我決定從今天開始,在每天的學習內容中加入算法的內容,大致分布時間的話,假設我一天可以學習八個小時,那算法兩個小時,八股三個小時,項目三個小時這樣的分布差不多吧。之所以還是需要做做筆試一是為了應對面試時一些基本的可能需要寫的東西,二是太久沒寫了感覺算法思想這一塊有點遺失了啊。
算法
我們大體上分為兩個部分吧,一部分當然是去做新題,另一部分則是去回顧一下以前寫的老題。
新題的話,我們就按照靈茶山題單的內容來:
今天我們來做常用數據結構這個部分的題,這里介紹了這些數據結構:
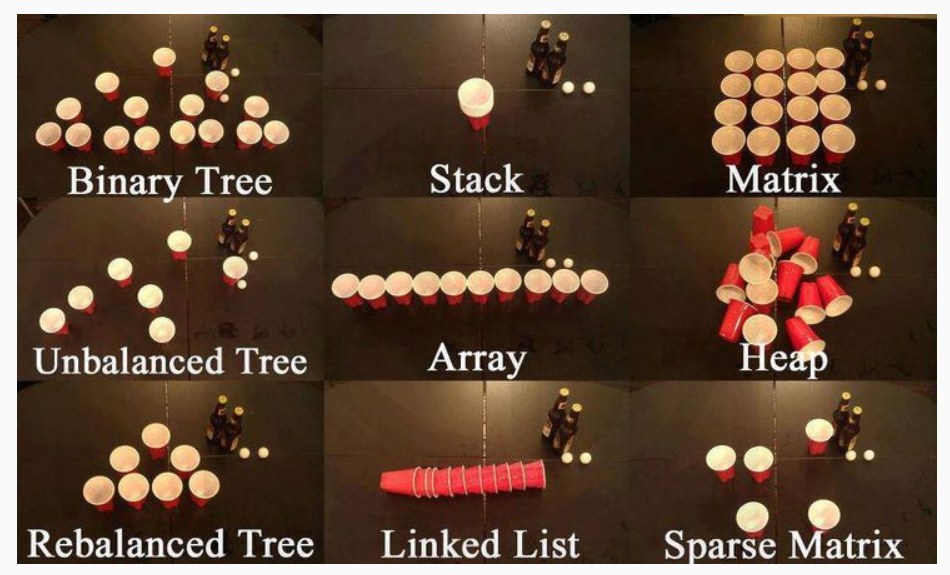
分別是二叉樹,棧,矩陣,不平衡樹,數組,堆,平衡樹,鏈表和稀疏矩陣。
大家可能不太熟悉的就是我們的稀疏矩陣的概念,大體上來說其實就是矩陣中的元素大多數是0的矩陣就可以稱為稀疏矩陣。
然后我們開始學習枚舉的使用方法:
第一種是針對雙變量問題,我們可以把其中一個變量用枚舉變量表示來將雙變量問題轉換成單變量問題。
我們拿最經典的兩數之和來介紹:
1. 兩數之和 - 力扣(LeetCode)
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {for (int i = 0; ; i++) { // 枚舉 ifor (int j = i + 1; j < nums.size(); j++) { // 枚舉 i 右邊的 jif (nums[i] + nums[j] == target) { // 滿足要求return {i, j}; // 返回兩個數的下標}}}// 題目保證有解,循環中一定會 return// 所以這里無需 return,畢竟代碼不會執行到這里}
};這其實就是一種利用枚舉將雙變量問題轉成單變量問題的思路體現。
2001. 可互換矩形的組數 - 力扣(LeetCode)

class Solution {
public:long long interchangeableRectangles(vector<vector<int>>& rectangles) {int size = rectangles.size();long long ans = 0;map<double,int>cnt;for(int i = 0; i < size; i++){double ratio = 1.0 * rectangles[i][0] / rectangles[i][1];cnt[ratio]++;} for(map<double,int>::iterator it = cnt.begin(); it != cnt.end(); it++){ans += 1LL * (it -> second) * (it -> second - 1) / 2;}return ans;}
};
兩個要注意的點是,一是要用double存寬高比不然值是錯誤的,而是直接利用組合數公式能夠快速從哈希表中得到每個寬高比的組合數總和。
1128. 等價多米諾骨牌對的數量 - 力扣(LeetCode)

class Solution {
public:int numEquivDominoPairs(vector<vector<int>>& dominoes) {int ans = 0;int cnt[10][10]{};for (auto& d : dominoes) {auto [a, b] = minmax(d[0], d[1]); // 保證 a <= bans += cnt[a][b]++;}return ans;}
};這個題解最大的特點就是使用了minmax這個函數,其核心作用是同時返回兩個值中的最小值和最大值,并以?std::pair形式返回結果,其中?first為最小值,second為最大值,這樣我們可以直接獲取到最小值和最大值之后進行比對即可。
3623. 統計梯形的數目 I - 力扣(LeetCode)

class Solution {
public:int countTrapezoids(vector<vector<int>>& points) {const int MOD = 1e9+7;unordered_map<int, int> cnt;for (auto& p : points) {cnt[p[1]]++; // 統計每一行(水平線)有多少個點}long long ans = 0, s = 0;for (auto& [_, c] : cnt) {long long k = 1LL * c * (c - 1) / 2;ans += s * k;s += k;}return ans % MOD;}
};利用哈希表統計每條水平線(相同 y 坐標)上的點數,計算每條水平線上可形成的點對組合數,隨后遍歷所有水平線,將當前水平線的組合數與此前所有水平線的組合數累積總和相乘,得到當前水平線與歷史水平線組合形成的梯形數量,并累加到結果中。
3371. 識別數組中的最大異常值 - 力扣(LeetCode)

class Solution {
public:int getLargestOutlier(vector<int>& nums) {unordered_map<int, int> cnt;int total = 0;for (int x : nums) {cnt[x]++;total += x;}int ans = INT_MIN;for (int x : nums) {cnt[x]--;if ((total - x) % 2 == 0 && cnt[(total - x) / 2] > 0) {ans = max(ans, x);}cnt[x]++;}return ans;}
};這個題的本質其實也是兩數之和,我們把數組分成三部分,一部分是異常值,一部分是其他數的總和,一部分是特殊數字,我們獲取一個總和,然后在哈希表中假設每個值都是異常值,總和去掉這個值的總和可以整除以2并且在哈希表中存在這樣的值就滿足條件。
1010. 總持續時間可被 60 整除的歌曲 - 力扣(LeetCode)

class Solution {
public:int numPairsDivisibleBy60(vector<int> &time) {int ans = 0, cnt[60]{};for (int t : time) {ans += cnt[(60 - t % 60) % 60];cnt[t % 60]++;}return ans;}
};看起來似乎有些抽象,但其實就是假如time[i]對60取余之后假如是1的話,就去找數組中對60取余后值為59的值的個數即可。
八股
這個部分我們主要針對的內容就是語言(C++,C#)計算機基礎(計網,操作系統)游戲引擎(Unity和UE)以及渲染和物理引擎,看起來量確實很大,但其實我們在項目中花費的時間本身也是在補習相關的八股,比如當我們回顧Unity的項目時實際上也是在復習Unity的八股,所以這里我決定把游戲引擎、渲染和物理的部分去除掉,也就是這三個小時只看語言和計算機基礎相關的知識。
很多知識都是翻來覆去地看的,重復性很高。
C++:
在main函數之前執行的內容有哪些?
在進入 main 之前,系統/加載器先創建進程、映射可執行文件與依賴庫、設置棧指針和初始棧(含 argc/argv/environ),并完成動態鏈接重定位;隨后由 C 運行時入口(如 _start/CRT)接管,依次把 .bss 清零、把 .data 初值從鏡像拷貝到內存(而編譯期常量通常直接放在 .rodata,無需運行時代碼初始化),初始化運行庫與線程/TLS 等環境,然后按順序調用預初始化與初始化數組中的函數(其中包含用 __attribute__((constructor)) 標記的構造器);上述步驟完成后才跳轉進入 main。
更直白的話語是:在進入?main?之前,系統先把程序裝進內存并把棧支好;接著把全局/靜態變量就位:沒寫初值的清零,帶初值的從鏡像拷到內存,而編譯期常量直接放在只讀區不用再跑代碼;然后把運行庫等環境準備好,按順序調用你標了?constructor 的初始化函數,做完這些才開始執行 main。
結構體內存?
每個成員的起始偏移必須是其類型對齊要求(由平臺/ABI規定,通常為2的冪,可能小于、等于或大于成員大小)的整數倍;結構體自身的對齊要求等于其所有成員對齊要求的最大值,結構體的起始地址也要滿足這個對齊;為保證結構體數組元素都正確對齊,sizeof(struct)?會向上補齊到該最大對齊的整數倍(因此成員間或末尾可能有填充);編譯器/ABI設置如?#pragma pack、__attribute__((packed))、alignas(N)?可降低或提高對齊,從而改變布局與大小。
為什么需要內存對齊?
內存對齊的本質是讓CPU“對得上口徑、一次拿全、少出事”:很多硬件規定數據要放在某個邊界上,不對齊可能直接報錯;即便能訪問,也常要拆成兩次讀寫、可能跨緩存行/頁,變慢還更耗能;按對齊放可以讓CPU一次就把需要的字節整塊取到,速度更穩、開銷更小。
指針和引用的區別?
這個已經說了很多次了,但這里我補充一下就是sizeof的用法:sizeof(指針變量)得到的是指針本身的大小(與指向什么無關,大小隨平臺如32位4字節、64位多為8字節);而sizeof(引用)得到的是被引用類型的大小,因為引用只是別名沒有“自身大小”;若想得到指針所指對象的大小應寫sizeof(*p)(不會真的解引用);另外通過引用不會發生數組衰減,所以對“數組的引用”做sizeof會得到整個數組的大小。
那我們再詳細地介紹一下sizeof的用法:
sizeof 可用于類型或表達式,返回字節數且不求值表達式;對指針得到指針本身大小(與指向類型無關,想要對象大小用 sizeof(p));對引用得到被引用類型大小;對“真數組對象”(局部/全局、結構體成員、數組引用)得到整個數組的字節數,但函數形參寫成 T?a[] 會退化為 T,在函數體內 sizeof(a) 僅是指針大小;字符串字面量包含結尾 '\0',如 sizeof "abc" 為?4;動態分配得到的是指針,sizeof 也只給指針大小。
傳遞函數參數時傳指針和傳引用有何區別?
在 C++ 里,傳引用像給形參起“別名”:語法自然(無需取址/解引用)、不能為 null、綁定后不可改綁(不能指向別處),可用 const 控制只讀,且 const 引用能綁定臨時對象;傳指針則要取址調用、函數內需解引用,指針可為 null(需判空)、可改指向別的對象,適合表示“可選/輸出參數”、與數組迭代和指針運算相關的場景;語義上引用用于“必須存在的別名”,指針用于“可空/可重綁定/數組”;性能通常等價,涉及所有權請用智能指針表達。
具體傳參的時候怎么傳呢?對小而可拷貝的標量(如 int、double、指針)直接按值傳;想只讀大對象且避免拷貝用 const?T&;需要修改且參數“必須存在”用?T&;參數是“可選的/可能為?null”或需要能改指向時用 T(只讀則 const?T);輸出參數優先用返回值,確需多輸出時:必定產出用?T&,可選產出用?T;要轉移/表達所有權用?std::unique_ptr?按值傳(或 std::shared_ptr 表示共享);需利用移動語義接收右值用?T&&;簡單記憶:引用表示“非空別名、不可改綁”,指針表示“可空、可改綁、也常用于數組/迭代”。
new的幾種用法?
是的,又是這個問題。
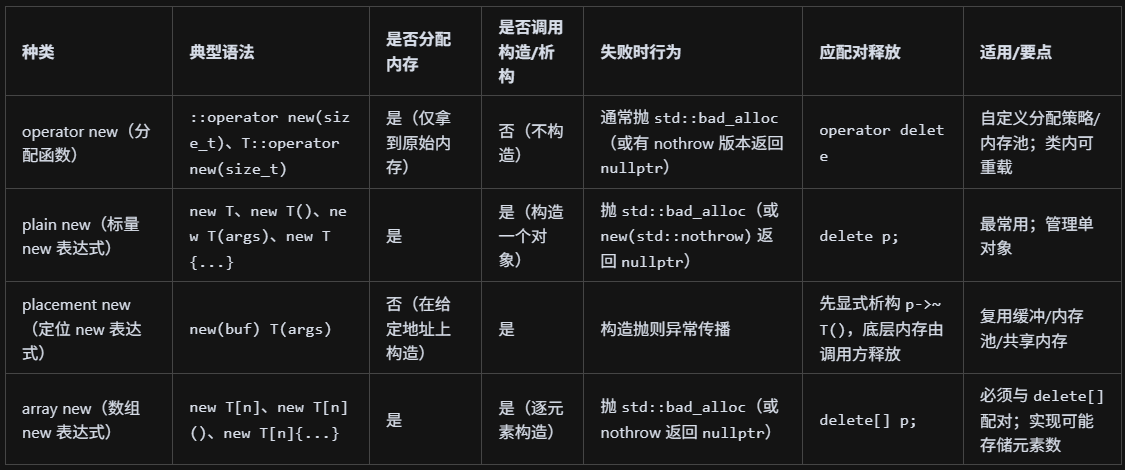
這里補充一下這個opertator new這個東西:operator new是“名為 operator new 的分配函數”,而不是你平常理解的“把某個運算符重載成自定義語義”的那個“新運算”;new?是一個“new 表達式”(關鍵字語法),它會先選擇并調用相應的分配函數?operator new/operator new[](可能是全局的也可能是類內重載的)取得原始內存,然后在這塊內存上調用構造函數。
變量的聲明和定義的區別?
聲明是“告訴編譯器有個名字及其類型/鏈接”,通常不分配存儲、可多次出現;定義是“真正落地創建實體”,會分配存儲并可初始化,在給定鏈接下只能有一次(一次定義規則)。所有定義都是聲明,但并非所有聲明都是定義。塊內的int x;既是聲明也是定義;文件作用域下不帶extern的一般是定義,帶extern且無初始化的是聲明,帶初始化的不管是否寫extern都是定義。
extern int g; // 聲明(不分配存儲)
int g; // 定義(分配存儲)
int g2 = 0; // 定義(并初始化)
extern int g3 = 1; // 定義(有初始化即為定義)
static int s; // 定義(內部鏈接)
void f(int); // 函數聲明
void f(int x) {} // 函數定義什么是頂層const和底層const?
頂層 const是修飾“對象本身”的不可變(如int const x;、T* const p),限制你不能通過這個名字改值或改指向,但按值拷貝/傳參會丟棄頂層 const;底層 const是修飾“經由指針/引用所指向的對象”的不可變(如const T* p、const T& r),它參與類型系統與重載,禁止通過該指針/引用改內容,允許T* -> const T*的加 const 轉換而不允許反向;快速判斷:從右往左讀,緊貼星號的 const?多為頂層(T* const),緊貼基本類型的 const 多為底層(const T*),兩者可同時存在(const T* const p)。
數組名和指針的區別?
數組名不是指針:它是“數組類型的表達式名”,在大多數表達式中會自動衰減為指向首元素的指針(T),但在用作?sizeof、&(以及?_Alignof)操作數時不衰減;數組名不可賦值、不可自增自減,指針變量可以重指向和運算;sizeof(數組名)得到整個數組的字節數,而 sizeof(指針)只得指針大小;函數形參寫成 T a[] 實際等同?T,在函數體內 sizeof(a)就是指針大小,所以只有在“真數組”仍未衰減的作用域里(如局部/全局數組、結構體里的數組成員,用作?sizeof?的操作數)才能用 sizeof(a)/sizeof(a[0])算元素個數;另需區分?&a?的類型是?“指向整個數組的指針”(T ()[N],步進按整塊),而衰減后的 a 是?T(步進按單元素)。
final和override關鍵字的作用是什么?
override 用在派生類的虛函數上,聲明“這是對基類同名虛函數的覆蓋”,并讓編譯器強制校驗簽名完全匹配(否則報錯);final 用來“封死擴展”,加在虛函數上表示此函數到本類為止不能再被重寫,加在類上表示該類不能被繼承;二者可組合寫成 “override final”,既確認確實在重寫,又禁止后續再重寫;簡言之:override是“意圖校驗”,final是“繼承/重寫限制”。
拷貝初始化和直接初始化有何區別?
類對象的拷貝初始化(T?x?= expr)只使用“可隱式”的構造/轉換把 expr 變成 T;若 expr 已是 T/派生則走拷貝/移動構造,explicit 在此不參與;直接初始化(T x(args) 或 T x{args})在構造函數中做重載決議,允許選擇 explicit,花括號還優先匹配 initializer_list 并做窄化檢查;T?x = {…} 是“拷貝列表初始化”,沿用花括號規則但?explicit 仍不參與;因此 explicit 的作用就是禁止隱式轉換與拷貝初始化,強制使用直接初始化或顯式轉換,避免意外轉換與重載歧義。
explict關鍵字的作用?
explicit 用在“轉換構造函數”和“類型轉換運算符”上,用來禁止隱式轉換和拷貝初始化(T x = a),從而只能通過直接初始化或顯式轉換(T x(a)/T?x{a}/static_cast)調用;它主要用于防止單參(或等效單參)構造帶來的意外自動轉換與重載歧義;C++11 起可用于轉換運算符,C++20 起支持 explicit(bool) 按條件禁用隱式轉換。
如何理解轉換構造函數?
轉換構造函數指能用單個實參(含默認參數湊成單參)把“其他類型的值”直接構造成本類對象的構造函數,即定義“其他類型 → 本類”的轉換;若未加 explicit,它可在賦值、傳參、表達式中被隱式調用參與重載決議(如 T x = a、f(a) 自動把 a 轉成 T),加了 explicit 則只能用于直接初始化或顯式轉換(如 T x(a)、static_cast<T>(a)),從而避免意外的自動轉換;與之相對,“本類 → 其他類型”的轉換由類型轉換運算符 operator U() 實現。
如何理解命名遮蔽?
基類函數非虛時,派生類若聲明同名同簽名成員,只是“名字隱藏”并重新定義了一個新函數;對派生對象調用命中派生版本,經由基類指針/引用調用仍靜態綁定到基類版本,需用限定名?Base::f()?指明基類;基類函數為虛時,派生類寫出同名同簽名成員(即使不寫 override)就是“重寫”,經由基類指針/引用會虛派發到派生,寫 override 只是做匹配校驗;一旦簽名不完全相同,就不會重寫而是觸發“名字隱藏”,把基類該名字下的所有重載都遮蔽,需要?using?Base::f;?把基類重載帶回,或用?Base::f(args)?指名調用;若想禁止派生重寫,則在基類虛函數上標注?final。
比如:
C++中的繼承權限?
public 繼承會把基類的 public 保持為 public、protected 保持為 protected(base 的 private 仍繼承但不可直接訪問);protected 繼承會把基類的 public 和 protected 都變成派生類中的 protected;private 繼承會把基類的 public 和?protected?都變成派生類中的 private(基類的 private 一直不可直接訪問)。
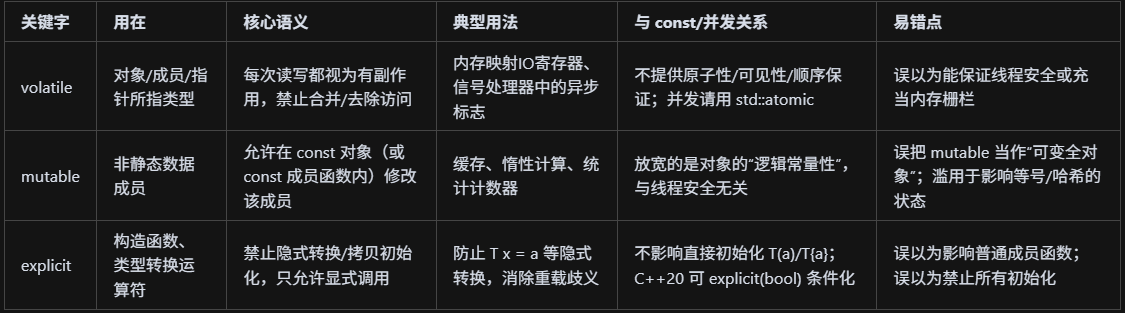
volatile、mutable和explicit關鍵字的用法?
volatile 是“別優化掉、每次都去真內存”的讀寫限定(用于硬件寄存器/異步修改,不是并發同步);mutable?是“即使對象是?const,這個成員也允許改”的成員修飾(常做緩存,不涉及線程安全);explicit?用在構造函數/轉換運算符上,禁止隱式轉換,只允許顯式構造/轉換,避免誤用與歧義。
計算機網絡:
DNS域名解析以什么協議為主?為什么?
DNS以UDP/53為主,因為無需建連、開銷小、延遲低,且大多數查詢/響應很小,單個往返包就能完成,便于高并發;但在響應過大被截斷(TC?置位)、區域傳送(AXFR/IXFR)或需更可靠傳輸時會改用TCP/53。(這里的53是端口號)
什么是區域傳送?
區域傳送就是權威DNS服務器之間同步同一域名“電話簿”的過程:主服務器把該域的所有記錄一次性整本復制給從服務器(AXFR,全量),或只把最近改動的部分給它(IXFR,增量),通常用 TCP/53 傳輸以確保可靠;它只發生在授權的權威服務器之間。
DNS負載均衡是什么?
當客戶端解析域名時,調度/權威 DNS 按策略(輪詢、權重、就近、健康狀況)從同一域名配置的多條 A/AAAA 記錄里選擇并返回一個或一組 IP,客戶端據此直連其中一個 IP,從而把不同用戶分散到不同服務器。
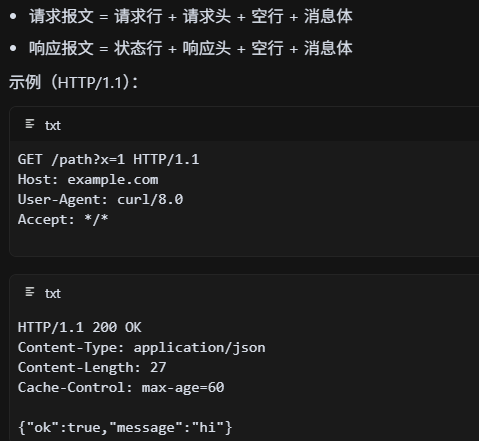
HTTP請求和響應報文的字段有哪些?
什么是ARP和RARP?
ARP?做?IP→MAC,RARP?做 MAC→IP地址的轉換。
HTTP是安全的嗎?
完全不是,HTTP協議的報文是明文傳輸,別人只要抓包后就能獲取所有傳輸的數據,要安全性就使用HTTPS。
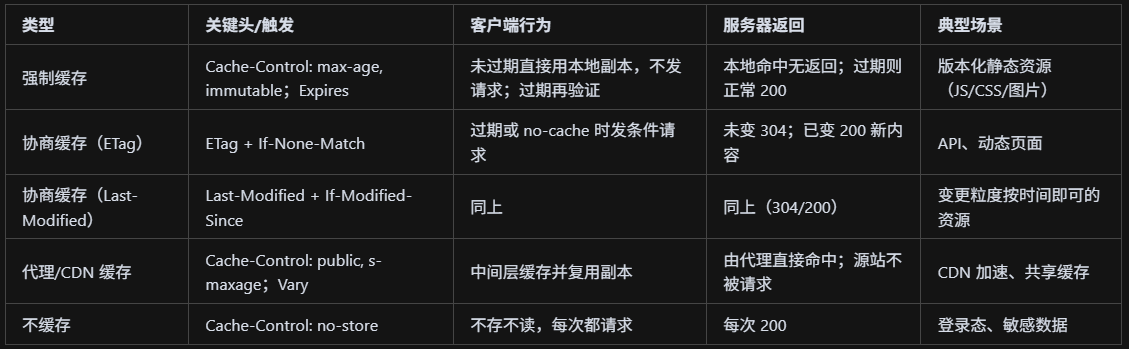
還記得HTTP中的緩存方案嗎?
HTTP 緩存主要分兩類:強制緩存(命中直接用本地,不發請求)和協商緩存(帶條件請求,未變化返回 304);核心頭包括 Cache-Control/Expires?控制時效,ETag/If-None-Match?與 Last-Modified/If-Modified-Since 判斷是否變化,配合?Vary、public/private、s-maxage 等用于瀏覽器與代理/CDN。
TCP的封包和拆包是什么?
TCP 是字節流無消息邊界的協議;“封包”是指應用層在發送前給每條消息加上可解析的邊界(如固定長度、長度前綴、分隔符或幀/TLV),再寫入?TCP;“拆包”是接收端從連續字節流中按這些邊界還原出一條條完整消息,以處理粘包/半包(一次讀到多條或不完整)的情況。





)
)
![為什么C++主函數 main 要寫成 int 返回值 | main(int argc, char* argv[]) 這種寫法是什么意思?](http://pic.xiahunao.cn/為什么C++主函數 main 要寫成 int 返回值 | main(int argc, char* argv[]) 這種寫法是什么意思?)











