點一下關注吧!!!非常感謝!!持續更新!!!
🚀 AI篇持續更新中!(長期更新)
AI煉丹日志-31- 千呼萬喚始出來 GPT-5 發布!“快的模型 + 深度思考模型 + 實時路由”,持續打造實用AI工具指南!📐🤖
💻 Java篇正式開啟!(300篇)
目前2025年09月01日更新到:
Java-113 深入淺出 MySQL 擴容全攻略:觸發條件、遷移方案與性能優化
MyBatis 已完結,Spring 已完結,Nginx已完結,Tomcat已完結,分布式服務正在更新!深入淺出助你打牢基礎!
📊 大數據板塊已完成多項干貨更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余項核心組件,覆蓋離線+實時數倉全棧!
大數據-278 Spark MLib - 基礎介紹 機器學習算法 梯度提升樹 GBDT案例 詳解

數據庫橫向擴容方案詳解
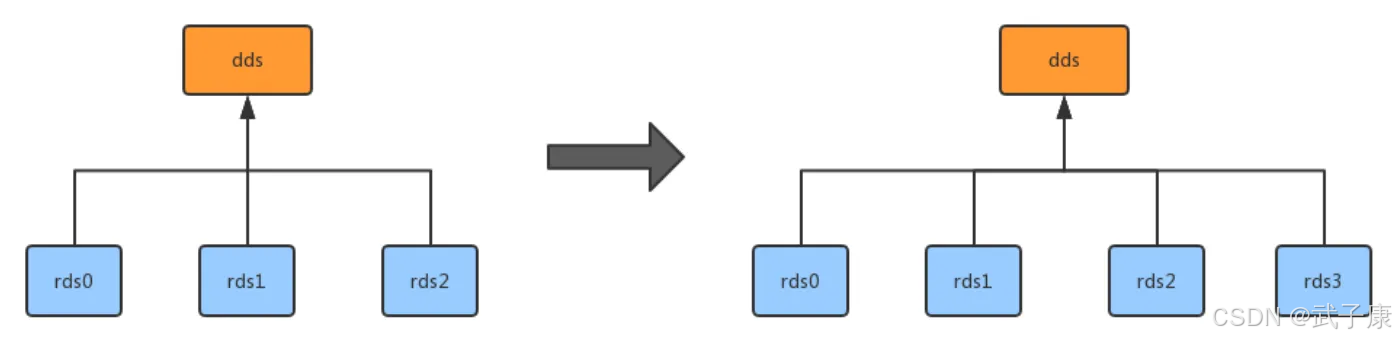
背景與需求
當業務進入高速增長期,系統用戶量和數據量呈現指數級上升時,傳統單一數據庫架構很快就會遇到性能瓶頸。即使已經實施了分庫分表策略,但隨著時間推移,數據庫容量和單表數據量仍會達到物理極限。此時,橫向擴容(Scale-out)成為必要的解決方案。
擴容觸發條件
- 容量指標:當磁盤使用率超過80%且預計3個月內將達到上限
- 性能指標:查詢響應時間持續超過SLA閾值(如>500ms)
- 并發指標:活躍連接數長期維持在最大連接數的70%以上
- 監控報警:周期性出現CPU/IO飽和度報警
橫向擴容實施步驟
1. 評估與規劃階段
- 進行容量評估,計算當前數據增長曲線
- 確定擴容比例(如增加50%節點數)
- 選擇擴容策略:一致性哈希擴容或范圍擴容
2. 數據遷移方案
方案A:在線遷移(推薦)
- 部署新節點并加入集群
- 配置數據同步機制(如MySQL的GTID復制)
- 分批遷移熱點數據
- 切換流量驗證
方案B:停機遷移
- 停止寫入服務
- 全量備份現有數據
- 重新分配數據到新舊節點
- 恢復服務
3. 分片策略調整
- 重構分片鍵(Sharding Key)算法
- 更新路由配置(如MyCat/ShardingSphere配置)
- 測試數據均衡性
4. 應用層適配
- 更新數據源配置
- 調整連接池參數
- 修改可能受影響的SQL語句
常見挑戰與解決方案
-
數據傾斜問題:
- 案例:某電商平臺用戶表按ID哈希分片,導致某些分片數據量是其他分片的3倍
- 解決方案:采用復合分片鍵(如ID+注冊時間)
-
跨分片事務:
- 引入分布式事務框架(如Seata)
- 或采用最終一致性模式
-
擴容成本控制:
- 采用混部策略(SSD+HDD混合存儲)
- 實施冷熱數據分離
最佳實踐案例
某社交平臺在日活用戶突破1000萬時的擴容經驗:
- 從8個分片擴容到12個分片
- 采用在線遷移方式,耗時72小時
- 遷移期間QPS下降控制在15%以內
- 擴容后TP99延遲從800ms降至300ms
監控與后續優化
擴容完成后需要:
- 建立容量預警機制(如每周增長報告)
- 配置自動擴縮容策略(基于K8s或云平臺)
- 定期進行分片均衡檢查
- 規劃下一次擴容窗口
技術選型參考
- 關系型數據庫:MySQL Cluster、PostgreSQL XL
- NoSQL:MongoDB分片集群、Cassandra
- 中間件:ShardingSphere、Vitess、MyCat
- 云服務:AWS Aurora、阿里云PolarDB
停機擴容
擴容方案詳解
這是一種在數據庫架構演進早期階段常用的停機擴容方案,適用于數據庫規模較小且能夠接受短暫服務中斷的場景。下面是完整的具體實施流程:
詳細實施步驟
-
服務公告階段
- 在擴容前3-5天,通過網站橫幅、APP推送、短信等多渠道發布維護公告
- 公告示例:“為提升服務質量,我們將在2023年11月15日00:00-04:00進行系統升級,期間將暫停所有服務”
- 建議選擇業務低峰期(如深夜)進行操作,最小化影響
-
服務停止階段
- 在預定時間點,執行以下操作:
- 關閉負載均衡器流量入口
- 停止所有應用服務進程
- 斷開與原有數據庫的所有連接
- 確認措施:
- 通過監控系統驗證所有外部請求已停止
- 檢查數據庫活動連接數為0
- 在預定時間點,執行以下操作:
-
數據遷移階段
- 新數據庫部署:
- 根據規劃新增N個數據庫實例(如從2個擴展到4個)
- 確保新實例配置(CPU/內存/存儲)與原有實例一致
- 數據遷移程序:
- 編寫特定遷移腳本(可使用Python/Go等語言)
- 示例分片規則變更:從
user_id % 2改為user_id % 4 - 遷移過程需包含數據校驗機制,確保完整性
- 執行遷移:
- 先遷移基礎數據(用戶信息、配置表等)
- 再遷移業務數據(訂單、交易記錄等)
- 新數據庫部署:
-
配置更新階段
- 修改應用配置:
- 更新數據庫連接池配置
- 調整分片路由邏輯
- 修改ORM框架設置
- 測試驗證:
- 在測試環境驗證新配置
- 執行基礎功能測試用例
- 修改應用配置:
-
服務恢復階段
- 按順序啟動:
- 先啟動數據庫服務
- 再啟動應用服務
- 最后恢復負載均衡
- 監控觀察:
- 密切監控系統指標15-30分鐘
- 驗證核心業務流程
- 按順序啟動:
回滾方案
-
回滾觸發條件
- 數據遷移失敗(如完整性校驗不通過)
- 新配置導致服務異常
- 性能指標超出閾值(如CPU使用率>90%持續10分鐘)
-
具體回滾步驟
- 立即停止所有新啟動的服務
- 恢復原有數據庫配置:
- 回退分片規則
- 還原連接池設置
- 數據回退:
- 使用備份恢復原數據庫
- 驗證數據一致性
- 服務恢復:
- 按照原架構重新啟動服務
- 后續計劃:
- 分析失敗原因
- 重新評估擴容方案
- 擇日重新發布公告
方案優缺點
優勢:
- 實施簡單直接,技術難度低
- 不需要復雜的數據同步機制
- 一次性完成架構調整
局限:
- 必須停機操作,影響業務連續性
- 隨著數據量增長,遷移時間會顯著增加
- 不適合7×24小時高可用要求的業務
典型應用場景
- 初創企業早期數據庫擴展
- 內部管理系統升級
- 能接受定時維護的ToB服務
- 數據量在TB級別以下的遷移
注意事項
- 必須提前做好完整備份
- 建議準備詳細的checklist
- 關鍵操作需要雙人復核
- 預留充足緩沖時間(建議實際用時的2倍)
- 準備應急聯絡機制
此方案雖然簡單,但在特定場景下仍然是最可靠的選擇,特別是在沒有專業DBA團隊的中小型企業環境中。隨著業務發展,建議逐步過渡到更高級的在線擴容方案。
停機優點
簡單易用!
停機缺點
● 停止服務,缺乏高可用
● 程序員壓力大,需要在規定的時間內完成
● 如果問題沒有及時測試出來就啟動了,后續發現有問題則會比較麻煩
適用場景
● 小型網站
● 大部分游戲
● 對高可用要求不高的服務
平滑擴容
擴容方案
數據庫擴容是系統規模擴展過程中的關鍵環節,為確保業務連續性,平滑擴容是最優選擇。平滑擴容的核心思想是采用漸進式倍增策略,通過分階段操作將數據庫數量逐步增加,同時保持服務不中斷。以下是具體的擴容實施步驟:
方案概述
- 擴容比例:采用2倍擴容策略(如從2個DB節點擴展至4個節點)
- 技術要求:依賴雙主復制機制實現數據同步
- 實施階段:分測試驗證和生產上線兩個主要階段
詳細實施步驟
第一階段:基礎設施準備
-
資源規劃:
- 根據當前數據庫規格(如CPU/內存/存儲配置)申請相同規格的新節點
- 網絡配置需確保新節點與原有集群處于同一VPC和安全組
- 示例:原2節點配置為16核64G,新節點需保持相同規格
-
環境初始化:
- 安裝相同版本的數據庫軟件(如MySQL 8.0.28)
- 配置文件需保持與現有集群一致的參數(如字符集、緩沖池大小等)
第二階段:測試環境驗證
-
搭建測試集群:
- 使用1個原節點+1個新節點建立雙主復制
- 配置復制賬號并驗證雙向同步(
SHOW SLAVE STATUS)
-
數據校驗:
- 通過pt-table-checksum工具校驗數據一致性
- 模擬業務流量(如使用sysbench)測試同步延遲
-
故障演練:
- 主動觸發網絡分區,驗證自動恢復機制
- 測試主備切換流程(如通過VIP漂移或中間件切換)
第三階段:生產環境上線
-
滾動部署:
- 凌晨低峰期逐個添加新節點(先添加DB3,再添加DB4)
- 每次添加后觀察監控指標(QPS/連接數/延遲)
-
數據遷移:
- 對于存量數據,使用mysqldump+GTID方式初始化
- 增量數據通過binlog實時同步(需確保
log_slave_updates開啟)
-
流量切換:
- 配置中間件(如ProxySQL)逐步將讀流量遷移至新節點
- 使用影子表驗證業務兼容性后切換寫流量
第四階段:后續維護
-
監控強化:
- 部署Prometheus監控各節點復制延遲
- 設置Alertmanager對異常同步狀態告警
-
性能優化:
- 根據負載情況調整線程池參數
- 定期執行
OPTIMIZE TABLE維護新節點
注意事項
- 必須確保原集群有足夠的磁盤空間支撐同步期間的binlog增長
- 建議提前準備回滾方案(如刪除新節點并重建復制)
- 跨機房部署時需評估網絡帶寬對同步延遲的影響
通過這種分階段、可驗證的擴容方式,能夠在保證服務可用性的同時,實現存儲容量和吞吐量的線性擴展。該方案已在電商大促、金融結算等多個高并發場景中得到驗證,平均擴容耗時約4-6小時(取決于數據量大小)。
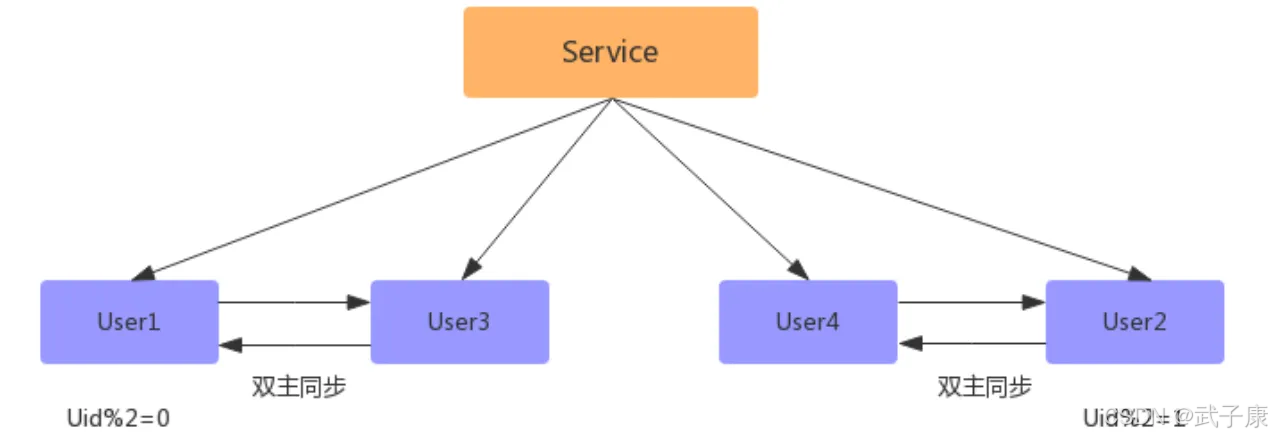
數據同步完成之后,配置雙主雙寫(同步因為數據有延遲,如果時時刻刻都有寫和更新操作,會存在不準確的問題)
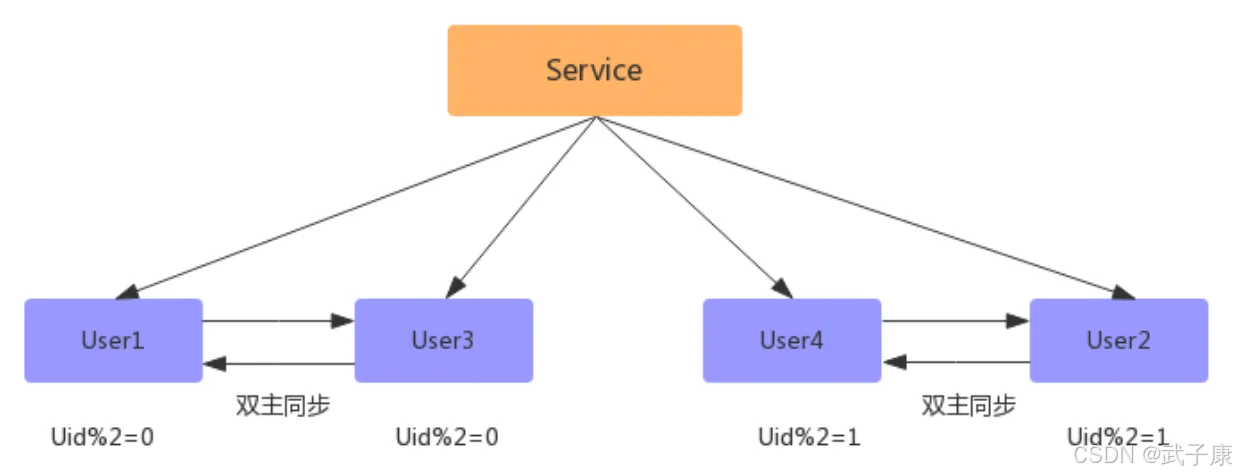
數據同步完成之后,刪除雙主同步,修改數據庫配置,并重啟:
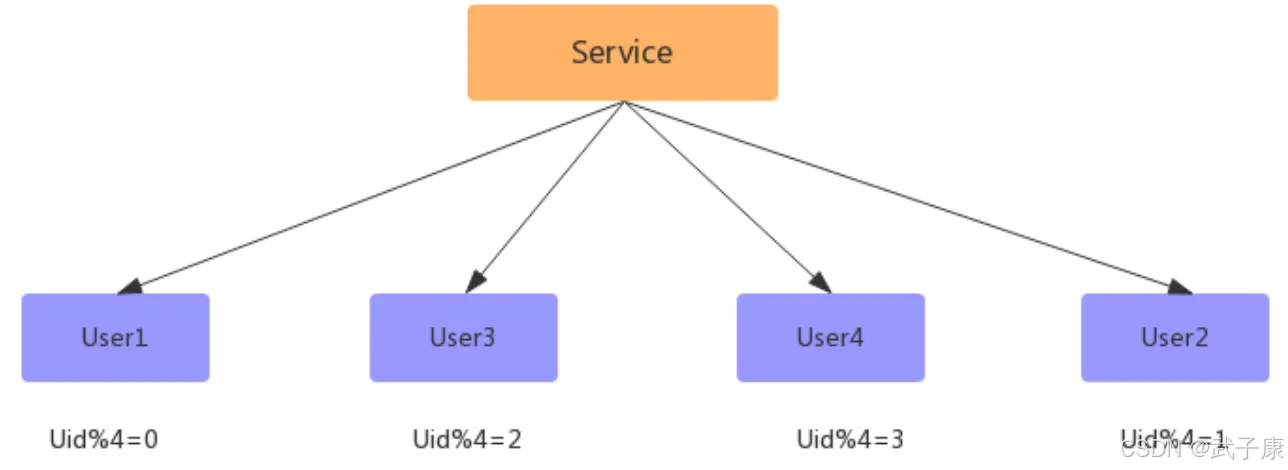
此時已經完成了擴容,但此時的數據沒有減少,新增的數據和就得數據庫一樣多的數據,此時還需要寫一個程序,清空數據庫中多余的數據,比如:
● User1 去除 uid%4 = 2 的數據
● User3 去除 uid%4 = 0 的數據
● User2 去除 uid%4 = 3 的數據
● User4 去除 uid%4 = 1 的數據
平滑擴容方案能夠實現N庫擴展2N庫的平滑擴容,增加數據庫服務能力,降低單庫一半的數據量,其核心原理是:成倍擴容,避免數據遷移。
平滑擴容的優點
-
業務連續性保障
- 擴容過程中服務持續可用,確保終端用戶無感知
- 適用于7×24小時運營的關鍵業務系統
- 示例:電商平臺在大促期間可保持正常交易
-
團隊壓力緩解
- 相比停機擴容,時間窗口更寬松(通常可延長至數周)
- 允許分階段執行,單個步驟失敗可回滾
- 每個階段完成后可進行充分驗證
-
風險控制優勢
- 實時監控各環節狀態,發現問題立即處理
- 支持"灰度"式擴容,先遷移部分數據驗證
- 緊急情況下可暫停擴容流程
-
性能優化效果
- 單庫數據量減少50%帶來顯著性能提升:
- 查詢響應時間縮短30-50%
- 索引效率提高
- 備份恢復時間大幅減少
- 支持更精細的資源分配策略
- 單庫數據量減少50%帶來顯著性能提升:
-
擴展性增強
- 為后續擴容建立標準化流程
- 積累的運維經驗可復用
- 形成可擴展的架構基礎
實施建議:
- 建議選擇業務低峰期啟動
- 每次遷移數據量控制在總量的5-10%
- 建立完善的監控告警機制
- 提前準備回滾方案
平滑缺點
1. 程序復雜度高
- 雙主同步配置:需要設置數據庫主從復制機制,確保兩個主庫之間的數據實時同步。例如MySQL的
master-master復制需要配置server-id、log-bin等參數,并處理可能出現的沖突問題。 - 雙主雙寫實現:應用層需要支持雙寫邏輯,包括:
- 寫操作路由(如通過分片鍵決定寫入哪個主庫)
- 沖突檢測(如時間戳或版本號機制)
- 失敗回滾(當一主庫寫入失敗時需撤銷另一主庫的變更)
- 同步狀態監控:需部署額外組件(如ZooKeeper)檢測主庫間同步延遲,并設置閾值告警。例如:當同步延遲超過5秒時觸發切換邏輯。
2. 擴容成本高
- 橫向擴展困難:若從雙主擴展到三主或更多節點,需重新設計數據分片策略(如一致性哈希),且可能引發數據遷移問題。例如:增減節點時需重新平衡10TB數據的分布。
- 運維成本激增:每增加一個主庫會帶來:
- 同步鏈路數呈平方級增長(如4主庫需維護6條雙向同步鏈路)
- 硬件成本上升(需保證所有主庫的SSD存儲和萬兆網絡)
- 監控復雜度提升(需跟蹤N×(N-1)條同步通道的狀態)
- 典型場景限制:在物聯網或用戶日志場景下,若設備/用戶ID分散在100個主庫中,跨庫查詢(如統計全平臺數據)需依賴額外的大數據聚合系統。
適用場景
● 大型網站
● 對高可用要求高的服務












)
)





