Title
題目
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shotdisease classification from chest X-ray
CXR-LT 2024:一場關于基于胸部X線的長尾、多標簽和零樣本疾病分類的MICCAI挑戰賽
01
文獻速遞介紹
CXR-LT系列是一項由社區推動的計劃,旨在利用胸部X光(CXR)改進肺部疾病分類,解決開放性長尾肺部疾病分類中的挑戰,并提升前沿技術的可衡量性(Holste等人,2022)。在首屆活動CXR-LT 2023(Holste等人,2024)中,這些目標通過以下方式實現:提供高質量的胸部X光基準數據用于模型開發,并開展詳細評估以識別影響肺部疾病分類性能的持續性問題。CXR-LT 2023引發了廣泛關注,共有59支團隊提交了超過500份獨特的成果。此后,該任務設置和數據為眾多研究提供了基礎(Hong等人,2024;Huijben等人,2024;Park和Ryu,2024;Li等人,2024a)。 ? 作為該系列的第二項活動,CXR-LT 2024延續了前作的總體設計和目標,同時新增了對零樣本學習的關注。這一補充旨在解決CXR-LT 2023中發現的局限性。據估計,獨特的放射學發現數量超過4500種(Budovec等人,2014),這表明胸部X光臨床發現的實際分布規模至少比現有基準數據集所能覆蓋的范圍大兩個數量級。因此,要有效應對放射學異常發現的“長尾”問題,必須開發能夠以“零樣本”方式對新類別進行泛化的模型。 ? 本文概述了CXR-LT 2024挑戰賽,包括兩項吸引廣泛參與的長尾任務和一項新引入的零樣本任務。任務1和任務2聚焦于長尾分類,其中任務1使用大規模含噪聲測試集,任務2使用小規模人工標注測試集;任務3則針對未見過的疾病進行零樣本泛化。每項任務均遵循CXR-LT 2023確立的總體框架,為參與者提供包含超過25萬張胸部X光圖像和40個二元疾病標簽的大規模自動標注訓練集。參與者的最終提交結果將通過單獨的預留測試集進行評估,該測試集的制備方式與訓練集一致。 ? 在下文章節中,我們將介紹各項任務設置并概述評估標準,詳細說明數據整理流程,隨后呈現每項任務的結果。接著,我們將匯總頂尖解決方案的關鍵見解并提供實踐視角。最后,基于研究發現提出少樣本和零樣本疾病分類的未來發展方向,重點強調多模態基礎模型的應用潛力。
Abatract
摘要
The CXR-LT series is a community-driven initiative designed to enhance lung disease classification usingchest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances themeasurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals byproviding high-quality benchmark CXR data for model development and conducting comprehensive evaluationsto identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identifiedin the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large,noisy test set, (ii) long-tailed classification on a manually annotated ‘‘gold standard’’ subset, and (iii) zeroshot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use ofmultimodal models for rare disease detection, advanced generative approaches to handle noisy labels, andzero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverageto better represent real-world clinical settings, offering a valuable resource for future research. By synthesizingthe insights and innovations of participating teams, we aim to advance the development of clinically realisticand generalizable diagnostic models for chest radiography
CXR-LT
系列是一項由社區推動的計劃,旨在利用胸部X光(CXR)提升肺部疾病分類水平。它致力于應對開放性長尾肺部疾病分類中的挑戰,并增強前沿技術的可衡量性。2023年舉辦的首屆CXR-LT活動,通過提供高質量的胸部X光基準數據用于模型開發,并開展全面評估以找出影響肺部疾病分類性能的現有問題,來實現這些目標。 在CXR-LT 2023取得成功的基礎上,CXR-LT 2024 將數據集擴展到377,110張胸部X光片和45種疾病標簽,其中包括19種新的罕見疾病發現。它還引入了對零樣本學習的新關注,以解決上一屆活動中發現的局限性。具體而言,CXR-LT 2024設置了三項任務:(i)在大規模、含噪聲的測試集上進行長尾分類;(ii)在人工標注的 “金標準” 子集上進行長尾分類;(iii)對五種之前未見過的疾病發現進行零樣本泛化。 本文對CXR-LT 2024進行了概述,詳細介紹了數據整理過程,并匯總了前沿的解決方案,包括使用多模態模型檢測罕見疾病、采用先進的生成方法處理含噪聲標簽,以及針對未見疾病的零樣本學習策略。此外,擴展后的數據集增強了疾病覆蓋范圍,能更好地反映現實臨床場景,為未來研究提供了寶貴資源。通過綜合各參賽團隊的見解和創新成果,我們旨在推動胸部X光臨床實用且具有泛化能力的診斷模型的發展。
Method
方法
2.1. Main tasks
The CXR-LT 2024 challenge includes three tasks: (1) long-tailedclassification on a large, noisy test set, (2) long-tailed classification ona small, manually annotated test set, and (3) zero-shot generalizationto previously unseen diseases. All can be formulated as multi-labelclassification problems.Given the severe label imbalance in these tasks, the primary evaluation metric was mean average precision (mAP), specifically the‘‘macro-averaged’’ AP across classes. While the area under the receiver operating characteristic curve (AUROC) is often used for similardatasets (Wang et al., 2017; Seyyed-Kalantari et al., 2020), it canbe heavily inflated in the presence of class imbalance (Fernándezet al., 2018; Davis and Goadrich, 2006). In contrast, mAP is moresuitable for long-tailed, multi-label settings as it measures the performance across decision thresholds without degrading under-classimbalance (Rethmeier and Augenstein, 2022). For thoroughness, meanAUROC (mAUROC) and mean F1 score (mF1) – with a threshold of 0.5– were computed as auxiliary classification metrics. We also calculatedthe mean expected calibration error (ECE) (Naeini et al., 2015) to quantify bias. To further enhance clinical interpretability, we also reportper-class F1 scores, as well as macro- and micro-averaged F1 scores andfalse-negative rates for critical findings, in addition to the challenge’sprimary evaluation metric. We believe these additions provide a moregranular understanding of model performance in practical settings.
2.1 主要任務 ? CXR-LT 2024挑戰賽包含三項任務:(1)基于大規模含噪聲測試集的長尾分類;(2)基于小規模人工標注測試集的長尾分類;(3)對未見過疾病的零樣本泛化。所有任務均可表述為多標簽分類問題。 ? 鑒于這些任務中存在嚴重的標簽不平衡問題,主要評估指標為平均精度均值(mAP),具體為跨類別的“宏平均”精度(macro-averaged AP)。盡管接收者操作特征曲線下面積(AUROC)常用于類似數據集(Wang等人,2017;Seyyed-Kalantari等人,2020),但在存在類別不平衡時,該指標可能被嚴重高估(Fernández等人,2018;Davis和Goadrich,2006)。相比之下,mAP更適用于長尾多標簽場景,因為它能在不同決策閾值下衡量性能,且不會因類別不平衡而降級(Rethmeier和Augenstein,2022)。為全面評估,我們還計算了平均AUROC(mAUROC)和平均F1分數(mF1,閾值設為0.5)作為輔助分類指標。此外,我們通過平均預期校準誤差(ECE)(Naeini等人,2015)量化偏差。為增強臨床可解釋性,除挑戰賽主要評估指標外,我們還報告了每個類別的F1分數、宏平均和微平均F1分數,以及關鍵發現的假陰性率。我們認為這些補充指標能更細致地反映模型在實際場景中的性能。
Conclusion
結論
In summary, we organized CXR-LT 2024 to address the challengesof long-tailed, multi-label disease classification and zero-shot learningfrom chest X-rays. For this purpose, we have curated and released alarge, long-tailed, multi-label CXR dataset containing 377,110 images,each labeled with one or more findings from a set of 45 diseasecategories. Additionally, we have provided a publicly available ‘‘goldstandard’’ subset with human-annotated consensus labels to facilitatefurther evaluation. Finally, we outline a pathway to enhance the reliability, generalizability, and practicality of methods, with the ultimategoal of making them applicable in real-world clinical settings.
總之,我們舉辦CXR-LT 2024是為了應對基于胸部X光的長尾、多標簽疾病分類及零樣本學習挑戰。為此,我們整理并發布了一個大規模、長尾分布的多標簽胸部X光數據集,包含377,110張圖像,每張圖像均標注有45種疾病類別中的一種或多種發現。此外,我們還提供了一個公開可用的“金標準”子集,該子集帶有人工標注的共識標簽,以方便進一步評估。最后,我們概述了提升方法可靠性、泛化性和實用性的路徑,最終目標是使其能夠應用于真實臨床場景。
Results
結果
3.1. Participation
The CXR-LT challenge received 96 team applications on CodaLab,of which 61 were approved after providing proof of credentialed accessto MIMIC-CXR-JPG (Johnson et al., 2019b). During the DevelopmentPhase, 29 teams participated, submitting a total of 661, 349, and 364unique submissions to the public leaderboard for Tasks 1, 2, and 3,respectively. In the final Test Phase, a total of 17 teams participated.We selected the top 9 teams for the invitation to present at the CXR-LT2024 challenge event at MICCAI 20246 and for inclusion in this study.Since two teams excelled in both Tasks 1 and 2, this comprised the top 4solutions in Tasks 1 and 2 as well as the top 3 solutions for the zero-shotTask 3. Table 3 summarizes the top-performing groups participating inone or more of these tasks and system descriptions. Additional details,including all presentation slides, are available on GitHub,7 allowingreaders to explore the specifics of all methods in greater depth.
3.1 參與情況 ? CXR-LT挑戰賽在CodaLab平臺收到了96支團隊的申請,其中61支團隊在提交MIMIC-CXR-JPG數據集的授權訪問證明后(Johnson等人,2019b)獲得批準。在開發階段,共有29支團隊參與,分別向任務1、任務2和任務3的公開排行榜提交了661份、349份和364份獨特的結果。在最終測試階段,共有17支團隊參與。 ? 我們選取了排名前9的團隊,邀請其在MICCAI 2024的CXR-LT 2024挑戰賽活動中進行成果展示,并納入本研究。由于有兩支團隊在任務1和任務2中均表現優異,最終包含任務1和任務2的前4名解決方案,以及零樣本任務3的前3名解決方案。表3匯總了參與一項或多項任務的頂尖團隊及其系統描述。更多細節(包括所有演示幻燈片)可在GitHub上獲取,供讀者深入了解所有方法的具體細節。
Figure
圖
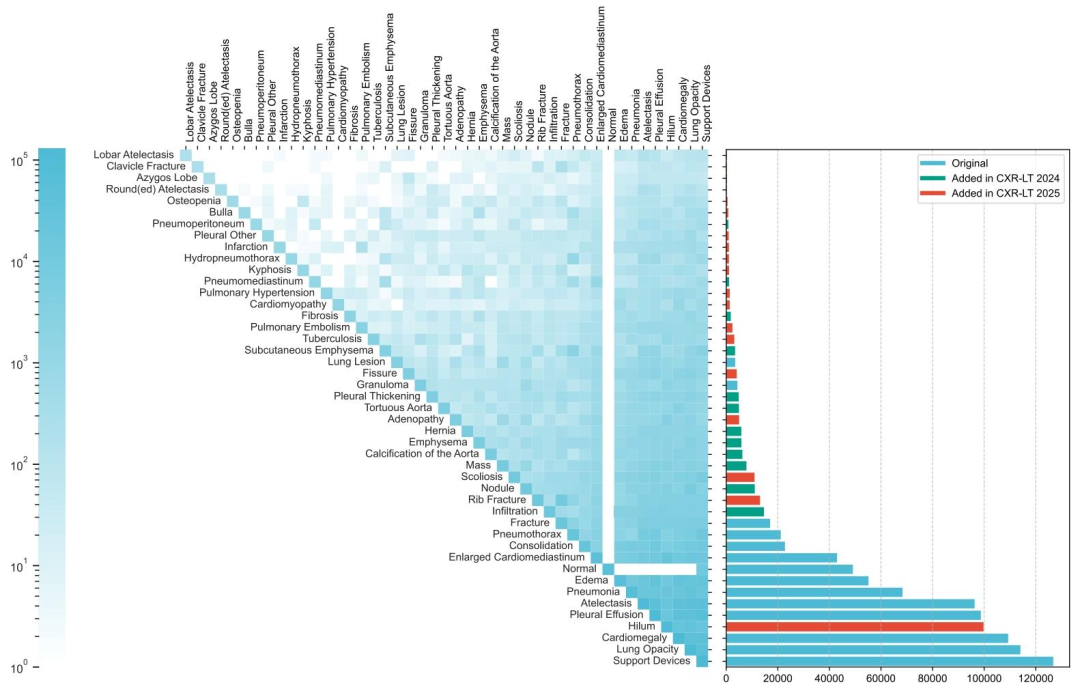
Fig. 1. Long-tailed distribution of the CXR-LT 2024 challenge dataset. The dataset was formed by extending the MIMIC-CXR benchmark to include 12 new clinical findings (red)by parsing radiology reports.
圖1 CXR-LT 2024挑戰數據集的長尾分布。該數據集通過擴展MIMIC-CXR基準數據集形成,新增了12種通過解析放射學報告獲得的臨床發現(紅色標注)。
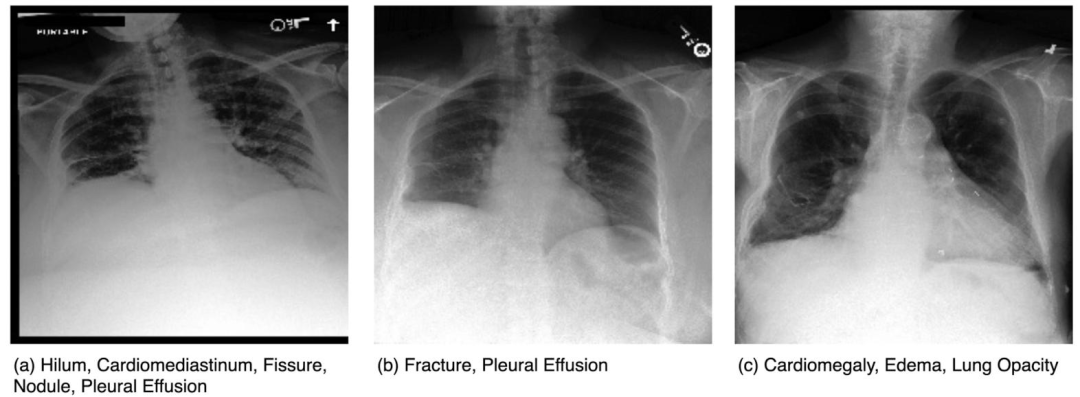
Fig. 2. Representative chest X-rays from the challenge dataset, each demonstrating multiple findings. (a) Includes the Hilum label (new in CXR-LT 2024); (b) shows Fracture(introduced in CXR-LT 2023); and (c) displays original MIMIC-CXR labels (Cardiomegaly, Edema, Lung Opacity).
圖2 挑戰數據集中具有代表性的胸部X光圖像,每張圖像均顯示多種病變。(a)包含肺門(Hilum)標簽(CXR-LT 2024新增);(b)顯示骨折(Fracture,CXR-LT 2023引入);(c)展示原始MIMIC-CXR標簽(心臟擴大、水腫、肺部實變)。
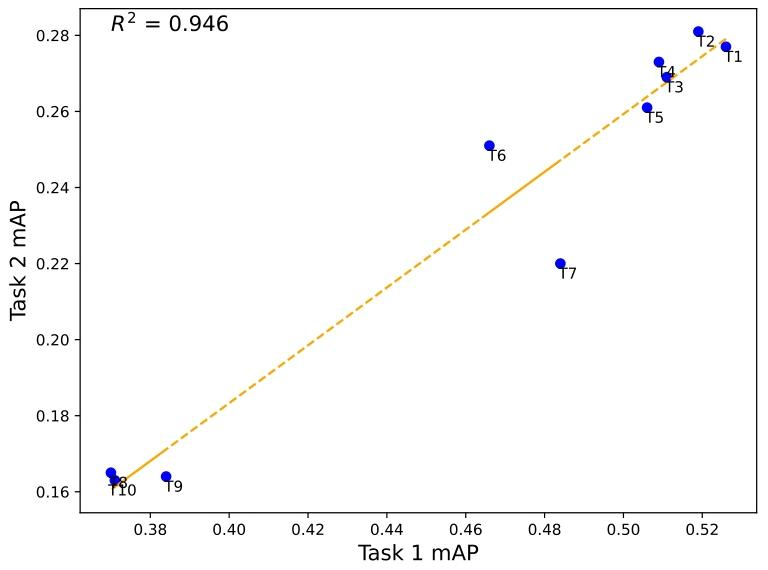
Fig. 3. Comparison of performance on CXR-LT Task 1 data (Section 2.2.1) and goldstandard Task 2 data (Section 2.2.2).
圖3 CXR-LT任務1數據(第2.2.1節)與金標準任務2數據(第2.2.1節)的性能對比。
Table
表
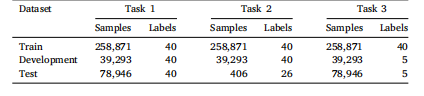
Table 1Characteristics of the datasets used in the three tasks
表1 三項任務所用數據集的特征
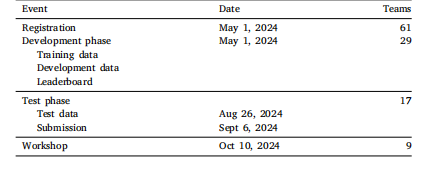
Table 2Schedule of CXR-LT 2024
表2 CXR-LT 2024的時間安排
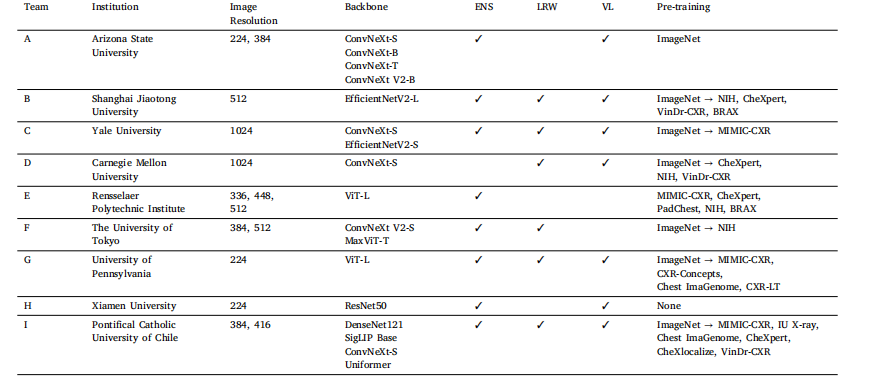
Table 3Overview of top-performing CXR-LT 2024 challenge solutions. ENS - ensemble; LRW - loss reweighting; VL - vision-language
表3 CXR-LT 2024挑戰賽頂尖解決方案概述 ?
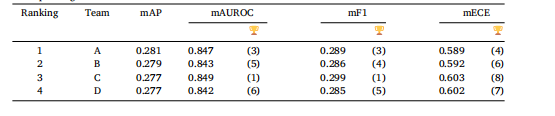
Table 4mAP of top-4 team’s final model on all 40 classes evaluated on the test set in Task 1. mAUROC, mF1,and mECE are also presented, with the numbers in parentheses indicating the rankings based on thecorresponding evaluation metric
表4 前4名團隊的最終模型在任務1測試集的全部40個類別上的平均精度均值(mAP)。表中還展示了平均接收者操作特征曲線下面積(mAUC)、平均F1分數(mF1)和平均預期校準誤差(mECE),括號中的數字表示基于相應評估指標的排名。
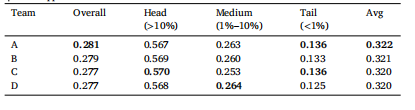
Table 5Long-tailed classification performance on ‘‘head’’, ‘‘medium’’, and ‘‘tail’’ classes byaverage mAP within each category. These categories were determined by the relativefrequency of each class in the training set (denoted in parentheses). The rightmostcolumn denotes the average of head, medium, and tail mAP. The best mAP in eachcolumn appears in bold.
表5 基于“頭部”“中等”和“尾部”類別的長尾分類性能(按每個類別內的平均mAP計算)。這些類別根據各類別在訓練集中的相對頻率確定(括號內為頻率標注)。最右側一列表示頭部、中等和尾部類別mAP的平均值。每列中最佳mAP以粗體顯示。
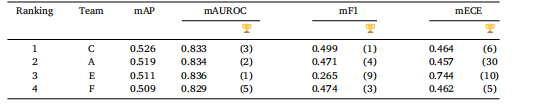
Table 6mAP of top-4 team’s final model on all 26 classes evaluated on the Gold standard test set in Task 2.mAUROC, mF1, and mECE are also presented, with the numbers in parentheses indicating the rankingsbased on the corresponding evaluation metric.
表6 前4名團隊的最終模型在任務2金標準測試集的全部26個類別上的平均精度均值(mAP)。表中還展示了平均接收者操作特征曲線下面積(mAUC)、平均F1分數(mF1)和平均預期校準誤差(mECE),括號中的數字表示基于相應評估指標的排名。?

Table 7Performance evaluation of the final models from the top 3 teams on the test set for all five unseen classesin Task 3. mAUROC, mF1, and mECE are also presented, with the numbers in parentheses indicating therankings based on the corresponding evaluation metric.
表7 前3名團隊的最終模型在任務3測試集的全部5個未見過類別上的性能評估。表中還展示了平均接收者操作特征曲線下面積(mAUC)、平均F1分數(mF1)和平均預期校準誤差(mECE),括號中的數字表示基于相應評估指標的排名。
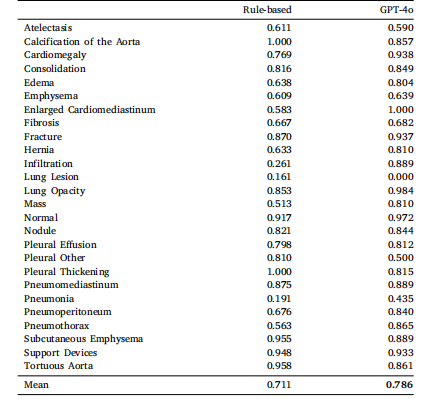
Table 8Performance of models on long-tailed, multi-label disease classification evaluated usingmicro-precision on our gold standard test set
表8 基于金標準測試集,采用微精度評估的長尾多標簽疾病分類模型性能
 的界面和功能)
![[NCTF2019]True XML cookbook](http://pic.xiahunao.cn/[NCTF2019]True XML cookbook)







)




)




