Qwen3 技術報告 的 Strong-to-Weak Distillation 強到弱蒸餾 和 代碼實現
flyfish
代碼在文末
技術報告就是不一定經過嚴格的學術期刊同行評審,但具有較強的專業性和實用性。
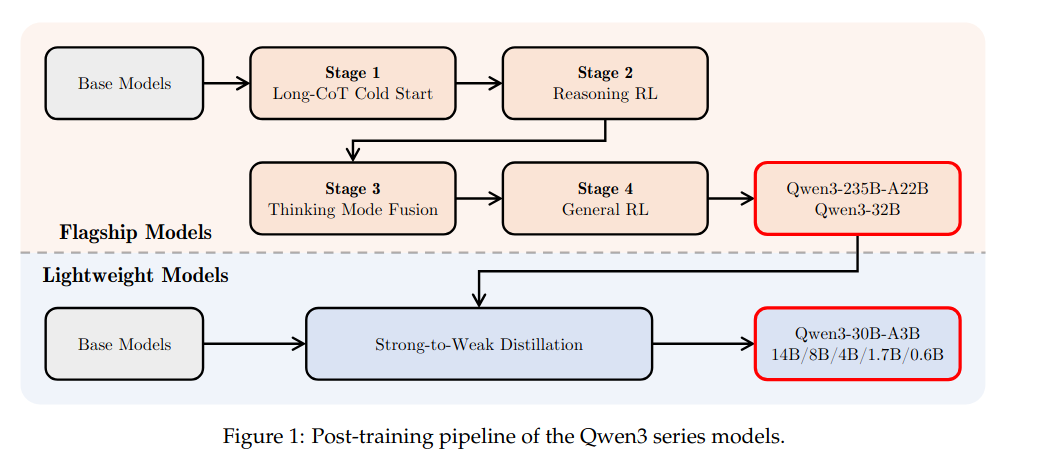
The post-training pipeline of Qwen3 is strategically designed with two core objectives:
(1) Thinking Control: This involves the integration of two distinct modes, namely the “non-thinking”
and “thinking” modes, providing users with the flexibility to choose whether the model should
engage in reasoning or not, and to control the depth of thinking by specifying a token budget for
the thinking process.
(2) Strong-to-Weak Distillation: This aims to streamline and optimize the post-training process
for lightweight models. By leveraging the knowledge from large-scale models, we substantially
reduce both the computational costs and the development efforts required for building smaller-
scale models.
post-training 后訓練
post-training強調的是 在模型完成預訓練(pre-training)之后、正式部署或應用之前 進行的一系列針對性訓練、優化步驟(比如 “思考控制”“強到弱蒸餾” 等)
“后訓練” 體現這一階段與 “預訓練” 的承接關系 —— 它屬于模型訓練生命周期中的一個特定階段(預訓練→后訓練→部署)
后訓練包括但不限于:微調(fine-tuning)、對齊(alignment)符合人類價值觀或指令、蒸餾(distillation)、能力增強等。
Qwen3 的后訓練流程
Qwen3 的后訓練流程經過精心設計,圍繞兩個核心目標展開:
(1)思考控制:整合 “非思考” 和 “思考” 兩種不同模式,為用戶提供靈活選擇的空間 —— 既可以決定模型是否進行推理,也能通過指定思考過程的 token 預算來控制思考深度。
(2)強到弱蒸餾:旨在簡化和優化輕量級模型的訓練后流程。借助大規模模型的知識,大幅降低構建小規模模型所需的計算成本和開發精力。
通過讓小模型直接學習大模型輸出的 logits,既能提升小模型性能,又能保留對其推理過程的精準調控,同時不用給每個小模型重復走復雜的四階段訓練流程,效率更高。
Strong-to-Weak Distillation 強到弱蒸餾
Strong-to-Weak Distillation
The Strong-to-Weak Distillation pipeline is specifically designed to optimize lightweight models, encompassing 5 dense models (Qwen3-0.6B, 1.7B, 4B, 8B, and 14B) and one MoE model (Qwen3-30B-A3B). This approach enhances model performance while effectively imparting robust mode-switching capabilities.The distillation process is divided into two primary phases:
(1) Off-policy Distillation: At this initial phase, we combine the outputs of teacher models generated
with both /think and /no think modes for response distillation. This helps lightweight student
models develop basic reasoning skills and the ability to switch between different modes of
thinking, laying a solid foundation for the next on-policy training phase.(2) On-policy Distillation: In this phase, the student model generates on-policy sequences for
fine-tuning. Specifically, prompts are sampled, and the student model produces responses in
either /think or /no think mode. The student model is then fine-tuned by aligning its logits
with those of a teacher model (Qwen3-32B or Qwen3-235B-A22B) to minimize the KL divergence.
Strong-to-Weak Distillation(強到弱蒸餾) 是一種知識遷移策略,其含義是:利用大規模高性能模型(強模型,即教師模型)的知識,通過系統性方法優化輕量級模型(弱模型,即學生模型)的訓練流程
強到弱蒸餾流程專為優化輕量級模型而設計,涵蓋 5 個密集型模型(Qwen3-0.6B、1.7B、4B、8B 和 14B)以及 1 個混合專家模型(Qwen3-30B-A3B)。該方法在提升模型性能的同時,能有效賦予其強大的模式切換能力。
蒸餾過程分為兩個主要階段:
(1)離線策略蒸餾:在這一初始階段,我們結合教師模型在 /think 模式和 /no think 模式下生成的輸出進行響應蒸餾。這有助于輕量級學生模型培養基本推理能力以及在不同思考模式間切換的能力,為下一階段的在線策略訓練奠定堅實基礎。
(2)在線策略蒸餾:在這一階段,學生模型生成在線策略序列以進行微調。具體而言,先對提示詞進行抽樣,再讓學生模型以 /think 模式或 /no think 模式生成響應。隨后,通過將學生模型的 logits 與教師模型(Qwen3-32B 或 Qwen3-235B-A22B)的 logits 對齊,以最小化 KL 散度,完成對學生模型的微調。
thinking and non-thinking modes 思考模式和非思考模式

Qwen3-4B-Instruct-2507
此模型僅支持非思考模式,在輸出中不會生成<think></think>塊。同時,不再需要指定enable_thinking=False。
Qwen/Qwen3-4B-Thinking-2507
此模型僅支持思考模式。同時,不再需要指定enable_thinking=True。
此外,為了強制模型思考,默認聊天模板自動包含 <think>。因此,模型輸出只包含 </think> 而沒有顯式的 <think> 開始標簽是正常的。
蒸餾代碼的實現
https://github.com/shaoshengsong/KDTrainer
代碼分析的是LLM-KD-Trainer/LLM-KD-Trainer.py
最好先看完基礎知識
知識蒸餾 - 蒸的什么
知識蒸餾 - 通過引入溫度參數T調整 Softmax 的輸出
知識蒸餾 - 對數函數的單調性
知識蒸餾 - 信息量的公式為什么是對數
知識蒸餾 - 根據真實事件的真實概率分布對其進行編碼
知識蒸餾 - 信息熵中的平均為什么是按概率加權的平均
知識蒸餾 - 自信息量是單個事件的信息量,而平均自信息量(即信息熵)是所有事件自信息量以其概率為權重的加權平均值
知識蒸餾 - 最小化KL散度與最小化交叉熵是完全等價的
知識蒸餾 - 基于KL散度的知識蒸餾 KL散度的方向
知識蒸餾 - 大語言模型知識蒸餾LLM-KD-Trainer 源碼分析 數據集處理
知識蒸餾 - 大語言模型知識蒸餾LLM-KD-Trainer 源碼分析 KnowledgeDistillationTrainer類
微調訓練時,ignore_empty_think是怎么保護模型的思考能力?
在對 Qwen3 進行微調訓練時,如何保護模型的思考能力?
模型的原始輸出為什么叫 logits




)

![crew AI筆記[3] - 設計理念](http://pic.xiahunao.cn/crew AI筆記[3] - 設計理念)
)
)
](http://pic.xiahunao.cn/使用 Conda 安裝 xinference[all](詳細版))

:脫圍機制一)


)




