論文閱讀
論文:https://arxiv.org/pdf/1403.6652
參考:【論文逐句精讀】DeepWalk,隨機游走實現圖向量嵌入,自然語言處理與圖的首次融合_隨機游走圖嵌入-CSDN博客
abstract
DeepWalk是干什么的:在一個網絡中學習頂點的潛在表示。這些潛在表示編碼了容易被統計學模型的在聯系向量空間中的社會關系。
DeepWalk怎么做到的:使用從截斷的隨機游走中獲得的局部信息,通過將行走視為句子來學習潛在表征。
統計學模型->指ML
introduction
網絡表示的稀疏性既是優點也是缺點。稀疏性使得設計高效的離散算法成為可能,但也使得推廣統計學習變得更加困難。因此ML就需要做到可以處理稀疏性。
在這篇文章中,通過對一系列短隨機游走(short random walks)進行建模來學習圖頂點的社會表示(social representations)。社會表征是捕獲鄰居相似性和社區成員的頂點的潛在特征。這些潛在表征將社會關系編碼在一個具有相對較少維度的連續向量空間中。

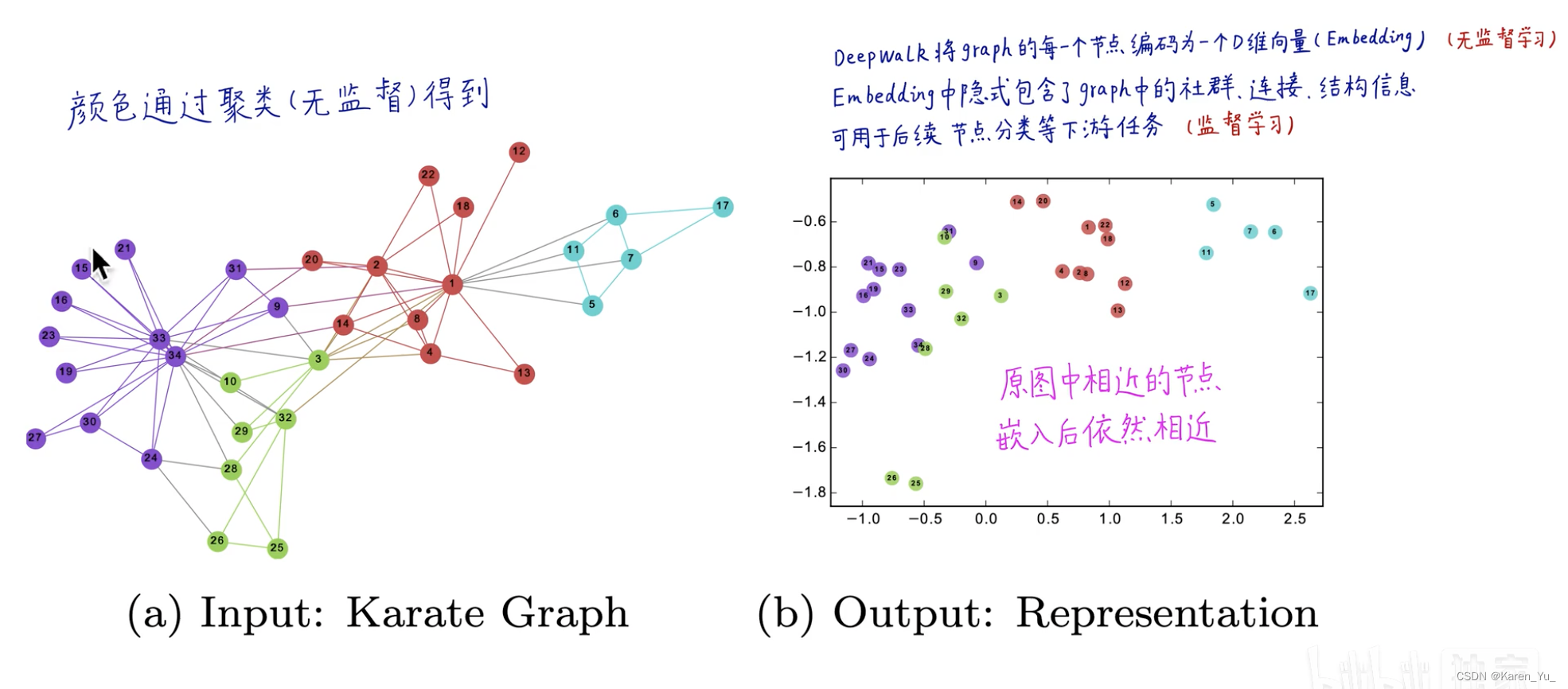
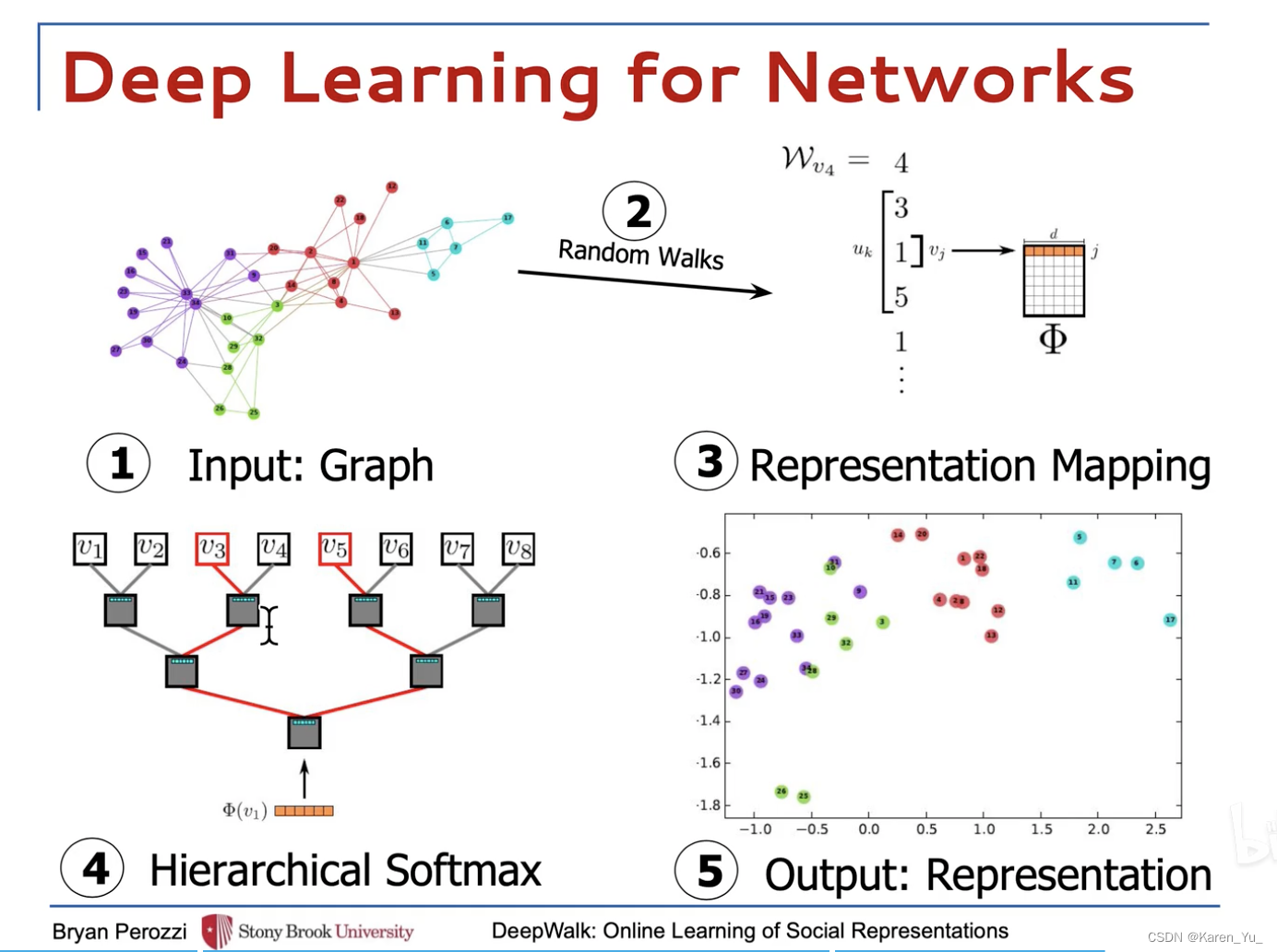
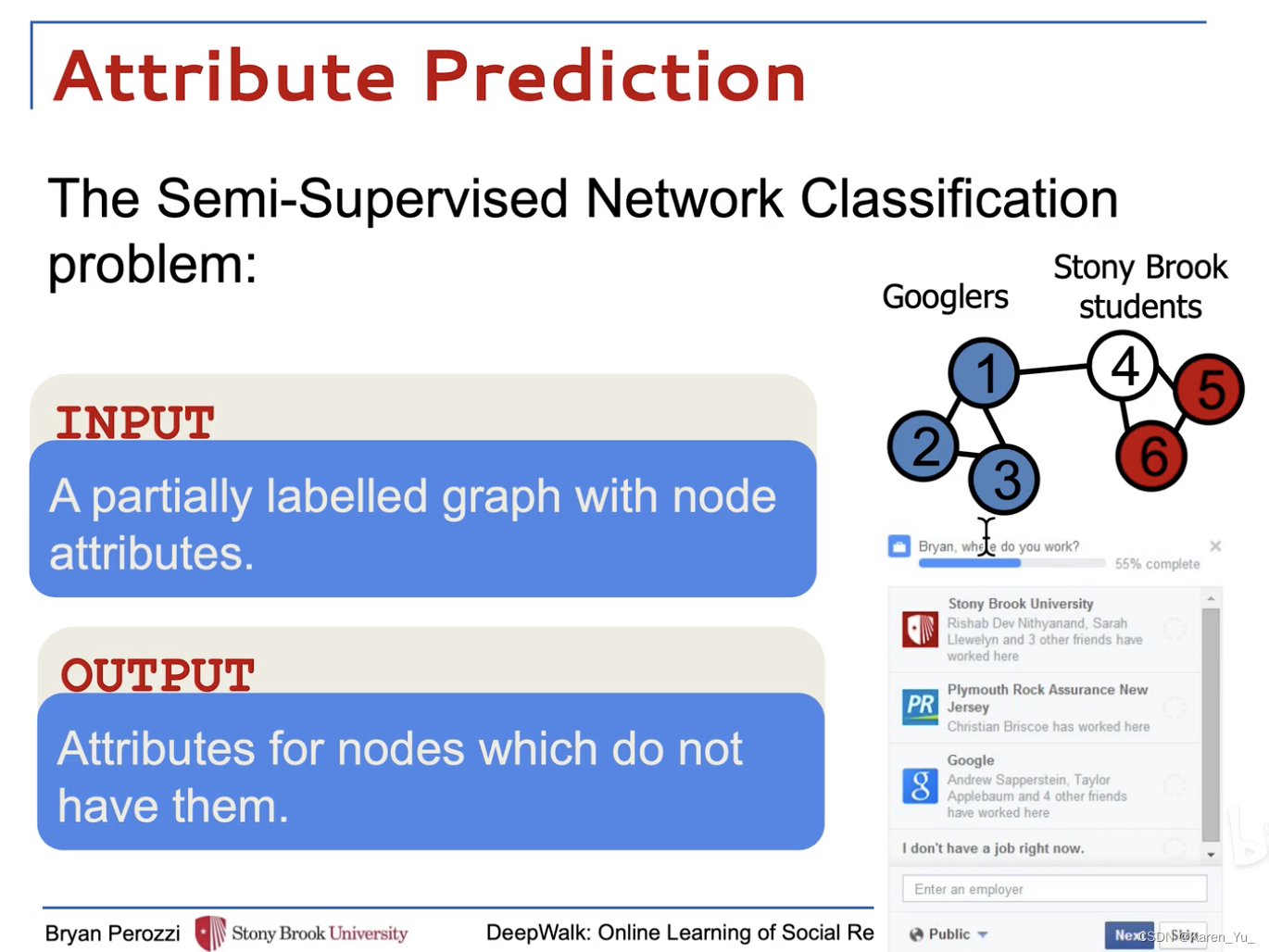
DeepWalk將一個圖作為輸入,并產生一個潛在的表示作為輸出。空手道網絡如圖1a所示。圖1b顯示了我們的方法具有2個潛在維度的輸出。
DeepWalk誕生背景和想要解決的問題
在DeepWalk誕生之前,往往是通過人工干預,創造的特征工程來進行圖機器學習,在這種情況下面臨兩個問題:
(1)特征工程的好壞決定模型的好壞。并且特征工程并沒有統一的標準,對于不同的數據集所需要做的特征工程是不一樣的,因此圖數據挖掘的模型的穩定性并不好。
(2)人工特征工程無非關注節點信息、邊信息、圖信息,且不論是否全部關注到,假設可以做到所有信息全部兼顧(實際上不可能)這樣近乎完美的特征工程,但是節點的多模態屬性信息無法得到關注。這意味著,即使是完美的特征工程,仍然只能兼顧到有限信息,數據挖掘的深度被嚴重限制。DeepWalk想要通過這么一種算法,把圖中每一個節點編碼成一個D維向量(embedding過程),這是一個無監督學習。同時,embedding的信息包含了圖中節點、連接、圖結構等所有信息,用于下游監督學習任務。
為什么可以借鑒NLP里面的方法?
圖數據是一種具有拓撲結構的序列數據。既然是序列數據,那么就可以用序列數據的處理方式。這里所謂的序列數據是指,圖網絡總是具有一定的指向性和關聯性,例如從磨子橋到火車南站,就可以乘坐3號線在省體育館轉1號線,再到火車南站,也可以在四川大學西門坐8號線轉。這都是具備指向關系。那么,我們把“磨子橋-省體育館-倪家橋-桐梓林-火車南站”就看作是一個序列。當然,這個序列是不唯一的,我們可以“四川大學望江校區-倪家橋-桐梓林-火車南站”。也可以再繞大一圈,坐7號線。總之,在不限制最短路徑的前提下,我們從一個點出發到另外一個點,有無數種可能性,這些可能性構成的指向網絡,等價于一個NLP中的序列,并且在這個圖序列中,相鄰節點同樣具備文本信息類似的相關性。Embedding編碼應該具有什么樣的特性?
在前文已經有過類似的一句話,embedding的信息包含了圖中節點、連接、圖結構等所有信息,用于下游監督學習任務。 其實這個更是一個思想,具體而言,在NLP領域中,我們希望對文本信息,甚至單詞的編碼,除了保留他單詞的信息,還應該盡可能保留他在原文中的位置信息,語法信息,語境信息,上下文信息等。因為只有這個基向量足夠強大,用這個向量訓練的模型解碼出來才能足夠強大。例如這么兩句話:
Sentence1:今天天氣很好,我去打籃球,結果不小心把新買的水果14摔壞了,但是沒關系,我買了保險,我可以免費修手機。
Sentence2:我今天去修手機。
很顯然,第一句話包含的信息更多,我們能夠更加清晰的理解到這個事件的來龍去脈。對計算機而言也是一樣,只有輸入的信息足夠完整,才能有更好的輸出可靠性。
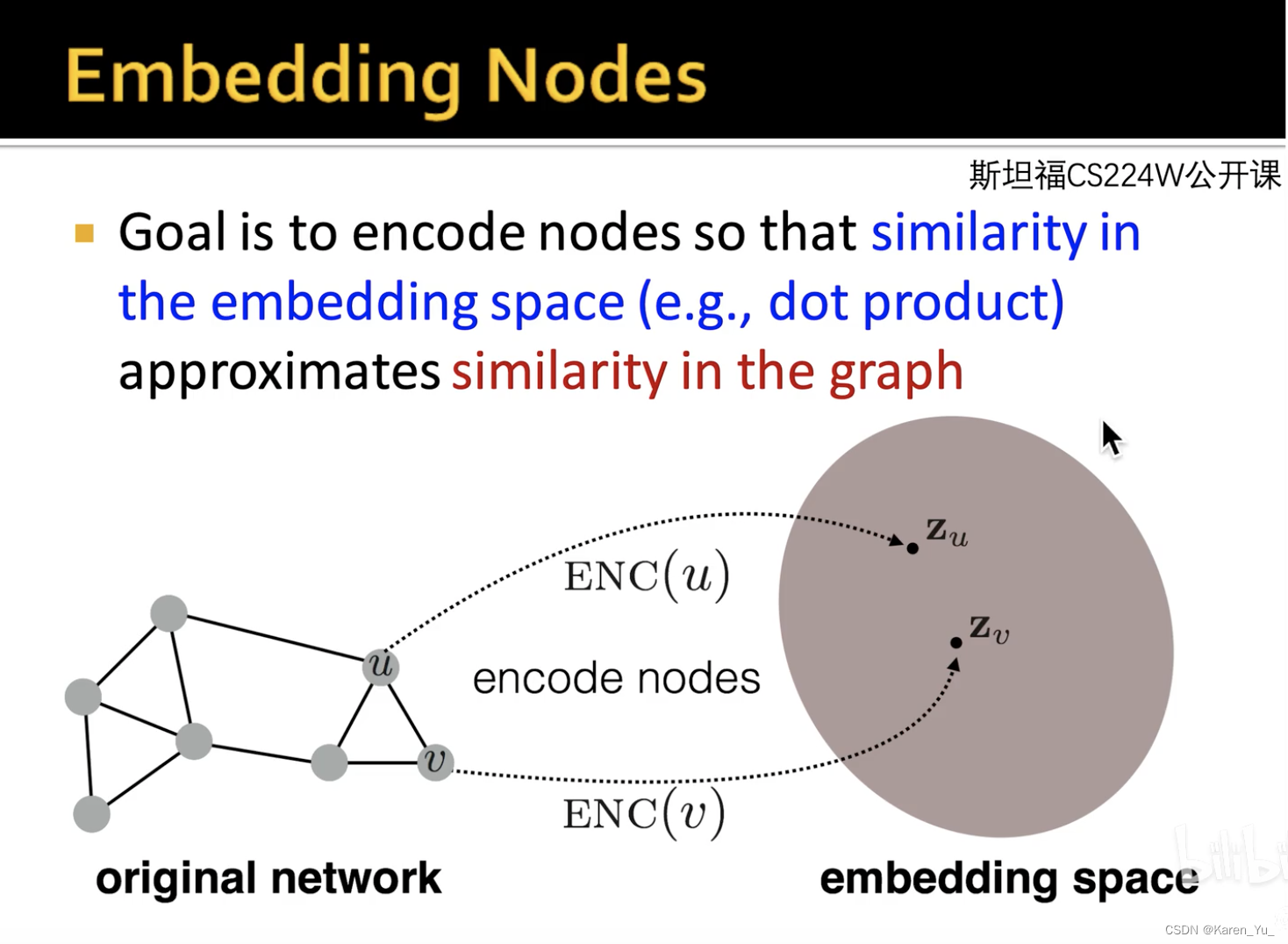
放到圖網絡里,假設有兩個節點u和v,他們在圖空間的信息應該和在向量空間的信息保持一致,這就是embedding最核心的特征(假設u和v在圖空間是鄰接點,那么在向量空間他們也應該是距離相近的;如果八竿子打不著關系,那么在向量空間應該也是看不出太多聯系)。把映射的向量放在二維空間或者更高維空間進行下游任務的設計,會比圖本身更加直觀,把圖的問題轉化成了不需要特征工程的傳統機器學習或者深度學習問題。什么是隨機游走(Random Walk)
首先選擇一個點,然后隨機選擇它的鄰接節點,移動一步之后,再次選擇移動后所在節點的鄰接節點進行移動,重復這個過程。記錄經過的節點,就構成了一個隨機游走序列。
Question:為什么要隨機游走?
Answer:一個網絡圖實際上可能是非常龐大的,通過無窮次采樣的隨機游走(實際上不可能無窮次),就可以”管中窺豹,可見一斑“。從無數個局部信息捕捉到整張圖的信息。
Random Walk的假設和Word2Vec的假設保持一致,即當前節點應該是和周圍節點存在聯系。所以可以構造一個Word2Vec的skip-gram問題。
? ? ? ? ? ? ? ? ? ? ? ??
原文鏈接:【論文逐句精讀】DeepWalk,隨機游走實現圖向量嵌入,自然語言處理與圖的首次融合_隨機游走圖嵌入-CSDN博客
關于這里對為什么可以應用NLP的內容,個人理解就是,在NLP中,一句話說出來的順序,或者說出來的方式,在一定程度上不影響句意,比如文言文里有倒裝、通假、省略、互文等等,但是表達出來的意思是一樣的,就像圖中從A節點到達D節點,我們可以走不通的路徑。
關于embedding編碼這部分,簡單回憶一下,關于語法信息,之前也提到過,比如位置編碼:
11.6. Self-Attention and Positional Encoding — Dive into Deep Learning 1.0.3 documentation
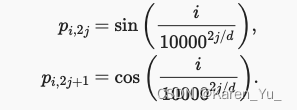
語法信息的話,BERT里面提過LeeMeng - 進擊的 BERT:NLP 界的巨人之力與遷移學習拆解不同的token,可以把單詞拆成單詞本身+ing或者+s這樣(我猜作者是這個意思)
之后關于圖的描述里面,確實在后續GNN的模型中都指出要讓相鄰的節點更相似(似乎PageRank也有關于相似度的應用)
關于隨機游走的部分,在后續的GNN中也有提到,這似乎是用到的一種采樣方法,當然在PageRank中也有提及(是一種迭代計算PageRank值的方法,但是因為其需要模擬的游走太多了,沒有被使用。
在引用的這篇文章中,也指出totally random walk并不是一個好方法,因為節點之間的權重是不一樣的,但是DeepWalk就完全均勻隨機游走了(還沒看后續怎么改,但是想想應該也是類似于加一個系數,讓能一定概率跳到某些點)
由于計算量的限制,這個隨機游走的長度并不是無限,所以對于一個巨大的網絡,雖然管中窺豹可見一斑,但這也注定了當前位置和距離非常遠的位置是完全無法構成任何聯系信息的,這和Word2Vec的局限性是一致的,在圖神經網絡GCN中,解除了距離限制,好像Transformer解除了RNN的距離限制一樣,極大釋放了模型的潛力,后續也會講到。
? ? ? ? ? ? ? ? ? ? ? ??
原文鏈接:【論文逐句精讀】DeepWalk,隨機游走實現圖向量嵌入,自然語言處理與圖的首次融合_隨機游走圖嵌入-CSDN博客
problem definition
我們考慮將社交網絡的成員劃分為一個或多個類別的問題。
令,其中
表示網絡中的成員,
表示邊,
(笛卡爾積?元素表示節點對?
)。給定一個部分標記的社交網絡
,其中屬性
,這里的
表示的是每個屬性向量的特征空間(即多少個特征),
,
表示標簽的集合。(
是特征)
在傳統的ML classification中,我們的目標是學習一個假設可以將元素
映射到標簽集
。
在文中,可以利用關于G結構中嵌入的示例的依賴性的重要信息來實現優越的性能。在文獻中,這被稱為關系分類(或集體分類問題[37])。傳統的關系分類方法將問題作為無向馬爾可夫網絡中的一個推理,然后使用迭代近似推理算法來計算給定網絡結構的標簽后向分布。
目標:學習,這里
是少量的潛在維度,這些低維表示是分布的,也就是說,每一個社會現象都是由維度的一個子集來表達的,而每一個維度都對空間所表達的社會概念的一個子集有所貢獻。利用這些結構特征,擴大屬性空間以幫助分類決策。

learning social representations
一些背景介紹,可移步【論文逐句精讀】DeepWalk,隨機游走實現圖向量嵌入,自然語言處理與圖的首次融合_隨機游走圖嵌入-CSDN博客
method
與任何語言建模算法一樣,唯一需要的輸出是一個語料庫和一個詞匯表V。DeepWalk將一組短截斷的隨機行走視為自己的語料庫,并將圖頂點作為自己的詞匯表()。盡管在訓練前知道
和頻率分布是有好處的,但是對于hierarchical softmax方法而言是非必要的。
frequency distribution
頻率分布:一種統計數據的排列方式,展示了變量值出現的頻率。
Frequency Distribution: values and their frequency (how often each value occurs).
關于頻率分布:
2.1: Organizing Data - Frequency Distributions - Statistics LibreTexts
Frequency Distribution | Tables, Types & Examples
Frequency Distributions – Math and Statistics Guides from UB’s Math & Statistics Center

Algorithm: Deep Walk
算法包含了兩個主要步驟,第一個是一個隨機游走生成器(random walk generator),第二個是更新過程(update procedure)。
其中,隨機游走生成器拿到圖并均勻采樣一個隨機頂點
作為隨機游走的根
。從最后訪問的頂點的鄰居中均勻采樣,直到達到最大長度(t)。雖然我們將實驗中隨機游走的長度設置為固定值(這里更容易被理解成是隨機游走的步數),但隨機游走的長度不受限制(這里應該指的是路徑的真實長度,因為可能跳回去)。這些行走可以有重新啟動(即瞬間返回到根節點的概率),但是初步結果并沒有顯示使用重新啟動的任何優勢。

上圖3-9行展示的是方法的核心。最外層的循環指定了在每個頂點開始隨機游走的次數。將每次迭代視為對數據進行“傳遞”,并在此傳遞期間對每個節點進行一次采樣。在每次“”傳遞開始的時候,我們生成一個隨機的順序來遍歷頂點。這不是嚴格要求的,但眾所周知,它可以加快隨機梯度下降的收斂速度。
在內部循環中,我們遍歷圖的所有頂點。對于每個頂點,我們生成一個隨機游動
,然后使用它來更新(第7行)->采用SkipGram算法??。

SkipGram
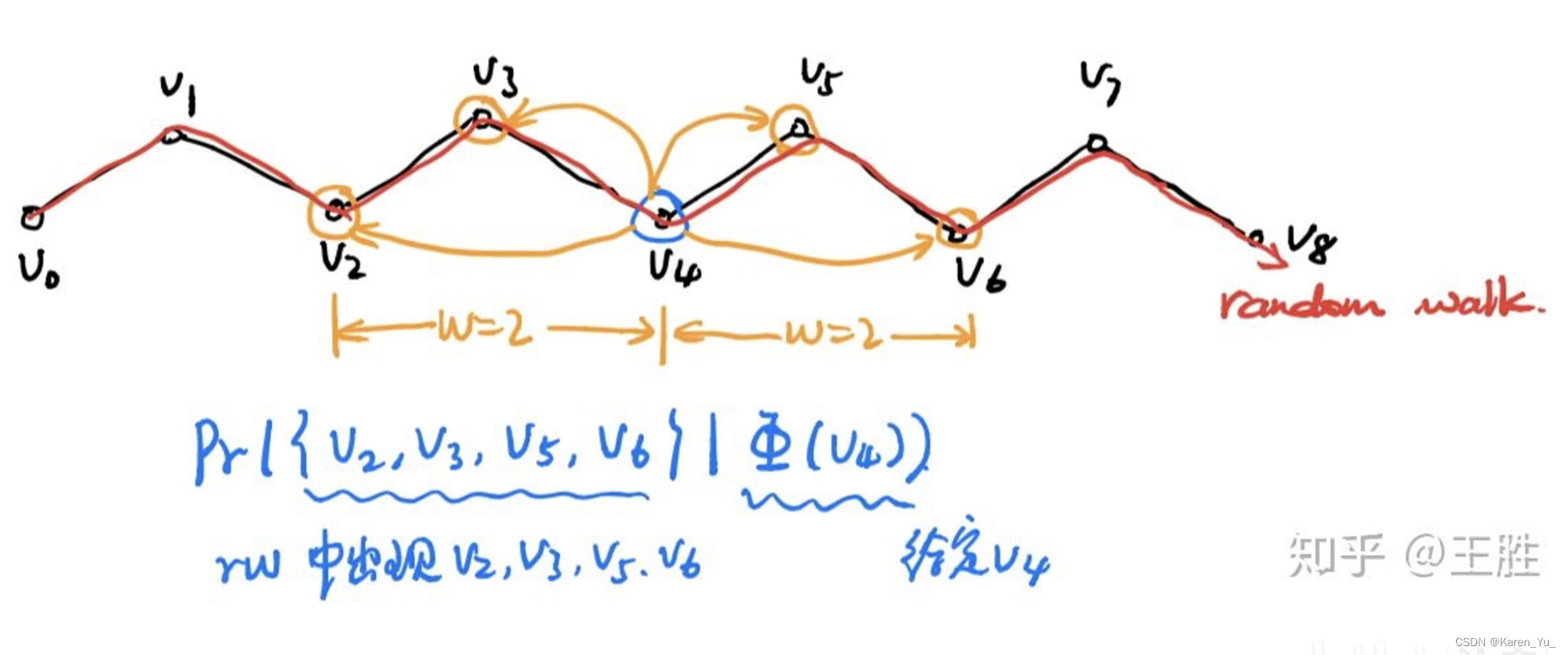
SkipGram是一種語言模型,它最大限度地提高句子中窗口內出現的單詞之間的共存概率
算法2在隨機游走中遍歷窗口(第1-2行)內出現的所有可能的搭配。對于每個頂點,我們將每個頂點
映射到其當前表示向量
(見圖??)。給定
的表示,我們希望最大化它在游走(第3行)中的鄰居的概率。可以使用幾種分類器來學習這種后驗分布。
這里的指的是對應的embedding
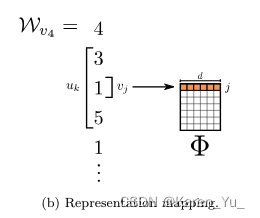
(這里沒太讀懂“maximize the probability of its neighbors in the walk”,按照前面的意思是SkipGram能夠提高cooccurrence probability,但是為什么要提高呢?這里斷一下去看看SkipGram)
參考:理解 Word2Vec 之 Skip-Gram 模型 - 知乎
Skip-gram Word2Vec Explained | Papers With Code
Skip-Gram Model in NLP - Scaler Topics
Word2Vec Tutorial - The Skip-Gram Model · Chris McCormick

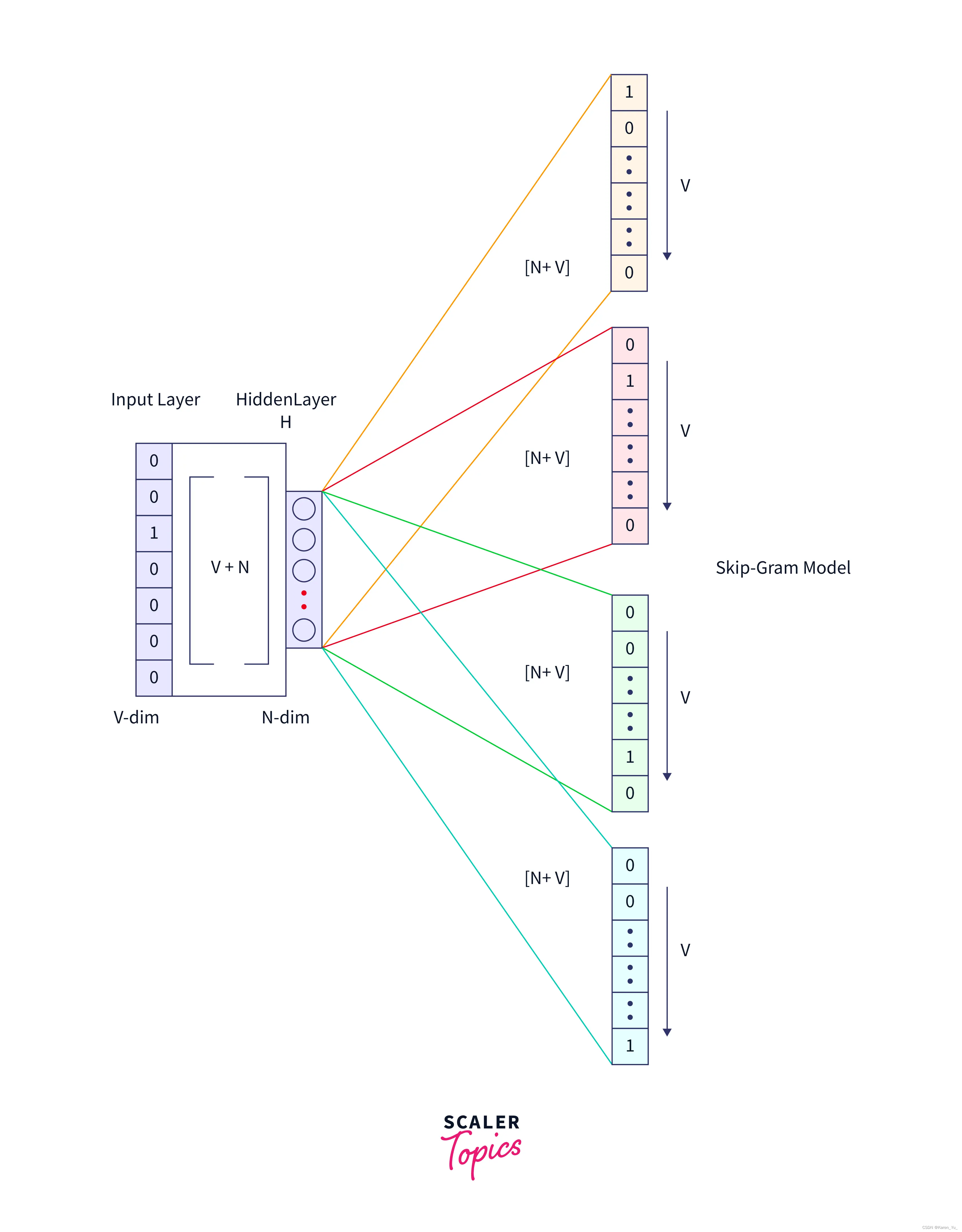
(目前的理解是,對于選擇的節點j我希望節點j能夠出現在節點i的隨機游走的路徑中)
Hierarchical Softmax
對于給定,計算
并不可行。計算partition function(歸一化因子)是昂貴的。如果我們將頂點分配給二叉樹的葉子,那么預測問題就變成了最大化樹中特定路徑的概率(參見圖??)。
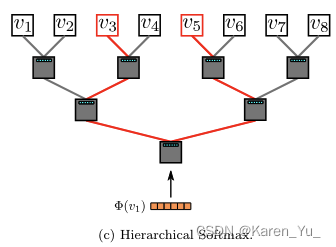
partition function-分區函數:在統計力學中的一種函數,用于表示系統的狀態數或相關函數的生成函數。
如果到達頂點的路徑被一系列數節點定義(
),(
),那么:
可以被分給其父節點的二分類器建模。
Optimization
隨機梯度下降(SGD)
在Overview里,作者提出DeepWalk也需要和自然語言處理算法一樣,構建自己的語料庫和詞庫。這里的語料庫就是隨機游走生成的序列,詞庫就是每個節點本身。從這一點上看,其實圖的Skip-Gram會更簡單一點,因為詞會涉及到分詞,切詞,例如”小明天天吃飯“,是小明還是明天,如果詞庫做不好,切割做不好,會非常影響模型性能;如果是英文單詞,好一點的做法會切分#-ed -#ing這樣的分詞,但是節點都是一個一個單獨的,不存在這樣的問題。
? ? ? ? ? ? ? ? ? ? ? ??
原文鏈接:
【論文逐句精讀】DeepWalk,隨機游走實現圖向量嵌入,自然語言處理與圖的首次融合-CSDN博客


示例代碼,請參考:
論文|DeepWalk的算法原理、代碼實現和應用說明 - 知乎
其他:
【論文筆記】DeepWalk - 知乎
【Graph Embedding】DeepWalk:算法原理,實現和應用 - 知乎
DeepWalk【圖神經網絡論文精讀】_嗶哩嗶哩_bilibili
DeepWalk【圖神經網絡論文精讀】_嗶哩嗶哩_bilibili
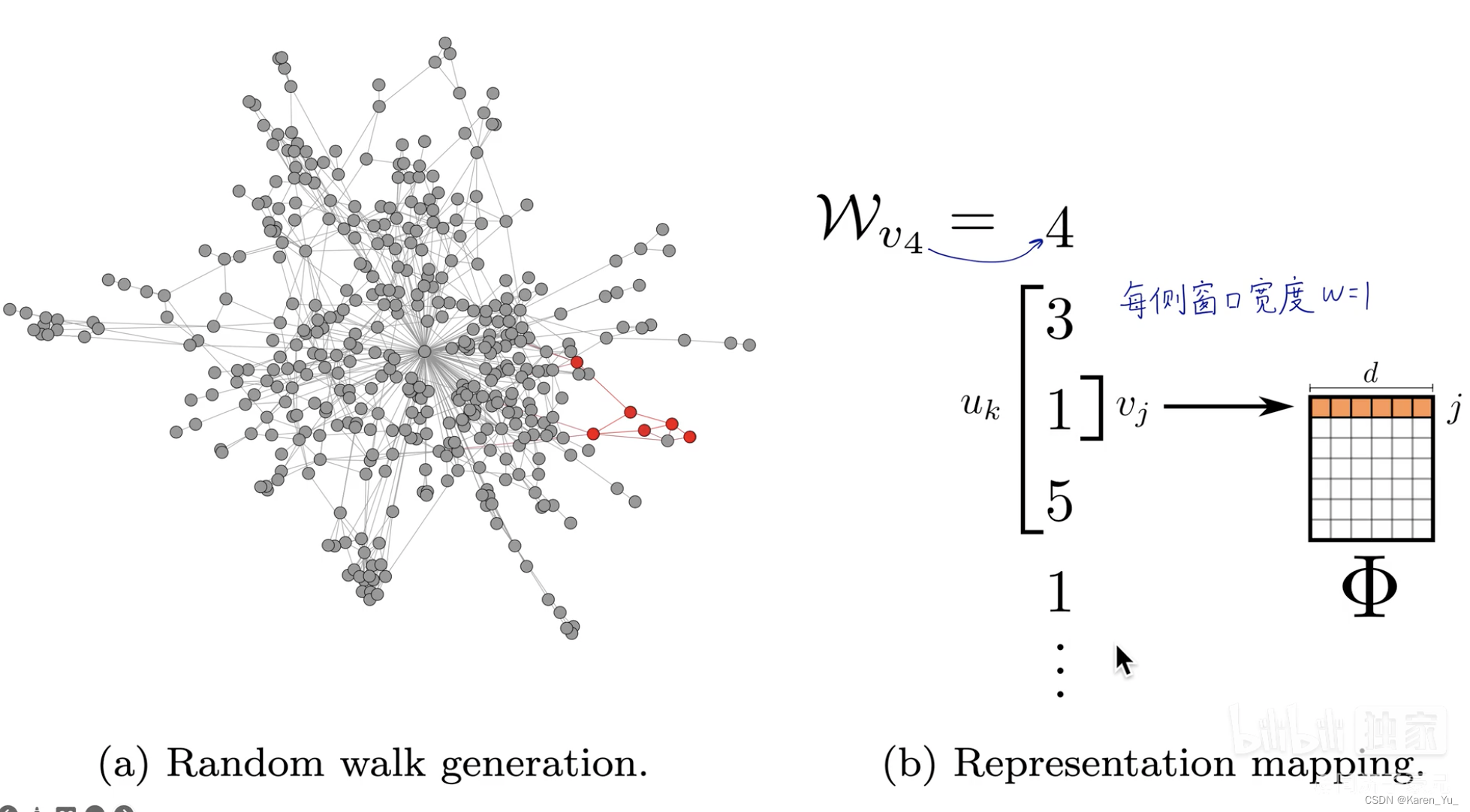
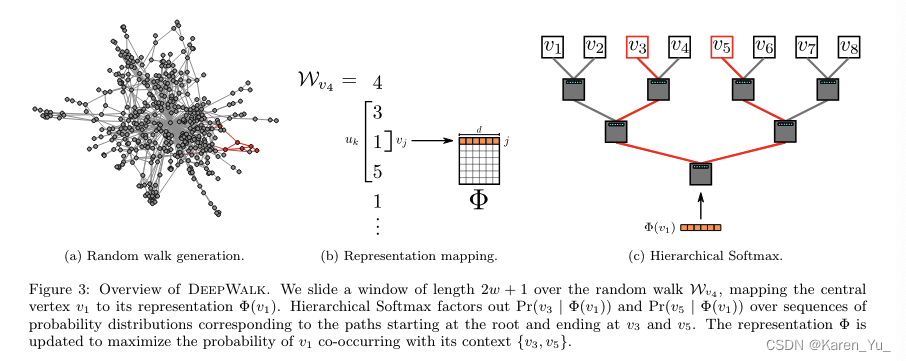
通過在圖里隨機游走,生成一連串隨機游走的序列,每一個序列都類似一句話,序列中的每一個節點就類似word2vec中的單詞,然后套用word2vec方法。word2vec中假設一句話中相鄰的單詞是相關的,deepwalk假設在一個隨機游走中,相鄰的節點是相關的。
比如圖中,用,即1,預測3和5,通過這種,用中心節點去預測周圍節點,就可以捕獲相鄰的關聯信息,最后迭代優化
,
反映了相似關系
通過隨機游走可以采樣出來一個序列。
輸入中心節點預測周圍臨近節點,那么我們就可以套用word2vec,把每一個節點編碼成一個向量。
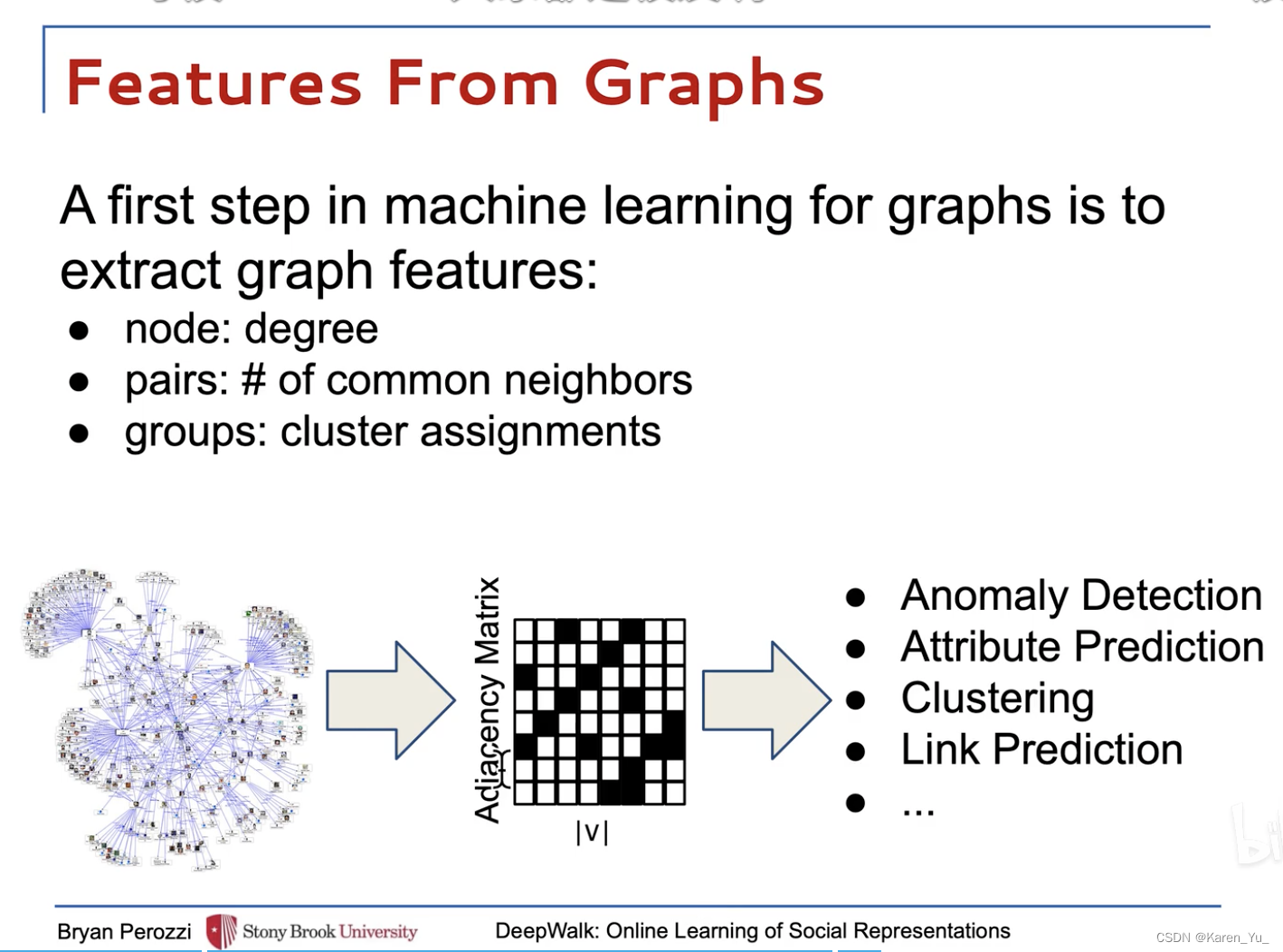
??手動構造特征,??學習特征?
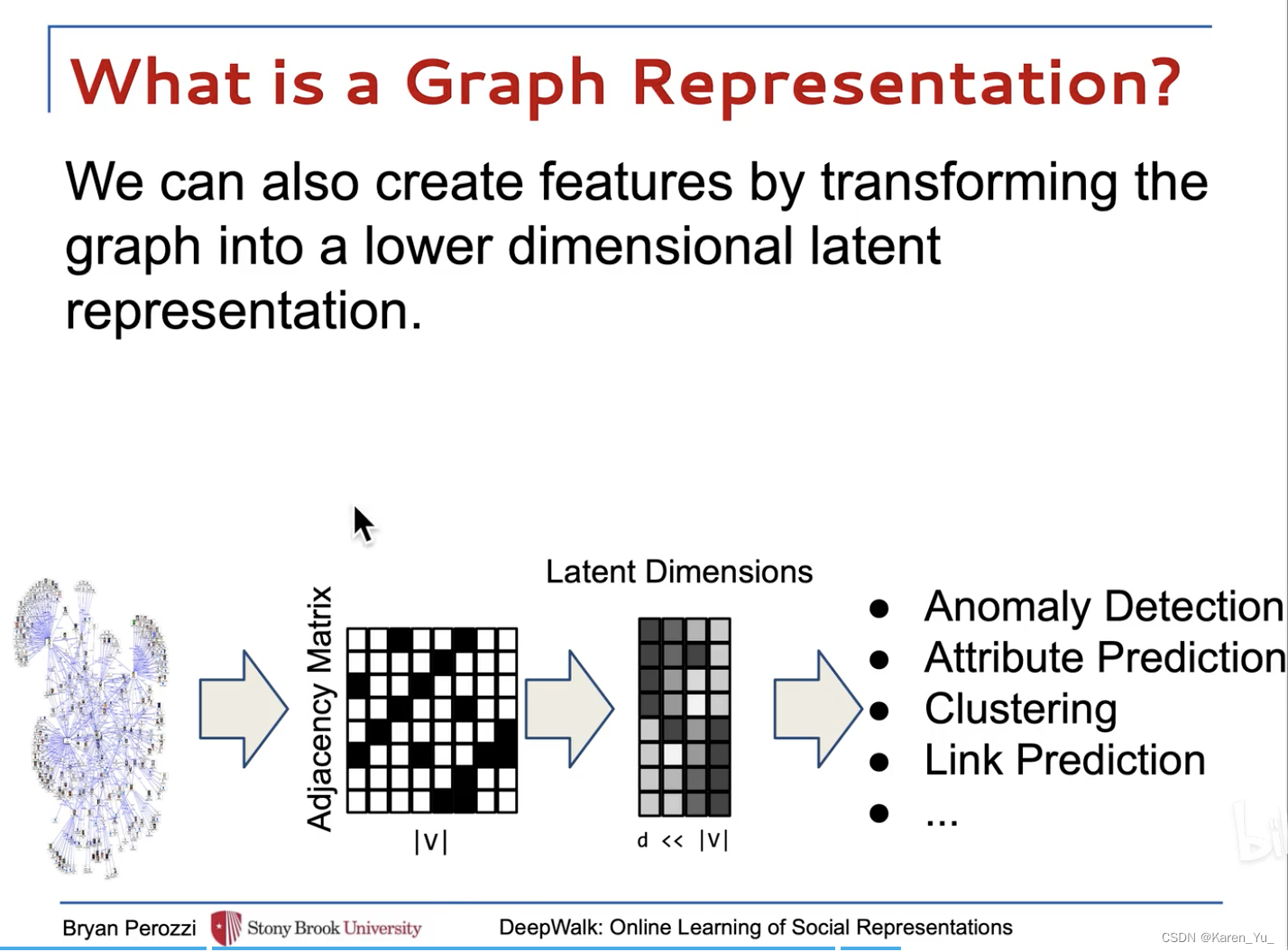
把詞匯表維度降到d維
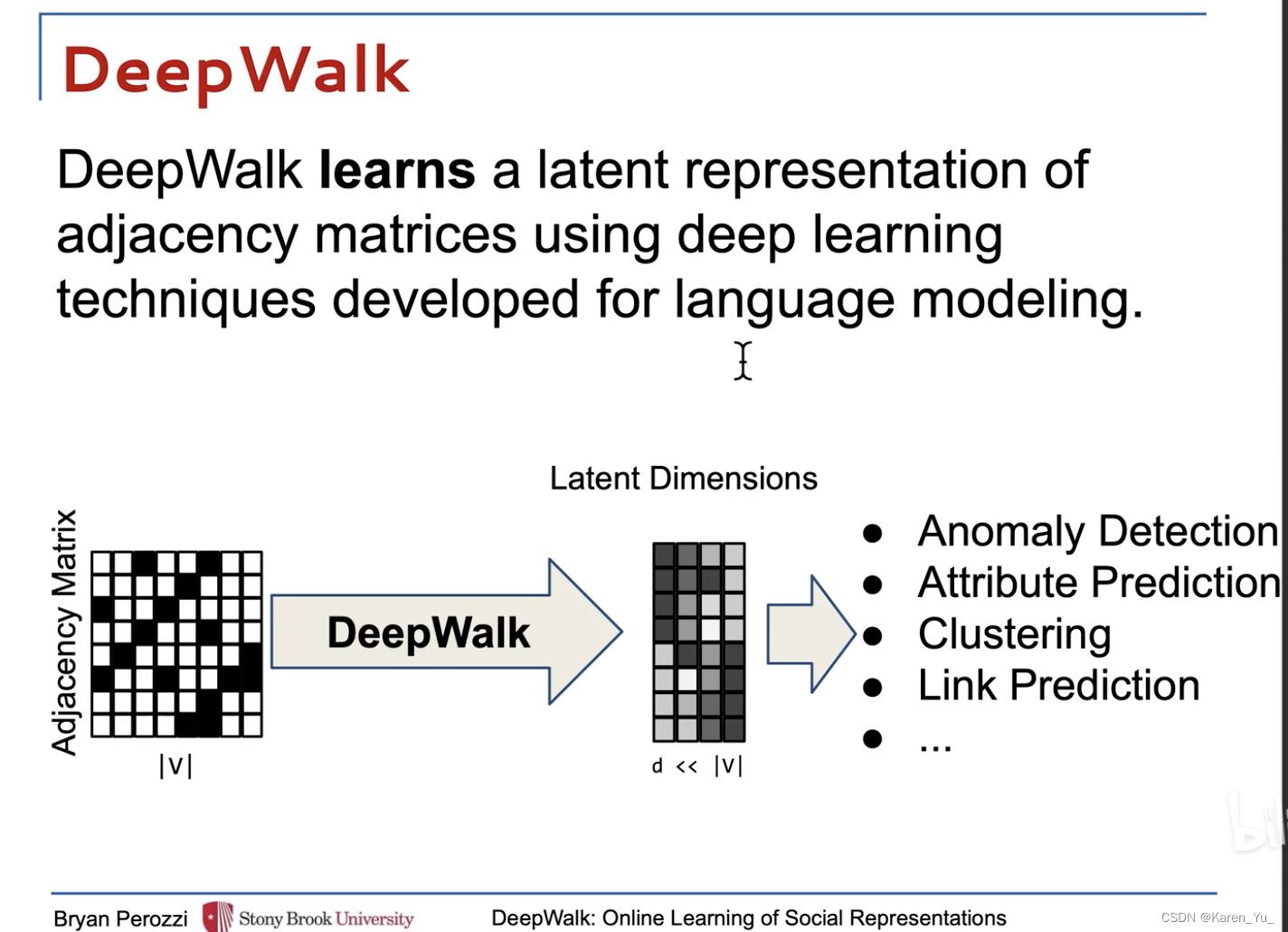
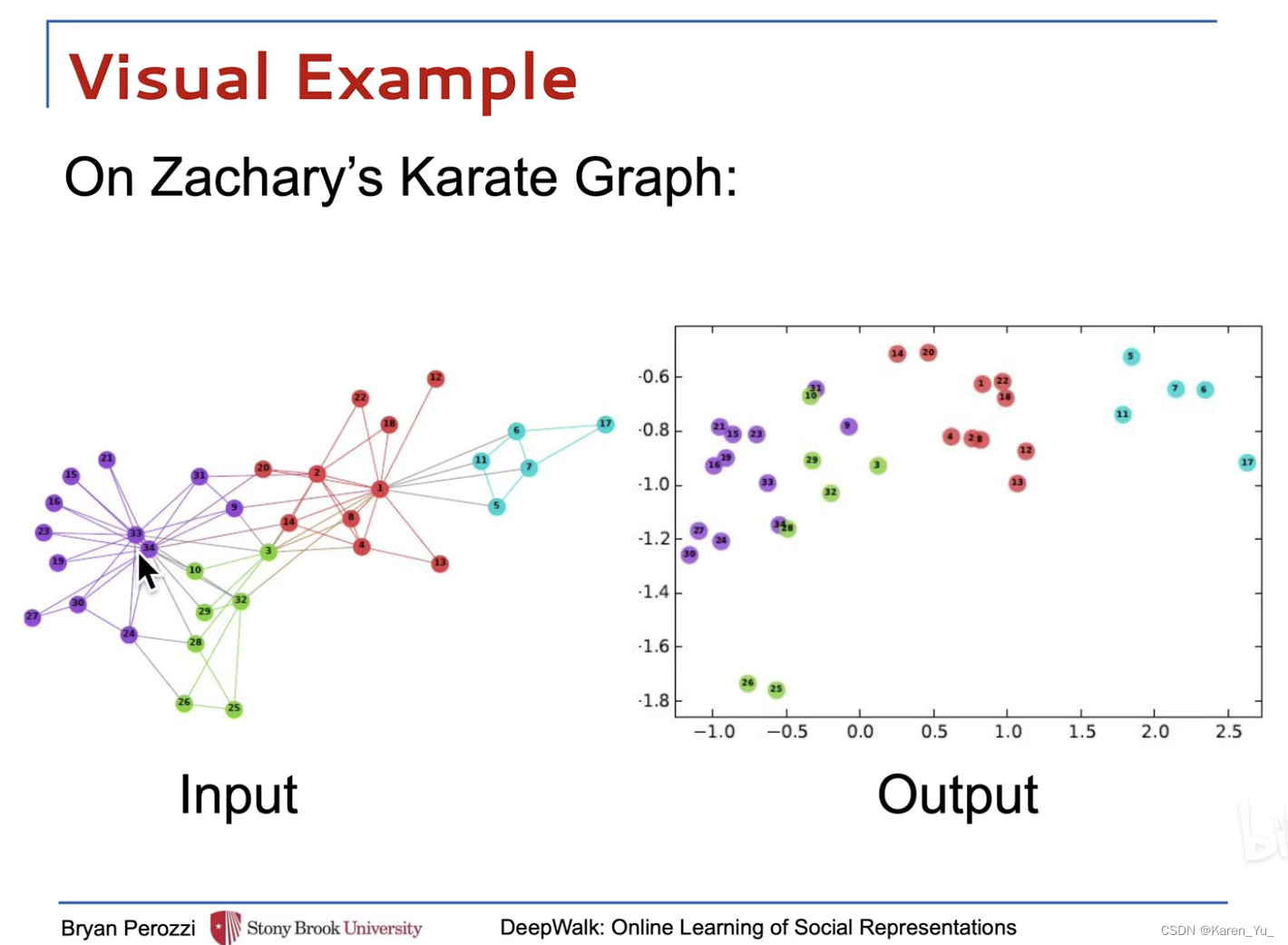
??原圖,??deepwalk編碼后到圖
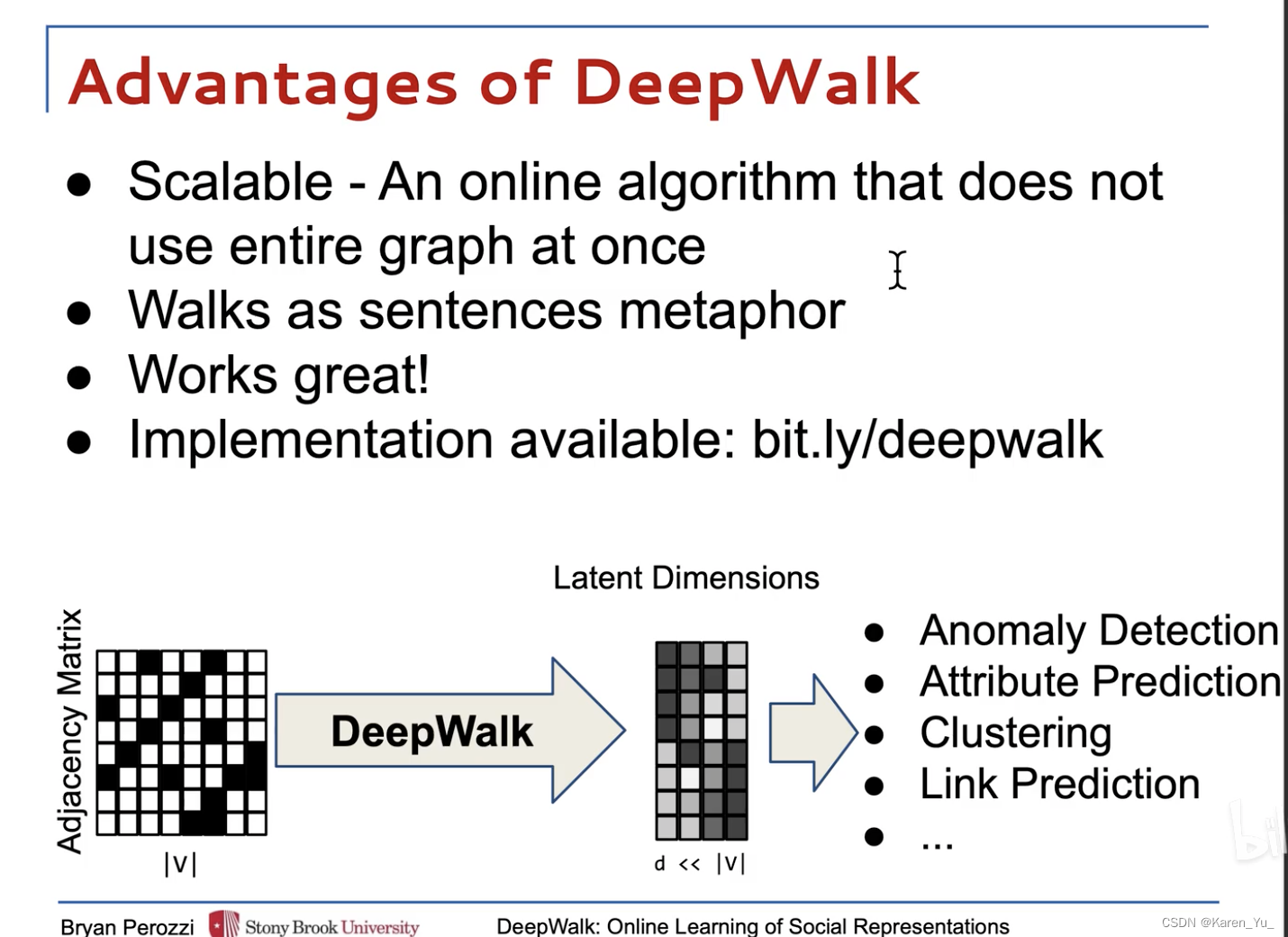
優點:
- 可擴展。來了一個新數據之后,即來即學,即建立一個新連接之后不需要從頭訓練,只需要把新增的節點和關聯,讓隨機游走采樣下來,然后在線訓練
- 可以直接套用NLP中的語言模型,把隨機游走當作是句子,把節點當作是單詞
- 效果不錯,尤其在稀疏標記的圖分類任務上

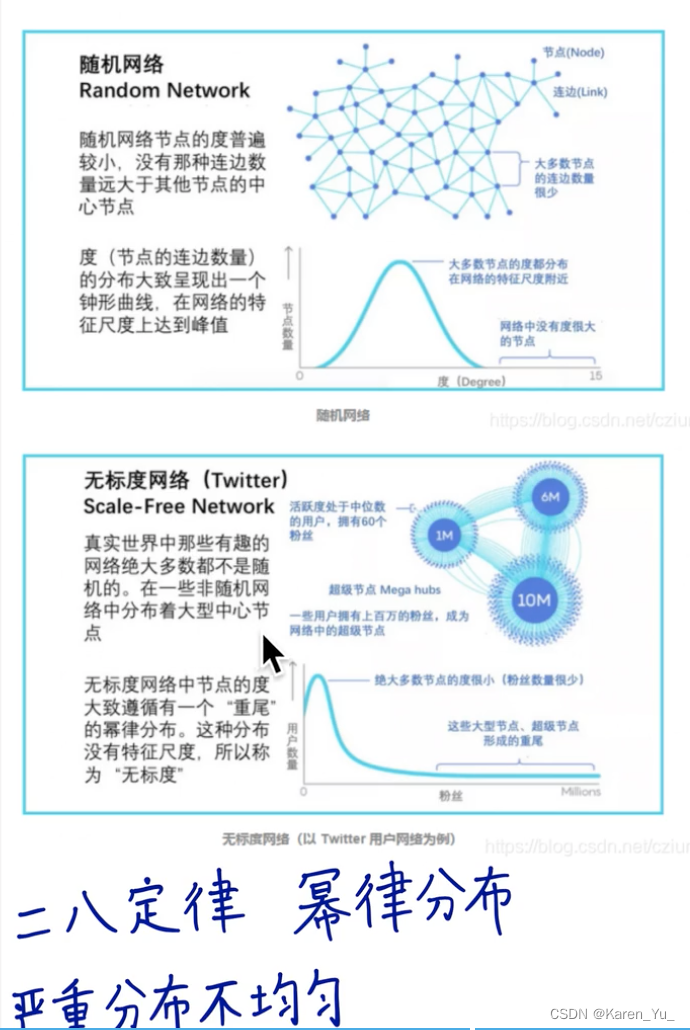
在NLP中有一個現象,稱為冪律分布/二八定律/長尾分布
有一些詞出現的特別頻繁(如:the, and, of, etc.),但是這些詞比較少,而大部分的詞出現的次數少(但是這些詞數量多)
帶入到圖中,比如網絡,很少部分的網站很多人訪問,而大部分的網站都沒人訪問
關于各種分布,可以參考:從冪律分布到特征數據概率分布——12個常用概率分布_數據和特征怎么估計概率分布-CSDN博客
->服從同一分布->可以類比->可以用相同的方法

5個步驟:
- 先輸入一個圖
- 采樣隨機游走序列
- 用隨機游走序列訓練word2vec
- 為了解決分類個數過多的問題,加一個分層softmax(or 霍夫曼編碼樹)
- 得到每一個節點的圖嵌入向量表示

首先來看random walk。每一個節點作為起始節點,產生個隨機游走序列,每一個隨機游走序列的最大長度是
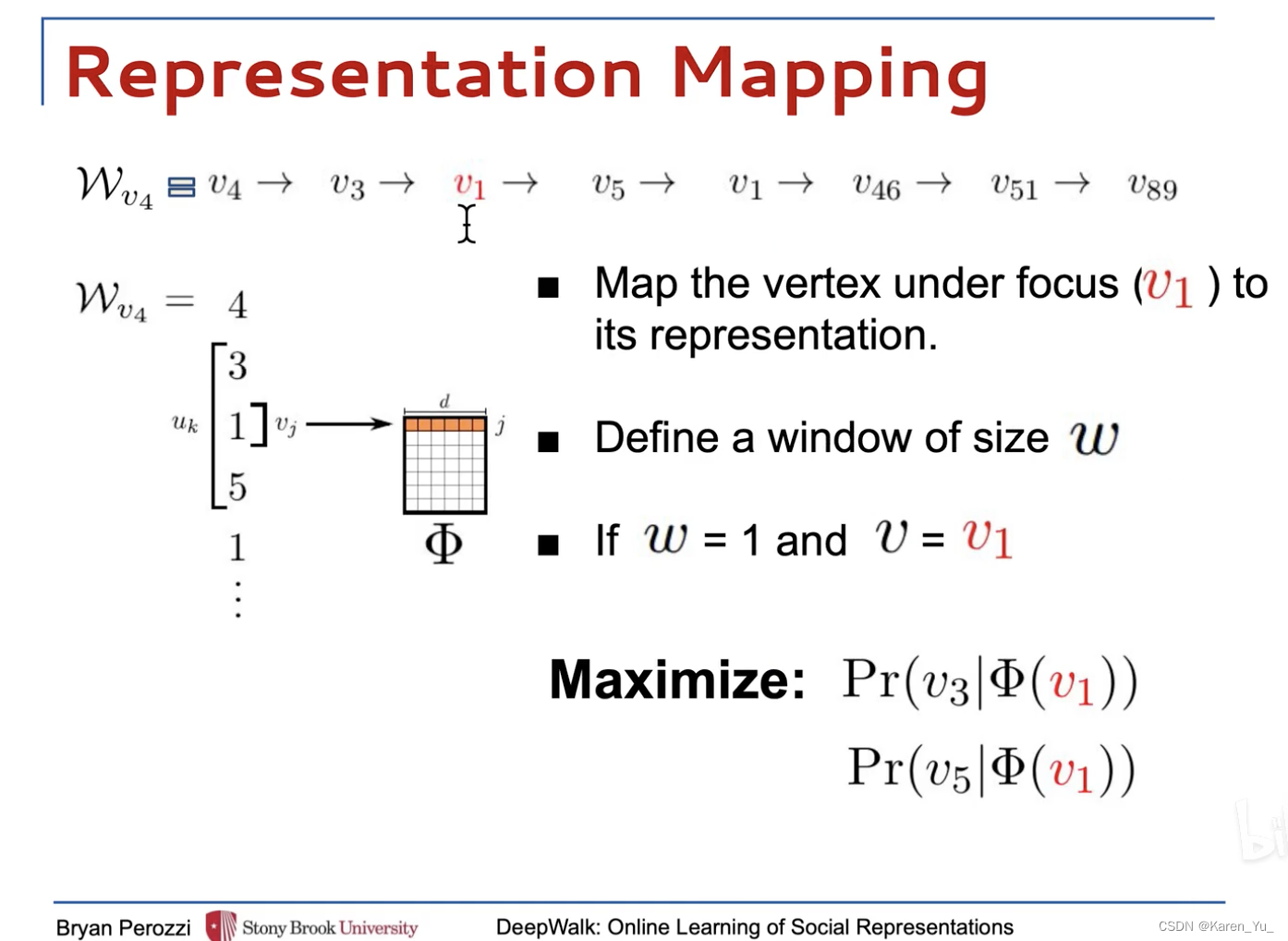
使用得到的隨機游走序列去構造skip-gram,輸入中心詞的編碼表示,預測周圍詞(輸入1,預測3 5)
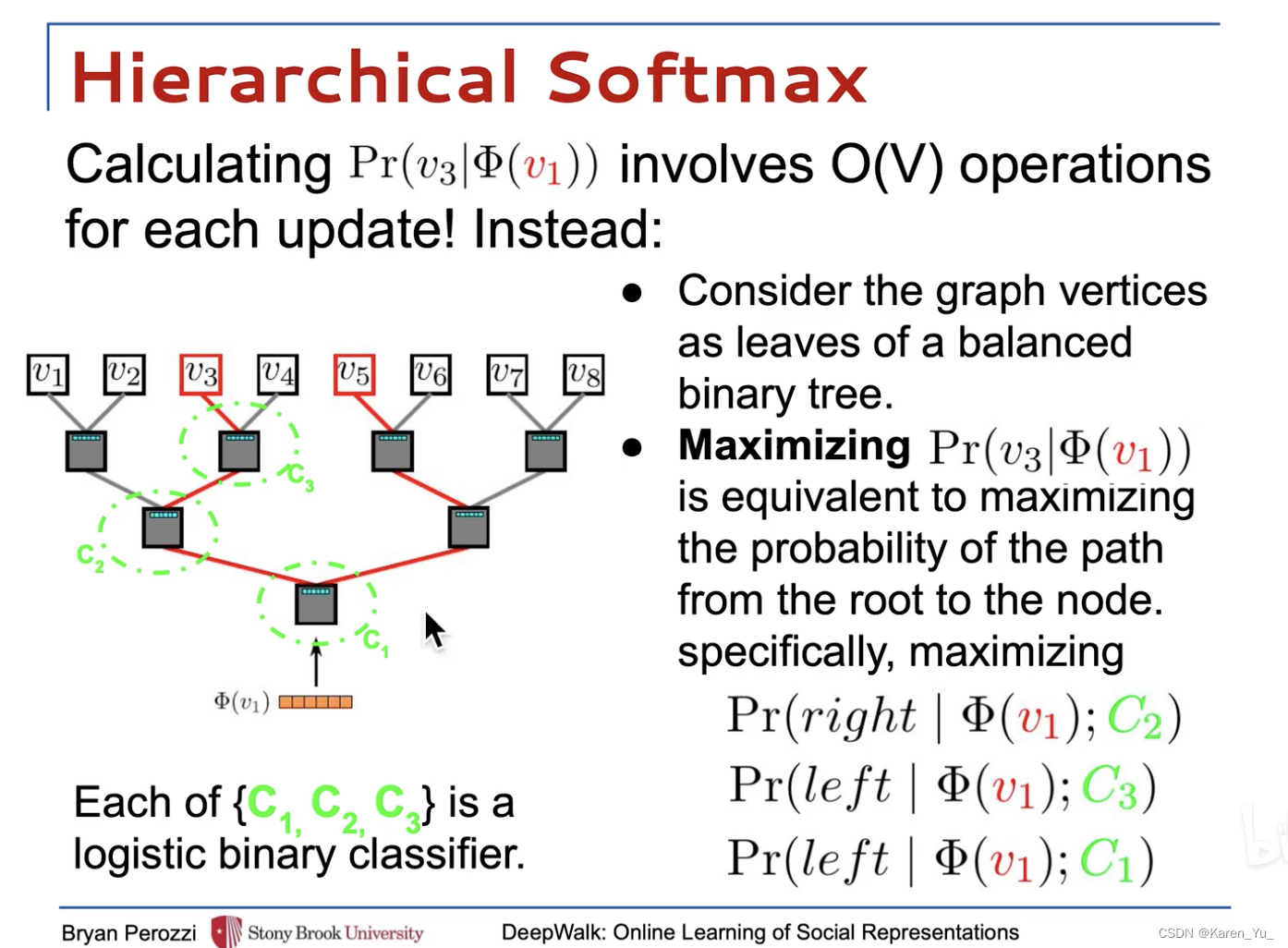
分層的softmax->比如一個八分類問題,分成三個分類任務,這里的每一個分類任務都是一個二分類的邏輯回歸。
->復雜度從O(n)降低到O(log n)

有兩套要學的參數:節點的表示 & 邏輯回歸的權重
節點表示需要優化的是skip-gram的損失函數,邏輯回歸是優化最大似然估計的交叉熵損失函數
同時優化
->最后得到每一個節點的向量
優缺點:

DeepWalk論文逐句精讀_嗶哩嗶哩_bilibili
online learning指的是在線學習算法,是一個即來即訓的算法,如果圖中有新的節點出現or有新的連接出現(比如一個社交網絡中有一個新的注冊用戶/一個新的好友關系的添加,不需要將全圖重新訓練一遍,而只要把新增的節點/關系構建新的隨機游走序列,迭代地更新到原有的模型中。
隱式向量(編碼后的結果)就編碼了節點的鄰域信息和社群信息。->一個連續、低維、稠密的空間。
在圖數據結構中,每個節點之間是有關聯的,這就違反了傳統機器學習的獨立同分布假設(比如iris數據集,每一條數據都是一朵獨立的鳶尾花,但是都屬于鳶尾花),但是圖的話,每個節點之間是有關聯的,所以不能用傳統的機器學習方法(就像紅樓夢四大家族一樣,互相掣肘)。
deepwalk是無監督學習,與節點的label、特征均無關,只與節點在網絡中的社群屬性、連接結構相關。
后續的算法可以加上節點本身的信息(但是deepwalk本身不包含)
(彈幕:deepwalk不用,但下游任務用)

word2vec不需要標簽,輸入中心詞,周圍的詞就是標簽


?
 v3.2.5安裝教程)







excel導出)


)

)


遇到的問題)
)

