論文題目:DiffusionDet: Diffusion Model for Object Detection(DiffusionDet:物體檢測的擴散模型)
會議:ICCV2023
摘要:我們提出了DiffusionDet,這是一個新的框架,它將物體檢測描述為從噪聲盒到目標盒的去噪擴散過程。在訓練階段,目標盒從真實值盒擴散到隨機分布,模型學習反轉這一噪聲過程。在推理中,該模型將隨機生成的一組框逐步細化到輸出結果。我們的工作具有吸引人的靈活性,這使得盒子的動態數量和迭代評估成為可能。在標準基準測試上進行的大量實驗表明,與以前成熟的檢測器相比,DiffusionDet具有良好的性能。例如,在從COCO到CrowdHuman的零樣本學習轉移設置下,當使用更多的盒子和迭代步驟進行評估時,DiffusionDet獲得了5.3 AP和4.8 AP增益。
源碼鏈接:https://github.com/ ShoufaChen/DiffusionDet
引言:當生成遇見檢測
想象一下,如果我們能像藝術家作畫一樣,從一張空白畫布(隨機噪聲)開始,逐步"繪制"出圖像中的所有目標,這會是怎樣一種體驗?DiffusionDet正是基于這樣的靈感,將近年來在圖像生成領域大放異彩的擴散模型引入目標檢測任務,開創了一個全新的研究方向。
傳統檢測方法的困境
目標檢測作為計算機視覺的核心任務,經歷了漫長的發展歷程。從最初的滑動窗口,到后來的錨框機制,再到近期的DETR系列,研究者們一直在尋找更優雅、更有效的解決方案。
然而,現有方法都面臨著一個共同的問題:缺乏靈活性。
固定候選的束縛
傳統的兩階段檢測器(如Faster R-CNN)依賴預定義的錨框,需要大量的超參數調整。即使是更現代的DETR,雖然實現了端到端檢測,但仍然依賴固定數量的可學習查詢。這意味著:
- 訓練時用300個查詢,推理時也必須用300個
- 無法根據場景密度動態調整
- 稀疏場景浪費計算,密集場景性能受限
迭代優化的缺失
大多數現有方法都是"一次性"的:網絡前向傳播一次就給出最終結果。這與人類視覺系統的工作方式相去甚遠——我們往往需要多次"審視"才能準確識別復雜場景中的所有目標。
DiffusionDet:革命性的新范式
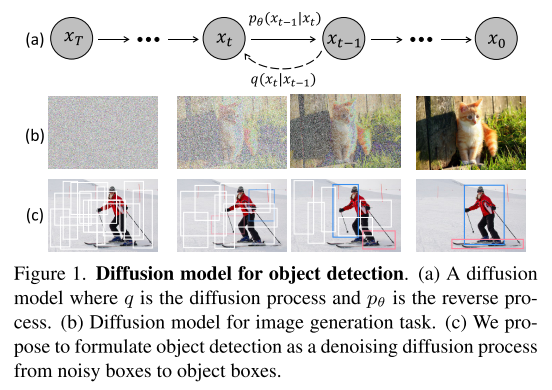
核心思想:從噪聲到目標
DiffusionDet的核心創新在于將目標檢測重新定義為一個漸進式去噪過程:
- 起點:完全隨機的邊界框
- 過程:通過學習到的去噪網絡逐步優化
- 終點:精確的目標檢測結果
這個過程可以用一個簡單的類比來理解:就像一個雕塑家從一塊粗糙的石頭開始,通過反復雕琢,最終創造出精美的藝術品。
技術架構:簡約而不簡單
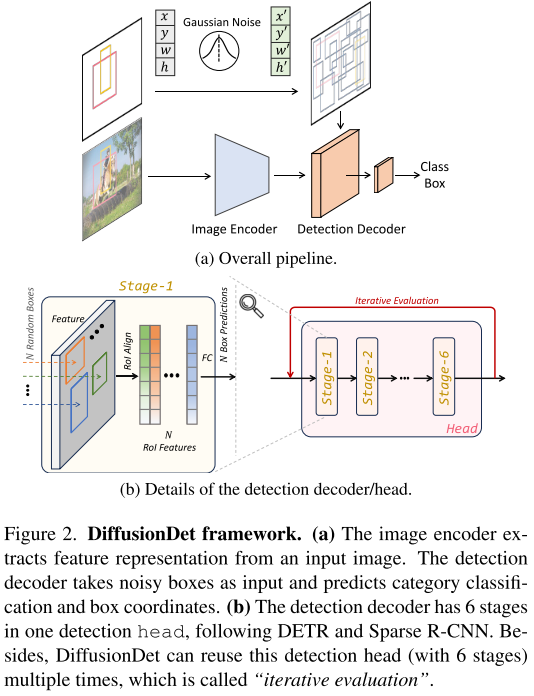
DiffusionDet的架構設計體現了"大道至簡"的哲學:
輸入圖像 → 圖像編碼器 → 特征圖
隨機框 → 檢測解碼器 → 精確框
圖像編碼器只運行一次,提取圖像的深層表征;檢測解碼器則可以多次使用,每次都在前一次的基礎上進一步優化結果。
訓練過程:學會"倒放電影"
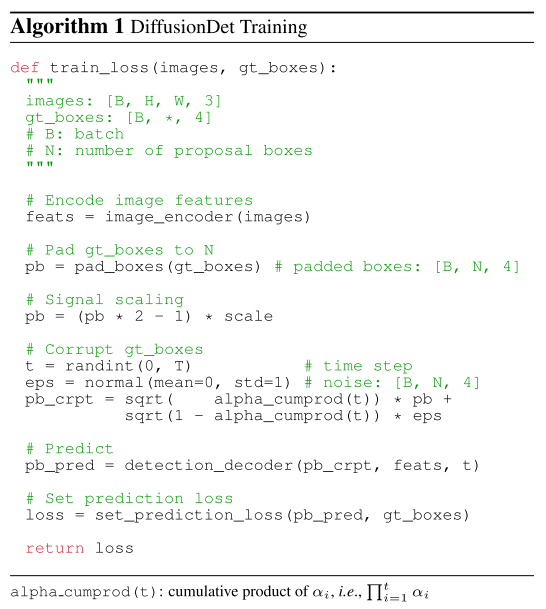
訓練DiffusionDet就像教會網絡"倒放電影":
- 前向過程:將真實邊界框逐步添加噪聲,直到變成隨機分布
- 學習目標:訓練網絡從任意噪聲狀態恢復到真實狀態
- 關鍵創新:引入時間步嵌入,讓網絡知道當前處于去噪過程的哪個階段
# 簡化的訓練偽代碼
def train_step(images, gt_boxes):# 隨機選擇時間步t = random.randint(0, T)# 添加噪聲noise = torch.randn_like(gt_boxes)noisy_boxes = sqrt(alpha_t) * gt_boxes + sqrt(1-alpha_t) * noise# 預測原始框pred_boxes = model(images, noisy_boxes, t)# 計算損失loss = F.mse_loss(pred_boxes, gt_boxes)return loss
令人驚喜的實驗結果
性能提升:數字說話
在COCO數據集上,DiffusionDet取得了令人印象深刻的結果:
- 基礎配置:45.8 AP(ResNet-50),超越Faster R-CNN 5.6個點
- 優化配置:46.8 AP(4次迭代,500框),接近Swin-Base級別的性能
- 強骨干網絡:53.3 AP(Swin-Base),達到SOTA水平
靈活性驗證:一個模型,多種場景
DiffusionDet最令人興奮的特性是其前所未有的靈活性。在零樣本遷移實驗中,從COCO(稀疏場景)到CrowdHuman(密集場景):
- 增加框數量:從300到2000框,性能提升5.3 AP
- 增加迭代次數:從1到4次,性能提升4.8 AP
- 對比實驗:傳統方法(DETR、Sparse R-CNN)性能下降或無提升
這意味著什么?一次訓練,終身受用!同一個模型可以:
- 在稀疏場景中高效運行(少框,少迭代)
- 在密集場景中追求極致性能(多框,多迭代)
- 根據計算預算靈活調整速度-精度權衡
消融研究:每個設計都有道理
通過詳盡的消融研究,研究者證明了每個設計選擇都是經過深思熟慮的:
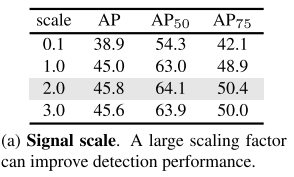
信號縮放的重要性: 目標檢測需要比圖像生成更高的信號縮放(2.0 vs 1.0),因為邊界框只有4個參數,比圖像的數千個像素更加"脆弱"。
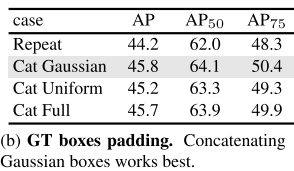
框更新策略的必要性: 在迭代過程中,主動替換低質量預測框,確保每次迭代都有"新鮮血液",避免陷入局部最優。
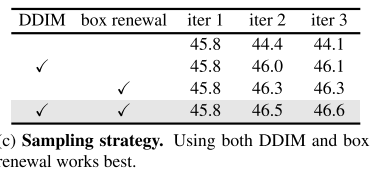
DDIM采樣的優勢: 相比直接傳遞預測結果,DDIM提供了更穩定的優化軌跡。
深度思考:為什么DiffusionDet有效?
從數學角度
擴散模型本質上在學習數據分布的梯度場。對于目標檢測:
- 數據分布:有效邊界框的分布
- 梯度場:指向最近有效框的方向
- 去噪過程:沿著梯度場的引導找到最優解
從認知角度
DiffusionDet的工作方式更接近人類視覺認知:
- 漸進式:從粗糙到精細的逐步優化
- 迭代式:允許多次"審視"和修正
- 自適應:根據場景復雜度調整處理深度
從工程角度
分離圖像編碼和框優化帶來了計算效率:
- 圖像編碼:計算密集,但只需一次
- 框優化:相對輕量,可多次迭代
- 總體效率:在迭代獲益和計算開銷間找到平衡
局限性與未來展望
當前局限性
- 推理速度:迭代優化帶來額外計算開銷
- 內存消耗:需要存儲中間狀態
- 超參數敏感:噪聲調度等需要細致調優
未來發展方向
- 加速采樣:借鑒一致性模型等快速采樣技術
- 架構優化:設計更高效的迭代結構
- 任務擴展:擴展到實例分割、全景分割等任務
- 多模態融合:結合文本、語音等多模態信息
結語:范式轉換的意義
DiffusionDet不僅僅是一個新的目標檢測算法,更代表了一種全新的思維方式。它告訴我們:
- 生成式思維可以解決判別式問題
- 靈活性比單純的性能提升更有價值
- 漸進式優化是處理復雜視覺任務的自然方式
正如深度學習歷史上的每一次范式轉換(從手工特征到端到端學習,從CNN到Transformer),DiffusionDet可能正在開啟目標檢測的新紀元。
在這個紀元中,模型不再是僵化的函數映射,而是能夠根據場景需求自適應調整的智能系統。這樣的系統更接近人類視覺智能,也更適合真實世界的復雜需求。
未來,當我們回顧目標檢測的發展歷程時,或許會將DiffusionDet視為一個重要的里程碑——它不僅推動了技術的發展,更重要的是,它改變了我們思考問題的方式。

的查詢速度有時會突然變慢)









與調優詳解)







)