網絡爬蟲技術全棧指南:從入門到AI時代的數據采集革命
關鍵詞:網絡爬蟲、Python爬蟲、數據采集、反爬技術、分布式爬蟲、AI爬蟲、Scrapy框架、自動化數據提取、爬蟲架構設計
摘要:本專欄是最全面的網絡爬蟲技術指南,涵蓋從基礎框架到AI驅動的智能爬蟲全棧技術。通過66篇深度文章,帶你掌握從傳統爬蟲到新一代AI爬蟲的完整技術棧,包括30篇基礎技術、10篇新一代框架、10篇高級反爬技術、10篇現代化架構設計,以及6篇特殊場景應用。無論你是初學者還是資深開發者,都能在這里找到適合的學習內容和實戰案例。
文章目錄
- 網絡爬蟲技術全棧指南:從入門到AI時代的數據采集革命
- 🚀 為什么這個專欄值得你訂閱?
- 數據時代的機遇與挑戰
- 這個專欄的獨特價值
- 📊 專欄技術棧全景圖
- 🎯 專欄內容體系
- 第一部分:爬蟲基礎技術棧(30篇)
- 核心庫與框架
- 數據存儲與處理
- 第二部分:新一代AI驅動爬蟲(10篇)
- AI智能框架
- 現代化工具
- 第三部分:高級反爬與繞過技術(10篇)
- 指紋偽造技術
- 智能檢測繞過
- 第四部分:現代化爬蟲架構(10篇)
- 分布式集群
- 第五部分:特殊場景爬蟲技術(6篇)
- 特殊場景應用
- 🎯 學習路線推薦
- 🌟 初級開發者(0-6個月經驗)
- 🔥 中級開發者(6個月-2年經驗)
- 🚀 高級開發者(2年+經驗)
- 💡 核心技術預覽
- 傳統爬蟲 vs AI爬蟲
- 傳統爬蟲方式
- AI驅動爬蟲方式
- 現代反爬技術示例
- TLS指紋偽造
- 設備指紋全方位偽造
- 🔍 專欄特色技術深度解析
- 1. 費曼學習法應用
- 2. 完整的代碼示例
- 3. 前沿技術追蹤
- 📈 學習收益預期
- 技術能力提升
- 職業發展助力
- 實際項目應用
- 🎁 專欄福利
- 完整源碼倉庫
- 技術交流社群
- 持續更新保障
- 🚀 立即開始你的爬蟲技術進階之旅
- 專欄訂閱說明
- 試讀文章推薦
🚀 為什么這個專欄值得你訂閱?
數據時代的機遇與挑戰
在這個信息爆炸的時代,數據就是新的石油。每天有數萬億字節的數據在互聯網上流轉,從電商網站的商品信息、社交媒體的用戶動態,到新聞網站的實時資訊。如何高效、智能地獲取這些數據,已經成為每個開發者、數據分析師,甚至企業決策者必須掌握的核心技能。
但是,網絡爬蟲技術正在經歷一場前所未有的變革:
- 傳統爬蟲面臨挑戰:反爬技術越來越復雜,TLS指紋、設備指紋、行為分析等新技術層出不窮
- AI技術帶來革命:大語言模型讓爬蟲具備了"理解"網頁內容的能力
- 架構要求更高:企業級應用需要分布式、高可用、可監控的爬蟲系統
這個專欄的獨特價值
🎯 技術全面性:涵蓋66個核心技術點,從基礎到前沿一網打盡
🔥 實戰導向:每篇文章都有完整的代碼示例和實際案例
💡 緊跟趨勢:深度解析AI驅動爬蟲、現代反爬技術等前沿方向
🏗? 架構思維:不僅教你寫爬蟲,更教你設計企業級爬蟲系統
📚 系統學習:遵循費曼學習法,復雜概念簡單化,易學易懂
📊 專欄技術棧全景圖
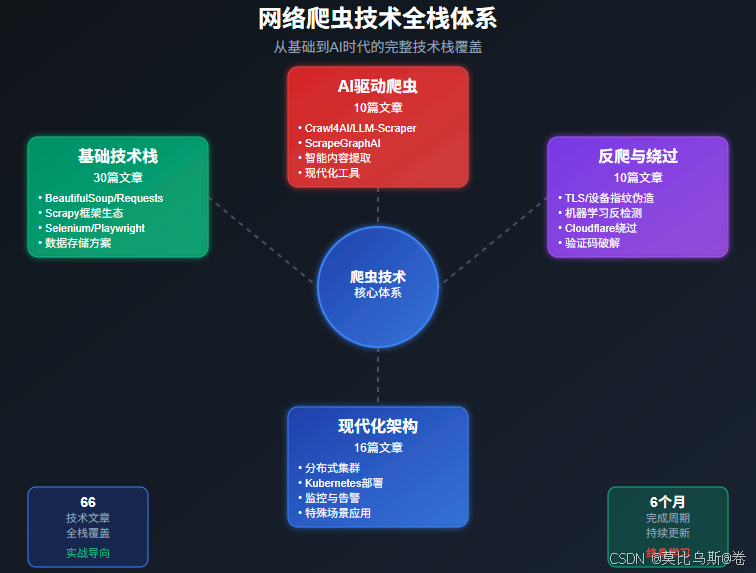
🎯 專欄內容體系
第一部分:爬蟲基礎技術棧(30篇)
從零基礎到熟練掌握傳統爬蟲技術,這是每個爬蟲開發者的必經之路。
核心庫與框架
- BeautifulSoup:HTML解析的瑞士軍刀
- Requests:HTTP請求處理的最佳實踐
- Scrapy系列:從單機到分布式的完整生態
- Selenium & Playwright:動態網頁的終極解決方案
數據存儲與處理
- MongoDB、Elasticsearch、Kafka:現代數據存儲方案
- 分布式架構設計:多機協同與任務分配
- 性能優化技巧:并發控制與資源管理
第二部分:新一代AI驅動爬蟲(10篇)
這是爬蟲技術的未來趨勢,也是本專欄的核心亮點。
AI智能框架
- Crawl4AI:讓AI理解網頁內容
- LLM-Scraper:大語言模型驅動的智能提取
- ScrapeGraphAI:基于圖神經網絡的網頁解析
現代化工具
- Trafilatura:高效網頁正文提取
- ScrapeFly:云端爬蟲服務
- Crawlee:TypeScript驅動的現代爬蟲
第三部分:高級反爬與繞過技術(10篇)
深入反爬與反反爬的技術對抗,掌握最前沿的繞過技術。
指紋偽造技術
- TLS指紋偽造:ja3、ja4指紋模擬
- 設備指紋全方位偽造:硬件特征、字體、插件模擬
- Canvas與WebGL指紋:瀏覽器特征偽造
智能檢測繞過
- 機器學習反爬檢測:行為模式識別與繞過
- 驗證碼進化史:從reCAPTCHA到GeeTest的破解
- Cloudflare繞過:5秒盾與Bot Fight Mode突破
第四部分:現代化爬蟲架構(10篇)
企業級爬蟲系統的設計與實現,讓你的爬蟲從玩具變成生產力工具。
分布式集群
- Scrapy-Cluster:大規模分布式爬蟲
- Kubernetes部署:云原生爬蟲管理
- 監控與告警:Prometheus + Sentry完整監控體系
第五部分:特殊場景爬蟲技術(6篇)
從移動端到區塊鏈的各種特殊場景爬蟲技術應用。
特殊場景應用
- 移動端App爬蟲:Android/iOS數據提取
- 小程序爬蟲:微信、支付寶生態數據采集
- 實時數據流:WebSocket、GraphQL、gRPC協議處理
- 區塊鏈數據:以太坊、比特幣鏈上數據采集
- 社交媒體API:Twitter、Instagram、TikTok數據獲取
- 電商平臺:亞馬遜、淘寶、京東商品信息采集
🎯 學習路線推薦
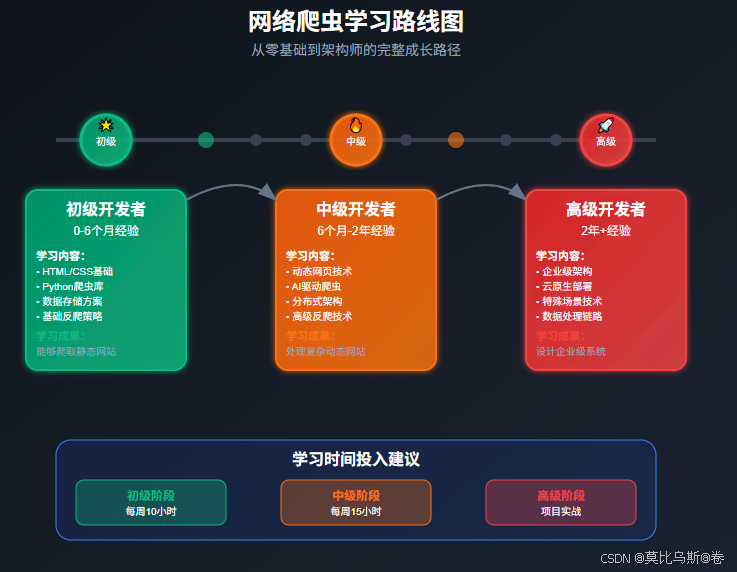
🌟 初級開發者(0-6個月經驗)
目標:掌握基礎爬蟲技術,能夠獨立完成簡單的數據采集任務
學習路徑:
- 基礎技術棧(第1-20篇):從BeautifulSoup到Scrapy基礎
- 數據存儲(第21-25篇):掌握常用數據存儲方案
- 簡單反爬(第26-30篇):應對基礎的反爬策略
學習成果:能夠爬取靜態網站、處理簡單的反爬機制、將數據存儲到數據庫
🔥 中級開發者(6個月-2年經驗)
目標:掌握動態網頁爬取和分布式技術,能夠設計中等復雜度的爬蟲系統
學習路徑:
- 基礎技術深化(第21-30篇):Selenium、Playwright深度應用
- AI驅動爬蟲(第31-40篇):體驗新一代爬蟲技術
- 高級反爬技術(第41-50篇):掌握現代反爬繞過技術
學習成果:能夠處理復雜的動態網站、使用AI技術提升爬蟲效率、突破大部分反爬機制
🚀 高級開發者(2年+經驗)
目標:設計企業級爬蟲系統,掌握前沿技術,具備架構思維
學習路徑:
- 現代化架構(第51-60篇):分布式集群、云原生部署
- 特殊場景技術(第61-66篇):移動端、區塊鏈、社交媒體爬蟲
學習成果:能夠設計和實現企業級爬蟲系統、掌握前沿技術、具備技術選型和架構設計能力
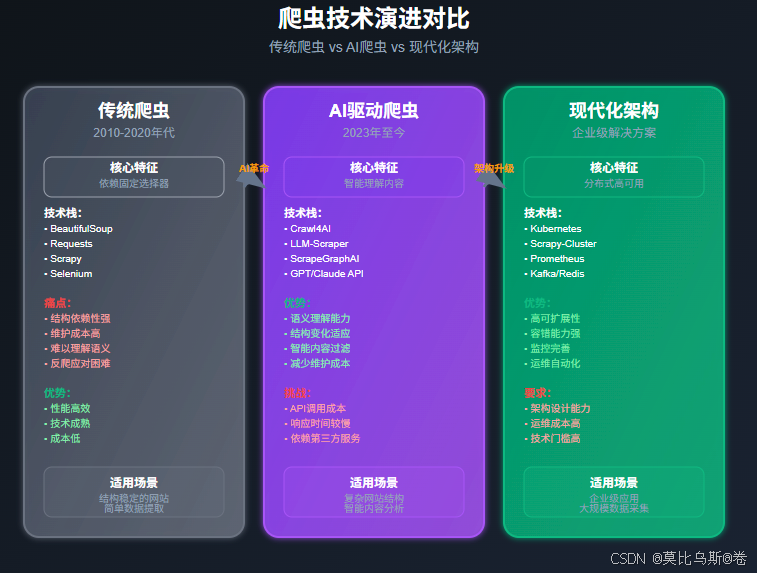
💡 核心技術預覽
傳統爬蟲 vs AI爬蟲
讓我們通過一個簡單的例子來看看傳統爬蟲和AI爬蟲的區別:
傳統爬蟲方式
import requests
from bs4 import BeautifulSoup# 傳統方式:依賴固定的CSS選擇器
url = "https://news.example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')# 如果網站結構改變,這些選擇器就失效了
titles = soup.select('.news-title')
contents = soup.select('.news-content')
AI驅動爬蟲方式
import asyncio
from crawl4ai import AsyncWebCrawlerasync def ai_crawl():async with AsyncWebCrawler() as crawler:# AI自動理解網頁內容,無需固定選擇器result = await crawler.arun(url="https://news.example.com",extraction_strategy=LLMExtractionStrategy(provider="ollama/llama2",instruction="提取所有新聞標題和內容"))return result.extracted_content
看到區別了嗎?AI爬蟲不再依賴脆弱的CSS選擇器,而是通過理解網頁內容來提取數據!
現代反爬技術示例
TLS指紋偽造
import tls_client# 模擬真實瀏覽器的TLS指紋
session = tls_client.Session(client_identifier="chrome_110",random_tls_extension_order=True
)# 現在你的請求看起來就像真實的Chrome瀏覽器
response = session.get("https://protected-site.com")
設備指紋全方位偽造
from undetected_chromedriver import Chrome
from fake_useragent import UserAgent# 創建難以檢測的瀏覽器實例
options = webdriver.ChromeOptions()
options.add_argument(f"--user-agent={UserAgent().random}")# 隨機化瀏覽器指紋
driver = Chrome(options=options)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined,})"""
})
🔍 專欄特色技術深度解析
1. 費曼學習法應用
每篇文章都采用費曼學習法,復雜概念簡單化:
- 從問題出發:為什么需要這個技術?
- 通俗解釋:用生活中的類比來解釋技術原理
- 實際案例:通過真實項目展示技術應用
- 深度思考:技術的局限性和發展方向
2. 完整的代碼示例
不是簡單的API介紹,而是完整的、可運行的項目代碼:
# 例如:企業級Scrapy分布式爬蟲架構
class DistributedSpider(Spider):name = 'enterprise_spider'def __init__(self):# Redis集群配置self.redis_client = RedisCluster.from_url("redis://cluster.example.com:7000")# 監控系統配置self.prometheus_client = CollectorRegistry()async def parse(self, response):# 智能數據提取extractor = AIContentExtractor(model="gpt-3.5-turbo",schema=ProductSchema)products = await extractor.extract(response.text)for product in products:yield {'name': product.name,'price': product.price,'timestamp': datetime.now(),'source': response.url}
3. 前沿技術追蹤
緊跟技術發展趨勢,涵蓋最新的爬蟲技術:
- AI驅動爬蟲:Crawl4AI、LLM-Scraper等新興框架
- 現代協議支持:HTTP/3、WebSocket、gRPC數據采集
- 云原生部署:Kubernetes、Docker容器化爬蟲
- 實時數據處理:Kafka、Redis Stream數據流處理
📈 學習收益預期
技術能力提升
- ? 掌握95%的爬蟲應用場景解決方案
- ? 具備企業級爬蟲系統設計能力
- ? 了解并應用最新的AI爬蟲技術
- ? 掌握復雜反爬機制的繞過方法
職業發展助力
- 📊 數據工程師:爬蟲是數據獲取的重要手段
- 🔍 爬蟲工程師:專業的爬蟲開發和維護工作
- 🤖 AI工程師:AI時代的數據采集和處理能力
- 💼 技術架構師:大規模數據采集系統的設計能力
實際項目應用
- 🛒 電商數據分析:商品價格監控、競品分析
- 📰 新聞資訊聚合:多源新聞采集和處理
- 💰 金融數據采集:股票、期貨、虛擬貨幣數據獲取
- 🏠 房產信息監控:樓盤信息、價格趨勢分析
🎁 專欄福利
完整源碼倉庫
- 📁 66個完整項目的源代碼
- 🔧 開箱即用的配置文件
- 📖 詳細的部署文檔
- 🐛 持續的Bug修復和功能更新
技術交流社群
- 💬 專屬技術交流群
- 🎯 定期技術分享會
- 🤝 一對一技術答疑
- 📚 獨家學習資料分享
持續更新保障
- 🔄 跟隨技術發展持續更新
- 📝 新技術第一時間補充
- 🎯 根據讀者反饋優化內容
- 📈 定期發布技術趨勢報告
🚀 立即開始你的爬蟲技術進階之旅
在這個數據驅動的時代,掌握高效的數據采集技術就是掌握了未來。無論你是想要:
- 📊 為數據分析獲取更多數據源
- 🔍 構建智能的信息收集系統
- 🤖 探索AI與爬蟲結合的新可能
- 💼 提升職場競爭力和技術深度
這個專欄都將是你最好的技術伙伴。
專欄訂閱說明
本專欄采用付費訂閱模式,確保內容質量和持續更新:
- 💎 專欄價格:一次付費,終身學習
- 📚 內容數量:66篇深度技術文章
- 🔄 更新頻率:每周2-3篇新文章
- 🎯 完成時間:預計6個月內完成全部內容
試讀文章推薦
為了讓你更好地了解專欄內容質量,建議你先閱讀以下免費試讀文章:
- 【網絡與爬蟲 01】BeautifulSoup從入門到精通**:了解傳統爬蟲基礎
- 【網絡與爬蟲 31】AI驅動的網頁內容提取革命**:體驗AI爬蟲的強大
準備好開啟你的爬蟲技術進階之旅了嗎?點擊訂閱,讓我們一起探索數據采集的無限可能! 🚀
💡 溫馨提示:如果你對專欄內容有任何疑問,歡迎通過評論區或私信聯系我。我會根據大家的反饋持續優化專欄內容,確保每一位讀者都能獲得最大的學習價值!
文章
![[Chat-LangChain] 前端用戶界面 | 核心交互組件 | 會話流管理](http://pic.xiahunao.cn/[Chat-LangChain] 前端用戶界面 | 核心交互組件 | 會話流管理)


















