一、什么是時間序列聚類?
如果把數據比作一本書,那么時間序列(Time Series)就是一本按時間順序記錄事件的日記。它可能是股票每天的價格波動、某臺機器的溫度曲線、一個城市的空氣質量變化,甚至是人的心電信號。時間序列聚類,就是要幫這些“日記”找到志同道合的伙伴——那些經歷相似、變化趨勢類似的“故事”。
舉個簡單的例子:
一家健身房記錄了上百名會員的心率曲線。
有的人曲線平穩(輕運動愛好者),有的人曲線起伏大(高強度訓練者)。
通過時間序列聚類,我們可以自動把這些心率曲線分成幾類,從而為不同人群定制運動方案。
這就是時間序列聚類的魔力:不需要預先告訴算法類別,它就能根據時間變化的形態,把相似的放一起。
二、為什么要關心時間序列聚類?
1. 時間是數據的靈魂
普通的聚類方法(比如K-means)更像是拍一張“靜態照片”——只看當前的特征值。而時間序列聚類更像是看“動態電影”——考慮數據的變化軌跡、節奏、周期性等信息。這意味著它能識別那些靜態上差不多,但趨勢完全不同的對象。
2. 應用領域極廣
金融領域:找出走勢相似的股票、基金,輔助投資策略。
醫療健康:分析病人的心電圖(ECG)、腦電圖(EEG)等,發現潛在疾病亞型。
工業運維:通過傳感器數據識別設備的健康狀態,提前發現異常模式。
氣象分析:聚類不同地區的溫度、降水曲線,揭示氣候分區特征。
電力系統:分析負荷曲線,做負荷預測與分組調度。
3. 不止是“分組”
很多人以為聚類就是為了分組,但在時間序列中,聚類還可以:
發現隱藏模式
數據壓縮與表示
異常檢測(離群曲線往往是異常信號)
特征工程(把聚類標簽作為新的特征輸入到后續模型中)
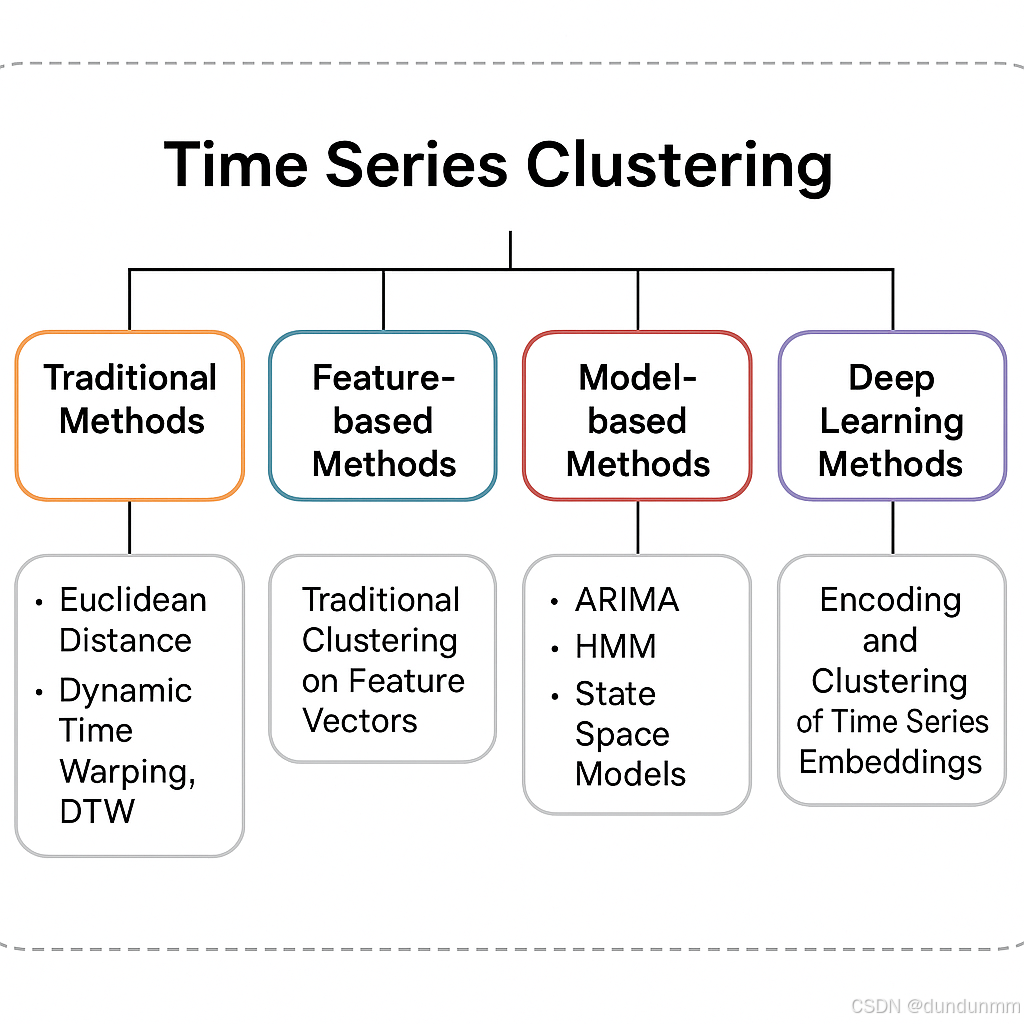
三、時間序列聚類的三大路線
時間序列聚類的方法并不是單一的,它有多條“路線”,就像旅游時你可以選擇直飛、轉機、或者自駕,目的地相同但過程不同。
1. 基于原始數據的聚類
這類方法直接在時間序列的原始形態上計算相似度。
歐幾里得距離(Euclidean Distance):簡單直接,對長度一致且對齊的序列適用。
動態時間規整(Dynamic Time Warping, DTW):可以“拉伸”時間軸來匹配曲線,解決了速度不同但形態相似的問題(就像兩個人跑同一條路線,一個快一個慢,也能判斷他們路線相似)。
編輯距離(Edit Distance on Real Sequence, EDR):類似文本編輯距離,允許插入、刪除和替換操作。
優點:保留了所有原始信息。
缺點:計算量大,對噪聲敏感。
2. 基于特征的聚類
這類方法會先把時間序列轉成一組特征(比如平均值、波動幅度、周期特征、小波系數等),再用傳統聚類方法分組。
統計特征:均值、方差、最大值、最小值、峰度、偏度。
頻域特征:傅里葉變換后的頻譜能量分布。
小波特征:多尺度分解得到的系數。
形狀特征:趨勢斜率、波峰波谷位置。
優點:速度快,適合大規模數據。
缺點:特征提取過程可能丟失局部模式信息。
3. 基于模型的聚類
這類方法假設每條時間序列由某種生成機制產生,通過擬合模型獲取參數,再對參數聚類。
ARIMA模型:用自回歸和移動平均擬合序列。
隱馬爾可夫模型(HMM):捕捉序列的隱含狀態轉換模式。
狀態空間模型:建模動態系統的觀測值與狀態。
優點:能解釋生成機制,適合有明顯規律的序列。
缺點:建模過程復雜,需要假設模型類型。
4. 深度學習驅動的聚類
近年來,深度學習為時間序列聚類帶來了新的可能:
RNN/LSTM/GRU自編碼器:學習序列的低維表示,再在表示空間中聚類。
卷積神經網絡(CNN):提取局部時間模式。
時序Transformer:捕捉長程依賴關系。
對比學習(Contrastive Learning):通過增強對比訓練得到更穩健的序列表示。
優點:能處理復雜、非線性模式,適應性強。
缺點:需要較多數據和計算資源,可解釋性較弱。
四、時間序列聚類的關鍵步驟
無論用哪條路線,時間序列聚類通常遵循以下步驟:
數據預處理
缺失值填補(插值、前向填充等)
去噪(濾波、平滑)
標準化(Z-score、Min-Max)
對齊(處理起止時間不一致)
相似度度量
根據場景選擇距離度量(Euclidean、DTW、相關系數等)
計算兩兩相似度矩陣
聚類算法選擇
K-means/K-medoids
層次聚類(Hierarchical Clustering)
DBSCAN(適合發現不規則簇)
譜聚類(Spectral Clustering)
結果評估
內部指標:輪廓系數(Silhouette)、DB指數
外部指標(有標簽時):ARI、NMI
可視化:t-SNE、UMAP降維
五、案例:用DTW做股票走勢聚類
假設我們有50只股票的近一年日收盤價曲線,目標是找出走勢相似的股票組。
預處理:
對每日收盤價做Z-score標準化,消除價格量級差異。
相似度計算:
用DTW距離度量每兩只股票的走勢相似度。
聚類:
采用K-medoids聚類,將股票分成5組。
結果分析:
發現A組股票都是周期性波動的消費股,B組是科技股的穩步上漲走勢。
這個過程可以輔助投資組合優化,也能為量化策略提供參考。
六、挑戰與發展方向
時間序列聚類雖好,但也有不少挑戰:
高維性與長序列:長時間序列的計算成本高,存儲壓力大。
多變量時序:很多場景下,不止一個傳感器或變量。
噪聲與異常值:現實數據常有缺失、漂移、突變。
可解釋性:特別是深度學習方法,難以解釋聚類原因。
未來的發展趨勢包括:
可解釋的深度聚類模型
增量式聚類(實時流數據處理)
多模態時序聚類(結合視頻、圖像、傳感器多源信息)
自動化特征提取與距離選擇
七、總結
時間序列聚類是讓“數據的時間故事”找到同類的藝術與科學。它兼具數學的嚴謹性和現實應用的廣泛性,既能服務科研探索,也能直接創造商業價值。無論是原始形態直接比較,還是特征提取與建模,甚至用深度神經網絡做智能聚類,核心都是理解時間背后的模式。
用一句形象的話來說:
普通聚類看的是“你今天長得像誰”,
時間序列聚類看的是“你這一路走來,像誰”。
【生成器+判斷器】)


DiffusionDet - 擴散模型在目標檢測中的開創性應用)

的查詢速度有時會突然變慢)









與調優詳解)



