R 語言是一種專為統計計算、數據分析和圖形可視化而設計的編程語言,在學術界和工業界都備受青睞。RStudio是一款為 R 語言量身打造的集成開發環境(IDE)。它如同一個功能強大的指揮中心,能夠將數據科學工作所需的一切:控制臺、腳本編輯器、環境窗口、文件管理、包管理、幫助文檔和繪圖窗口等集成在一個界面中,極大地提升了編程與數據分析的效率和體驗。
OpenBayes 平臺現已內置了 RStudio 軟件鏡像,今天給大家介紹一下如何在 OpenBayes 平臺使用 RStudio 進行高性能計算的入門操作,本教程導入了模擬心理學上一個比較常用的量表抑郁量表的測評數據進行分析演示。
新用戶使用下方邀請鏈接注冊,可獲得 4 小時?RTX 4090?+ 5 小時 CPU 的免費時長!
小貝總專屬邀請鏈接(直接復制到瀏覽器打開):
https://go.openbayes.com/9S6Dr
一、工具準備
- 創建容器
首先進入「高性能計算」頁面,點擊「創建新容器」。
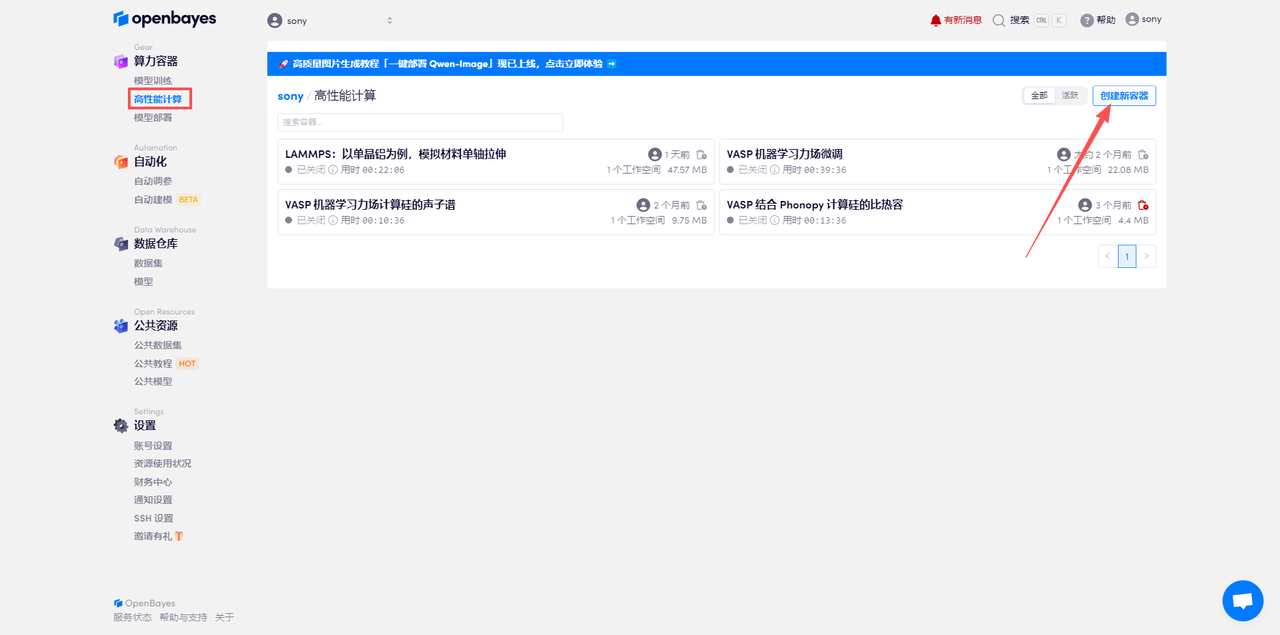
創建容器頁面,選擇和填寫容器信息。然后點擊「執行」
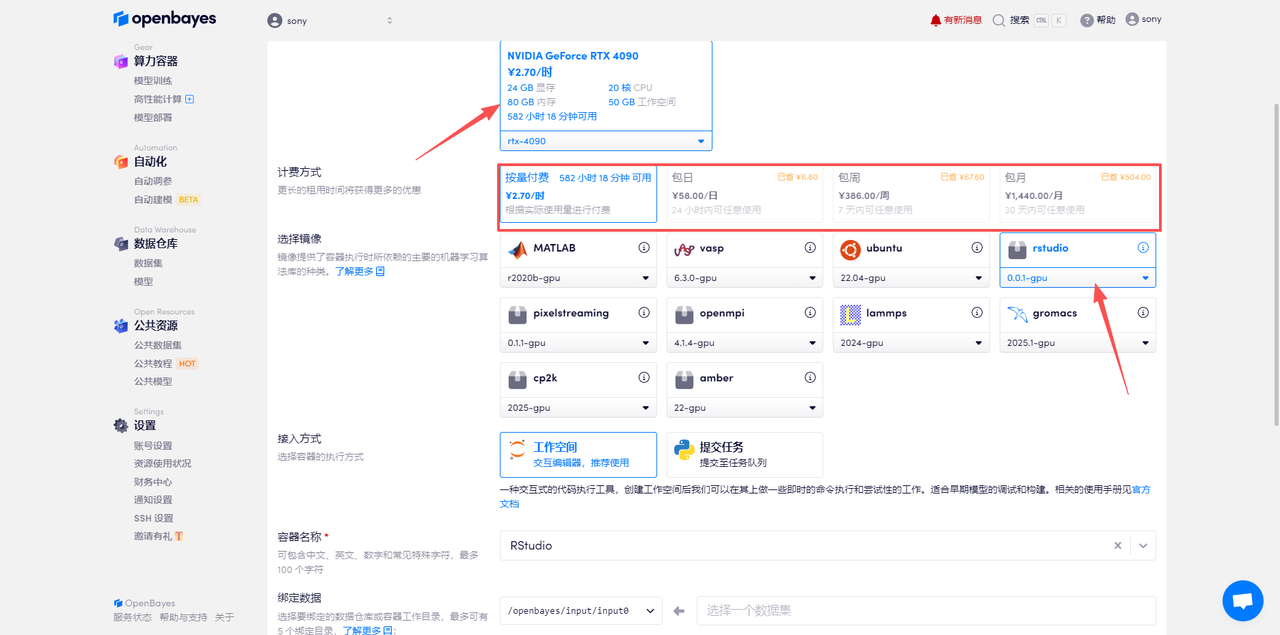
- 算力選擇:默認為 RTX 4090;
- 計費方式:默認為「按量付費」。還可以選擇包日/月/周。免費資源(邀請鏈接會寫在簡介中):使用視頻下方邀請鏈接可以獲得 4 小時 RTX 4090 和 5 小時 CPU。
- 鏡像選擇:已經內置了一些高性能計算所需軟件,可以在研究范圍內直接使用。這里我們要使用 R 軟件進行數據分析,所以選「rstudio」。
- 容器名稱:按照要求填寫即可
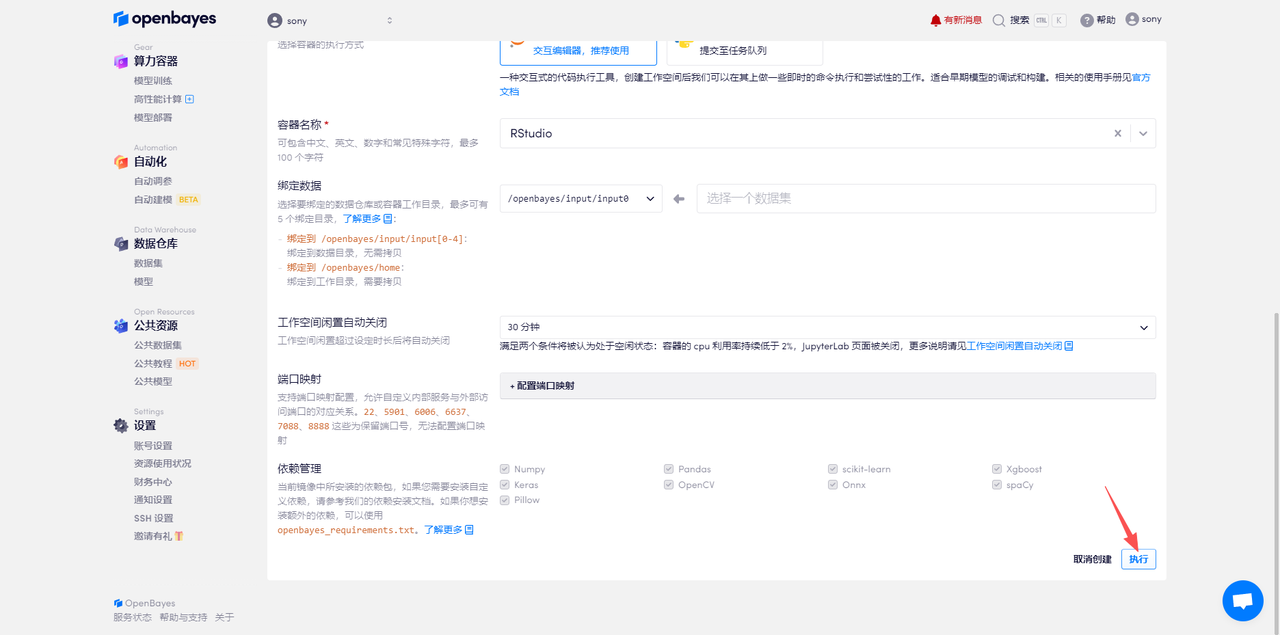
2. 進入 R studio Server
待系統分配好資源,當狀態變為「運行中」后,點擊「打開工作空間」。
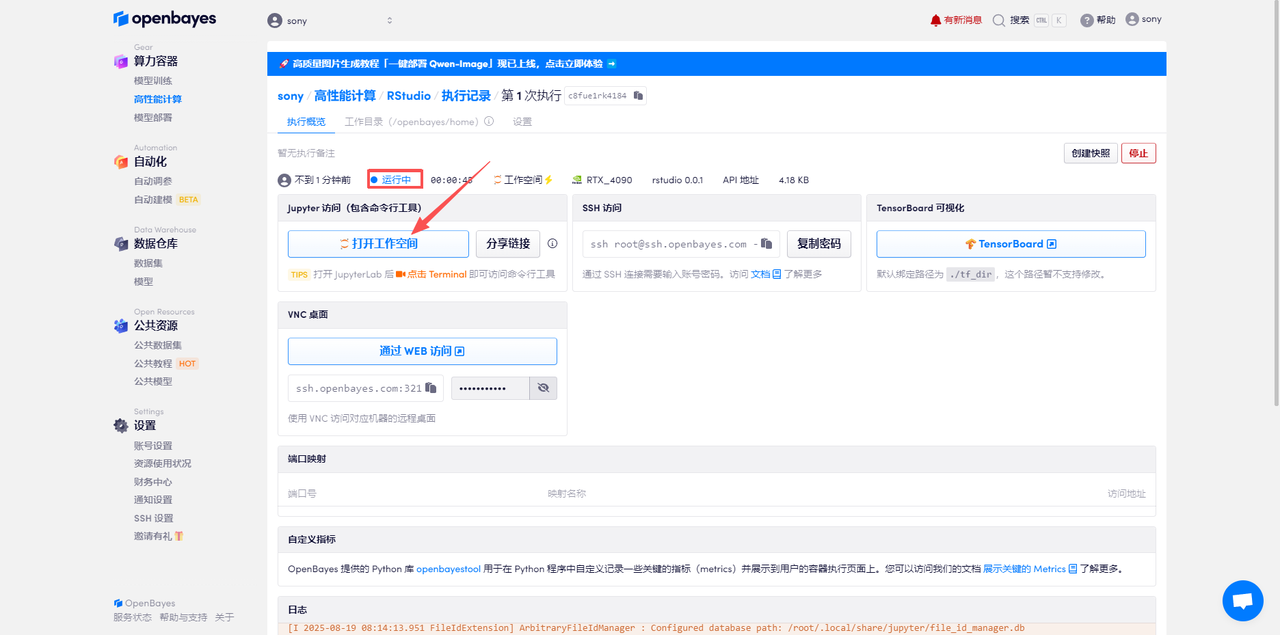
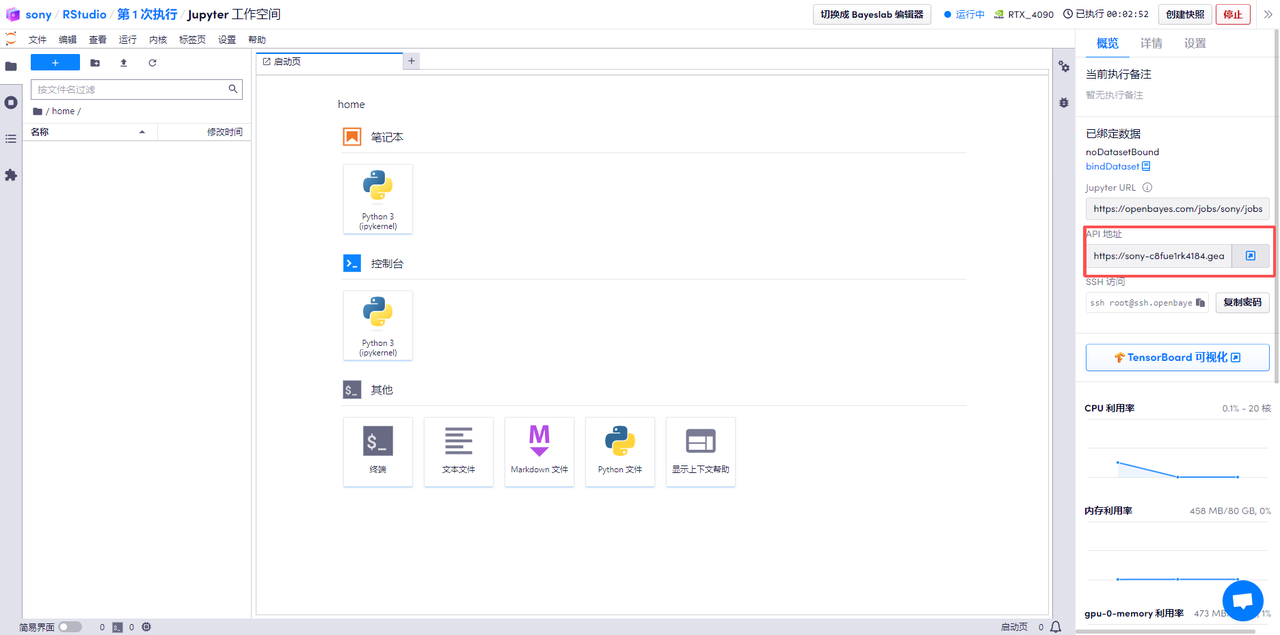
進入到工作空間后,在頁面右邊,點擊「API 地址」打開(先要進行支付寶實名認證),默認用戶名和密碼都是 rstudio,填寫正確后,即可進入了?Rstudio Server?的界面。
3. 設置 RStudio 工作目錄
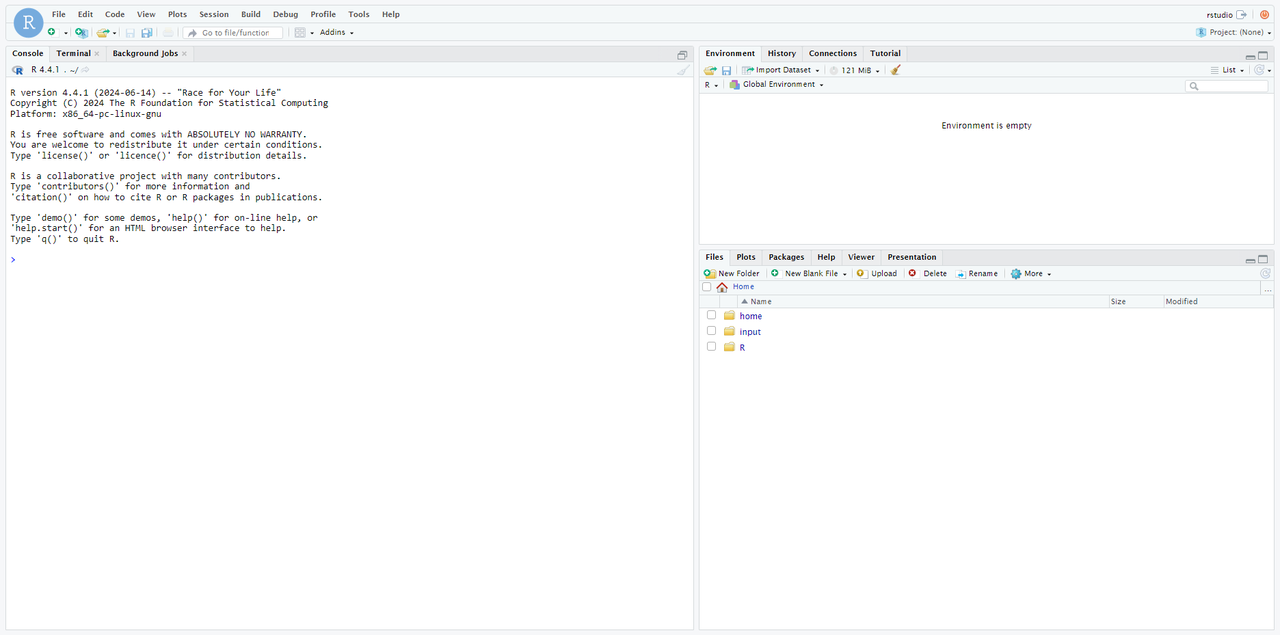
進入到 Rstudio Server 頁面后,可以發現跟我們本地安裝使用的 Rstudio 是一樣的。而唯一不同的是工作目錄。
輸入以下命令查看當前工作目錄,為:/home/rstudio
getwd() 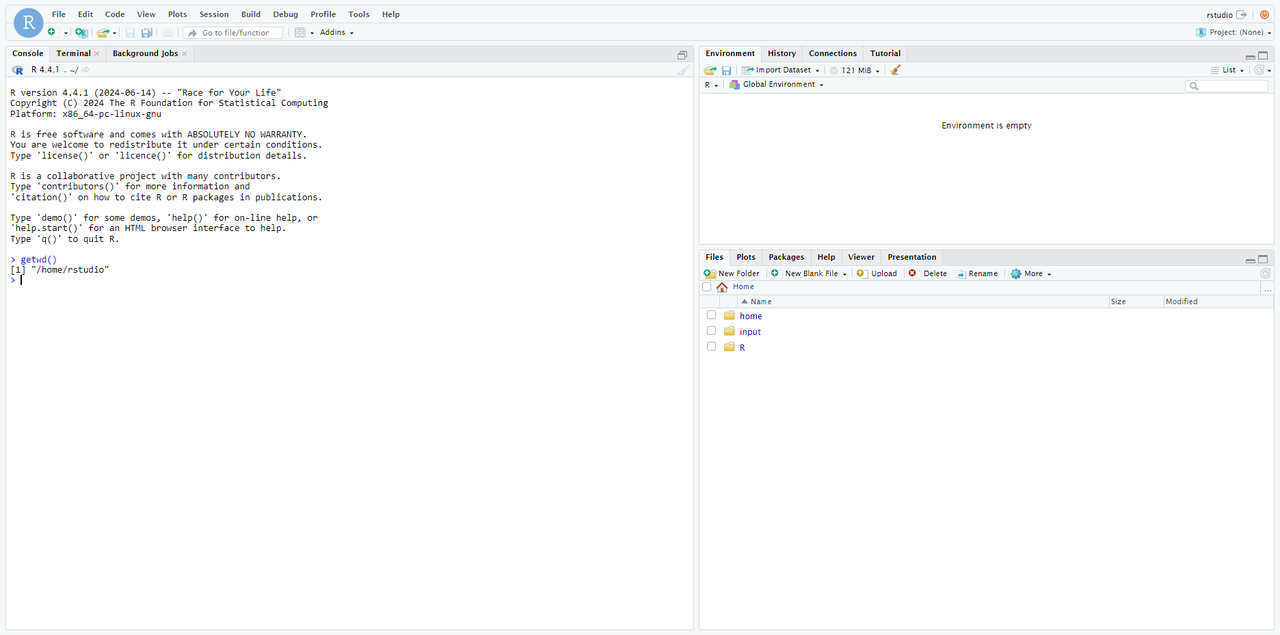
為了方便數據分析,我們可輸入以下命令將 rstudio 當前工作目錄變更為「/home」,在 home 目錄下新增 data 文件夾和 output 文件夾,將原始數據、輸出結果及源代碼文件均存放在 home 文件夾中。
setwd("~/home")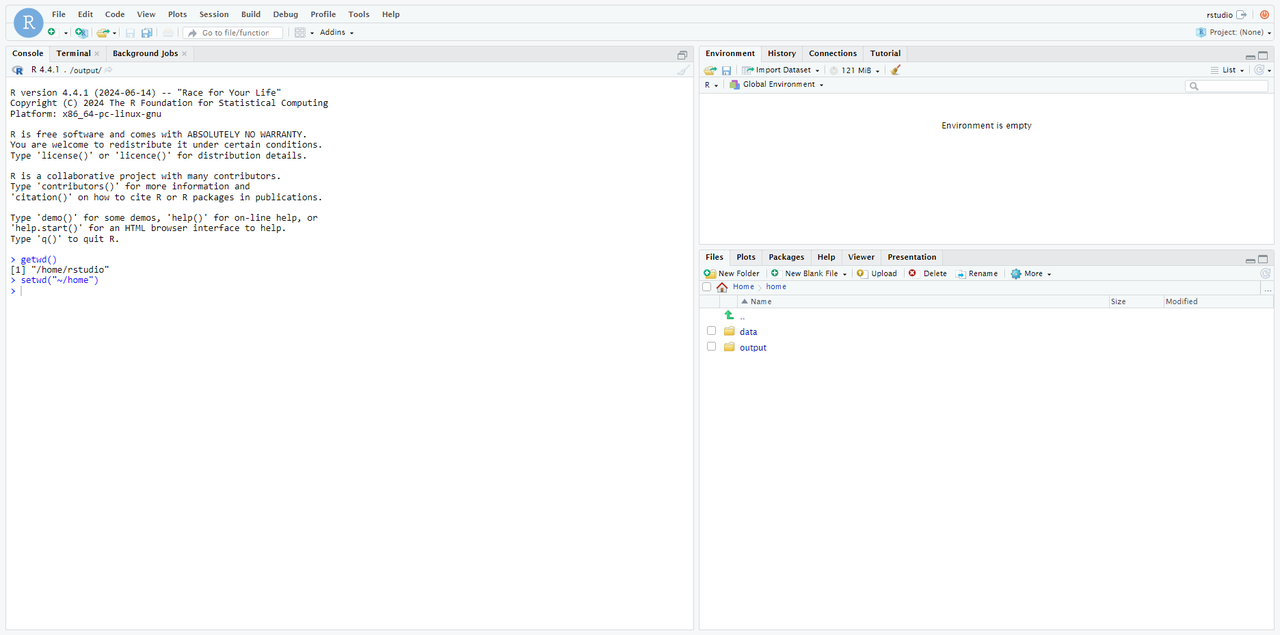
二、數據準備
將準備好的 Excel 數據文件,上傳至當前工作目錄下。本教程使用的數據集為「PHQ 心理學抑郁量表的測評數據」,是模擬心理學上一個比較常用的量表抑郁量表的測評數據。
獲取數據集:https://go.openbayes.com/6uF7Y
運行以下命令讀取準備好的 PHQ.xlsx 中的第 2 個 sheet。
library(readxl)
df <- read_excel("~/home/data/PHQ.xlsx",1)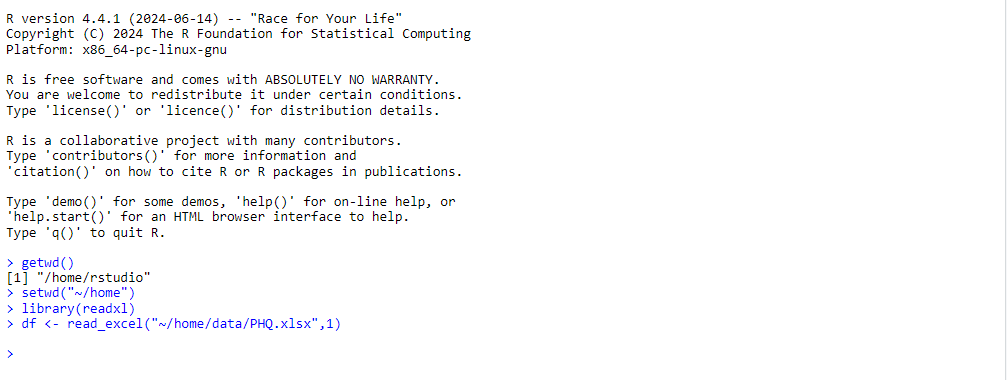
讀取完成后在運行以下代碼,讀取它的前五行。
head(df)
對數據進行初步預處理,核查:第一,數據類型;第二,分類因子化;第三,是否有缺失值。
分類因子化:
factor(df$gender,ordered = TRUE)
factor(df$grade,ordered = TRUE)數據類型:
str(df) #確認各列數據的類型查看是否有缺失值:
sum(is.na(df))#查看是否有缺失值
na.omit(df)#如果有缺失值,刪除缺失值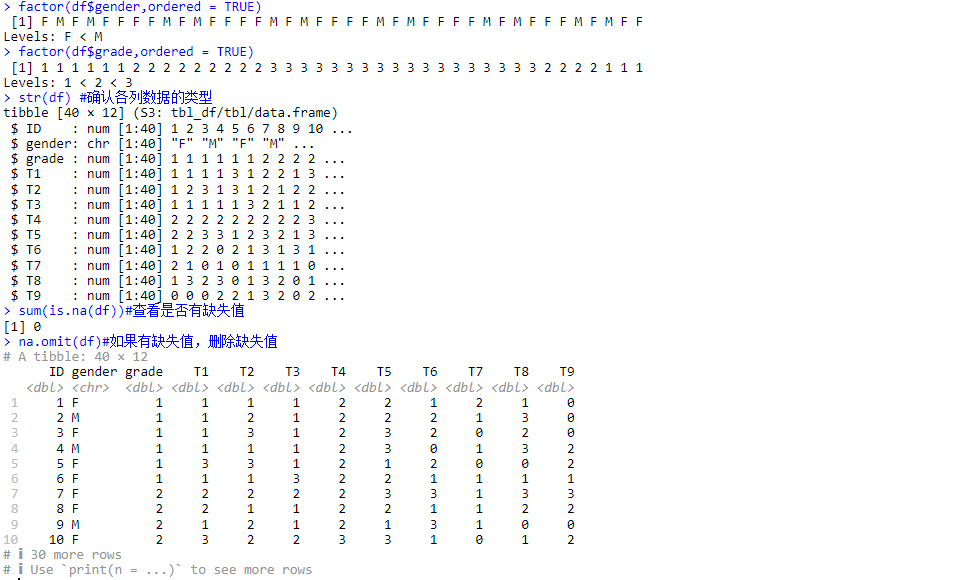
三、數據分析
- 計算量表總分
輸入以下命令對 4—12 列按行求和。
df$phq <- apply(df[c(4:12)],1,sum)
head(df)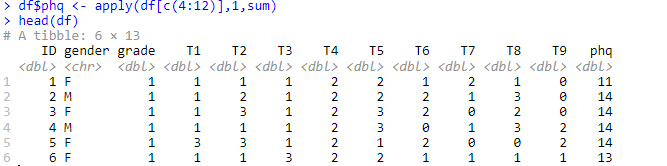
得到計算結果后要對分數進行劃分,這里 PHQ 量表的劃分標準為:1-4 分正常,5-9 分輕度抑郁,10-14 分中度抑郁,15-19 分中重度抑郁,20-27 分重度抑郁。輸入以下命令,模型即可按照標準劃分。
df$level <- cut(df$phq,c(0,4,9,14,19,27),labels = c("正常","輕","中","中重","重"))
df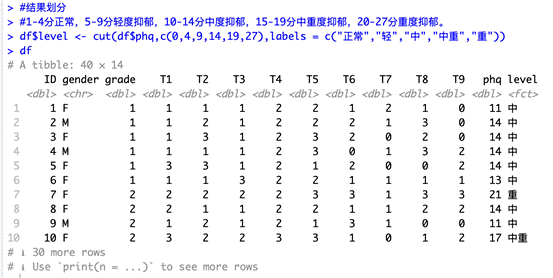
得到劃分結果后,要對數據進行描述統計。首先需要安裝「psych」,輸入以下命令進行安裝。
library(psych)安裝完成后輸入以下命令加載「psych」。
phqdescri <- psych::describe(df)
phqdescri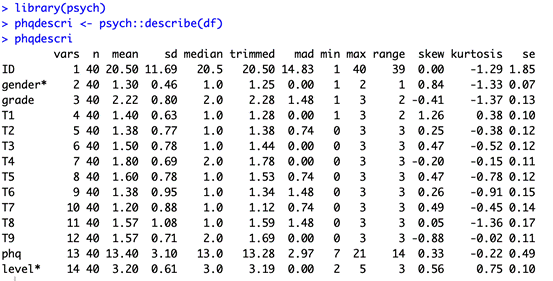
2. 不同得分等級的數量匯總分析
輸入以下命令,對不同的分等級的數量進行匯總。
levelphq <- table(df$level) #各等級的數量
levelphq然后輸入以下命令,按年級和性別分類匯總不同等級下的數量分布。
genderlevel <- df l>subset(select=c(gender,level))l>table()l> addmargins() #不同性別抑郁等級分布情況
genderlavelgenderlevel <- df l>subset(select=c(gender,level))l>table()l> addmargins() #不同年級抑郁等級分布情況
genderlavel
3. 計算得分均值
利用「psych」包中的「describeBy」函數計算得分均值,輸入以下命令即可開始計算。
henderDescri <-psych::describeBy(df[c("phq")],list(df$gender))#不同性別得分差異
genderDescrihenderDescri <-psych::describeBy(df[c("phq")],list(df$gende))#不同年級得分差異
genderDescri
4. 信度分析
運行以下命令,利用「psych」包中的「alpha」函數進行信度分析。
#信度分析
library(psych)
phqr <-alpha(df[,c(4:12)])
phqr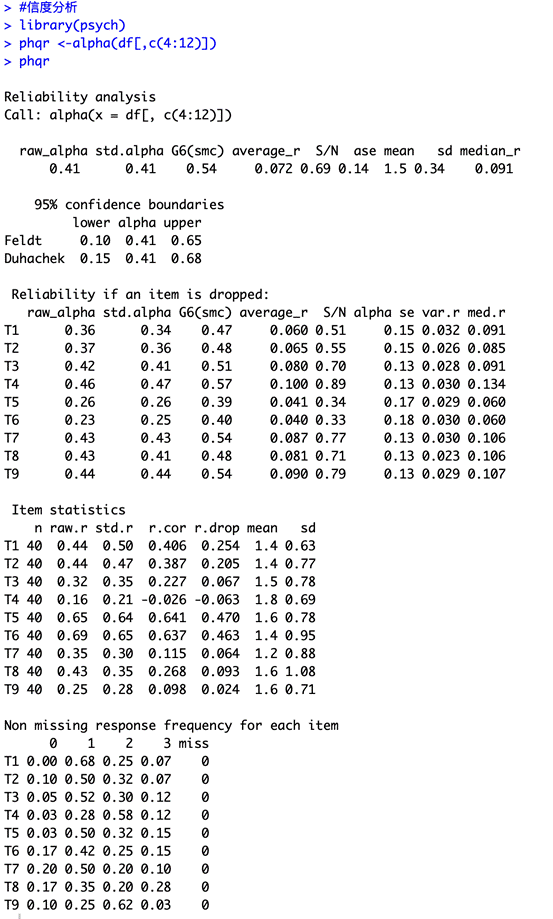
5. 計算量表信度
利用「psych」包中的「corr」函數可以進行題總相關的信度分析。
rr <- corr.test(df[,c(4:12)],df$phq)
rr$r #提取相關系數rr$p #提取p值resultphq <- round(rr$p,3)#保存結果,設置小數點后位數為3位
conlnames(result) <- c("phq")#修改結果中的列表為phq
resultphq
四、報告保存
保存結果需要用到「writexl」包,運行以下命令安裝。
install.packages("writexl")
安裝完成之后,輸入以下命令加載。
library(writexl)我們在上述分析時,每一步分析都會把分析結果保存,命名為一個名稱。然后把這些命名的對象創建成一個列表 list。用 sink 函數在目錄中創建「output」文件夾。將分析結果保存到該文件夾下。
result_list <- list(df,phgdescri,genderDescri,gradeDescri,levelphg,genderlevel,gradelevel ,phqr,resultphq)
sink("~/home/output/outout.txt")
print(result_list)
sink()
最后可以返回控制臺界面查看輸出文件。



 (三))
)
)






- 狀態管理與容錯)


)



 異常問題排查實錄)