摘要
【關鍵詞】
第一章 緒論
1.1 研究背景及意義
1.2 國內外文獻綜述
1.2.1 國外研究結果
1.2.2 國內研究結果
1.3 本課題主要工作
第二章 相關工作介紹
2.1文本量化方法
2.2 CNN、LSTM模型
2.3評測準確率及收益率
第三章 開發技術介紹
3.1 系統開發平臺
3.2平臺開發相關技術
3.2.1 Python技術
3.2.2 Mysql數據庫介紹
3.2.3 ?Mysql環境配置
3.2.4 ?B/S架構
3.2.5 ?Django框架
第四章 系統分析
4.1 可行性分析
4.1.1?技術可行性
4.1.2?操作可行性
3.1.3經濟可行性
4.2性能需求分析
4.3非功能性需求
第五章 系統設計
6.1功能結構
6.2?數據庫設計
6.2.1 數據庫E/R圖
6.2.2?數據庫表
第六章 系統功能實現
6.1?用戶登錄
6.2用戶管理
6.3?管理員管理
6.4股票列表
6.5 綜合數據
6.6?模型配置
第七章 系統測試
第八章 總結
8.1 總結
8.2 展望
致 ?謝
參考文獻
股市的漲跌變化及價格預測一直都是一個火熱的話題,以往機器學習剛興起時,便被用于股市預測的研究當中。而隨后來機器學習縱向發展,引發了深度學習的出現及興起,針對國內股市,量化交易較為火熱,但在國內學術上此方面的研究還較少,于是本文提出并實現了結合及股市歷史的CNN及LSTM預測模型,以深度學習方法來挖掘股市變化的規律,并分析是否能預測其變化。本研究主要內容有:(1)獲取2019.01-2023.12的內容,及相關股票在該期間的歷史數據,以此為基礎構建出多種不同的訓練集,如:CNN的新聞標題word2vec訓練集、新聞關鍵詞word2vec訓練集、新聞關鍵詞百度指數訓練集、新聞傾向值及股市數據訓練集;LSTM的股市數據訓練集、百度指數加股市數據訓練集、新聞傾向加股市歷史訓練集;(2)針對CNN的兩類訓練集,構建出文本量化預測模型和純數值預測模型;LSTM構建出一種預測模型。對其分別從模型參數、學習率、訓練次數、loss公式等方面進行優化,提高預測準確率和收益率;(3)依據集成學習方法,把本研究中所提出的模型構成一個集成模型,以得到一個總模型,并以十折十次交叉驗證法測試所有模型的準確率及收益率。從研究結果來分析,深度學習結合和股市歷史數據來預測股市未來變化有一定的準確性,為研究股市變化的內在規律提供了一定的幫助。
第一章 緒論
伴隨科技發展,人們通過各種軟件來進行股票交易,同時,在股市交易當中,出現了基本分析、技術分析、演化分析等分析方法。近年來,計算機領域快速發展,機器學習、深度學習等技術興起,也使得量化投資變得越來越火熱,人們相信他們能通過機器找出股市的內在關系并以此獲利。
人們每天通過交易軟件頻繁地進行買入賣出,由此,股票價格也會一直在變化,并且會產生海量的交易數據。投資者在投資股票時,越來越把這些數據作為重要的參考依據,能用其畫出各種各樣的K線及結合各種理論來得出買入賣出點,這也即是技術分析。
新聞對股市有一定影響,尤其是,這是投資者了解所購股票的公司經營狀況的主要手段,其能影響投資者的交易意愿。這些的報道往往包含有上市公司的戰略決策、經營狀況、財務報告等等,這些資訊對投資者選擇投資時機及研究市場走勢都起到了重要的作用,這也即是基本分析。
內容中通常包含大量有價值的信息,其與股市歷史數據有一定的關聯,應當用更為先進的方法來挖掘。在國內學術中,早在2012年便有人以機器學習方法去挖掘新聞中內容,證實新聞對股市有較強的影響[1]。而在國外,更早一點學者們便已對金融市場中的三種人工智能技術,即人工神經網絡,專家系統和混合智能系統進行了比較研究,?表明這些人工智能方法的準確性優于以傳統統計方法處理財務問題[2]。
在2023年10月,全球第一只應用人工智能、機器學習進行投資的ETF:AI-powered Equity?ETF被推出。它利用了相關數學方法,每天24小時不停地去處理上百萬條企業公告及新聞,以此不斷優化自身的模型。但從下圖1中可看出,該ETF從17年10月到18年4月仍出現了不少的大起大落,半年時間其股價總增長率為6.81%。而美股標準普爾500指數從2562.87上升到2670.29,增長率為4.19%,表明這AI-ETF整體上要好于市場,但其仍有不少錯誤的時候,仍需要進行一定的沉淀及發展。實際上在國內的眾多量化投資平臺上,也有多個不同的看似優秀的預測模型、交易策略,但往往這些模型的策略回測結果都很漂亮,但用于實戰時卻不盡人意。
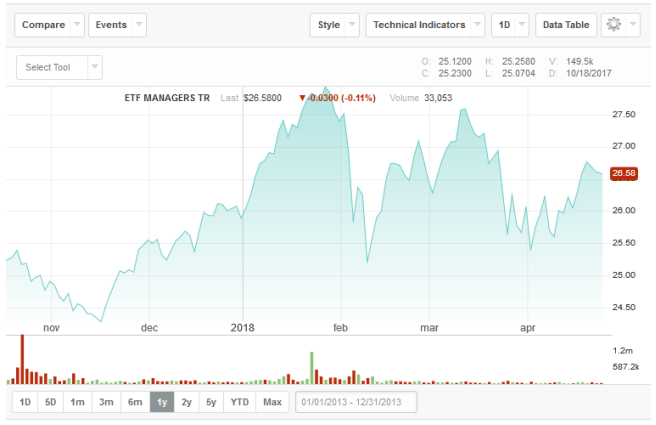
圖1-1?AI-powered Equity ETF從2023/10/18-2023/04/23走勢圖,圖片來源[3]
現在深度學習也已經被用于股市投資當中。深度學習神經網絡是一個高度復雜的非線性人工智能系統,是對人腦抽象和具象能力的人工模擬,其具有自組織及自調整等能力,適合處理多影響因素、類隨機的復雜非線性難題。同時,利用神經網絡方法能把內容進行數值量化,化為一個個詞語矩陣,現在已有較為成熟的方法,如:Word2Vec。由此,把新聞文本內容量化后,便可將其加入到深度學習神經網絡中訓練。
而CNN和LSTM作為新型神經網絡,各自有其特性。CNN可訓練新聞文本轉換成數值矩陣后的數據集;而LSTM具備時序觀念,可以依照時間序列實現多個輸入輸出,訓練具有時序屬性的數據,且其通過記憶門解決了梯度消失問題。
以此,通過結合與股市歷史數據,把深度學習應用在股市變化的分析中,以對股市的變化進行預測,依據預測結果制定交易策略,計算收益率,分析內在規律,為以深度學習方法結合和股市歷史應用于國內股市的預測分析提供一定的理論與實踐價值。
Nassirtoussi AK等學者基于金融新聞的標題來預測外匯市場中金額的日內變動[4],其實現了一種多層算法:第一層為語義抽象層,解決了文本挖掘中共同參考的問題;第二層為情感積分層,提取情緒權重;第三層為同步目標特征減少(STFR)的動態模型創建算法,使用了機器學習中的三個算法,分別為SVM、K-NN和樸素貝葉斯方法,準確率頗高,在分析傳統機器學習于股市預測中的應用有一定參考性。
而Maragoudakis M等學者使用了馬爾科夫鏈蒙特卡羅(MCMC)貝葉斯推理方法[5],估計了通過樹增強樸素貝葉斯(TAN)算法獲得的網絡結構的條件概率分布,來對股市進行預測。
而Vargas MR等人在2023年采用深度學習方法,以金融新聞標題和一套技術指標作為輸入,對標準普爾500指數進行了當日漲跌預測[6]。其重點研究了卷積神經網絡(CNN)和遞歸神經網絡(RNN)的結構,構建了RCNN模型且與其它文獻中的預測模型進行比較,研究結果顯示CNN在捕捉文本語義方面優于RNN,而RNN在捕捉上下文信息和以復雜時間特征建模來進行股市預測中更優,并且RCNN模型要優于其它模型。
也有學者使用高頻盤中股票的收益率作為輸入數據,研究了三種無監督特征提取方法(主成分分析,自動編碼器和受限波爾茲曼機)對網絡預測未來市場行為的整體能力的影響[7]。實證結果表明,深層神經網絡可以從自回歸模型的殘差中提取附加信息,提高預測性能。
國外相關文獻,多是以是美國的股票市場作為研究目標的。基于以中國為代表的發展中國家的股票市場,國外學者的研究中較少涉及。
國內學者們更加傾向以一部分新聞財經內容或評論來量化為特征向量去預測股市的漲跌。
孟雪井[8]等學者在2016年時選取了國內9大財經網站爬取新聞作文本挖掘,然后從中獲取出關鍵的詞語,隨后以這些詞語去關聯百度指數作為特征向量,以隨機森林算法去選擇重要特征,再以KNN算法去預測股市大盤指數漲跌。
同在2016年,鄒海林使用 Adaboost結合決策樹算法訓練漲跌預測模型,其使用最近鄰回歸k-NN方法對股市收盤指數和漲幅進行回歸結果分析,并對各種 HICT 詞特征選擇方法實驗結果進行比較[9]。其在文本詞語的處理上做出了較多的研究,使文本預測股市應用有一定的進展。
另外,孫瑞奇分析了BP、RNN、LSTM三種神經網絡的區別并以LSTM神經網絡對美股進行短期預測的可行性并作出相應對比,研究預測模型準確性[10]。其對2013年至2015年的美股股指進行預測,誤差均值在1%以內,而對中國的上證指數預測時,誤差在8.66%左右,故其認為預測中國股市時,需加入一些內容作輸入特征,才能有效把誤差減小。
本課題的主要目的是預測股市中個股在未來交易日的漲跌情況,以獲取收益,故希望能獲得較高的預測準確率及收益率。
經過了解、思索以及結合股市預測這一主題后,決定選用CNN和LSTM這兩種深度學習算法來研究預測情況。本文主要解決的問題包括把的標題和內容以機器學習、百度指數和傾向詞典等方法量化,結合股市歷史數據組合成各種不同的訓練集,建立CNN對文本矩陣及數值的兩種輸入數據的預測模型和LSTM對文本量化值這一種數據的預測模型,預測出股市中單個股票的未來漲跌情況(收盤價格漲跌情況),并以此設定交易策略,獲取收益(計算出收益率)。
對其分析得出和股市歷史數據在深度學習應用下對國內股市預測所能提供的幫助,為對國內股市的研究預測提供一定的參考。
第二章 相關工作介紹
2.1文本量化方法
一般需要把文本量化為數值數據,才方便用于進行模型輸入。而從Deep learning for stock market prediction from financial news articles[7]一文中了解到,對于新聞文本的量化處理有各種各樣的方法,得到各種各樣量化后的數據,如:單詞嵌入向量、句子嵌入向量、事件嵌入向量、詞袋、結構化事件元組等。
而在這里參考了多篇相關文獻的常用方式,及針對國內股市這一問題背景,提出了四種文本量化方法。
一為量化新聞標題為詞語向量;二為以TF-IDF方法提取出每篇新聞中的關鍵詞,然后將其量化為詞語向量;三為以TF-IDF方法提取出每篇新聞中的關鍵詞,然后以相關權重計算方法,得出一定數量的新聞集關鍵詞語,去獲取百度指數,即把新聞集量化為百度指數;四為利用相關數學公式去處理新聞集中詞語的詞頻,量化為漲跌傾向值。
2.2 CNN、LSTM模型
CNN(卷積神經網絡):
CNN一般用來處理圖像任務,其卷積、池化操作能夠提取出圖像中各種不同的特征,并最終通過全連接網絡實現信息的匯總及輸出。在文本處理中,由于句子長度較短,且能獨立表達意思,使得CNN也能較好地處理這些文本內容[11]。
CNN模型在結構上一般包括有4個部分,下圖2-1為處理詞向量訓練集的CNN基本模型結構:
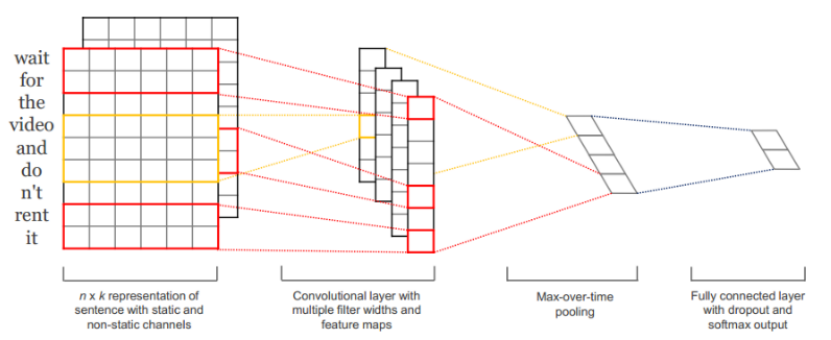
圖2-1 處理詞向量的CNN模型基本結構,圖片來源[11]
1、輸入層:
在文本處理中,輸入層是文本詞語對應的詞向量從上到下排列的矩陣,假設文本m個詞,詞向量長度為l,那么這個矩陣就是m*l(可看作一副為m*l大小的圖像)。對于未知詞語,其向量可用相關默認值來填充。
2、卷積層:
卷積層通過卷積操作得到若干個特征圖,卷積窗口的大小為n*l,其中n表示詞語的個數,而l表示詞向量的維數。通過這樣的卷積操作,將得到若干個列數為1的特征圖(一般同時會有多個不同大小的卷積窗口,來提取出不同的特征)。
3、池化層:
接下來的池化層,一般使用取最大值(其代表著最重要的信號)的方法來處理特征圖,故也稱最大池化層。這種池化方式可以解決可變長度的句子的輸入問題,最終池化層的輸出為各個特征圖的最大值們,即一個一維的向量。
4、全連接+softmax層:
池化層的一維向量的輸出通過全連接的方式,連接一個Softmax層,來獲得輸出(通常反映著最終類別上的概率分布)。
在此中間,卷積層和池化層可擁有多層,這些卷積池化層可以是同級的,即使用多個不同大小的卷積核及池化層去卷積并池化數據,獲得多種不同的特征并拼接起來,再進行下一層處理;或是在一次卷積池化結束后,對得到的特征圖再進行卷積池化,即特征多次提取,縮減單元數。
參考基于卷積神經網絡的互聯網短文本分類方法[12]一文中的流程模型圖,及基于文本量化情況、輸入數據集結構,構建了兩種CNN預測模型。分別處理文本型(詞向量)數據集(新聞標題訓練集和新聞關鍵詞訓練集)和數值型數據集(新聞百度指數數據集和新聞漲跌傾向數值及股市歷史數據集)。
同時,從卷積層數量、卷積窗口大小、多重卷積、特征拼接、全連接層數量等方面進行調優。
LSTM(長短時序記憶網絡)
實際上LSTM的發展是有一個演變過程的,其演變順序為BP神經網絡(反向傳播神經網絡)-> RNN(循環神經網絡)->?LSTM(長短時序記憶網絡)。在每一個演變階段,其保留前一階段的特性同時還會針對于各種缺陷進行改進,于是本實驗中直接采用LSTM應用于股票預測,LSTM的基本結構[10]可見圖2-2。
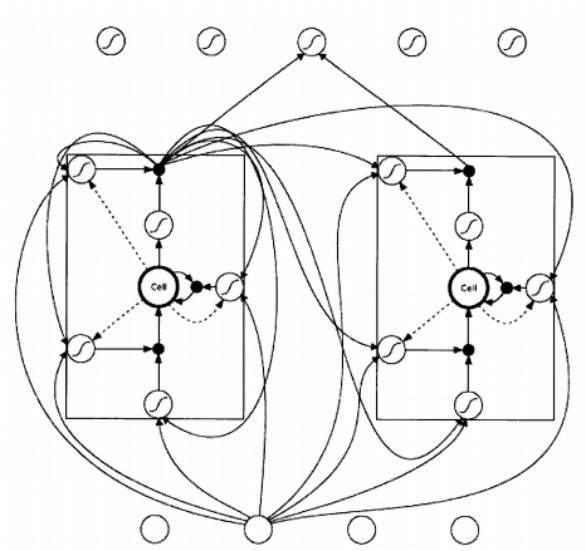
圖2-2 LSTM基本結構,圖片來源[10]
傳統BP神經網絡模型是由輸入層、隱藏層和輸出層組成,其中隱藏層包含一層或多層。數據從輸入層輸入,然后通過全連接向隱藏層傳遞下去,最后傳導到輸出層,其通過一層層反饋傳遞修正權值,從而調整整個神經網路。而其不足在于,其在訓練的過程中并未體現先后時序關系,所以每次神經元權值的修正均只是基于單條數據的影響,沒有時序概念。這在股票價格預測中理論上具有極大的缺陷。
隨后因相關應用需要,RNN出現,其通過添加跨越時間點的自連接隱藏層而具有對時間進行顯式建模的能力。即隱藏層的反饋,除了進入輸出端,還進入了下一時間步的隱藏層,從而影響下一個時間步上的各個權值。而其主要缺陷在于隨著神經網絡層數的增加,會出現梯度消失的問題。
LSTM應運而生,它主要是給每個單元增加了記憶單元,這些記憶單元的入口主要由三個門控制著,分別是輸入門、忘記門和輸出門,操作功能有保存、寫入和讀取。這些門都是邏輯單元,用選擇性記憶反饋的誤差函數來隨著梯度下降修正參數,根據反饋的權值修正數來選擇性遺忘和部分或全部接受,這樣就不會每個神經元都得到修改了,從而使梯度不會多次消失,這樣前面幾層的權值也可以得到相應的修改,同時使誤差函數隨梯度下降得更快。
調整LSTM隱藏層數、記憶單元門控遺忘概率,能使模型獲得更好的效果。
集成模型:
????最后對于所提出的所有模型,結合集成學習方法,將它們組成一個集成模型,主要使用結合策略中的學習法,來生成最終模型。
2.3評測準確率及收益率
利用各模型對于個股的漲跌進行預測,以預測結果為依據,來按照同樣的交易策略進行交易,計算出預測的準確率及收益率。
其中使用十折十次交叉驗證法來評測模型在準確率、收益率上的效果。十折十次交叉驗證法,即在十折交叉驗證(數據處理形式如圖2-3)基礎上,對于每一折的數據進行十次訓練得到十次預測結果。這樣一來,即一個模型對于一個數據集需進行10*10次訓練,得到上百次預測結果、準確率及收益率。
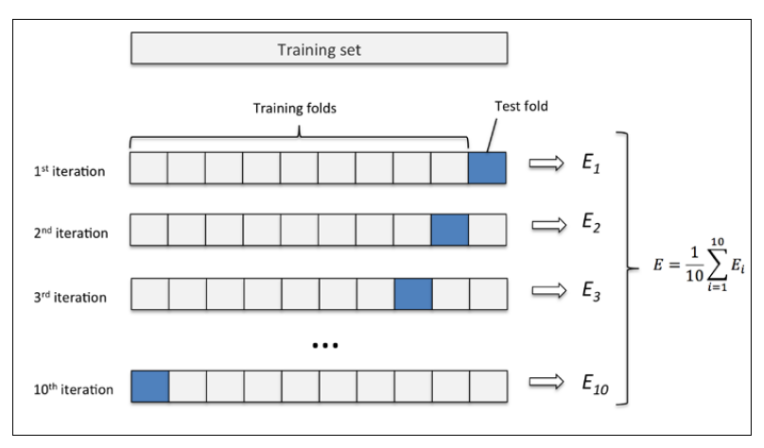
圖2-3 十折交叉驗證法,圖片來源[13]
通過這種做法,能得出各模型的泛化結果,較好地評測各模型的真實效果。
第三章 開發技術介紹
此系統的關鍵技術和架構,Python技術、B/S結構、Django框架和Mysql數據庫,是本系統的關鍵開發技術,對系統的整體、數據庫、功能模塊、系統頁面以及系統程序等設計進行了詳細的研究與規劃。
3.1 系統開發平臺
在該在線股票量化分析系統中,Eclipse能給用戶提供更多的方便,其特點一是方便查詢股票信息,方便快捷;二是有非常大的信息儲存量,主要功能是用在對數據庫中查詢和編程。其功能有比較靈活的數據應用,只需利用小部分代碼就能實現非常強大的功能。因此,利用Eclipse 技術進行系統代碼管理是該系統數據庫的首選。
3.2平臺開發相關技術
3.2.1 Python技術
Python?是一個高層次的腳本語言結合了解釋性、編譯性、互動性和面向對象的。Python?的設計,相比其他語言經常使用英文關鍵字和其他語言的一些標點符號,它具有比其他語言更有特色語法結構,具有很強的可讀性。
解釋型語言:類似于PHP和Perl語言,這意味著開發過程中沒有了編譯這個環節。
交互式語言:可以在一個 Python?提示符 >>>?后直接執行代碼。
面向對象語言:Python支持面向對象的風格或代碼封裝在對象的編程技術。
3.2.2 Mysql數據庫介紹?
利用Mysql的數據獨立性、安全性等特點,在軟件項目中對數據進行操作,可以保證數據準確無誤,并降低了程序員的應用開發時間。
Mysql的特點是支持多線程,能方便的對系統資源充分利用,有效提高速度,還提供多種方式途徑來對數據庫進行連接;Mysql的功能相對弱小、規模也小,但本系統要求不高,Mysql完全可以滿足本系統使用。
利用Mysql建立系統數據庫,不僅有利于數據處理業務的早期整合,還能利于發展后兩種數據擴展的操作。
3.2.3 ?Mysql環境配置
本系統的數據使用的是Mysql,所以要將Mysql安裝到指定目錄,如果下載的是非安裝的Mysql壓縮包,直接解壓到指定目錄就可以了。然后點擊C:\Program Files\Mysql\bin\winMysqladmin.exe這個文件其中C:\Program Files\Mysql是Mysql安裝目錄。輸入winMysqladmin的初始用戶、密碼(注:這不是Mysql里的用戶、密碼)隨便填不必在意,確定之后右下角任務的啟動欄會出現一個紅綠燈的圖標,紅燈亮代表服務停止,綠燈亮代表服務正常,左擊這個圖標->winnt->install the service 安裝此服務,再左擊這個圖標->winnt->start the service 啟動Mysql服務。
修改Mysql數據庫的root密碼。用cmd進入命令行模式輸入如下命令:
cd C:\Program Files\Mysql\bin
Mysqladmin -u root -p password 123
回車出現Enter password: ,這是要輸入原密碼. 剛安裝時密碼為空,所以直接回車,此時Mysql?中賬號 root 的密碼被改為 123 安裝完畢。
3.2.4 ?B/S架構?
B/S結構是目前使用最多的結構模式,它可以使得系統的開發更加的簡單,好操作,而且還可以對其進行維護。使用該結構時只需要在計算機中安裝數據庫,和一些很常用的瀏覽器就可以了。瀏覽器就會與數據庫進行信息的連接,可以實現很多的功能,B/S結構是可以直接進行使用的,而且B/S結構在使用中極大的減少了工作的維護。基于B/S的軟件,所有的數據庫之間都是相互獨立的,因此是非常安全的。因為基于B/S結構可以清楚的看到系統正在處理的業務,并且能夠及時的讓管理人員做出決策,這樣就可以避免學校的損失。B/S結構的基本特點是集中式的管理模式,用戶使用系統生成數據后,這些數據就可以存儲到系統的數據庫中,方便日后能夠用到,這樣就可以滿足人們的所有的需求。
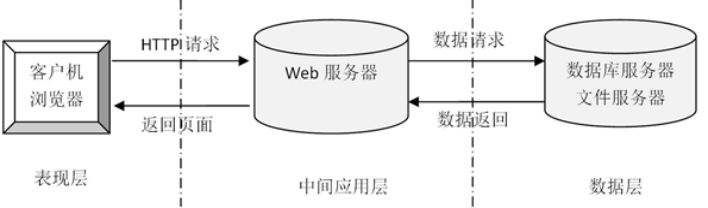
圖2-1 ?B/S模式三層結構圖
3.2.5 ?Django框架
Django是一種開源的大而且全的Web應用框架,是由python語言來編寫的。他采用了MVC模式,Django最初是被開發來用于管理勞倫斯出版集團下的一些以新聞為主內容的網站。一款CMS(內容管理系統)軟件。并于 2005 年 7 月在 BSD 許可證下發布。這套框架是以比利時的吉普賽爵士吉他手 Django Reinhardt 來命名的。
Django是Python語言中的一個web框架,并遵循MVC設計。Python語言中主流的web框架有Django、Tornado、Flask 等多種,Django相較與其它WEB框架,其優勢為:大而全,框架本身集成了ORM、模型綁定、模板引擎、緩存、文件管理、認證權限Session等功能,是一個全能型框架,擁有自己的Admin數據管理后臺,第三方工具齊全,性能折中。Django的主要目的是簡便、快速的開發數據庫驅動的網站。?
)

![crew AI筆記[3] - 設計理念](http://pic.xiahunao.cn/crew AI筆記[3] - 設計理念)
)
)
](http://pic.xiahunao.cn/使用 Conda 安裝 xinference[all](詳細版))

:脫圍機制一)


)








