引言
2025年8月,OpenAI正式發布了其新一代旗艦模型GPT-5。與業界此前期待的AGI(人工通用智能)突破不同,GPT-5更像是OpenAI對現有技術的一次深度整合與用戶體驗優化。本文將全面解析GPT-5的新特性、實際測試表現以及官方發布的基準數據,幫助開發者與普通用戶了解這一最新AI模型的真實能力與應用場景。
什么是GPT-5?
GPT-5是OpenAI推出的新一代旗艦模型,它完全取代了GPT-4時代的各種變體模型。與此前用戶需要在GPT-4o、GPT-4o-mini、o3等不同版本間手動選擇不同,GPT-5采用了智能路由機制,系統會根據任務類型自動決定使用快速響應還是深度推理模式。
模型的核心創新在于其統一架構設計:
- 自動路由:根據輸入提示實時決定響應策略
- 統一體驗:單一模型名稱,一致的行為表現
- 可選模式:仍保留GPT-5 Thinking(深度思考)和GPT-5 Pro(專業研究)等特殊模式
GPT-5的新功能
用戶體驗優化
-
界面個性化:
- 自定義聊天界面顏色主題
-
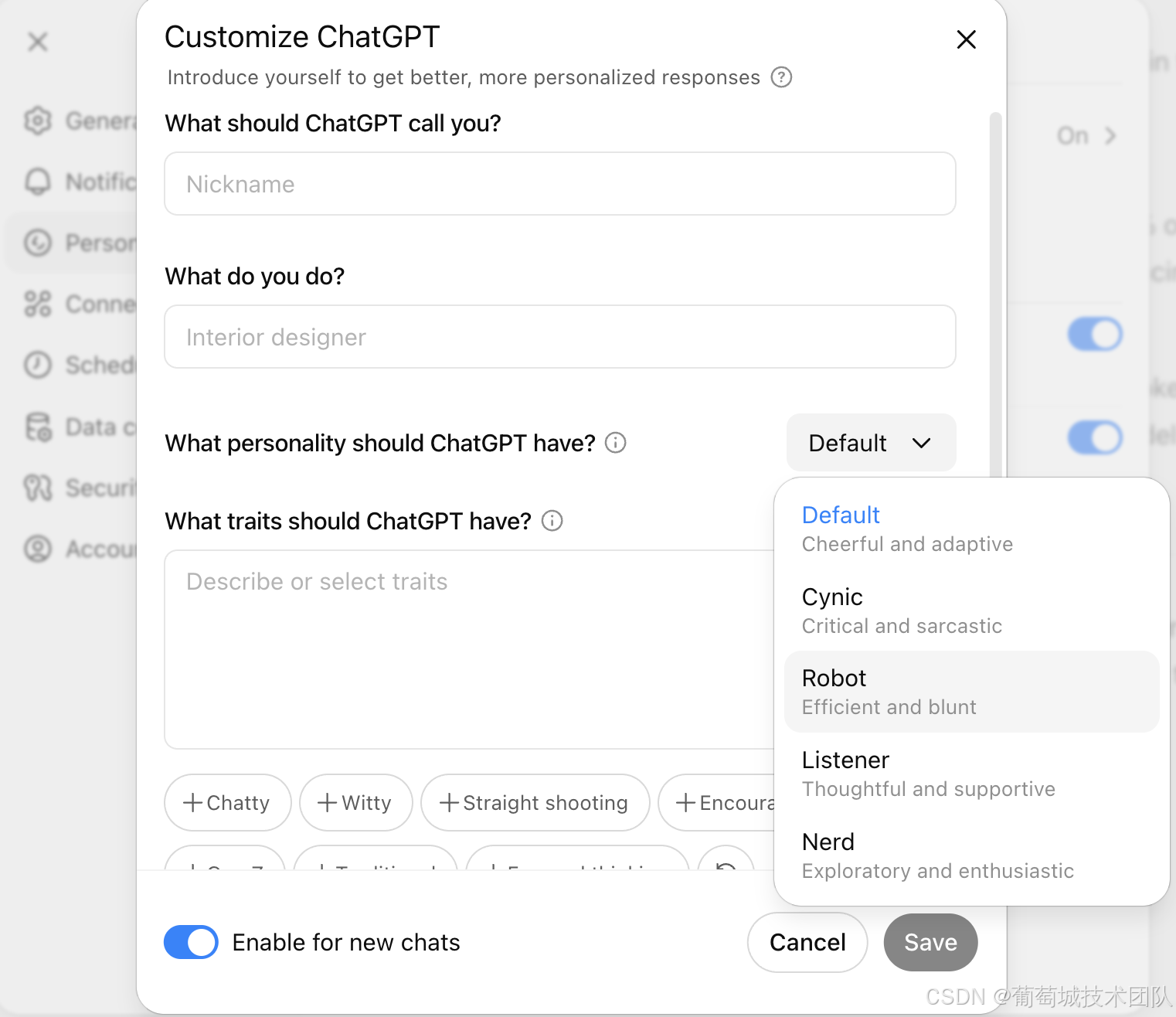
預設個性風格選擇(支持型、簡潔專業型、輕微諷刺型等)
-
個性風格在整個對話中保持穩定
-
生產力整合:
- Gmail和Google日歷深度集成(僅限付費用戶)
- 自動日程管理功能
- 郵件草擬與回復建議
-
安全改進:
- 采用"安全完成"機制替代簡單拒絕
- 提供最大限度的有用信息同時說明限制
- 減少阿諛奉承式的回答
開發者專項功能
# 示例:使用reasoning_effort參數控制推理深度
response = openai.ChatCompletion.create(model="gpt-5",messages=[{"role": "user", "content": "解釋量子糾纏現象"}],reasoning_effort="high", # 可選:minimal/medium/highverbosity="medium" # 控制回答長度
)
-
精細控制:
reasoning_effort參數控制推理深度verbosity參數調整回答長度
-
工具調用改進:
- 支持純文本工具調用(替代JSON)
- 自定義工具格式約束(正則/完整語法)
-
長時任務支持:
- 顯著提升多步驟代理任務能力
- 支持數十個工具調用的串聯/并行
詳細信息可以參考這篇文章:《ChatGpt 5系列文章1——編碼與智能體》
測試GPT-5的實際表現
數學能力測試
基礎算術:
- 9.11 - 9.9 = 0.21 (即時正確解答)
- 采用思維鏈推理(內部將9.9重寫為10-0.1)
復雜問題:
使用0-9所有數字各一次組成x+y=z的三個數字
- 30秒思考后給出兩個正確答案
- 內部使用"快速程序"解決排列問題
長上下文多模態測試
歐盟委員會AI報告分析(167頁):
- Pro賬戶(128K tokens)仍出現明顯問題
- 免費賬戶(8K tokens)完全無法處理
- 識別信息圖表任務表現不佳
測試結果表明,盡管GPT-5在官方基準測試中長上下文表現有所提升,但在實際復雜文檔處理中仍存在顯著局限。
GPT-5基準測試數據
編碼性能
| 測試項目 | GPT-5得分 | GPT-4.1得分 | 提升幅度 |
|---|---|---|---|
| SWE-bench Verified | 74.9% | 54.6% | +37% |
| Aider Polyglot | 88% | 81% | +8.6% |
效率提升:
- 高推理任務輸出token減少22%
- 工具調用減少45%
數學與科學推理
-
競賽數學:
- AIME 2025: 94.6%(無工具)
- HMMT: 93.3%(無工具)
-
前沿數學:
- FrontierMath: 26.3%(使用Python工具)
-
博士級科學:
- GPQA Diamond: 87.3%(有工具)
多模態推理
-
視覺推理:
- MMMU(大學級): 84.2%
- MMMU-Pro(研究生級): 78.4%
-
視頻理解:
- VideoMMMU(256幀): 84.6%
-
專業領域:
- CharXiv Reasoning: 81.1%
- ERQA空間推理: 65.7%
極限測試:Humanity’s Last Exam
這個包含2,500個博士級問題的測試集結果顯示:
- GPT-5無工具: 24.8%
- GPT-5 Pro: 42.0%
- Grok 4 Heavy: 50.7%
表明在多代理協作方面,xAI的Grok 4架構仍保持領先。










)








)