論文信息
論文標題:StoryWriter: A Multi-Agent Framework for Long Story Generation
論文作者:Haotian Xia, Hao Peng et al. (Tsinghua University)
論文鏈接:https://arxiv.org/abs/2506.16445
代碼鏈接:https://github.com/THU-KEG/StoryWriter 未提供運行代碼
研究背景與動機
核心挑戰: 現有大語言模型(LLMs)生成長篇故事(>1000詞)存在兩大瓶頸:
- 語篇連貫性(Discourse Coherence):長文本中難以維持情節一致性、邏輯連貫性與完整性(如角色/事件關系丟失)。
- 敘事復雜性(Narrative Complexity):LLM生成故事同質化嚴重,缺乏人類敘事的交織結構與吸引力。
現有方法局限: 傳統基于LLM的提綱生成方法缺乏細粒度事件控制,導致生成內容單一且邏輯松散。
核心貢獻
- 提出了一種多智能體框架 STORYWRITER ,用于高質量長篇故事生成。
- 構建了一個高質量的長篇故事數據集 LONGSTORY ,包含約6000個平均長度為8000詞的故事。
- 基于 LONGSTORY 對 Llama3.1-8B 和 GLM4-9B 進行監督微調,訓練出性能優越的長篇故事生成模型 STORYWRITERLLAMA 和 STORYWRITERGLM 。
- 在多個評估指標上驗證了 STORYWRITER 的有效性,并通過消融實驗分析各模塊的作用。
StoryWriter
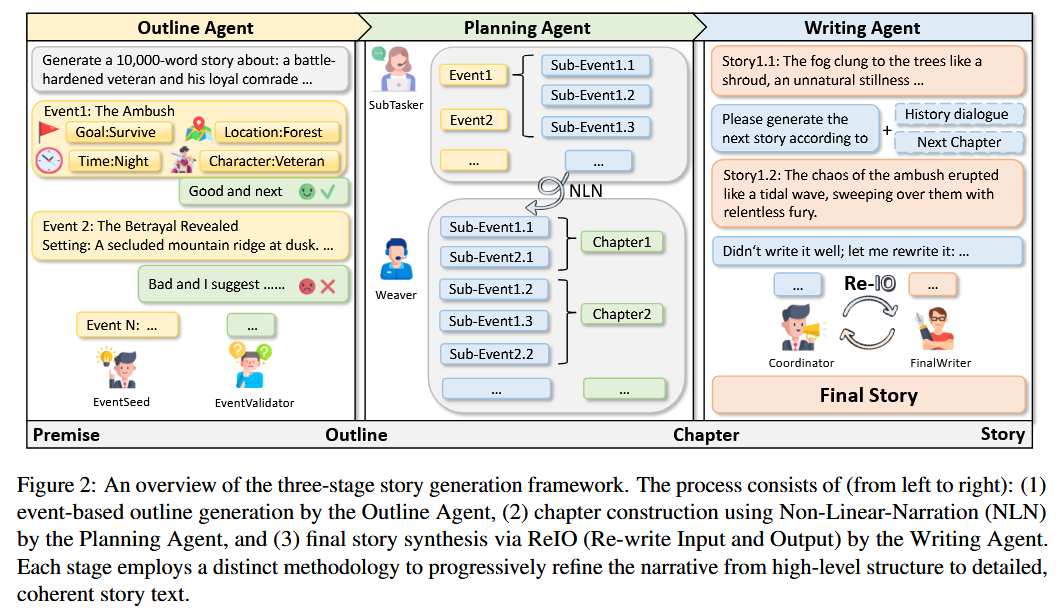
StoryWriter 框架在 Auto-Gen 框架下實現 ,其 Agent 網絡由以下三個主要模塊組成:
Outline Agent
- 該模塊負責生成基于事件的大綱,其中包含豐富的事件情節、人物和事件-事件關系 。
- 它由兩個專門的Agent構成:
EventSeed和EventValidator EventSeed負責根據給定的前提(premise)順序生成事件,為每個事件提供時間、地點和關系等基本信息 。EventValidator持續監控和評估生成的大綱,提供反饋以確保每個事件的合理性和敘事連貫性 。- 與傳統的大綱生成方法不同,該方法將大綱構建為一系列事件元組,從而增強了可控性和邏輯一致性 。
Planning Agent
- 該模塊進一步細化事件,并全局規劃每個章節應包含哪些事件,以保持故事的交織性和吸引力 。
- 它引入了“非線性敘事”(Non-Linear Narration, NLN)策略,將事件分解為子事件,并有策略地將它們分布在不同的章節中 。
- 該模塊由
SubTasker和Weaver組成 。 SubTasker負責將高級別事件分解為更細粒度的敘事單元,即子事件 。Weaver則將這些子事件分配到不同的章節中,即使它們以非時間順序呈現,也能保持整體敘事結構的連貫性 。- 這種方法克服了線性敘事的單調性,增強了敘事的多樣性和讀者的參與度 。
Writing Agent
- 該模塊根據歷史上下文生成和完善具體的故事內容 。
- 它采用了一個名為“重寫輸入和輸出”(Re-write Input and Output, ReIO)的機制,由
Coordinator和FinalWriter兩個Agent協作完成 。 - 在輸入處理階段,
Coordinator動態地壓縮歷史敘事上下文,只保留與當前子事件相關的信息,從而有效減少輸入長度并保持關鍵上下文 。 - 在輸出處理階段,
Coordinator會評估生成的文本,并在必要時對其進行重寫,以確保其與預定敘事結構和風格要求的一致性 。 - 這種分工確保了宏觀結構連貫性和微觀敘事流暢性 。
實驗部分
實驗設置
- 數據集: 評估采用 MoPS 數據集 。
- 評估方法: 采用人工評估和基于GPT-4o的自動評估,涵蓋六個維度:相關性(Relevance)、連貫性(Coherence)、同理心(Empathy)、意外性(Surprise)、創造性(Creativity)和復雜性(Complexity)。
- 基線模型: DOC、Agents’ Room 和 GPT-4o-mini 。
實驗結果
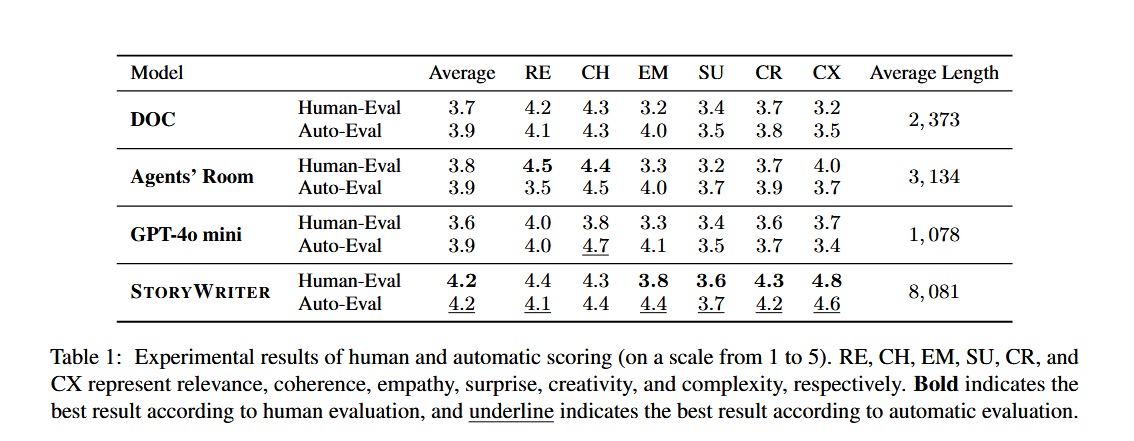
主要實驗
StoryWriter 在人工和自動評估中均顯著優于所有基線模型 。它在保持高質量的同時,顯著超越了以往基線模型的生成長度 。在內容多樣性和創造性方面 StoryWriter 表現突出 。
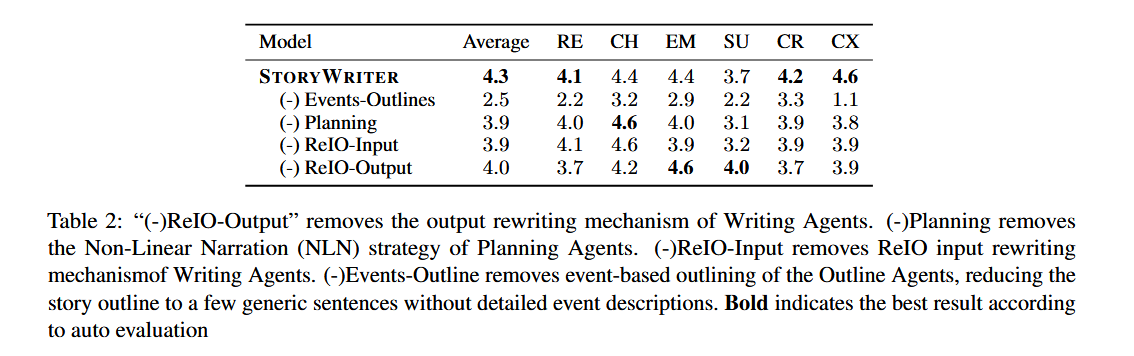
消融實驗
- 移除大綱Agent: 故事大綱缺乏深度和結構,導致所有評估指標顯著下降 。
- 移除規劃Agent: 子事件嚴格按時間順序排列,導致復雜性得分顯著降低 。
- 移除ReIO-Input: 輸入文本長度大幅增加,導致計算成本上升和整體性能下降 。
- 移除ReIO-Output: 生成文本的相關性得分顯著下降,因為該模塊對于維持結構連貫性至關重要。
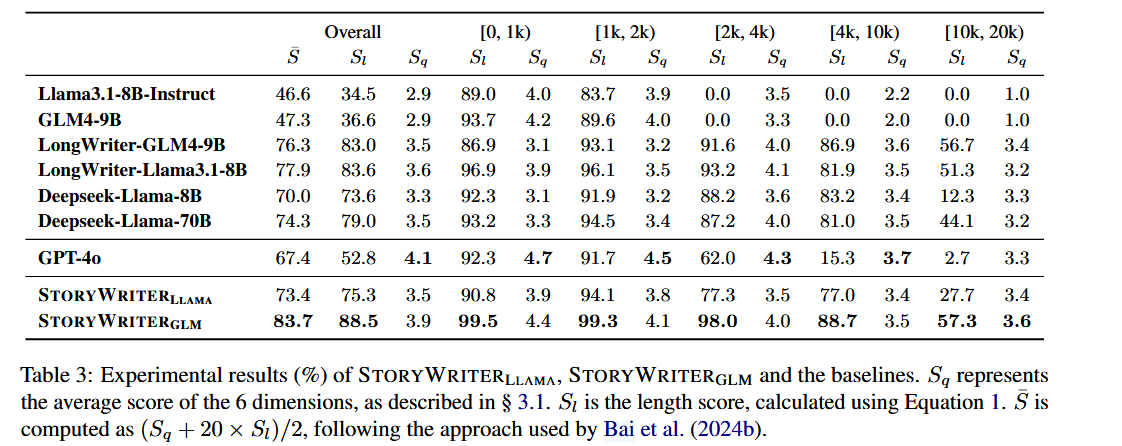
LONGSTORY 數據集與模型訓練
- 數據集構建: LONGSTORY 數據集是使用 StoryWriter 框架,從 MoPS 訓練集中收集的6000個故事前提生成而成的 。經過數據清洗,最終包含5500個平均長度約8000字的高質量長篇故事 。
- 模型微調: 使用 LONGSTORY 數據集,通過監督微調(SFT)訓練了基于 Llama3.1-8B 和 GLM-4-9B 的模型 。
- 評估指標: 采用 LongBench-Write 評估方法,包括內容質量分數 SqS_qSq?、SlS_lSl?,和綜合分數 Sˉ\bar{S}Sˉ。
- 結果:
- StoryWriter-GLM 在故事質量 SqS_qSq? 上顯著優于其基礎模型,尤其是在生成超過 4000 字的故事時。
- StoryWriter-Llama 和 StoryWriter-GLM 在長度分數 SlS_lSl? 也遠優于 Llama3.1-8B-Instruct 和 GPT-4o,這表明即使訓練中沒有明確的長度約束增強,訓練長文本也能提高模型遵循長度約束的能力 。
總結
- 研究只考慮了英文,并不支持多語言生成
- 只關注了小說故事生成,并未考慮其他藝術風格
- 該文章中的復雜敘事結構,其實就是把 生成的 Outline 在擴寫后,交給 LLM 重構了 Outline 的順序,這樣不能解決實際問題,只是表面上的工作,該處可以參考 Multi-Agent Based Character Simulation for Story Writing 中對于復雜敘事結構的描述,或許有參考價值。
- 生成長度為 4000 字,并不能很好的解決小說的故事生成,還是個 toy。
)


詳解)






:RKNN-ToolKit2性能和內存評估)








詳解)