GPU 基礎概述:從圖形渲染到 AI 與高性能計算的核心
Graphics Processing Units(GPU)已從專用的圖形渲染硬件演進為 AI、科學計算與高性能任務的中堅力量。本文將介紹 GPU 架構的基礎知識,包括其組成部分、內存層次結構,以及 Streaming Multiprocessors(SM)、核(cores)、warp 與程序(programs)的角色。
CPU vs. GPU:根本區別
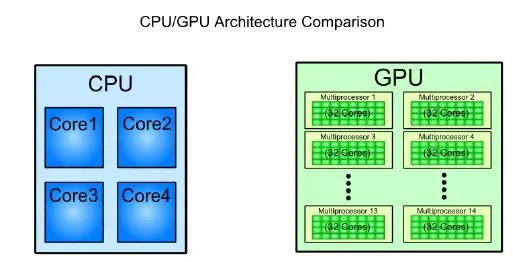
CPU(中央處理單元)與 GPU(圖形處理單元)都用于處理數據,但其處理方式存在根本差異:
資料來源:tutorialspoint.com
- CPU:擁有少量強大核心,擅長順序或有限并行任務處理。
- GPU:包含成千上萬的較小核心,設計用于大規模并行計算,適用于圖像渲染、訓練 AI 模型和仿真等任務。
簡言之,CPU 優化通用計算任務,而 GPU 擅長同時處理大量獨立的小規模計算。
GPU 的內存層次結構
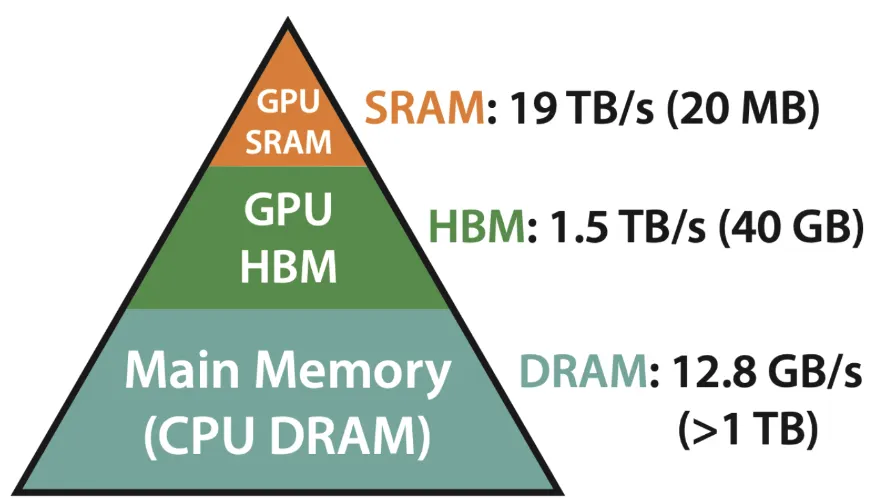
GPU 擁有復雜的內存層次結構以最大化計算效率。主要的內存類型包括:
SRAM(Static RAM)——最快的緩存層
位于 GPU 內核內部,包含寄存器、L1 Cache 與 L2 Cache:
- 寄存器(Registers):每個 GPU core 內的超快小內存,用于存放核心正在處理的即時值,速度最快。
- L1 Cache:位于每個 Streaming Multiprocessor(SM)內部的一級緩存,存儲常用數據以減少對慢速內存(如 DRAM)的訪問。
- L2 Cache:跨多個 SM 共享的二級緩存,用于存放不適合放入 L1 的數據,減少對外部顯存(VRAM)的依賴。
重要性:寄存器、L1、L2 減少了從較慢全局內存讀取數據的次數,從而加速計算,尤其對 AI 和游戲負載的性能至關重要。它們快速但容量小,因此合理利用緩存能顯著提升性能。
DRAM(Dynamic RAM)——主內存(GPU 上的 VRAM)
- 位于顯卡上,作為 VRAM(Video RAM)使用。
- 存放大量數據,如模型權重與貼圖。
- 比 SRAM 慢但容量更大,常見類型為 GDDR(Graphics DDR)。
HBM(High Bandwidth Memory)——高性能顯存
- 用于高性能 GPU(AI 與深度學習場景)。
- 采用堆疊式(vertical stacking)設計,降低延遲并提升帶寬。
- 比 GDDR 更快,但成本更高,常見于專業 GPU。
GPU 中的數據傳輸成本
從 DRAM(VRAM)向 SRAM(寄存器 / L1)移動數據代價很高,因此 kernel 優化通常聚焦于最小化這種傳輸。高效的內存使用能顯著提升 AI 與渲染任務的性能。
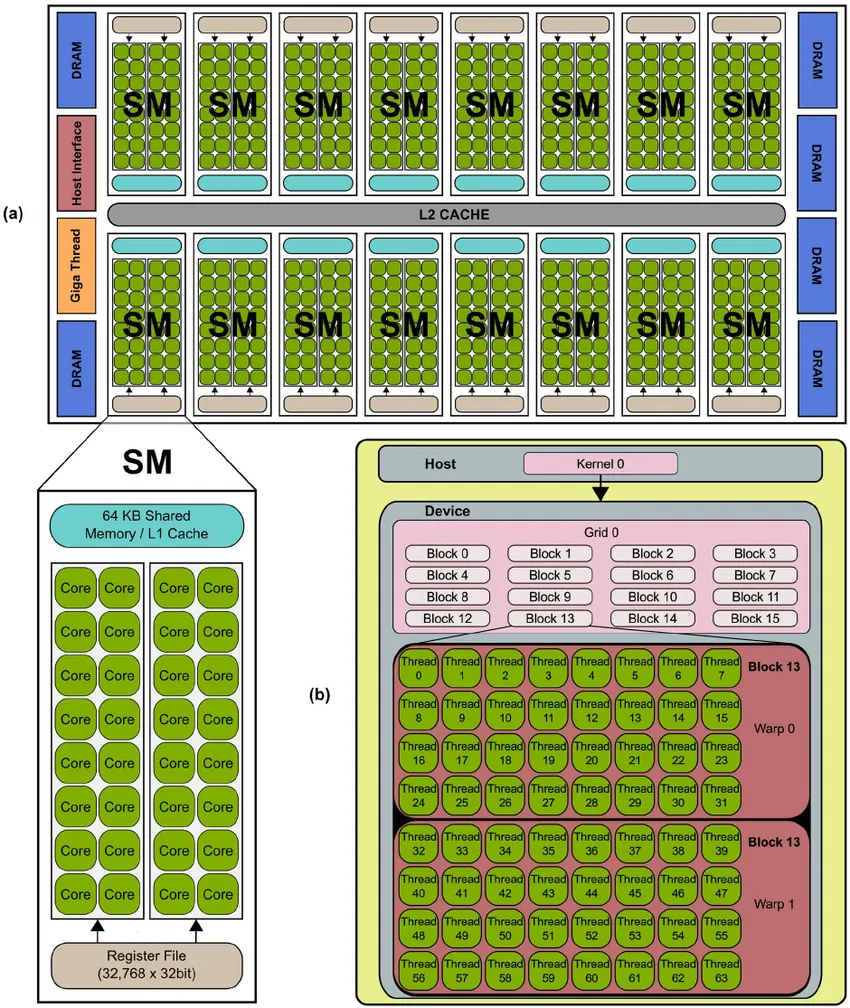
Streaming Multiprocessors(SMs)及其作用
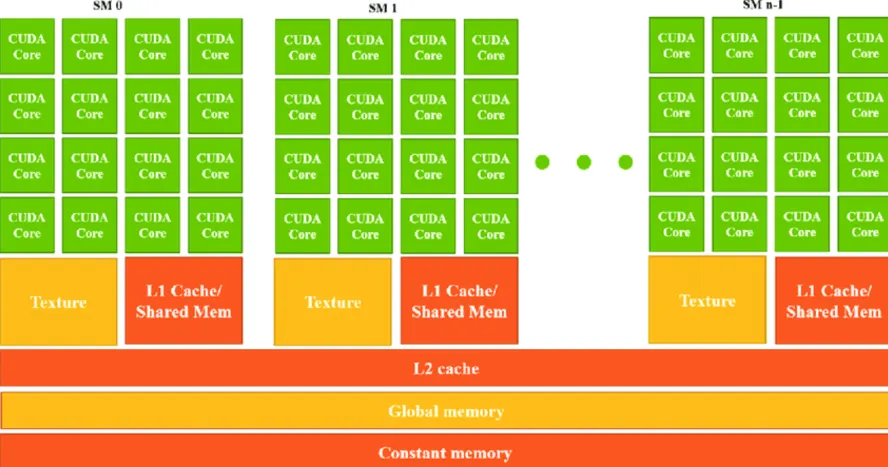
SM 是 GPU 的基本處理單元:
- 每個 SM 包含多個 GPU core、少量快速內存(SRAM)與執行單元。
- 每個 SM 可以獨立運行,處理多個并行程序實例。
- GPU 中 SM 的數量直接影響其計算能力:SM 越多,理論上并行處理能力越強。
當一個程序運行在 GPU 上時,它會被拆分到多個 SM 上,每個 SM 負責處理數據的一部分。更多的 SM 通常意味著更好的并行性能。
程序、PID 與并行執行
在 GPU 中,一個**程序(program)**是內核代碼的一個并行實例。每個程序:
- 被分配一個程序 ID(PID);
- 處理特定的數據塊;
- 使用所在 SM 的 SRAM 來高效執行計算。
每個 SM 能同時承載的 PID 數量取決于每個程序所需的 SRAM 大小:如果每個程序占用內存過多,SM 無法并行運行太多程序,效率就會下降。
核心(Cores)、Warp 與并行性
GPU 核心:最小計算單元
- 核心是 GPU 的最小計算單元,優化用于浮點運算(FLOPs)。
- 每個核心大多能在每個周期執行一次浮點操作。
Warp:核心的執行組
- GPU 的核心按 warp 分組。NVIDIA 的 warp 大小為 32,AMD 通常為 64。
- 一個 warp 內的所有核心必須同時執行同一條指令,但在不同數據上運行(SIMD 風格)。
- warp 作為一個執行單元按 lock-step(鎖步)方式運行。如果工作負載的尺寸不是 warp 大小的整數倍(例如張量形狀不是 32 的倍數),部分核心會空閑,導致性能下降,這種現象稱為 warp divergence。
建議:在張量與數據布局上盡量使用 32 的倍數(或 AMD 上的 64 倍數),以充分利用 warp 中所有核心,減少空閑與效率損失。
優化 GPU 性能的要點
- 減少內存傳輸 — 盡量降低 VRAM(DRAM)與 SRAM 之間的數據搬移次數。
- 最大化并行度 — 通過降低每個程序的內存占用,盡量讓更多 PID 在同一 SM 中并行運行。
- 為 warp 優化工作 — 在 AI 工作負載中使用 32(或 64)為單位的維度,確保 warp 內所有核心都有可做的工作。
結論
GPU 天生適合大規模并行計算,這使得它們在 AI、深度學習、游戲渲染與模擬等領域表現卓越。理解 SM、內存層次、核心、warp 與程序執行機制,有助于你為工作負載做出更合理的優化設計。無論是在訓練模型還是渲染復雜場景,高效利用 GPU 都是提升速度與可擴展性的關鍵。
)

)







![第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(4、矩陣圈層交錯旋轉)](http://pic.xiahunao.cn/第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(4、矩陣圈層交錯旋轉))
![【FastGTP?】[01] 使用 FastGPT 搭建簡易 AI 應用](http://pic.xiahunao.cn/【FastGTP?】[01] 使用 FastGPT 搭建簡易 AI 應用)

)

詳解)

:系統架構)

