一、概覽
1.1 定義
大語言模型(LLM)是基于深度學習和神經網絡的自然語言處理技術,目前主要通過Transformer架構和大規模數據訓練來理解和生成語言。
GPT不同架構的訓練參數:
- GPT-1(2018):1.17億參數
- GPT-2(2018):15億參數
- GPT-3(2020):1750億參數
- GPT-4(2023):參數規模進一步增加
1.2 流程
主要步驟如下:
- 輸入文本 → 2. Tokenize分詞 → 3. 查表映射為詞向量 → 4. Transformer網絡編碼/解碼 → 5. 生成token分布 → 6. 采樣/查表輸出文本
1.3 主流大模型架構對比
經典Transformer架構由編碼器(Encoder)和解碼器(Decoder)2個組件構成,每個組件都含有自注意力機制和前饋網絡2個核心機制。
當前主流大模型是此基礎的變體
模型 | 架構類型 | 構成/特點 | 主要用途 |
BERT | Encoder-only | 多層編碼器,雙向自注意力 | 理解(分類、問答等) |
GPT系列/DeepSeek R1 | Decoder-only | 多層解碼器,單向(因果)自注意力 | 文本生成、對話 |
Gemini | 多模態/異構架構 | 可統一處理文本、視覺等 | 多模態AI任務 |
Claude/文心/DeepSeek V3 | Decoder-only/增強 | 安全、知識注入等優化 | 更可靠的文本任務 |
二、大模型原理
輸入層
1.用戶輸入文本
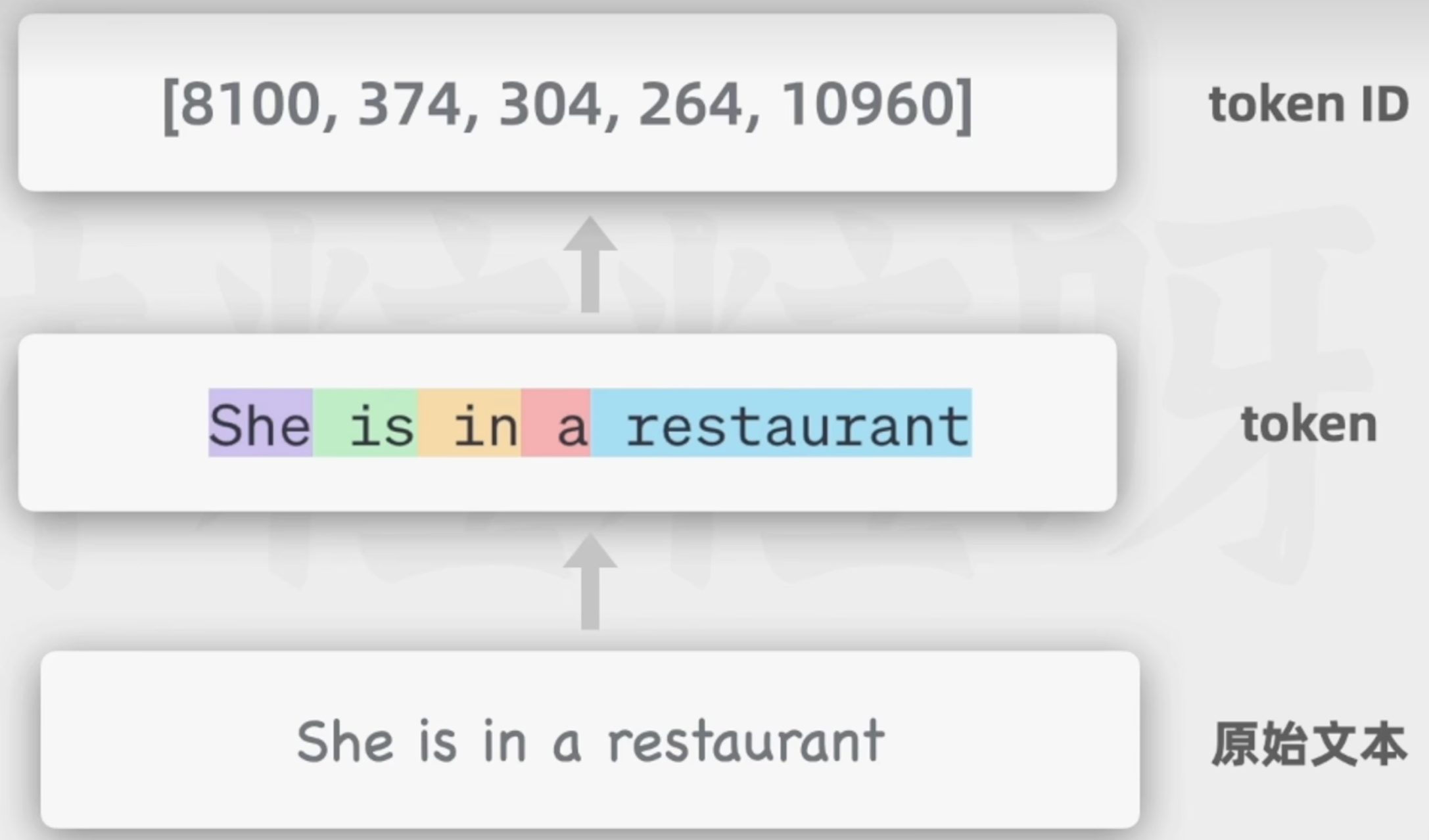
2.分詞(Tokenization)
3.Token到Token ID(查詞表得到整數編碼)
便于計算機存儲
4.Token ID到詞向量(查embedding矩陣)
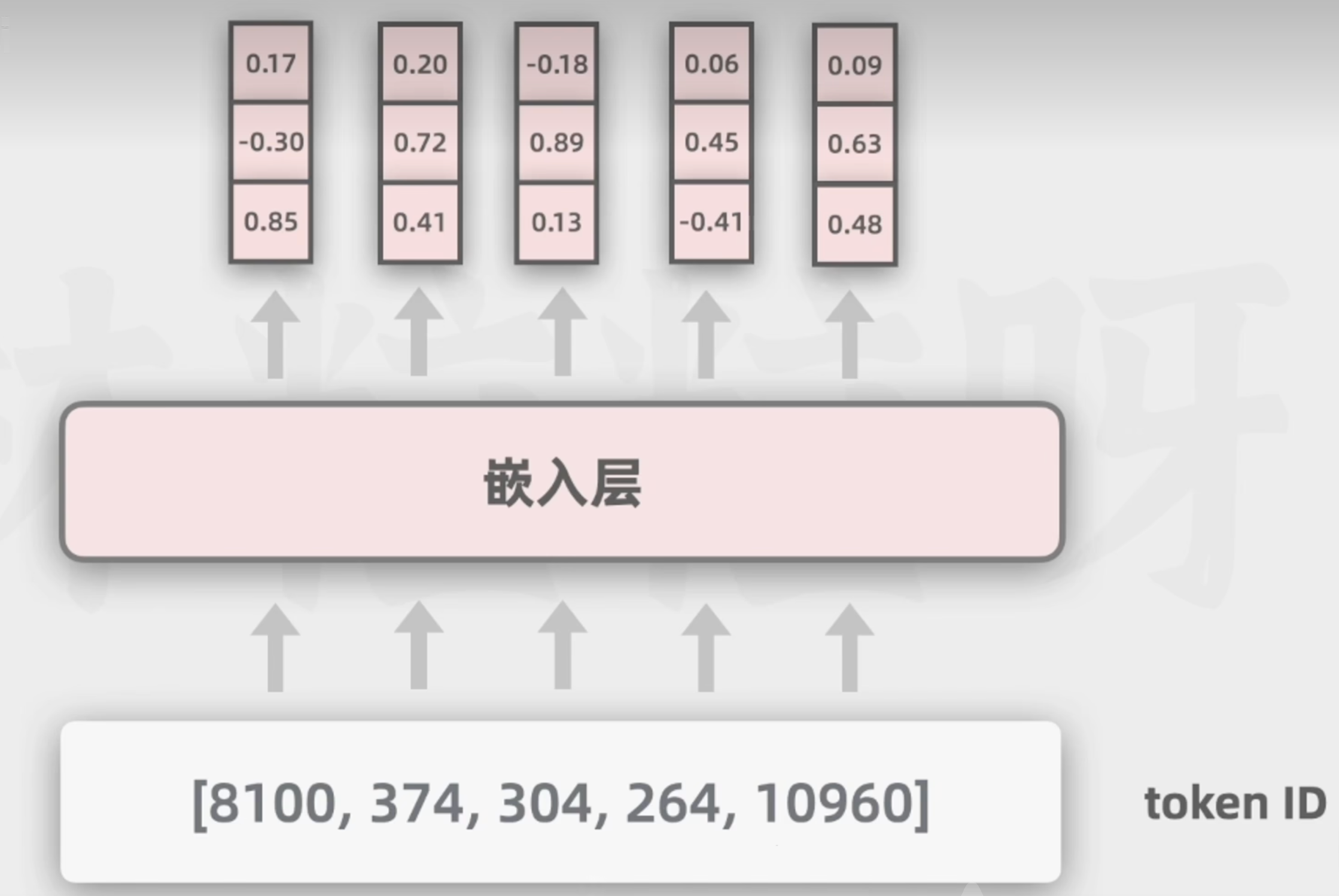
詞向量可以表示更多的維度的含義,利于模型通過數學計算向量空間的距離,去捕捉不同詞在語義和語法等方面的相似性
- 詞的含義
- 詞與詞之間的復雜關系
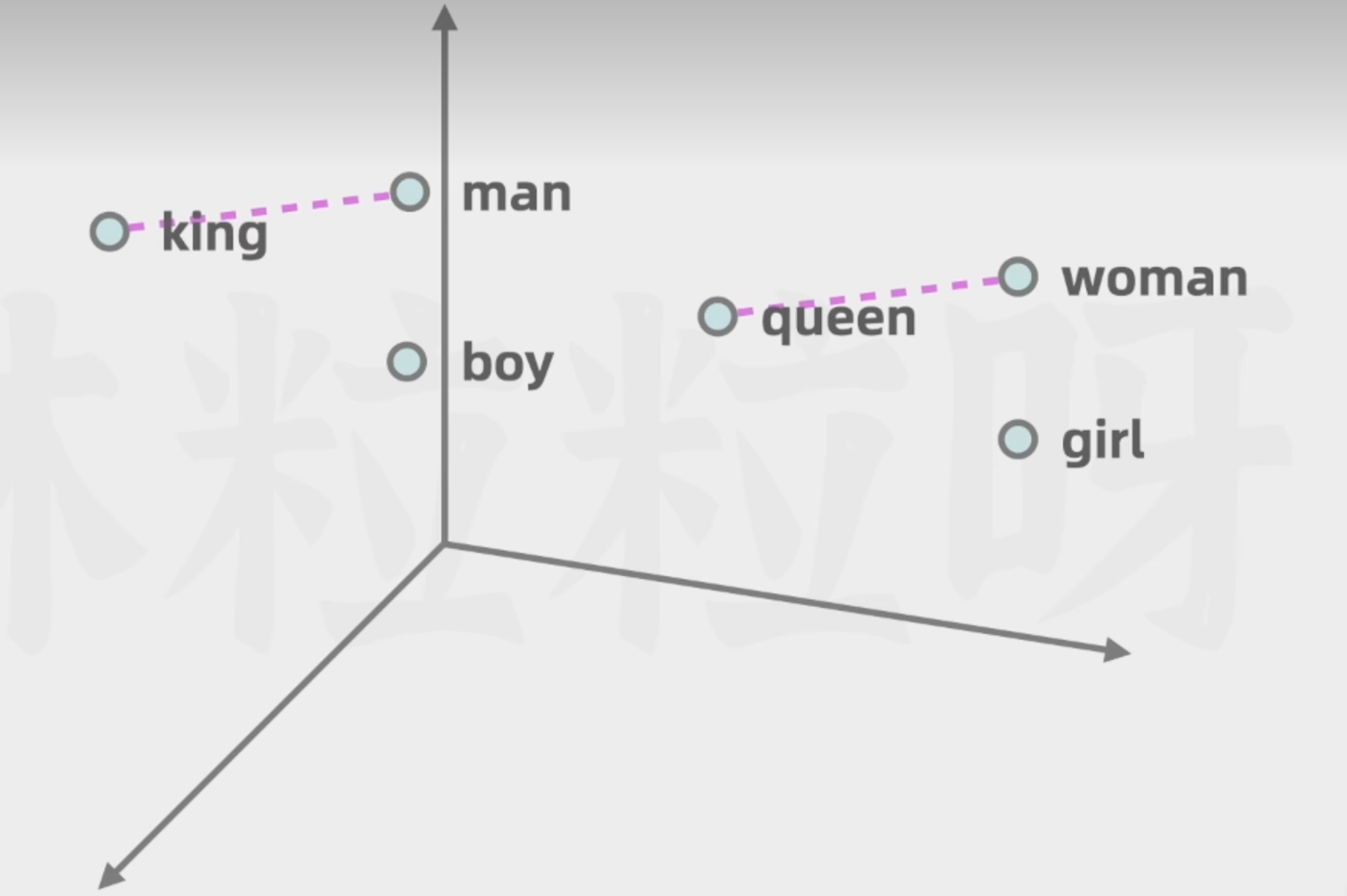
如下圖,男人與國王,女人與女王,兩者之間的差異可以被看作是相似的
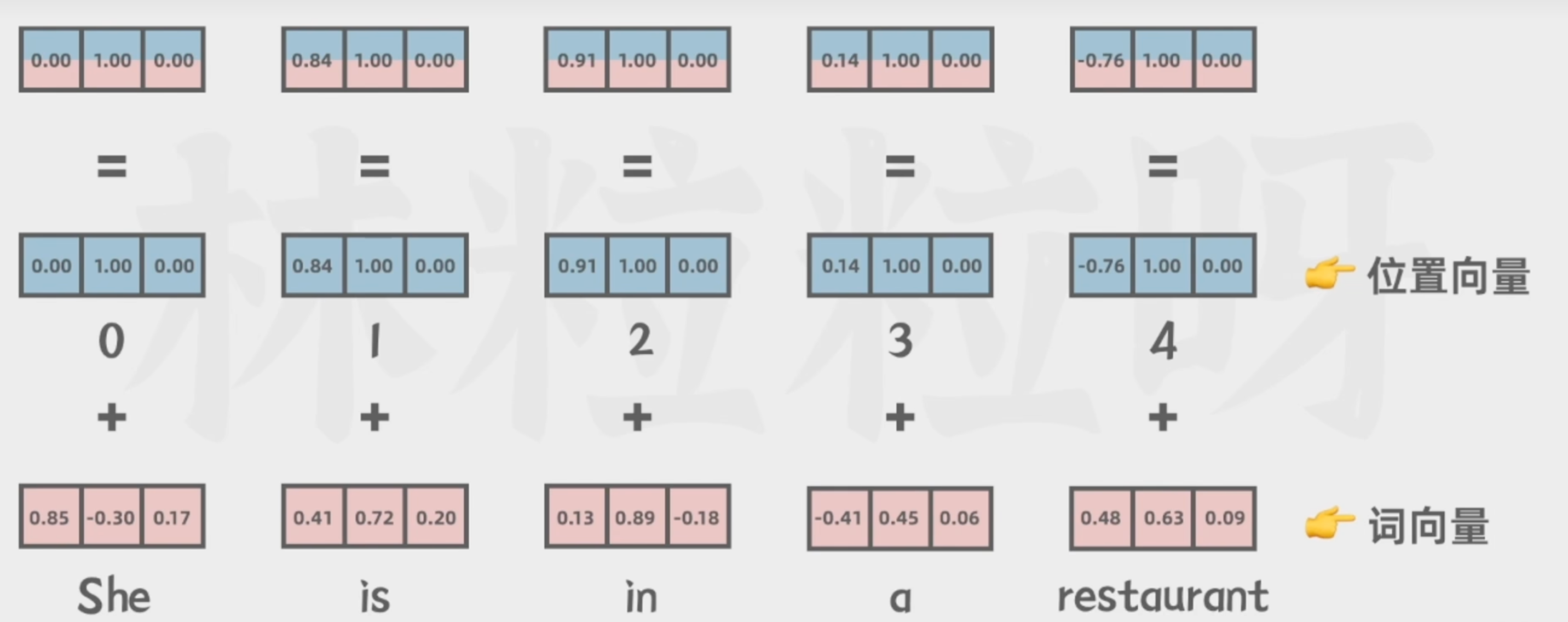
5.詞向量與位置向量相加
讓模型理解不同詞之間的順序關系
Transformer架構
編碼器只做一次(輸入全序列),解碼器每生成一個詞都要重新遞歸一次(擴展目標序列),但會用編碼器已保存的輸出。
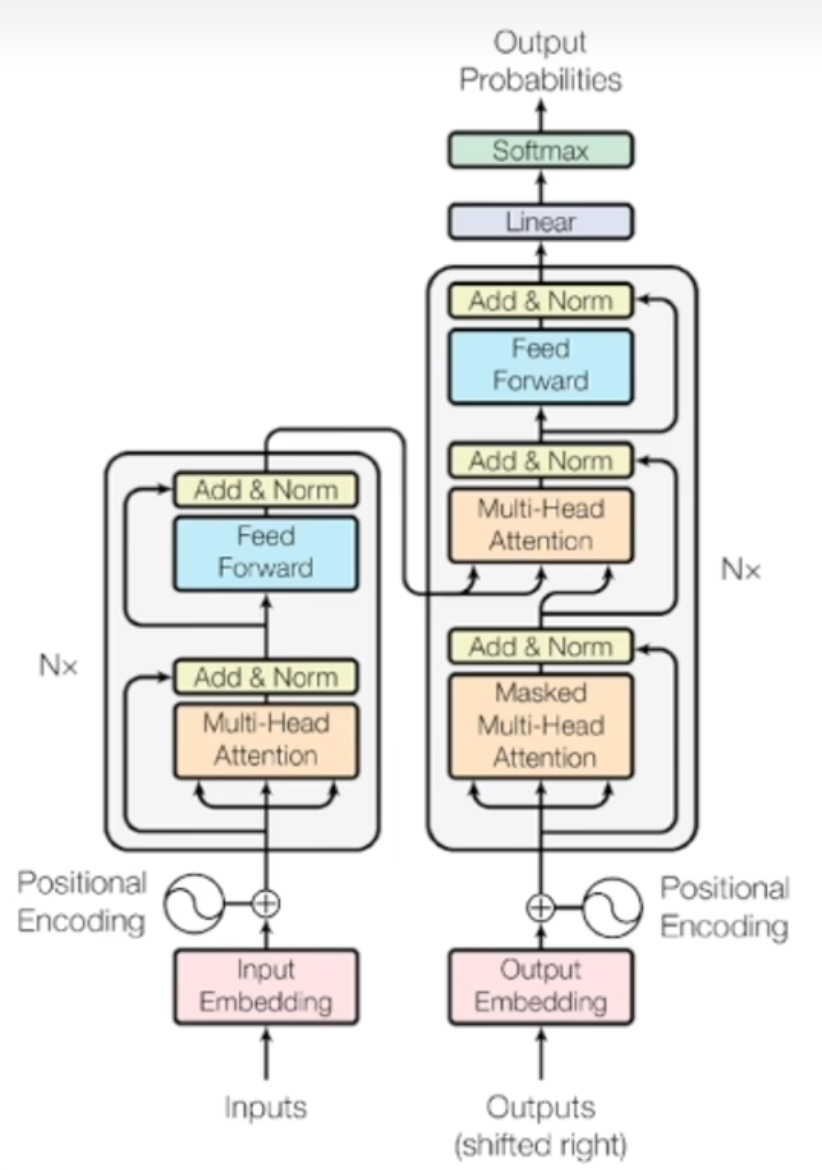
編碼器(模型理解的關鍵)
自注意力機制
作用:
融合上下文中的相關信息
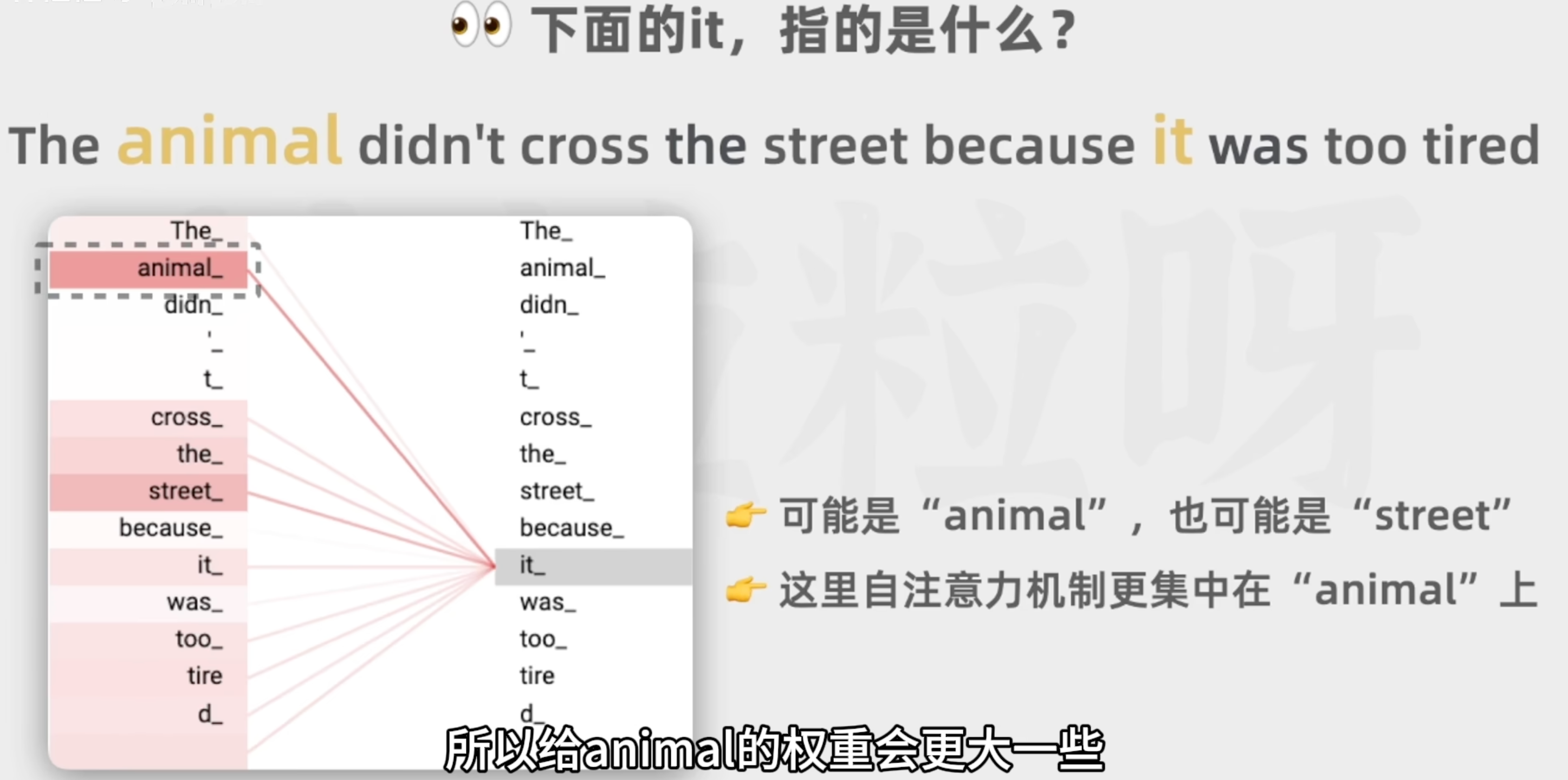
可以有多個自注意力頭,關注情感的,關注命名實體的,可以并行運算
每個自注意力頭的權重是模型在之前的訓練過程中從大量文本里學習和調整的
原理:
用三個權重矩陣Wq、Wk、Wv與每個詞的向量表示相乘后得到q、k、v向量
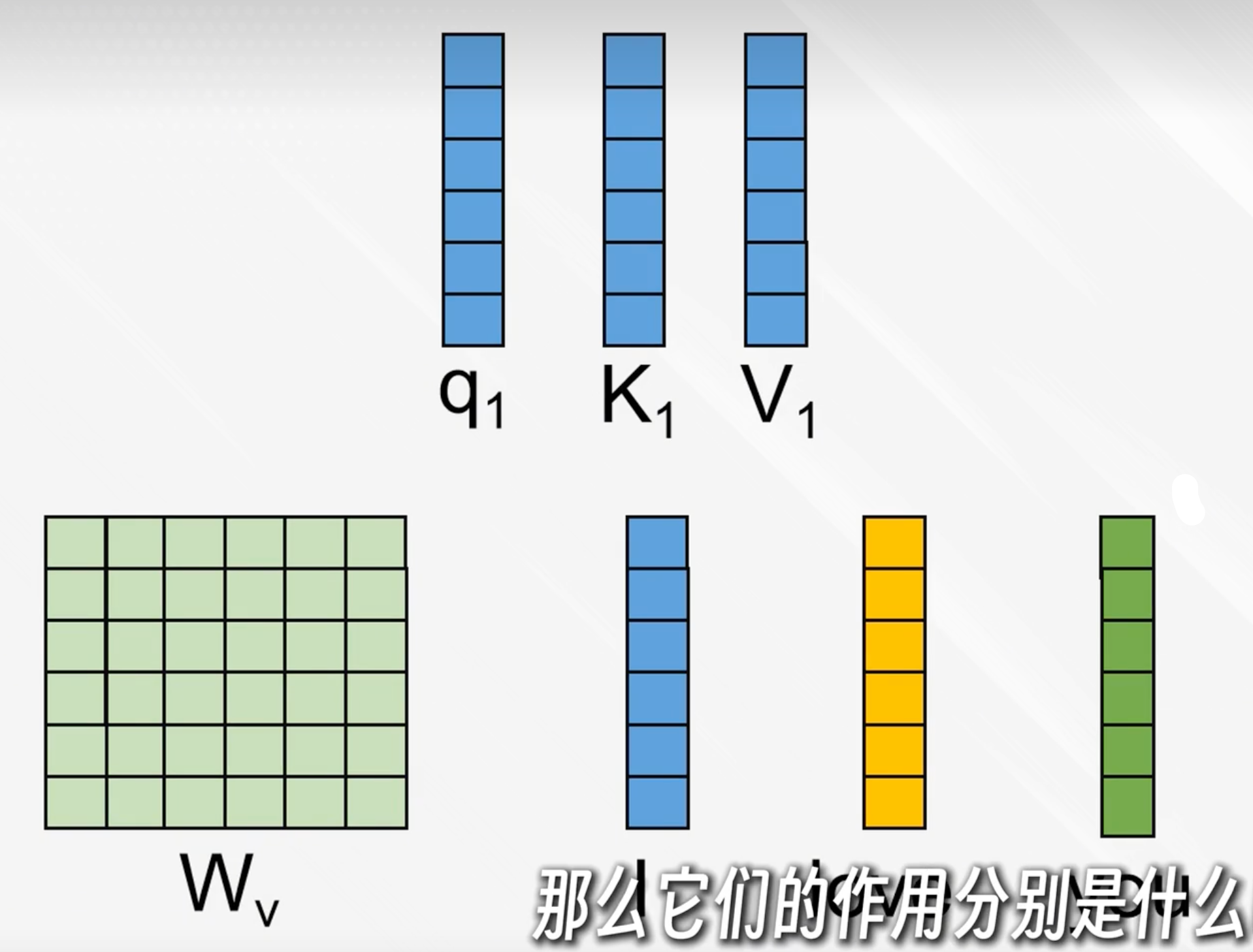
q:我想要找什么
k:你有沒有我要找的東西(權重)
v:我要傳遞的內容
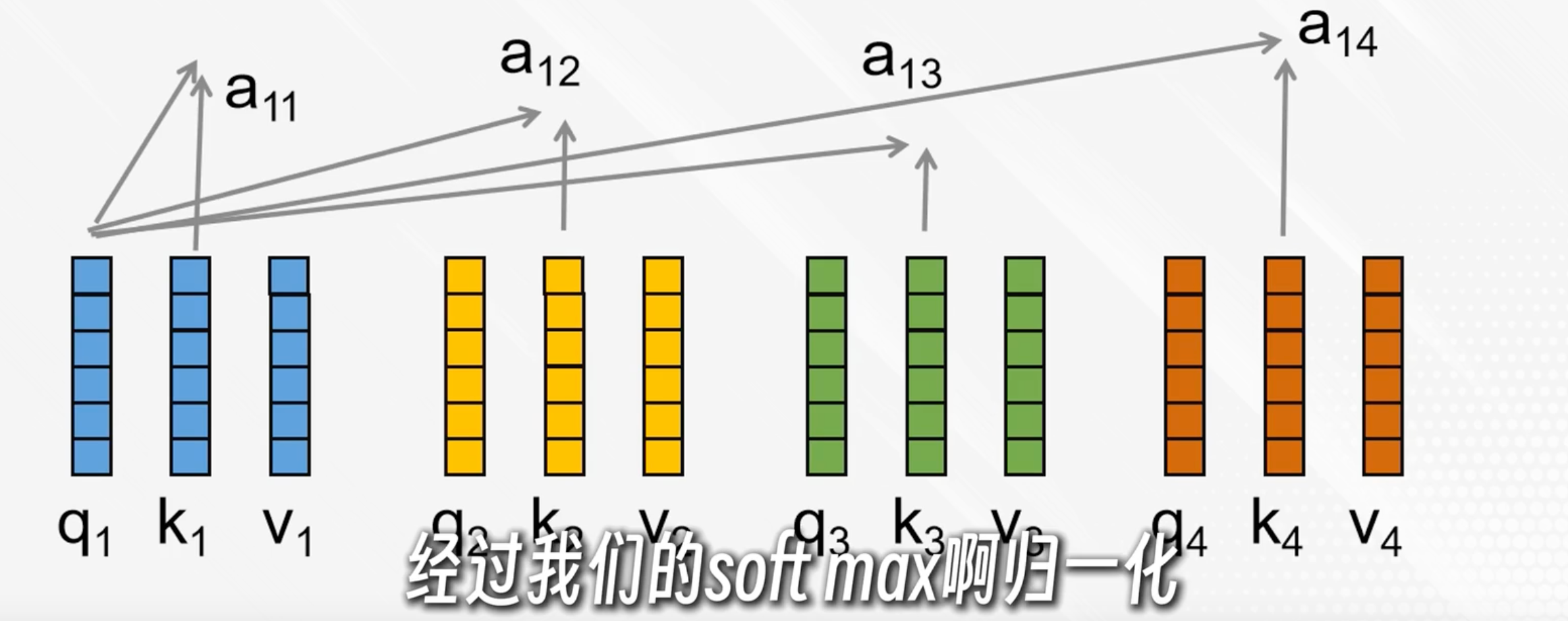
q與每個k點積后各自得到一個分數,經過softmax歸一化變成加權系數aij
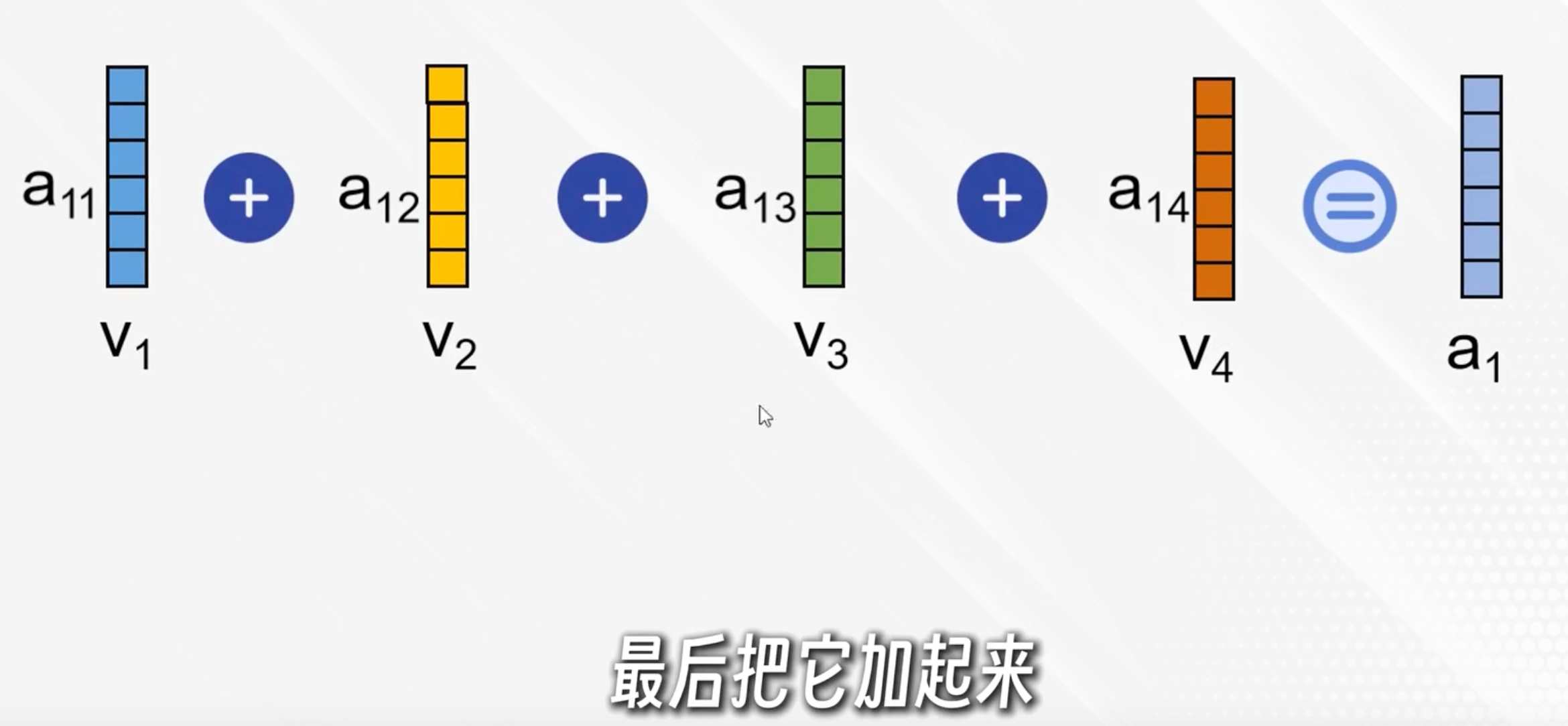
每個加權系數與對應的v點積,再相加,得到ai,表示在第i個詞的視角下,按照權重與其他詞的內容融合
簡單說,ai就是以第i個詞為中心理解了上下文

實際有多個自注意力頭,把對應的拼接起來(如a11+a12)再乘上一個權重矩陣得到輸出
前饋神經網絡
為為每個位置的“單詞”做復雜的、非線性加工
標準FFN結構:
- 一個線性層,升維,通常把d_model提升到更高的d_ff(通常是d_model的4倍)
- 非線性激活(如ReLU或GELU)
- 一個線性層,降維,回到d_model
- 殘差+LayerNorm
假如模型在生成句子時,自注意力層捕捉到了“貓”和“坐在墊子上”的關聯;前饋神經網絡可以進一步細化每個詞的語義,比如讓“坐”這個詞的隱藏向量更好地表達了動作信息,讓“墊子上”這個詞的向量更好地表達了空間關系。最后,經過多層疊加,模型能生成更自然有上下文語義的話。
解碼器(模型生成的關鍵)
解碼器把編碼器的輸出和已經生成的文本作為每次的輸入,保持輸出的連貫性和上下文的相關性
每個解碼器有2個多頭自注意力和一個前饋神經網絡
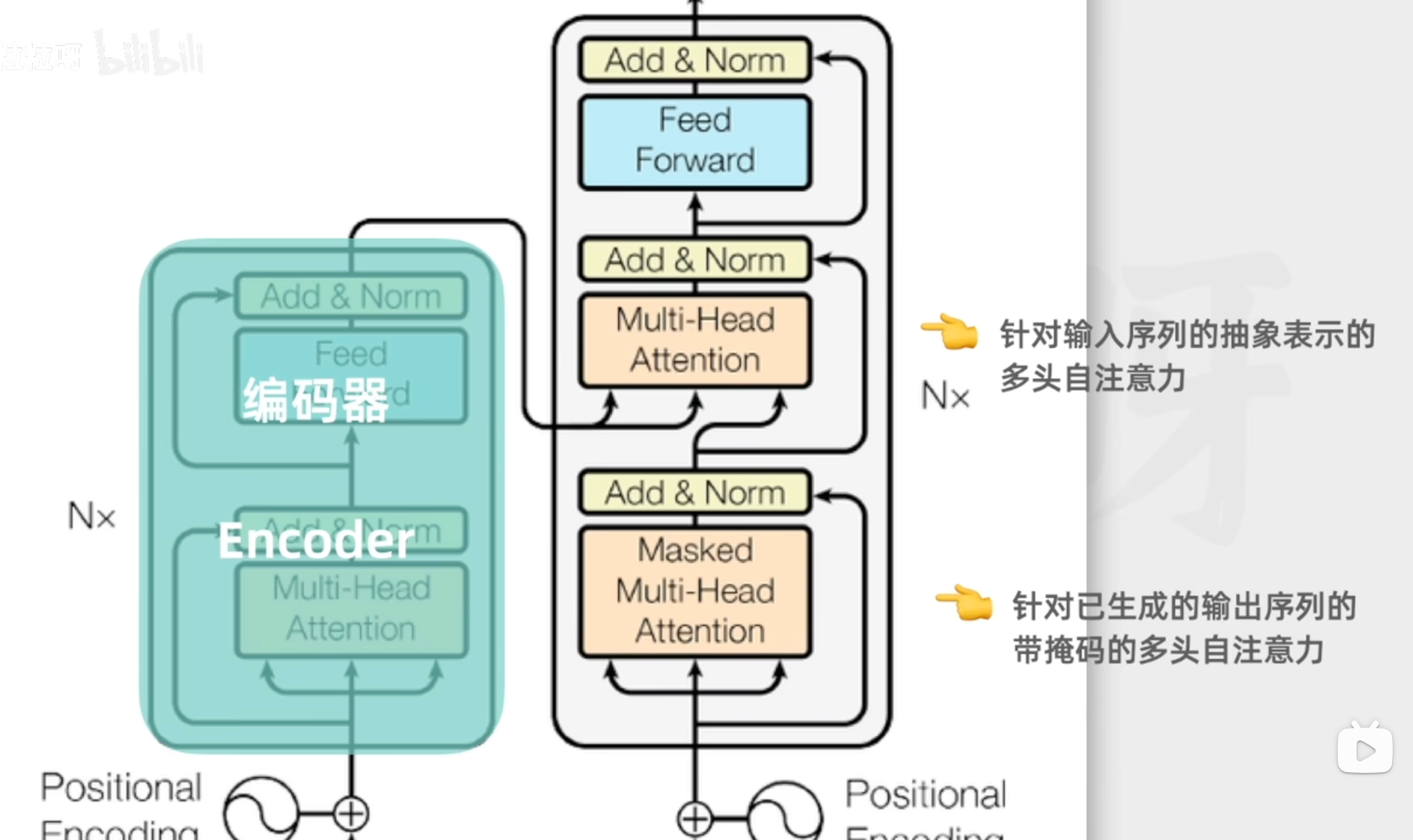
帶掩碼的自注意力機制
針對已生成的輸出序列,只使用前面的詞作為上下文

第二個自注意力機制
捕捉編碼器的輸出的和解碼器即將生成的輸出之間的對應關系,從而將原始輸入序列融合到輸出序列的生成過程中
前饋神經網絡
與編碼器的類似,通過額外計算增強模型的表達能力
輸出層
logits = [3.2, 0.9, -2.0, ...] # 詞表每個詞的分數
softmax = [0.54, 0.13, 0.001, ...] # 轉成概率,每個詞的出現概率線性層
將解碼器輸出的隱藏表示投影到詞表大小(Vocab size),得到每個詞的logits(詞表每個詞的分數)
Softmax層
將logits變為概率分布,用于采樣/選擇下一個詞









)

)



)


:IO與網絡優化的4個關鍵方向)
