精選專欄鏈接 🔗
- MySQL技術筆記專欄
- Redis技術筆記專欄
- 大模型搭建專欄
- Python學習筆記專欄
- 深度學習算法專欄
歡迎訂閱,點贊+關注,每日精進1%,與百萬開發者共攀技術珠峰
更多內容持續更新中!希望能給大家帶來幫助~ 😀😀😀
詳解MySQL子查詢
- 1,什么是子查詢
- 2,從具體需求理解子查詢
- 3,子查詢的分類
- 4,單行子查詢實戰
- 4.1,普通的單行子查詢
- 4.2,HAVING子句中的單行子查詢
- 4.3,CASE中的單行子查詢
- 5,多行子查詢實戰
- 5.1,多行子查詢實戰
- 5.2,多行子查詢的空值問題
- 6,相關子查詢和不相關子查詢
- 6.1,相關子查詢的執行流程
- 6.2,不相關子查詢與相關子查詢對比
- 6.3,在ORDER BY 中使用關聯子查詢
- 6.4,案例進階
- 6.5,EXISTS 與 NOT EXISTS關鍵字
- 7,子查詢和自連接效率
1,什么是子查詢
子查詢指一個查詢語句嵌套在另一個查詢語句內部的查詢。 SQL 中子查詢的使用大大增強了 SELECT 查詢的能力,因為很多時候查詢需要從結果集中獲取數據,或者需要從同一個表中先計算得出一個數據結果,然后與這個數據結果(可能是某個標量,也可能是某個集合)進行比較。
2,從具體需求理解子查詢
需求:查詢employees表中誰的工資比 Abel 高
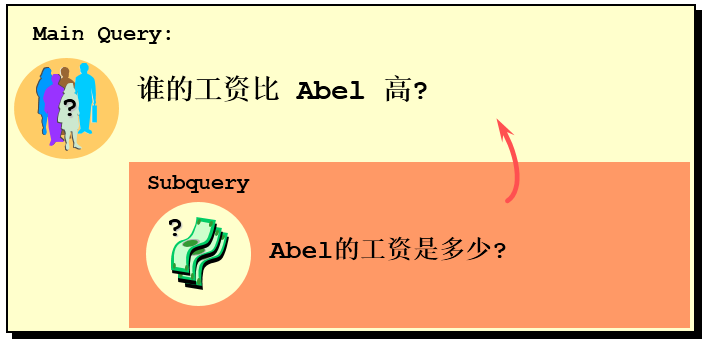
針對此需求,有多種實現方式可供選擇。
實現方式一 :使用多個SQL語句
先查詢員工Abel的工資:
SELECT salary
FROM employees
WHERE last_name = 'Abel';
運行結果如下:

根據查詢結果進行篩選:
SELECT last_name,salary
FROM employees
WHERE salary > 11000;
運行結果如下:

此實現方式與數據庫進行了兩次交互,效率較低。
實現方式二:使用自連接
SQL語句如下:
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e2.`salary` > e1.`salary`
AND e1.last_name = 'Abel';
運行結果如下:

自連接的實現方式通過聯表將符合連接條件的記錄拼接在一起進行查詢。只需與數據庫進行一次交互,效率高于方式一。
實現方式三:使用子查詢
方式一中是先查詢出 Abel 的工資為11000,然后在第二條SQL語句中通過WHERE salary > 11000 進行過濾,找到符合條件的信息。如果我們不把11000寫死,而是用一段SQL語句實現,那么這就是一個簡單的子查詢。其中:
- 子查詢語句要包含在括號內;
- 外面的SELECT語句稱為主查詢或外查詢,內部的子查詢SELECT語句稱為子查詢或內查詢;
- 子查詢在主查詢之前一次執行完成,子查詢的結果被主查詢使用 ;
SQL示例如下:
SELECT last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE last_name = 'Abel');
運行結果如下:

3,子查詢的分類
- 根據從子查詢中返回的結果的條目數可以分為:單行子查詢和多行子查詢;
- 根據子查詢是否被執行多次可以分為相關子查詢和不相關子查詢;
下面我們會結合具體需求,詳細講解這幾類子查詢。
4,單行子查詢實戰
單行子查詢只返回一個結果數據供主查詢使用。
單行子查詢常結合如下比較操作符:
| 操作符 | 含義 |
|---|---|
| = | 等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| <> | 不等于 |
4.1,普通的單行子查詢
需求一:查詢工資大于149號員工工資的員工的信息
SQL語句如下:
SELECT employee_id,last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE employee_id = 149);
需求二:返回job_id與141號員工相同,salary比143號員工多的員工姓名,job_id和工資
SQL語句如下:
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = (SELECT job_idFROM employeesWHERE employee_id = 141)
AND salary > (SELECT salaryFROM employeesWHERE employee_id = 143);
運行結果如下:
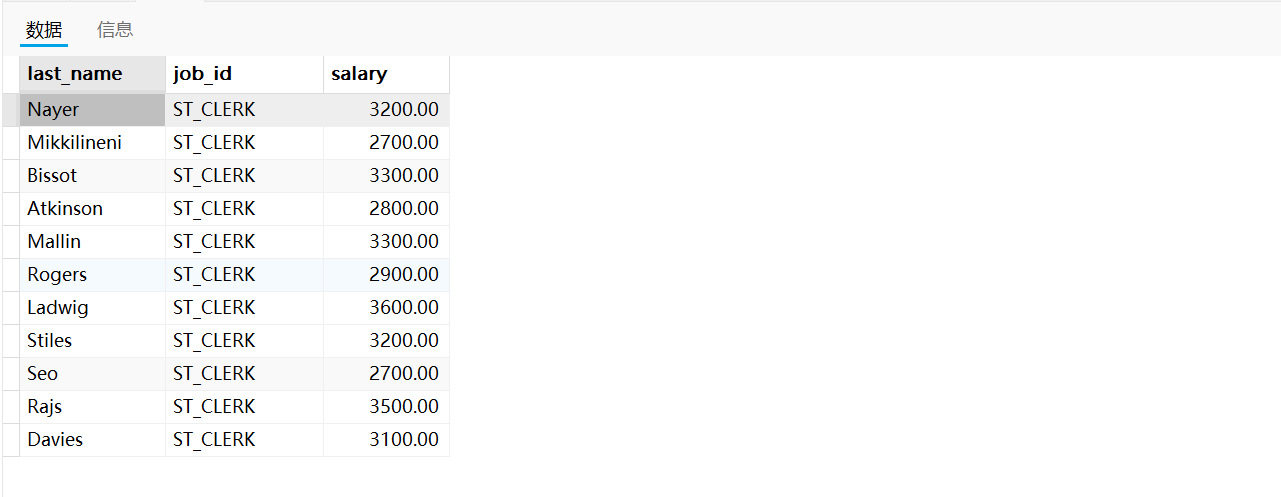
需求三:返回公司工資最少的員工的last_name、job_id和salary
SQL語句如下:
SELECT last_name, job_id, salary
FROM employees
# 即找出工資等于最少工資的所有員工的信息
WHERE salary = (SELECT MIN(salary)FROM employees);
運行結果如下:

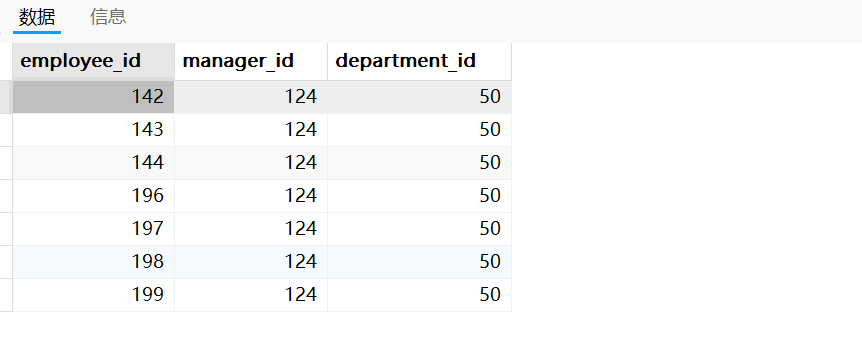
需求四:查詢與141號員工的manager_id和department_id相同的其他員工的employee_id,manager_id,department_id。
實現方式一:
SELECT employee_id,manager_id,department_id
FROM employees
WHERE manager_id = (SELECT manager_idFROM employeesWHERE employee_id = 141)
AND department_id = (SELECT department_idFROM employeesWHERE employee_id = 141)
AND employee_id <> 141;
實現方式二(了解):成對查詢
SELECT employee_id,manager_id,department_id
FROM employees
WHERE (manager_id,department_id) = (SELECT manager_id,department_idFROM employeesWHERE employee_id = 141)
AND employee_id <> 141;
以上兩種實現方式返回的運行結果相同,如下圖所示:
4.2,HAVING子句中的單行子查詢
需求:查詢最低工資大于110號部門最低工資的部門id和其最低工資
SELECT department_id,MIN(salary)
FROM employees
WHERE department_id IS NOT NULL # 過濾掉department_id為NULL的部門
GROUP BY department_id
HAVING MIN(salary) > (SELECT MIN(salary)FROM employeesWHERE department_id = 110);
這是一個HAVING子句中使用單行子查詢的例子。
4.3,CASE中的單行子查詢
需求:查詢員工的employee_id,last_name和一個新字段location。其中,若員工department_id與location_id為1800的department_id相同,則location為’Canada’,其余則為’USA’。
SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id = 1800) THEN 'Canada'ELSE 'USA' END "location"
FROM employees;
運行結果如下:

5,多行子查詢實戰
子查詢返回多行數據即為多行子查詢,也可稱為集合比較子查詢。
多行子查詢使用的時候常結合多行比較操作符,如下:
| 操作符 | 含義 |
|---|---|
| IN | 等于列表中的任意一個 |
| ANY | 需要和單行比較操作符一起使用,和子查詢返回的某一個值比較 |
| ALL | 需要和單行比較操作符一起使用,和子查詢返回的所有值比較 |
| SOME | 實際上是ANY的別名,作用相同,一般常使用ANY |
5.1,多行子查詢實戰
需求一:找出所有工資等于任意部門最低工資的員工(無論其所屬部門)
SQL語句如下:
SELECT employee_id, last_name
FROM employees
WHERE salary IN(SELECT MIN(salary)FROM employeesGROUP BY department_id);
運行結果如下:

需求二:返回
其它job_id中比job_id為‘IT_PROG’部門任意一個工資低的員工的員工號、姓名、job_id 以及salary
SQL代碼如下:
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ANY (SELECT salaryFROM employeesWHERE job_id = 'IT_PROG');
運行結果如下:
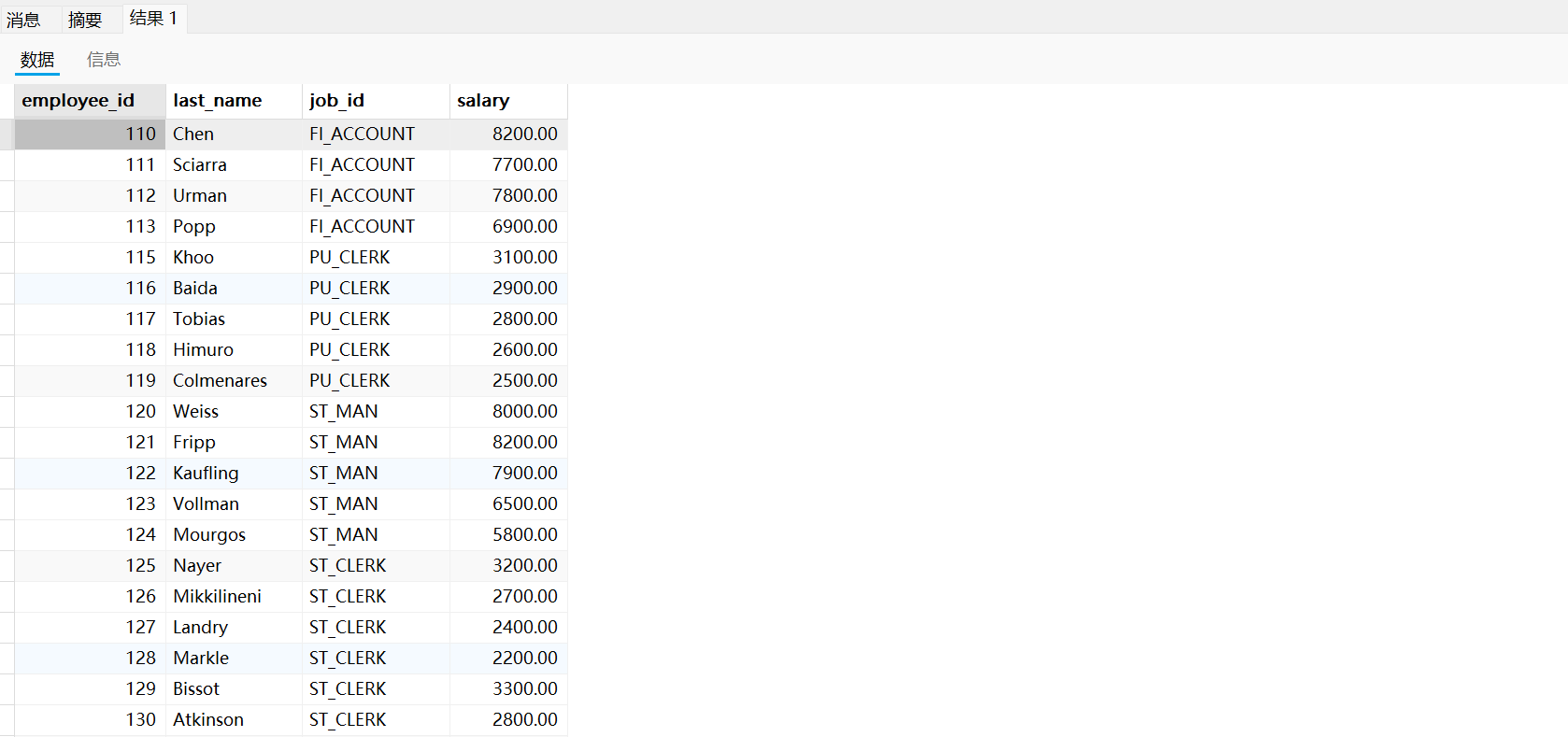
需求三:返回
其它job_id中比job_id為 ‘IT_PROG’ 部門所有工資低的員工的員工號、姓名、job_id 以及salary
SQL代碼如下:
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ALL (SELECT salaryFROM employeesWHERE job_id = 'IT_PROG');
運行結果如下:
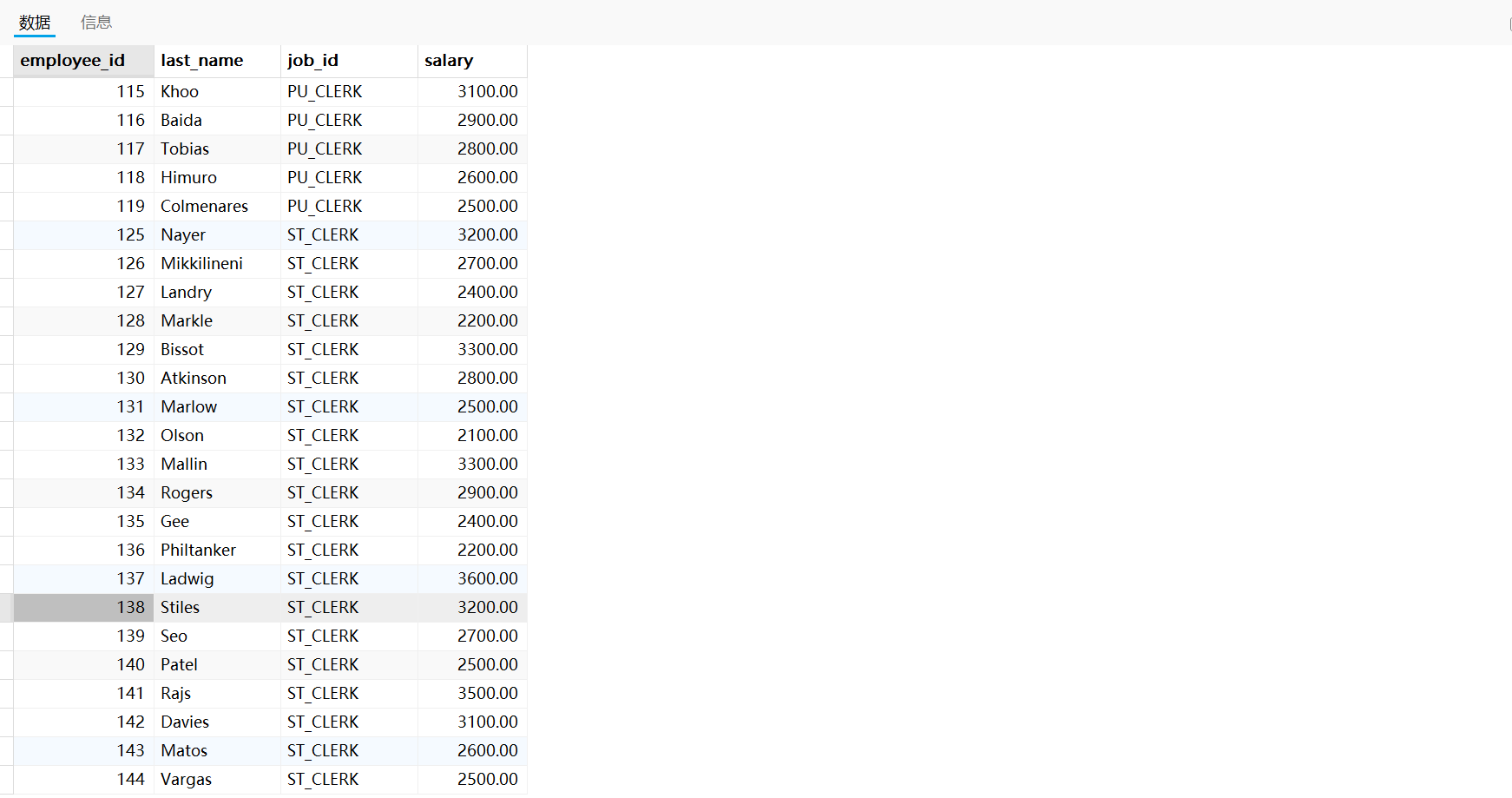
需求四:查詢平均工資最低的部門 id
實現方式一: 先求各部門的最低平均工資,然后看哪個部門的最低平均工資等于此最低平均工資
求最低平均工資時的錯誤SQL示例:
SELECT MIN(AVG(salary))
FROM employees
GROUP BY department_id;
運行報錯,錯誤原因:MySQL中不支持聚合函數的嵌套使用。
針對此需求,我們可以發散思維:可以將查詢出的各個部門的平均工資結果形成一張中間表t1,平均工資是其中的一個字段,然后對此字段再次做聚合操作(求Min)。
求最低平均工資的正確SQL示例如下:
SELECT MIN(avg_sal)
FROM (SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id
) t_dept_avg_sal # 注意此處需要給表起別名,否則報錯此時 avg_sal 相當于 t_dept_avg_sal 表的一個字段,巧妙地避開了聚合函數的嵌套。
因此,實現此需求的完整SQL代碼如下:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (SELECT MIN(avg_sal)FROM (SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id) t_dept_avg_sal # 注意此處需要給表起別名,否則報錯
)
運行結果如下:

實現方式二: 看作多行查詢,借助ALL操作符實現
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL( SELECT AVG(salary) avg_salFROM employeesGROUP BY department_id)
運行結果如下:

5.2,多行子查詢的空值問題
多行子查詢的空值問題使開發中尤其需要注意的問題。子查詢返回的結果如果有NULL值時需要特別注意!!!
接下來我們結合具體場景分析空值問題。
需求一:查出employees表中所有的管理者的last_name
SQL語句如下:
SELECT last_name
FROM employees
WHERE employee_id IN (SELECT manager_idFROM employees);
運行結果如下:

需求二:查出employees表中所有的
非管理者的last_name
運行如下SQL語句:
SELECT last_name
FROM employees
WHERE employee_id NOT IN (SELECT manager_idFROM employees);
發現查出的結果為空:

錯誤分析:原因是子查詢返回的結果存在NULL值,則會導致最終返回空。
正確的SQL語句是:
SELECT last_name
FROM employees
WHERE employee_id NOT IN (SELECT manager_idFROM employeesWHERE manager_id IS NOT NULL);
運行結果如下:

6,相關子查詢和不相關子查詢
根據子查詢是否被執行多次可以分為相關子查詢和不相關子查詢。我們前面講到的場景都是不相關子查詢,因此本節我們重點理解相關子查詢。
6.1,相關子查詢的執行流程
如果子查詢的執行依賴于外部查詢,通常情況下都是因為子查詢中的表用到了外部的表,并進行了條件關聯,因此每執行一次外部查詢,子查詢都要重新計算一次,這樣的子查詢就稱之為相關子查詢。
相關子查詢按照一行接一行的順序執行,主查詢的每一行都執行一次子查詢。
6.2,不相關子查詢與相關子查詢對比
需求一:查詢員工中工資大于
公司平均工資的員工的last_name,salary和其department_id
SQL語句如下:
SELECT last_name,salary,department_id
FROM employees
WHERE salary > (SELECT AVG(salary)FROM employees);
子查詢執行一次,所以此案例為不相關子查詢。
需求二:查詢員工中工資大于
本部門平均工資的員工的last_name,salary和其department_id
SQL語句如下:
SELECT last_name,salary,department_id
FROM employees e1
WHERE salary > (SELECT AVG(salary)FROM employees e2WHERE department_id = e1.`department_id`);
顯然 每執行一次外部查詢,子查詢都要重新計算一次 ,所以此案例為相關子查詢。
此外,需求二還有另外一種實現方式:在FROM中聲明子查詢
SELECT e.last_name,e.salary,e.department_id
FROM employees e,(SELECT department_id,AVG(salary) avg_salFROM employeesGROUP BY department_id) t_dept_avg_sal
WHERE e.department_id = t_dept_avg_sal.department_id
AND e.salary > t_dept_avg_sal.avg_sal
第二種實現方式不屬于相關子查詢,但是也可以達到同樣的效果。
6.3,在ORDER BY 中使用關聯子查詢
需求:查詢員工的id,salary,按照department_name 升序排序
SELECT employee_id,salary
FROM employees e
ORDER BY (SELECT department_nameFROM departments dWHERE e.`department_id` = d.`department_id`) ASC;
6.4,案例進階
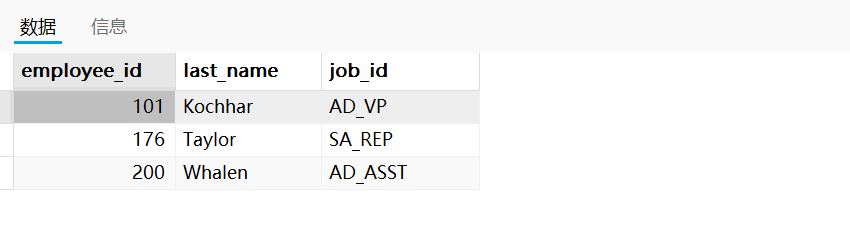
需求:若employees表中employee_id與job_history表(崗位變動信息表)中employee_id相同的數目不小于2,輸出這些相同id的員工的employee_id,last_name和其job_id
SQL語句如下:
SELECT employee_id,last_name,job_id
FROM employees e
WHERE 2 <= (SELECT COUNT(*)FROM job_history jWHERE e.`employee_id` = j.`employee_id`)
運行結果如下:
6.5,EXISTS 與 NOT EXISTS關鍵字
關聯子查詢通常也會和
EXISTS關鍵字一起來使用,用來檢查在子查詢中是否存在滿足條件的行。
- 如果在子查詢中不存在滿足條件的行:
- 條件返回 FALSE
- 繼續在子查詢中查找
- 如果在子查詢中存在滿足條件的行:
- 不在子查詢中繼續查找
- 條件返回 TRUE
NOT EXISTS關鍵字表示如果不存在某種條件,則返回TRUE,否則返回FALSE。
需求一:查詢公司管理者的employee_id,last_name,job_id,department_id信息
實現方式一:自連接
# 去重保證每個管理者只出現一次
SELECT DISTINCT mgr.employee_id,mgr.last_name,mgr.job_id,mgr.department_id
FROM employees emp JOIN employees mgr
ON emp.manager_id = mgr.employee_id;
實現方式二 :子查詢
SELECT employee_id,last_name,job_id,department_id
FROM employees
WHERE employee_id IN ( # 先查出所有管理者的manager_idSELECT DISTINCT manager_idFROM employees);
實現方式三:使用EXISTS
SELECT employee_id,last_name,job_id,department_id
FROM employees e1
# 逐個記錄執行,沒有符合條件的就返回FALSE,有符合條件的就返回TRUE
WHERE EXISTS (SELECT *FROM employees e2WHERE e1.`employee_id` = e2.`manager_id`);
需求二:查詢departments表中,不存在于employees表中的部門的department_id和department_name
SQL代碼如下:
SELECT department_id,department_name
FROM departments d
# 對于傳入子查詢的每一個記錄,都去employees 看有無對應的記錄,有則返回TRUE
WHERE NOT EXISTS (SELECT *FROM employees eWHERE d.`department_id` = e.`department_id`);
需求三 :在employees中增加一個department_name字段,數據為員工對應的部門名稱
SQL語句如下:
UPDATE employees e
SET department_name = (SELECT department_name FROM departments dWHERE e.department_id = d.department_id);
需求四:刪除表employees中,其與emp_history表皆有的數據
DELETE FROM employees e
WHERE employee_id in (SELECT employee_idFROM emp_history WHERE employee_id = e.employee_id);
7,子查詢和自連接效率
回顧需求: 誰的工資比Abel的高?
#方式1:自連接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e1.last_name = 'Abel'
AND e1.`salary` < e2.`salary`
#方式2:子查詢
SELECT last_name,salary
FROM employees
WHERE salary > (SELECT salaryFROM employeesWHERE last_name = 'Abel');
問題: 以上兩種方式有好壞之分嗎?
解答: 自連接方式好!
題目中可以使用子查詢,也可以使用自連接。
一般情況建議使用自連接,因為在許多 DBMS 的處理過程中,對于自連接的處理速度要比子查詢快得多。
可以這樣理解:子查詢實際上是通過未知表進行查詢后的條件判斷,而自連接是通過已知的自身數據表進行條件判斷,因此在大部分 DBMS 中都對自連接處理進行了優化。





)
)




算法詳解與應用)


)



項目)
