前言:
有很多同學想學習大模型開發,又無從下手,網上一搜,鋪天蓋地的付費課程。又不想當韭菜,打破認知障礙,通過自學,改變自己,改變世界!
一、大模型蒸餾、微調、RAG的適用場景
一、技術特性對比
-
?模型蒸餾?
- ?適用場景?:需要將大模型壓縮為輕量級部署版本時(如移動端/邊緣設備),或需快速復現大模型核心能力但計算資源有限時?1。
- ?優勢?:顯著降低推理成本,保留教師模型80%以上能力(如Qwen3-4B蒸餾后性能接近Qwen2.5-72B)?
-
?全參數微調?
- ?適用場景?:需模型掌握特定領域知識(如醫療診斷、金融研報分析)或調整輸出風格(如客服話術定制)?
- ?優勢?:直接優化模型權重,實現領域專業化(如醫療大模型微調后診斷準確率提升15%)?
-
?RAG(檢索增強生成)?
- ?適用場景?:處理動態更新數據(如企業實時業務文檔)或需透明引用來源的場景(如法律咨詢)?
- ?優勢?:無需重新訓練,通過檢索外部知識庫即時更新信息(如金融數據更新周期從周級縮短至分鐘級)?
二、場景選擇決策樹
-
?數據動態性?
- 高頻更新數據 → RAG(如新聞摘要生成)?
- 靜態數據 → 微調或蒸餾(如古籍翻譯)?
-
?能力需求?
- 基座模型不具備的特殊能力 → 微調(如醫療術語生成)?
- 通用能力增強 → 蒸餾(如多語言支持)?
-
?成本約束?
- 低預算/快速迭代 → RAG(檢索成本僅為微調的1/10)?
- 長期穩定需求 → 微調(一次性投入換取持續性能)?
三、混合應用案例
-
金融風控系統?:
- RAG實時檢索監管政策 + 微調模型生成合規報告?
-
?智能客服?:
- 蒸餾模型處理常規咨詢 + LoRA微調實現品牌話術適配?
二、微調模型LoRA
論文原文:https://arxiv.org/abs/2106.0968
LoRA是什么
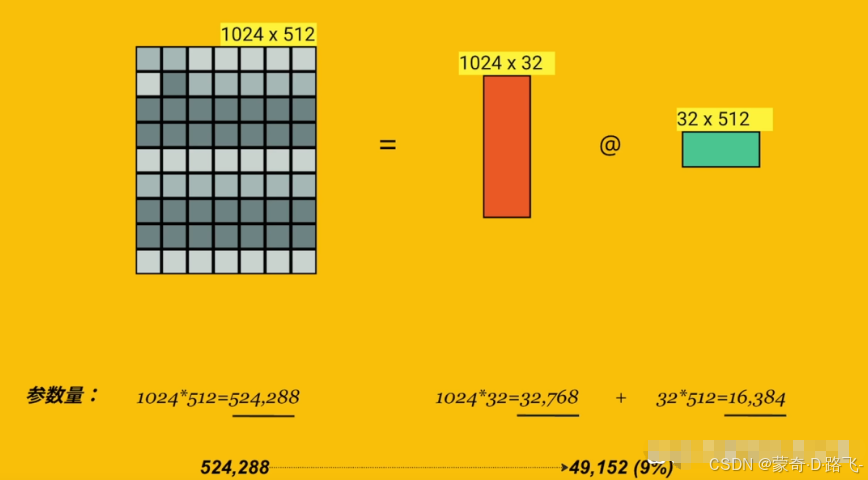
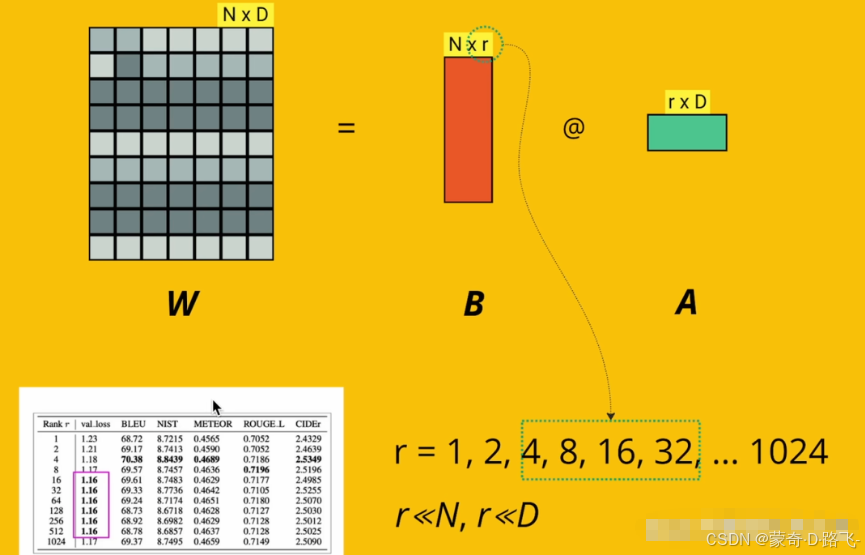
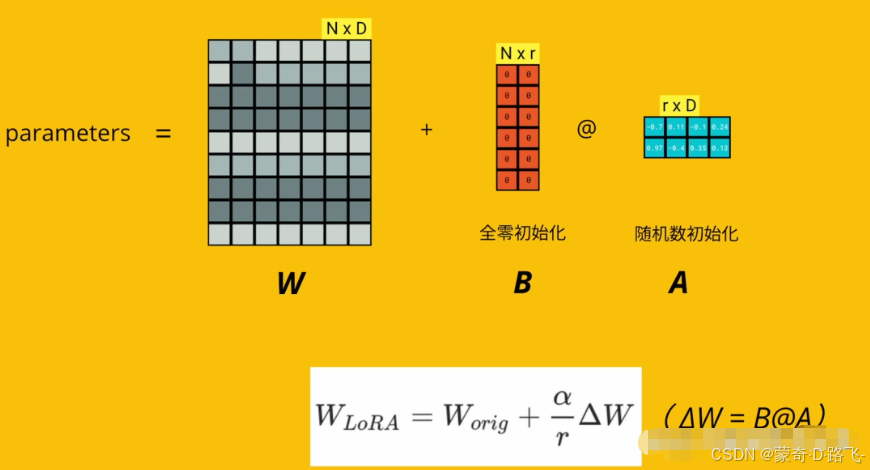
LORA (Low-Rank Adaptation) 微調是一種針對大規模預訓練模型的優化技術,用于在較少計算資源和數據的情況下,對這些模型進行有效微調。
LORA通過引入低秩矩陣來減少模型參數的更新量,進而顯著降低訓練的計算開銷,同時保持微調的性能。由于LLM參數量巨大,直接微調耗費大量資源,LORA的做法是凍結模型的絕大部分參數,只更新很小一部分參數。這就像修車時不需要重造整輛車,而是只修理一些特定的部件。
矩陣的秩是指矩陣中線性無關行或列的最大數量,低秩矩陣表示矩陣的秩較低。
LoRa的使用小技巧
-
進行LoRA高效的模型微調,重點是保持參數尺寸最小化。
-
使用PEFT庫來實現LORA,避免復雜的編碼需求。
-
將LORA適應擴展到所有線性層,增強整體模型的能力。
-
保持偏置層歸一化可訓練,因為它們對模型的適應性至關重要,并且不需要低秩適應。
-
應用量化低秩適應 (QLORA)以節省GPU顯存并訓練模型,從而能夠訓練更大的模型。
三、ms-swift?
github : https://github.com/modelscope/ms-swift
論文:https://arxiv.org/abs/2408.05517
Swift3.x中文文檔 https://swift.readthedocs.io/zh-cn/latest/
魔搭社區官網: https://modelscope.cn/home
ms-swift是什么?
ms-swift是魔搭社區提供的大模型與多模態大模型微調部署框架,現已支持450+大模型與150+多模態大模型的訓練(預訓練、微調、人類對齊)、推理、評測、量化與部署。
其中大模型包括:Qwen2.5、InternLM3、GLM4、Llama3.3、Mistral、DeepSeek-R1、Yi1.5、TeleChat2、Baichuan2、Gemma2等模型;
多模態大模型包括:Qwen2.5-VL、Qwen2-Audio、Llama3.2-Vision、Llava、InternVL2.5、MiniCPM-V-2.6、GLM4v、Xcomposer2.5、Yi-VL、DeepSeek-VL2、Phi3.5-Vision、GOT-OCR2等模型。
🍔 除此之外,ms-swift匯集了最新的訓練技術,包括LoRA、QLoRA、Llama-Pro、LongLoRA、GaLore、Q-GaLore、LoRA+、LISA、DoRA、FourierFt、ReFT、UnSloth、和Liger等輕量化訓練技術,以及DPO、GRPO、RM、PPO、KTO、CPO、SimPO、ORPO等人類對齊訓練方法。
ms-swift支持使用vLLM和LMDeploy對推理、評測和部署模塊進行加速,并支持使用GPTQ、AWQ、BNB等技術對大模型進行量化。ms-swift還提供了基于Gradio的Web-UI界面及豐富的最佳實踐。
?
為什么選擇ms-swift?
🍎 模型類型:支持450+純文本大模型、150+多模態大模型以及All-to-All全模態模型、序列分類模型、Embedding模型訓練到部署全流程。
數據集類型:內置150+預訓練、微調、人類對齊、多模態等各種類型的數據集,并支持自定義數據集。
硬件支持:CPU、RTX系列、T4/V100、A10/A100/H100、Ascend NPU、MPS等。
🍊 輕量訓練:支持了LoRA、QLoRA、DoRA、LoRA+、ReFT、RS-LoRA、LLaMAPro、Adapter、GaLore、Q-Galore、LISA、UnSloth、Liger-Kernel等輕量微調方式。
分布式訓練:支持分布式數據并行(DDP)、device_map簡易模型并行、DeepSpeed ZeRO2 ZeRO3、FSDP等分布式訓練技術。
量化訓練:支持對BNB、AWQ、GPTQ、AQLM、HQQ、EETQ量化模型進行訓練。
RLHF訓練:支持純文本大模型和多模態大模型的DPO、GRPO、RM、PPO、KTO、CPO、SimPO、ORPO等人類對齊訓練方法。
🍓 多模態訓練:支持對圖像、視頻和語音不同模態模型進行訓練,支持VQA、Caption、OCR、Grounding任務的訓練。
界面訓練:以界面的方式提供訓練、推理、評測、量化的能力,完成大模型的全鏈路。
插件化與拓展:支持自定義模型和數據集拓展,支持對loss、metric、trainer、loss-scale、callback、optimizer等組件進行自定義。
🍉 工具箱能力:不僅提供大模型和多模態大模型的訓練支持,還涵蓋其推理、評測、量化和部署全流程。
推理加速:支持PyTorch、vLLM、LmDeploy推理加速引擎,并提供OpenAI接口,為推理、部署和評測模塊提供加速。
模型評測:以EvalScope作為評測后端,支持100+評測數據集對純文本和多模態模型進行評測。
模型量化:支持AWQ、GPTQ和BNB的量化導出,導出的模型支持使用vLLM/LmDeploy推理加速,并支持繼續訓練。
?
SWIFT安裝
# 推薦
pip install 'ms-swift'
# 使用評測
pip install 'ms-swift[eval]' -U
# 全能力
pip install 'ms-swift[all]' -U源代碼安裝?
# pip install git+https://github.com/modelscope/ms-swift.git# 全能力
# pip install "git+https://github.com/modelscope/ms-swift.git#egg=ms-swift[all]"git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .# 全能力
# pip install -e '.[all]'以上安裝參考官網:SWIFT安裝 — swift 3.8.0.dev0 文檔
支持的硬件
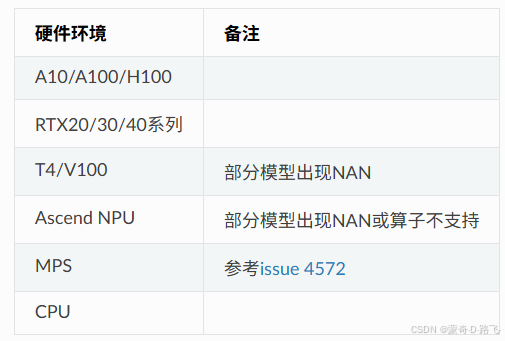
運行環境
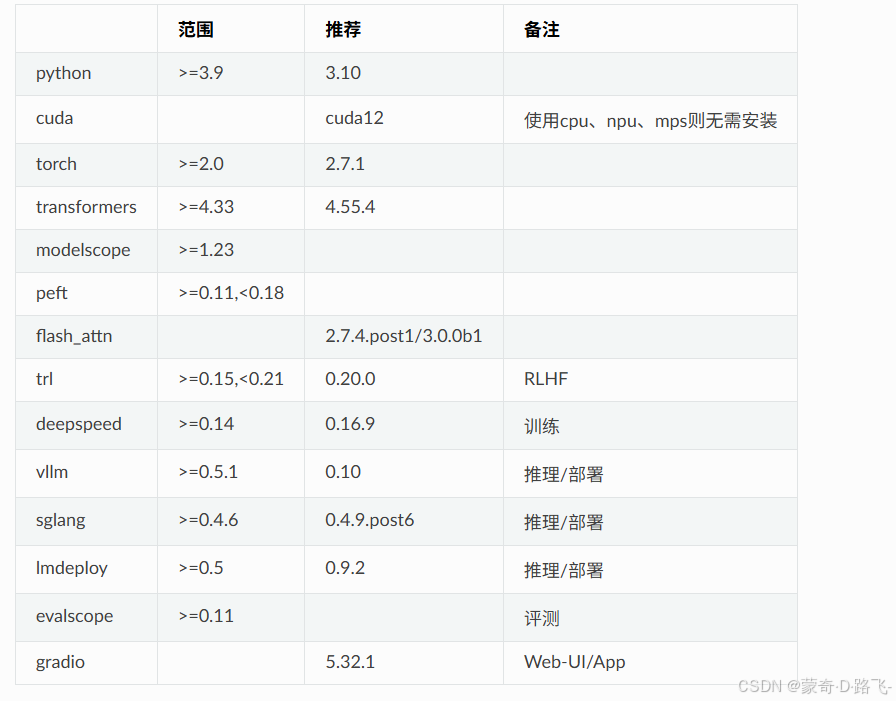
更多參考:https://github.com/modelscope/ms-swift/blob/main/requirements/install_all.sh
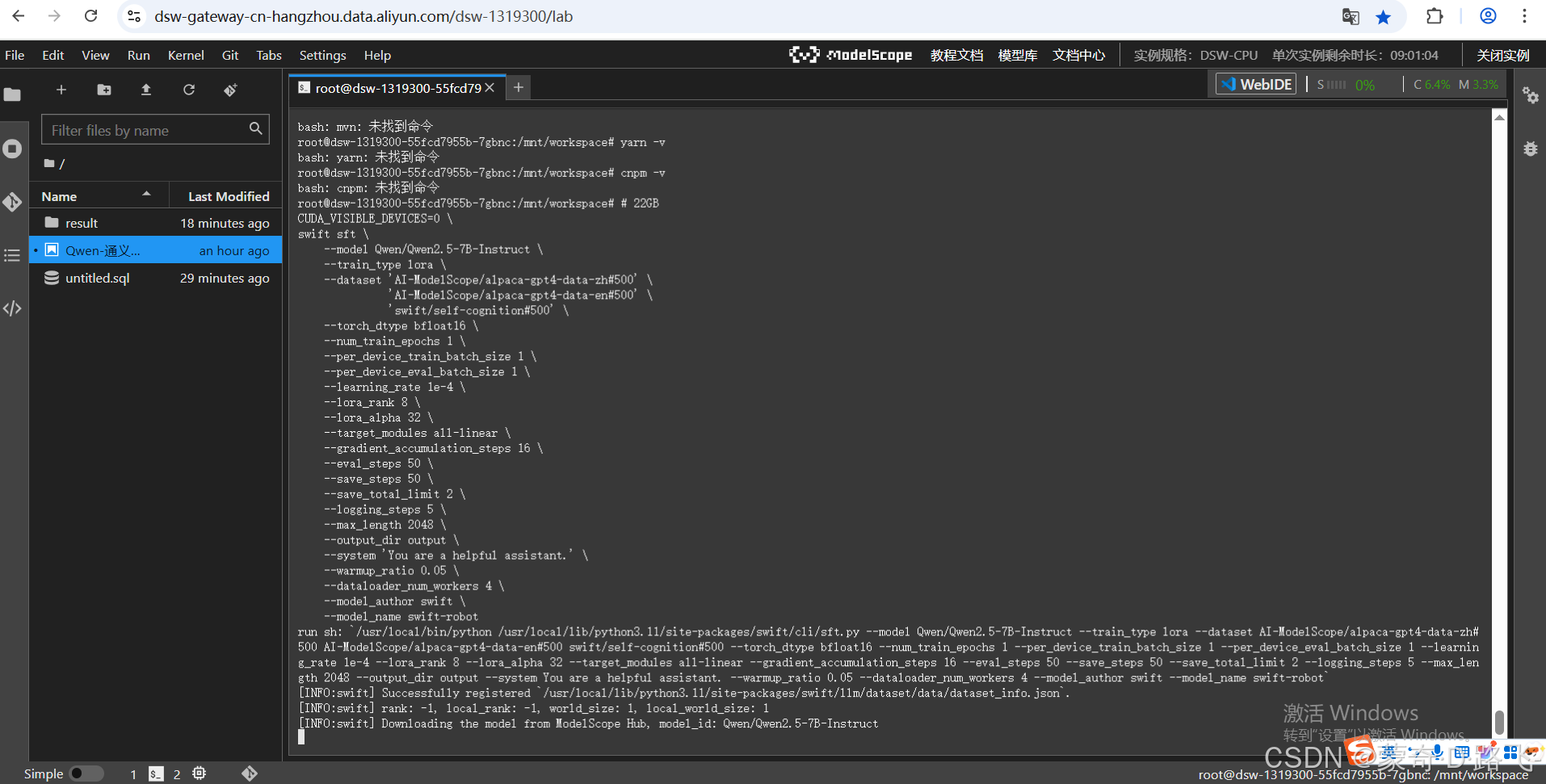
快速開始,微調:
10分鐘在單卡3090上對Qwen2.5-7B-Instruct進行自我認知微調:
# 22GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \--model Qwen/Qwen2.5-7B-Instruct \--train_type lora \--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \'AI-ModelScope/alpaca-gpt4-data-en#500' \'swift/self-cognition#500' \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--learning_rate 1e-4 \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--gradient_accumulation_steps 16 \--eval_steps 50 \--save_steps 50 \--save_total_limit 2 \--logging_steps 5 \--max_length 2048 \--output_dir output \--system 'You are a helpful assistant.' \--warmup_ratio 0.05 \--dataloader_num_workers 4 \--model_author swift \--model_name swift-robot我這里用阿里魔塔社區的免費試用環境:
小貼士:
- 如果要使用自定義數據集進行訓練,你可以參考這里組織數據集格式,并指定
--dataset <dataset_path>。 --model_author和--model_name參數只有當數據集中包含swift/self-cognition時才生效。- 如果要使用其他模型進行訓練,你只需要修改
--model <model_id/model_path>即可。 - 默認使用ModelScope進行模型和數據集的下載。如果要使用HuggingFace,指定
--use_hf true即可。
訓練完成后,使用以下命令對訓練后的權重進行推理:
- 這里的
--adapters需要替換成訓練生成的last checkpoint文件夾。由于adapters文件夾中包含了訓練的參數文件args.json,因此不需要額外指定--model,--system,swift會自動讀取這些參數。如果要關閉此行為,可以設置--load_args false。
# 使用交互式命令行進行推理
CUDA_VISIBLE_DEVICES=0 \
swift infer \--adapters output/vx-xxx/checkpoint-xxx \--stream true \--temperature 0 \--max_new_tokens 2048# merge-lora并使用vLLM進行推理加速
CUDA_VISIBLE_DEVICES=0 \
swift infer \--adapters output/vx-xxx/checkpoint-xxx \--stream true \--merge_lora true \--infer_backend vllm \--vllm_max_model_len 8192 \--temperature 0 \--max_new_tokens 2048最后,使用以下命令將模型推送到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \--adapters output/vx-xxx/checkpoint-xxx \--push_to_hub true \--hub_model_id '<your-model-id>' \--hub_token '<your-sdk-token>' \--use_hf falseWeb-UI
我這里用阿里魔塔社區的免費試用環境:
swift web-ui --lang zh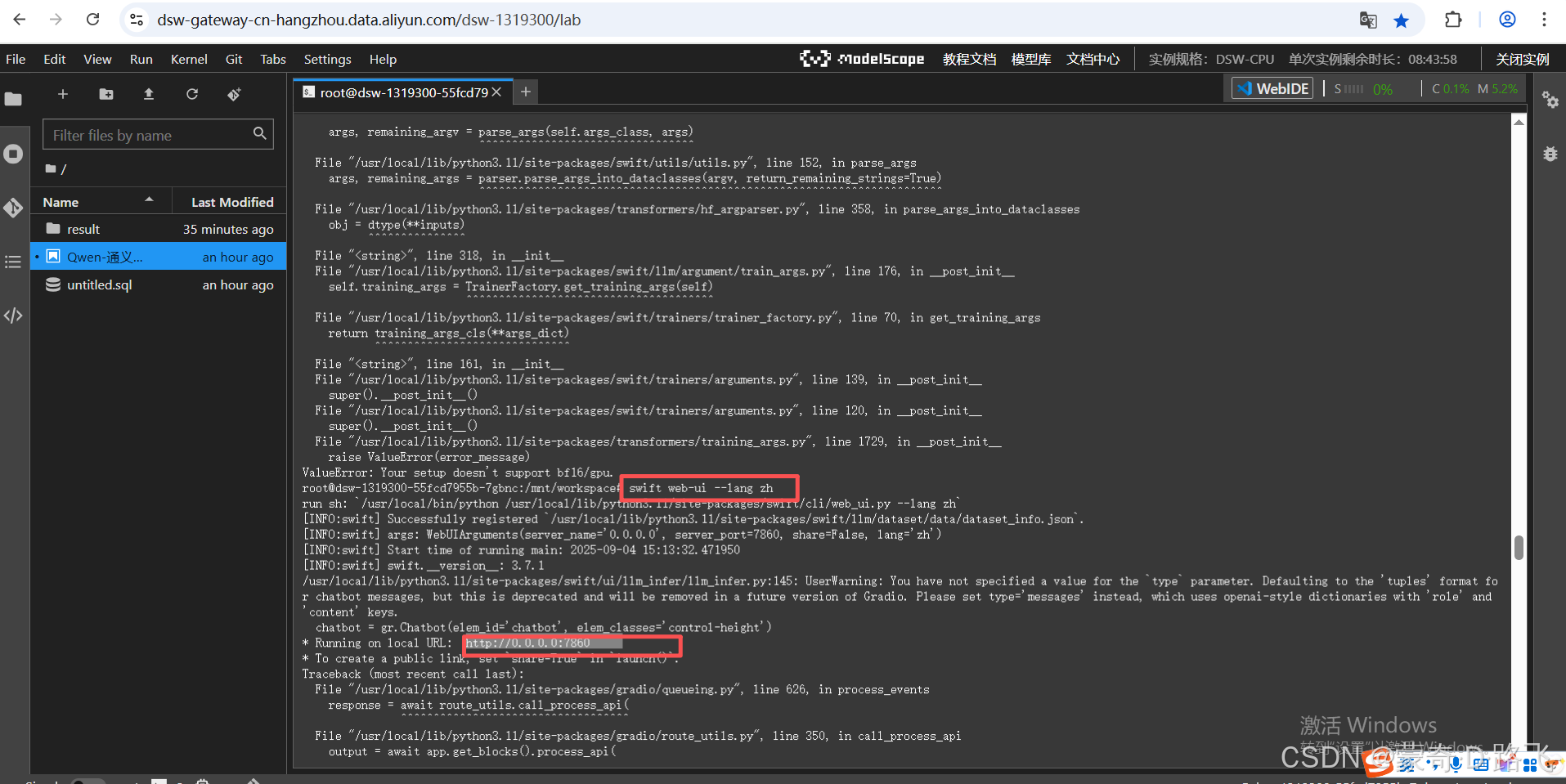
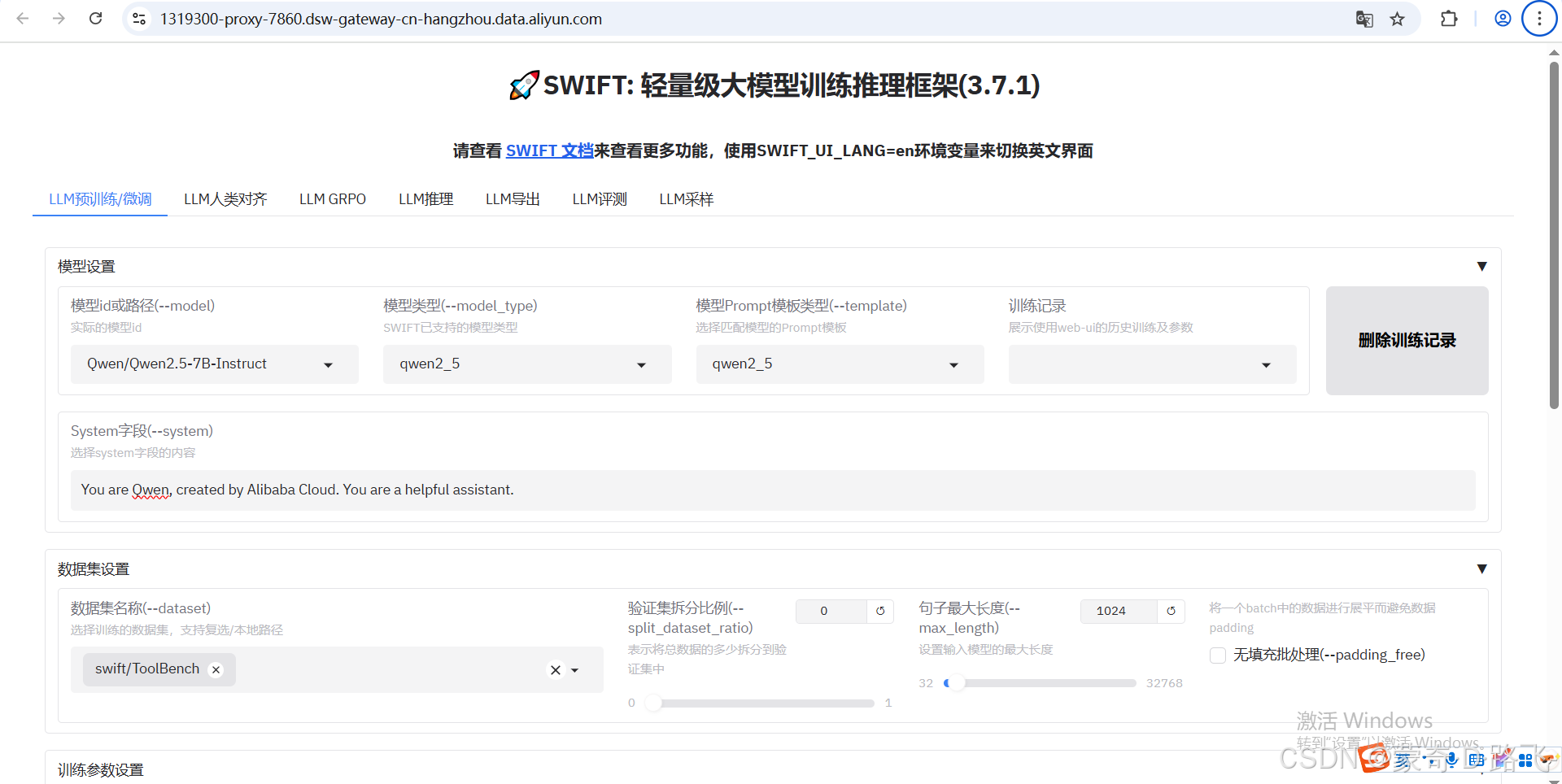
啟動后,在瀏覽器訪問,都可以在界面上操作了!
導出與推送
https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%AF%BC%E5%87%BA%E4%B8%8E%E6%8E%A8%E9%80%81.html
推送模型
SWIFT支持將訓練/量化的模型重新推送到ModelScope/HuggingFace。默認推送到ModelScope,你可以指定--use_hf?true推送到HuggingFace。
swift export \--model output/vx-xxx/checkpoint-xxx \--push_to_hub true \--hub_model_id '<model-id>' \--hub_token '<sdk-token>' \--use_hf false小貼士:
-
你可以使用
--model?<checkpoint-dir>或者--adapters?<checkpoint-dir>指定需要推送的checkpoint目錄,這兩種寫法在推送模型場景沒有差異。 -
推送到ModelScope時,你需要確保你已經注冊了魔搭賬號,你的SDK token可以在該頁面中獲取。推送模型需確保sdk token的賬號具有model_id對應組織的編輯權限。推送模型將自動創建對應model_id的模型倉庫(如果該模型倉庫不存在),你可以使用
--hub_private_repo?true來自動創建私有的模型倉庫。
寫在結尾:
? ? ? ?引用魯迅先生的《秋夜》中的一句話:“我家后院有兩棵樹,一棵是棗樹,另一棵也是棗樹”,在這個浮躁的社會,即使你當下的內心是彷徨、孤寂、苦悶的,每一個在時代洪流中掙扎卻依然挺立的人?。在這個浮躁的時代,我們或許無法改變世界,但至少可以像棗樹一樣——?在沉默中生長,在黑暗中抗爭?。

)






)
)




算法詳解與應用)


)

