時加上合適的ORDER BY子句。如果有對應的索引,通 常效率會不錯,否則,MySQL需要做大量的文件排序操作。
# 方案一 :返回上次查詢的最大記錄(偏移量)
SELECT id, name FROM employee WHERE id > 10000 LIMIT 10;# 方案二:orderby + 索引
SELECT id, name FROM employee ORDER BY id LIMIT 10000, 10;# 方案三:在業務允許的情況下限制頁數,太靠后的頁不查了,因為絕大多數用戶都不會往后翻太多頁。# 方案四:延遲聯接,通過覆蓋索引優化查詢
# 比如:
SELECT * FROM student WHERE age > 10 LIMIT 10000,10;
# 此時會把所有滿足數據加載進內存,然后拋棄前面10000條。# 延遲聯接優化,此時子查詢會走覆蓋索引查詢需要記錄id,再通過id集合查詢需要的數據
SELECT * FROM student INNER JOIN (SELECT id FROM student WHERE age > 10 LIMIT 10000,10) AS s;Redis
1、項目主要用Redis做什么?
2、項目中用到最多的數據類型?
3、在使用hash的時候,對于大Key值是如何操作的?
4、如果我要刪除一個hash的value,但是其中的鍵值對很多,如何刪除?
5、那如果值刪除一部分,而不是全部刪除,怎么做?
6、redis緩存機制你了解嗎?
7、RDB和AOF你們公司如何使用的?二者都用嗎還是選擇其一?
8、緩存雪崩、緩存擊穿和緩存穿透你知道嗎?都是什么意思?
緩存雪崩:
現象:緩存在同?時間??積的失效,或者redis服務宕機,后?的請求都直接落到了數據庫上,造成數據庫短時間內承受?量請求。
解決辦法:
- 采? Redis 集群,避免單機出現問題整個緩存服務都沒辦法使?。
- 限流,避免同時處理?量的請求。
緩存穿透:
現象:緩存穿透說簡單點就是?量請求的 key 根本不存在于緩存中,導致請求直接到了數據庫上,根本沒有經過緩存這?層。舉個例?:某個?客故意制造我們緩存中不存在的 key 發起?量請求,導 致?量請求落到數據庫。
解決辦法:
-
做好參數校驗。
-
布隆過濾器。(維持一個請求參數的Map)

9、剛剛提到布隆過濾器,你知道布隆過濾器是如何實現的嗎?
10、布隆過濾器的結果一定是準確無誤的嗎?
11、還有其他方式防止緩存穿透嗎?二者區別?
12、緩存雪崩如何解決,或者避免?
13、Redis的過期策略都有哪些?
14、你們有用過集群,主從嗎?
15、哨兵模式是什么,具體說說?
16、那如果哨兵掛了怎么辦?
17、使用集群或者主從是如何保證數據一致性的?
18、緩存一致性問題如何解決?
延遲雙刪:先刪緩存、更新數據庫,延遲T時間后再刪緩存。
不能完全解決。真要一致性,就別查緩存,直接從數據庫查。
19、redis的優缺點
優點:基于內存,操作非常快,而且提供了豐富的數據結構,能幫助我們解決不同的問題。
缺點:水能載舟亦能覆舟。基于內存,意味著斷電數據就沒了,需要一定的持久化策略或者集群部署。另一方面redis單機的性能瓶頸受限于內存大小。
分布式
1、你怎么理解分布式和微服務?
2、你們用的是SpringCloud是吧,那介紹一下SpringCloud都有哪些組件?
注冊中心、Feign、熔斷、網關
3、熔斷是怎么做的?
4、dubbo有用過嗎?(自己沒用過,老實說沒用過就好)
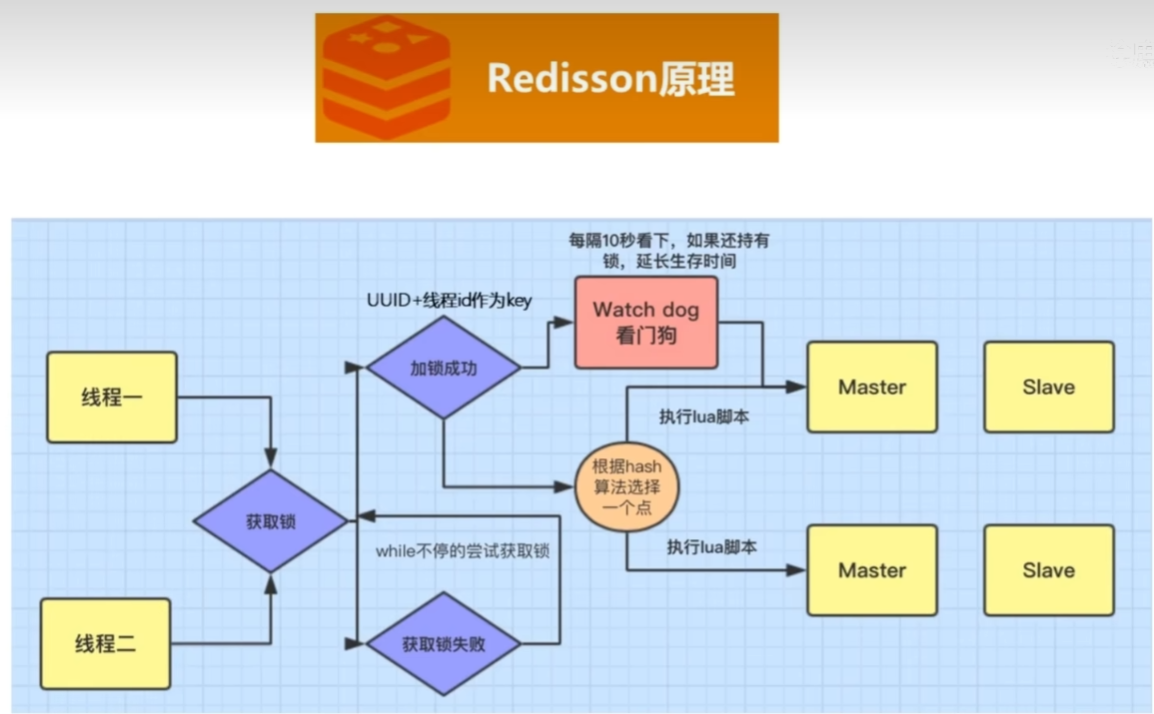
5、分布式中的鎖你知道怎么實現嗎?
6、用Redis實現需要注意什么?(這里較深,需要注意的地方也多,各種原子性,過期時間延長等等)
7、分布式事務是什么?如何實現?
分布式事務有這一篇就夠了! - 知乎 (zhihu.com)
2PC:兩階段提交,有兩種實現基于數據庫 XA 協議和Seata 實現(推薦)。由于 Seata 的 0 侵入性并且解決了傳統 2PC 長期鎖資源的問題,推薦采用 Seata 實現 2PC。
TCC:分為三個階段,業務檢查、確認提交、業務取消,三個階段需要用戶編程實現。這種方式優勢在于,可以讓應用自己定義數據操作的粒度,使得降低鎖沖突、提高吞吐量成為可能
try:
// 業務檢查
confirm:
// 確認提交
cancel:
// 業務取消

8、2PC和TCC可以詳細說一下嗎?
9、最大努力通知這種實現有了解嗎?
10、分布式鎖
其他
1、打包時使用package和install的區別?
2、項目啟動時如何跳過單元測試?
3、單元測試作用是什么?
4、Nexus你了解嗎?
私服。
5、服務部署平時有做嗎?
6、Linux使用多嗎?
消息隊列
【RocketMQ面試題(23道)】-CSDN博客
1、項目組當中用到消息隊列的場景是什么?
2、 那消息丟失和重復你們有遇到過嗎?是如何解決的?
3、Kafka消息是全局有序的嗎?
不是。
4、Kafka如何保證消息有序消費
分區內消費是有序的。
-
1 個 Topic 只對應?個 Partition。
-
(推薦)發送消息的時候指定 key/Partition。
RocketMq順序消息實現方式:
發送端單線程串行發送,接收端每個消費組單線程串行消費,每個消費組的消息發送到同一個隊列中。
5、RocketMQ如何保證消息的可用性/可靠性/不丟失呢?
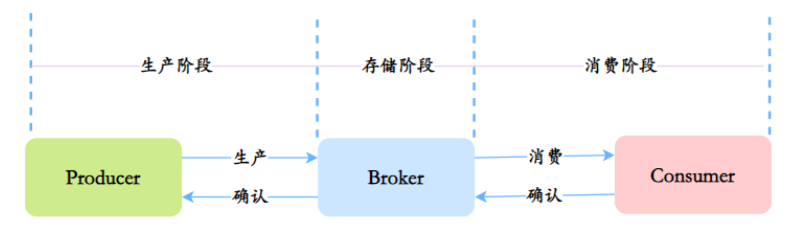
從這三個過程考慮:
生產階段:
通過請求確認機制,來保證消息的可靠傳遞。
- 同步發送的時候,要注意處理響應結果和異常。如果返回響應OK,表示消息成功發送到了Broker,如果響應失敗,或者發生其它異常,都應該重試。
- 異步發送的時候,應該在回調方法里檢查,如果發送失敗或者異常,都應該進行重試。
- 如果發生超時的情況,也可以通過查詢日志的API,來檢查是否在Broker存儲成功。
存儲階段:
存儲階段,可以通過配置可靠性優先的 Broker 參數來避免因為宕機丟消息,簡單說就是可靠性優先的場景都應該使用同步。
- 消息只要持久化到CommitLog(日志文件)中,即使Broker宕機,未消費的消息也能重新恢復再消費。
- Broker的刷盤機制:同步刷盤和異步刷盤,不管哪種刷盤都可以保證消息一定存儲在pagecache中(內存中),但是同步刷盤更可靠,它是Producer發送消息后等數據持久化到磁盤之后再返回響應給Producer。
- Broker通過主從模式來保證高可用,Broker支持Master和Slave同步復制、Master和Slave異步復制模式,生產者的消息都是發送給Master,但是消費既可以從Master消費,也可以從Slave消費。同步復制模式可以保證即使Master宕機,消息肯定在Slave中有備份,保證了消息不會丟失。
消費階段:
邏輯執行完再發送消費進行確認
- Consumer保證消息成功消費的關鍵在于確認的時機,不要在收到消息后就立即發送消費確認,而是應該在執行完所有消費業務邏輯之后,再發送消費確認。因為消息隊列維護了消費的位置,邏輯執行失敗了,沒有確認,再去隊列拉取消息,就還是之前的一條。
6、如何處理消息重復的問題呢?
處理消息重復問題,主要有業務端自己保證,主要的方式有兩種:業務冪等和消息去重。
業務冪等:第一種是保證消費邏輯的冪等性,也就是多次調用和一次調用的效果是一樣的。這樣一來,不管消息消費多少次,對業務都沒有影響。
消息去重:第二種是業務端,對重復的消息就不再消費了。這種方法,需要保證每條消息都有一個唯一的編號,通常是業務相關的,比如訂單號,消費的記錄需要落庫,而且需要保證和消息確認這一步的原子性。可以建立一個消費記錄表,拿到這個消息做數據庫的insert操作。給這個消息做一個唯一主鍵(primary key)或者唯一約束,那么就算出現重復消費的情況,就會導致主鍵沖突,那么就不再處理這條消息。
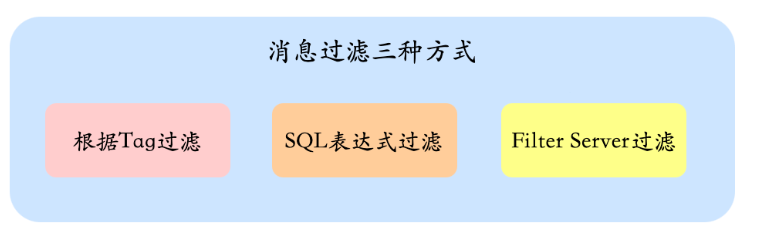
7、如何實現消息過濾?
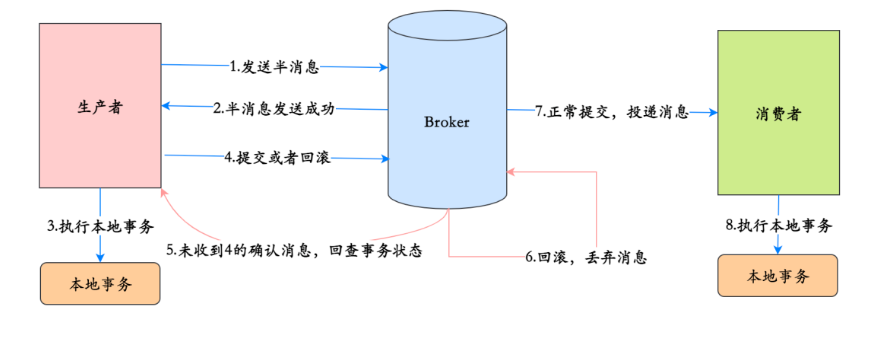
8、事務消息的實現
9、死信隊列知道嗎?
死信隊列用于處理無法被正常消費的消息,即死信消息。
一條消息初次消費失敗,消息隊列 RocketMQ 會自動進行消息重試;達到最大重試次數后,若消費依然失敗,則表明消費者在正常情況下無法正確地消費該消息,此時,消息隊列 RocketMQ 不會立刻將消息丟棄,而是將其發送到該消費者對應的特殊隊列中,該特殊隊列稱為死信隊列。
死信消息的特點:
- 不會再被消費者正常消費。
- 有效期與正常消息相同,均為 3 天,3 天后會被自動刪除。因此,需要在死信消息產生后的 3 天內及時處理。
死信隊列的特點:
- 一個死信隊列對應一個 Group ID, 而不是對應單個消費者實例。
- 如果一個 Group ID 未產生死信消息,消息隊列 RocketMQ 不會為其創建相應的死信隊列。
- 一個死信隊列包含了對應 Group ID 產生的所有死信消息,不論該消息屬于哪個 Topic。
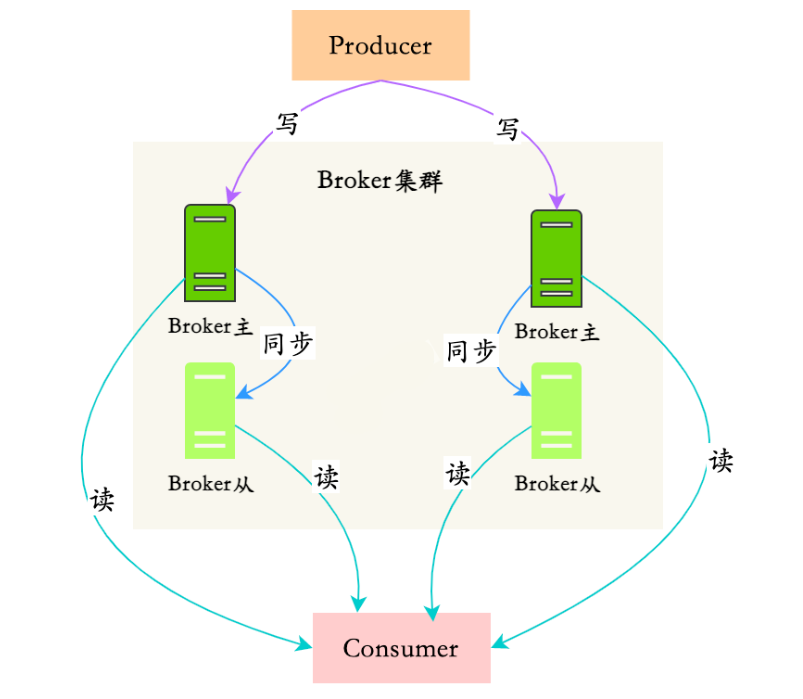
10.如何保證RocketMQ的高可用?
NameServer因為是無狀態,且不相互通信的,所以只要集群部署就可以保證高可用。
RocketMQ的高可用主要是在體現在Broker的讀和寫的高可用,Broker的高可用是通過集群和主從實現的。
11、消息刷盤怎么實現的呢?
RocketMQ提供了兩種刷盤策略:同步刷盤和異步刷盤
- 同步刷盤:在消息達到Broker的內存之后,必須刷到commitLog日志文件中才算成功,然后返回Producer數據已經發送成功。
- 異步刷盤:異步刷盤是指消息達到Broker內存后就返回Producer數據已經發送成功,會喚醒一個線程去將數據持久化到CommitLog日志文件中。
計算機網絡
1、 TCP粘包和拆包問題有了解嗎?
面試題:聊聊TCP的粘包、拆包以及解決方案 - 知乎 (zhihu.com)
TCP是面向字節流的。
由于緩沖區的存在,兩個TCP報文被同一個緩沖區接收,就是粘包。一個TCP報文被多個緩沖區接收就是拆包。
對于粘包和拆包問題,常見的解決方案有四種:
- 發送端將每個包都封裝成固定的長度,比如100字節大小。如果不足100字節可通過補0或空等進行填充到指定長度;
- 發送端在每個包的末尾使用固定的分隔符,例如\r\n。如果發生拆包需等待多個包發送過來之后再找到其中的\r\n進行合并;例如,FTP協議;
- 將消息分為頭部和消息體,頭部中保存整個消息的長度,只有讀取到足夠長度的消息之后才算是讀到了一個完整的消息;
- 通過自定義協議進行粘包和拆包的處理。
Netty對粘包和拆包問題的處理:
- LineBasedFrameDecoder:以行為單位進行數據包的解碼;
- DelimiterBasedFrameDecoder:以特殊的符號作為分隔來進行數據包的解碼;
- FixedLengthFrameDecoder:以固定長度進行數據包的解碼;
- LenghtFieldBasedFrameDecode:適用于消息頭包含消息長度的協議(最常用);
)









—— 深度優先)



)




