論文:
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
作者對傳統CoT方法和本文提出的CoT Prompting的區分。
1. 傳統方法的局限性
(1) 基于微調的CoT(Rationale-Augmented Training)
- 實現方式:需人工標注大量〈輸入,推理鏈,輸出〉三元組,然后微調模型
# 訓練數據示例(需人工編寫) {"input": "小明有5個蘋果,吃了2個,還剩幾個?","rationale": "初始5個 - 吃掉2個 = 剩余3個", # 人工撰寫成本高"output": "3" } - 限制:
- 標注成本:撰寫高質量推理鏈比單純標注答案昂貴10-20倍(論文數據)
- 泛化性差:每個新任務都需要重新微調
(2) 傳統Few-Shot Prompting
- 典型結構(Brown et al., 2020):
輸入: "3個蘋果每個2元,總價多少?" 輸出: "6元"輸入: "火車2小時行駛240公里,時速多少?" 輸出: "120公里/小時"輸入: "問題..." # 測試樣本 - 缺陷:
- 僅展示輸入-輸出對,缺乏推理過程示范
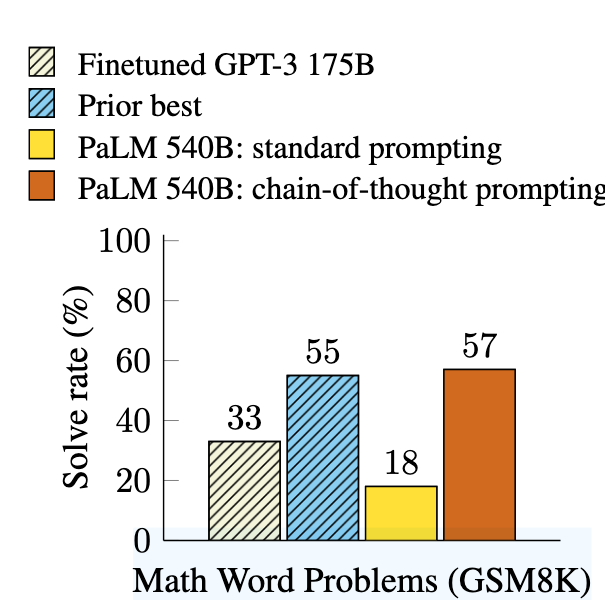
- 在GSM8K數學題測試中,540B參數模型準確率僅17%(對比CoT Prompting的56%)
2. 本文創新:Chain-of-Thought Prompting
核心突破
通過提示工程而非微調,直接激發模型的推理能力:
輸入: "小明有5個蘋果,吃了2個,還剩幾個?"
思考: 初始5個 - 吃掉2個 = 剩余3個
輸出: "3"輸入: "一個書包原價80元打7折,現價多少?"
思考: 80元 × 0.7 = 56元
輸出: "56元"輸入: "問題..." # 測試樣本
技術差異
| 維度 | 傳統微調CoT | 本文CoT Prompting |
|---|---|---|
| 是否需要訓練數據 | 需大量標注三元組 | 僅需3-5個示范樣例 |
| 模型修改 | 需任務特定微調 | 同一模型參數處理所有任務 |
| 推理鏈來源 | 依賴標注數據 | 模型自動生成 |
| 計算成本 | 高(每次任務需微調) | 零(僅推理) |
3. 為什么Prompting版CoT更優?
(1) 數據效率
- 傳統方法:需5000+標注樣本才能微調出可用模型(Cobbe et al., 2021)
- 本文方法:僅需8個示范樣例即可達到SOTA(GSM8K上56%準確率)
(2) 涌現能力
-
參數規模效應:當模型 > 100B參數時,CoT Prompting效果突然提升(見論文中的圖2,如下)
-
傳統Few-Shot:模型增大后性能提升平緩
(3) 任務泛化
- 統一框架:同一組提示模板可處理算術/常識/符號推理
- 傳統方法:每類任務需獨立微調
4. 案例驗證
GSM8K數學題測試:
- 標準Prompting:
輸入: "農場有15只雞和8頭牛,共有多少條腿?" 輸出: "46" # 錯誤(未展示計算過程) - CoT Prompting:
輸入: "農場有15只雞和8頭牛,共有多少條腿?" 思考: 雞腿=15×2=30,牛腿=8×4=32,總腿數=30+32=62 輸出: "62" # 正確
結果:準確率從17% → 56%(540B參數模型)
5. 本質創新點
作者并非發明CoT概念,而是發現了:
- 無需微調:通過精心設計的提示模板即可激發模型固有推理能力
- 規模效應:超大模型(>100B)在少量示范下能自主生成高質量推理鏈
- 通用接口:〈輸入,思考鏈,輸出〉三元組作為跨任務統一范式
這種方法的革命性在于:將推理能力從模型訓練階段解耦,轉變為提示工程問題,使單個預訓練模型能零樣本處理復雜推理任務。

![[深度學習] 大模型學習4-RAG技術全景解析](http://pic.xiahunao.cn/[深度學習] 大模型學習4-RAG技術全景解析)

)
)




、隨機搜索)


)

)




