目錄
寫在前面
一、LoRA算法原理
1.設計思想
2.具體實現
二、peft庫
三、完整的訓練代碼
四、總結
寫在前面
? ? ? ? 現在有很多開源的大模型,他們一般都是通用的,這就意味著這些開源大模型在特定任務上可能力不從心。為了適應我們的下游任務,就需要對預訓練模型進行微調。
????????全參數微調有兩個問題:在新的數據集上訓練,會破壞大模型原來的能力,使其泛化能力急劇下降;而且現在的模型參數動輒幾十億上百億,要執行全參數微調的話,他貴啊!!

? ? ? ? 于是LoRA出現了,?LoRA(Low-Rank Adaptation)是微軟提出的一種參數有效的微調方法,可以降低微調占用的顯存以及更輕量化的遷移。同時解決了上述兩個問題,那它憑什么這么厲害?往下看吧。
一、LoRA算法原理
1.設計思想
? ? ? ? 論文地址:https://arxiv.org/pdf/2106.09685
????????模型是過參數化的,它們有更小的內在維度,模型主要依賴于這個低的內在維度(low intrinsic dimension)去做任務適配。假設模型在適配任務時參數的改變量是低秩的,由此引出低秩自適應方法lora,通過低秩分解來模擬參數的改變量,從而以極小的參數量來實現大模型的間接訓練。
? ? ? ?上面那段話也許有點難以理解。簡單來講,LoRA是大模型的低秩適配器,或者就簡單的理解為適配器,在圖像生成中可以將lora理解為某種圖像風格(比如SD社區中的各種漂亮妹子的lora,可插拔式應用,甚至組合式應用實現風格的融合)的適配器,在NLP中可以將其理解為某個任務的適配器(比如基于通用大模型訓練的各個領域的專家大模型)。
2.具體實現
? ? ? ? LoRA的實現方式是在基礎模型的線性變換模塊(全連接、Embedding、卷積)旁邊增加一個旁路,這個旁路是由兩個小矩陣做內積得來的,兩個小矩陣的中間維度,就是秩!!
????????通過低秩分解(先降維再升維)來模擬參數的更新量。
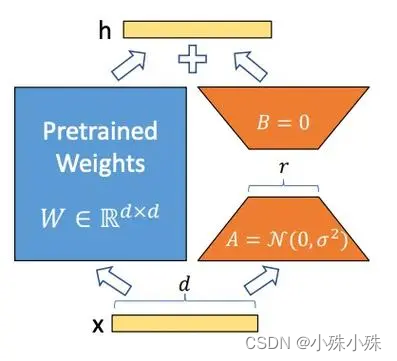
????????下面是LoRA的公式:
? ? ? ?上面公式中x是這一層的輸入,h是這一層的輸出,是基礎模型的權重參數;A和B是兩個小矩陣,A的輸入和B的輸出形狀跟
一樣,A的輸出和B的輸入一樣,稱為秩,秩一般很小,微調的所有“新知識”都保存在A和B里面;
是一個縮放系數,這個數越大,LoRA權重的影響就越大。
? ? ? ? 下面就是經典的LoRA運算流程圖:
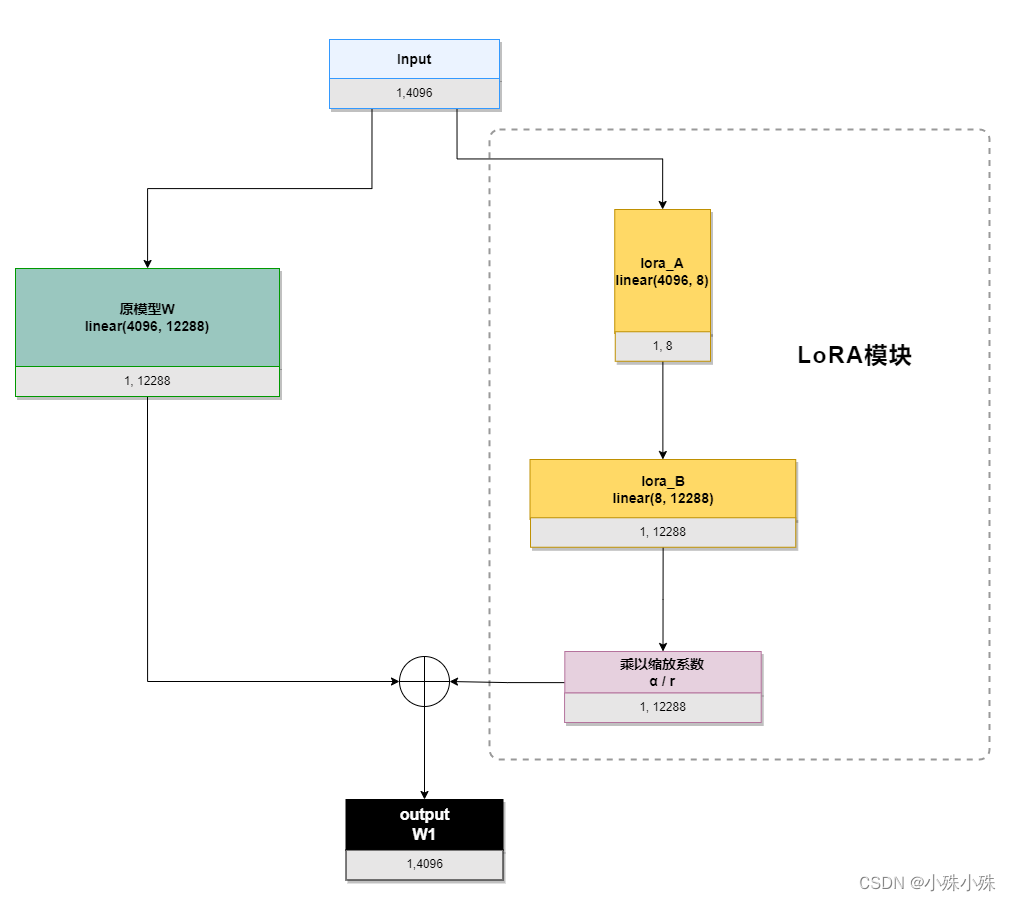
? ? ? ? 我們以ChatGLM的attention模塊的query_key_value(是一個linear(4096, 12288))為例,描述一下流程,其中輸入4096、輸出12288,LoRA的秩是8:
? ? ? ? 初始化時,lora_A采用高斯分布初始化,lora_B初始化為全0,保證訓練開始時旁路為0矩陣;????????
????????訓練時,原模型固定,只訓練降維矩陣A和升維矩陣B;
????????推理時需要做參數合并,就是將AB的內積(一個與基礎模型形狀一樣的低秩矩陣)加到原參數上,這樣不引入額外的推理延遲。對于上圖的例子,lora_A與lora_B做內積,得到4096x1228的參數矩陣,然后與基礎模型W相加就可以了。
? ? ? ? 我們來算算需要訓練多少參數,如果是全參數需要訓練4096*12288=50331648個參數,LoRA需要訓練4096*8+8*12288=131072,參數可是數量級的減少啊。
二、peft庫
? ? ? ? Pytorch中peft庫實現了LoRA算法,而且使用非常方便,我們以ChatGLM代碼為例,看一下LoRA對ChatGLM模型做了什么,直接上代碼:
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModel, HfArgumentParser, TrainingArgumentsfrom finetune import CastOutputToFloat, FinetuneArgumentsdef count_params(model):for name, param in model.named_parameters():print(name, param.shape)def make_peft_model():# 初始化原模型model = AutoModel.from_pretrained("THUDM/chatglm-6b", load_in_8bit=False, trust_remote_code=True, device_map="auto", local_files_only=True).float()# 給原模型施加LoRApeft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=True,r=8,lora_alpha=32,lora_dropout=0.1,target_modules=['query_key_value'],)model = get_peft_model(model, peft_config).float()count_params(model)if __name__ == '__main__':make_peft_model()? ? ? ? 輸出如下:? ? ? ?
base_model.model.transformer.word_embeddings.weight torch.Size([130528, 4096])
base_model.model.transformer.layers.0.input_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.0.input_layernorm.bias torch.Size([4096])
base_model.model.transformer.layers.0.attention.query_key_value.base_layer.weight torch.Size([12288, 4096])
base_model.model.transformer.layers.0.attention.query_key_value.base_layer.bias torch.Size([12288])
base_model.model.transformer.layers.0.attention.query_key_value.lora_A.default.weight torch.Size([8, 4096])
base_model.model.transformer.layers.0.attention.query_key_value.lora_B.default.weight torch.Size([12288, 8])
base_model.model.transformer.layers.0.attention.dense.weight torch.Size([4096, 4096])
base_model.model.transformer.layers.0.attention.dense.bias torch.Size([4096])
base_model.model.transformer.layers.0.post_attention_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.0.post_attention_layernorm.bias torch.Size([4096])
base_model.model.transformer.layers.0.mlp.dense_h_to_4h.weight torch.Size([16384, 4096])
base_model.model.transformer.layers.0.mlp.dense_h_to_4h.bias torch.Size([16384])
base_model.model.transformer.layers.0.mlp.dense_4h_to_h.weight torch.Size([4096, 16384])
base_model.model.transformer.layers.0.mlp.dense_4h_to_h.bias torch.Size([4096])
base_model.model.transformer.layers.1.input_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.1.input_layernorm.bias torch.Size([4096])......
? ? ? ? 可以看到模型中被添加了LoRA模塊(紅色部分),是根據全連接“query_key_value”生成的。因為query_key_value層輸入是4096,輸出是12288,而配置中LoRA的秩是8,所以兩個LoRA塊是(8,4096)和(12288, 8)
????????代碼也很好理解,get_peft_model方法將原模型參數凍結并且根據配置向模型中添加LoRA模塊。
????????解釋一下配置LoraConfig,下面是這個對象的主要參數:
?1.task_type:
????????SEQ_CLS:序列分類(Sequence Classification)任務。這種任務涉及對輸入序列整體進行分類,例如情感分析、文本分類等。
????????SEQ_2_SEQ_LM:序列到序列語言建模(Sequence-to-Sequence Language Modeling)任務。這種任務能夠將一個輸入序列映射到另一個輸出序列,例如機器翻譯、文本摘要等。
????????CAUSAL_LM:因果語言建模(Causal Language Modeling)任務。這種任務涉及訓練一個模型,使其能夠預測給定先前上下文的下一個標記,例如自動補全、語言生成等。
????????TOKEN_CLS:標記分類(Token Classification)任務。這種任務涉及對輸入序列中的每個標記進行分類,例如命名實體識別、詞性標注等。
????????QUESTION_ANS:問答(Question Answering)任務。這種任務涉及根據給定的問題和相關的上下文文本來預測答案。輸入是Prompt+問題。
????????FEATURE_EXTRACTION:特征提取(Feature Extraction)任務。這種任務涉及從文本或序列中提取有用的特征,以供其他任務或模型使用。
2.r:LoRA秩的維度,這數越大,微調帶來的“影響”越強,但是需要訓練的參數量會增加。
3.lora_alpha:LoRA在前向傳播的過程中引入一個額外的擴展系數(scaling coefficient),用于將LoRA權重應用于預訓練權重。這個數越大,LoRA權重的影響就越大。
4.target_modules:要施加LoRA的模塊名稱,需要注意的是,參數是字符串數組,模塊類型必須是`torch.nn.Linear`, `torch.nn.Embedding`, `torch.nn.Conv2d`, `transformers.pytorch_utils.Conv1D`中的一個。比如這個例子中還可以填寫"word_embeddings"和"dense"。
三、完整的訓練代碼
? ? ? ? 現在給出一個完整的基于LoRA的ChatGLM訓練代碼,peft庫在原模型基礎上添加LoRA非常方便,對代碼的侵入也很小。下面的代碼我添加了注釋,流程還是很清楚的:
from transformers.integrations import TensorBoardCallback
from torch.utils.tensorboard import SummaryWriter
from transformers import TrainingArguments
from transformers import Trainer, HfArgumentParser
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn as nn
from peft import get_peft_model, LoraConfig, TaskType
from dataclasses import dataclass, field
import datasets
import ostokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)@dataclass
class FinetuneArguments:dataset_path: str = field(default="data/alpaca")model_path: str = field(default="output")lora_rank: int = field(default=8)class CastOutputToFloat(nn.Sequential):def forward(self, x):return super().forward(x).to(torch.float32)def data_collator(features: list) -> dict:len_ids = [len(feature["input_ids"]) for feature in features]longest = max(len_ids)input_ids = []labels_list = []for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):ids = feature["input_ids"]seq_len = feature["seq_len"]labels = ([-100] * (seq_len - 1) + ids[(seq_len - 1) :] + [-100] * (longest - ids_l))ids = ids + [tokenizer.pad_token_id] * (longest - ids_l)_ids = torch.LongTensor(ids)labels_list.append(torch.LongTensor(labels))input_ids.append(_ids)input_ids = torch.stack(input_ids)labels = torch.stack(labels_list)return {"input_ids": input_ids,"labels": labels,}class ModifiedTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False):return model(input_ids=inputs["input_ids"],labels=inputs["labels"],).lossdef save_model(self, output_dir=None, _internal_call=False):self.model.save_pretrained(output_dir)def main():writer = SummaryWriter()# 組織訓練參數finetune_args, training_args = HfArgumentParser((FinetuneArguments, TrainingArguments)).parse_args_into_dataclasses()# init modelmodel = AutoModel.from_pretrained("THUDM/chatglm-6b", load_in_8bit=False, trust_remote_code=True, device_map="auto", local_files_only=True).float()model.gradient_checkpointing_enable()model.enable_input_require_grads()# 模型是可以并行化的。model.is_parallelizable = True# 啟用模型的并行化。model.model_parallel = True# 將模型的 lm_head(語言模型頭)的輸出轉換為浮點數類型。model.lm_head = CastOutputToFloat(model.lm_head)# 禁用模型配置中的緩存,用于禁止緩存中間結果,可以減少顯存占用,但是訓練時間會變長model.config.use_cache = (False # silence the warnings. Please re-enable for inference!)# LoRA配置peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False,r=finetune_args.lora_rank,lora_alpha=32,lora_dropout=0.1,)# 對模型使用LoRAmodel = get_peft_model(model, peft_config).float()# 使用alpaca數據集dataset = datasets.load_from_disk(finetune_args.dataset_path)print(f"\n{len(dataset)=}\n")# for d in dataset.iter(batch_size=1):# print("d:", d)# start traintrainer = ModifiedTrainer(model=model,train_dataset=dataset,args=training_args,callbacks=[TensorBoardCallback(writer)],data_collator=data_collator,)trainer.train()writer.close()# 存訓練后的參數model.save_pretrained(training_args.output_dir)if __name__ == "__main__":main()
? ? ? ? 訓練之后模型文件會保存在output_dir目錄中。到這里我們發現一個問題,畢竟LoRA在原模型的基礎上加了分支,這會帶來推理效率的降低,其實我們調用merge_and_unload方法就能將LoRA的分支模塊合并到基礎模型,推理代碼如下:
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModel, AutoModelForSeq2SeqLM
import torch
from transformers import AutoTokenizer# 加載基礎模型
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)# 配置LoRA
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM, inference_mode=True,target_modules=['query_key_value'],r=8, lora_alpha=32, lora_dropout=0.1
)
# 對模型使用LoRA
model = get_peft_model(model, peft_config).half()
# 加載LoRA參數
model.load_state_dict(torch.load("output/checkpoint-1000/adapter_model.bin", map_location=torch.device("cuda")), strict=False)
# 將LoRA的分支模塊合并到基礎模型
model.merge_and_unload()while True:prompt = input("Prompt: ")inputs = tokenizer(prompt, return_tensors="pt")model.params_dtype = torch.float32response = model.generate(input_ids=inputs["input_ids"],max_length=inputs["input_ids"].shape[-1] + 128)response = response[0, inputs["input_ids"].shape[-1]:]print("responseL", response)for r in response:print(r, ":", tokenizer.decode([r], skip_special_tokens=False))print("Response:", tokenizer.decode(response, skip_special_tokens=True))
四、總結
1.LoRA的實現方式是在原模型的線性變換模塊(全連接、Embedding、卷積)旁邊增加一個旁路,通過低秩分解(先降維再升維)來模擬參數的更新量。
2.LoRA模塊由兩個小矩陣組成,這兩個矩陣內積的輸入輸出形狀與原模型一致,大模型需要的“新知識”就存在這個模塊中;
3.秩可以很小,有實驗表明,就算秩=1,效果也不是很差;
4.盡量多的對模型中的線性變換模塊使用秩很小LoRA;而不是對一個模塊使用秩很大的LoRA;
5.推理時需要做參數合并,就是將AB的內積加到原參數上,從而不引入額外的推理延遲;
5.LoRA智能一定程度提升模型在某個領域的能力,并不能使模型發生根本性的能力提升。
LoRA就介紹到這里,關注不迷路(#^.^#)
關注訂閱號了解更多精品文章

交流探討、商務合作請加微信





即將召開!)
深入理解 Chrome 擴展的 manifest.json 配置文件)



)



-maven-shade-plugin)


:樹和存儲結構及示例)

: binary file matches)
