
首發網站 https://tianfeng.space
前言
- 零樣本文本到語音(TTS): 輸入 5 秒的聲音樣本,即刻體驗文本到語音轉換。
- 少樣本 TTS: 僅需 1 分鐘的訓練數據即可微調模型,提升聲音相似度和真實感。
- 跨語言支持: 支持與訓練數據集不同語言的推理,目前支持英語、日語和中文。
- WebUI 工具: 集成工具包括聲音伴奏分離、自動訓練集分割、中文自動語音識別(ASR)和文本標注,協助初學者創建訓練數據集和 GPT/SoVITS 模型。
使用
安裝
https://github.com/RVC-Boss/GPT-SoVITS?tab=readme-ov-file

同時下載權重文件放入相應文件夾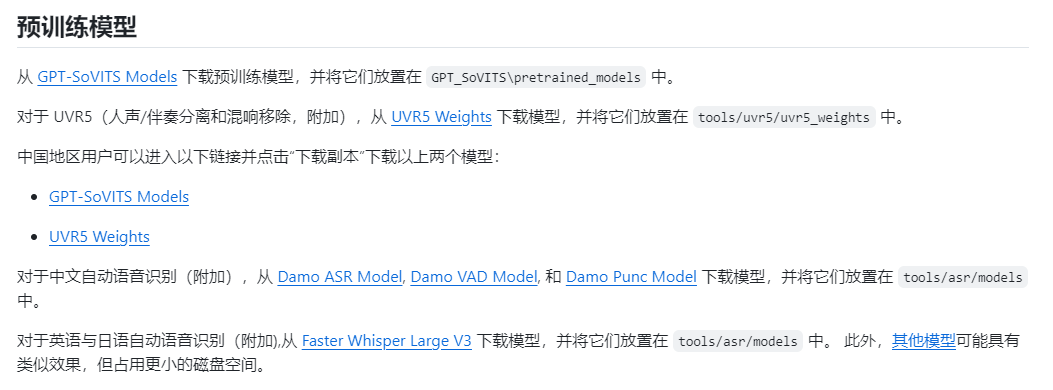
如果網速不好,怕麻煩,百度網盤:
鏈接: https://pan.baidu.com/s/1jeub2AzO6SeGge_YTimirQ 提取碼: 2qkp
準備數據
雖然幾分鐘即可訓練,但是聲音數據半個小時到一個小時更好,吐字清晰,格式最好WAV
解壓后雙擊 go-webui.bat 即可啟動 GPT-SoVITS-WebUI
來到頁面,勾選開啟UVR5,自動跳轉webui(如果你的數據有雜音和伴奏)
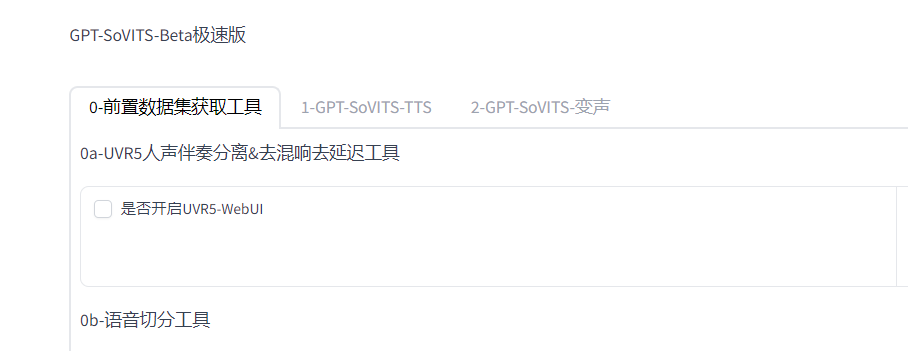
去伴奏
填入你音頻文件路徑或拖拽你的文件,HP2伴奏分離,然后依次是人聲與伴奏聲保存路徑,導出格式WAV
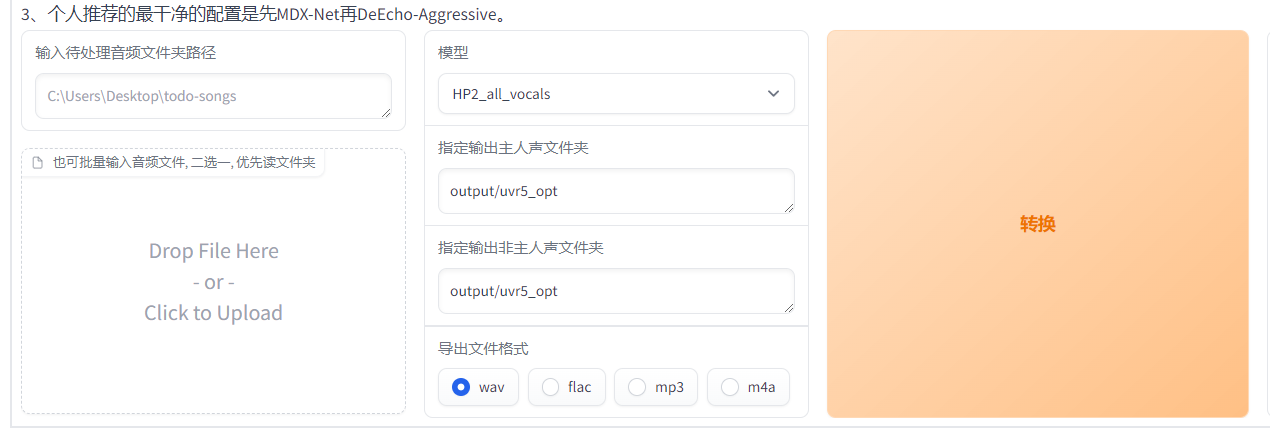
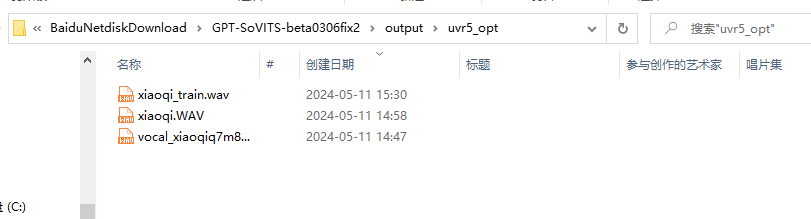
然后文件就在改路徑下vocal(人聲)
去混響延時
輸入去玩伴奏的人聲音頻路徑,輸出依然是哪個文件夾下帶vocal(人聲)
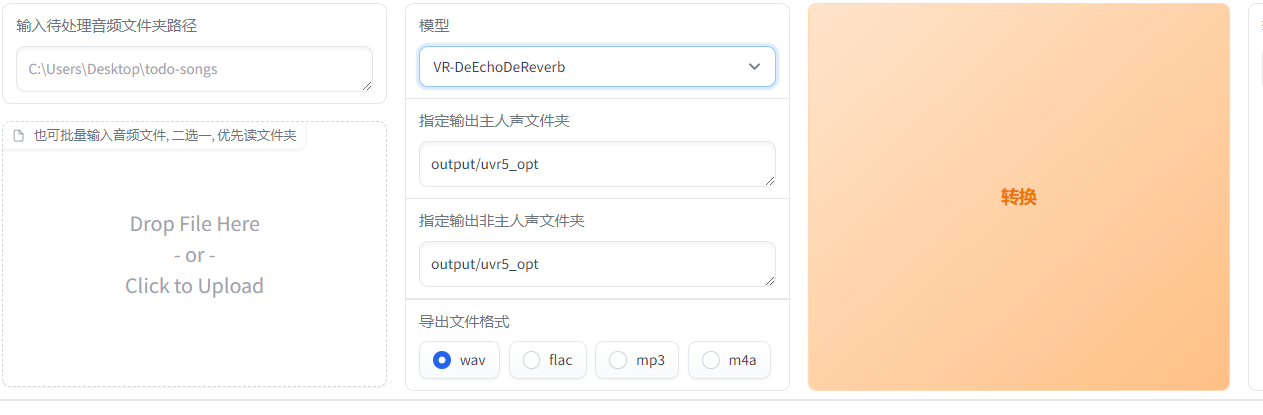
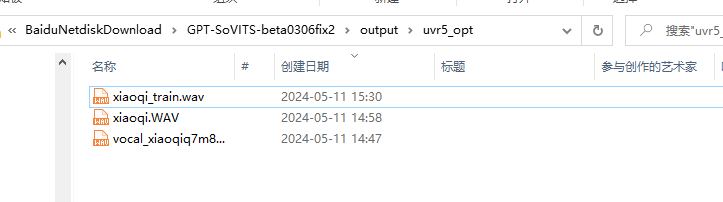
xiaoqi_train.wav我改名的去伴奏去混響最終文件
分割音頻
關閉UVR5,切分音頻,填入文件路徑,其他默認
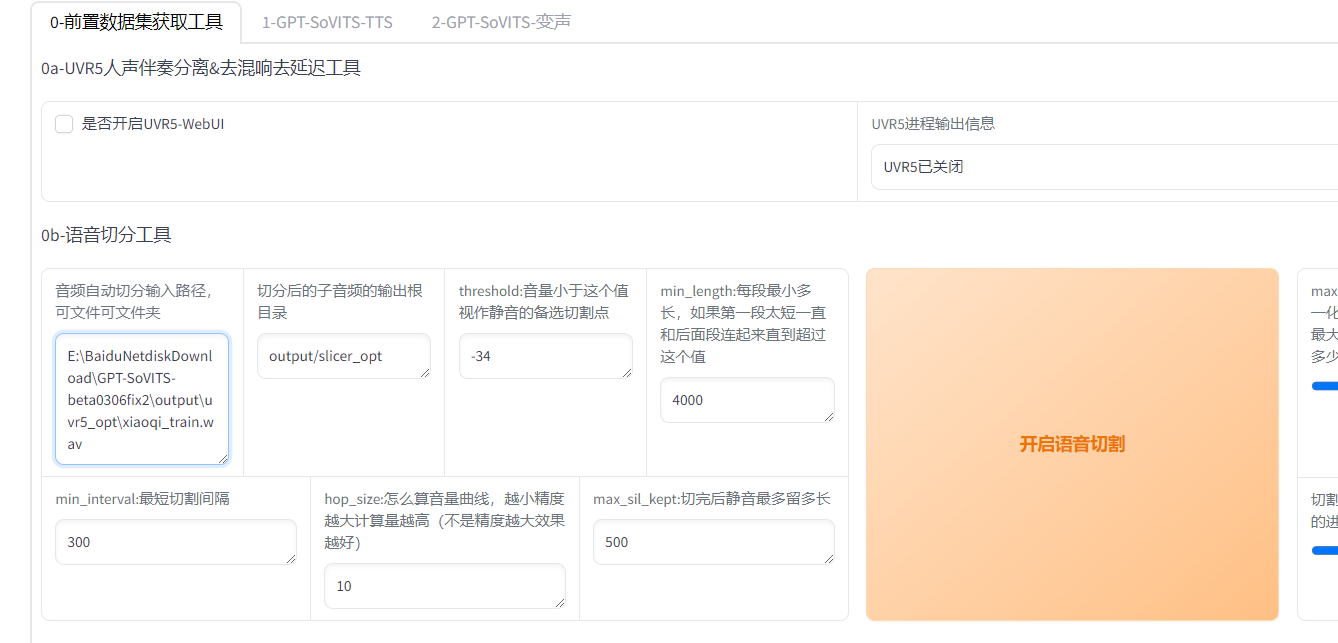
降噪
輸入切分的文件夾路徑

ASR
輸入降噪后音頻文件,中文選達摩,英文whisper
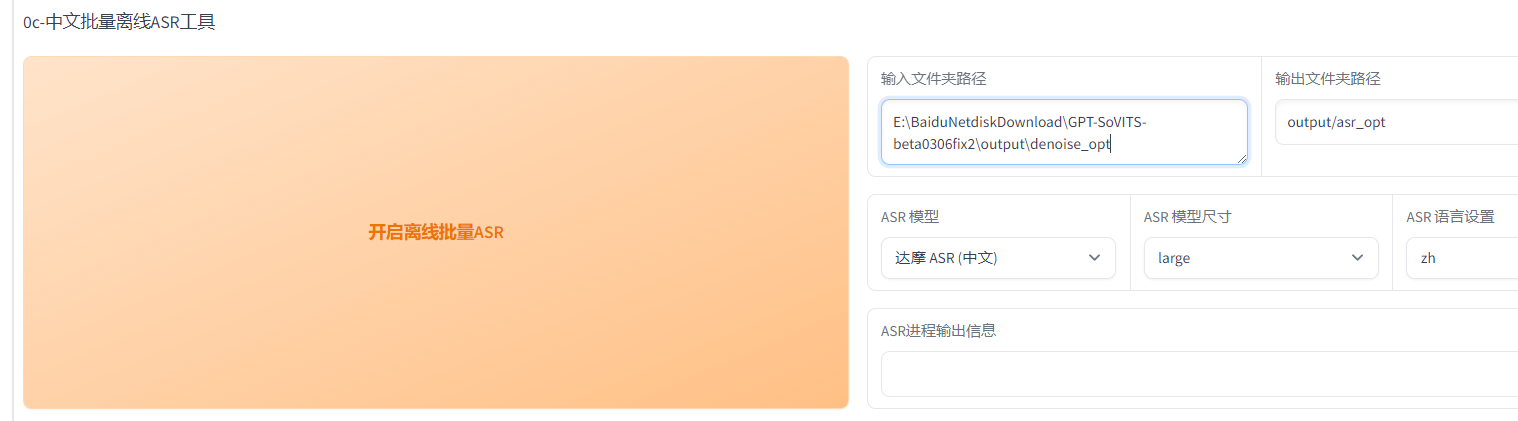
數據清洗
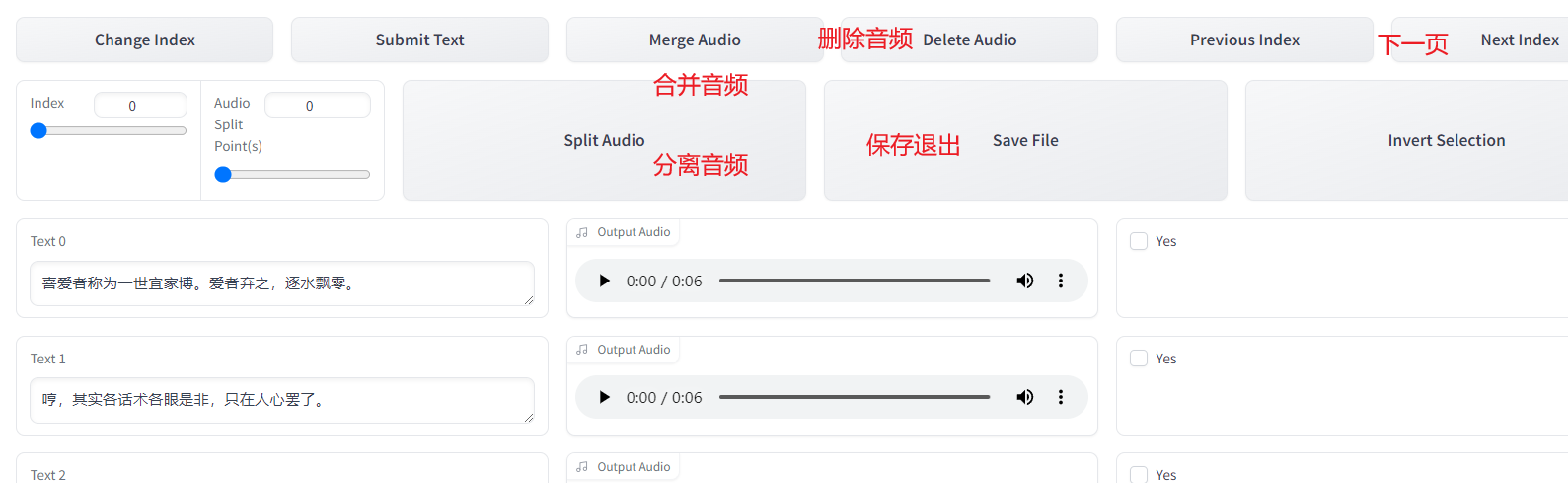
勾選webui,輸入ASR輸出文件路徑

主要這幾個就夠用了,修改文字對應音頻,刪除一些雜亂語音,合并一些過短語音,最后保存退出
訓練集格式化
填入實驗名和路徑,其他默認
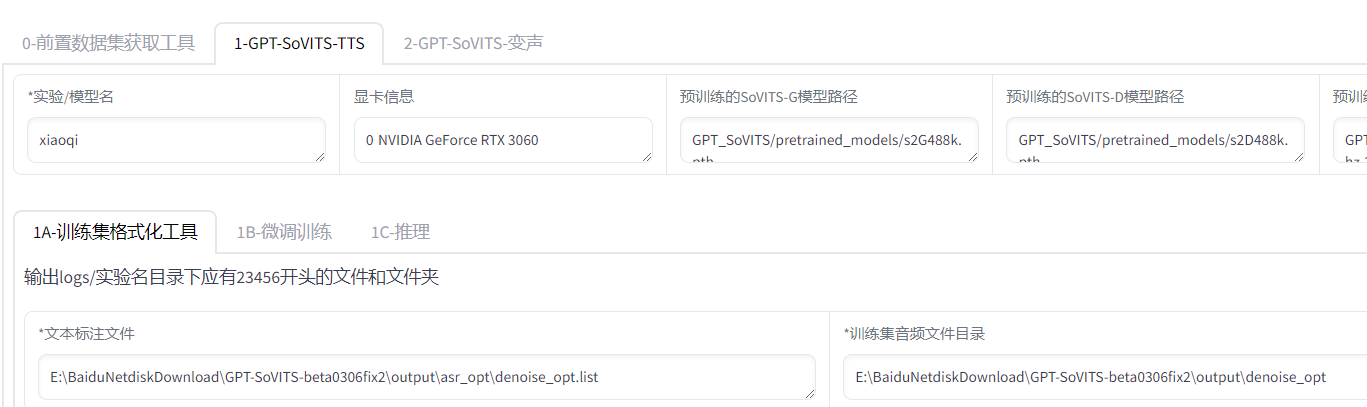
點擊一鍵三連,一次全部運行(E:\BaiduNetdiskDownload\GPT-SoVITS-beta0306fix2\logs\xiaoqi生成五個文件)
微調訓練
8G顯存,按照我這個設置,時長幾分鐘,SOVITS訓練輪數25以下夠了,時長抄半小時,語音吐字清晰,訓練輪數100,200都可以,學習率權重適當降低,否則默認,顯卡大于8G,batch size可以加大,GPT訓練25輪一般效果不錯
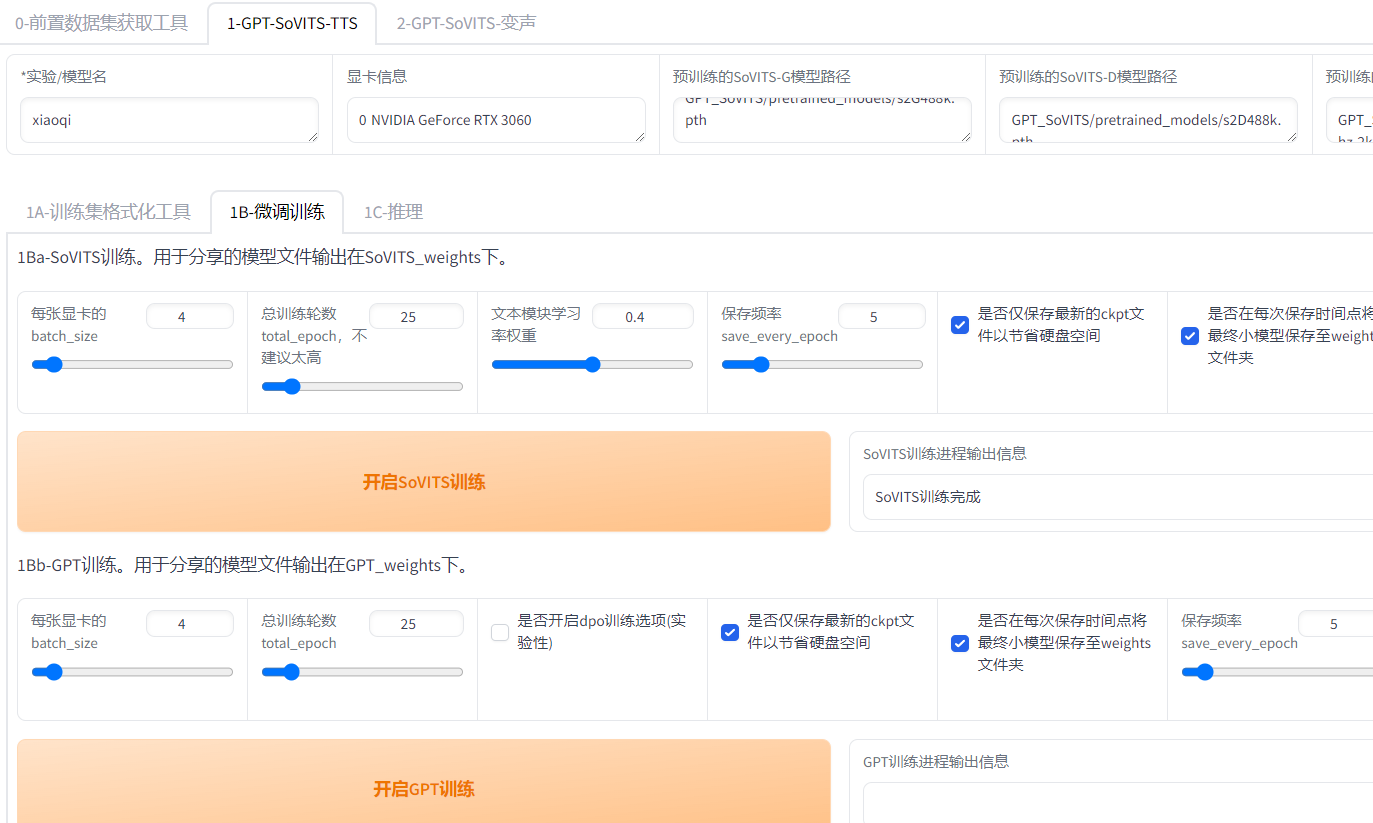
訓練上線無法超過25問題解決,編輯器打開webui.py
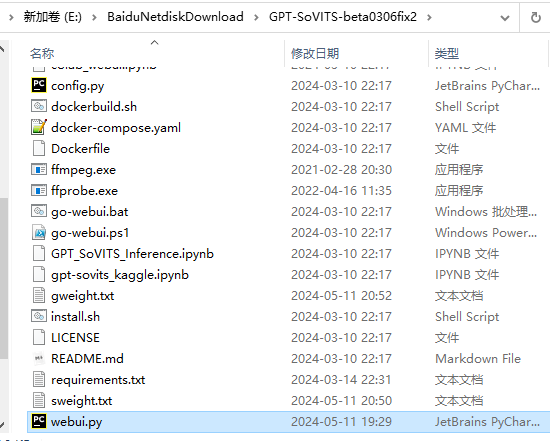
大概830行左右,修改200即可

模型路徑
推理
勾選TTS webui
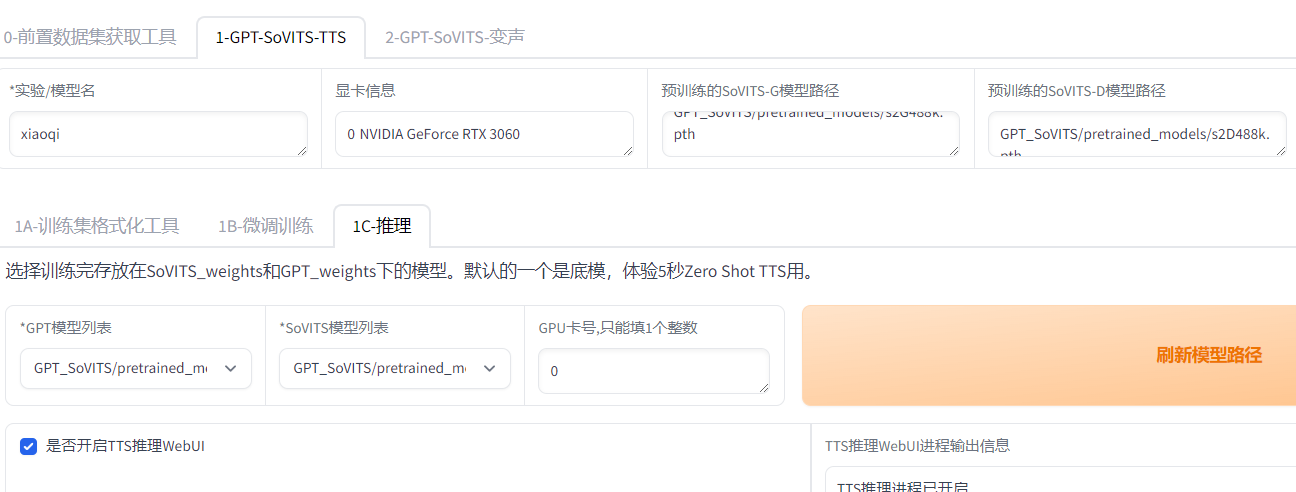
來到
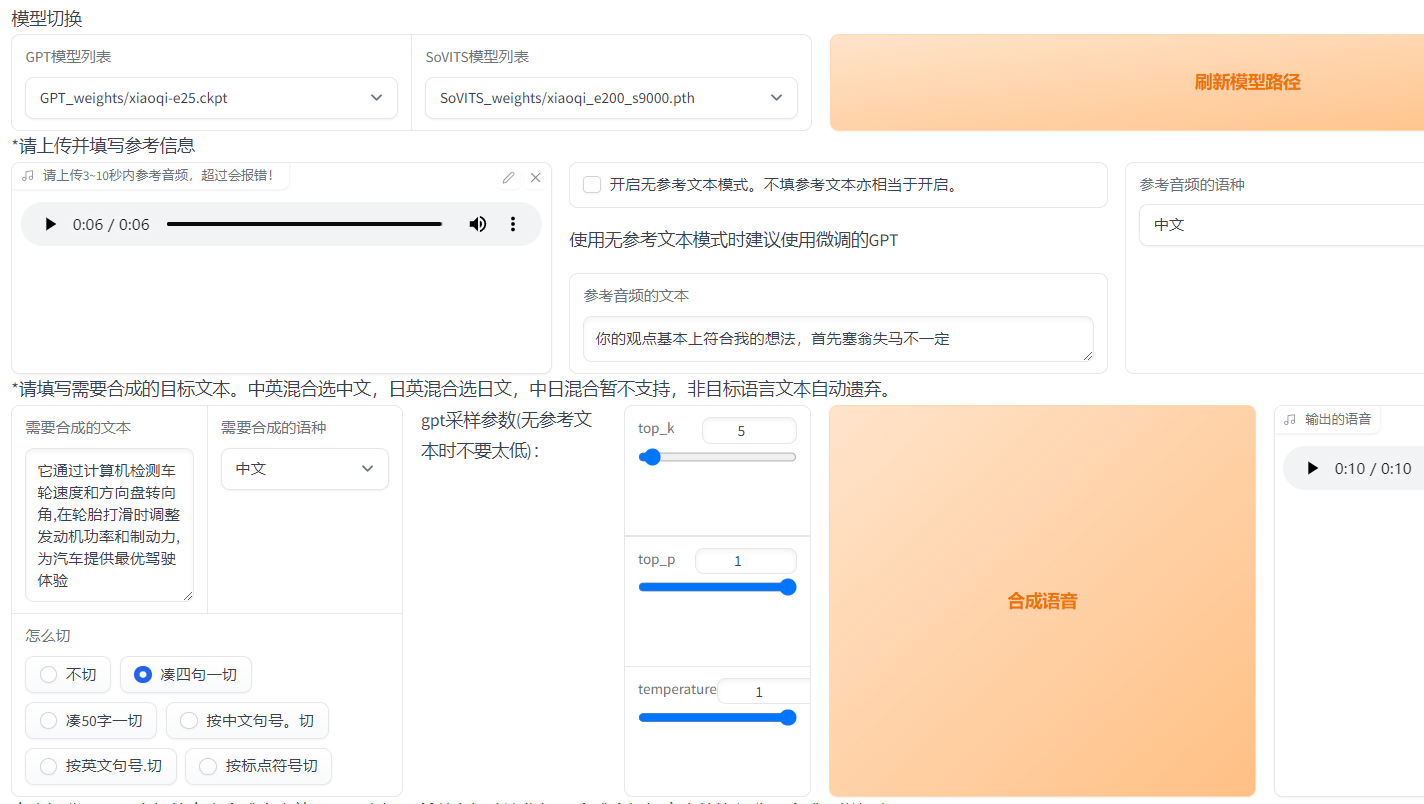
GPT25輪效果不錯,SOVITS選擇輪數最高的,因為我音頻大概35分鐘,訓練久點效果更好
如果參考音頻選擇訓練音頻則推理出的聲音更符合訓練集音色,如果看看音頻為非訓練集音頻,則為音頻融合(音色融合),切分方式我感覺湊四句一切效果較好
還可以輸入日文轉英語,有那味了,
其他更多有待自己嘗試了




![PermissionError: [Errno 13] Permission denied: ‘xx.xlsx‘的解決辦法](http://pic.xiahunao.cn/PermissionError: [Errno 13] Permission denied: ‘xx.xlsx‘的解決辦法)
——實現敵人接收攻擊傷害,并作出反應)




)




: 樣式庫搭建)



)