?1. 實例編譯????????????????運行
main.cu
//nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main#include <iostream>
#include <thrust/device_vector.h>/*
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16};
*/__device__
void ldmatrix_x2(unsigned int (&x)[2], const void* ptr){ asm volatile("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];" : "=r"(x[0]), "=r"(x[1]): "l"(__cvta_generic_to_shared(ptr)));
}__global__
void mykernel(const int* loadOffsets, bool print){alignas(16) __shared__ half A[128 * 16];for(int i = threadIdx.x; i < 128*16; i += blockDim.x){A[i] = i;}__syncthreads();const int lane = threadIdx.x % 32;unsigned int result[2];const int offset = loadOffsets[lane];ldmatrix_x2(result, &A[offset]);half2 loaded[2];memcpy(&loaded[0], &result[0], sizeof(half2) * 2);if(print){for(int m = 0; m < 2; m++){for(int t = 0; t < 32; t++){if(lane == t){printf("%4d %4d ", int(loaded[m].x), int(loaded[m].y));if(lane % 4 == 3){printf("\n");}}__syncwarp();}if(lane == 0){printf("\n");}__syncwarp();}}
}int main(){thrust::device_vector<int> d_loadOffsets(32, 0);for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = row * 16 + matrix * 8;}mykernel<<<1,32>>>(d_loadOffsets.data().get(), true);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 33.393, Bank Conflicts 0for(int i = 0; i < 16; i++){const int row = i / 2;const int matrix = i % 2;d_loadOffsets[i] = row * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 131.674, Bank Conflicts 98.304for(int i = 0; i < 16; i++){const int row = i / 2;const int matrix = i % 2;d_loadOffsets[i] = (4*row) * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 66.488, Bank Conflicts 32.768for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = row * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();// Shared Load Matrix: Requests 16.384, Wavefronts 263.070, Bank Conflicts 229.376for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = (4*row) * 16 + matrix * 8;}std::cout << "offsets: ";for(int i = 0; i < 16; i++){std::cout << d_loadOffsets[i] << " ";}std::cout << "\n";mykernel<<<1024,512>>>(d_loadOffsets.data().get(), false);cudaDeviceSynchronize();
}編譯運行:
nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main或者 device 代碼 debug版:
$ nvcc -g -G -std=c++17 -arch=native main.cu -o main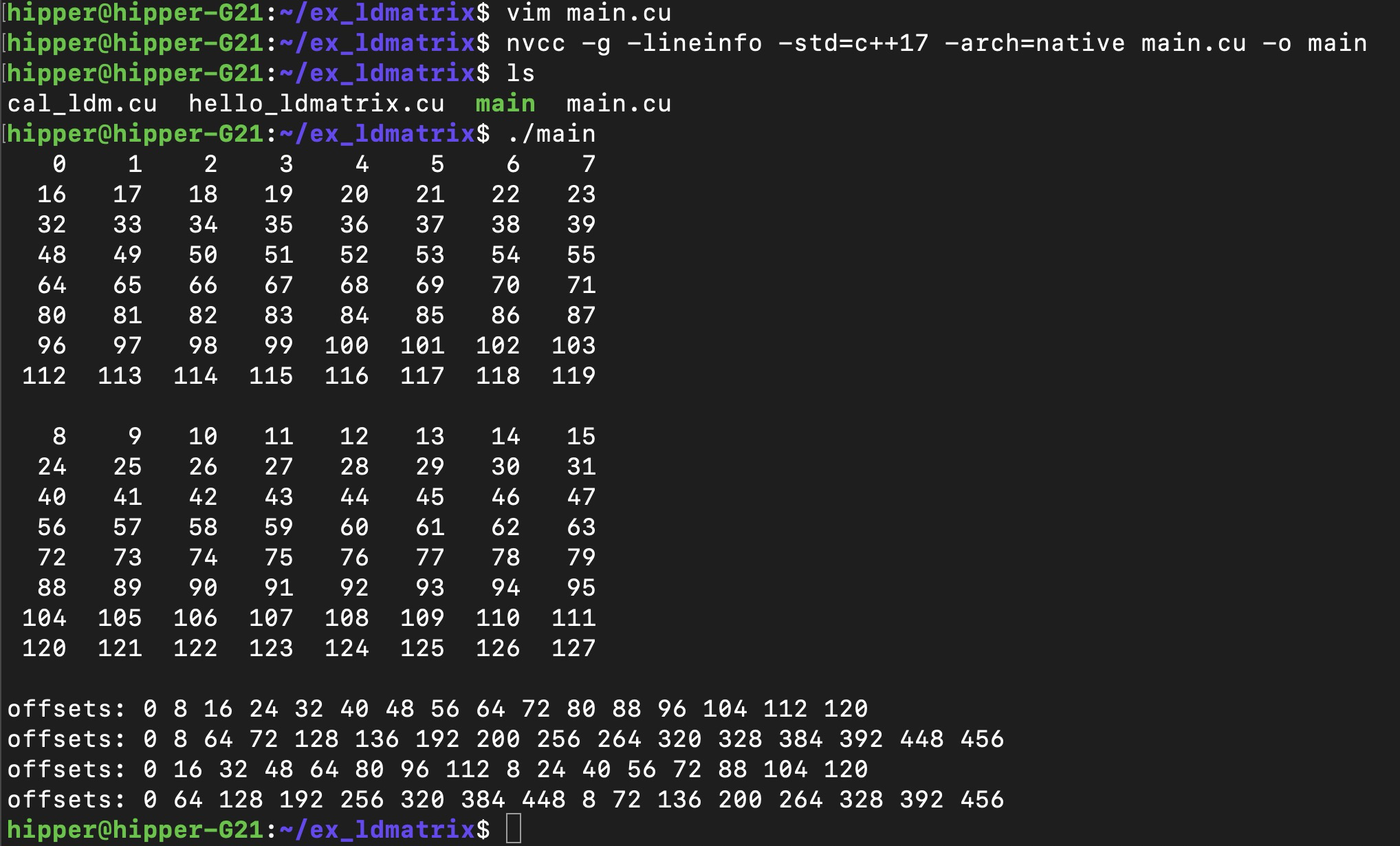
修改程序后,
//nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main#include <iostream>
#include <thrust/device_vector.h>/*
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16};
*/__device__
void ldmatrix_x2(unsigned int (&x)[2], const void* ptr){asm volatile("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];": "=r"(x[0]), "=r"(x[1]): "l"(__cvta_generic_to_shared(ptr)));
}__global__
void mykernel(const int* loadOffsets, bool print){alignas(16) __shared__ half A[128 * 16];for(int i = threadIdx.x; i < 128*16; i += blockDim.x){A[i] = i;}__syncthreads();const int lane = threadIdx.x % 32;unsigned int result[2];//one int, 2 half mem spaceconst int offset = loadOffsets[lane];ldmatrix_x2(result, &A[offset]);half2 loaded[2];memcpy(&loaded[0], &result[0], sizeof(half2) * 2);if(print){for(int m = 0; m < 2; m++){for(int t = 0; t < 32; t++){//if(lane == t){if(lane == t){printf("[%2d]%4d %4d ",lane, int(loaded[m].x), int(loaded[m].y));if(lane % 4 == 3){printf("\n");}}__syncwarp();}if(lane == 0){printf("\n");}__syncwarp();}}
}int main(){thrust::device_vector<int> d_loadOffsets(32, 0);for(int i = 0; i < 16; i++){const int row = i % 8;const int matrix = i / 8;d_loadOffsets[i] = row * 16 + matrix * 8;printf("%d ", row*16 + matrix*8);}
printf("\n\n");//thrust::host_vector<int> h_loadOffsets(32, 0);
int * hld = nullptr;
hld = (int*)malloc(32*sizeof(int));
cudaMemcpy(hld, d_loadOffsets.data().get(), sizeof(int)*32, cudaMemcpyDeviceToHost);for(int i=0; i<32; i++)printf("%d, ", hld[i]);
printf("\n");mykernel<<<1,32>>>(d_loadOffsets.data().get(), true);cudaDeviceSynchronize();}
同上編譯方式,輸出:
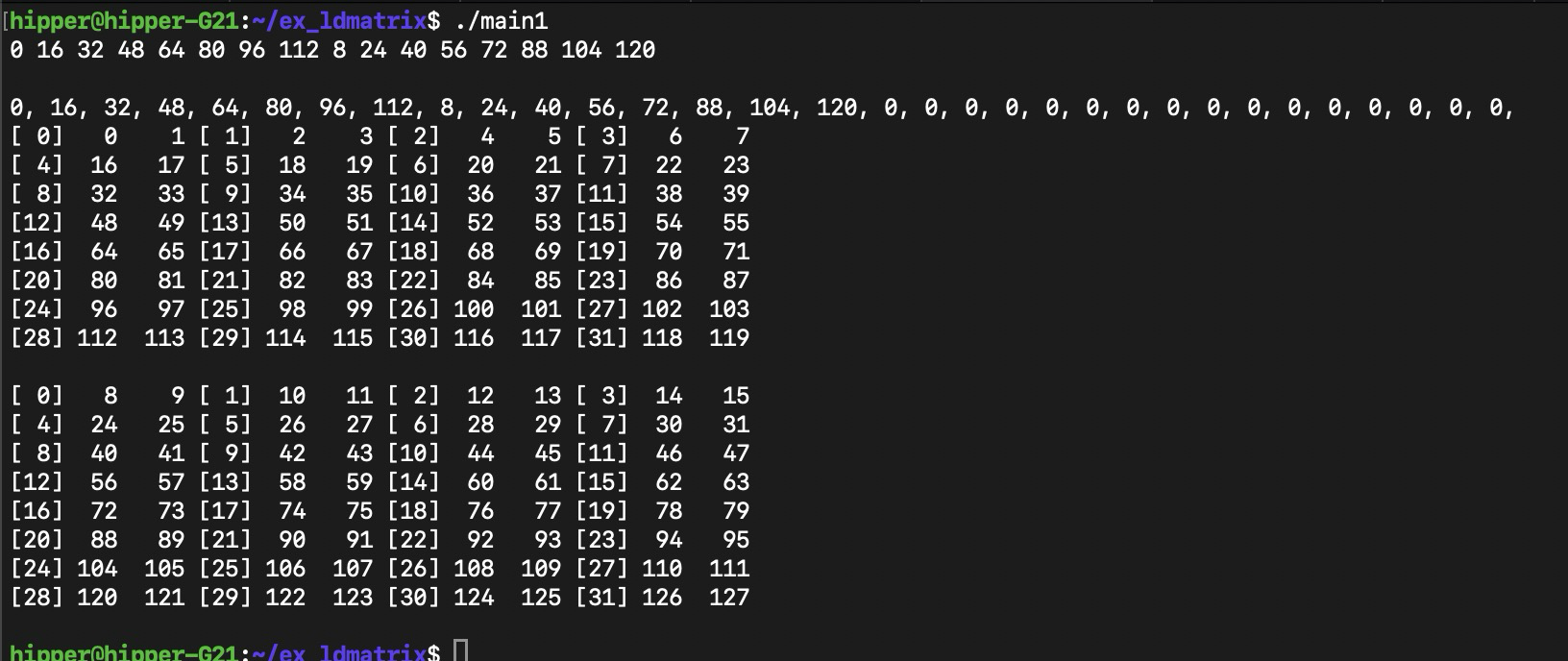
比較容易發現搬運數據映射關系
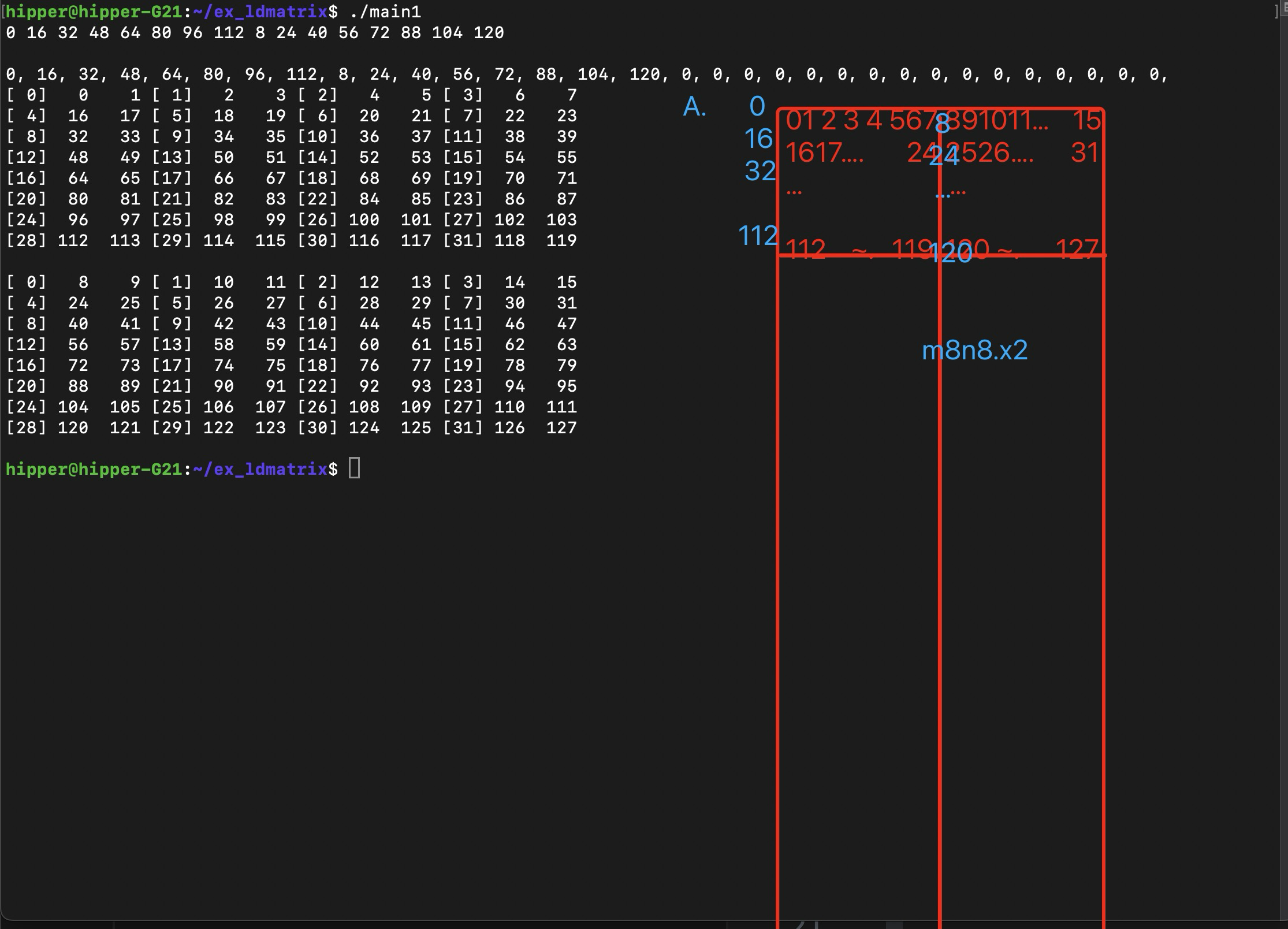
這里我們先猜一下其數據關系,
? ? ? ? 首先,矩陣以m8n8為一個小矩陣加載進warp 的 32個 lane中,每個lane 從這個小矩陣中拿到兩個地址連續的變量;x2,是說一次 load 兩個8x8小矩陣,這樣的話,每個lane 會得到4個變量;x4的話,就是4*2=8個變量。
? ? ? ? 每個小矩陣需要提供8個行的起始地址,第一個小矩陣的8個行起始地址填寫在0~7號 lane 的寄存器中;第二個小矩陣的8個行起始地址填寫在 8~15號lane的寄存器中,各個lane中同名寄存器作為 ldmatrix 的參數。即,代碼中的 const void* ptr 。
? ? ? ? 可以推得,如果是x4,4個8x8 的小矩陣,那么需要提供4組8個行的起始地址,這樣,32個 lane 每個都持有一個小矩陣的行起始地址。
? ? ? ? 第二節第三節再深入系統地分析。
2. 實例功能解析
? ? ? ? 進一步詳細解析這個執行了?ldmatrix?的 CUDA Device 函數,這是一個非常經典且高效的用法。
2.1. 函數簽名解析
__device__ void ldmatrix_x2(unsigned int (&x)[2], const void* ptr)__device__
????????????????cuda 語法,聲明這是一個在 GPU 上執行的函數。
unsigned int (&x)[2]
????????????????這是一個對包含 2 個?unsigned int?的數組的引用,C++ 語法。使用引用 (&) 允許函數直接修改調用者傳入的數組元素,避免了傳值拷貝。這個數組的兩個元素?x[0]?和?x[1]?將被用作內聯匯編中的目標寄存器。
const void* ptr
????????????????這是一個指向共享內存中某個數據的通用指針(generic)。const?表示函數不會通過這個指針修改數據,void*?提供了靈活性,可以指向任何類型的數據。
2.2. 內聯匯編詳解
asm volatile("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];": "=r"(x[0]), "=r"(x[1]) // Output operands: "l"(__cvta_generic_to_shared(ptr))); // Input operandptx ISA ldmatrix spec
我們一點一點地分解:
2.2.1. 匯編模板字符串
("ldmatrix.sync.aligned.m8n8.x2.shared.b16 {%0, %1}, [%2];")
這是要執行的 PTX 指令。
? ? ldmatrix: 指令本身,用來加載矩陣。
? ? .sync: Warp 級同步指令,確保 Warp 內所有活躍線程協同執行。
? ? .aligned:?強制要求源內存地址 (ptr) 必須是 16 字節對齊的。
? ? .m8n8: 指定從內存中加載的數據布局對應于一個?8 行 x 8 列的矩陣。這個形狀的矩陣數據元素只能是 16bit的。還可以有 .m16n16、.m8n16,這是對應 8bit/6bit/4bit 矩陣元素。
? ? .x2: 指定一次執行 ldmatrix 時,加載 2? 個 m8n8 的小矩陣。
? ? ? ? ? ? ? ? ? The values?.x1,?.x2?and?.x4?for?.num?indicate one, two or four matrices respectively. When?.shape?is?.m16n16, only?.x1?and?.x2?are valid values for?.num.
? ? .shared: 明確指定源數據位于共享內存(Shared Memory)?中。
? ? .b16: 指定內存訪問模式。.b16?表示這是一次 16 字節的訪問。這與共享內存的 bank 寬度和高效訪問模式有關。
? ? {%0, %1}: 這是目標操作數列表。占位符?%0?和?%1?將會被編譯器替換為后面約束列表中找到的實際寄存器。這里它要求?2 個?32 位的寄存器。
? ? ? ? ? ?? ? ?為什么是 2 個??一個 8x8 的矩陣,每個元素 2 字節,總大小為?8 * 8 * 2 = 128?字節。一個 Warp 有 32 個線程。ldmatrix?指令將這 128 字節的數據轉置后,分布到整個 Warp 的線程寄存器中。每個線程負責?128/32 = 4?字節的數據。一個 32 位寄存器是 4 字節,所以每個線程需要 1 個寄存器來存儲它的那部分數據。那么為什么這里列表里有 2 個?實際上,這條指令是在加載2個這樣的 8x8 矩陣。這里的關鍵在于指令的變體。在 SM_70+ 上,ldmatrix?可以加載 1、2 或 4 個矩陣。
? ? [%2]: 這是源操作數。它是一個包含共享內存地址的寄存器,地址為16bit aligned。%2?將被替換為輸入操作數提供的值。
2.2.2. 輸出操作數
(: "=r"(x[0]), "=r"(x[1]))
? ? "=r": 約束修飾符。
? ? ? =?表示這是一個只寫的輸出操作數。
? ? ? r?register 之意,表示要求編譯器分配一個32 位通用寄存器來保存這個值。
? ? (x[0]), (x[1]): 對應的 C++ 變量。指令執行后,目標寄存器?%0?和?%1?中的值會被寫回到數組?x?的這兩個元素中。
? ? ? ? ? 作用:告訴編譯器:“請為?x[0]?和?x[1]?分配兩個寄存器。執行匯編指令后,結果將在這兩個寄存器中,請將它們寫回?x[0]?和?x[1]。”
2.2.3. 輸入操作數
(: "l"(__cvta_generic_to_shared(ptr)))
這是最精妙和關鍵的部分。
? __cvta_generic_to_shared(ptr): 這是一個 CUDA 內部函數。
? ? ? ? ? ? 作用:它將一個通用指針?(ptr) 轉換為其對應的共享內存空間下的地址值。
? ? ? ? ? ? 原理:在 PTX 中,不同的內存空間(全局、共享、本地等)有獨立的地址空間。一個通用(generic)的?void*?指針不能直接用于?ldmatrix?的?shared?操作。這個函數執行必要的位操作,提取出專用于共享內存地址空間的地址比特位。
? "l": 這是一個約束修飾符。
? ? ? ? ? ? l?location register 之意。表示一個 32 位的專用寄存器,通常用于存儲地址**。這與通用寄存器?r?略有不同,編譯器知道這個寄存器將用于尋址。
? ? 作用:告訴編譯器:“計算?__cvta_generic_to_shared(ptr)?這個表達式的值,并將其放入一個專用的地址寄存器中,然后在匯編模板中用?%2?來引用這個寄存器。”
2.2.4.?volatile?關鍵字
? ? 防止編譯器優化掉這條匯編指令(例如,因為它看起來沒有使用輸出?x),或者將其移出循環。確保指令嚴格按照代碼中的位置和執行次數運行。
2.3. 函數功能總結
這個?ldmatrix_x2?函數的功能是:
? ? ? ? 讓一個 Warp(32 個線程)協同工作,從共享內存中?ptr?所指的、16 字節對齊的地址開始,加載 2 個連續的 8x8 矩陣(每個元素 2 字節)。數據在加載過程中會被重新排列(轉置)。加載完成后,每個線程會獲得 8 字節(2 個?unsigned int)的數據,存儲在其?x[0]?和?x[1]?中。
? ? ? ? 這些數據通常是更大矩陣乘法操作中的一個小塊(Tile)。每個線程持有的?x[0]?和?x[1]?是轉置后矩陣的一小部分,它們的形式非常適合直接作為輸入喂給后續的?mma(矩陣乘加)指令,從而實現極其高效的矩陣計算。
注意事項:
-
調用約定:這個函數必須由整個 Warp?的線程同時調用,且?
ptr?的值在 Warp 內必須一致(通常是通過廣播獲得)。 -
對齊:
ptr?必須是 16 字節對齊的,否則行為未定義。 -
數據布局:共享內存中的數據必須按照?
ldmatrix?指令所期望的布局進行排列,這通常由之前的數據存儲步驟(例如使用?st.shared.v2.b32?之類的指令)來保證。
這個函數是手動優化 CUDA 核函數、充分發揮 Tensor Core 性能的典型代表。
3. ldmatrix 功能系統解析
? ? CUDA PTX 中的?ldmatrix?指令是高效利用 Tensor Cores(張量核心)進行矩陣計算的關鍵所在。接著前面的具體實例,這里更為系統第介紹一下 ldmatrix 指令的原理用法。
3.1. 指令概述與原理
目的
? ? ldmatrix(Load Matrix)指令用于從一個線程束(Warp)內線程協同訪問的連續共享內存區域中,高效地加載一個小的、密集的矩陣塊(如 8x8),并將其轉置后分布到該 Warp 中多個線程的寄存器中。
核心思想
? ? ? ? Tensor Cores 執行的是?D = A * B + C?操作,其中 A、B、C、D 都是小矩陣。然而,全局內存或共享內存中的數據通常按行主序或列主序存儲。ldmatrix?指令在數據從共享內存加載到寄存器的過程中,巧妙地完成了數據重排(轉置),使得數據在寄存器中的布局恰好符合 Tensor Cores 所期望的輸入格式,從而避免了顯式的轉置操作,極大提升了效率。
工作原理
? ? ? ? 一個 Warp(32 個線程)共同協作,從共享內存中讀取一片連續的數據。每個線程負責讀取數據的一部分。指令會自動地將這些數據重新組織(轉置),并存入指定線程的指定寄存器。最終,整個 Warp 的寄存器合在一起,就構成了一個完整的、經過轉置的矩陣。
3.2. 指令語法格式
完整的 PTX 語法如下:
ldmatrix.sync.aligned.{num}{.trans}{.ss}.type [rd1, rd2, ...], [rs1, rs2];
// 或者更常見的格式,指定矩陣形狀:
ldmatrix.sync.aligned.shape.{num}{.trans}{.ss}.rspace [rd1, rd2, ...], [rs];3.3. 指令中各域詳解
.sync?(Synchronization)
? ? ? ? 作用
? ? ? ? ? ? ? ? 指定這是一個Warp-level 同步指令。指令的執行會涉及 Warp 中所有活躍線程的協同操作。.sync?后綴確保所有線程在邏輯上同時參與此次加載。
? ? ? ? 可選值
? ? ? ? ? ? ? ? 在較新的架構中,可以指定?.sync.syncid?以實現更細粒度的同步,但通常直接使用?.sync。
.aligned?(Alignment)
? ? ? ? 作用
? ? ? ? ? ? ? ? 指定共享內存的源地址必須是 16 字節對齊的。這是為了滿足內存子系統的高效訪問要求。如果地址未對齊,執行結果將是未定義的。
? ? ? ? 注意
? ? ? ? ? ? ? ? 這是一個強制要求,不是可選項。你必須確保傳入的共享內存指針是 16 字節對齊的。
.{num}?(Number of Matrices)
? ? ? ? 作用
? ? ? ? ? ? ? ? 指定一次指令調用要加載的矩陣數量。
? ? ? ? 可選值
? ? ? ? ? ? ? ? .1:加載 1 個矩陣;
? ? ? ? ? ? ? ? .2:加載 2 個矩陣;.4:加載 4 個矩陣;
? ? ? ? 影響
? ? ? ? ? ? ? ? 加載的矩陣數量直接決定了目標寄存器的數量。例如,加載一個 8x8x16 的矩陣(.m8n8?+?.x2)需要 4 個寄存器(8*8*2/32/1?更正:通常加載 1 個?.m8n8.x4?矩陣需要 8 個寄存器)。加載?.4?個矩陣就需要 4 倍數量的寄存器。
.{trans}?(Transposition)
? ? ? ? 作用
? ? ? ? ? ? ? ? 指定是否對加載的矩陣進行轉置。
? ? ? ? 可選值
? ? ? ? ? ? ? ? (空):不進行轉置,按原樣加載;
? ? ? ? ? ? ? ? .trans:對加載的矩陣進行轉置;
? ? ? ? 這是關鍵
? ? ? ? ? ? ? ? 這個功能是為了適配 Tensor Cores 的輸入。例如,在計算 A * B 時,可能需要將 B 矩陣轉置后再輸入給 Tensor Core。使用?.trans?可以在加載時一步完成,無需后續單獨的轉置指令。
.{ss}?(Element Size / Storage Spacing)
? ? ? ? 作用
? ? ? ? ? ? ? ? 指定源數據中每個矩陣元素的大小和存儲間隔。
? ? ? ? 可選值
? ? ? ? ? ? ? ? .x1:8 位元素(如?char,?uint8_t);.x2:16 位元素(如?half,?__half,?short)。這是用于 FP16 張量計算最常見的大小;
? ? ? ? ? ? ? ? .x4:32 位元素(如?float,?int);
.{type}?/?.{rspace}?(Type / Resource Space)
? ? ? ? 作用
? ? ? ? ? ? ? ? 指定源數據所在的內存空間。
? ? ? ? 可選值
? ? ? ? ? ? ? ? .shared:源數據位于共享內存中。這是?ldmatrix?最常用、最主要的使用場景;
? ? ? ? ? ? ? ? .global:源數據位于全局內存中。(在某些架構上支持,但不如從共享內存加載高效);
.[rd1, rd2, ...]?(Destination Registers)
? ? ? ? 作用
? ? ? ? ? ? ? ? 目標操作數,是一個寄存器列表,用于接收加載來的矩陣數據。
? ? ? ? 要求
? ? ? ? ? ? ? ? 寄存器的數量取決于?{num},?{ss}?和矩陣形狀。例如,加載?1?個?8x8?的矩陣(.m8n8),每個元素是?32位(.x4),則需要?(8 * 8 * 4) / 32 = 8?個 32 位寄存器;
? ? ? ? ? ? ? ? 寄存器必須是?32 位寬的(例如?%r0,?%f1);
? ? ? ? ? ? ? ? 列表中的寄存器必須是連續的;
.[rs1, rs2]?/?[rs]?(Source Address)
? ? ? ? 作用
? ? ? ? ? ? ? ? 源操作數,是包含共享內存地址的寄存器。
? ? ? ? 要求
? ? ? ? ? ? ? ? 通常是一個包含 32 位地址的寄存器(例如?%r0);
? ? ? ? ? ? ? ? 該地址必須指向共享內存,并且必須是?16 字節對齊的(由?.aligned?保證);
.{shape}?(Matrix Shape - 替代方案)
? ? ? ? 作用
? ? ? ? ? ? ? ? 另一種語法是明確指定矩陣的形狀,這通常更直觀。
? ? ? ? 可選值
? ? ? ? .m8n8:加載一個 8x8 的矩陣。這是最常用的形狀;
? ? ? ? .m8n8k4?等:用于更復雜的加載模式,但?.m8n8?是基礎;
3.4. 用法示例與解釋
? ? ? ? 假設我們要從共享內存加載一個?8x8 的 FP16 矩陣,并對其進行轉置,然后分布到寄存器中。
PTX 代碼:
ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {%0, %1, %2, %3}, [%4];分解:
? ? ? ? .sync.aligned:Warp 同步且地址對齊;
? ? ? ? .m8n8:加載 8x8 的矩陣;
? ? ? ? .x2:源元素是 16 位(FP16);
? ? ? ? .trans:加載時進行轉置;
? ? ? ? .shared.b16:從共享內存以 16 字節的訪問模式讀取;
? ? ? ? {%0, %1, %2, %3}:需要?4 個?32 位目標寄存器;
? ? ? ? ? ? ? ? *計算:一個 8x8 FP16 矩陣總大小 = 8 * 8 * 2字節 = 128 字節。一個 Warp 有 32 個線程,每個線程負責 128 / 32 = 4 字節的數據。一個 32 位寄存器正好是 4 字節,所以每個線程需要 1 個寄存器。但為什么這里有 4 個?實際上,ldmatrix?指令的寄存器列表是每個線程持有的寄存器數量?不,更準確的說法是:這條指令為整個 Warp 指定了 4 個連續的寄存器,但每個線程看到的是這些寄存器中的不同部分。通常,加載一個?.m8n8.x2?矩陣需要 4 個目標寄存器。
? ? ? ? [%4]:源地址寄存器,其值是一個 16 字節對齊的共享內存地址;
在 CUDA C++ 中的內聯匯編用法:
__shared__ half smem_buffer[64]; // 8x8 FP16 矩陣asm volatile ("ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {%0, %1, %2, %3}, [%4];": "=r"(reg0), "=r"(reg1), "=r"(reg2), "=r"(reg3) // 4個輸出寄存器: "r"(smem_buffer) // 輸入:共享內存地址// 可能還需要 clobber 列表,但有時可省略
);3.5. 小結
? ? ldmatrix?是一條極其強大的指令,它將數據加載和數據重排(轉置)?兩個耗時的操作合并為一條高效的硬件指令。它的設計完美契合了 Tensor Cores 的工作方式,是實現高性能矩陣乘法(尤其是深度學習推理和訓練)的核心原語之一。理解其各個參數的含義對于在 PTX 或 CUDA 內聯匯編中正確使用它至關重要。
4. 附錄
4.1. 示例的 ptx生成
生成 ptx 文件:
nvcc -ptx -lineinfo -std=c++17 -arch=native main.cu -o main.ptx或者不帶源碼行號
$ nvcc -ptx --gpu-architecture=sm_120 main.cu -o main_sm_120.ptx4.2. m8n8.x4 的示例
//nvcc -g -lineinfo -std=c++17 -arch=native main.cu -o main#include <iostream>
#include <thrust/device_vector.h>/*
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16};
*/__device__
void ldmatrix_x2(unsigned int (&x)[4], const void* ptr){asm volatile("ldmatrix.sync.aligned.m8n8.x4.shared.b16 {%0, %1, %2, %3}, [%4];": "=r"(x[0]), "=r"(x[1]), "=r"(x[2]), "=r"(x[3]): "l"(__cvta_generic_to_shared(ptr)));
}__global__
void mykernel(const int* loadOffsets, bool print){alignas(16) __shared__ half A[128 * 16];for(int i = threadIdx.x; i < 128*16; i += blockDim.x){A[i] = i;}__syncthreads();const int lane = threadIdx.x % 32;unsigned int result[4];//one int, 2 half mem spaceconst int offset = loadOffsets[lane];ldmatrix_x2(result, &A[offset]);half2 loaded[4];memcpy(&loaded[0], &result[0], sizeof(half2) * 4);if(print){for(int m = 0; m < 4; m++){for(int t = 0; t < 32; t++){//if(lane == t){if(lane == t){printf("[%2d]%4d %4d ",lane, int(loaded[m].x), int(loaded[m].y));if(lane % 4 == 3){printf("\n");}}__syncwarp();}if(lane == 0){printf("\n");}__syncwarp();}}
}int main(){thrust::device_vector<int> d_loadOffsets(32, 0);for(int i = 0; i < 32; i++){const int row = i % 8 + (i/16)*8; // row of m8n8const int matrix = (i%16) / 8; // colum of m8n8d_loadOffsets[i] = row * 16 + matrix * 8;printf("%d ", row*16 + matrix*8);}
printf("\n\n");//thrust::host_vector<int> h_loadOffsets(32, 0);
int * hld = nullptr;
hld = (int*)malloc(32*sizeof(int));
cudaMemcpy(hld, d_loadOffsets.data().get(), sizeof(int)*32, cudaMemcpyDeviceToHost);for(int i=0; i<32; i++)printf("%d, ", hld[i]);
printf("\n");mykernel<<<1,32>>>(d_loadOffsets.data().get(), true);cudaDeviceSynchronize();}
運行:
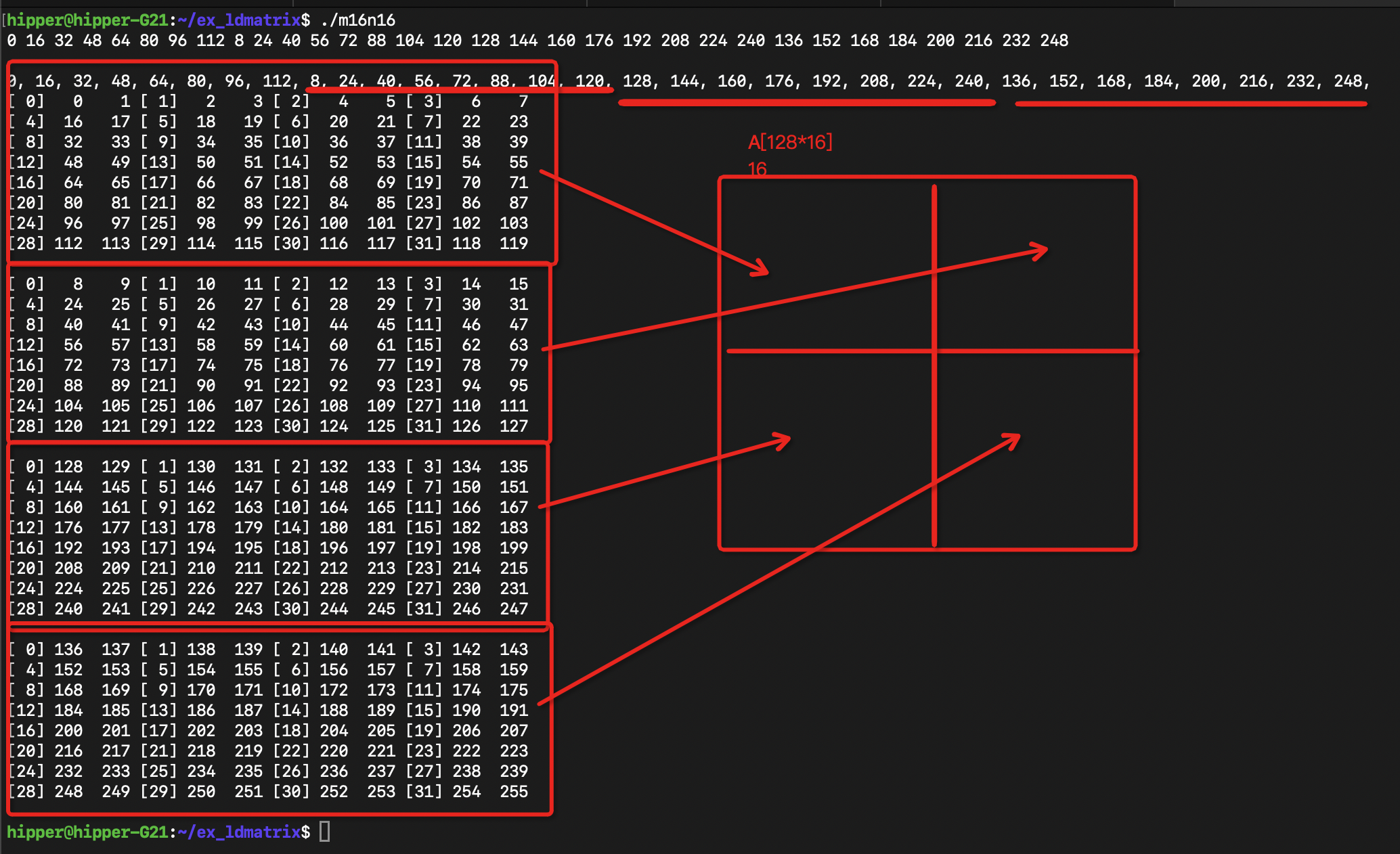





)






![[Dify] 實現“多知識庫切換”功能的最佳實踐](http://pic.xiahunao.cn/[Dify] 實現“多知識庫切換”功能的最佳實踐)
)
)


)

BGP路由 選路規則)