
序言:
在這篇博客中我們將講解線程的概念,如何理解線程,線程和進程的區別,線程的優缺點等,我相信你看完這篇博客后會以別樣的視角重新理解線程,下面的內容全部是基于Linux操作系統的。
一、線程的概念
1.1、重新理解地址空間
在外面之前的博客中我們說過:進程 = 內核數據結構 + 自己的代碼和數據。內核數據結構,代碼和數據都需要保存在內存中。它們都經過內核頁表或者用戶頁表進行映射到地址空間讓我們的進程看見這些資源,換一句話來說地址空間不就是進程的 “窗口” 嗎?,因為進程大部分的數據都需要直接或者間接(比如棧,加載的庫,進程的代碼和數據,內核的代碼和數據等等)通過地址空間看見。
下面我們回答一些問題讓我們的理解更加深刻:
缺頁中斷是怎么回事?
現在我們帶入一個場景:
當我們malloc的時候,操作系統會做什么?
操作系統會根據我們需要的大小在我們的地址空間開辟一塊空間(mm_struct的end和start指針上下移動就可以在地址空間開辟空間),但我們的操作系統并沒有在我們的物理內存上為我們開辟真正的空間,如果當我們使用這一塊空間的時候CPU上的MMU寄存器在進行虛擬地址和物理地址轉化的時候失敗觸發中斷CPU保護現場拿到中斷號,然后去中斷向量表去執行指定的中斷方法(在物理內存上開辟空間,創建頁表建立虛擬地址和物理地址的映射)執行完成再恢復現場去執行進程下面的代碼)。
看完上面對缺頁中斷的處理方法,我們有一種體會:只要我們的進程有了虛擬地址那么我們就一定還會有物理地址,只是當我們申請空間的時候開辟還是當我們真實使用的時候才會去開辟。
那么我們得出來一個結論:進程有多少虛擬地址就代表進程有多少資源,換一句話來說地址空間就是資源的代表。
教材給進程的定義是:進程是承擔分配系統資源的基本實體。
這句話應該如何去理解呢?
當我們創建一個進程的時候,操作系統會創建PCB,地址空間,用戶頁表等,這些都是需要占據CPU或者內存資源,所以進程是分配系統資源的基本實體。
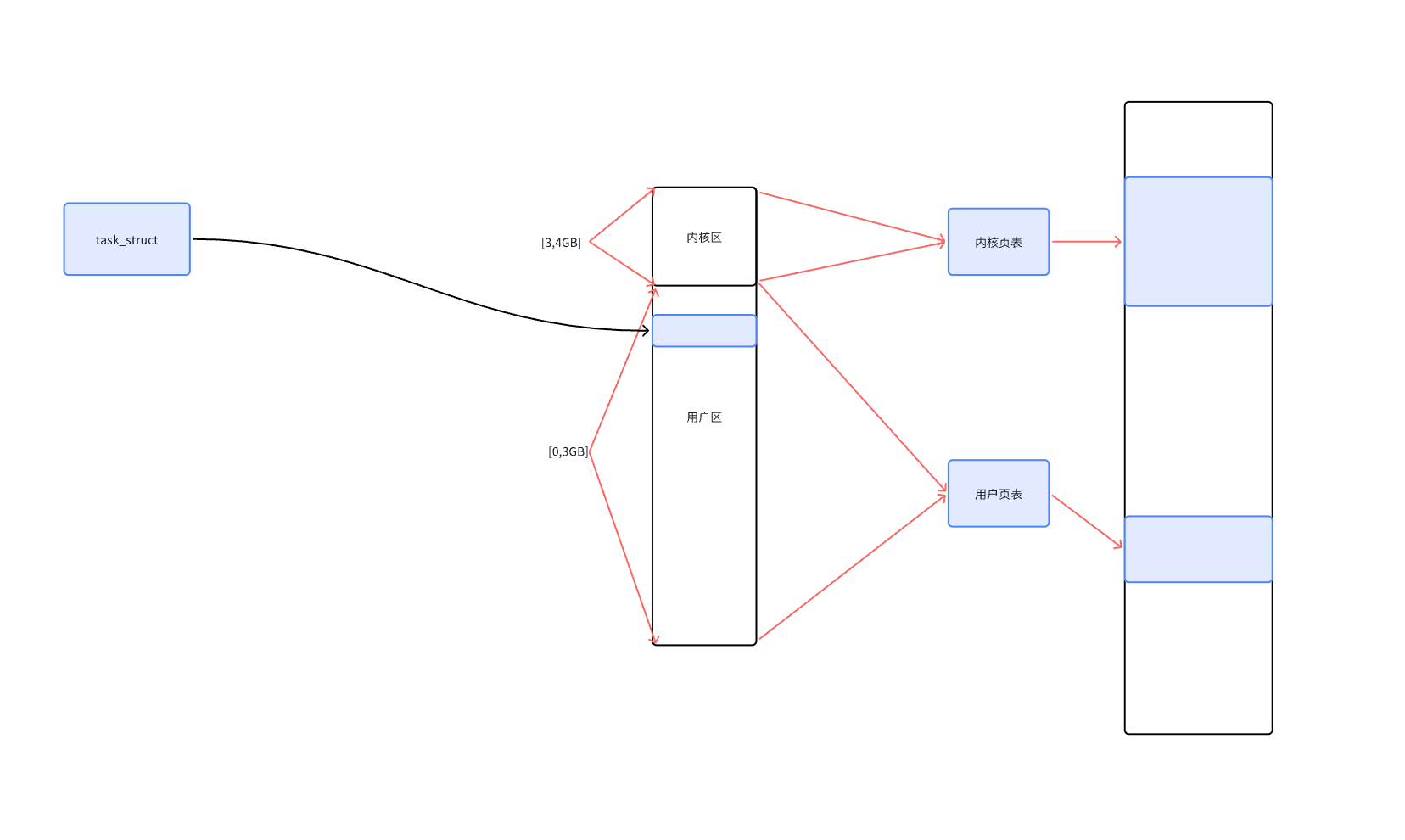
1.2、什么是線程?
如果現在我們在一個主進程創建一個 “進程”(這里的進程只需要PCB不需要創建地址空間等內核數據),這個“新進程”可以看見和使用主進程的系統資源。如果可以把資源劃分給不同的PCB再讓不同的PCB執行對應的資源,這就是線程的概念。
如何去劃分資源?
地址空間就是資源的代表,劃分地址空間不就相當于劃分資源嗎?,劃分地址空間換一句話來說不就相當于劃分虛擬地址范圍,如果我們可以讓不同的執行流去執行不同的函數不就相當于去劃分了資源。
為什么執行不同的函數就相當于劃分資源?
當我們的函數編譯成匯編代碼以后每一句代碼都有自己的地址,這些地址不就是虛擬地址嗎?換一句話來說函數就是虛擬地址的集合,函數天然就幫我們劃分好了資源,當我們給不同的PCB不同的入口代碼地址那么這些PCB可以并發的執行起來了。
教材給線程的定義是:線程是進程內部的一個執行流。
站在內核和資源的角度給線程的定義:線程是CPU調度的基本單位。
如何去理解我們之前說的進程?
我們之前說進程是一個執行流的,它有PCB內核結構也有進程的代碼和數據加載到內存中,那這和我們上面說的線程不是一樣嗎?其實不一樣,我們給進程的定義是:進程 = 內核數據結構 +? 自己的代碼和數據。
下面我們來看一副圖來理解一下:
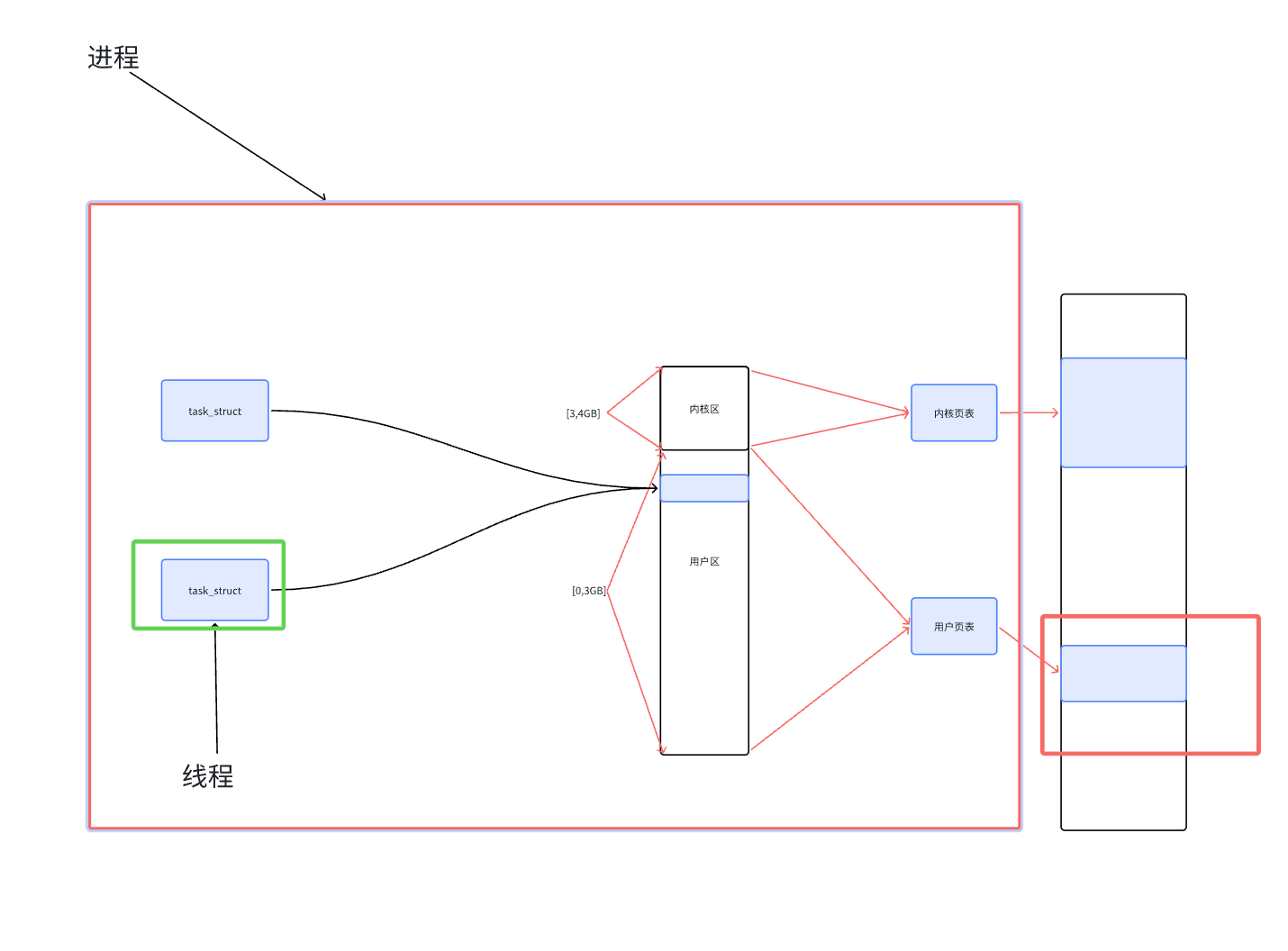
上面圖上畫紅框的才是進程,畫綠框的才是線程,我們可也有說進程中包含線程。我們之前說的那種進程是一種特殊的形式:單線程的進程。

站在操作系統和CPU的角度如何去理解線程?
在Linux中并沒有為了線程單獨設計內核數據結構而是用來以前進程的PCB,這樣做的好處是操作系統的調度算法不需要再重新設計,因為PCB的結構沒有改變,所以在系統看來都是一個一個的執行流,操作系統做進程調用的時候只要調度一個個的執行就好了。
Linux:一個個執行流的概念。
CPU:一種輕量級的進程,因為線程比任何的進程都要更小,換一句話來說 線程 <= 進程。
二、物理內存的管理
2.1、管理頁的結構體
內存中一些空間正在被創建一些需要被銷毀等,我們的內存這么大的空間我們如何去管理它呢?答案還是 “先描述,再組織” 。在我們內核數據結構中有struct page用來管理我們的內存空間。
下面我們來看一下struct page結構體:
struct page {unsigned long flags; /* Atomic flags, some possibly* updated asynchronously */atomic_t _count; /* Usage count, see below. */union {atomic_t _mapcount; /* Count of ptes mapped in mms,* to show when page is mapped* & limit reverse map searches.*/struct { /* SLUB */u16 inuse;u16 objects;};};union {struct {unsigned long private; /* Mapping-private opaque data:* usually used for buffer_heads* if PagePrivate set; used for* swp_entry_t if PageSwapCache;* indicates order in the buddy* system if PG_buddy is set.*/struct address_space *mapping; /* If low bit clear, points to* inode address_space, or NULL.* If page mapped as anonymous* memory, low bit is set, and* it points to anon_vma object:* see PAGE_MAPPING_ANON below.*/};
#if USE_SPLIT_PTLOCKSspinlock_t ptl;
#endifstruct kmem_cache *slab; /* SLUB: Pointer to slab */struct page *first_page; /* Compound tail pages */};union {pgoff_t index; /* Our offset within mapping. */void *freelist; /* SLUB: freelist req. slab lock */};struct list_head lru; /* Pageout list, eg. active_list* protected by zone->lru_lock !*//** On machines where all RAM is mapped into kernel address space,* we can simply calculate the virtual address. On machines with* highmem some memory is mapped into kernel virtual memory* dynamically, so we need a place to store that address.* Note that this field could be 16 bits on x86 ... ;)** Architectures with slow multiplication can define* WANT_PAGE_VIRTUAL in asm/page.h*/
#if defined(WANT_PAGE_VIRTUAL)void *virtual; /* Kernel virtual address (NULL ifnot kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGSunsigned long debug_flags; /* Use atomic bitops on this */
#endif#ifdef CONFIG_KMEMCHECK/** kmemcheck wants to track the status of each byte in a page; this* is a pointer to such a status block. NULL if not tracked.*/void *shadow;
#endif
};struct page結構體的成員變量
flags:用來存放頁的狀態,一共有32種狀態。
_mapcount:這個頁被多少個頁表引用。
virtual:這個也在地址空間里的虛擬地址。
strcut page的大小大概是40多字節全部的頁的struct page放在一起也不過40MB對內存資源的銷毀并不大。
內存天然是4KB大小塊劃分的嗎?
答案是不是的,內存是被操作系統分為4KB大小的塊的,內存本身是一塊連續的空間。
為什么要以4KB為大小?
這個是科學家經過測試出來的4KB的效率更高,當然也有很多其他的因素,比如歷史,硬件等。
下面我想補充幾個概念:
頁框和頁幀:現在在教材中頁幀和頁框的概念是相同的了,它們都表示在磁盤中或者在內存中4KB的存儲空間。
頁:表示4KB頁框中存儲的數據內容。
2.2、如何去申請空間?
在操作系統中我們可以認為管理struct page結構體通過數組的方式管理

那么我們如何去申請一塊空間呢?
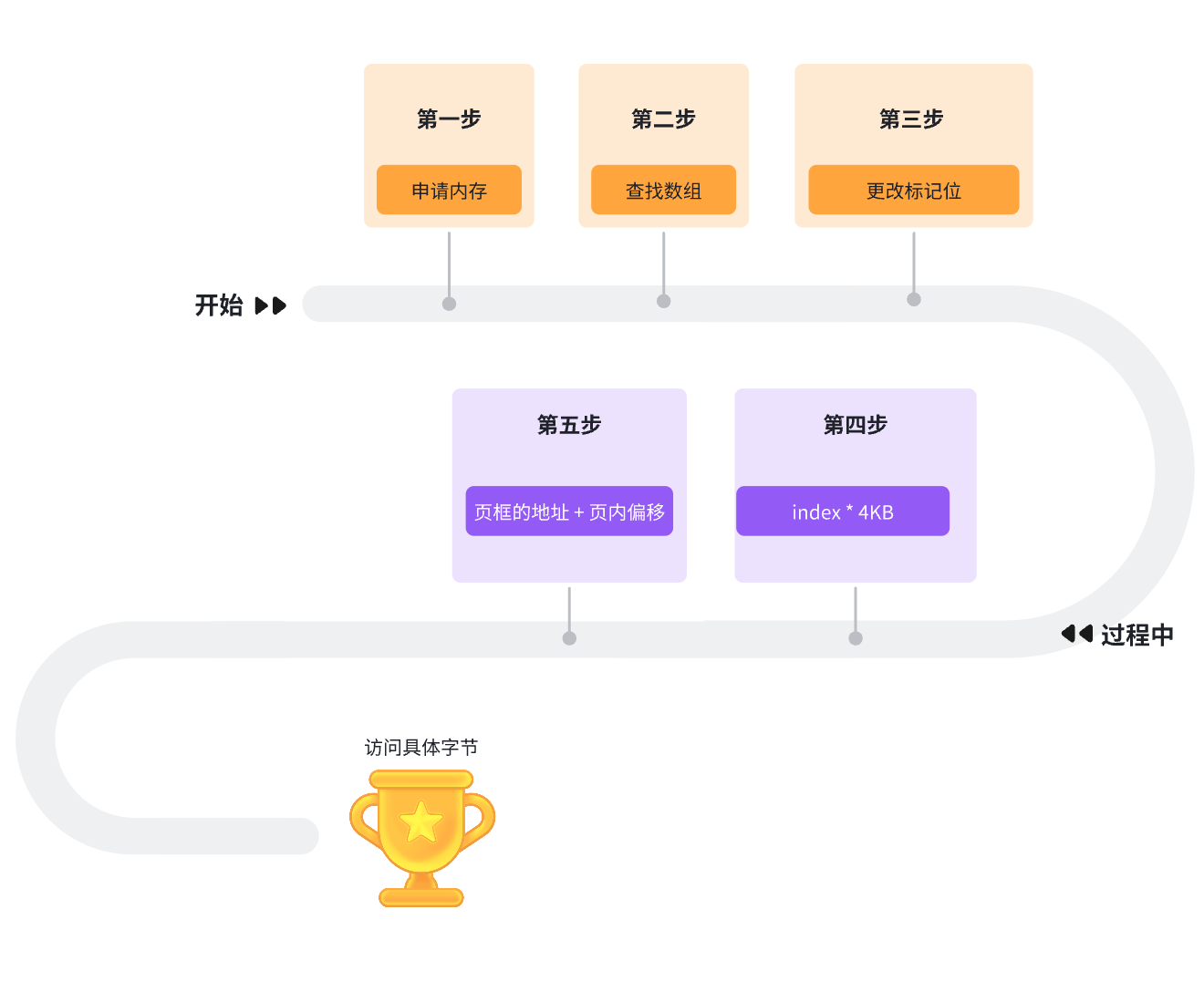
我們可以現在struct page數組中尋找到一個struct page我們知道了它的下標,再去更改struct page中的flag標志位將未占用改為占用,然后通過下標index * 4KB就可以找到內存中具體的頁框地址。
申請內存的流程是:
如何去銷毀對應的空間呢?
通過物理地址 / 4KB找到對應struct page的下標,再去更改struct page里的flag標記位,就可以了。
三、如何去理解頁表?
按32位的機器來說,我們的內存有4GB如果按照我們說的左邊是虛擬地址右邊是物理地址的形式,那光光頁表如果是全部映射的話就需要32GB(4GB * 8字節)的大小,在我們的操作系統里肯定會有很多的進程,我們的內存全部用來存頁表都不夠,這種方式顯然是不可能是我們操作系統實現頁表的方法。

那么我們的操作系統是如何實現對頁表的保存的:多級頁表的形式。
3.1、多級頁表
32位機器中地址一共32位個比特位,操作系統把32個比特位分為三份,第一份為0~10位,第二份為11~20位,第三份為21~32位,它們三個分別承擔了不同的任務。
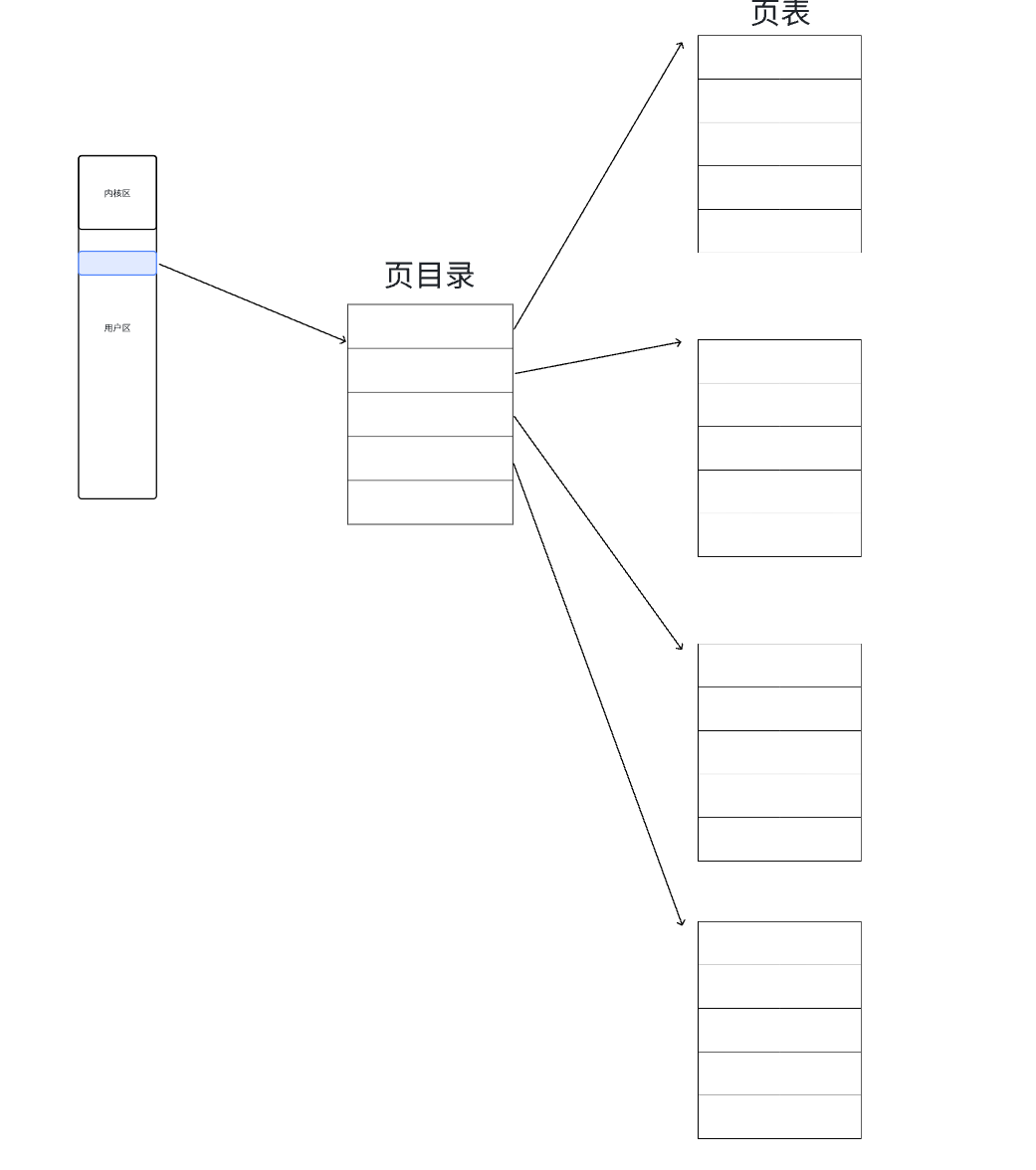
在頁目錄表項存儲的是:頁表的地址。
在頁表表項存儲的是:具體物理內存頁框的地址。
前10為比特位作為索引去查找頁目錄找到對應的頁表地址,再用中間10為比特位來作為索引查找頁表找到對應的頁框的地址,最后再用最后12位比特位來作為具體的頁內偏移去訪問具體的字節內容。
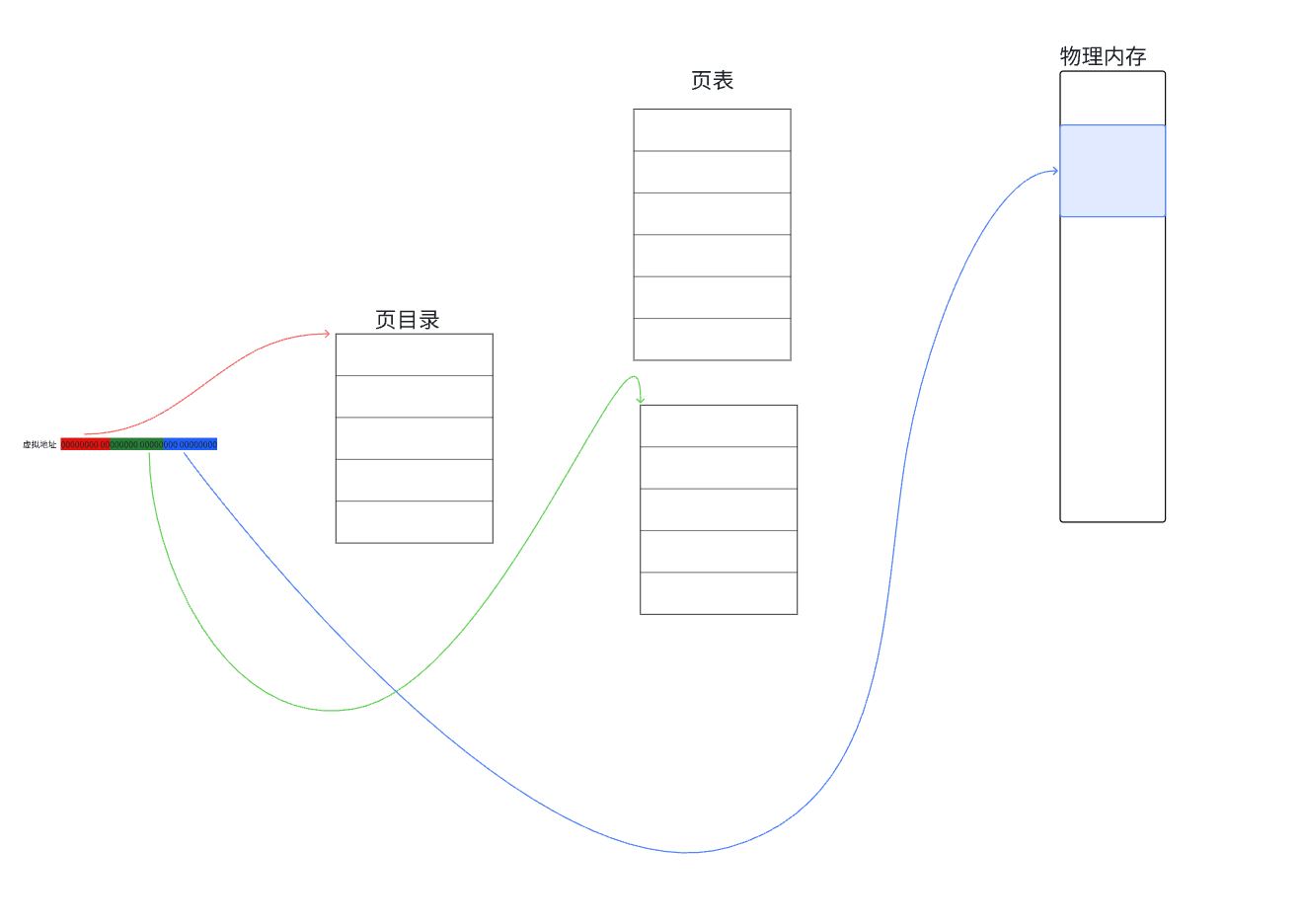
我們前面說過 具體的物理地址 = 物理內存頁框地址 + 頁內偏移,通過上面這種多級頁表的方式就可以訪問具體的字節。
下面我們來回答幾個問題:
為什么頁內偏移設置成地址的低12位?
這個問題的答案在前20位上,一個頁框內的地址是不是前20位都是一樣的,我們在訪問一句代碼的時候根據局部性原理我們很有可能訪問這句代碼周圍的代碼和數據,如果訪問的數據是在附近的那么它們的前20位很可能是相同的它們只要低12位是不一樣的,這也就說明它們在同一個頁框中我們可以用盡量少次數的訪問把它們全部找到效率高。
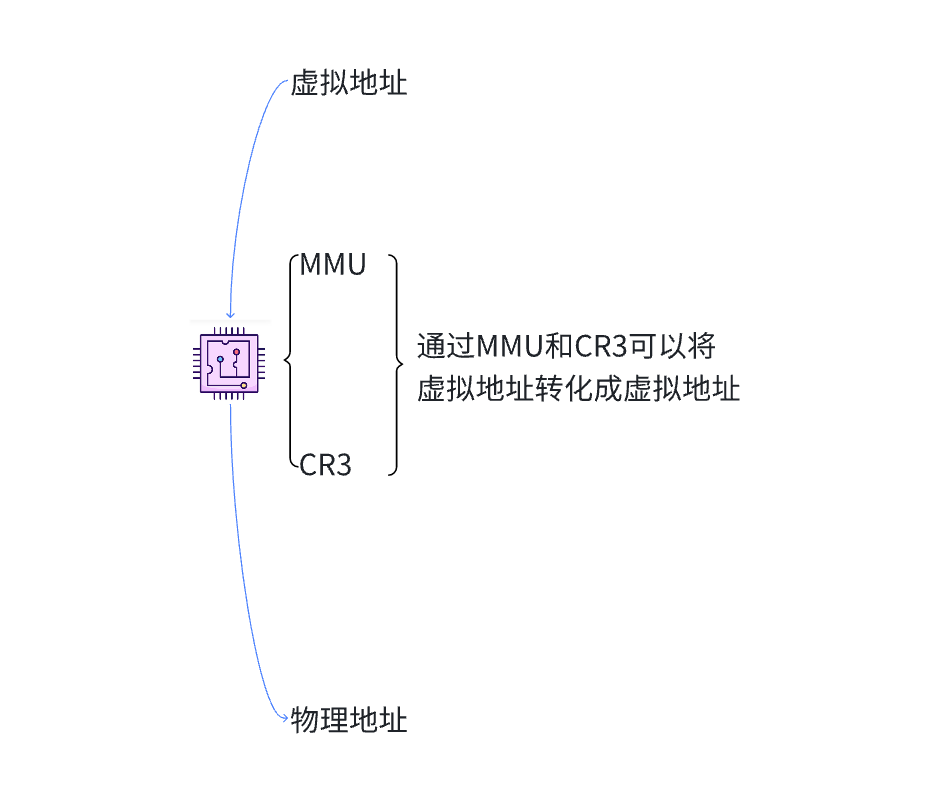
我們的用戶用的全部都是虛擬地址通過什么去進行轉化?
在我們的CPU中集成了MMU和CR3寄存器,CR3中存放的是頁目錄的地址,MMU可以根據CR3提供的頁目錄地址去查找頁目錄,頁表進而將虛擬地址轉化成物理地址。
MMU要先進?兩次?表查詢確定物理地址,在確認了權限等問題后,MMU再將這個物理地址發送到總線,內存收到之后開始讀取對應地址的數據并返回。那么當?表變為N級時,就變成了N次檢索+1次讀寫,這也就說明了多級頁表的一個缺點:效率低。
?
多級頁表和單張頁表的優缺點:
多級頁表:
優點:省空間。
缺點:如果頁表分級比較多查找需要多次降低效率。
單級頁表:
優點:效率高,只需要查找一次。
缺點:需要占據的內存大小比較大。
3.2、頁表的優點
1、維護進程的獨立性
如果沒有頁表,進程直接去訪問物理空間,如果有惡意軟件直接去改變其他進程的數據,就可能導致其他軟件的錯誤導致進程被殺死,進而進程的安全性無法保證。
2、高效利用物理內存
離散分配:進程的虛擬地址空間可以映射到物理內存中不連續的頁框(物理頁),避免了傳統連續內存分配導致的 “內存碎片” 問題,提高了物理內存的利用率。
按需加載:結合分頁機制,進程無需將全部數據加載到物理內存即可運行(僅加載當前需要的頁),實現了 “部分加載”,讓有限的物理內存可以支持更多進程并發運行。
3、?支持內存共享與保護
共享內存:多個進程的頁表可映射到同一物理頁框(如共享庫、進程間通信的共享內存區域),實現內存內容的共享,減少重復存儲,節省物理內存。
權限控制:頁表項(PTE)中包含權限位(如讀、寫、執行權限),操作系統可通過設置這些位限制對內存頁的操作(如只讀頁禁止修改、數據頁禁止執行),防止非法訪問(如緩沖區溢出攻擊)。
四、缺頁中斷怎么回事?
當我們給CPU一個虛擬地址的時候,它會先去到TLB(我們之前在《Linux Ext文件系統》中介紹過)中去尋找,沒有找到,它再去把虛擬地址給MMU,MMU再去通過CR3提供的頁目錄地址去想你找對應的頁表,也沒有找到,這個時候觸發軟中斷。
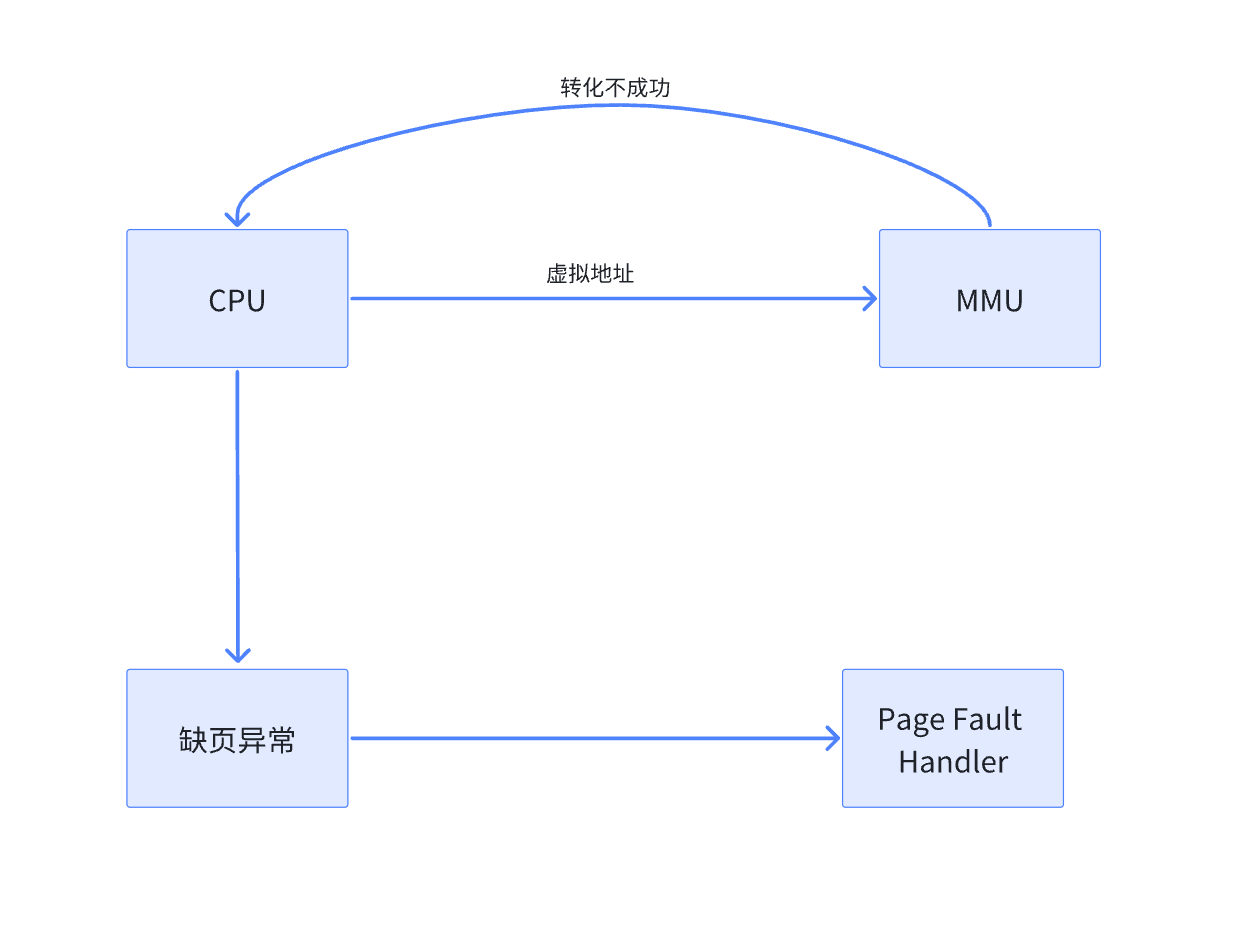
Page Falut Handler:在磁盤中找到對應的數據,在struct page中申請內存空間,將磁盤中的數據載入到內存中申請頁表建立頁表和物理內存的映射關系,然后返回。
=========================================================================
本篇關于Linux的文件理解與操作的介紹就暫告段落啦,希望能對大家的學習產生幫助,歡迎各位佬前來支持糾正!!!



)





)


)
-部署和使用指南)






