
【導讀】
本文提出 DarkNet-YOLO 工業級實踐框架,通過引入 殘差優化結構 與 多尺度特征融合技術,在保持實時檢測精度同時顯著提升復雜場景適應性。
目錄
一、目標檢測的進化之路:從“兩步走”到“一眼定乾坤”
YOLO的核心思想:
二、DarkNet:YOLO背后的“鋼筋鐵骨”
簡單理解DarkNet:
三、實戰演練:用YOLO(DarkNet)為自動駕駛“開眼”
項目成果展示:
開發效率升級:
四、挑戰與前沿
前沿技術正在破局:
高級訓練技巧:
五、從實驗室到改變世界:無處不在的目標檢測
案例聚焦
結語:目光所及,未來已來
想象一下,讓計算機不僅能認出你桌上的咖啡杯,還能精準地指出它所在的位置——這正是目標檢測(Object Detection)的魅力所在。作為計算機視覺的核心任務,目標檢測的飛速發展,尤其是近十年的突破,幾乎完全歸功于機器學習,特別是卷積神經網絡(CNN)的革命。而在眾多突破性成果中,DarkNet這個開源高性能框架功不可沒,它正是大名鼎鼎的YOLO(You Only Look Once)系列目標檢測器背后的強大引擎。今天,我們就來深入剖析DarkNet與YOLO的理論基礎、實戰技巧,并一窺它們在現實世界(如自動駕駛)中的驚艷表現。
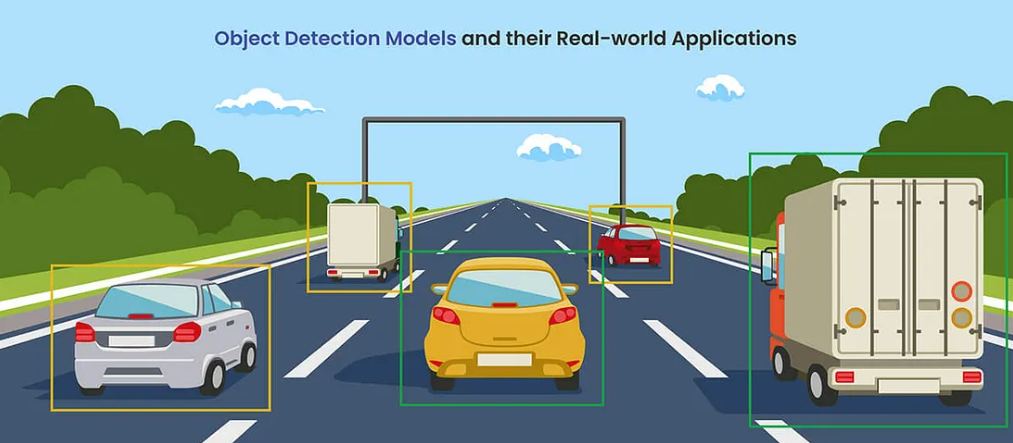
一、目標檢測的進化之路:從“兩步走”到“一眼定乾坤”
目標檢測的核心挑戰在于精準定位(Localization)。早期的深度學習方法,如R-CNN家族,采用“先找候選區域,再分類”的兩步策略,雖準但慢。
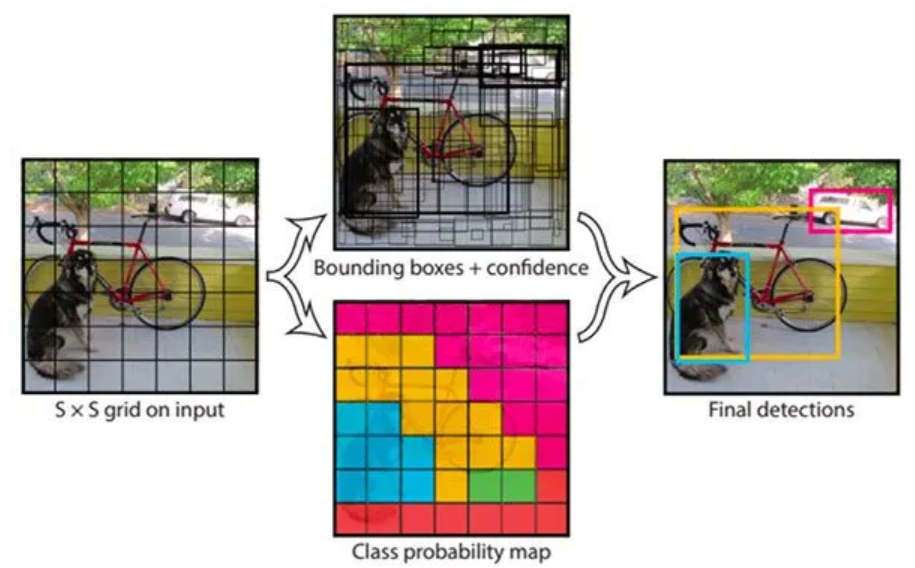
真正的變革來自單階段(One-Stage)檢測器,以YOLO為代表。它將檢測視為一個統一的任務:只需“看一眼”圖像,就能同時預測出圖像中所有物體的位置和類別。這種設計理念犧牲了少許精度,卻換來了驚人的速度,為自動駕駛、實時監控等應用打開了大門。而YOLO速度的秘訣,很大程度上源于其精心設計的骨干網絡——DarkNet。
-
YOLO的核心思想:
YOLO將輸入圖像劃分為網格(Grid)。每個網格單元負責預測:
-
邊界框(Bounding Boxes):預測多個可能包含物體的框。
-
置信度(Confidence Scores):表示框內包含物體且預測準確的程度。
-
類別概率(Class Probabilities):預測框內物體屬于各個類別的可能性。
通過一次性處理整個圖像并理解其上下文,YOLO大幅減少了誤檢,并利用非極大值抑制(Non-Maximum Suppression, NMS)?等技術精煉最終檢測結果,實現了速度與精度的卓越平衡。
二、DarkNet:YOLO背后的“鋼筋鐵骨”
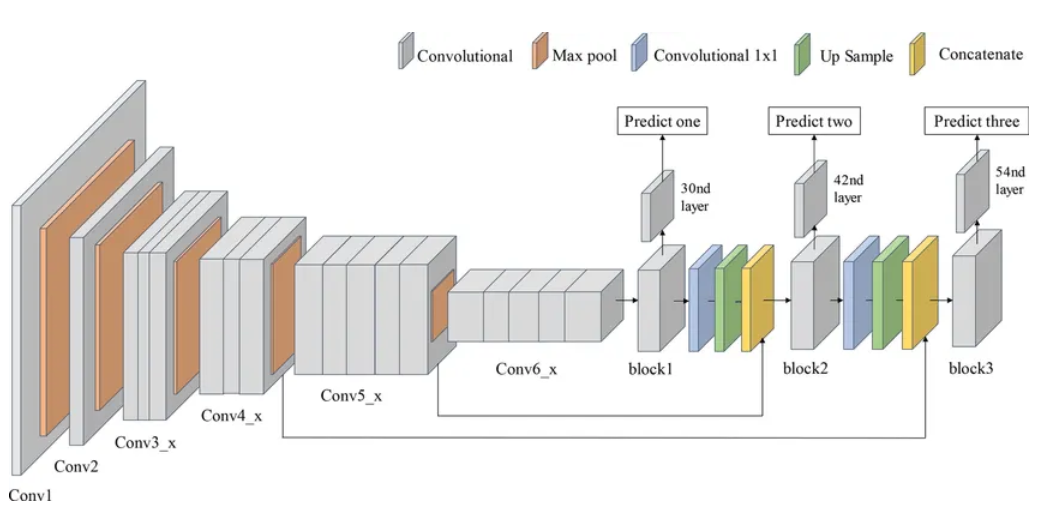
DarkNet并非一成不變。從輕量級的DarkNet-19,到助力YOLOv3登上巔峰的DarkNet-53,它不斷進化。
-
深度與效率:DarkNet-53擁有53個卷積層,深度甚至超過著名的ResNet。它擅長從圖像中提取多尺度特征——既能識別汽車的輪廓,也能捕捉車窗上的微小反光。
-
核心優勢-殘差連接(Shortcut/Residual Connections):這是DarkNet高效訓練的關鍵。它讓信息在網絡層間更順暢地流動,有效緩解了深層網絡普遍面臨的梯度消失(Vanishing Gradients)問題,使模型更穩定。
-
持續進化:研究者們不斷吸收如DenseNet等架構的優點,通過增強層間連接和特征復用,使模型對小目標、遮擋物體的檢測更加魯棒(Robust),更能適應復雜多變的真實環境。
-
簡單理解DarkNet:
圖像依次通過層層卷積網絡:
-
淺層:識別基礎模式(邊緣、顏色)。
-
深層:理解復雜特征(形狀、紋理)。
-
殘差連接:如同“信息高速公路”,確保關鍵信號不丟失,讓整個系統高效地完成目標定位與識別。不必糾結于每個細節框,它們共同構成了一個強大、快速、準確的檢測引擎。
三、實戰演練:用YOLO(DarkNet)為自動駕駛“開眼”
理論需要實踐檢驗。在筆者進行的自動駕駛目標檢測項目中,核心就是運用了基于DarkNet的YOLO模型。以下是關鍵代碼環節的思路解析(非完整代碼):
-
模型加載:
import tensorflow as tf
darknet = tf.keras.models.load_model(model_path, compile=False) # 加載預訓練DarkNet模型作用:加載預訓練好的DarkNet模型(TensorFlow Keras格式),準備用于推理(檢測)。
-
視頻目標檢測函數?(detect_video):
import cv2
from PIL import Image
import numpy as np
from your_detection_module import detect_image # 假設這是你實現單幀檢測的函數
def detect_video(video_path, output_path, obj_thresh=0.4, nms_thresh=0.45, darknet=darknet, net_h=416, net_w=416, anchors=anchors, labels=labels):"""處理視頻文件,對每一幀進行目標檢測并保存結果視頻。參數:video_path: 輸入視頻文件路徑output_path: 輸出視頻文件路徑obj_thresh: 目標置信度閾值nms_thresh: 非極大值抑制閾值darknet: 加載的DarkNet模型net_h, net_w: 模型輸入高度和寬度anchors: YOLO錨框labels: 類別標簽列表"""# 打開輸入視頻vid = cv2.VideoCapture(video_path)if not vid.isOpened():raise IOError("Couldn't open webcam or video")# 獲取視頻屬性并創建VideoWritervideo_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC))video_FourCC = cv2.VideoWriter_fourcc(*'mp4v') # 使用MP4V編碼video_fps = vid.get(cv2.CAP_PROP_FPS)video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)# 處理每一幀num_frame = 0while vid.isOpened():ret, frame = vid.read()num_frame += 1print("=== 正在處理第 {} 幀 ===".format(num_frame))if ret:# 將OpenCV BGR幀轉換為RGB (PIL/模型通常使用RGB)frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)pil_image = Image.fromarray(frame_rgb)# 核心檢測步驟:調用單幀檢測函數 (這里假設detect_image返回帶標注的PIL圖像)# 在實際項目中,模型的推理邏輯封裝在detect_image或類似函數里。# 如果使用Coovally平臺,其推理SDK或API調用可以方便地集成在此處進行預測。detected_image = detect_image(pil_image, darknet, net_h, net_w, anchors, labels, obj_thresh, nms_thresh)# 將檢測結果(PIL Image)轉換回OpenCV BGR格式用于寫入視頻detected_frame_cv = cv2.cvtColor(np.array(detected_image), cv2.COLOR_RGB2BGR)# 寫入處理后的幀到輸出視頻out.write(detected_frame_cv)else:break # 視頻結束# 釋放資源vid.release()out.release()print("目標檢測視頻已保存至: ", output_path)作用: 處理整個視頻流。核心在于對每一幀圖像實時運行YOLO目標檢測算法,并將檢測結果(框出的物體)合成到新視頻中。
-
運行檢測:
video_path = '/path/to/input_video.mp4'
output_path = '/path/to/output_video_detected.mp4'
detect_video(video_path, output_path) # 執行視頻檢測作用: 指定輸入視頻路徑和輸出視頻路徑,調用detect_video函數,生成包含目標檢測結果的視頻。
-
項目成果展示:
處理前幀示例:?

處理后幀示例:
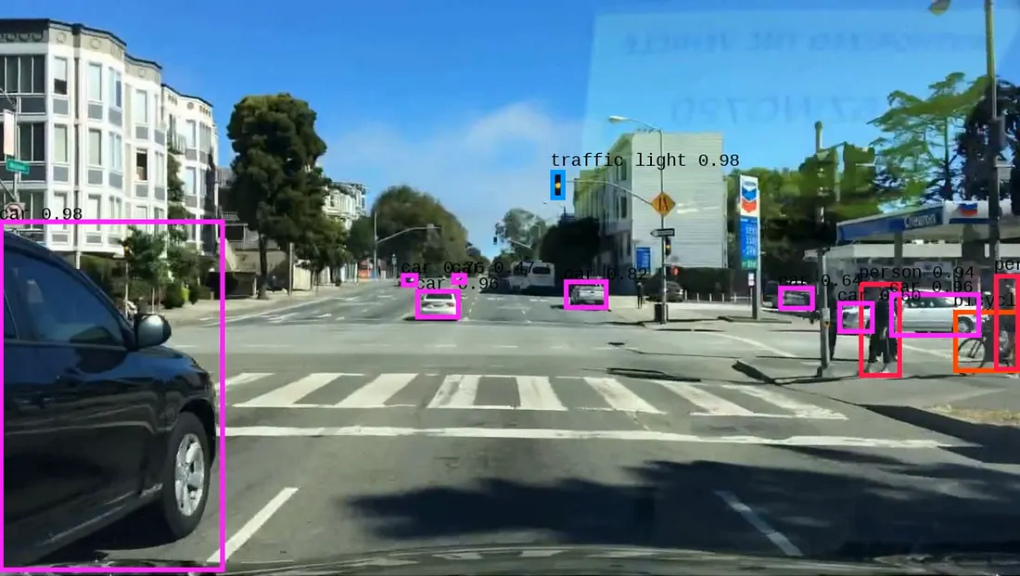
系統能力:
模型能夠持續檢測并追蹤道路上的關鍵目標(車輛、行人、車道線等)。通過逐幀分析并結合邊界框傳播技術,系統能穩定、精確地識別移動中的車輛,清晰展示自動駕駛汽車如何感知并理解其周圍動態環境。
四、挑戰與前沿
盡管基于CNN和DarkNet的檢測器已非常強大,挑戰依然嚴峻:
-
惡劣環境:低光照、極端天氣下的檢測。
-
密集與遮擋:區分緊密相鄰、部分或完全遮擋的物體。
-
復雜背景:背景干擾物多。
-
前沿技術正在破局:
-
無錨框(Anchor-Free)檢測:簡化設計,提升靈活性。
-
多任務學習(Multi-Task Learning):同時優化檢測及相關任務(如語義分割)。
-
領域自適應(Domain Adaptation):提升模型在不同場景(如不同城市道路、不同攝像頭)下的泛化能力。
-
高級訓練技巧:
-
Mosaic?數據增強: 將多張圖像拼接訓練,模擬復雜場景,提升魯棒性。
-
改進的損失函數(如?CIoU Loss): 更精準地優化邊界框的位置和大小。
-
這些進步在Pascal VOC、COCO、KITTI等權威基準數據集上不斷刷新著性能記錄。
五、從實驗室到改變世界:無處不在的目標檢測
DarkNet與YOLO引領的目標檢測技術已深刻融入我們的生活:
-
自動駕駛: 實時感知車輛、行人、交通標志(如特斯拉Autopilot核心組件)。
-
智能安防: 監控視頻中異常行為/物體識別。
-
工業檢測: 自動化產品缺陷檢測。
-
智慧農業/生態: 無人機/衛星圖像中的農作物監測、野生動物追蹤。
-
零售分析: 顧客行為分析、商品識別。
-
案例聚焦
特斯拉Autopilot是DarkNet/YOLO類技術落地的典范:
-
環繞攝像頭陣列: 提供多視角、高分辨率的實時視覺數據流。
-
強大的神經網絡: 基于類似YOLO的架構,單次前向傳播即可同時識別車輛、行人、標志、車道線等多種目標。
-
速度與精度平衡: 滿足自動駕駛對低延遲和高可靠性的嚴苛要求。
-
傳感器融合 + AI決策: 結合其他傳感器數據,構建環境感知模型,實現安全導航和實時決策。
結語:目光所及,未來已來
以DarkNet為基石、以YOLO為代表的目標檢測技術,結合先進的神經網絡設計和訓練方法,完美詮釋了理論與工程實踐結合如何驅動科技進步。架構間的持續探索與實驗,預示著未來的系統將在性能和優雅性上超越今天。
探索DarkNet、CNN和機器學習驅動的目標檢測世界,僅僅是觸及了人工智能與計算機科學廣袤天地的冰山一角。每一次深入學習都讓人既感謙卑又興奮不已——學得越多,越能感受到創新、創造以及改變人機交互方式的無限可能。這種理論、實踐與持續發現的精妙融合,正是驅使我們深入探索這些重塑未來技術的源動力。
正如計算機科學先驅艾倫·圖靈所言:
“我們目光所及有限,然應做之事無窮。” ("We can only see a short distance ahead, but we can see plenty there that needs to be done.")
讓我們懷抱好奇心與承諾,擁抱前方的挑戰。因為每一次前進,都在為機器理解并增強人類體驗的征程上,開辟著新的機遇。
這,只是我們邁向科技未來之旅的起點。在這里,創新與影響力交匯,每一項發現都讓我們通過人工智能的力量,離改變世界更近一步。




)





 和 完全二叉樹 (Complete Binary Tree))
的機制)

)


詳解)



