【C++高階六】哈希與哈希表
- 1.什么是哈希?
- 2.unordered系列容器
- 3.哈希表
- 3.1將key與存儲位置建立映射關系
- 3.1.1直接定址法
- 3.1.2除留余數法(產生哈希沖突)
- 3.2解決哈希沖突的方法
- 3.2.1閉散列(開放定址法)
- 3.3.2開散列(鏈地址法)(哈希桶)
- 4.實現哈希表(除留余數法建立映射)
- 4.1閉散列實現
- 4.1.1狀態與結構
- 4.1.2 Insert
- 4.1.3負載因子和擴容
- 4.1.4 Find
- 4.1.5 Erase
- 4.1.6 完整代碼
- 4.2 開散列實現
- 4.2.1 狀態與結構
- 4.2.2 Insert
- 4.2.3 負載因子和擴容
- 4.2.4 Find
- 4.2.5 Erase
- 4.2.6 仿函數
- 4.2.7 完整代碼
1.什么是哈希?
理想中的搜索方法:不經過任何比較和遍歷就可以直接從表中搜索想要的元素
如果構造一種存儲結構,并通過某種函數能使元素的存儲位置與它自身關鍵碼之間建立映射的關系,那么在查找時只要通過函數就可以快速找到該元素
當向該結構中插入元素時,根據待插入元素的關鍵碼,以函數計算出該元素的存儲位置并按此位置進行存儲
當向該結構中搜索元素時,用函數對元素的關鍵碼進行同樣的計算求得元素的存儲位置,在結構中按此位置取元素比較,若關鍵碼相等則搜索成功
該方式即為哈希(散列)方法,哈希方法中使用的轉換函數稱為哈希(散列)函數,構造出來的結構稱為哈希表(Hash Table)(或者稱散列表)
2.unordered系列容器
unordered_map和unordered_set與map和set是什么關系?

在內部,unordered_map沒有對<kye, value>按照任何特定的順序排序
其實unordered_map和map使用起來沒什么區別,那么什么時候應該用unordered系列呢?答案是你只關心鍵值對的內容而不關心是否有序時就選擇unordered系列
3.哈希表
3.1將key與存儲位置建立映射關系
3.1.1直接定址法
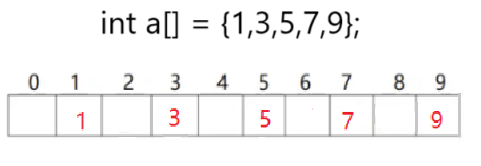
每一個值都有一個唯一位置,適用于范圍比較集中的數據
3.1.2除留余數法(產生哈希沖突)
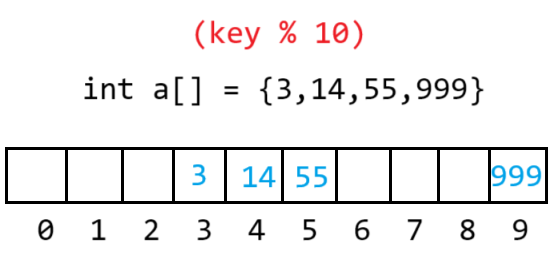
范圍不集中,分布分散
key值跟存儲位置的關系是取模出來的,不同的值有可能映射到相同的位置,造成哈希沖突,如:5和55取模后都為5
3.2解決哈希沖突的方法
3.2.1閉散列(開放定址法)
當發生哈希沖突時,如果哈希表未被裝滿,說明哈希表中必然還有空位置,則可以用線性探測把key存放到沖突位置中的下一個位置,若有兩個取模相同的值,則將先進來的占住當前取模位置,后進來的向后探測,若有空位置則放入
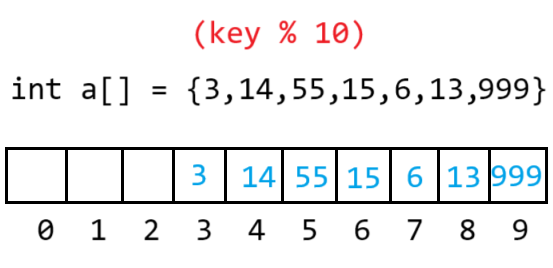
key%len,len是表的長度
3.3.2開散列(鏈地址法)(哈希桶)
對關鍵碼集合用散列函數計算散列地址,具有相同地址碼歸于同一個子集合,每一個子集稱為一個桶,各個桶中的元素通過一個單鏈表鏈接起來,各鏈表的頭節點存儲在哈希表中
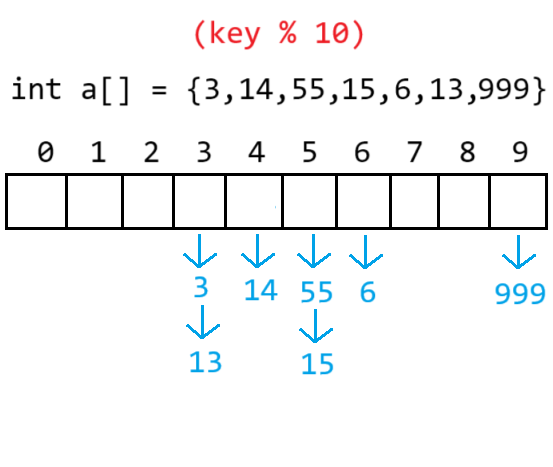
4.實現哈希表(除留余數法建立映射)
4.1閉散列實現
4.1.1狀態與結構
整體實現全部放入名為開放地址法Open_Address的命名空間中
假設要刪除55,因為55取余后為5,所以先去位置為5的地方去找,沒有找到則繼續向后尋找,到空才結束
但是把33刪除后,再次查找13時,由于提前遇到空,則查找直接結束,不會向后尋找 所以找到后不能直接刪除,會影響繼續查找
設置三種狀態: 空、存在、刪除
enum Status//狀態
{EMPTY,//空EXIST,//存在DELETE//刪除
};template<class K,class V>
struct HashData
{pair<K, V> _kv;//kv值Status _status = EMPTY;//狀態默認為空
};
state默認設為空,不然有可能造成映射位置沒有數據,但狀態為存在的情況
4.1.2 Insert
key值跟存儲位置的關系是取模出來的(key%len)
len為 _tables.size() 還是 _tables.capacity()?
假設為capacity,若當前位置為空,將值填入并將狀態設置為存在,就會造成越界,在vector中
operator[]會做越界檢查,下標是否小于size
插入:
bool Insert(const pair<K, V>& kv)
{size_t hashi = kv.first % _table.size();_table[hashi]._kv = kv;_table[hashi]._status = EXIST;
}
線性探測:
while (_table[hashi]._status == EXIST)
{hashi++;hashi %= _table.size();//防止越界,可以回到0
}
完整代碼:
bool Insert(const pair<K, V>& kv)
{size_t hashi = kv.first % _table.size();while (_table[hashi]._status == EXIST){hashi++;hashi %= _table.size();//防止越界,可以回到0}_table[hashi]._kv = kv;_table[hashi]._status = EXIST;
}
4.1.3負載因子和擴容
哈希表沖突越多效率就越低,若表中位置都滿了就需要擴容,所以提出負載因子的概念
負載因子 = 填入表的元素個數 / 表的長度,用于表示 表儲存數量的百分比
填入表的元素個數 越大,表示沖突的可能性越大,所以在開放定址法時,應該控制在0.7-0.8以下,超過就會擴容
if (_num * 10 / _table.size() == 7)
{size_t new_num = _table.size() * 2;HashTable<K, V> new_HT;for (size_t i = 0; i < _table.size();i++)//遍歷舊表{if (_table[i]._status == EXIST){new_HT.Insert(_table[i]._kv);}}_table.swap(new_HT._table);
}
創建new_HT,將其中的_tables的size進行擴容,通過復用insert的方式,完成對新表的映射,最后交換舊表的_tables與new_HT的_tables ,以達到更新數據的目的
4.1.4 Find
若當前位置的狀態為存在或者刪除,則繼續找, 遇見空就結束
若在循環中找到了,則返回對應位置的地址,若沒找到則返回nullptr
刪除只是把要刪除的數據的狀態改為DELETE,但是數據本身還是在的,所以Find還是可以找到的
HashData<K, V>* Find(const K& key)
{size_t hashi = key % _table.size();while (_table[hashi]._status != EMPTY){if (_table[hashi]._status == EXIST && _table[hashi]._kv.first == key){return &_table[hashi];}hashi++;hashi %= _table.size();}return nullptr;
}
4.1.5 Erase
bool Erase(const k& key)
{HashData<K, V>* temp = Find(key);if (temp){temp->_status = DELETE;_num--;return true;}else{return false;}
}
4.1.6 完整代碼
using namespace std;
namespace Open_Address//閉散列(開放定址法)
{enum Status//狀態{EMPTY,//空EXIST,//存在DELETE//刪除};template<class K,class V>struct HashData{pair<K, V> _kv;//kv值Status _status = EMPTY;//狀態默認為空};template<class K,class V>class HashTable{public:HashTable(){_table.resize(10);}bool Insert(const pair<K, V>& kv){//負載因子等于0.7時擴容if (_num * 10 / _table.size() == 7){size_t new_num = _table.size() * 2;HashTable<K, V> new_HT;for (size_t i = 0; i < _table.size();i++)//遍歷舊表{if (_table[i]._status == EXIST){new_HT.Insert(_table[i]._kv);}}_table.swap(new_HT._table);}//線性探測size_t hashi = kv.first % _table.size();while (_table[hashi]._status == EXIST){hashi++;hashi %= _table.size();//防止越界,可以回到0}_table[hashi]._kv = kv;_table[hashi]._status = EXIST;}HashData<K, V>* Find(const K& key){size_t hashi = key % _table.size();while (_table[hashi]._status != EMPTY){if (_table[hashi]._status == EXIST && _table[hashi]._kv.first == key){return &_table[hashi];}hashi++;hashi %= _table.size();}return nullptr;}bool Erase(const k& key){HashData<K, V>* temp = Find(key);if (temp){temp->_status = DELETE;_num--;return true;}else{return false;}}private:vector<HashData<K, V>> _table;//指針數組size_t _num;//存儲的數據個數};
}
4.2 開散列實現
4.2.1 狀態與結構
整體實現全部放入名為哈希桶Hash_Bucket的命名空間中
template<class K,class V>
struct HashNode
{HashNode(const pair<K,V>& kv):_kv(kv),_next(nullptr){}HashNode<K, V>* _next;//指向下一個節點pair<K, V> _kv;//記錄數據
};
4.2.2 Insert
在同一個桶中數據不分先后
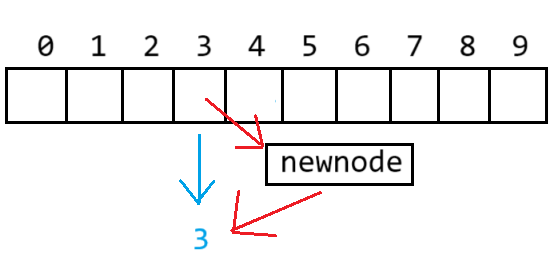
創建一個新節點newnode,使newnode的next連接到當前映射位置,再讓newnode成為桶的頭節點
size_t hashi = kv.first % _table.size();
Node* newnode = new Node(kv);
newnode->_next = _table[hashi];
_table[hashi] = newnode;
4.2.3 負載因子和擴容
負載因子越大,沖突的概率越高,查找效率越低,空間利用率越高
負載因子越小,沖突的概率越低,查找效率越高,空間利用率越低
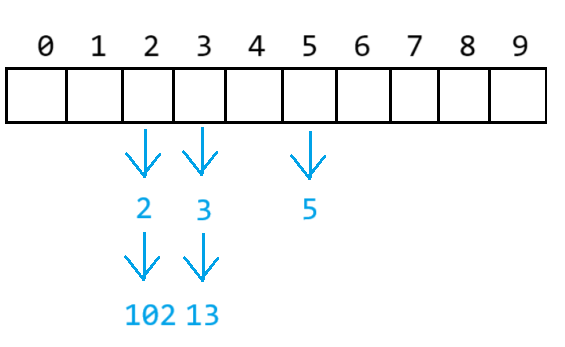
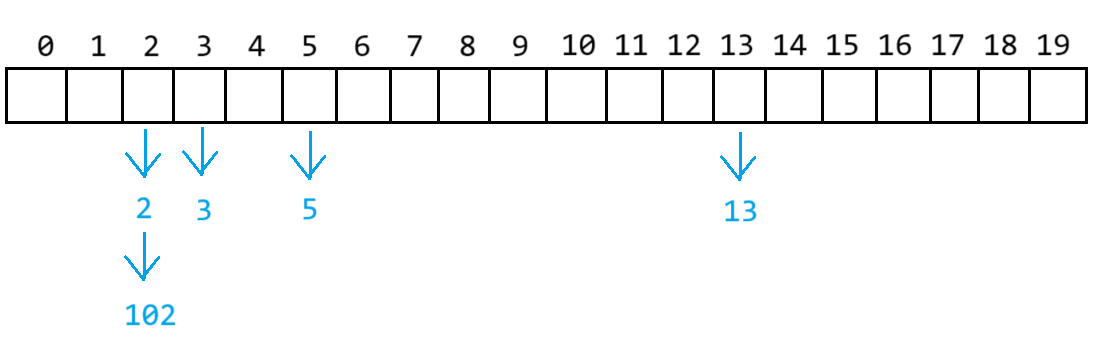
原表的節點重新計算位置后移動到新表中
由于新表的size大小為20,所以12可以找到對應位置的桶 ,而102沒有對應大小的桶,所以取模來到對應2位置處,與2形成鏈式結構
遍歷舊表中的數據,若數據為空,就往后遍歷
若數據不為空,則將其移動到新表中 ,進行頭插
if (_num == _table.size())
{size_t newsize = _table.size() == 0 ? 10 : _table.size()*2;vector<Node*> new_table;new_table.resize(newsize, nullptr);for (size_t i = 0; i < _table.size(); i++){Node* temp = _table[i];while (temp){Node* next = temp->_next;//挪動到新表size_t hashi = _table[i] % new_table.size();temp->_next = new_table[i];new_table[hashi] = temp;temp = next; }_table[i] = nullptr;}_table.swap(new_table);
}
4.2.4 Find
使用temp記錄當前映射位置,遍歷當前位置的單鏈表 ,查詢是否有key值的存在,若有則返回temp,若沒有則返回空
Node* Find(const K& key)
{if (_table.size() == 0){return nullptr;}size_t i = key % _table.size();Node* temp = _table[i];while (temp){if (temp->_kv.first == key){return temp;}temp = temp->_next;}return nullptr;
}
4.2.5 Erase
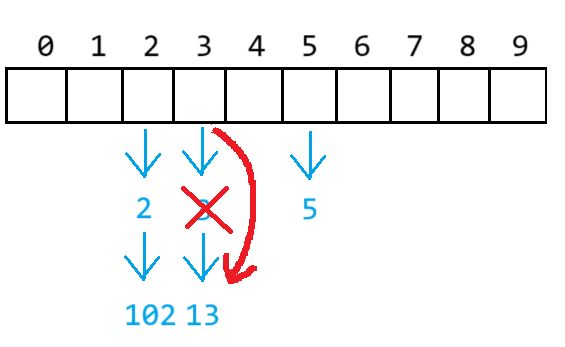
假設要刪除3,則 需讓表的位置指向要刪除節點的下一個
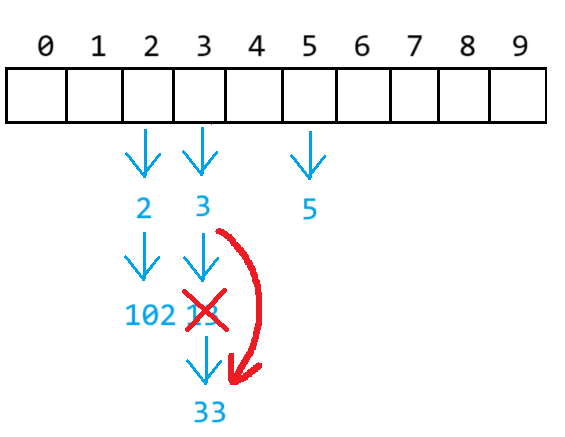
假設要刪除13,則需找到刪除節點的前一個節點,使其指向要刪除節點達到后一個節點
bool Erase(const K& key)
{size_t i = key % _table.size();Node* prev = nullptr;//記錄前一個結點Node* temp = _table[i];while (temp){if (temp->_kv.first == key){if(prev == nullptr)//刪除頭節點{_table[i] = temp->_next;}else{prev->_next = temp->_next;}delete temp;return true;}prev = temp;temp = temp->_next;}return false;
}
4.2.6 仿函數
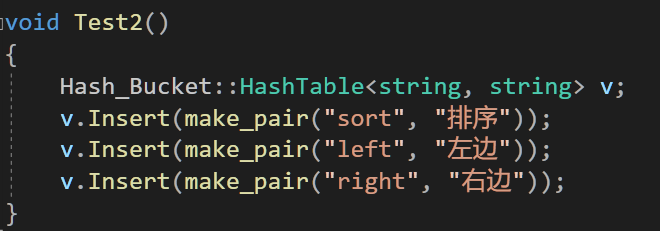

若為string類型,使用insert無法計算對應的hashi值,所以需要加入仿函數
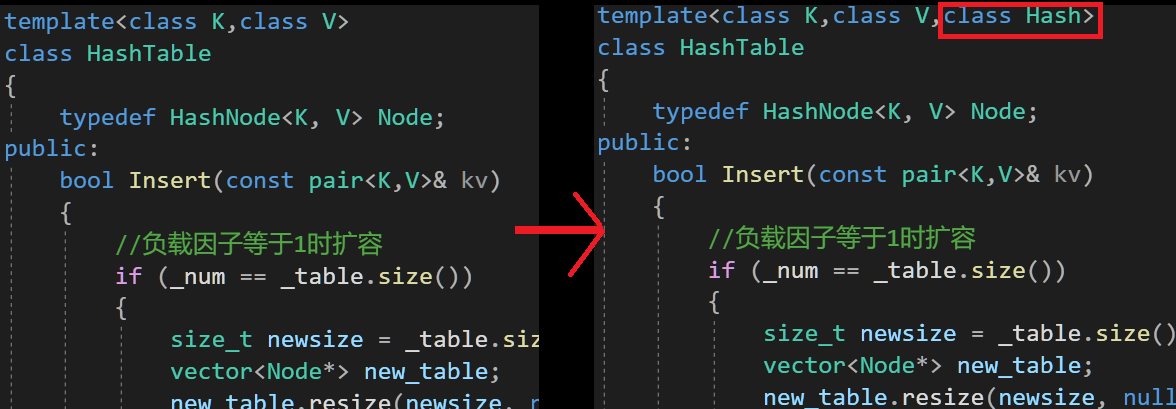
加入全局仿函數:
template<class K>
struct HashFunc//仿函數
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct HashFunc<string>//仿函數特化
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash *= 31;//乘31或者131都行,為了避免數字重復hash += e;}return hash;}
};
再次使用 HashTable時不用傳入仿函數也能調用string 類型
4.2.7 完整代碼
namespace Hash_Bucket//開散列(哈希桶)
{template<class K,class V>struct HashNode{HashNode(const pair<K,V>& kv):_kv(kv),_next(nullptr){}HashNode<K, V>* _next;//指向下一個節點pair<K, V> _kv;//記錄數據};template<class K,class V,class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:bool Insert(const pair<K,V>& kv){//負載因子等于1時擴容Hash hash;if (_num == _table.size()){size_t newsize = _table.size() == 0 ? 10 : _table.size()*2;vector<Node*> new_table;new_table.resize(newsize, nullptr);for (size_t i = 0; i < _table.size(); i++){Node* temp = _table[i];while (temp){Node* next = temp->_next;//挪動到新表size_t hashi = hash(temp->_kv.first) % new_table.size();temp->_next = new_table[i];new_table[hashi] = temp;temp = next; }_table[i] = nullptr;}_table.swap(new_table);}size_t hashi = hash(kv.first) % _table.size();Node* newnode = new Node(kv);//頭插newnode->_next = _table[hashi];_table[hashi] = newnode;_num++;return true;}Node* Find(const K& key){if (_table.size() == 0){return nullptr;}size_t i = hash(key) % _table.size();Node* temp = _table[i];while (temp){if (temp->_kv.first == key){return temp;}temp = temp->_next;}return nullptr;}bool Erase(const K& key){size_t i = key % _table.size();Node* prev = nullptr;//記錄前一個結點Node* temp = _table[i];while (temp){if (temp->_kv.first == key){if(prev == nullptr)//刪除頭節點{_table[i] = temp->_next;}else{prev->_next = temp->_next;}delete temp;return true;}prev = temp;temp = temp->_next;}return false;}private:vector<Node*> _table;//指針數組size_t _num = 0;//存儲的數據個數};
}



















