機器學習基礎
一、什么是機器學習
定義:讓計算機利用大量數據在特定任務上持續改進性能的過程,可以讓任務完成的更好。
機器學習的領域很多。
二、機器學習基本術語
數據集、樣本、特征(屬性)、屬性空間、向量表示、訓練集(訓練模型的數據集合,含標記信息)、測試集(測試模型的數據集合)
三、主要學習任務(以好瓜壞瓜為例子)
監督學習:已知正確答案和參數,達到要求的學習過程。
分類:輸出的結果位有限,離散型(好瓜/壞瓜)。
回歸:輸出某個范圍內任何數值,連續型(房價預測)。
無監督學習:提供數據集合,不提供有信息的學習過程。
聚類:把樣本按相似度分組。
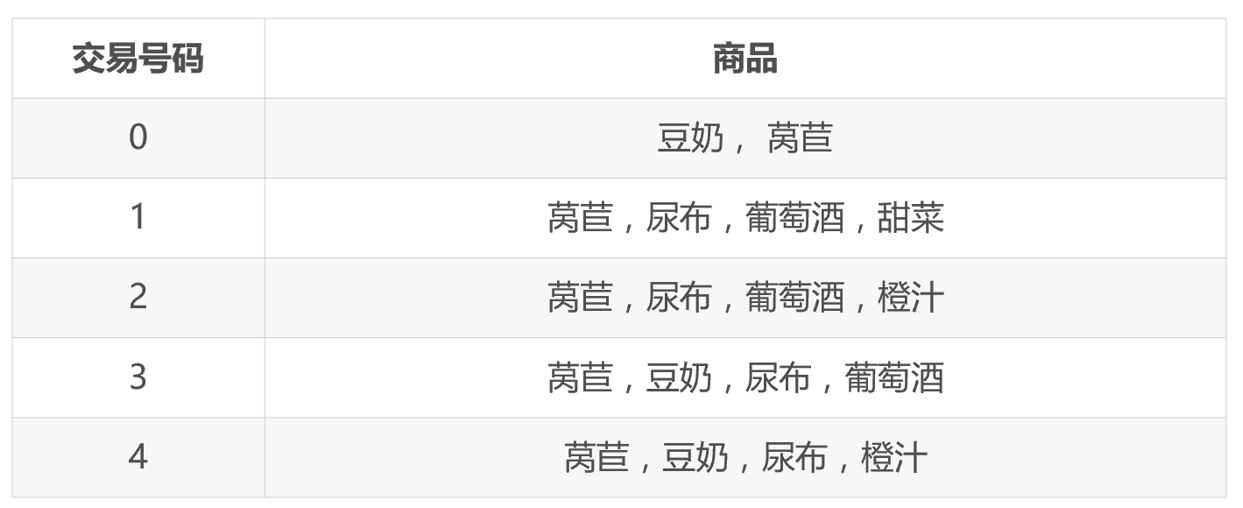
關聯分析:尿布 → 葡萄酒推薦。
集成學習
①結合多個弱學習器提升整體性能。
四、模型評估與選擇
誤差
訓練誤差(經驗誤差):在訓練集上的誤差。
泛化誤差:在新樣本上的期望誤差。
錯誤率:錯誤的樣本占樣本總數的比例。
殘差:實際預測輸出與樣本真實輸出的差異。
擬合狀態
欠擬合:模型太簡單,訓練誤差高。
→ 解決:增加特征、提高模型復雜度、減小正則化。
過擬合:模型太復雜,訓練誤差低但泛化誤差高。
→ 解決:增數據、降維、正則化、集成學習。
損失函數:衡量模型預測誤差大小的函數。(損失函數越小越好)
評估方法
留出法:70 % 訓練 / 30 % 測試,分層采樣。
k 折交叉驗證:常用 10 折,取 k 次平均。
性能指標(二分類)
TP, FP, TN, FN
查準率 P = TP / (TP+FP)
查全率 R = TP / (TP+FN)
五、選擇模型的原則
奧卡姆剃刀:在可解釋數據的前提下選最簡單模型。
沒有免費午餐(NFL):脫離具體任務談算法優劣無意義。
機器學習=數據+算法+評估
用經驗提升任務性能,警惕欠擬合與過擬合,通過交叉驗證和性能指標選擇最適合實際問題的簡潔模型。







![第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(4、矩陣圈層交錯旋轉)](http://pic.xiahunao.cn/第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(4、矩陣圈層交錯旋轉))
![【FastGTP?】[01] 使用 FastGPT 搭建簡易 AI 應用](http://pic.xiahunao.cn/【FastGTP?】[01] 使用 FastGPT 搭建簡易 AI 應用)

)

詳解)

:系統架構)




|輕量化 MobileNetV2 高光譜分類)