??
目錄
一、SpatialVLM
1、概述
2、方法
3、實驗
二、SpatialRGPT
1、概述
2、方法
3、訓練方法
4、實驗
一、SpatialVLM
1、概述
? ? ? ? SpatialVLM是最早的依賴傳統VLMs實現3D空間推理能力的論文,在24年1月由DeepMind團隊提出,當時對比的還是GPT4v,Gemini-pro,qwen-vl-plus這一組大模型,這些大模型在空間推理上能力較差,究其原因是數據集的問題,缺少含有空間數據的圖文對信息。
? ? ? ? 所以SpatialVLM設計了一個新的數據集,然后在VLM上訓練獲得了強大的空間推理能力。
? ? ? ? 從圖例來看,SpatialVLM也是首次實現在VLM模型上輸出準確的3D空間中具體數值信息的模型,其實這也歸根于數據集中的深度信息和點云信息。

2、方法
Spatial VQA Dataset
? ? ? ??數據集從互聯網圖像中保留場景級照片,并設定一個自動化過程,無需人工標注。
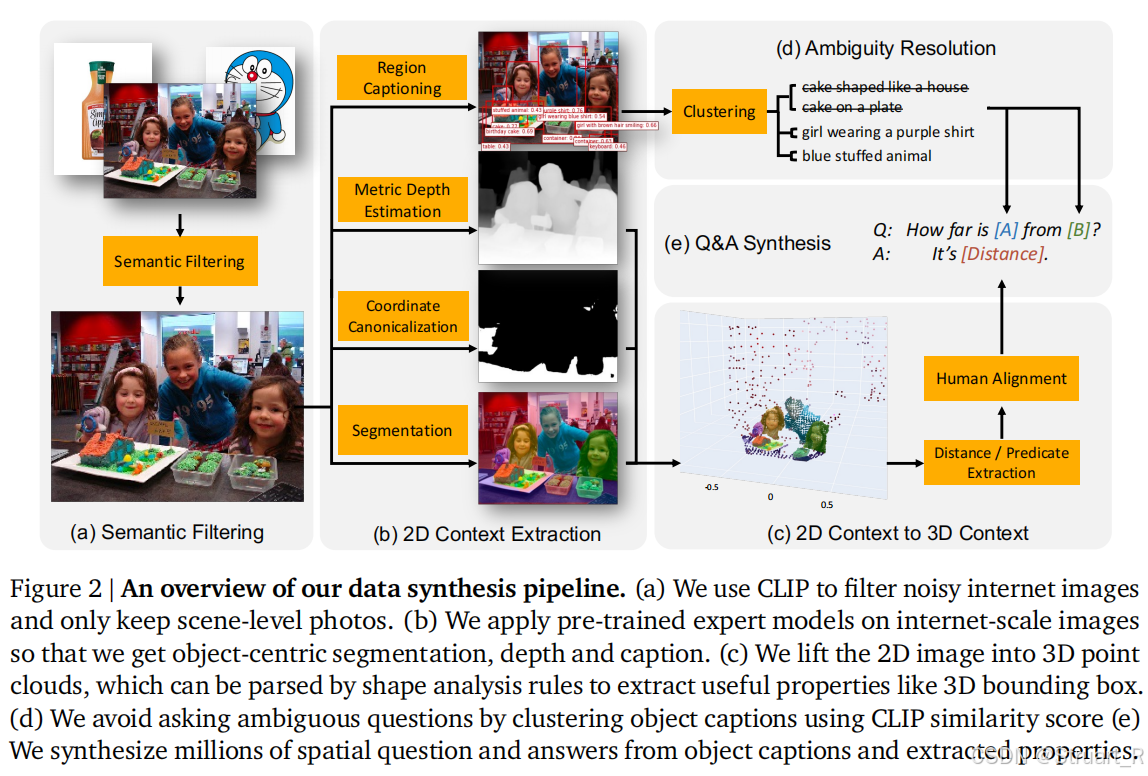
(1)語義過濾:利用CLIP模型對圖像分類,保留室內或室外場景照片,拒絕“單物體”“白色背景商品圖”“GUI”截圖等不適合空間推理的圖像
(2)物體中心信息提取:整合多個專家模型,用開放詞匯檢測模型定位物體邊界框,再用FlexCap生成該區域1-6詞的差異化描述,避免傳統檢測器粗粒度歧義(很妙啊),之后用ShapeMask模型分割物體像素簇,支持后續3D重建
(3)2D->3D轉換:采用ZoeDepth預測metric depth,利用內參轉換到3D點云,并檢測水平面信息,擬合平面方程,進而將點云轉換到世界坐標系。(在appendix中有完整的介紹)
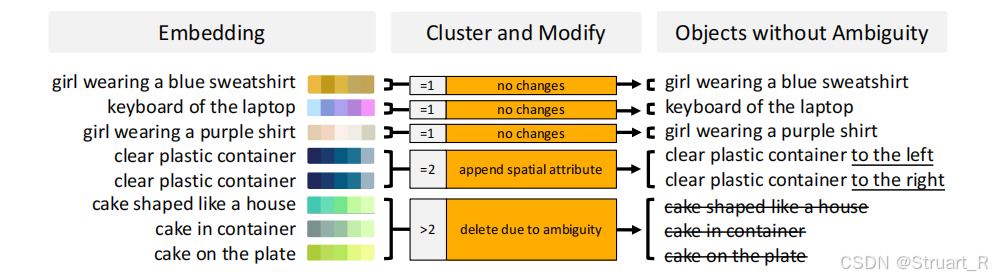
(4)歧義消除:比如同一個蛋糕,指代圖像中的若干個蛋糕,所以計算所有物體描述的CLIP,對物體名字相似的物體加以方位詞,分別這兩個物體,如果沒有解決,直接剔除該圖像。
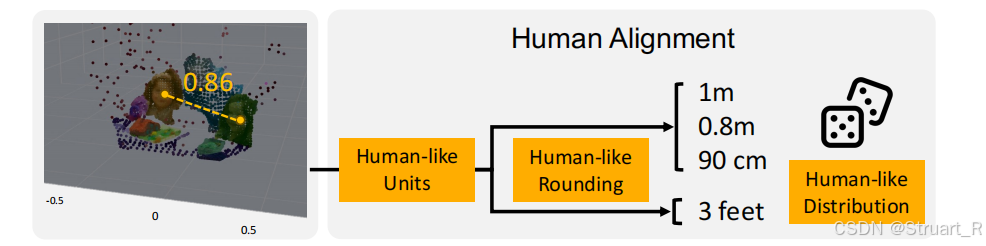
(5)QA模版生成:包括38類空間問題,定性問題和定量問題各占一半,每類問題含有20+問題模版和10+的答案模版,避免組合重復。對于答案生成,空間關系計算則基于物體3D bbox中心計算距離和方位,另外引入人類對齊處理,也就是準確數據如何轉換為人類的模糊語言,比如數值四舍五入(0.86m->約1m),概率化采樣單位(80%采用公制單位,20%采用英制)
????????Spatial VQA dataset如下:

架構設計
? ? ? ? 沿用PaLM-E(的更小體量PaLM 2-S)架構實現,數據集混合原有的PaLM數據集(95%)和該論文的Spatial VQA dataset(5%),訓練過程完全依賴PaLM的訓練方法,PaLM架構如下,這個PaLM模型是一個具身智能領域的多模態大語言模型,主要是通過給定假設,給定圖像條件,來實現規劃和推理。但是這個模型也是缺乏3D信息的,只是依賴具身智能相關和通用圖像信息來硬訓練的。

? ? ? ? 訓練過程解凍ViT微調,使得視覺編碼器學習幾何特征。
鏈式空間推理
? ? ? ? 將一個復雜的LLM問題拆解為若干個簡單的空間子問題,并利用SpatialVLM發起子問題查詢,最終利用LLM匯總子答案,合成結論。
? ? ? ? 比如下圖,詢問“三個可樂罐是否構成等腰三角形?(最長邊與最短邊差<0.1米)”
? ? ? ??鏈式推理利用SpatialVLM計算每一個邊的距離,最后利用LLM匯總,得到誤差內是一個等腰三角形。

VLA結合?
? ? ? ? 利用SpatialVLM生成獎勵信號,來指導機器人動作優化。
? ? ? ? 比如讓機器臂去抓一個橘色茶杯,那么手與橘色茶杯的距離將作為機械臂強化學習的獎勵,根據實時估計物體距離,生成單調遞增的獎勵曲線。? ?

3、實驗
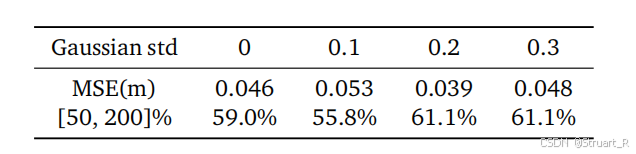
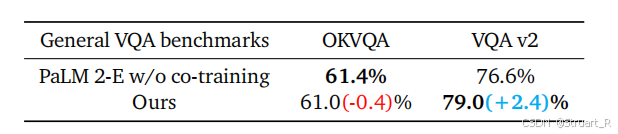
? ? ? ? 在數據集中其實引入了一部分的高斯噪聲,但是在實驗中發現,引入一部分高斯噪聲σ=0.2訓練,仍能保證模型訓練穩定,這也就證明了如果深度相機存在問題的情況下,仍然可以保證一定的準確性。下表為高斯噪聲在σ=0.2下魯棒性最高。答案在真實值的50%-200%范圍內更高。
? ? ? ? 當然當時沒有那么多的評測benchmark,只能在正確性和穩定性上進行判斷。這里評測的是對于時序問題的情況:

? ? ? ? 二元謂詞情況,可以理解為傳統問題

? ? ? ? 相比于backbone(PaLM)的對比,OKVQA和VQAv2都是通用知識的問題,OK-VQA更加依賴非視覺的外部知識,純推理題,所以有所降低,但是對于VQAv2這種依賴視覺的推理知識可以提升一點。
二、SpatialRGPT
1、概述
? ? ? ? SptialRGPT同樣是24年的論文(NVIDIA),基于SpatialVLM的問題進一步優化。
? ? ? ? 動機:同樣是VLMs在空間推理任務上深度信息缺失的問題,但是擴展到區域級場景,整體上學習了SpatialVLM的很多操作,比如數據合成,空間推理時的物體歧義,鏈式推理,人類標注基準等,但SpatialRGPT相比于SpatialVLM提出了一個新的區域級評估,SpatialRGPT-Bench,覆蓋更廣的環境(包括室內,室外,模擬環境),另外SpatialVLM只是利用深度信息點云信息來構建問答數據集中的文本信息,SpatialRGPT則將深度估計器直接作為一個插件,并列于圖像提取器,用于提取不同的數據信息,保證數據與文本之間的高度統一。

2、方法
SpatialRGPT數據集
? ? ? ? Open Spatial Dataset數據集分為兩步,將單圖生成三維場景圖,再通過LLM生成復雜的VQA對。
? ? ? ??對于數據集的圖像來源主要為OpenImages數據集(1.7M圖像)。
(1)圖像過濾:通過CLIP-based開放詞匯分類模型(這里用的EVA-CLIP)進行圖像分類,方法與Spatial-VLM相同,并且定義正面標簽和負面標簽,過濾掉負面的標簽信息(700K)。正例更專注于自然場景。

(2)開放詞匯檢測與分割:優化了SpatialVLM中的專家模型,這里先利用圖像標注模型Recognize Anything識別所有對象類標簽,確保泛化性,之后采用GroundingDino來實現開放詞匯下檢測,獲取對象邊界框,采用SAM-HQ模型細化邊界框為高精度掩碼,確保對象輪廓準確。
? ? ? ? 這一套流程可以理解為,圖像標注模型獲得整張圖片中有哪些物品,開放詞匯下檢測獲取每一個物體的檢測框,SAM則根據這個檢測框和文字信息,獲得他的準確物體掩碼。
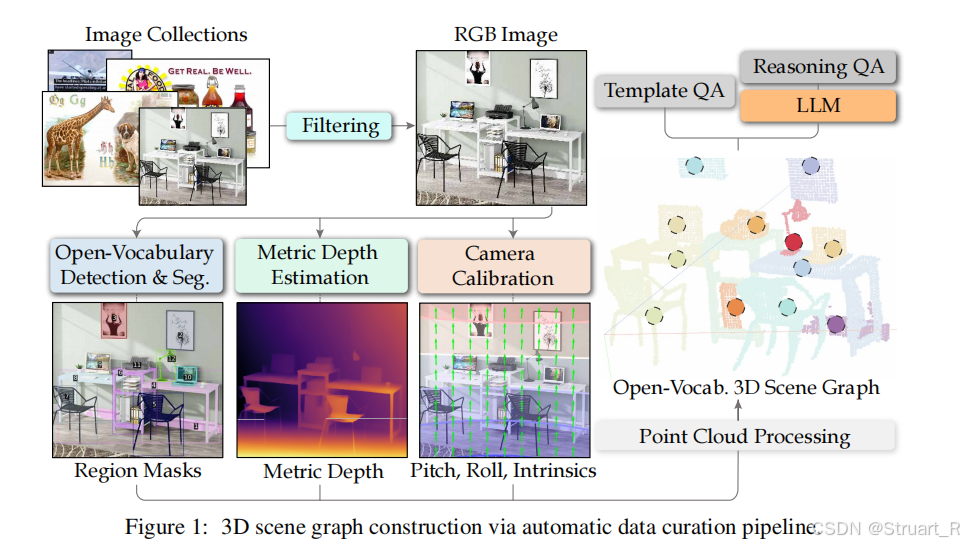
(3)度量深度估計:從單張圖像中預測深度圖,使用Metric3Dv2模型預測深度和表面法線,之后將深度圖投影到3D點云,感覺以往的單圖估計方法應該不太準確。
(4)相機校準:使用WidCamera模型預測4自由度內參,并利用PerspectiveFields獲取每個像素上的向量和緯度值,轉換為相機外參,通過旋轉矩陣將點云從相機坐標系轉換到世界坐標系。這種方法也是后來很常用的方法,沒有采用SpatialVLM中依賴地面分割,得到地面坐標系的方法,因為這種方法可能因為地面沒有正確分割而失敗。
(5)構建3D場景圖:3D場景圖類似于一個集合,比如Graph=(Nodes,Edges),其中節點表示物體實例(如椅子,蘋果),邊表示物體間空間關系(如椅子在蘋果左側)。
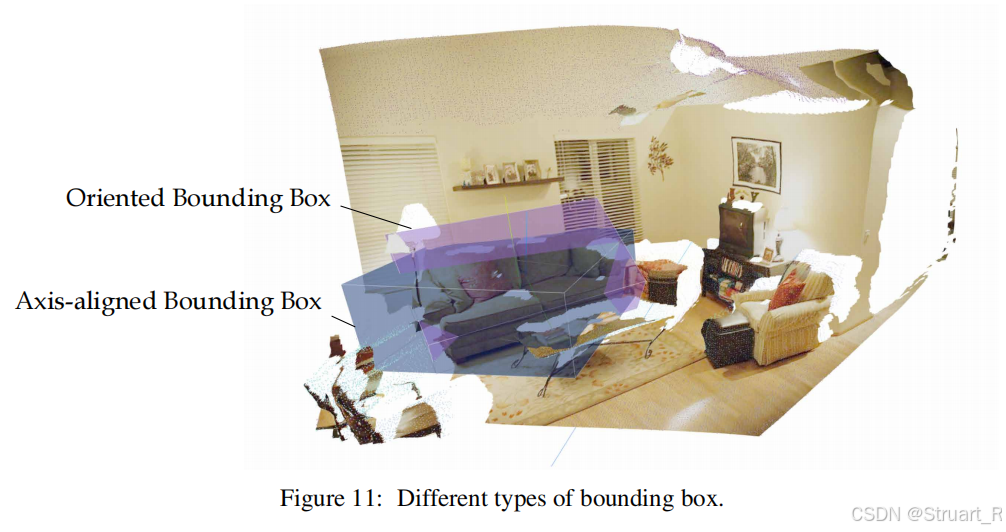
? ? ? ? 首先在原有的世界坐標系下的場景點云圖中,通過移除離群點,體素下采樣,DBSCAN剔除噪聲,并通過兩個視角下的點云信息,使用軸對齊邊界框(AABB)擬合可以獲得空間關系,并且提到方向包圍盒OBB雖然更準確,但是缺乏物體姿態估計。
? ? ? ? 對于每個位置的空間關系,定義相對關系和度量關系兩種,最終輸出場景圖。比如下面這種:
{"nodes": [{"id": 0, "label": "apple", "width": 0.2, "height": 0.3},{"id": 1, "label": "table", "width": 1.5, "height": 0.8}],"edges": [{"source": 0, "target": 1, "relation": "on_top", "distance": 0.4},{"source": 0, "target": 1, "relation": "left", "horizontal_dist": 0.3}]
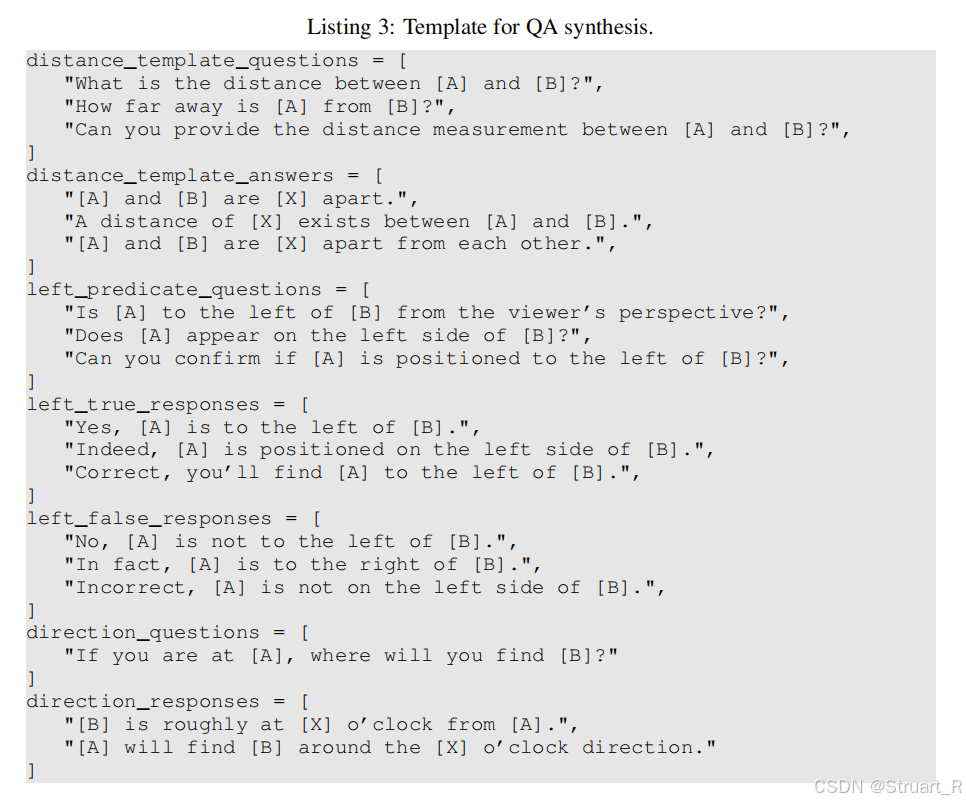
}(6)生成模版基礎VQA對:提取場景圖節點的信息,使用預定義的模版生成問題,比如下圖的模板對。
(7)依賴LLM生成復雜的VQA對:依賴于Llama3-70B結合(6)中的基礎VQA對,生成更加依賴語言的描述,創建推理性問題。
(8)整合數據集:最終數據集包含8M的模版基礎QA和0.7M的LLM-based QA,并利用人類驗證過濾錯誤標注。
? ? ? ? Open Spatial Dataset數據集如下:

SpatialRGPT模型架構
? ? ? ? SpatialRGPT依賴LLaMA2-7B大語言模型主干,輸入部分采用雙分支提取器,一個視覺編碼器,一個區域特征提取器以及RGB和Depth連接器用于與大語言模型對齊。
? ? ? ? 視覺編碼器采用凍結的CLIP-ViT-L/14提取全局特征信息,分辨率為336x336。
? ? ? ? 深度編碼器權重采用RGB編碼器初始化,同樣采用CLIP-ViT-L/14提取特征,在Visual Backbone中關閉,不作為LLM的輸入,只輸入視覺編碼器的輸出CLIP特征。
? ? ? ? 區域特征提取器依賴用戶給定的框或掩碼,作為定向區域的條件,用于提取局部CLIP特征,具體來說,依賴圖像和深度的CLIP特征作為輸入,經過兩層反卷積上采樣特征圖,在掩碼區域執行MaskPooling,邊界框區域計算RoIAlign,從而生成區域RGB嵌入和區域深度嵌入。
? ? ? ? Connector層通過獨立的線性層來對齊CLIP特征與LLM嵌入語言空間。
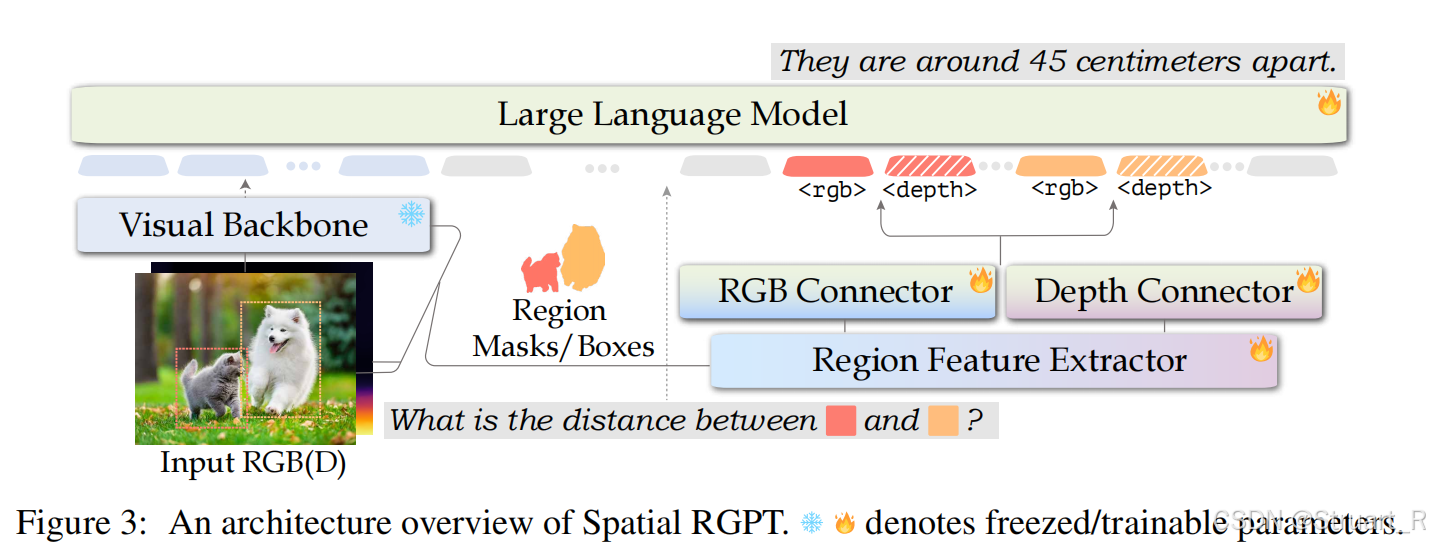
3、訓練方法
? ? ? ? 采用三階段訓練,完全凍結CLIP主干,減少訓練成本。
? ? ? ? 先單獨利用CC3M圖像-文本對訓練RGB Connector對齊。
? ? ? ? 在用MMC4+COYO通用VLM數據,進行視覺語言預訓練,訓練多模態信息,此時訓練LLM+Region Feature Extractor。
? ? ? ? 最后引入OSD數據和區域指令數據,和通用VQA數據,強化空間推理能力,訓練深度Connector和Region Feature Extractor。
4、實驗
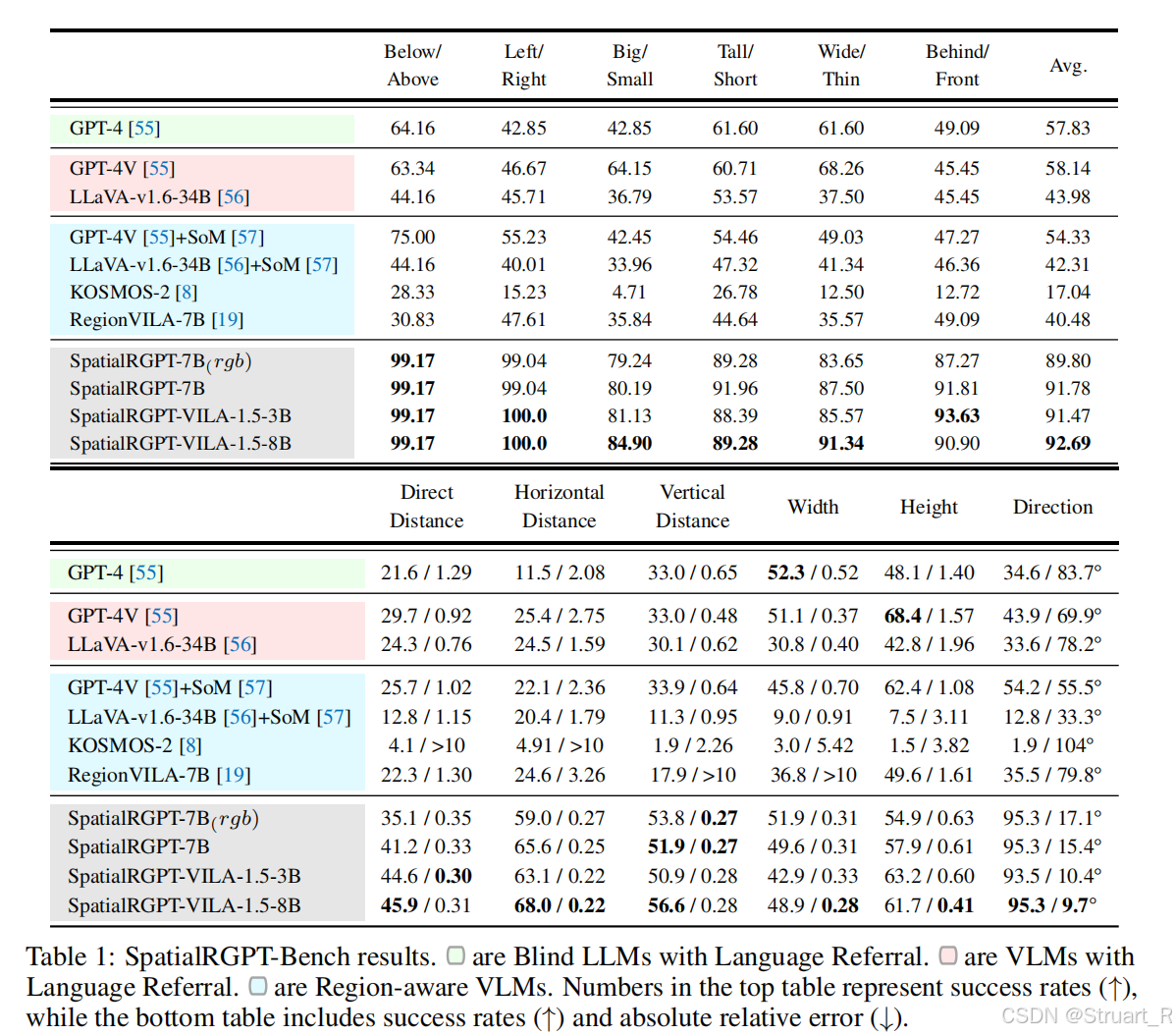
Spatial-RGPT Bench
? ? ? ??SpatialRGPT-Bench是論文中提出的??首個專為評估視覺語言模型(VLM)3D空間認知能力設計的基準??。
? ? ? ? 解決現有VLM在3D空間理解(如方向、距離、尺寸)上存在顯著缺陷,如SpatialVLM模型依賴2D人工標注產生透視歧義,并且缺乏更多場景的需求。
? ? ? ? 數據來源:包括室內場景SUNRGBD,ARKitScenes,室外場景nuScenes,KITTI,模擬場景Hypersim。
? ? ? ? 數據標注:來自基于Omni3D預處理的3D立方體標注,并帶有語義類別標簽,所有物體在同一個相機坐標系下。
? ? ? ? 問題設計:包括定性問題(方向關系,尺寸關系)與定量問題(距離,尺寸,方向)
? ? ? ? 指標設計:定性問題--準確率,定量問題--成功率(誤差±25%),相對誤差,方向誤差。并利用GPT-4作為裁判,判斷定性問題中是否滿足真值,定量問題上單位的標準性和誤差計算。
? ? ? ? 基線模型:實驗中對比了三類基線包括盲測LLM(如GPT-4,僅文本輸入),普通VLM(如GPT-4V,LLaVA-1.6),區域感知VLM(如KOSMOS-2框輸入,RegionVILA掩碼輸入,GPT-4V+SoM交互標注,這一類都具有支持區域提示輸入的特性)
? ? ? ? 在eval中,定性實驗中方向判斷近乎完美,并且整體上顯著超越基線。定量實驗中由于深度信息的引入,顯著提升度量精度。
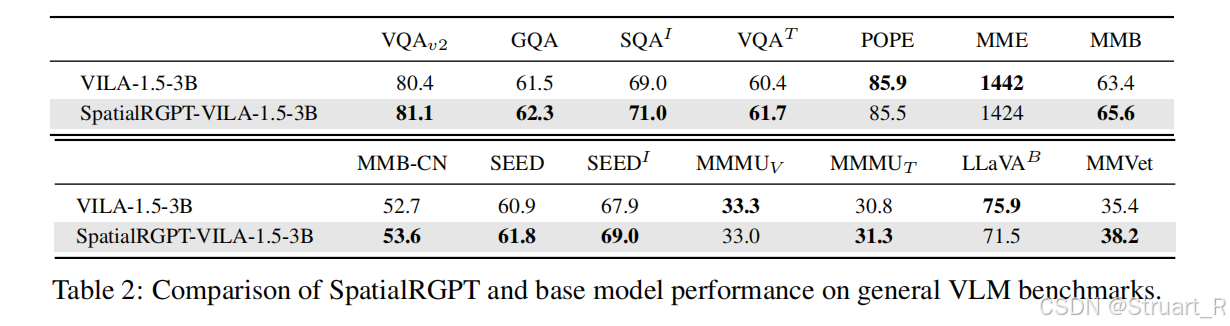
? ? ? ? 另外提到的一個SpatialRGPT-VILA模型是直接在預訓練VILA-1.5上微調得到的,更加節省訓練成本,在保留VILA所有語言模型和視覺編碼器的情況下,將深度特征集成到統一框架上。在實驗中測試通用benchmark,并沒有因為微調降低原有的模型學習到的圖像和視頻理解信息。
? ? ? ? 其中SpatialRGPT更適合基礎空間感知(比如機器人獎勵),Spatial-VILA更適合復雜環境實時推理(多跳推理)。
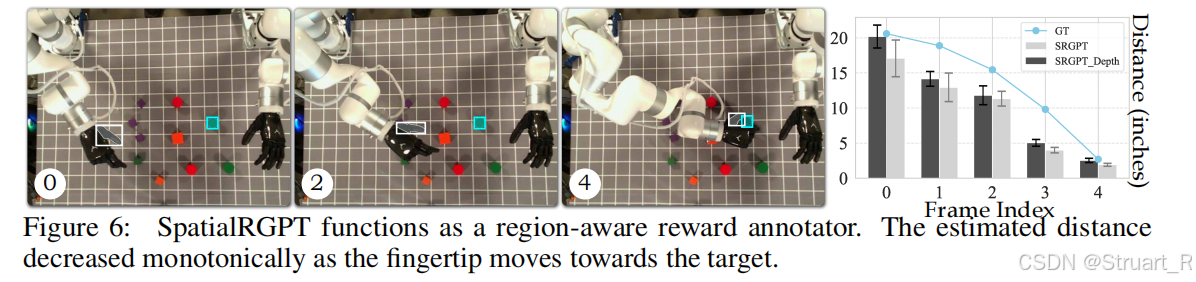
? ? ? ? 同樣的,SpatialRGPT類比SpatialVLM也可以計算獎勵用于機器人的路徑規劃下。
? ? ? ? 多跳推理。

參考論文:
[2401.12168] SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
[2406.01584] SpatialRGPT: Grounded Spatial Reasoning in Vision Language Models

)

)







![第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(4、矩陣圈層交錯旋轉)](http://pic.xiahunao.cn/第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(4、矩陣圈層交錯旋轉))
![【FastGTP?】[01] 使用 FastGPT 搭建簡易 AI 應用](http://pic.xiahunao.cn/【FastGTP?】[01] 使用 FastGPT 搭建簡易 AI 應用)

)

詳解)

:系統架構)
