在數據挖掘和機器學習領域,TPR(True Positive Rate)是指在實際為陽性的情況下,模型正確預測為陽性的比例。TPR也被稱為靈敏度(Sensitivity)或召回率(Recall)。它是評估分類模型性能的一個重要指標,尤其是在不平衡數據集的情況下。
TPR的計算公式如下:

- TP(True Positive)是指模型正確預測為陽性的數量。
- FN(False Negative)是指模型錯誤預測為陰性的實際陽性數量。
TPR的范圍從0到1,值越高表示模型的性能越好,即模型能夠更好地識別出實際的陽性樣本。在有些應用中,如疾病篩查或欺詐檢測,我們通常希望模型有較高的TPR,以減少漏診或漏檢的情況。
與TPR相關的另一個指標是FPR(False Positive Rate),它是指在實際為陰性的情況下,模型錯誤預測為陽性的比例。TPR和FPR通常一起用于繪制ROC(Receiver Operating Characteristic)曲線,這是一種評估分類模型性能的圖形化工具。
在數據挖掘和機器學習領域,TPR(True Positive Rate)是指在實際為陽性的情況下,模型正確預測為陽性的比例。TPR也被稱為靈敏度(Sensitivity)或召回率(Recall)。它是評估分類模型性能的一個重要指標,尤其是在不平衡數據集的情況下。
TPR的計算公式如下:

其中:
- TP(True Positive)是指模型正確預測為陽性的數量。
- FN(False Negative)是指模型錯誤預測為陰性的實際陽性數量。
TPR的范圍從0到1,值越高表示模型的性能越好,即模型能夠更好地識別出實際的陽性樣本。在有些應用中,如疾病篩查或欺詐檢測,我們通常希望模型有較高的TPR,以減少漏診或漏檢的情況。
與TPR相關的另一個指標是FPR(False Positive Rate),它是指在實際為陰性的情況下,模型錯誤預測為陽性的比例。TPR和FPR通常一起用于繪制ROC(Receiver Operating Characteristic)曲線,這是一種評估分類模型性能的圖形化工具。
在數據挖掘和機器學習領域,TNR(True Negative Rate)是指在實際為陰性的情況下,模型正確預測為陰性的比例。TNR也被稱為特異性(Specificity)。它是評估分類模型性能的另一個重要指標,尤其是在需要嚴格控制假陽性(錯誤地預測為陽性)的應用場景中。
TNR的計算公式如下:

其中:
- TN(True Negative)是指模型正確預測為陰性的數量。
- FP(False Positive)是指模型錯誤預測為陽性的實際陰性數量。
TNR的范圍同樣從0到1,值越高表示模型的特異性越好,即模型在識別陰性樣本方面的能力越強。在一些醫學檢測、安檢和金融風控等領域,減少假陽性結果非常重要,因此TNR是一個關鍵的評估指標。
與TNR相關的另一個指標是TPR(True Positive Rate),它是指在實際為陽性的情況下,模型正確預測為陽性的比例。TNR和TPR通常一起考慮,以全面評估模型的性能。在ROC(Receiver Operating Characteristic)曲線中,TNR以FPR(False Positive Rate)的補數形式表示,即:
?

ROC曲線是基于TPR和FPR繪制的,它可以幫助我們理解模型在不同閾值設置下的性能表現。
在數據挖掘和機器學習領域,FPR(False Positive Rate)是指在實際為陰性的情況下,模型錯誤預測為陽性的比例。FPR也被稱為假陽性率,它是評估分類模型性能的一個重要指標,特別是在需要控制錯誤拒絕(即錯誤地將陰性樣本判定為陽性)的應用場景中。
FPR的計算公式如下:
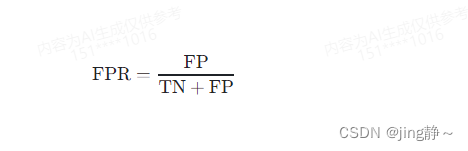
其中:
- FP(False Positive)是指模型錯誤預測為陽性的實際陰性數量。
- TN(True Negative)是指模型正確預測為陰性的數量。
FPR的范圍從0到1,值越低表示模型的特異性越好,即模型在避免將陰性樣本錯誤分類為陽性方面的能力越強。在醫學檢測、安檢和金融風控等領域,降低假陽性結果非常重要,因此FPR是一個關鍵的評估指標。
與FPR相關的另一個指標是TPR(True Positive Rate),它是指在實際為陽性的情況下,模型正確預測為陽性的比例。FPR和TPR通常一起考慮,以全面評估模型的性能。在ROC(Receiver Operating Characteristic)曲線中,FPR作為橫軸,而TPR作為縱軸,它可以幫助我們理解模型在不同閾值設置下的性能表現。
在數據挖掘和機器學習領域,FNR(False Negative Rate)是指在實際為陽性的情況下,模型錯誤預測為陰性的比例。FNR也被稱為漏診率(Miss Rate),它是評估分類模型性能的一個重要指標,特別是在需要盡量避免遺漏陽性樣本的應用場景中。
FNR的計算公式如下:

其中:
- FN(False Negative)是指模型錯誤預測為陰性的實際陽性數量。
- TP(True Positive)是指模型正確預測為陽性的數量。
FNR的范圍從0到1,值越低表示模型的敏感性越好,即模型在識別陽性樣本方面的能力越強。在疾病診斷、欺詐檢測等應用中,減少漏診或漏檢的情況非常關鍵,因此FNR是一個重要的性能指標。
與FNR相關的另一個指標是TNR(True Negative Rate),它是指在實際為陰性的情況下,模型正確預測為陰性的比例。FNR和TNR通常一起考慮,以全面評估模型的性能。在ROC(Receiver Operating Characteristic)曲線中,FNR以TNR的補數形式表示,即:
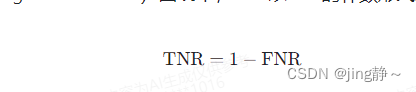
ROC曲線是基于TPR和FPR(FPR是FNR的補數)繪制的,它可以幫助我們理解模型在不同閾值設置下的性能表現。
決策樹是一種常用的機器學習算法,用于分類和回歸任務。它是一種樹形結構,其中每個內部節點代表一個特征或屬性,每個分支代表一個特征值,每個葉節點代表一個類別標簽。一個決策樹通常包含以下要素:
1. **根節點**:決策樹的頂部節點,代表整個數據集,是決策過程的起點。
2. **內部節點**:決策樹中的決策點,每個內部節點都基于一個特征來分割數據集。內部節點通常會有兩個或更多的分支,每個分支代表一個可能的特征值。
3. **分支**:連接內部節點和其子節點的連線,代表特征的某個具體值。數據集根據分支上的特征值被分割成子集。
4. **葉節點**:決策樹的底部節點,也稱為終端節點或葉子節點。每個葉節點代表一個類標簽(在分類樹中)或一個預測值(在回歸樹中)。
5. **特征選擇**:在構建決策樹時,選擇哪個特征作為內部節點的依據是一個關鍵步驟。不同的特征選擇標準(如信息增益、增益率、基尼不純度等)會導致不同的樹結構。
6. **分割標準**:決策樹算法使用分割標準來決定如何在內部節點分割數據集。常用的分割標準包括信息增益、增益率和基尼不純度等。
7. **剪枝策略**:為了防止過擬合,決策樹可能會通過剪枝來簡化模型。剪枝可以分為預剪枝(在樹生長過程中提前停止生長)和后剪枝(在樹完全生長后刪除不必要的節點)。
8. **樹的深度**:決策樹的深度是指從根節點到葉節點的最長路徑。樹的深度影響模型的復雜度和泛化能力。
9. **子樹**:每個內部節點的子節點可以看作是一個子樹,它包含了該節點下的所有分支和葉節點。
10. **純度**:決策樹的目標是創建純度高的葉節點,即葉節點中盡量屬于同一類別的數據。純度可以通過熵、基尼不純度等指標來衡量。




)



![[華為OD] C卷 dfs 特殊加密算法 100](http://pic.xiahunao.cn/[華為OD] C卷 dfs 特殊加密算法 100)









 v3.2.5安裝教程)
