目錄
本文說明
一:字典程序的幾個問題
1:字典的本質
2:翻譯功能的本質
3:讓服務端和翻譯功能相關聯
二:字典類(Dict.hpp)
1:加載詞典(Load)
2:翻譯單詞(Translate)
三:服務端(UdpServer.hpp)
四:Main.cc
五:客戶端(UdpClient.cc)
六:日志文件(Log.hpp)
七:makefile
八:運行效果
本文說明
本文旨在實現UDP編程下的字典程序,輸入英文返回中文,在其中不大改之前的echo程序的代碼,而是讓翻譯功能和服務端類分離開,形成松耦合的效果~~
其中涉及到的socket接口、echo程序、日志文件都在以下博客中:
socket接口及echo程序:https://blog.csdn.net/shylyly_/article/details/151292001
日志文件的實現:https://blog.csdn.net/shylyly_/article/details/151263351
一:字典程序的幾個問題
1:字典的本質
直接導入一個名為Dict.txt的文件即可,文件內容如下,暫且導入這點詞匯,作為測試
apple: 蘋果
banana: 香蕉
cat: 貓
dog: 狗
book: 書
pen: 筆
happy: 快樂的
sad: 悲傷的
run: 跑
jump: 跳
teacher: 老師
student: 學生
car: 汽車
bus: 公交車
love: 愛
hate: 恨
hello: 你好
goodbye: 再見
summer: 夏天
winter: 冬天2:翻譯功能的本質
既然我們是松耦合,那么我們選擇在新文件中創建一個字典類Dict來完成關于字典的操作;字典的操作分為兩步:①導入詞匯,②翻譯
①導入詞匯:只需把詞匯插入進哈希表unordered_map
②翻譯:這樣我們的翻譯就可以直接使用哈希表unordered_map進行,翻譯可以分為兩種!第一種是英文作為K值,中文作為V值,使用哈希表自帶的[ ]即可形成翻譯效果,第二種是通過遍歷得到對應的K值的迭代器,然后打印迭代器的second即可
3:讓服務端和翻譯功能相關聯
如果是強耦合,則很簡單,我們只需要在服務端類中大改代碼,成員變量增加哈希表等,成員函數增加翻譯函數等,但是這是不優雅的寫法
松耦合讓我們擁有了一個獨立的字典類,該類中有翻譯功能,而我們的服務端類相使用字典類中的翻譯函數,只需使用bind實現,一個類綁定另一個類中的函數即可!
bind的講解博客:https://blog.csdn.net/shylyly_/article/details/151109228
所以我們的服務端類的構造函數的參數就應該新增一個去接受字典類的翻譯函數,然后使用bind把服務端類構造時的參數和字典類的翻譯函數綁定即可,這樣我們的服務端運行起來依舊只需要輸入端口號,這才優雅
二:字典類(Dict.hpp)
#pragma once#include <iostream> //C++頭文件
#include <unordered_map> //哈希表
#include <fstream> //C++的文件操作
#include <string> //使用string類型
#include "Log.hpp" //包含日志文件// 字典命名空間
namespace dict_ns
{const std::string defaultpath = "./Dict.txt"; // 字典文件的默認文件路徑 為當前路徑下的Dict.txt文件const std::string sep = ": "; // 字典文件中鍵值對的分隔符// 字典類class Dict{private:bool Load() // 私有方法:從文件加載字典數據到哈希表{std::ifstream in(_dict_conf_filepath); // 創建輸入文件流if (!in.is_open()) // 檢查文件是否成功打開 及其打開失敗的處理{LOG(FATAL, "open %s error\n", _dict_conf_filepath.c_str());return false;}std::string line;while (std::getline(in, line)) // 逐行讀取文件{if (line.empty()) // 如果讀到空行(什么字符都沒有的一行)continue; // 則跳過此空行 回到while里的getline 去讀取下一行// 來到這 則代表改行不是空行auto pos = line.find(sep); // 則需要先找到分隔符的 pos為分隔符的起始位置if (pos == std::string::npos) // 如果沒有分隔符 代表格式不對!continue; // 則繼續continent 回到while里的getline 去讀取下一行// 來到這 代表一定有分隔符std::string word = line.substr(0, pos); // 則提取改行中的單詞if (word.empty()) // 如果分隔符前面沒有單詞continue; // 則繼續continent 回到while里的getline 去讀取下一行// 來到這 代表已經提取到了單詞 則下面進行提取到中文std::string han = line.substr(pos + sep.size()); // 提取出中文if (han.empty()) // 如果分割符后面沒有中文continue; // 則繼續continent 回到while里的getline 去讀取下一行LOG(DEBUG, "load info, %s: %s\n", word.c_str(), han.c_str()); // 順便使用日志 打印一下提取到的單詞和中文_dict.insert(std::make_pair(word, han)); // 把提取到的單詞和中文插入到哈希表}in.close(); // 關閉文件LOG(DEBUG, "load %s success\n", _dict_conf_filepath.c_str()); // 順便使用日志 打印加載成功 以及詞典的文件名字return true;}public:// 構造函數 內部直接調用加載函數// 構造函數接收一個 path 參數,path參數默認缺省為"./Dict.txt" 也可以自己傳參指定路徑// 再用 path 的值來初始化成員變量 _dict_conf_filepathDict(const std::string &path = defaultpath) : _dict_conf_filepath(path){Load(); // 調用加載函數}// 翻譯函數std::string Translate(const std::string &word, bool &ok) // 第一個參數是單詞 第二個是bool值(用來反映翻譯是否可靠){ok = true;auto iter = _dict.find(word); // 單詞作為哈希表的find接口的參數,去查找是否存在if (iter == _dict.end()) // 如果find的返回值是end(),代表沒找到{ok = false; // 則返回的不是翻譯 而是提示語句 所以bool值為false 表示返回的值不可靠return "未找到";}// return _dict[word];return iter->second; // 返回v值}// 析構函數~Dict(){}private:std::unordered_map<std::string, std::string> _dict; // 哈希表std::string _dict_conf_filepath; // 詞典的路徑};
}1:加載詞典(Load)
字典類的重點在于如何把文件中每一行的單詞和中文加載到哈希表中,我們將次邏輯封裝進了Load函數中,代碼邏輯如下:
①:創建一個?ifstream(輸入文件流)對象?in,并且打開詞典文件(路徑:_dict_conf_filepath)
std::ifstream in(_dict_conf_filepath); // 創建輸入文件流
if (!in.is_open()) // 檢查文件是否成功打開 及其打開失敗的處理
{LOG(FATAL, "open %s error\n", _dict_conf_filepath.c_str());return false;
}②:使用getline函數讀取詞典文件中的每一行,而每一行不一定都是 apple: 蘋果 這樣的格式,所以我們需要對不符合要求的行進行跳過,而不符合要求的行有幾種情況:
情況1:直接就是空行
情況2:不是空行 但沒有分隔符
情況3:有分隔符 但是沒有單詞
情況4:有分隔符 但是沒有中文
遇到以上的4中情況,只需使用關鍵字continue即可,其會跳過后序代碼,來到while中的getline再次取到下一行!因為每次不管是否合規,我們都已經讀取到了一整行,所以continue之后,回到最初的while中getline就會讀取到下一行
Load函數代碼:
bool Load() // 私有方法:從文件加載字典數據到哈希表{std::ifstream in(_dict_conf_filepath); // 創建輸入文件流if (!in.is_open()) // 檢查文件是否成功打開 及其打開失敗的處理{LOG(FATAL, "open %s error\n", _dict_conf_filepath.c_str());return false;}std::string line;while (std::getline(in, line)) // 逐行讀取文件 (std::getline(輸入流對象, 字符串變量);){if (line.empty()) // 如果讀到空行(什么字符都沒有的一行)continue; // 則跳過此空行 回到while里的getline 去讀取下一行// 來到這 則代表改行不是空行auto pos = line.find(sep); // 則需要先找到分隔符的 pos為分隔符的起始位置if (pos == std::string::npos) // 如果沒有分隔符 代表格式不對!continue; // 則繼續continent 回到while里的getline 去讀取下一行// 來到這 代表一定有分隔符std::string word = line.substr(0, pos); // 則提取改行中的單詞if (word.empty()) // 如果分隔符前面沒有單詞continue; // 則繼續continent 回到while里的getline 去讀取下一行// 來到這 代表已經提取到了單詞 則下面進行提取到中文std::string han = line.substr(pos + sep.size()); // 提取出中文if (han.empty()) // 如果分割符后面沒有中文continue; // 則繼續continent 回到while里的getline 去讀取下一行LOG(DEBUG, "load info, %s: %s\n", word.c_str(), han.c_str()); // 順便使用日志 打印一下提取到的單詞和中文_dict.insert(std::make_pair(word, han)); // 把提取到的單詞和中文插入到哈希表}in.close(); // 關閉文件LOG(DEBUG, "load %s success\n", _dict_conf_filepath.c_str()); // 順便使用日志 打印加載成功 以及詞典的文件名字return true;}理解了四種需要continue的情況之后,還需要理解怎么從一個合格的行中,摘取出單詞和中文,這就需要使用到string的substr接口了!關鍵點在于我們知道分隔符是冒號空格,我們已經將其定義成了sep!
所以當我們不是情況1空行的時候,我們首先要做的就是查找到我們的分隔符,如果找不到就是情況2,反之找到了分隔符,我們的find函數就會返回分隔符的第一個字符也就是冒號的下標,所以此時我們就使用substr去摘取單詞!代碼如下:
std::string word = line.substr(0, pos); // 則提取改行中的單詞
if (word.empty()) // 如果分隔符前面沒有單詞continue; 參數0代表從下標為0處開始摘取單詞,pos代表摘取的字符的個數,冒號的下標剛好就是單詞中字符的格式,所以直接line.substr(0, pos)即可!
再下來就是摘取中文,此時我們還會再使用substr,第一個參數應該是中文的第一個字符的下標,所以我們只需pos(冒號的下標)+分隔符的size即可讓pos移動到中文的第一個字符的下標,代碼:
// 來到這 代表已經提取到了單詞 則下面進行提取到中文
std::string han = line.substr(pos + sep.size()); // 提取出中文
if (han.empty()) // 如果分割符后面沒有中文continue; substr的第二個參數不填,代表sunstr會一直向后取到line這個字符串,也就是我們getline獲取到的當前行的末尾,我們無需再傳遞參數
2:翻譯單詞(Translate)
而翻譯函數就更簡單了,我們只需對接收到的參數,也就是一個英文單詞,將其作為哈希表的k值即可,返回v值即可達到翻譯的效果
而Translate參數中的bool值,只是用來避免我們詞典中沒有這個單詞,返回未找到,但是用戶剛好傳進來的單詞的翻譯就是未找到的情況,所以bool值為true代表翻譯是可靠的,反之代表翻譯不可靠,也就是買找到,打印未找到
當然,你也可以完全不用這個bool值參數,因為我們本來就是翻譯一個單詞,干脆把沒找到翻譯的情況,我們打印"該單詞未被收錄"即可,因為不會有一個單詞的翻譯會是"該單詞未被收錄"這么長!
// 翻譯函數
std::string Translate(const std::string &word, bool &ok) // 第一個參數是單詞 第二個是bool值(用來反映翻譯是否可靠)
{ok = true;auto iter = _dict.find(word); // 單詞作為哈希表的find接口的參數,去查找是否存在if (iter == _dict.end()) // 如果find的返回值是end(),代表沒找到{ok = false; // 則返回的不是翻譯 而是提示語句 所以bool值為false 表示返回的值不可靠return "未找到";}// return _dict[word];return iter->second; // 返回v值
}三:服務端(UdpServer.hpp)
#pragma once#include <iostream>
#include <string>
#include <cerrno>
#include <cstring>
#include <cstdlib>
#include <strings.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <functional>
#include "Log.hpp"// 一些發生錯誤時候 返回的枚舉變量
enum
{SOCKET_ERROR = 1,BIND_ERROR,USAGE_ERROR
};// socket接口默認的返回值
const static int defaultfd = -1;// typedef std::function<std::string(const std::string&)> func_t;
using func_t = std::function<std::string(const std::string &, bool &ok)>; // 定義一個函數類型 別名為func_tclass UdpServer
{
public:// 構造函數 socket的返回值 端口號 是否運行 翻譯函數UdpServer(uint16_t port, func_t func) : _sockfd(defaultfd), _port(port), _isrunning(false), _func(func){}// 析構函數~UdpServer(){}// 初始化服務端void InitServer(){// 1:創建udp socket 套接字_sockfd = socket(AF_INET, SOCK_DGRAM, 0); // AF_INET代表網絡通信 SOCK_DGRAM代表數據報 所以就是UDP 第三個參數填寫0即可// 創建套接字失敗 打印語句提醒if (_sockfd < 0){LOG(FATAL, "socket error, %s, %d\n", strerror(errno), errno);exit(SOCKET_ERROR);}// 創建套接字成功 打印語句提醒LOG(INFO, "socket create success, sockfd: %d\n", _sockfd);// 2.0 填充sockaddr_in結構struct sockaddr_in local; // 網絡通信 所以定義struct sockaddr_in類型的變量bzero(&local, sizeof(local)); // 先把結構體情況 好習慣local.sin_family = AF_INET; // 填寫第一個字段 (地址類型)local.sin_port = htons(_port); // 填寫第二個字段PORT (需先轉化為網絡字節序)local.sin_addr.s_addr = INADDR_ANY; // 填寫第三個字段IP (直接填寫0即可,INADDR_ANY就是為0的宏)// 2:bind綁定// 我們填充好的local和我們創建的套接字進行綁定(綁定我們接收信息發送信息的端口)int n = bind(_sockfd, (struct sockaddr *)&local, sizeof(local));// 綁定失敗 打印語句提醒if (n < 0){LOG(FATAL, "bind error, %s, %d\n", strerror(errno), errno);exit(BIND_ERROR);}// 綁定成功 打印語句提醒LOG(INFO, "socket bind success\n");}// 啟動服務端(不想讓網絡通信模塊和業務模塊進行強耦合)void Start(){// 先把bool值置為true 代表服務端在運行_isrunning = true;while (true) // 服務端都是死循環{char request[1024]; // 對方端發來的信息 存儲在buffer中struct sockaddr_in peer; // 對方端的網絡屬性socklen_t len = sizeof(peer); // 必須初始化成為sizeof(peer) 不能初始化為0// 我們要讓server先收數據ssize_t n = recvfrom(_sockfd, request, sizeof(request) - 1, 0, (struct sockaddr *)&peer, &len);if (n > 0){request[n] = 0; // 添加字符串終止符 方便得到正確完整的單詞bool ok; // 定義bool值std::string response = _func(request, ok); // 將翻譯請求,回調出去,在外部進行數據處理// 再把翻譯得到的中文,發回給對方sendto(_sockfd, response.c_str(), response.size(), 0, (struct sockaddr *)&peer, len);}}_isrunning = false;}private:int _sockfd; // socket的返回值 在多個接收中都需要使用uint16_t _port; // 服務器所用的端口號bool _isrunning; // 反映是否在運行的bool值// 給服務器設定回調,用來執行翻譯的函數func_t _func;
};解釋:
服務端和上篇博客的echo程序的服務端大致相同,因為我們是松耦合!將翻譯函數全部交給了字典類中的翻譯函數,所以服務端只需要額外理解我們如果引入一個承載字典類中的Translate函數的載體就行!
①:我們需要先定義出一個函數類型,再給其起一個別名,代碼:
using func_t = std::function<std::string(const std::string &, bool &ok)>;
// 定義一個函數類型 別名為func_t這個類型就是我們字典類中的類型,這樣才能完美的將字典類的Translate函數bind到func_t上
②:然后我們需要利用定義出的類型去創建一個成員變量,因為只有創建除了成員變量,我們才可以通過構造函數的參數進行綁定!
func_t _func;③:start中調用_func函數
前面準備工作做好之后,我們需要就是在start函數中進行調用_func函數,也就是我們接收到客戶端傳來的單詞,我們就要把單詞作為參數傳遞進_func函數中,再把_func函數的返回值,也就是翻譯得到的中文,發送給客戶端即可!
// 我們要讓server先收數據
ssize_t n = recvfrom(_sockfd, request, sizeof(request) - 1, 0, (struct sockaddr *)&peer, &len);if (n > 0)
{request[n] = 0; // 添加字符串終止符 方便得到正確完整的單詞bool ok; // 定義bool值std::string response = _func(request, ok); // 將翻譯請求,回調出去,在外部進行數據處理//再把翻譯得到的中文,發回給對方sendto(_sockfd, response.c_str(), response.size(), 0, (struct sockaddr *)&peer, len);
}這樣在我們進行bind操作之后,就可以實現松耦合的翻譯功能了!
四:Main.cc
#include <iostream>
#include <memory>
#include "Dict.hpp"
#include "UdpServer.hpp"using namespace dict_ns; // 打開字典類的命名空間// 運行服務端的時候,因為IP在服務端文件中給定0了
// 所以只需要使用者只需要給服務端一個PORT即可
void Usage(std::string proc)
{std::cout << "Usage:\n\t" << proc << " local_port\n"<< std::endl;
}int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(USAGE_ERROR);}EnableScreen(); // 表示把日志打印到屏幕上Dict dict; // 定義字典類對象uint16_t port = std::stoi(argv[1]); // 從main的參數列表中獲取到PORT// 創建服務端對象 并且使用bind把字典類的成員函數綁定到服務器類的構造參數中std::unique_ptr<UdpServer> usvr = std::make_unique<UdpServer>(port, std::bind(&Dict::Translate, &dict, std::placeholders::_1, std::placeholders::_2));usvr->InitServer(); // 初始化服務端usvr->Start(); // 啟動服務端return 0;
}
解釋:
重點就在于bind的使用!首先需要包含字典文件已經打開字典類的命名空間,然后創建一個字典類的對象,這樣,我們下一步進行創建服務端對象的時候,就可以進行bind了。bind的語法就不再贅述了,都整理在了博客中:https://blog.csdn.net/shylyly_/article/details/151109228
bind之后,就相當于我們服務端類中的_func函數就擁有了實體了,其才能夠真正的實現翻譯功能
五:客戶端(UdpClient.cc)
#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>// 啟動客戶端 需要用戶輸入服務端的IP+PORT
void Usage(std::string proc)
{std::cout << "Usage:\n\t" << proc << " serverip serverport\n"<< std::endl;
}int main(int argc, char *argv[])
{if (argc != 3){Usage(argv[0]);exit(1);}std::string serverip = argv[1]; // 從main的參數列表中獲取到服務端IPuint16_t serverport = std::stoi(argv[2]); // 從main的參數列表中獲取到服務端PORT// 1. 創建socketint sockfd = socket(AF_INET, SOCK_DGRAM, 0);if (sockfd < 0){std::cerr << "socket error" << std::endl;}// 2. 無需顯式的bind OS會自己做// 用戶已經傳遞服務端的IP+PORT// 所以我們sendto就知道了 給哪個服務端傳遞信息// 所以需要事先構建好服務端的網絡屬性struct sockaddr_in server; // 定義出struct sockaddr_in的變量memset(&server, 0, sizeof(server)); // 清零server.sin_family = AF_INET; // 地址類型字段的填寫server.sin_port = htons(serverport); // PORT字段的填寫server.sin_addr.s_addr = inet_addr(serverip.c_str()); // IP字段的填寫std::string message; // 存放用戶輸入的信息// 3. 直接通信即可while (true){std::cout << "Please Enter# "; // 提示用戶可以輸入你想向服務端發送的信息了std::getline(std::cin, message); // 獲取到用戶輸入的信息 cin到message中// 發送信息sendto(sockfd, message.c_str(), message.size(), 0, (struct sockaddr *)&server, sizeof(server));// 構建出接收服務端的網絡屬性結構體struct sockaddr_in peer;socklen_t len = sizeof(peer);char buffer[1024];// 接收信息ssize_t n = recvfrom(sockfd, buffer, sizeof(buffer) - 1, 0, (struct sockaddr *)&peer, &len);// 接收成功if (n > 0){buffer[n] = 0; // 添加字符串終止符std::cout << "server echo# " << buffer << std::endl; // 打印服務器回復的信息}}return 0;
}解釋:客戶端代碼與echo程序一模一樣,不再贅述
六:日志文件(Log.hpp)
#pragma once#include <iostream> //C++必備頭文件
#include <cstdio> //snprintf
#include <string> //std::string
#include <ctime> //time
#include <cstdarg> //va_接口
#include <sys/types.h> //getpid
#include <unistd.h> //getpid
#include <thread> //鎖
#include <mutex> //鎖
#include <fstream> //C++的文件操作std::mutex g_mutex; // 定義全局互斥鎖
bool gIsSave = false; // 定義一個bool類型 用來判斷打印到屏幕還是保存到文件
const std::string logname = "log.txt"; // 保存日志信息的文件名字// 日志等級
enum Level
{DEBUG = 0,INFO,WARNING,ERROR,FATAL
};// 將日志寫進文件的函數
void SaveFile(const std::string &filename, const std::string &message)
{std::ofstream out(filename, std::ios::app);if (!out.is_open()){return;}out << message << std::endl;out.close();
}// 日志等級轉字符串--->字符串才能表示等級的意義 0123意義不清晰
std::string LevelToString(int level)
{switch (level){case DEBUG:return "Debug";case INFO:return "Info";case WARNING:return "Warning";case ERROR:return "Error";case FATAL:return "Fatal";default:return "Unknown";}
}// 獲取當前時間的字符串
// 時間格式包含多個字符 所以干脆糅合成一個字符串
std::string GetTimeString()
{// 獲取當前時間的時間戳(從1970-01-01 00:00:00開始的秒數)time_t curr_time = time(nullptr);// 將時間戳轉換為本地時間的tm結構體// tm結構體包含年、月、日、時、分、秒等字段struct tm *format_time = localtime(&curr_time);// 檢查時間轉換是否成功if (format_time == nullptr)return "None";// 緩沖區用于存儲格式化后的時間字符串char time_buffer[1024];// 格式化時間字符串:年-月-日 時:分:秒snprintf(time_buffer, sizeof(time_buffer), "%d-%02d-%02d %02d:%02d:%02d",format_time->tm_year + 1900, // tm_year: 從1900年開始的年數,需要加1900format_time->tm_mon + 1, // tm_mon: 月份范圍0-11,需要加1得到實際月份format_time->tm_mday, // tm_mday: 月中的日期(1-31)format_time->tm_hour, // tm_hour: 小時(0-23)format_time->tm_min, // tm_min: 分鐘(0-59)format_time->tm_sec); // tm_sec: 秒(0-60,60表示閏秒)return time_buffer; // 返回格式化后的時間字符串
}// 日志函數-->打印出日志
// 格式:時間 + 等級 + PID + 文件名 + 代碼行數 + 可變參數
void LogMessage(int level, std::string filename, int line, bool issave, const char *format, ...)
{std::string levelstr = LevelToString(level); // 得到等級字符串std::string timestr = GetTimeString(); // 得到時間字符串pid_t selfid = getpid(); // 得到PID// 使用va_接口+vsnprintf得到用戶想要的可變參數的字符串 存儲與buffer中char buffer[1024];va_list arg;va_start(arg, format);vsnprintf(buffer, sizeof(buffer), format, arg);va_end(arg);std::lock_guard<std::mutex> lock(g_mutex); // 引入C++的RAII的鎖 保護打印功能// 保存格式為時間 + 等級 + PID + 文件名 + 代碼行數 + 可變參數 的日志信息 到message中std::string message = "[" + timestr + "]" + "[" + levelstr + "]" +"[" + std::to_string(selfid) + "]" +"[" + filename + "]" + "[" + std::to_string(line) + "] " + buffer;// 打印到屏幕if (!issave){std::cout << message << std::endl;}// 保存進文件else{SaveFile(logname, message);}
}// 宏定義 省略掉__FILE__ 和 __LINE__
#define LOG(level, format, ...) \do \{ \LogMessage(level, __FILE__, __LINE__, gIsSave, format, ##__VA_ARGS__); \} while (0)// 用戶調用則意味著保存到文件
#define EnableScreen() (gIsSave = false)// 用戶調用則意味著打印到屏幕
#define EnableFile() (gIsSave = true)解釋:日志博客:https://blog.csdn.net/shylyly_/article/details/151263351
七:makefile
.PHONY:all
all:udpserver udpclientudpserver:Main.ccg++ -o $@ $^ -std=c++14
udpclient:UdpClient.ccg++ -o $@ $^ -std=c++14
.PHONY:clean
clean:rm -f udpserver udpclient八:運行效果
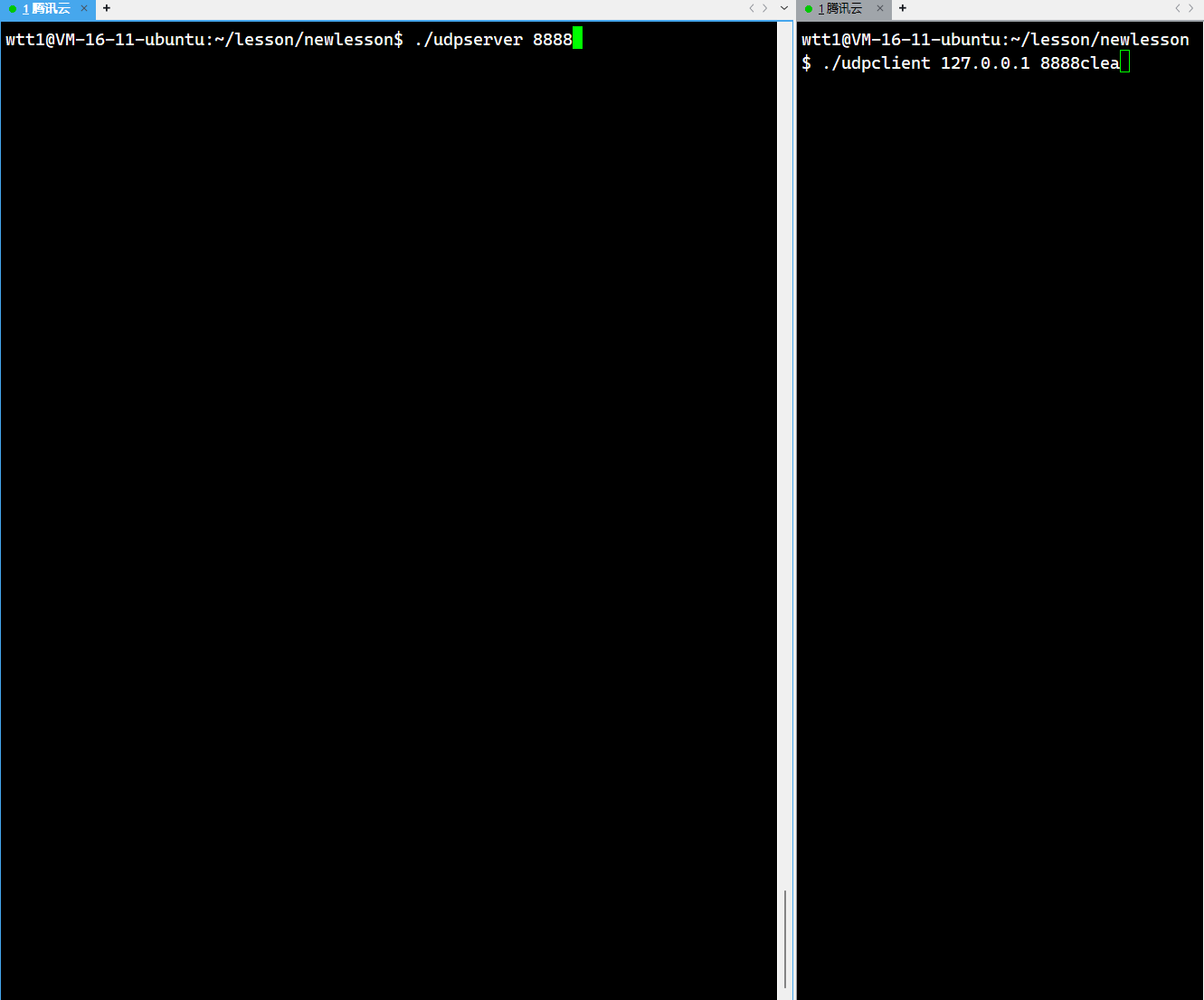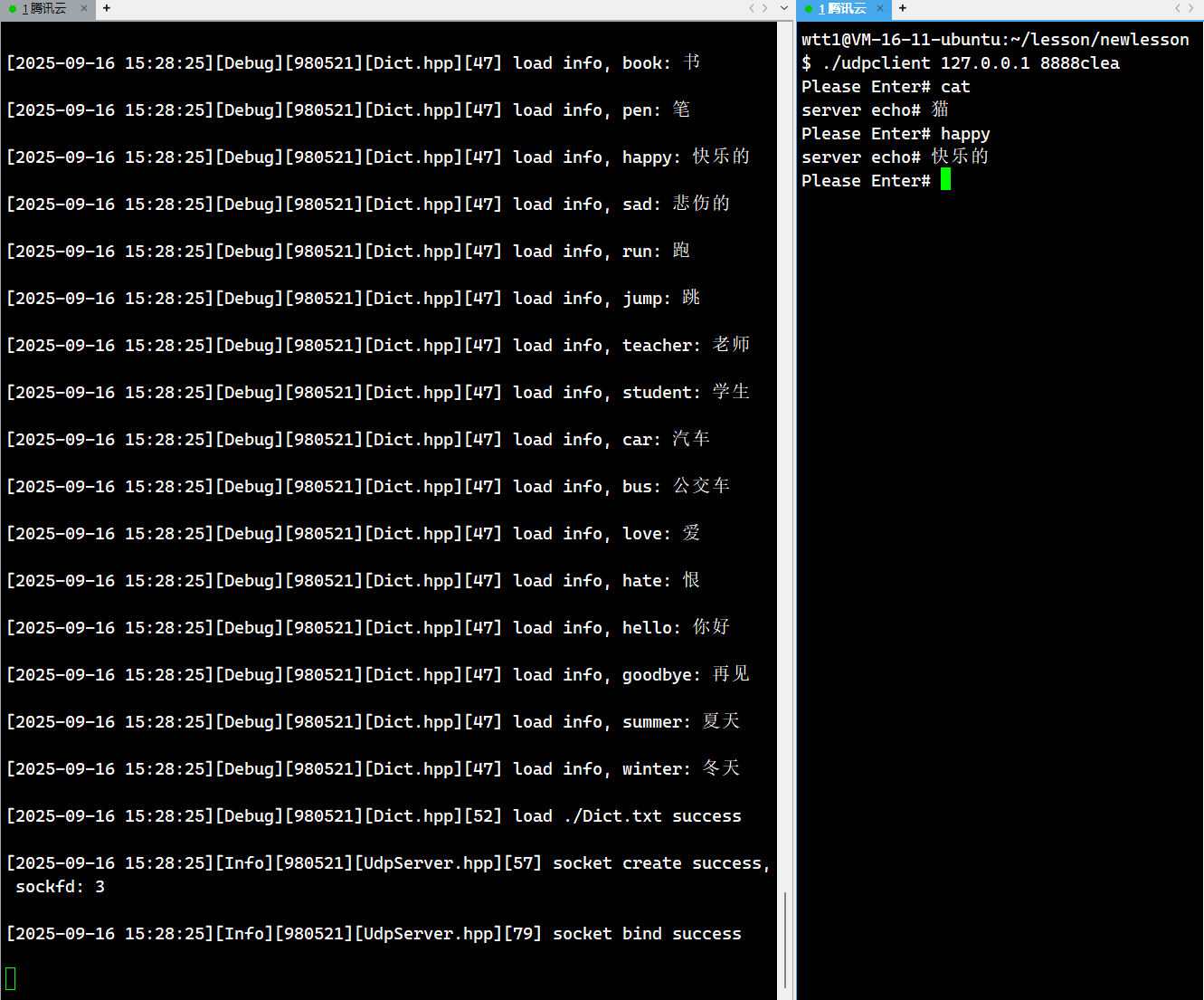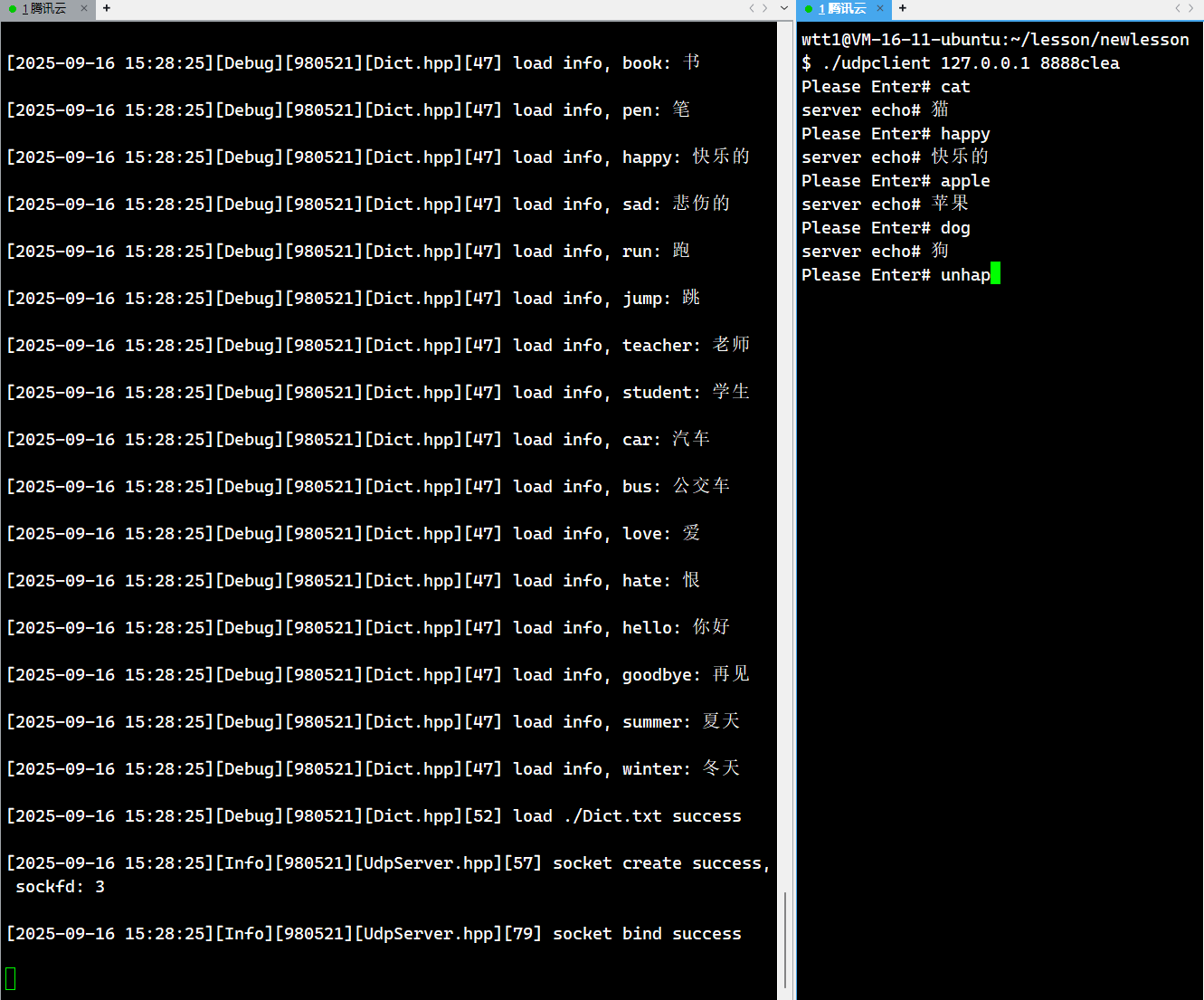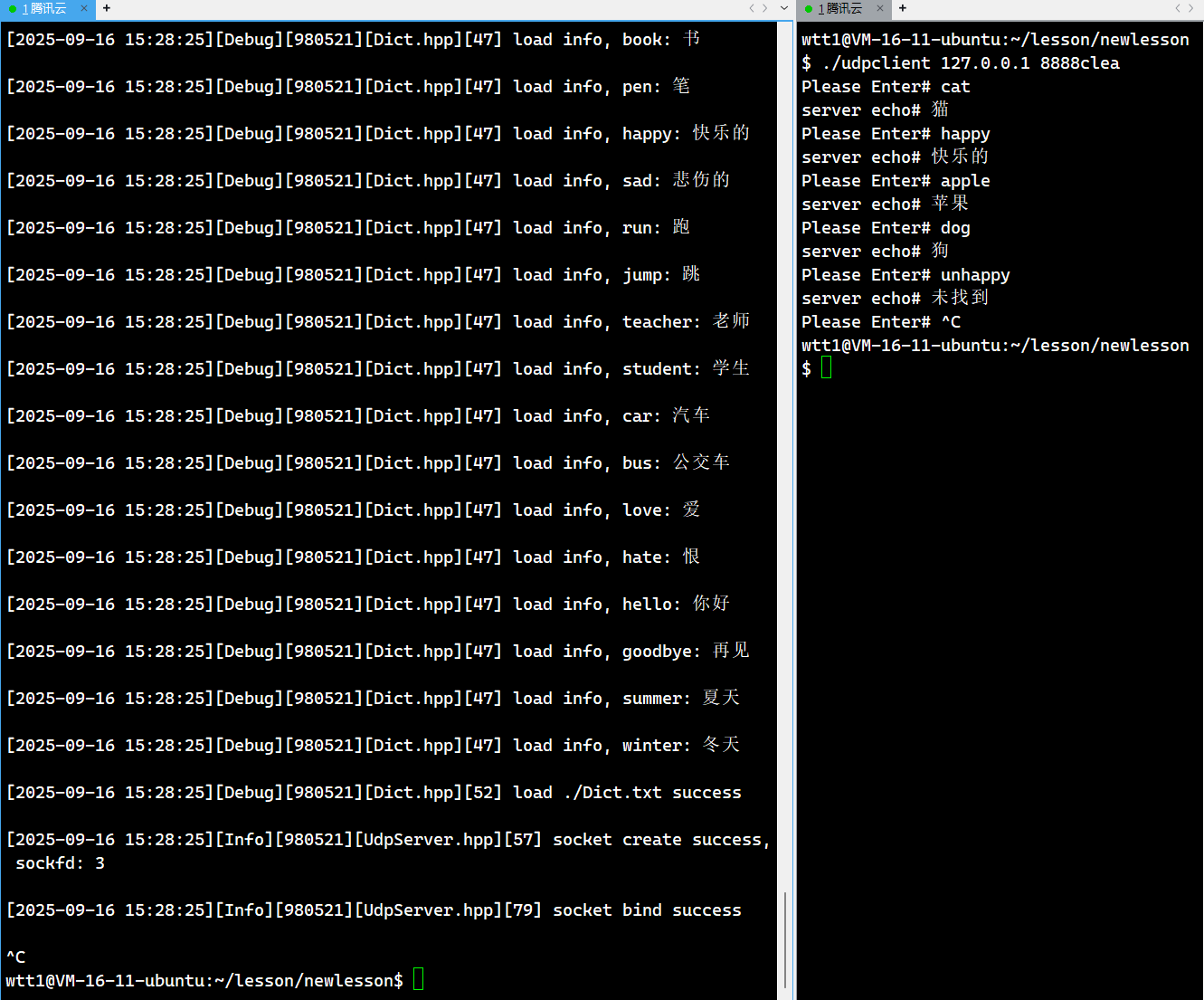
解釋:
當我們運行服務端的時候,因為我們添加了日志,所以每次我們插入到哈希表中的單詞中文,都會被打印出來,而在右側客戶端,我們就實現了翻譯的功能
最后我也準備一份更全面的常用單詞文件:
apple: 蘋果
banana: 香蕉
cat: 貓
dog: 狗
book: 書
pen: 筆
happy: 快樂的
sad: 悲傷的
run: 跑
jump: 跳
teacher: 老師
student: 學生
car: 汽車
bus: 公交車
love: 愛
hate: 恨
hello: 你好
goodbye: 再見
summer: 夏天
winter: 冬天
water: 水
food: 食物
house: 房子
home: 家
family: 家庭
friend: 朋友
money: 錢
time: 時間
work: 工作
school: 學校
one: 一
two: 二
three: 三
four: 四
five: 五
six: 六
seven: 七
eight: 八
nine: 九
ten: 十
red: 紅色
blue: 藍色
green: 綠色
yellow: 黃色
black: 黑色
white: 白色
orange: 橙色
purple: 紫色
pink: 粉色
brown: 棕色
rice: 米飯
noodle: 面條
bread: 面包
meat: 肉
fish: 魚
chicken: 雞肉
egg: 雞蛋
milk: 牛奶
tea: 茶
coffee: 咖啡
tiger: 老虎
lion: 獅子
elephant: 大象
monkey: 猴子
bird: 鳥
horse: 馬
cow: 牛
sheep: 羊
pig: 豬
sun: 太陽
moon: 月亮
star: 星星
rain: 雨
snow: 雪
wind: 風
cloud: 云
weather: 天氣
hot: 熱的
cold: 冷的
head: 頭
eye: 眼睛
ear: 耳朵
nose: 鼻子
mouth: 嘴巴
hand: 手
foot: 腳
heart: 心臟
blood: 血液
bone: 骨頭
doctor: 醫生
nurse: 護士
engineer: 工程師
driver: 司機
cook: 廚師
farmer: 農民
worker: 工人
manager: 經理
artist: 藝術家
singer: 歌手
angry: 生氣的
excited: 興奮的
tired: 疲倦的
scared: 害怕的
surprised: 驚訝的
calm: 平靜的
nervous: 緊張的
proud: 自豪的
shy: 害羞的
curious: 好奇的
walk: 走路
sit: 坐
stand: 站
sleep: 睡覺
eat: 吃
drink: 喝
read: 閱讀
write: 寫
speak: 說話
listen: 聽
day: 天
night: 夜晚
morning: 早上
afternoon: 下午
evening: 晚上
week: 周
month: 月
year: 年
today: 今天
tomorrow: 明天
city: 城市
country: 國家
park: 公園
hospital: 醫院
restaurant: 餐廳
hotel: 酒店
store: 商店
bank: 銀行
station: 車站
airport: 機場
study: 學習
knowledge: 知識
exam: 考試
question: 問題
answer: 答案
class: 班級
lesson: 課程
homework: 作業
test: 測試
degree: 學位
computer: 電腦
phone: 電話
internet: 互聯網
music: 音樂
movie: 電影
game: 游戲
sport: 運動
ball: 球
dance: 舞蹈
photo: 照片
father: 父親
mother: 母親
son: 兒子
daughter: 女兒
brother: 兄弟
sister: 姐妹
grandfather: 祖父
grandmother: 祖母
uncle: 叔叔
aunt: 阿姨
big: 大的
small: 小的
tall: 高的
short: 矮的
long: 長的
new: 新的
old: 舊的
young: 年輕的
beautiful: 美麗的
ugly: 丑陋的
rich: 富有的
poor: 貧窮的
strong: 強壯的
weak: 虛弱的
fast: 快的
slow: 慢的
easy: 容易的
difficult: 困難的
right: 正確的
wrong: 錯誤的
true: 真實的
false: 虛假的
open: 打開
close: 關閉
start: 開始
stop: 停止
buy: 買
sell: 賣
give: 給
take: 拿
help: 幫助
wait: 等待
play: 玩
sing: 唱歌
dance: 跳舞
swim: 游泳
fly: 飛
travel: 旅行
meet: 見面
think: 思考
know: 知道
understand: 理解
remember: 記住
forget: 忘記
live: 生活
die: 死亡
birth: 出生
growth: 成長
change: 改變
stay: 停留
leave: 離開
arrive: 到達
depart: 出發
win: 贏
lose: 輸
success: 成功
failure: 失敗
hope: 希望
dream: 夢想
plan: 計劃
goal: 目標
problem: 問題
solution: 解決方案
reason: 原因
result: 結果
cause: 導致
effect: 影響解釋:彩色是因為是關鍵字




)


)
-部署和使用指南)










