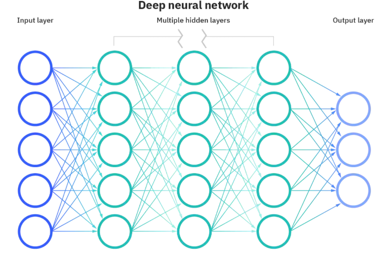
在當今人工智能蓬勃發展的時代,深度學習和神經網絡已經成為最受關注的技術領域之一。從智能手機的人臉識別到自動駕駛汽車的環境感知,從醫療影像分析到金融風險預測,這些技術正在深刻改變我們的生活和工作方式。本文將帶您了解深度學習和神經網絡的基本概念、發展歷程以及它們之間的關系。
簡介
一、機器學習:智能的基石
機器學習是人工智能的核心分支,它使計算機系統能夠從數據中"學習"并改進性能,而無需顯式編程。想象一下教孩子識別動物:不是通過編寫詳細的規則("貓有尖耳朵、長胡須..."),而是通過展示大量圖片讓他們自己發現規律——這正是機器學習的基本理念。
機器學習的三大主要類型包括:
- 監督學習??:使用標記數據訓練模型(如圖像分類)
- ??無監督學習??:發現未標記數據中的模式(如客戶細分)
- ??強化學習??:通過試錯和獎勵機制學習(如游戲AI)
二、神經網絡:模仿生物大腦的計算模型
神經網絡是機器學習的一個重要分支,其靈感來源于生物神經元的工作方式。就像人腦由數十億個相互連接的神經元組成,人工神經網絡由人工神經元(節點)和連接它們的"突觸"(權重)構成。

關鍵組成部分:
- ??輸入層??:接收原始數據
- 隱藏層??:進行特征提取和轉換(可能有多層)
- ??輸出層??:產生最終預測或分類結果
- ??激活函數??:決定神經元是否"激活"(如ReLU、Sigmoid)
- 權重??:連接強度,通過訓練不斷調整
1943年,McCulloch和Pitts提出了第一個神經網絡數學模型,開啟了這一領域的研究。1958年,Frank Rosenblatt發明的感知機(Perceptron)是第一個可學習的神經網絡模型。
三、深度學習:神經網絡的"深度"進化
深度學習本質上是具有多個隱藏層的神經網絡。這里的"深度"指的是網絡層次的深度,通常包含多個非線性變換層,能夠自動學習數據的多層次抽象表示。
深度學習的突破性進展:
- 特征自動提取??:傳統機器學習需要人工設計特征,而深度學習可以自動學習
- ??處理復雜數據??:特別適合圖像、語音、視頻等高維數據
- ??性能突破??:在許多任務上達到或超越人類水平
2012年,AlexNet在ImageNet競賽中大幅領先傳統方法,標志著深度學習時代的真正開啟。隨后,各種深度網絡架構如雨后春筍般涌現。
神經網絡的構造
一、神經元:神經網絡的基本單元
- 生物神經元與人工神經元對比
? 生物神經元:
- 結構組成:由樹突(接收輸入信號)、細胞體(整合處理信號)和軸突(傳輸輸出信號)構成
- 工作原理:通過突觸傳遞電化學信號,當輸入信號總和超過閾值時產生動作電位
- 典型特性:具有興奮性、抑制性和可塑性等特征
? 人工神經元(MCP模型):
- 數學模型:output = activation_function(∑(inputs * weights) + bias)
- 模擬特性:
- 輸入接收:對應生物神經元的樹突功能
- 加權處理:模擬突觸強度(權重)對信號的影響
- 激活輸出:類似細胞體的閾值激活機制
- 示例:感知機(Perceptron)是最簡單的人工神經元實現
- 數學表達
單個神經元的計算過程可分為以下步驟:
1)輸入階段:
- 接收n維輸入向量X = [x?, x?, ..., x?]
- 每個輸入x?對應一個權重w?
2)加權求和:
- 計算加權和z = w?x? + w?x? + ... + w?x? + b
- 偏置項b的作用是調整神經元的激活閾值
3)激活輸出:
- 應用激活函數y = f(z)
- 常用激活函數示例:
- Sigmoid:f(z) = 1/(1+e??)
- ReLU:f(z) = max(0,z)
- Tanh:f(z) = (e? - e??)/(e? + e??)
數學表達式中各參數含義: ? x?:第i個輸入信號(如特征值或前一層的輸出) ? w?:對應輸入的連接權重(決定輸入的重要性) ? b:偏置項(調整神經元激活的難易程度) ? f:非線性激活函數(引入非線性表達能力)
應用場景說明:
- 在圖像識別中,x?可能代表像素值
- 在自然語言處理中,x?可能代表詞向量維度
- 權重w?通過訓練過程自動學習得到
感知機(Perceptron)是神經網絡發展史上第一個可學習的計算模型,由Frank Rosenblatt于1957年在康奈爾航空實驗室提出。作為人工神經網絡的雛形,感知機不僅開創了機器學習的新范式,更為現代深度學習的發展奠定了基礎。
感知器是人工神經網絡中最簡單的形式,也是深度學習的基礎組成部分。作為單層神經網絡,感知器在機器學習發展史上具有里程碑式的意義。
感知器
一、感知器的基本概念
1. 數學模型
感知器的數學模型可以表示為:
y = f(∑(w_i * x_i) + b)
其中各參數詳細說明:
輸入特征(x_i):表示感知器接收的第i個輸入信號。例如在圖像識別中,可以是像素值;在房價預測中,可以是房屋面積、臥室數量等特征。
權重(w_i):每個輸入特征對應的權重參數,決定了該特征對輸出的影響程度。在訓練過程中這些權重會被不斷調整。
偏置項(b):類似于線性函數中的截距,用于調整神經元的激活閾值。它允許我們移動決策邊界而不依賴于輸入。
激活函數(f):通常為階躍函數(原始感知器),其數學表達式為:
f(z) = { 1, if z ≥ 0
{ 0, otherwise現代神經網絡中常用其他激活函數如Sigmoid、ReLU等作為替代。
2. 工作原理
感知器的工作流程可分為以下幾個步驟:
- 輸入接收:同時接收多個輸入信號x?, x?,...,xn
- 加權求和:計算各輸入與對應權重的乘積之和 ∑(w_i * x_i)
- 偏置處理:加上偏置項b,形成凈輸入 z = ∑(w_i * x_i) + b
- 激活判斷:通過激活函數f(z)產生二值輸出(0或1)
這個過程模擬了生物神經元的工作方式:當"刺激"(加權和)超過某個閾值(由偏置控制)時,神經元就會被激活。例如,在垃圾郵件分類中,輸入可以是郵件中的關鍵詞頻率,輸出0表示正常郵件,1表示垃圾郵件。
感知器的結構與類型
1. 基本結構
感知器的基本結構包含三個主要組成部分:
輸入層:
- 接收外部輸入特征
- 每個輸入節點對應一個特征
- 通常不進行任何計算處理
權重和求和單元:
- 存儲權重參數(w?,w?,...,wn)
- 執行加權求和計算 ∑(w_i * x_i)
- 加上偏置項b
激活函數:
- 接收求和結果z
- 應用非線性變換
- 產生最終輸出y
2. 激活函數類型
感知器可以使用多種激活函數:
階躍函數(原始感知器):
- 最早使用的激活函數
- 輸出僅為0或1
- 缺點:不可微,不能用于梯度下降
Sigmoid函數:
- 輸出范圍(0,1)
- 表達式:σ(z) = 1/(1+e^{-z})
- 優點:平滑可微
- 常用于概率輸出
ReLU函數(現代變種):
- 表達式:ReLU(z) = max(0,z)
- 目前最常用的激活函數
- 解決了梯度消失問題
- 計算效率高
3. 單層與多層感知器
單層感知器:
- 僅包含輸入層和輸出層
- 只能學習線性決策邊界
- 可以完美解決線性可分問題(如AND、OR邏輯運算)
- 無法解決XOR等非線性可分問題
- 典型應用:簡單的線性分類任務
多層感知器(MLP):
- 包含一個或多個隱藏層
- 每層都有對應的權重和激活函數
- 理論上可以逼近任何連續函數(萬能逼近定理)
- 能夠解決復雜的非線性問題
- 典型應用:圖像識別、語音處理等復雜模式識別任務
- 示例:一個簡單的3層MLP結構:輸入層(4個節點)→隱藏層(5個節點)→輸出層(1個節點)
中間層的確立
輸入層的節點數:與特征的維度匹配
輸出層的節點數:與目標的維度匹配。
中間層的節點數:目前業界沒有完善的理論來指導這個決策。一般是根據經驗來設置。較好的方法就是預先設定幾個可選值,通過切換這幾個值來看整個模型的預測效果,選擇效果最好的值作為最終選擇。
損失函數
均方差損失(MSE)與交叉熵損失的理論解析
均方差損失(MSE)與交叉熵損失的理論解析
一、均方差損失(Mean Squared Error)
數學定義 ? 基本形式:![]()
其中N為樣本數量,y_i為真實值,?_i為預測值。例如在房價預測中,若真實價格為300萬,預測值為280萬,則單個樣本損失為(300-280)^2=400
? 矩陣形式:![]()
Frobenius范數在批量計算時更高效,特別適用于深度學習框架中的矩陣運算
概率解釋 ? 對應高斯分布的最大似然估計: ![]()
這意味著當數據噪聲服從高斯分布時,MSE是最優的損失函數選擇
? 噪聲假設: 假設觀測誤差ε~N(0,σ^2),且各樣本噪聲相互獨立。這種假設在物理測量等場景中常見
梯度特性 ? 單樣本梯度: 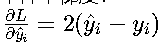 梯度與誤差成正比,在反向傳播時提供線性更新信號
梯度與誤差成正比,在反向傳播時提供線性更新信號
? Hessian矩陣: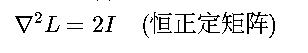 嚴格凸性保證優化過程不會陷入局部最優
嚴格凸性保證優化過程不會陷入局部最優
理論性質 ? 凸性分析: 二次函數的凸性保證全局最優解存在,在凸優化問題中具有理論保證
? 利普希茨常數: 梯度滿足![]() ,影響學習率的選擇和收斂速度
,影響學習率的選擇和收斂速度
? 異常值敏感度: 平方項使大誤差被放大10倍,如10單位誤差產生100損失,而1單位誤差僅產生1損失
二、交叉熵損失(Cross-Entropy)
數學定義 ? 二分類形式:![]()
典型應用于邏輯回歸,如腫瘤分類中y_i∈{0,1}表示惡性/良性
? 多分類形式: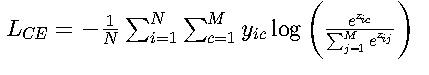
配合Softmax使用,適用于圖像分類等任務(如MNIST手寫數字識別)
信息論基礎 ? KL散度關系: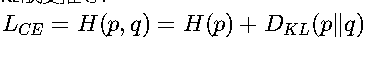
其中H(p)是真實分布的熵,D_KL衡量預測分布與真實分布的差異
? 似然估計等價: 等價于最大化伯努利分布的似然函數,在分類問題中具有統計合理性
![]()
梯度特性 ? Softmax梯度: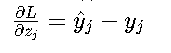
這種簡潔形式使得反向傳播計算效率極高
? 曲率分析: 半正定的Hessian矩陣在凸區域保證優化穩定性理論性質 ? 極端懲罰: 當預測概率接近0而真實標簽為1時,損失趨向無窮大,迫使模型做出明確判斷
? 類別平衡: 可通過調整權重w解決樣本不平衡問題,如在醫學診斷中提高罕見病的權重
三、理論對比分析
特性 | MSE | Cross-Entropy |
|---|---|---|
??輸出空間?? | 連續值(?) | 概率空間([0,1]) |
??概率假設?? | 高斯噪聲 | 多項分布 |
??梯度飽和性?? | 線性梯度無飽和 | 極端概率時梯度飽和 |
??最優預測?? | 條件期望 E[y|x] | 條件概率 P(y|x) |
??多分類擴展?? | 需配合歐式距離 | 天然支持(Softmax) |
??異常值魯棒性?? | 低(平方放大) | 高(對數抑制) |
梯度下降法
一、梯度下降的數學基礎
1. 一階優化理論
梯度下降法建立在一階優化理論的基礎上,其核心思想是沿著目標函數負梯度方向迭代更新參數:
![]()
其中η為學習率(learning rate),?_θ L(θ_t)表示目標函數在θ_t處的梯度。收斂條件需滿足Lipschitz連續性:
![]()
這一條件保證了梯度變化不會過于劇烈,使得算法能夠穩定收斂。例如在邏輯回歸中,交叉熵損失函數就滿足此條件。
2. 泰勒展開解釋
通過泰勒展開可以更深入理解梯度下降的數學本質。對目標函數進行二階近似:
![]()
其中H是Hessian矩陣。由此可推導出最優步長:
![]()
在實際應用中,由于計算Hessian矩陣代價高昂,通常使用固定學習率或自適應學習率策略。
二、基本算法形式
1. 批量梯度下降 (BGD)
批量梯度下降使用全部訓練數據計算梯度:
![]()
其收斂性可表示為:
![]()
2. 隨機梯度下降 (SGD)
隨機梯度下降每次隨機選取一個樣本更新:
![]()
收斂速率為:
![]()
3. 小批量梯度下降 (Mini-batch GD)
折中方案使用小批量數據(batch):
![]()
批次大小b影響梯度方差:
![]()
三、優化策略改進
1. 動量方法 (Momentum)
引入動量項加速收斂并減少震蕩:
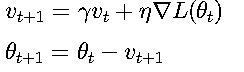
動量系數γ∈(0,1)模擬物理慣性,常見設置為0.9。
2. 自適應學習率方法
AdaGrad算法:
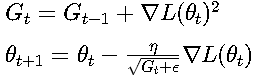
Adam算法結合動量和自適應學習率:
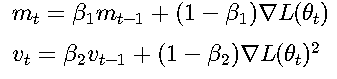
四、收斂性理論
1. 凸函數收斂
對于強凸函數:
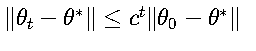
對于一般凸函數:
![]()
2. 非凸函數收斂
在非凸情況下:
![]()
對于鞍點問題:
![]()
五、實現技術細節
1. 學習率調度
衰減策略:
![]()
余弦退火:
![]()
2. 梯度裁剪
控制梯度范數防止爆炸:
![]()
六、前沿發展
1. 二階優化方法
擬牛頓法近似Hessian矩陣:
![]()
使用Fisher信息矩陣:
![]()
2. 分布式優化
參數服務器架構:
![]()
通信壓縮技術:
![]()
BP神經網絡
BP(Back-propagation,反向傳播)前向傳播得到誤差,反向傳播調整誤差,再前向傳播,再反向傳播一輪一輪得到最優解的。
BP神經網絡反向傳播理論精要
一、前向傳播理論
1. 線性變換
神經網絡第l層的第j個神經元的輸入z_j^(l)通過以下線性變換得到:
![]()
其中:
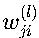 :第l層第j個神經元與第l-1層第i個神經元的連接權重
:第l層第j個神經元與第l-1層第i個神經元的連接權重- 例如,在一個3層神經網絡中,w_24^(2)表示第二層的第2個神經元與第一層第4個神經元的連接權重
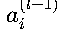 :第l-1層第i個神經元的激活值
:第l-1層第i個神經元的激活值- 對于輸入層(l=1),a_i^(0)即為網絡輸入x_i
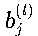 :第l層第j個神經元的偏置項
:第l層第j個神經元的偏置項- 偏置項允許激活函數在輸入為0時也能產生非零輸出
2. 非線性激活
每個神經元的輸出a_j^(l)通過激活函數g(z_j^(l))
計算:
![]()
常用激活函數及其導數:
Sigmoid函數:
![]()
- 特點:將輸入壓縮到(0,1)區間
- 示例:當z=0時,g(0)=0.5,g'(0)=0.25
ReLU函數:
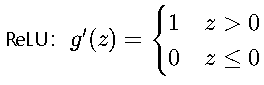
- 特點:計算簡單,緩解梯度消失問題
- 應用場景:在深層網絡中表現優異
二、損失函數構造
1. 均方差損失(MSE)
![]()
其中:
- N:樣本數量
- y_i:第i個樣本的真實值
- ?_i:第i個樣本的預測值
- 1/2系數:方便求導時消去平方項的2
2. L2正則化項
![]()
其中:
- λ:正則化系數,控制正則化強度
- ||W^(l)||_F:權重矩陣的Frobenius范數
- 作用:防止過擬合,使權重趨于較小值
3. 復合目標函數
![]()
- 訓練目標:最小化J
- 實際應用中可能還包括其他正則化項
三、反向傳播理論
1. 輸出層誤差
![]()
推導過程:
- ?J/??_j = ?_j - y_j
- ??_j/?z_j^(L) = g'(z_j^(L))
- 根據鏈式法則相乘得到δ_j^(L)
2. 隱藏層誤差傳播
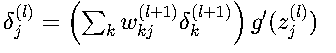
解釋:
- ∑_k w_kj^(l+1) * δ_k^(l+1):將后一層的誤差反向傳播到當前層
- g'(z_j^(l)):考慮當前層的非線性變換
3. 參數梯度計算
權重梯度:
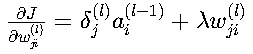
- 第一項:誤差信號與前一層的激活值相乘
- 第二項:L2正則化帶來的額外項
偏置梯度:
![]()
四、參數更新理論
1. 梯度下降規則
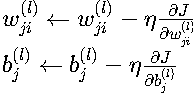
其中:
- η:學習率,控制更新步長
- 實際應用中可能使用改進的優化器(如Adam、RMSProp等)
2. 收斂條件
梯度范數閾值:
![]()
- ε:預設的極小正數
- 表示參數變化已足夠小
最大迭代次數限制:
- 防止無限循環
- 常用值:1000-10000次迭代
五、理論特性分析
1. 鏈式法則本質
![]()
- 展示了誤差從輸出層到輸入層的傳播路徑
- 解釋了深層網絡訓練困難的原因
2. 梯度消失機理
當|g'(z)|<1時:![]()
- 典型表現:使用Sigmoid激活的深層網絡
- 解決方案:使用ReLU、殘差連接等
3. 隱式正則化效應
梯度下降等價于:![]()
- 解釋了為什么梯度下降傾向于找到平坦的最小值
- 與顯式正則化(L1/L2)有協同作用






:Oracle 11g LISTAGG函數使用陷阱,缺失WITHIN子句解決方案)








)
)


