前言
如果你一直在跟著Fanstuck博主的腳步探索AI大模型的相關內容,從最初的大模型Prompt工程解析,DeepSeek全面解析,到實際的私有化大模型開發部署,再到深入NL2SQL、知識圖譜大模型和ChatBI等更高階應用.我是Fanstuck,致力于將復雜的技術知識以易懂的方式傳遞給讀者,熱衷于分享最新的行業動向和技術趨勢。如果你對大模型的創新應用、AI技術發展以及實際落地實踐感興趣,那么請關注Fanstuck。

1、推薦算法分類
推薦系統的發展歷史可以看作是一場技術迭代的縮影。從最早的協同過濾,到后來基于深度學習的方法,再到近幾年火熱的圖神經網絡與強化學習,直到今天我們談論的大模型(LLM)推薦,這條路線背后反映的是行業不斷追求更高精度、更強泛化能力以及更好的用戶體驗的過程。
在這一章里,我們先來回顧一下常見的幾類推薦算法,理解它們的原理、優勢與不足,同時配合一些實際案例,幫助你從整體上把握推薦系統技術的發展脈絡。

1.1基于傳統方法的推薦
在互聯網早期,用戶行為數據相對有限,模型復雜度也無法做得太高。于是,簡單直觀的推薦方法成了主流。這里面最典型的就是協同過濾和基于內容的推薦。除此之外,還有基于知識的推薦,以及將多種方法融合的混合推薦。
| 名稱 | 核心思想 | 典型模型/做法 | 優點 | 局限與風險 | 適用場景 |
|---|---|---|---|---|---|
| 協同過濾(CF) | “物以類聚、人以群分”:利用用戶–物品交互矩陣中的相似性做外推 | User-KNN / Item-KNN、MF(SVD/ALS/BPR)、item2vec | 簡單有效、可解釋性較強(特別是 Item-CF) | 冷啟動、數據稀疏、易受噪聲影響 | 老練業務、交互較豐富的場景 |
| 基于內容(Content-Based) | 比較物品內容與用戶畫像的相似度 | TF-IDF/BM25、特征工程 + 余弦相似度、詞向量/句向量 | 冷啟動友好、偏好可遷移 | 內容表征質量決定上限,易“窄化” | 媒體/長文本、屬性豐富的品類 |
| 基于知識(Knowledge-Based) | 注入領域知識與規則,約束與增強推薦 | 規則庫、知識圖譜、約束檢索 | 冷啟動與合規友好、精準可控 | 知識獲取/維護成本高,多樣性受限 | 強合規/強約束場景(金融/醫療/政企) |
| 混合(Hybrid) | 多策略組合、取長補短 | 加權融合、切換、分區展示、分層(Meta-Level) | 綜合表現最好、魯棒 | 復雜度高、參數調優難 | 大規模線上業務的主流工程范式 |
1.1.1 基于協同過濾的推薦
協同過濾(Collaborative Filtering,CF)可能是最廣為人知的推薦算法了。它的直覺非常貼近人類社交:如果我和你興趣相似,那么你喜歡的東西,我大概率也會喜歡。
協同過濾有兩種經典形式:
- 基于用戶的協同過濾:尋找一群和目標用戶興趣相似的人,再把他們喜歡的物品推薦給目標用戶。
- 基于物品的協同過濾:找出和用戶喜歡過的物品相似的候選物品,再推送給用戶。
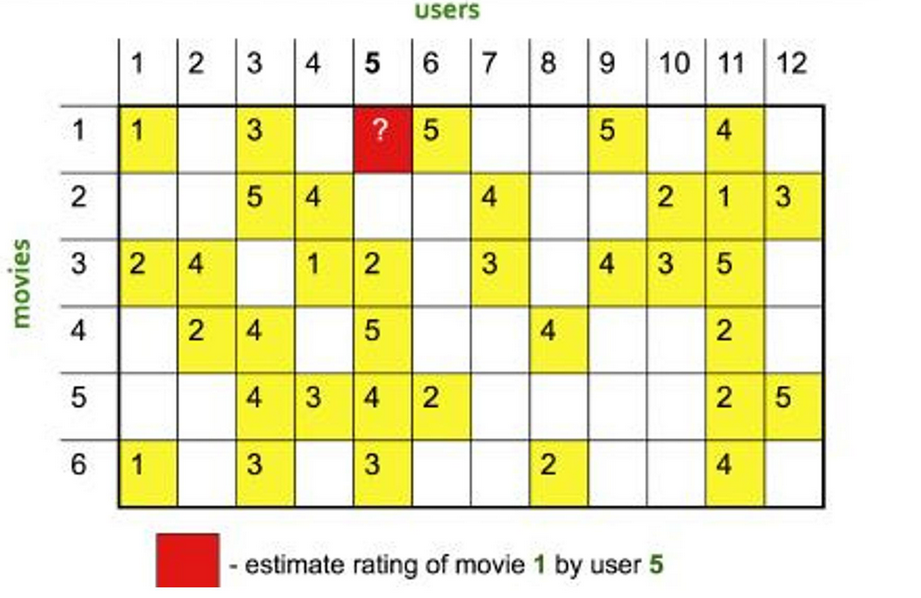
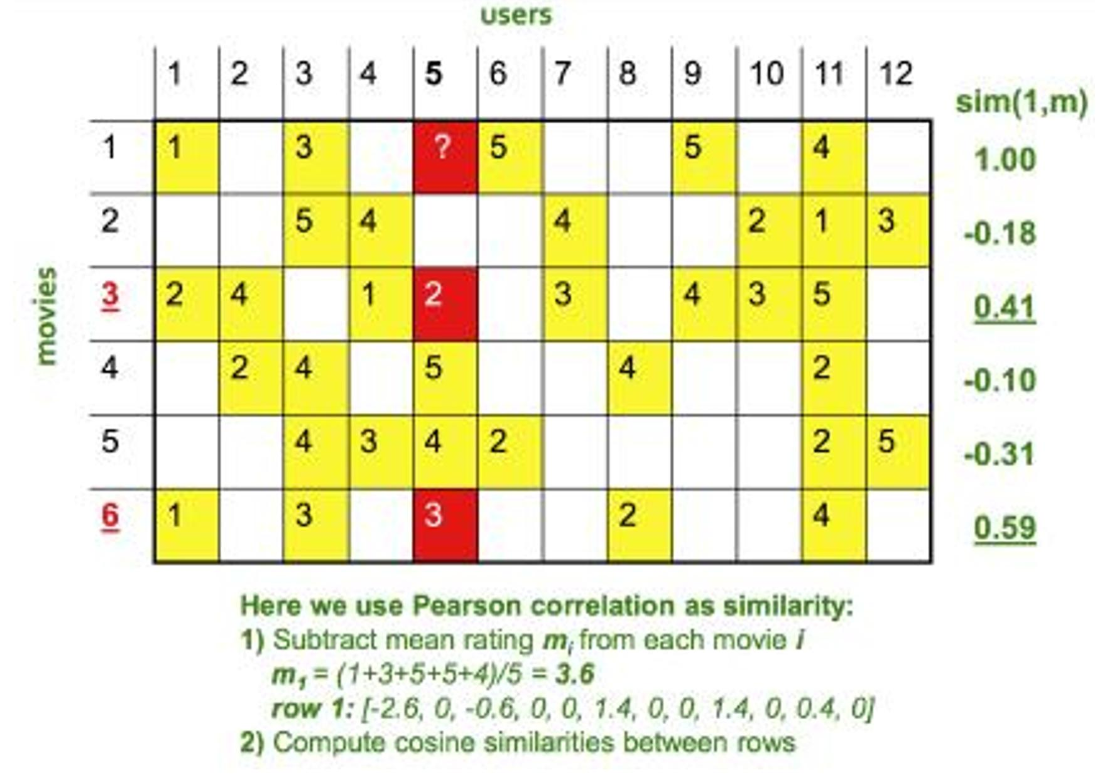
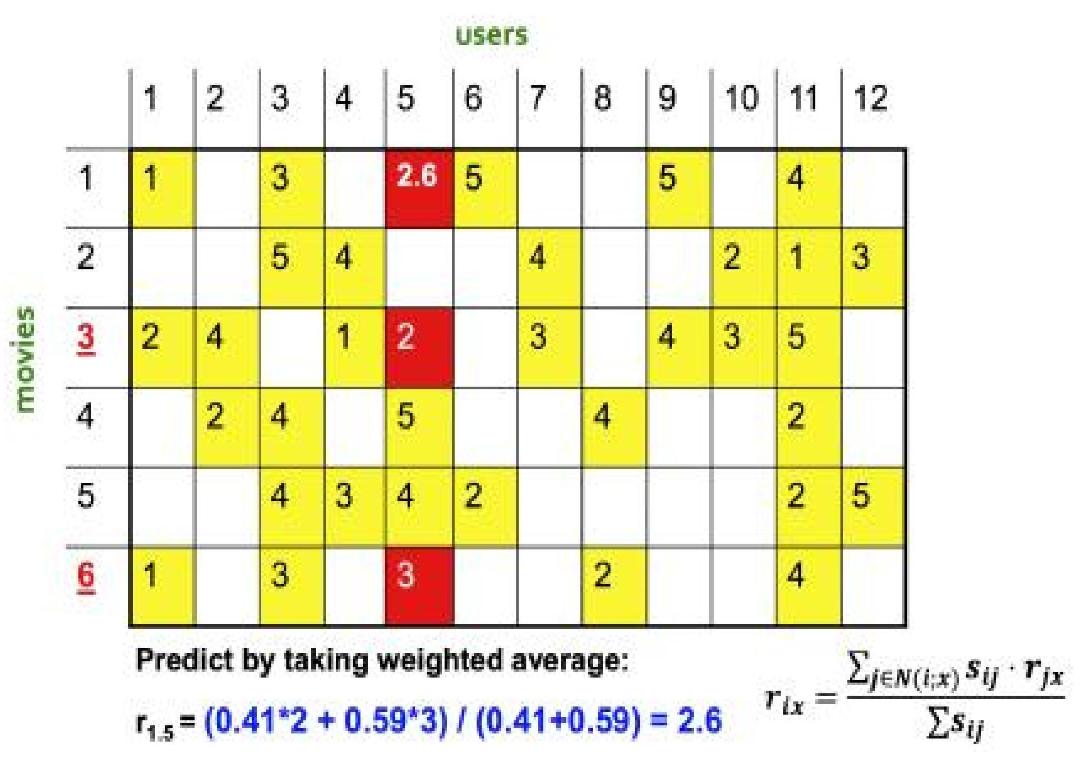
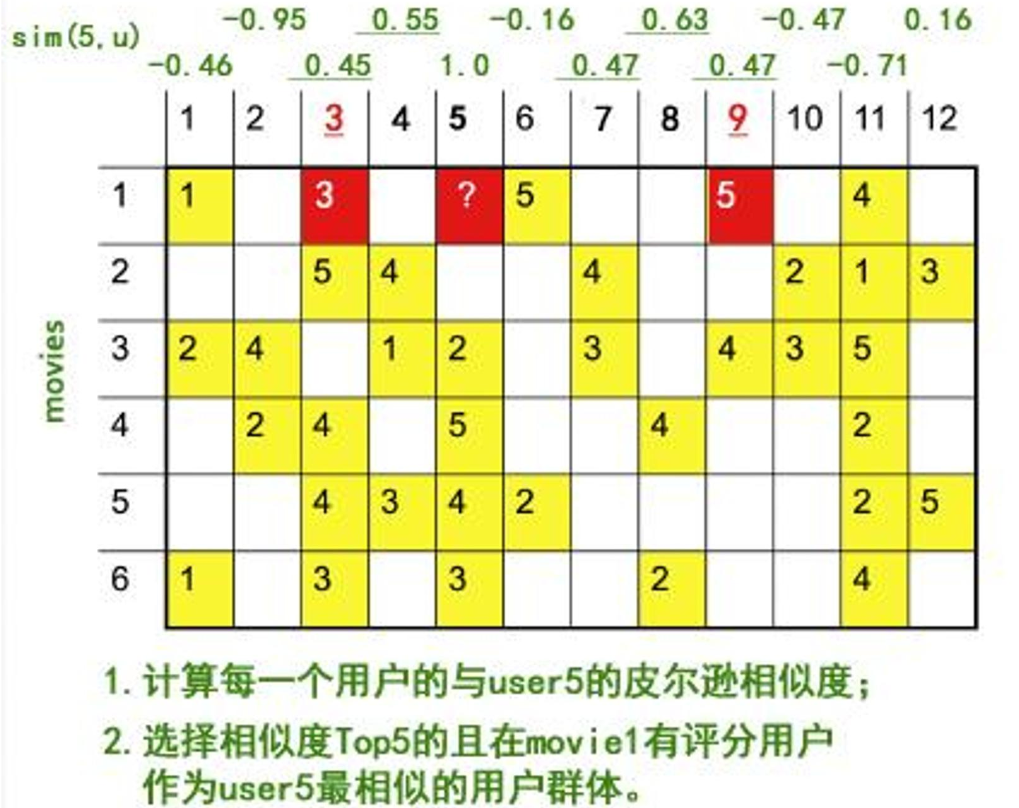
舉個例子。在一個電影網站上,我們收集了用戶對電影的打分,構建出一個用戶–電影的評分矩陣。如果我們想預測 user5 對《盜夢空間》的喜好,可以先找到和 user5 觀影口味最接近的幾位用戶,看看他們對這部電影的打分,再綜合這些打分推測 user5 的偏好。
迷你案例(電影):構建用戶–電影矩陣 → 計算 Item-Item 相似度 → 對目標用戶做 Top-N 候選 → 結合近鄰權重打分 → 推薦。
計算流程展示: 矩陣填充示例,預估user5對 movie1 的評分
步驟:
①數據收集:首先,需要收集用戶與電影之間的交互數據,例如用戶對電影的評分、瀏覽記錄、購買記錄等。
②創建矩陣:根據用戶與電影的交互數據,構建一個用戶-項目(電影)評分矩陣。
③選擇協同濾波算法,此處默認選擇與用戶的協同過濾,該算法通過計算用戶之間的相似度
④來找到與目標用戶相似的其他用戶,然后根據這些相似用戶的喜好為目標用戶推薦電影。
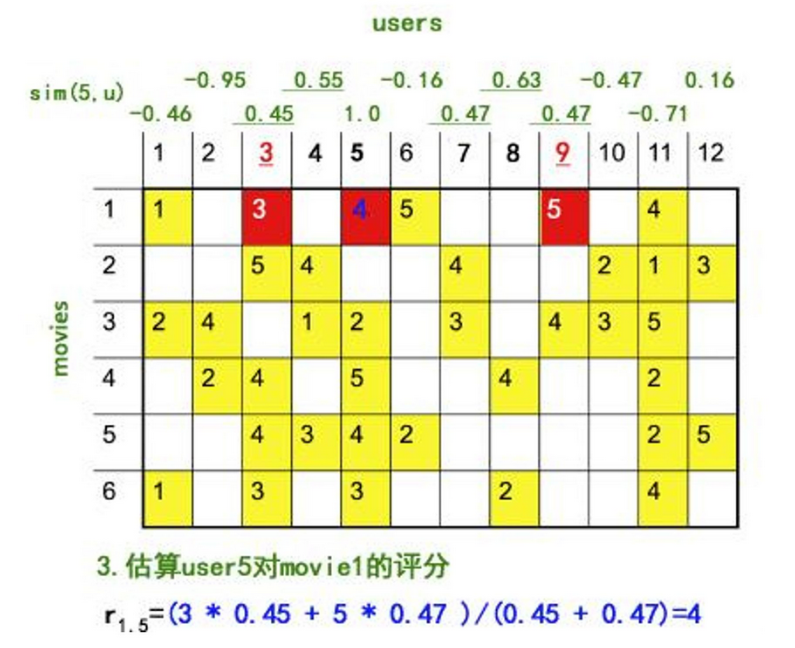
這種方法實現簡單,而且在數據相對稠密的情況下表現很不錯。但它的問題也很明顯:
- 新用戶、新物品沒有數據時,系統很難做出推薦,這就是所謂的冷啟動問題;
- 評分矩陣往往非常稀疏,很多地方都是空的,導致算法難以找到可靠的相似性。
為了緩解稀疏性,人們后來引入了矩陣分解(Matrix Factorization)方法,把用戶和物品都映射到一個低維向量空間里,用向量點積來預測用戶的興趣。這類方法在 Netflix Prize 比賽中大放異彩,也推動了工業界的廣泛應用。
1.1.2 基于內容的推薦
如果協同過濾強調的是“人以群分”,那么基于內容的推薦強調的就是“物以類聚”。它關注的是物品本身的特征,而不是依賴大量的用戶行為。
比如,我們有一部電影的簡介:“一支探索隊進入蟲洞,尋找人類的新家園。”如果用戶之前喜歡過《星際穿越》,那么這部電影很可能也會吸引他。這里的關鍵在于如何把“電影的內容”轉化為可計算的特征向量。
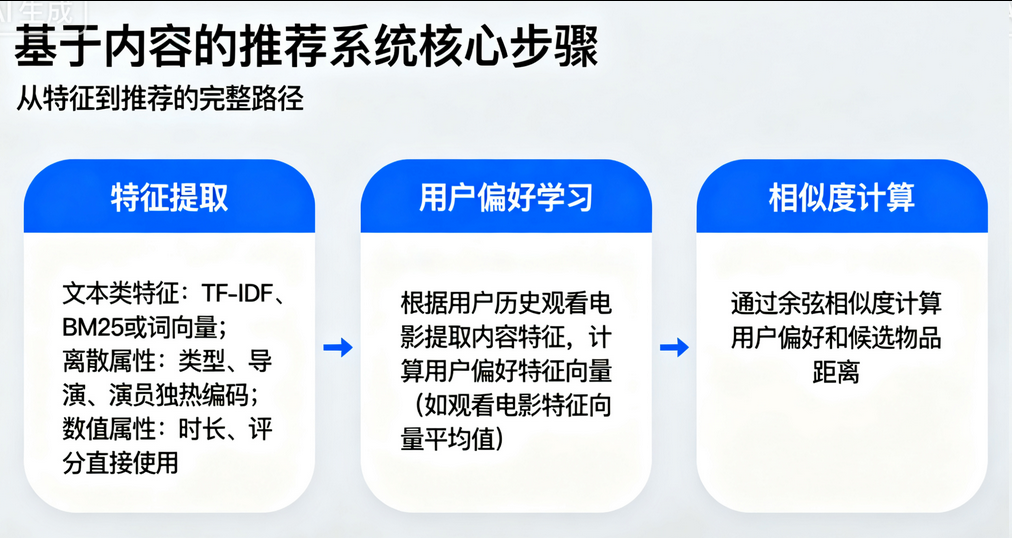
常見做法是對文本類特征使用 TF-IDF、BM25 或詞向量來表示,對離散屬性(類型、導演、演員)做獨熱編碼,對數值屬性(時長、評分)直接使用。最后,通過余弦相似度計算用戶偏好和候選物品之間的距離。
基于內容的推薦在冷啟動時比協同過濾更有優勢,因為它不依賴用戶行為。但它也容易陷入“越推越窄”的陷阱:如果你看了幾部科幻片,系統就會一直推薦科幻,難以拓展到多樣化的興趣。
比如構建一個電影推薦系統,首先需要準備電影數據,這里假設有一個包含電影信息的 DataFrame,其中包括電影的標題、類型、導演、演員以及劇情簡介等字段。
根據用戶歷史觀看的電影(如“星際穿越”和“盜夢空間”),系統推薦了具有相似特征(如科幻類型、相同導演等)的電影。在這個例子中,BM25 算法有效地計算了用戶偏好與候選電影之間的相似度,并為用戶推薦了最相關的電影。
流程: ①特征提取:使用文本處理技術(如分詞、去停用詞等)對電影的劇情簡介進行預處理,并構建詞袋模型或 TF-IDF模型來表示電影的內容特征。
②用戶偏好學習:根據用戶歷史觀看的電影,提取這些電影的內容特征,并計算用戶偏好的特征向量。例如,可以將用戶觀看過的電影的特征向量求平均作為用戶的偏好向量
③相似度計算:使用余弦相似度、BM25 等算法計算用戶偏好向量與候選電影特征向量之間的相似度。
1.1.3 基于知識/混合的推薦算法
除了協同過濾和內容推薦,還有一種方法是基于知識的推薦。它常見于強約束領域,例如醫療或金融。在這些場景里,推薦結果不僅要符合用戶偏好,還必須滿足一系列嚴格的業務規則。比如,在金融推薦中,用戶的資質、風險等級、合規要求,都會影響能不能推薦某個理財產品。
工業界更常用的是混合推薦。這是因為單一方法往往有局限,而混合能取長補短。舉例來說,電商網站可能會同時展示“基于內容的個性化推薦”、“熱門商品推薦”、“知識規則約束下的必推品”,并通過加權或分區的方式綜合展示給用戶。像亞馬遜、當當這樣的大型平臺,幾乎都是混合推薦的典型代表。
1.2 基于深度學習的推薦
隨著深度學習的興起,推薦系統也逐漸進入“深度建模”的階段。深度學習的優勢在于能夠自動學習復雜的特征表示和交互關系,而不需要人工設計大量特征。
例如,DSSM、YouTube DNN、雙塔模型等架構擅長處理大規模向量召回;Wide&Deep、DeepFM類模型可以同時捕捉特征的記憶性與泛化性;DIN、DIEN則通過注意力機制對用戶的行為序列進行建模,能夠理解用戶興趣的動態變化。
這些模型大幅提升了推薦的精度,讓系統能夠更準確地捕捉用戶的細粒度興趣。不過,它們對算力和數據規模的要求也更高,因此更適合頭部平臺。
1.3基于圖的推薦
有些場景下,用戶和物品之間的關系本質上是一張復雜的網絡。比如,在知識圖譜中,用戶、物品、屬性、標簽都可以看作節點,而交互就是連接它們的邊。推薦的任務就是在圖上挖掘潛在的連接。
典型方法包括 PersonalRank(類似 PageRank,從用戶節點出發迭代傳播權重),以及 DeepWalk / node2vec 這樣的圖嵌入方法(通過隨機游走生成節點序列,再用 Word2Vec 把節點表示成向量)。近年來,圖神經網絡(GNN)也逐漸應用到推薦中,比如 LightGCN 就通過層次聚合鄰居節點的信息,捕捉更復雜的興趣關系。
1.4 基于強化學習的推薦
強化學習是一種機器學習方法,通過代理在環境中進行交互來學習如何實現最佳行為。在推薦系統中,代理可以理解為推薦系統,環境可以理解為用戶行為空間,狀態可以理解為用戶在系統中的不同情況,動作可以理解為推薦不同的內容,獎勵可以理解為用戶對推薦內容的反饋。
典型算法:
- Q-Learning:基于 Q值的強化學習算法,用于學習代理在環境中實現最佳行為。
- Deep Q-Network(DQN):基于深度神經網絡的 Q-Learning 算法,用于解決推薦系統中的數據稀疏性問題。
- Policy Gradient:基于策略梯度的強化學習算法,用于學習多種策略以適應各種不同的用戶需求。
1.5 基于大模型的推薦
最后,我們來到大模型(LLM)的時代。雖然 LLM 本身并不是專門為推薦系統設計的,但它們具備強大的語義理解與生成能力,能夠在推薦中發揮獨特作用。
它們可以幫助推薦系統更好地理解復雜文本、跨模態信息;可以生成自然的推薦理由,提升用戶體驗;還能在冷啟動時快速為新物品構建語義畫像。可以說,大模型的引入,為推薦系統提供了一種全新的思路。后續我們將在第三章中深入展開這部分的應用。
2、推薦系統的詳細方案理解
很多初學者一開始會以為“推薦系統 = 推薦算法”,但實際上這是一種誤解。真正的推薦系統更像是一條復雜的流水線,算法只是其中的一個環節。它既要保證推薦的精準度,又要在合規性、可解釋性和用戶體驗之間找到平衡。
理解了推薦算法之后,我們需要意識到:一個真正能在生產環境中運行的推薦系統,遠遠不只是一個“模型”。它更像是一條流水線,既包括數據采集與特征工程,也包括召回、排序、重排,最后還要有合規、安全與監控保障。
為了說明這一點,我們不妨繼續用短視頻平臺作為案例。
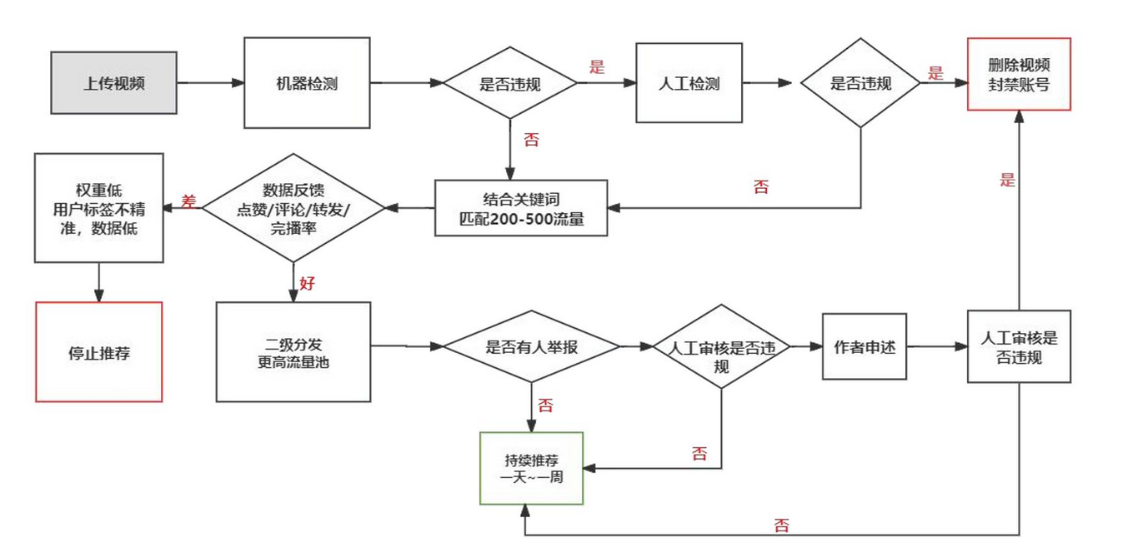
視頻推薦的完整流程
首先是內容審核。在視頻進入推薦前,平臺會先進行多模態審核:利用計算機視覺模型識別畫面中的違規元素,用 NLP 模型分析標題和文案,過濾掉敏感信息。機器篩查之后,仍然會把部分視頻交給人工審核員進一步把關。只有通過這一關的視頻,才能進入推薦系統。
接下來是冷啟動分發。系統會把新視頻隨機推送給一個小規模的測試人群,比如兩三百個用戶。平臺會觀察這些用戶的反饋指標,例如完播率、點贊、評論、轉發、是否關注作者等。如果反饋良好,視頻就會獲得更多曝光機會。
當視頻表現優異時,它就會進入更大流量池,同時系統會利用標簽機制,把它推薦給興趣更匹配的用戶。例如,一個關于“科幻主題”的視頻會更容易推送給平時愛看科幻短片的觀眾。
一旦視頻進入精品推薦池,它就能獲得大規模曝光。這個階段系統會弱化標簽限制,讓內容接觸到更廣泛的人群,有時甚至會觸發“爆款效應”。
除此之外,系統還會周期性地重新挖掘舊視頻。如果一個視頻和當下的熱點事件產生了新的聯系,它可能會再次被推薦,形成“延遲爆款”。
在整個流程中,平臺必須時刻關注合規性與用戶隱私。任何推薦內容都不能觸碰法律和道德的紅線;同時,用戶數據必須經過嚴格的保護和最小化使用。
算法在其中的角色
需要強調的是,在這一整條鏈路中,推薦算法雖然只是其中的一個環節,但卻是最核心的“心臟”。沒有好的算法,視頻無法精準匹配用戶;但如果缺少審核、冷啟動、合規、反饋閉環的支持,再好的算法也難以真正落地。
因此,一個推薦系統的成功,往往來自“算法 + 工程 + 規則”的協同。算法解決“精確性”,工程保障“效率與可擴展性”,規則確保“安全與合規”。三者缺一不可。


。”解決方案)



:項目介紹和ThreadCache(線程緩存)實現)




(141))

)



_281)

/RabbitMQ集群模式)