引言
? ? ? ? 在學習網絡編程之前,我們編寫的程序幾乎都是“單機版”的——只能在本地運行,自娛自樂,無法與其他主機(用戶)進行交互。
????????有些同學可能會產生誤解:既然 Java 號稱“一次編譯,到處運行”,那把程序拷貝到另一臺安裝了 Java 環境的電腦上運行,不也算是交互嗎?其實并不是。那只是同一個程序在不同環境中運行,并沒有真正的信息交流。
????????真正的“交互通信”更像是打電話——雙方能夠互相發送消息,并根據對方的內容做出回應。比如,我們在瀏覽器輸入一個網址并訪問網站時,其實就是網站的服務器發起了網絡請求,服務器處理后再返回響應,我們才能看到網頁內容。這才是真正的主機之間通信。那么問題來了:我們要如何在自己的程序中實現這種通信呢?答案就是利用 java.net 包。它為我們提供了豐富的類和接口,幫助我們輕松實現網絡通信功能,從而開發出屬于自己的網絡應用程序。
網絡基礎知識
在學習網絡編程之前,我們需要掌握一些基本的網絡概念。這樣在調用 java.net 包中的接口和類時,才能理解為什么需要某些參數,以及這些參數背后的意義。
如果缺少這些知識儲備,直接上手網絡編程往往會感到一頭霧水。
不過,本篇文章重點是 Java 網絡編程,因此不會花大量篇幅講解網絡原理,只會簡要介紹網絡分層模型(七層/五層)、傳輸層協議(TCP/UDP)、網絡層(IP)以及數據鏈路層等核心內容。更深入的網絡知識,我會在單獨的文章中詳細展開,尤其是 TCP 與 UDP,這也是面試中經常考到的高頻知識點。
網絡協議
那么,什么是網絡協議?
簡單來說,網絡協議就是一套 通信規則和約定。在 Java 中,接口(interface)本質上就是一種規范,協議的作用與此類似。
你可以把網絡想象成一門“語言”:全世界的計算機要想互相通信,就必須遵循統一的規則,否則彼此無法理解數據。就像學習英語時,我們必須掌握詞匯、語法和發音,遵守規范后,才能與他人順暢交流。網絡協議也是如此,它規定了數據在網絡中的發送與接收方式,保證不同計算機之間能夠“說同一種語言”。
但由于網絡本身非常復雜,如果用一個龐大的協議去涵蓋所有問題,協議會變得臃腫難學。為什么呢?因為設計網絡需要考慮的事情很多:
-
物理層:用什么信號傳輸二進制數據?光信號、電信號還是無線信號?比如電信號中,高電平可能表示
1,低電平表示0。 -
數據準確性:信號在傳輸過程中可能受干擾,如何保證傳輸的
1不被誤判為0?或者如果出現傳輸錯誤我們如何區分?又如何補救?這就需要校驗與糾錯機制。 -
路徑選擇:數據要如何找到最優路徑傳遞到目標主機?
-
交付問題:數據到達目標主機后,應該交給哪個程序處理?
這些只是冰山一角,現實中的網絡設計遠比想象復雜。顯然,如果用單一協議來解決所有問題,就會像在 Java 中把所有邏輯塞進一個方法里——不僅難以維護,也難以理解。
因此,網絡協議被設計為 分層結構。
分層的好處
-
各層功能相互獨立,擴展靈活
協議分層后,各層之間通過接口交互,互不影響。如果某一層需要優化或擴展,只需改動這一層即可,不會牽一發而動全身。 -
易于實現和維護
分層將復雜問題拆解為多個小問題,每層只關注自己的功能,便于實現和維護。 -
協議制定更清晰
各層只需定義自身的規則,避免了一個協議包攬所有內容導致的臃腫。學習和使用時也更直觀,就像一個接口只包含必要的方法,而不是堆滿難以區分的功能。
OSI 模型
最早提出的網絡參考模型是 OSI 七層模型,它將網絡劃分為:
物理層 → 數據鏈路層 → 網絡層 → 傳輸層 → 會話層 → 表示層 → 應用層。
作為學習 Java 網絡編程的同學,其實不必過于糾結底層(物理層、鏈路層等)的原理,因為這些已經由硬件和操作系統封裝好了。我們在開發時,主要接觸的就是 傳輸層到應用層,比如 TCP/UDP 協議 以及 HTTP 協議。
不過 OSI 模型存在一些問題:
-
制定周期太長,落地困難;
-
協議過于復雜,運行效率低;
-
層與層之間功能劃分不夠清晰,部分功能存在重復。
因此,雖然 OSI 模型更像是一個 理論指導標準,但在實際應用中,計算機網絡普遍采用 TCP/IP 模型。
TCP/IP 模型
TCP/IP 模型是一個 五層結構,自下而上分別是:
物理層 → 數據鏈路層 → 網絡層 → 傳輸層 → 應用層。
與 OSI 相比,它將 會話層、表示層和應用層 合并成了統一的 應用層。因此在一些書籍里,你也會看到“TCP/IP 四層模型”的說法(物理層通常被視為硬件實現,不作為協議層來討論)。
下面我們逐層來簡單理解:
1. 數據鏈路層
負責 相鄰節點之間的數據傳輸。節點可以是計算機、路由器、交換機等設備。
主要解決的問題包括:
-
如何找到下一個節點?
-
如何檢測數據是否出錯?
常見協議有 以太網協議(Ethernet)、PPP 協議等。
2. 網絡層
負責 選擇路徑,讓數據能從起點主機到達目標主機。
你可以把它類比成快遞路線規劃:并不是最短路徑就一定最快,有時需要根據網絡情況繞路以避免擁堵。
常見協議有 IP 協議(IPv4/IPv6)、ICMP 協議等。
3. 傳輸層
負責 端到端(進程到進程)的傳輸。
主機上的每個應用程序都通過 端口號 來區分,就像房子里的房間號,一個端口號對應一個程序的位置。
知名協議:
-
TCP(傳輸控制協議):可靠傳輸,保證數據不丟失、不亂序。
-
UDP(用戶數據報協議):不保證可靠性,但效率高。
4. 應用層
應用層負責面向用戶提供具體的服務,也是程序員最常接觸的一層。在開發過程中,我們需要在應用層根據請求生成相應的結果,這既包括返回哪些數據,也包括如何將這些數據展示給用戶。也就是當數據到達主機后,應用層決定如何處理和展示。
常見協議有:
-
HTTP/HTTPS:網頁訪問
-
FTP:文件傳輸
-
SMTP/POP3/IMAP:電子郵件
比如,當你在瀏覽器中輸入網址并回車時,就發起了一次 HTTP 請求,服務器返回響應后,瀏覽器再將其渲染成網頁。
數據鏈路層
? ? ? ? 數據鏈路層負責解決兩個節點之間的數據傳輸問題。在這一層中,有一個核心概念——MAC 地址。
????????MAC 地址是網絡設備的唯一標識,由廠商在設備出廠時向權威組織申請分配。它長度為 6 字節(48 位),可表示數百億個地址,足以滿足當前的需求。
為什么要使用 MAC 地址?
-
尋址作用:根據 MAC 地址找到下一跳節點的位置。
-
識別作用:接收方通過 MAC 地址判斷該數據幀是否發給自己;若不是,則繼續轉發到目標 MAC 地址。
? ? ? ? 為了讓大家更容易理解這個過程。接下來會用數據鏈路層的常用協議:以太網協議給大家舉例。首先是要清楚協議里面到底有什么,也就是它的格式是什么。

協議本質上就是一段二進制數據,不同位置的比特有不同含義。例如:
-
前 6 字節:目的 MAC 地址
-
后 6 字節:源 MAC 地址
-
類型字段:指明交付給上層的哪種網絡層協議
這些位于數據前端的額外信息稱為首部;而位于數據尾端的附加信息則稱為尾部。其中,首部包含了目的地址和源地址,而尾部常見的字段是 CRC(循環冗余校驗碼)。
CRC 的作用是檢測數據傳輸過程中的錯誤:
-
發送方:根據要發送的數據計算出 CRC 值,并附加在幀尾。
-
接收方:收到數據后重新計算 CRC,并與幀中攜帶的 CRC 比較。若二者不同,說明數據在傳輸中出錯,該幀將被丟棄。
下面舉一個例子,讓大家更清楚看到在數據鏈路層是如何工作的。假設例子中小A和小C電腦沒有直連的線,只能通過小B傳輸。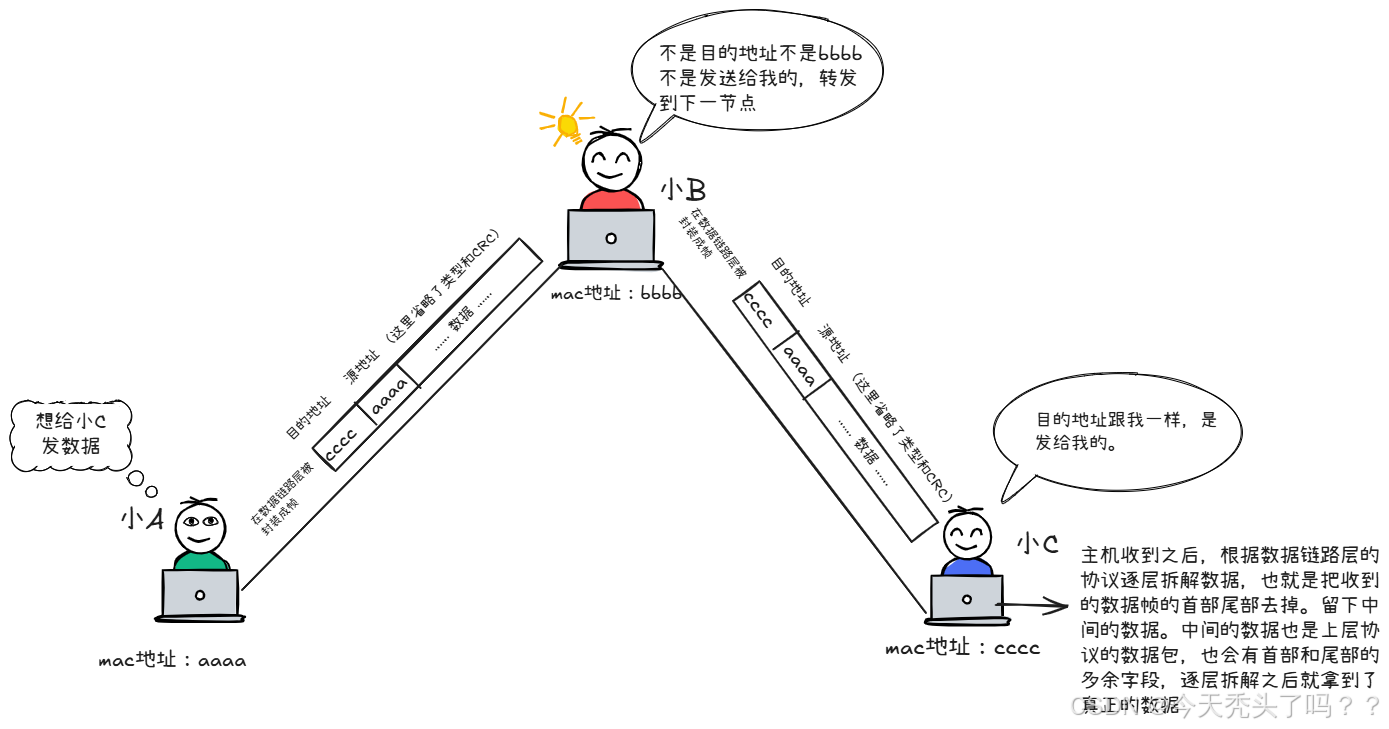
在網絡傳輸過程中,數據會按照五層協議逐層封裝:每一層在源數據外層加上本層規定的控制信息,形成一個新的數據單元。接收方在收到數據包時,則會逐層拆解,依次去掉各層的首部和尾部,最終還原出原始數據。
上面舉的小 A → 小 B → 小 C 的例子,只是為了幫助大家直觀理解數據鏈路層的工作原理,因此進行了簡化。在真實網絡中,主機之間幾乎不會直接通過網線相連,更不會像例子里的小 B 那樣替別人轉發數據。
-
主機網卡的設計只負責接收和處理發給自己的數據幀(目的 MAC 地址與自己一致,或是廣播幀),其余數據幀會直接丟棄,而不會轉發。
-
在實際環境下,通常會借助交換機來實現轉發。交換機提供更多接口,每臺主機只需接入交換機,就能與其上的任意主機通信。
-
此外,交換機還能維護 MAC 地址表,根據目的地址快速查找并轉發到目標端口,效率遠比簡單直連更高。
因此,可以把前面的例子看作教學化的簡化演示:它幫助我們理解 MAC 地址在逐跳傳輸中的作用。但在真實網絡中,只有像交換機、路由器這樣的設備才會承擔轉發任務,而主機只負責收發自身的數據,如果不是發送給自己的數據包會直接丟棄。
網絡層
網絡層涉及的概念更多,例如局域網(LAN)、廣域網(WAN)以及IP 地址。
局域網與廣域網
局域網和廣域網其實是相對的概念,范圍的大小取決于參照對象:
-
在家里,手機和電腦都連到同一個路由器、同一個 WiFi,就可以看作是一個局域網。
-
在寢室,如果你開手機熱點,同學連上你的熱點,你們兩部手機就組成了一個小小的局域網。相對而言,整個校園網就是更大的網絡,可以視作廣域網。
-
但換個角度看,校園網與城市范圍內的**城域網(MAN)**相比,又是一個局域網。
可見,“局域”與“廣域”并沒有絕對的標準,而是依賴于比較對象。
IP 地址與短缺問題
IP 地址是網絡層中最重要的概念,用于標識主機的唯一位置,就像快遞的收件人地址一樣。
IPv4 在設計之初采用 4 字節(32 位) 表示,最大可分配約 42 億個地址。然而,隨著電腦、手機以及越來越多的物聯網設備接入網絡,這些地址早已不夠用。為此,人們提出了幾種解決方案:
-
動態分配 IP
設備只有在上網時才會被分配 IP,用完釋放回收再分配給其他設備。這樣提高了利用率,但并沒有增加總量,屬于“治標不治本”。 -
NAT(網絡地址轉換)
將 IP 地址劃分為公網 IP和內網 IP:-
公網 IP 唯一,能被全球訪問。
-
內網 IP 僅在局域網內唯一,不同局域網之間可以重復使用。
通信時,局域網出口設備(如路由器)會將內網 IP 替換為公網 IP,并建立一個映射表:
內網 IP ? 公網 IP:端口這樣,百度等公網服務器收到請求時看到的源地址就是公網 IP;返回響應時,數據先到達出口設備,再由它根據映射表準確轉發到對應的內網主機。
如果局域網內有多臺主機同時訪問百度,區分的依據就是“端口號”。這個端口由 NAT 設備分配,需要和傳輸層的端口號加以區分。
例子:在同一個局域網內,主機A和主機B都 訪問了百度,那么路由器的映射表應如下:
主機A的IP地址 :客戶端隨機分配的端口? ??路由器公網IP:50001(端口)
主機B的IP地址 : 客戶端隨機分配的端口 ??路由器公網IP:50002(端口)
所以當響應返回的時候也能通過端口號的不同來區分,應該映射成哪一個地址。
數據包傳輸的時候也是有帶IP和端口的。所以可以根據端口區分。這里客戶端隨機分配的端口,就相當于是開了一個房間,端口的值就是房間號,當響應返回的時候主機知道應該返回給哪一個程序,就是根據端口來確定的。而路由器的端口則是為了區分不同的主機映射關系。
-
-
IPv6
IPv6 是根本性的解決方案,采用 16 字節(128 位) 表示地址,理論上可以給地球上每一粒沙子分配一個獨立 IP。IPv6 空間幾乎無限,也徹底解決了地址不足問題。
不過,IPv4 已經廣泛使用,因此需要一個較長的過渡期。目前中國的多數應用和設備已經支持 IPv6,正逐步向 IPv6 網絡遷移。現階段,主流做法仍是 NAT + 動態分配。
IP地址格式
IP地址分為兩個部分,網絡號和主機號。網絡號:標識網段,保證相互連接的兩個網段具有不同的標識。主機號:標識主機,同一網段內,主機之間具有相同的網絡號,但是必須有不同的主機號(這里就是前面說的局域網中IP不能相同)。通過合理的設置網絡號和主機號,就可以保證在相互連接的網絡中,每臺主機的IP地址都是唯一的。
同一個局域網中,主機之間的網絡號是相同的,主機號必須不同。在相鄰的兩個局域網中,要求網絡號是不同的。
那么如何劃分網絡號和主機號呢?這就需要通過子網掩碼。子網掩碼有32位,它的規定是它的左邊一定都是1,右邊一定都是0。不會01混著,左邊都是連續的1接著到右邊連續的0。把IP地址和子網掩碼做按位與運算就是網絡號。
特殊IP
如果一個IP地址,主機號為0,此時這個IP就表示網絡號,例如192.168.0.0,代碼當前局域網。
如果一個IP地址,主機號為1,此時這個IP往往表示這個局域網的“網關”,192.168.0.1代表局域網的網關(通常是路由器的IP)。網關的角色通常就是路由器,把守這當前局域網和其他局域網之間的出入口。當然路由器的IP也可以自己更改,不是強制要求主機號要為1,只是習慣用法。
如果一個IP地址,主機號為全1,此時這個IP表示廣播IP。用點分十進制表示就是255.255.255.255。
127.*開頭,都是環回IP。典型的就是127.0.0.1,表示當前主機地址。
網絡層如何工作的?
網絡層最重要的就是路由選擇。這些都是由路由器完成的。路由的選擇是“啟發式”的。過程非常類似于問路。網絡數據包到達路由的時候,路由器自身有一個路由表的數據結構(路由表就是這個路由器認的路),一個路由器無法認識到網絡的全貌,但是可以認識附近的一部分。
如果目的IP路由器認識,就會給出一個明確的路線。如果目的IP不認識,路由器就會把數據報轉發給一個“更見多識廣”的路由器(在路由表里有個默認的選項是下一跳)。
那有沒有可能問了一大圈也沒有找到目的地呢?也是有可能的,比如IP地址不存在,或者不可達。數據包通常會有一個生存時間TTL。TTL的單位是次數,數據傳輸是,每經過一個路由器轉發TTL就-1,如果減到0了,此時就要把包丟棄(不再繼續轉發了)。預期正常情況下,數據包是可以在很短的次數內就能傳輸到世界上任何一個主機上的。TTL的初始值是一個整數,一般是32/64/128這樣的數。
為什么說在很短的次數就能傳輸到世界上任何一個主機上呢?畢竟網絡結構這么龐大。這是基于一個社會科學上的假設:六度空間理論。這個理論的核心就是,如果你想認識一個人,你就去問你的朋友中有沒有認識這個人的人,如果沒有,則朋友繼續跟自己的朋友們傳達。一般經過6層朋友,就可以認識這個人了。
我們在可以在命令行測試一下,命令行有個ping命令,里面就可以查看TTL。我們可以ping一個國內網站和一個國外網站查看。
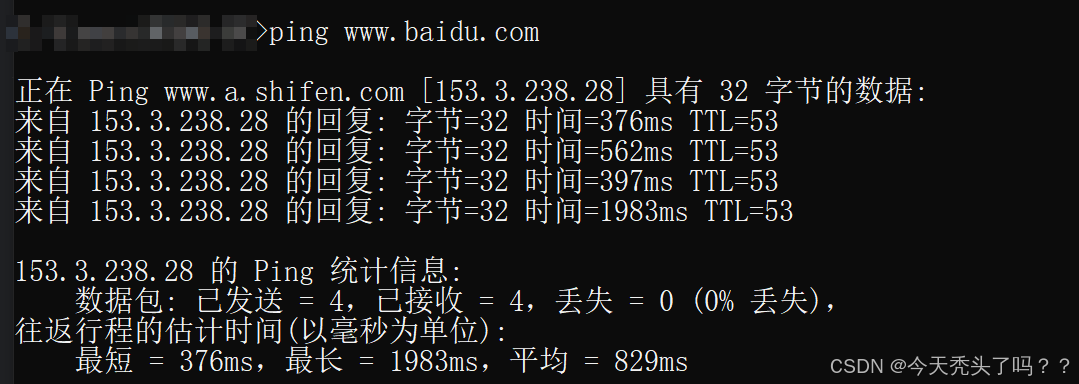
我們可以看到訪問百度網站,只經過了11跳就訪問到了(初始值應該是64)。再來訪問一個國外的網站github。可以看到經過了16跳才訪問到(初始值128)。
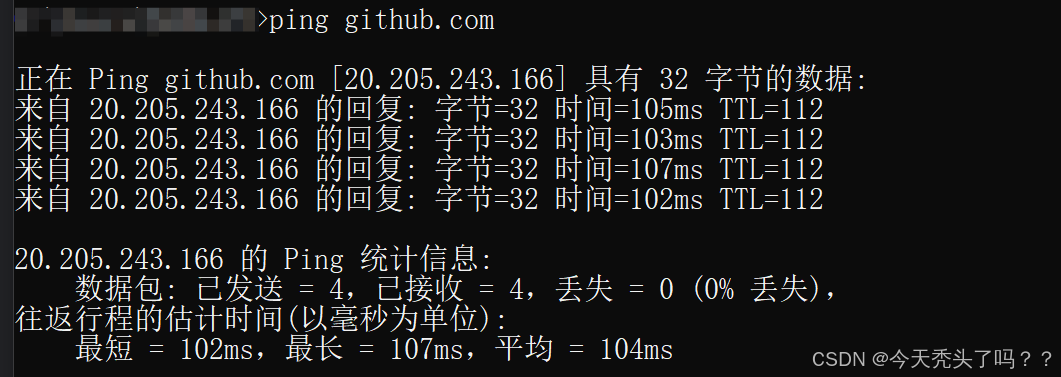
再測試一個不可達的,youtube。可以看到請求超時。
傳輸層
傳輸層最常用的兩個協議就是UDP和TCP,而本文要敘述的網絡編程也正是由這兩個協議封裝的類。所以本文來講傳輸層是重點,但是也是只需要對這兩個協議有個基本認識即可,在另外的文章會講到它們具體是如何實現的。傳輸層是端到端之間的傳輸。這不是說就不需要底層那些協議和網絡路徑運輸數據了。只是我們在學習每層協議的時候,只需要關注對等的實體即可,這樣會更容易理解本層協議,因為下層協議都已經封裝好了,我們可以不予理會,直接看做端到端的運輸,這樣理解即可。
TCP
? ? TCP是有連接,可靠傳輸,面向字節流,全雙工。首先解釋一下什么叫做連接。就是說主機在進行網絡通信前必須先和要通信的主機建立連接,才可以進行后續通信的操作。有點像打電話,只有對方接聽你的電話(同意建立連接),你們才可以相互交流。如果對方拒絕接聽你的電話(拒絕建立連接),那么就無法進行后續的通信交流操作。
? ? ? ?可靠傳輸指的就是發送方可以知道接收方有沒有收到數據,因為網絡上常常會有意外的情況,數據包可能會丟失(網絡擁塞,中間路由器處理不過來就會把新來的包丟棄,或者誤碼也會被丟棄)。所以知道接收方有沒有收到很重要,TCP采取了確認應答機制來確定接收方有沒有收到。具體就是接收方如果收到數據包,要馬上回給發送方一個ack包表示收到了。如果發送方沒有收到ack,就能采取一些補救措施,比如重新傳數據。這里千萬不要誤認為可靠就是指的安全或者是一定能把數據送達。
? ? ? ? 面向字節流就是指TCP發送數據包的方式是沒有明確的邊界界定的。就像字節流那樣,直接把數據傳輸過去,接收方自己按需讀取。只要觸發一個請求就寫入字節流中,TCP發送數據包可能把第一次和第二次請求混合著發,這是取決于TCP的分包機制,TCP只管向字節流里面拿去待發送的數據然后自行決定如何分包發送。所以接收方這邊也是用字節流接收的,你如果一個包一個包接收讀取,可能讀出的數據是一個半數據(第二次請求的部分數據和第一次請求的數據混合發)。
? ? ? ? 全雙工就是既能收消息也能發消息。這兩個功能可以同時進行。 于全雙工對應的就是半雙工,他只能同時做一件事,要么收消息,要么發消息。
我們可以簡單看一下TCP協議有哪些字段,本篇文章不會每個字段都解釋,我會在另外一篇TCP詳解的文章講解。其實TCP的格式也是連在一起的長條形的,圖片做換行處理只是為了排版好看。其實這些字段都是在一行的。
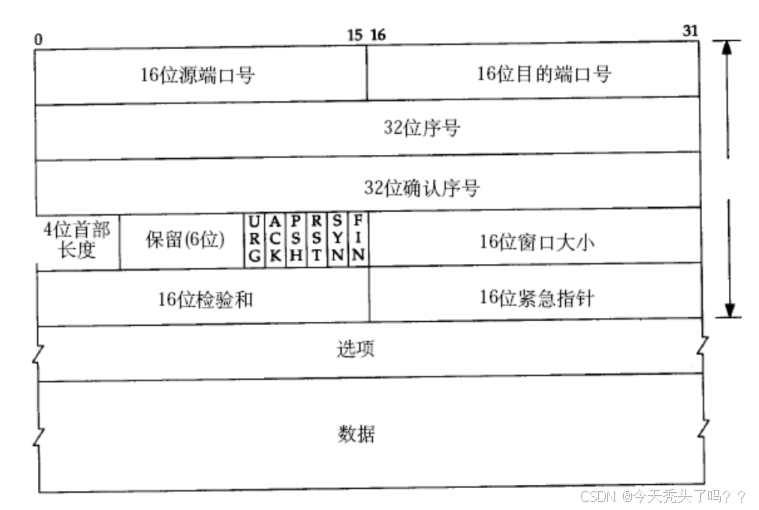
源/目的端口號:表示數據是從哪個進程來,到哪個進程去;
4位TCP報頭長度:表示該TCP頭部有多少個32位bit(有多少個4字節);所以TCP頭部最大長度是15 * 4 = 60字節。
6位標志位:
URG:緊急指針是否有效
ACK:確認號是否有效
PSH:提示接收端應用程序立刻從TCP緩沖區把數據讀走
RST:對方要求重新建立連接;我們把攜帶RST標識的稱為復位報文段
SYN:請求建立連接;我們把攜帶SYN標識的稱為同步報文段
FIN:通知對方,本端要關閉了,我們稱攜帶FIN標識的為結束報文段
現在不理解標志位每位的意思不要緊,只做了解。但是在講可靠傳輸的時候提到過ACK,如果是應答報文的話,標志位ACK這里就會被標為1。
UDP
? ?UDP是無連接,不可靠傳輸,面向數據報,全雙工。首先解釋一下什么叫做無連接,和TCP的有連接對應。UDP更像是發短信,不需要經過對方的同意(不需要建立連接),直接就可以把短信發送到對方手機上。至于不可靠這里也是和TCP的可靠相對應的,也就是不能知道發送數據后,接收方是不是真的收到了數據。
? ? ? ? 面向數據報,就是UDP的每次請求都是單獨包裝成一個數據報發送的,也就是說UDP是一個數據報一個數據報發送的。接收方每次接收一個數據報里面就是一次請求的數據。全雙工指能同時收發消息。
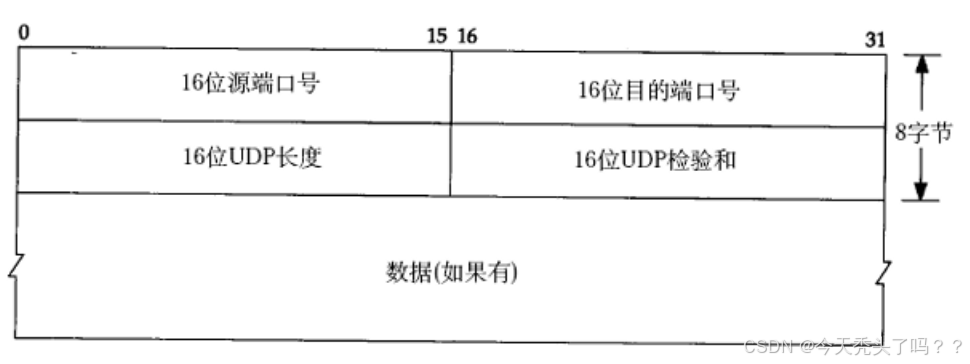
UDP協議格式也是大致了解一下即可,其實可以看到UDP其實少很多字段,因為它的功能比TCP少很多。這里需要注意的是16位UDP長度指的是整個數據報(UDP首部+UDP數據)的長度。
UDP編程
DatagramSocket 是 Java 對 UDP 的封裝類,基于它即可實現 UDP 數據傳輸。本文示例采用經典的服務器/客戶端模型:服務器在固定端口上監聽客戶端請求,客戶端在需要時向服務器發送數據,服務器接收并返回響應。
-
DatagramSocket 的創建
-
new DatagramSocket(int port):在本機的所有網絡接口(通配地址)上綁定指定端口,適合服務器。 -
new DatagramSocket():在本機隨機分配一個空閑端口,常用于客戶端發起請求時使用臨時端口。因為客戶端是在用戶的主機上的,如果代碼里面把客戶端端口定死了,很可能和用戶主機上的其他某個應用起沖突,但是程序員又無法事先得知用戶主機上有哪些應用。而服務端則不同,是程序員可以清楚指定一個不沖突的端口。并且服務器的端口必須實現規定好,這樣客戶端才知道向哪個端口發送數據。 -
new DatagramSocket(int port, InetAddress bindAddr):在指定的本地地址(某個網卡)和端口上綁定,適用于多網卡環境下需指定出/入接口的場景。
-
-
DatagramPacket 的用途
-
接收用:
new DatagramPacket(byte[] buf, int length),receive()會把網絡層收到的數據放入buf,并更新packet.getLength()、packet.getAddress()、packet.getPort()(發送方地址/端口)。 -
發送用:
new DatagramPacket(byte[] buf, int length, InetAddress dest, int port),發送時需要目標地址和端口。 -
注意:若到達的數據比接收緩沖區
buf大,超出部分會被截斷并丟棄。
-
-
實踐要點
-
服務端必須知道并綁定一個固定端口,客戶端一般使用無參構造獲得臨時端口。
-
若主機有多塊網卡,指定
InetAddress可控制流量走哪塊網卡;否則默認由操作系統選擇。 -
DatagramSocket.receive()是阻塞調用,也就是說如果一直沒有收到數據就會阻塞在該行代碼,可通過setSoTimeout()設置超時避免無限阻塞。
-
我先寫一個簡單的回顯服務器(客戶端發啥,服務器回啥)的示例,在示例中就能知道它的語法。
服務端:
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.SocketException;public class UDPServer {public static void main(String[] args) throws SocketException {try(DatagramSocket socket = new DatagramSocket(8888)){byte[] buf = new byte[1024];DatagramPacket packet = new DatagramPacket(buf, buf.length);while(true){socket.receive(packet); // 準備接收客戶端發送的數據// 讀取int length = packet.getLength(); // 此時packet已經填充好了接收到的數據,返回的長度是接收數據的實際長度String s = new String(buf, 0, length);System.out.println(packet.getAddress() + ":" + packet.getPort() + "對服務器說:" + s);byte[] data = s.getBytes();DatagramPacket sendPacket = new DatagramPacket(data, data.length, packet.getAddress(), packet.getPort());// 給客戶端返回一模一樣的內容socket.send(sendPacket);}} catch (IOException e) {throw new RuntimeException(e);}}
}客戶端:
public class UDPClient {public static void main(String[] args) {try(DatagramSocket socket = new DatagramSocket()) {Scanner sc = new Scanner(System.in);while (true) {System.out.print("請輸入你要對服務器發送的話:");String s = sc.nextLine();if (s.equals("exit")) {break;}byte[] data = s.getBytes();DatagramPacket sendPacket = new DatagramPacket(data, data.length, InetAddress.getByName("localhost"), 8888);socket.send(sendPacket);DatagramPacket receivePacket = new DatagramPacket(new byte[1024], 1024);socket.receive(receivePacket);int length = receivePacket.getLength();System.out.println("服務器回復你:" + new String(receivePacket.getData(), 0, length));}} catch (SocketException e) {throw new RuntimeException(e);} catch (UnknownHostException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}}
}運行效果: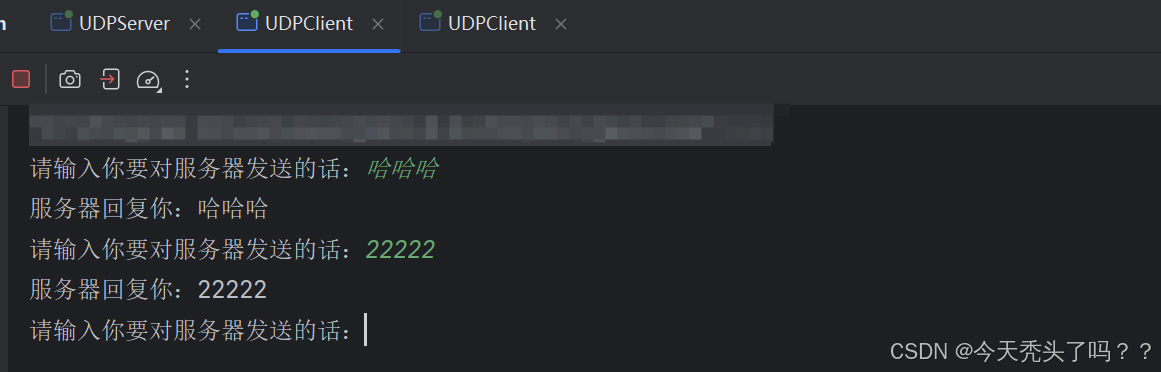
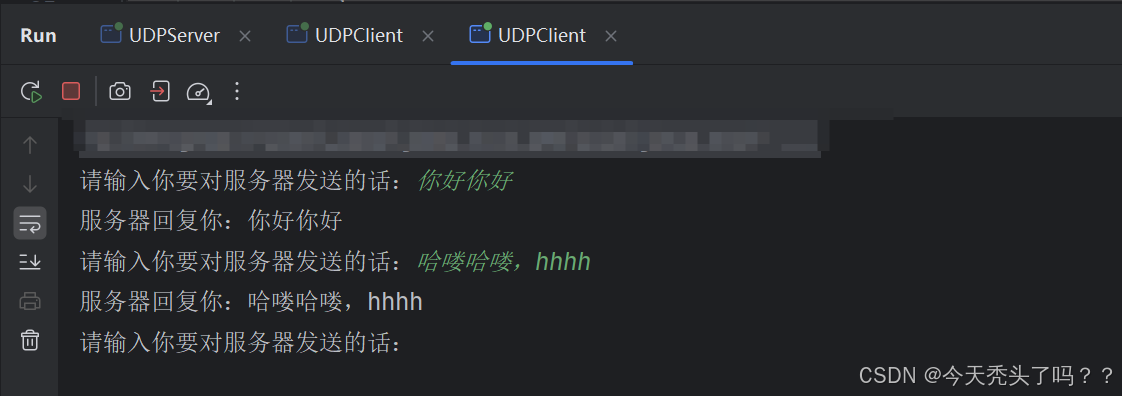
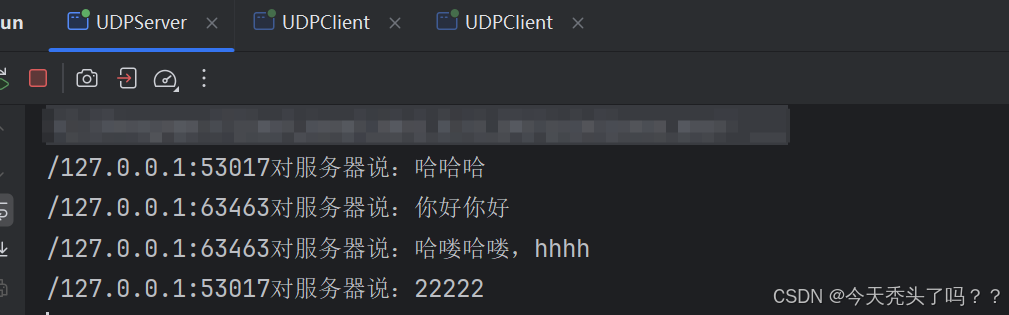
從服務端的打印可以看到,客戶端的端口確實是隨機分配的。
總結
整個程序的運行過程如下:
-
進程與端口
-
客戶端和服務器各自運行在主機上的一個進程中。進程需要通過 端口號 來標識,才能在網絡通信中被準確定位。
-
服務端端口號固定:由程序員指定,例如
8888,這樣客戶端才能知道去哪里發送數據。因為服務器由我們掌控,可以避免沖突。 -
客戶端端口號隨機:通常由操作系統分配一個臨時端口。因為客戶端的主機環境不確定,避免手動指定導致沖突。
-
-
客戶端流程
-
從鍵盤讀取用戶輸入。
-
將數據轉為字節數組,封裝到
DatagramPacket中,并指定 目的 IP + 目的端口。 -
發送數據包。
-
構造一個接收數據用的
DatagramPacket,調用receive方法阻塞等待服務器的響應。 -
使用
packet.getLength()獲取真實數據長度(而不是緩沖區大小),再解碼成字符串。 -
整個過程可放入循環中,用戶輸入
"exit"時退出程序。由于 UDP 無連接,所以不需要像 TCP 那樣通知服務器關閉。
-
-
服務器流程
-
在指定端口(如
8888)創建DatagramSocket,進入循環。 -
調用
receive方法阻塞等待數據(這是 UDP 編程里唯一會阻塞的方法)。 -
接收到數據后,取出內容,并打印 客戶端地址 + 端口,這就相當于日志記錄。
-
再將接收到的內容重新封裝為
DatagramPacket,發送回客戶端,完成回顯。
-
-
注意事項
-
構造
DatagramPacket時,發送長度必須是字節數組的長度,而不是字符串的長度。因為字符串和字節的對應關系依賴于編碼方式,尤其是中文等多字節字符,字符串長度和字節長度可能不一致。
-
緩沖區大小(如 1024 字節)只是接收的容器,真正收到多少數據要看
getLength(),否則可能出現臟數據或亂碼。
-
TCP編程
在 TCP 編程中,服務端通常通過 ServerSocket 類來監聽客戶端的連接請求。顧名思義,ServerSocket 專門用于服務端,它需要綁定到一個 端口號,作為服務器進程在網絡中的唯一標識。
核心方法是 accept():
-
當沒有客戶端請求時,它會阻塞等待;
-
一旦有客戶端發起連接,
accept()就會返回一個新的Socket對象。
需要注意的是:
-
ServerSocket自身只負責“接收請求、建立連接”; -
而返回的
Socket才是 真正用于數據傳輸的通道。
我們知道TCP是面向字節流的,所以在 Socket 中,提供了輸入流和輸出流:
-
輸入流(
InputStream):用來讀取客戶端發送的數據; -
輸出流(
OutputStream):用來向客戶端發送響應。
通常,服務端會:
-
使用
ServerSocket在指定端口監聽; -
調用
accept()接收客戶端連接; -
使用返回的
Socket進行雙向通信; -
通信完成后關閉
Socket,最后再關閉ServerSocket。
如果需要同時處理多個客戶端,可以為每個 Socket 單獨分配一個線程,或者使用線程池來提升并發處理能力。
接下來繼續用回顯服務器進行舉例:
服務端代碼:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.ServerSocket;
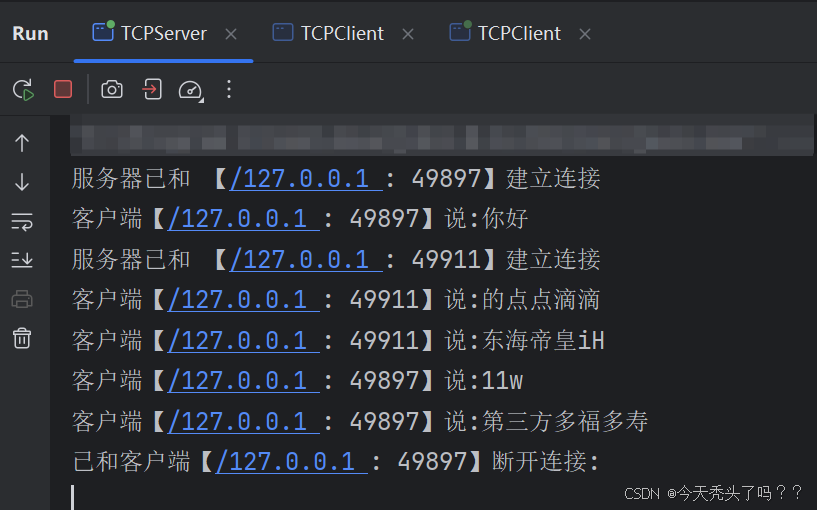
import java.net.Socket;public class TCPServer {public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket(9999); // 開啟服務器進程端口while(true){Socket socket = serverSocket.accept(); // 等待接收客戶端請求System.out.println("服務器已和 【" + socket.getInetAddress() + " : " + socket.getPort() + "】建立連接");process(socket);}}public static void process(Socket socket) {new Thread(() -> { // 由于需要對每個建立連接的客戶端實時監聽請求,所以需要多線程,進行同時處理try(BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));PrintWriter out = new PrintWriter(socket.getOutputStream())){while(true){ // 需要反復監聽客戶端有沒有發請求,所有用while循環讀取String s = reader.readLine(); // 讀取客戶端數據if("exit".equals(s)){break; // 如果收到的消息為exit,則說明客戶端請求斷開連接}System.out.println("客戶端【"+ socket.getInetAddress() + " : " + socket.getPort() + "】說:" + s);out.println(s); // 給客戶端返回響應,由于是回顯服務器,客戶端發啥回啥out.flush(); // PrintWriter類帶有緩沖區,需要flush將數據刷新出去,以確保發送}} catch (IOException e) {throw new RuntimeException(e);}finally {try {socket.close();System.out.println("已和客戶端【"+ socket.getInetAddress() + " : " + socket.getPort() + "】斷開連接:");} catch (IOException e) {throw new RuntimeException(e);}}}).start();}
}客戶端代碼:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.InetAddress;
import java.net.Socket;
import java.net.UnknownHostException;
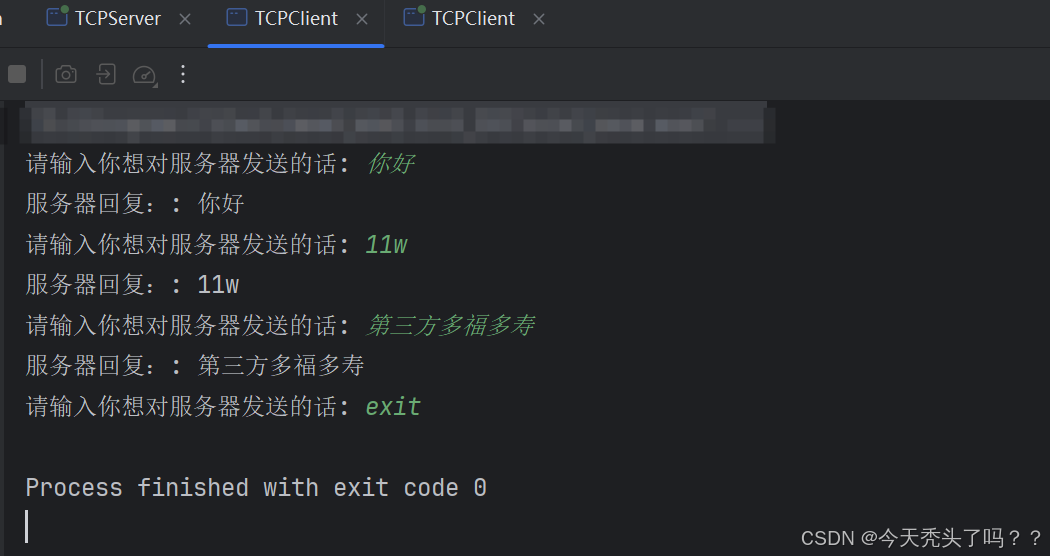
import java.util.Scanner;public class TCPClient {public static void main(String[] args) {try(Socket socket = new Socket(InetAddress.getByName("localhost"), 9999);BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));PrintWriter outer = new PrintWriter(socket.getOutputStream())){// 和服務器建立連接Scanner sc = new Scanner(System.in);while(true){System.out.print("請輸入你想對服務器發送的話: ");String s = sc.nextLine();outer.println(s); // 向服務器發送數據outer.flush(); // 刷新緩沖區確保數據真的發送出去if("exit".equals(s)){ // 如果為exit就退出break;}String res = reader.readLine(); // 接收響應System.out.println("服務器回復:: " + res);}} catch (UnknownHostException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}}
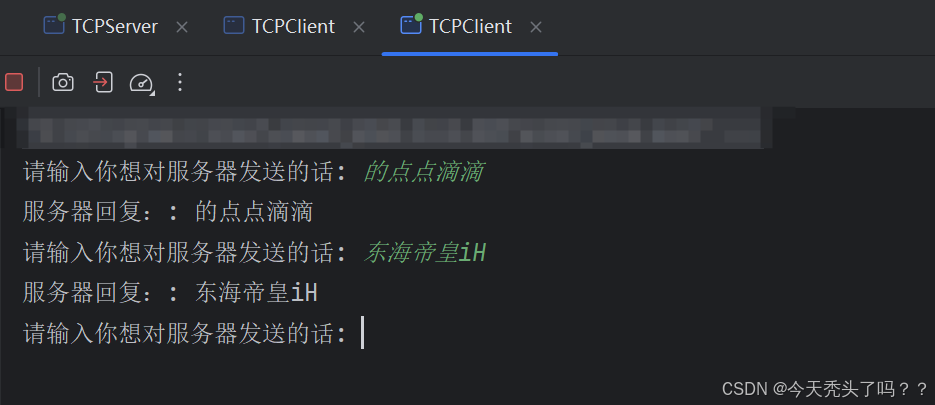
}運行效果:
總結
1. 進程與端口
-
和 UDP 一樣,客戶端和服務器各自運行在主機的一個進程里,依靠 端口號 來標識。
-
服務端端口固定(例如
9999),這樣客戶端才能知道去哪連接。 -
客戶端端口則由操作系統分配一個臨時端口。
不同之處在于:TCP 是面向連接的,在真正傳輸數據前,必須先完成 三次握手,建立連接。
2. 客戶端流程
-
創建
Socket,指定服務器 IP + 端口,主動發起連接。 -
從鍵盤讀取用戶輸入。
-
調用
PrintWriter向服務器發送數據。因為有緩沖區,必須調用flush()確保數據真正發出去。 -
調用
BufferedReader.readLine()等待服務器響應。 -
如果輸入
"exit",客戶端主動斷開連接,釋放資源。
3. 服務端流程
-
創建
ServerSocket,綁定端口并等待連接。 -
調用
accept()方法阻塞,直到有客戶端請求到來。-
這時服務器會為每個客戶端生成一個新的
Socket,表示與該客戶端的連接。
-
-
每個客戶端連接交給獨立線程處理(否則多個客戶端會相互阻塞)。
-
在子線程中:
-
使用
BufferedReader持續讀取客戶端發送的數據。 -
如果收到
"exit",關閉該客戶端連接。 -
否則打印日志,并用
PrintWriter將消息原樣返回。
-
-
客戶端斷開時,關閉對應的
Socket,并打印斷開提示。
4.注意事項
-
帶緩沖區的輸出流必須
flush()-
在 TCP 編程中,如果使用
PrintWriter、BufferedWriter等帶緩沖區的輸出流,寫入數據后必須調用flush(),否則數據可能一直停留在緩沖區里,只有緩沖區滿時才會真正發送。 -
這點在 回顯服務器 或 即時交互場景 下尤其重要,否則會出現“客戶端發了消息但遲遲收不到響應”的情況。
-
-
服務器端必須顯式關閉
Socket-
當客戶端斷開連接時,服務端線程會結束循環,這時一定要顯式調用
socket.close()釋放資源。 -
原因:
-
Socket底層依賴的是操作系統的文件描述符(FD),并非普通的 Java 對象。Java 只是做了封裝,方便程序員調用。 -
JVM 的垃圾回收器只負責托管 Java 堆內存對象,而底層操作系統資源(如文件、網絡套接字)并不受 GC 直接管理。
-
對普通 Java 對象來說,內存回收的延遲不會造成致命問題,因為 JVM 最終一定會釋放堆空間。但
Socket屬于有限的系統級資源,如果依賴 GC 觸發finalize()回收,不僅時機不可控(可能長時間不回收),而且還可能因為 FD 數量耗盡,導致新客戶端無法建立連接,最終造成服務端崩潰。這就是所謂的 資源泄露。
-
-
-
客戶端
Socket不需要特別擔心泄露-
客戶端通常只會維護有限個
Socket,數量可控,不會像服務端那樣“一來一個請求就創建一個連接”。 -
所以客戶端退出時即使忘記
close(),一般也不會導致大規模的資源浪費,但依舊推薦養成顯式關閉的習慣。
-
-
ServerSocket一般不用關閉-
服務端通常會長時間運行,如果關閉
ServerSocket,就等于停止對新連接的監聽,相當于讓服務停機。 -
只有在服務端要整體下線時,才會去關閉
ServerSocket。
-
和UDP 的對比
-
UDP:
-
無連接,不需要顯式關閉“連接資源”。
-
客戶端和服務端都只有一個
DatagramSocket,資源消耗固定。 -
就算不
close(),最多就是占用一個端口,不會因為高并發出現“資源膨脹”的問題。
-
-
TCP:
-
面向連接,每接入一個客戶端,服務端就會分配一個新的
Socket。 -
如果不主動關閉,資源會不斷累積,形成泄露,最終影響整個服務器的穩定性。
-
有趣的案例
網頁案例
? ? ? ?有了網絡通信機制,我們同樣也可以完成像我們平時訪問網頁的那樣的案例。我們不用在寫一個客戶端程序發送請求,就用瀏覽器充當客戶端,在瀏覽器敲下服務器的地址,發送請求。但是需要注意的是瀏覽器的請求還涉及一個應用層協議HTTP協議。這個請求我們不用管,因為在輸入網址敲下回車的時候瀏覽器就已經包裝好了HTTP請求發送。我們需要關注的是接收到請求之后如何返回響應,因為要在瀏覽器看到響應,就必須使用HTTP協議。我們可以簡單了解一下HTTP響應的格式,首先的它的響應頭格式:
HTTP的版本 + 空格 + 狀態碼(200表示請求成功)+ 空格 + 響應描述
HHTP/Version 狀態碼 響應描述例如:
HTTP/1.1 200 ok
中間還有很多其他字段可以設置,但是我們就不具體講了,感興趣的參考另一篇博文:
https://blog.csdn.net/qq_56776909/article/details/133220078?spm=1001.2014.3001.5501
這些字段之后,加一個空行,空行后面就是我們要向客戶端返回的數據。
有了這些了解之后,我們就可以按照HTTP協議的格式自行構造一個HTTP響應返回給瀏覽器。
代碼如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Random;
public class Test2 {public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket(9999);System.out.println("Server started on port 9999...");while (true) {Socket socket = serverSocket.accept();String client = socket.getInetAddress().getHostAddress() + ":" + socket.getPort();
// BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// String line;
// while ((line = reader.readLine()) != null && !line.isEmpty()) { // 打印請求行
// System.out.println(line);
// }// 打印客戶端 IP 和端口System.out.println("客戶端連接" + client );String[] colors = new String[]{"red","pink","blue","green","yellow","orange","purple"};int len = colors.length;String color = colors[new Random().nextInt(len)];// 簡單的HTTP響應String response ="HTTP/1.1 200 OK\r\n" +"\r\n" +"<h1 style = \"color:" + color + "\">Hello, 【" + client + "】!</h1>";socket.getOutputStream().write(response.getBytes("gbk")); // 瀏覽器socket.close();}}}代碼里面注釋掉的是打印HTTP協議的請求,如果感興趣可以打印看看。
運行服務器代碼之后,我們可以打開瀏覽器敲下地址和端口,就可以收到響應:
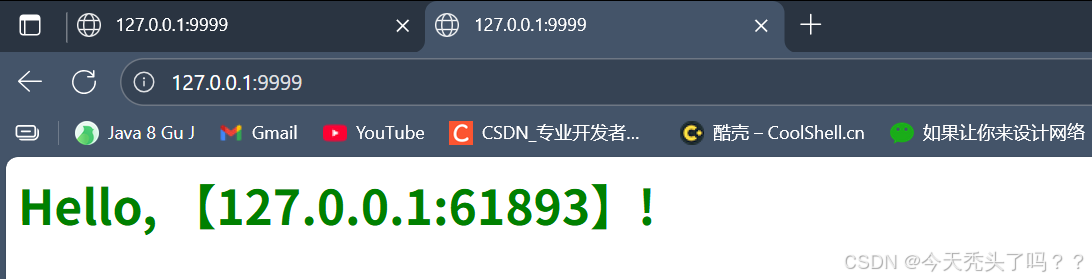


可以每新開一個標簽頁訪問服務器地址,客戶端的端口都是不一樣的。
爬蟲案例
在第一個案例中,我們是利用瀏覽器直接作為客戶端來訪問網頁,這樣就省去了寫客戶端代碼的步驟。但實際上,我們也可以自己寫客戶端程序,像瀏覽器一樣發送請求并接收響應,從而獲取網頁內容。按理說,這是完全可行的。
網頁訪問是通過 HTTP請求 完成的,因此我們可以構造一個 HTTP 請求來獲取網頁內容。
需要注意的是,現在幾乎所有網站都是 HTTPS 的,而普通的
Socket無法處理 HTTPS,需要使用SSLSocket。為了演示方便,這里選擇一個可以通過 HTTP 訪問的網頁,例如百度(雖然只能訪問舊版本頁面,但僅用于學習 Socket 原理,這沒關系)。
如何獲取 IP 和端口
很多人會疑問:我們不知道百度的 IP 和端口,如何創建 Socket 對象呢?
-
IP 地址可以直接用域名,
Socket構造方法可以傳入域名,它會自動解析 IP。 -
端口如果不指定,HTTP 默認端口是 80,所以我們可以直接使用 80 端口訪問網頁。
代碼實現
import java.io.*;
import java.net.Socket;public class Test {public static void main(String[] args) throws IOException {String host = "www.baidu.com";Socket socket = new Socket(host, 80);PrintWriter out = new PrintWriter(socket.getOutputStream());// 發送 HTTP GET 請求out.println("GET / HTTP/1.1");out.println("Host:" + host);out.println("Connection:close"); // 如果不關閉連接,代碼程序會一直運行和服務端保持連接out.println();out.flush();PrintWriter printWriter = new PrintWriter(new FileWriter("src//baidu.html")); // 保存到網頁BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));String s = reader.readLine();System.out.println("打印響應頭:");while (!s.isEmpty()) {System.out.println(s);s = reader.readLine();}System.out.println("打印響應體:");while(s != null) {s = reader.readLine();System.out.println(s);printWriter.println(s);}printWriter.flush();}
}注意點
-
響應頭與響應體由空行分隔,因此我們用兩次循環分別讀取。
-
響應體才是真正的網頁內容,所以只將響應體寫入
baidu.html文件。 -
如果網站使用 HTTPS,就需要使用
SSLSocket或者直接使用高級 HTTP 庫(如HttpClient或Jsoup)。
運行程序后,可以在 src/baidu.html 文件中查看網頁內容,確認爬取成功。
運行結果如下: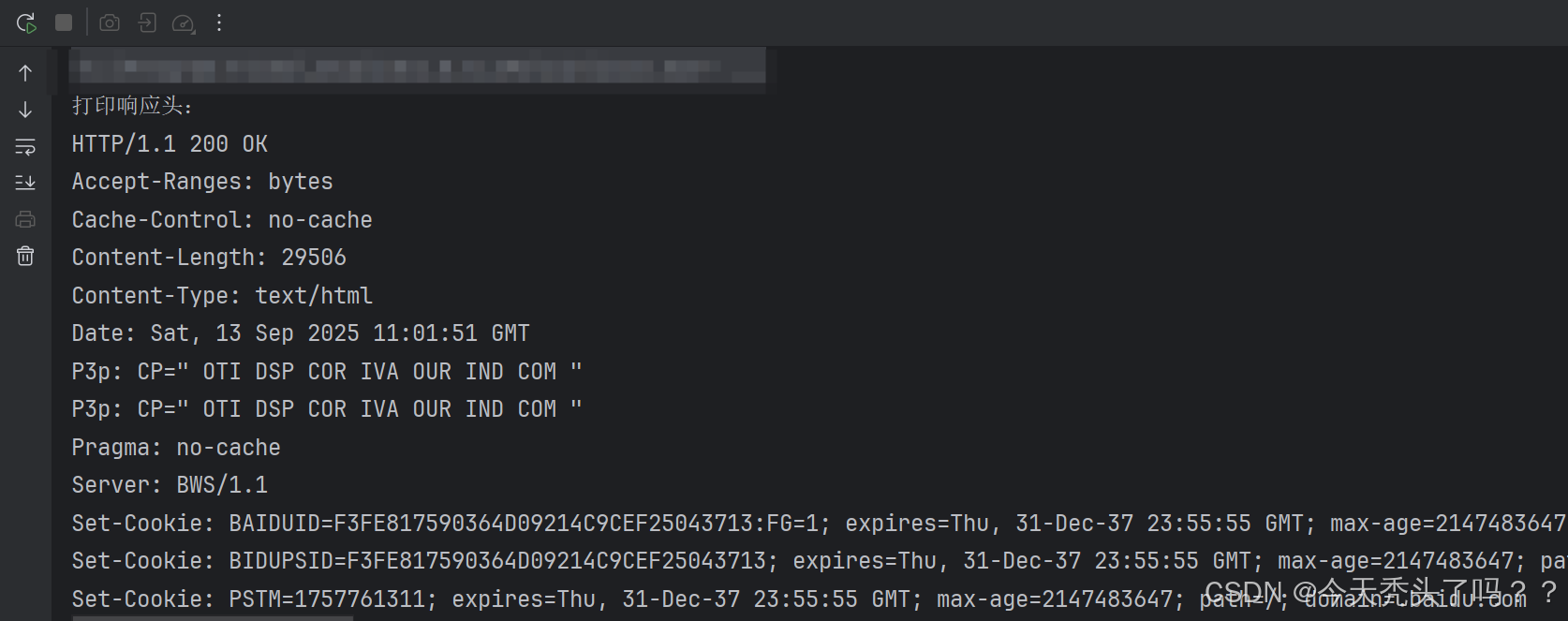
我們可以打開baidu.html文件查看是不是里面寫入了響應體的內容,查看響應體長什么樣子:
這并不是百度的網址,而是剛剛我們寫入的文件。可以看到確實是把百度網頁爬取下來了。




評測與實操:5 秒在線摳圖、支持批量與換底(電商/設計團隊提效指南))




 (三))
)
)






- 狀態管理與容錯)
