目錄
YOLOv8的網絡結構圖:
Backbone
卷積塊(Conv Block)
Conv2d層
BatchNorm2d層
SiLU激活函數
瓶頸塊(Bottleneck Block)
C2f 模塊結構
Neck
SPPF(空間金字塔池化快速)
PAN?- FPN
Head
結構1.卷積層和激活函數:
2.預測層(Prediction Layers):
3.非極大值抑制
其他優化
YOLOv5 與 YOLOv8 的主要區別:
?
YOLOv8的網絡結構圖:
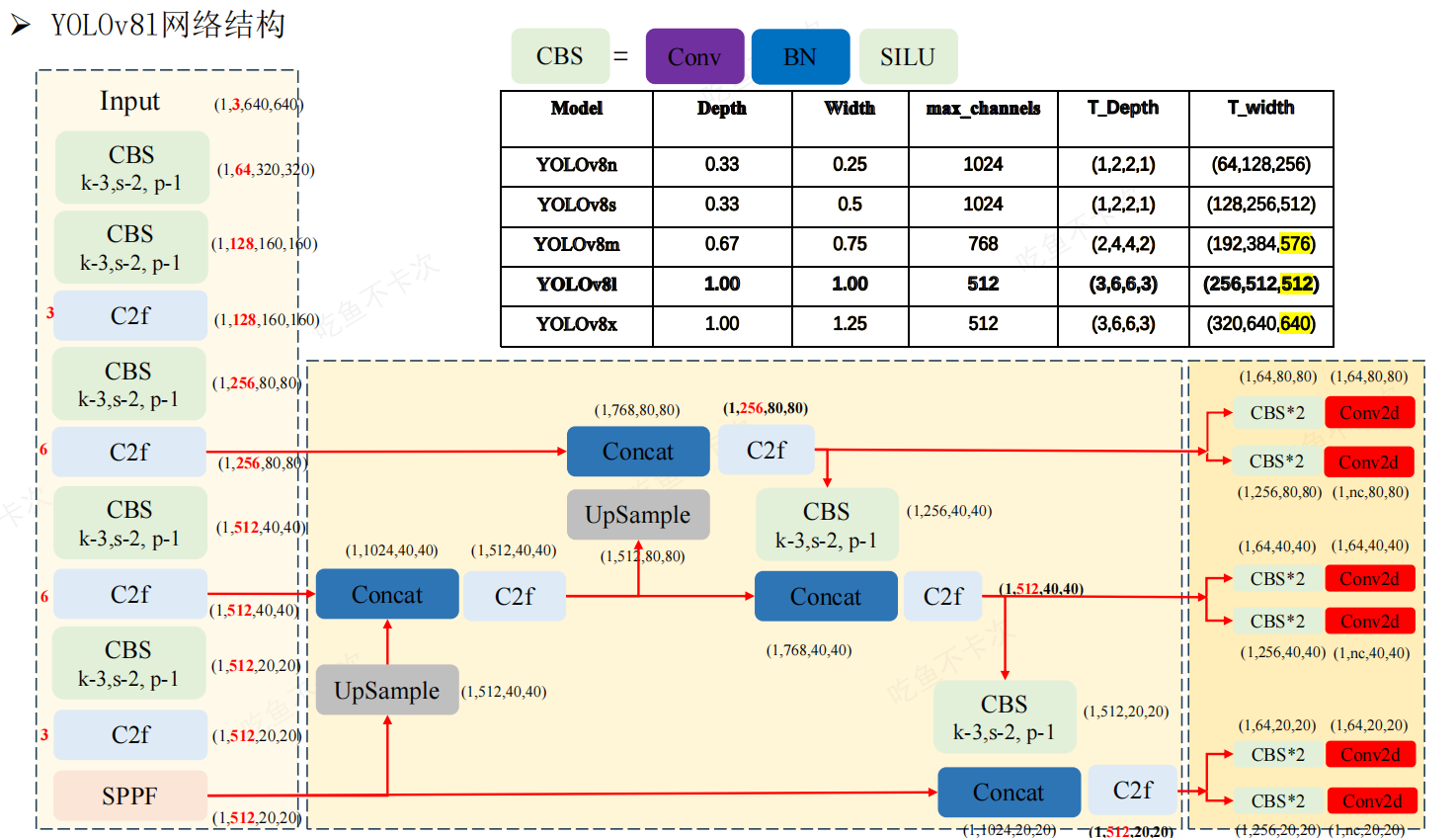
YOLOv8的網絡結構主要由以下三大部分組成 :
Backbone
Backbone部分負責特征提取,采用了一系列卷積和反卷積層,同時使用了殘差連接和瓶頸結構來減小網絡的大小并提高性能。該部分采用了C2f模塊作為基本構成單元,與YOLOv5的C3模塊相比,C2f模塊具有更少的參數量和更優秀的特征提取能力。具體來說,C2f模塊通過更有效的結構設計,減少了冗余參數,提高了計算效率。此外,Backbone部分還包括一些常見的改進技術,如深度可分離卷積(Depthwise Separable Convolution)和膨脹卷積(Dilated Convolution),以進一步增強特征提取的能力。
卷積塊(Conv Block)

Conv2d層
卷積是一種數學運算,涉及將一個小矩陣(稱為核或濾波器)滑動到輸入數據上,執行元素級的乘法,并將結果求和以生成特征圖。“2D”在Conv2d中表示卷積應用于兩個空間維度,通常是高度和寬度。
- k(kernel數量):濾波器或核的數量,代表輸出體積的深度,每個濾波器負責檢測輸入中的不同特征,
- s(stride步幅):步幅,指濾波器/核在輸入上滑動的步長。較大的步幅會減少輸出體積的空間維度。
- p(padding填充):填充,指在輸入的每一側添加的額外零邊框,有助于保持空間信息,并可用于控制輸出體積的空間維度。
- c(channels輸入通道數):輸入的通道數。例如,對于RGB圖像,c為3(每個顏色:紅色、綠色和藍色各一個通道)。
BatchNorm2d層
批歸一化(BatchNorm2d)是一種在深度神經網絡中使用的技術,用于提高訓練穩定性和收斂速度。在卷積神經網絡(CNN)中BatchNorm2d層特定地對2D輸入進行批歸一化,通常是卷積層的輸出。它通過在每個小批次的數據中標準化特征,使每個特征在小批次中的均值接近0、方差接近1,確保通過網絡的數據不會太大或太小,這有助于防止訓練過程中出現的問題。
SiLU激活函數
SiLU(Sigmoid Linear Unit)激活函數,也稱為Swish激活函數,是神經網絡中使用的激活函數。SiLU激活函數定義如下:
其中,σ(x)是Sigmoid函數,定義為:
SiLU的關鍵特性是它允許平滑的梯度,這在神經網絡訓練過程中是有益的。平滑的梯度可以幫助避免如梯度消失等問題,這些問題會阻礙深度神經網絡的學習過程.
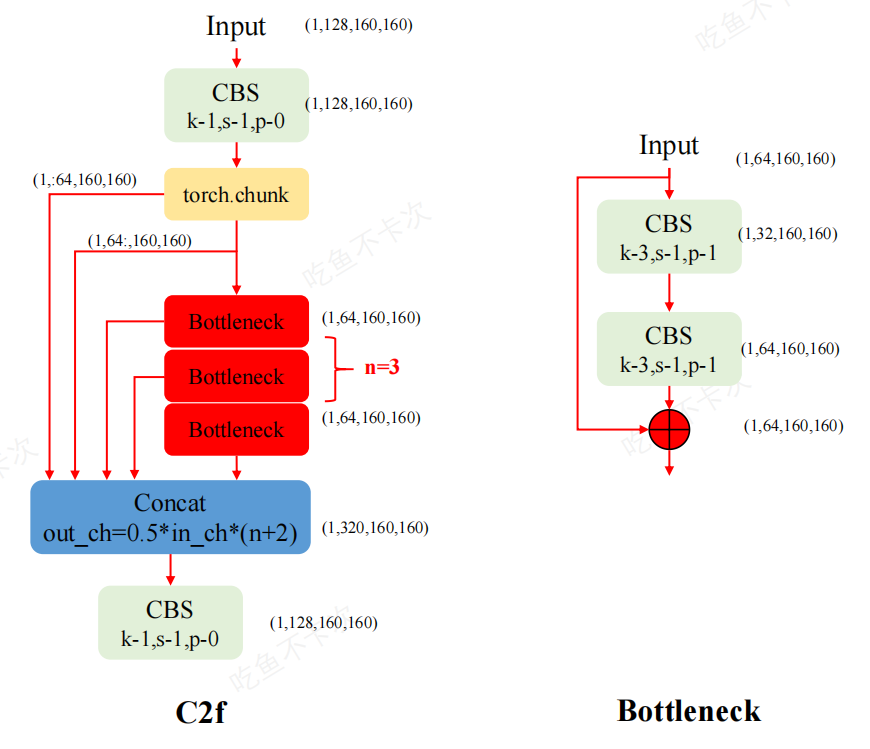
瓶頸塊(Bottleneck Block)
YOLOv8瓶頸塊結構說明
- 卷積層1(Conv 1):首先輸入通過一個卷積層,通常卷積核大小為(1 x 1),用于減少特征圖的通道數。
- 卷積層2(Conv 2):緊接著輸入通過一個卷積層,通常卷積核大小為(3 x 3),用于提取特征并增加感受野。
- 跳躍連接 (Skip Connection):在卷積層之間加入跳躍連接,將輸入直接連接到輸出。這種連接方式可以緩解梯度消失問題,幫助網絡更好地學習。
- 拼接(Concatenate):最后,將跳躍連接后的輸出與卷積層的輸出進行拼接,形成最終輸出。
功能和優勢
- 減少參數和計算量:通過(1 x 1)卷積層減少特征圖的通道數,降低計算復雜度。
- 增加網絡深度和非線性能力:通過增加(3 x3)卷積層,提取更多特征,提高模型表達能力。
- 跳躍連接:緩解梯度消失問題,幫助訓練更深的網絡。
C2f 模塊結構
- C2f塊: 首先由一個卷積塊(Conv)組成,該卷積塊接收輸入特征圖并生成中間特征圖。
- 特征圖拆分: 生成的中間特征圖被拆分成兩部分,一部分直接傳遞到最終的Concat塊,另一部分傳遞到多個Bottieneck塊進行進一步處理。
- Bottleneck塊: 輸入到這些Botleneck塊的特征圖通過一系列的卷積、歸一化和激活操作進行處理,最后生成的特征圖會與直接傳遞的那部分特征圖在Concat塊進行拼接(Concat)。通過多個Bottleneck塊進一步提煉和增強特征,這些Bottle neck塊可以捕捉更復雜的模式和細節。
- 模型深度控制: 在C2f模塊中,Botleneck模塊的數量由模型的depth_muliple參數定義,這意味著可以根據需求靈活調整模塊的深度和計算復雜度,
- 最終卷積塊:拼接后的特征圖會輸入到一個最終的卷積塊進行進一步處理,生成最終的輸出特征圖.通過Concat塊將直接傳遞的特征圖和處理后的特征圖進行融合,使得模型可以綜合利用多尺度、多層次的信息輸出生成最終特征圖.
Neck
Neck部分負責多尺度特征融合,通過將來自Backbone不同階段的特征圖進行融合,增強特征表示能力。具體來說,YOLOv8的Neck部分包括以下組件:
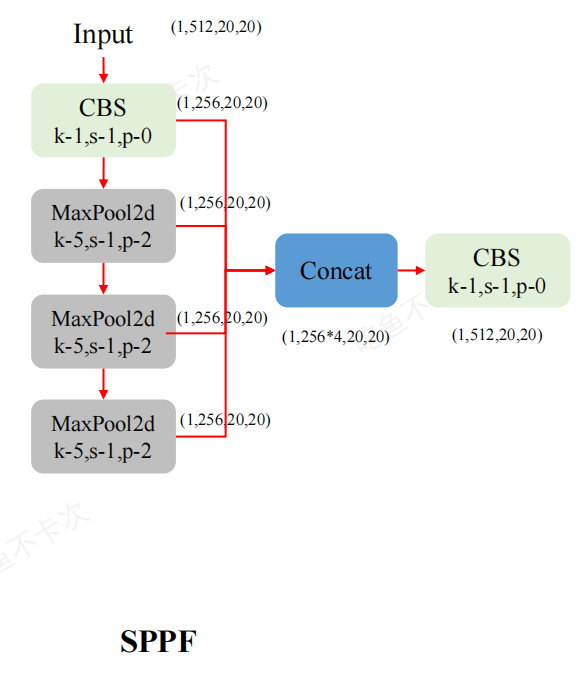
SPPF(空間金字塔池化快速)
SPPF模塊(Spatial Pyramid Pooling Fast):用于不同尺度的池化操作,將不同尺度的特征圖拼接在一起,提高對不同尺寸目標的檢測能力。
SPPF偽代碼:
import torch
import torch.nn as nnclass SPPFBlock(nn.Module):
? ? def __init__(self, in_channels, out_channels, pool_size=5):
? ? ? ? super(SPPFBlock, self).__init__()
? ? ? ? self.initial_conv = nn.Sequential(
? ? ? ? ? ? nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0),
? ? ? ? ? ? nn.BatchNorm2d(out_channels),
? ? ? ? ? ? nn.SiLU()
? ? ? ? )
? ? ? ??
? ? ? ? self.pool1 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2)
? ? ? ? self.pool2 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2)
? ? ? ? self.pool3 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2)
? ? ? ??
? ? ? ? self.final_conv = nn.Sequential(
? ? ? ? ? ? nn.Conv2d(out_channels * 4, out_channels, kernel_size=1, stride=1, padding=0),
? ? ? ? ? ? nn.BatchNorm2d(out_channels),
? ? ? ? ? ? nn.SiLU()
? ? ? ? )
? ??
? ? def forward(self, x):
? ? ? ? x_initial = self.initial_conv(x)
? ? ? ??
? ? ? ? x1 = self.pool1(x_initial)
? ? ? ? x2 = self.pool2(x1)
? ? ? ? x3 = self.pool3(x2)
? ? ? ??
? ? ? ? x_concat = torch.cat((x_initial, x1, x2, x3), dim=1)
? ? ? ??
? ? ? ? x_final = self.final_conv(x_concat)
? ? ? ??
? ? ? ? return x_final# 使用示例
sppf_block = SPPFBlock(in_channels=64, out_channels=128)
output = sppf_block(input_tensor)
PAA模塊(Probabilistic Anchor Assignment):用于智能地分配錨框,以優化正負樣本的選擇,提高模型的訓練效果。
PAN模塊(Path Aggregation Network):包括兩個PAN模塊,用于不同層次特征的路徑聚合,通過自底向上和自頂向下的路徑增強特征圖的表達能力。
PAN?- FPN
在 YOLOv8 中,PAN(特征金字塔) -FPN(路徑聚合網絡)的實現結合了 FPN 和 PAN 的優點,具體如下:
1.多尺度特征提取:
YOLOv8 的主干網絡首先提取出不同尺度的特征圖。通過 FPN 構建自頂向下的特征金字塔,實現多尺度特征的初步融合。
2.雙向特征融合:
?在 FPN 的基礎上,引入 PAN 的自底向上路徑,將低層特征逐層傳遞到高層,進一步豐富多尺度特征。通過橫向連接,將不同尺度的特征進行融合,確保每一層的特征都包含豐富的上下文信息。
3.增強的特征表示:
?PAN-FPN 通過雙向路徑的融合,使得特征圖包含更豐富的上下文信息和語義信息,增強了模型對不同尺度目標的檢測能力。
Head
Head部分負責最終的目標檢測和分類任務,包括一個檢測頭和一個分類頭:
結構1.卷積層和激活函數:
Head部分通常包括若干卷積層和激活函數。這些卷積層用于進一步處理Neck部分輸出的特征圖,以提取更多的高級特征。常見的激活函數包括ReLU或Leaky ReLU,能夠引入非線性,從而提升特征表達能力。
2.預測層(Prediction Layers):
在YOLOv8中,預測層是關鍵組件,負責生成最終的檢測結果。預測層包括三個主要輸出:
- 1.邊界框回歸(Bounding Box Regression):預測目標的位置和大小。通常輸出四個值,分別對應邊界框的中心坐標(x,y)和寬度、高度(w,h)。
- 2.置信度評分(Confidence Scores):預測每個邊界框內是否包含目標,以及目標的置信度。
- 3.類別概率(Class Probabilities):預測目標屬于每個類別的概率。
3.非極大值抑制
(Non-Maximum suppression, NMS)最終的預測結果會經過非極大值抑制處理,以去除重復的檢測框。NMS保留置信度最高的邊界框,并移除與之重罍度高的其他邊界框,確保每個目標只被檢測一次。
其他優化
除了上述結構外,YOLOv8還引入了一些新的優化技術,如:
Anchor-free機制:減少了錨框的超參數設置,通過直接預測目標的中心點來簡化訓練過程。
自適應NMS(Non-Maximum Suppression):改進了傳統的NMS算法,通過自適應調整閾值,減少誤檢和漏檢,提高檢測精度自動混合精度訓練(Automatic Mixed Precision Training):通過在訓練過程中動態調整計算精度,加快訓練速度,同時減少顯存占用。
YOLOv5 與 YOLOv8 的主要區別:
YOLOv5 與 YOLOv8 的主要區別-CSDN博客


)
















