在大語言模型基礎知識一文中,檢索增強生成(Retrieval-Augmented Generation,簡稱 RAG)技術作為構建大語言模型(Large Language Model,簡稱 LLM)應用的一種方式已被簡要提及,本文將詳細介紹RAG技術的實現流程及其演進趨勢。
關于RAG技術更全面更系統的介紹,可以閱讀以下論文:
- Retrieval-Augmented Generation for AI-Generated Content: A Survey
- Retrieval-Augmented Generation for Large Language Models: A Survey
文章目錄
- 1 RAG技術解析
- 1.1 RAG技術的重要性
- 1.2 RAG系統簡介
- 1.3 RAG系統工作流程詳細介紹
- 2 RAG技術演進趨勢和常見問題
- 2.1 RAG技術優化與演進趨勢
- 2.1.1 RAG技術增強路徑
- 2.1.2 RAG系統實現模式的演化
- 2.2 RAG技術典型問題與優化方案
- 2.2.1 RAG技術常見問題及解決辦法
- 2.2.2 RAG系統固有挑戰
- 2.2.3 RAG技術與模型指令微調的對比
- 3 實戰
- 3.1 RAG系統示例代碼
- 3.2 主流開源RAG框架概覽
- 4 參考
1 RAG技術解析
1.1 RAG技術的重要性
僅依賴LLM的局限性
盡管LLM的參數規模與訓練數據量顯著增長,使其在自然語言處理任務中的能力快速提升,但模型的知識記憶能力仍受限于架構與訓練范式。由于通常需要預訓練數據對同一知識點進行多次曝光才能實現有效記憶,導致其記憶效率偏低,且難以全面覆蓋各領域知識。
更核心的局限在于,LLM的性能高度依賴訓練階段接觸的靜態數據。這使其在處理實時更新信息(如最新科技、時事新聞)、長尾知識(即罕見或未納入訓練數據的內容)及動態變化內容時表現不佳,可能生成錯誤、不完整甚至虛構的信息,即出現 “幻覺” 問題。
此外,針對特定領域的復雜專業知識,LLM的處理效率與深度理解能力也顯不足。僅依靠模型無法動態訪問外部知識庫,這在需依賴精確、最新信息的場景(如問答、醫療診斷、法律咨詢、實時信息查詢等)中尤為受限。因此,如何克服對靜態數據的依賴、提升知識獲取的效率與實時性、減少幻覺現象并增強領域深度理解能力,已成為當前LLM發展面臨的關鍵挑戰。
RAG技術的誕生
為彌補LLM單獨使用時的局限性,檢索增強生成技術應運而生。其核心原理是融合“檢索”與“生成”:在接收用戶查詢時,系統先從外部大規模知識源(如文檔、數據庫)中動態檢索相關信息片段,再將這些片段作為附加上下文輸入生成模型,輔助其完成答案創作。借助這一機制,模型能夠生成更精準、可靠且貼合上下文的答案,不僅大幅提升了生成內容的準確性、相關性與實時性,有效緩解了“幻覺”問題,還增強了答案的可追溯性與可信度;同時,通過動態引入最新信息源,RAG技術顯著加快了知識更新效率。
此外,RAG技術賦予模型處理復雜任務的能力,例如串聯整合多步驟推理、融合不同領域知識等。以“近期哪個品牌的新款手機拍照功能最優”這一問題為例,其可快速調取最新測評文章,并基于這些內容給出詳盡解答,因此在需精準且及時信息的場景中優勢顯著。
簡言之,RAG技術是一種通過融入外部知識庫優化LLM性能的模式。關于RAG技術的起源可以參考RAG起源、演進與思考。
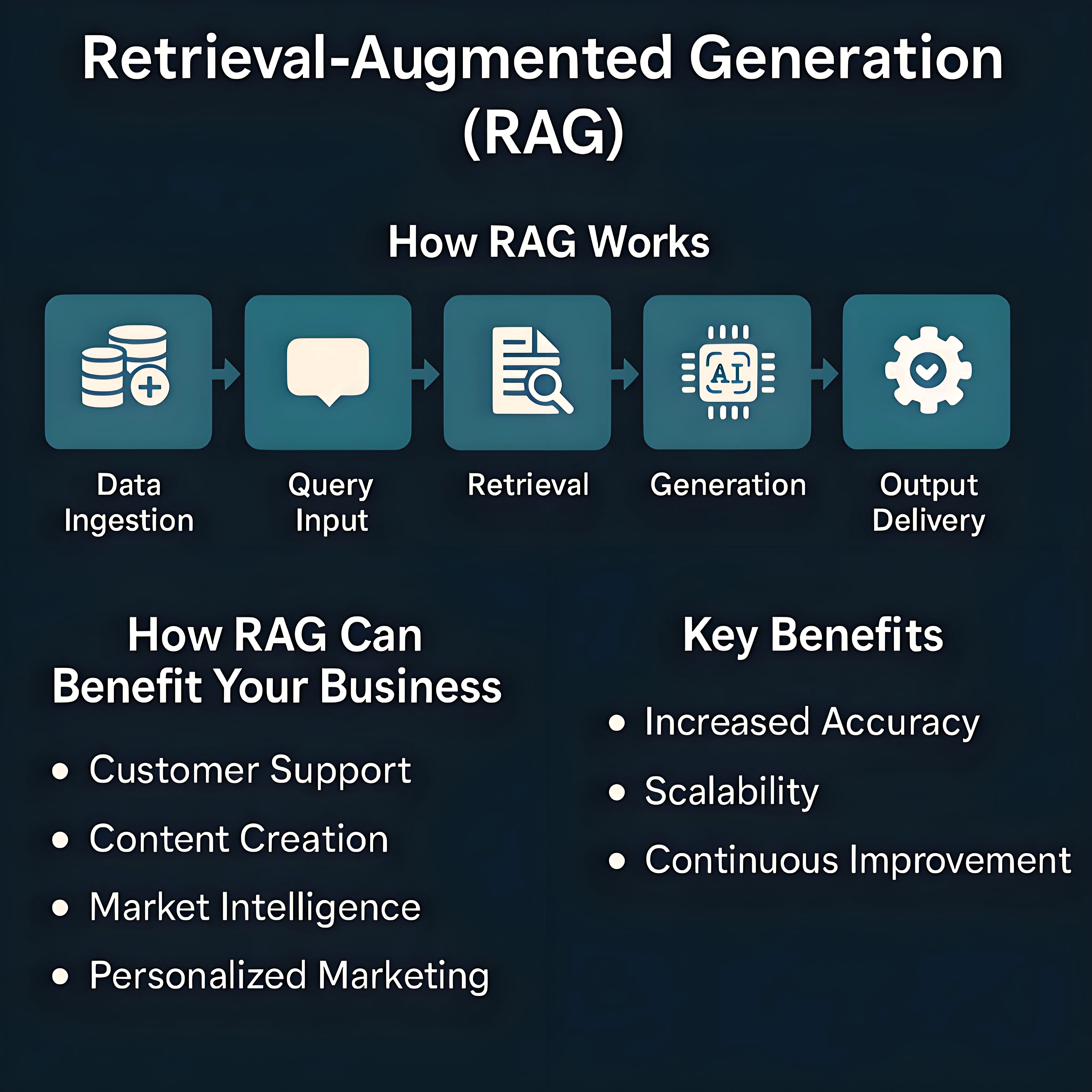
RAG技術的應用場景
RAG技術的核心優勢在于整合信息檢索與文本生成能力,有效突破了LLM在時效性與準確性不足等固有局限,憑借這一核心優勢,其應用已延伸至智能問答、文本摘要、對話系統、教育培訓、知識增強型問答與推理、個性化推薦及決策支持等多個領域。典型如:
- 在企業知識庫管理中,可快速定位內部文檔中的關鍵信息并生成結構化解讀,提升團隊協作效率;
- 在金融領域,能實時整合市場動態、政策變動等數據,為投資分析提供基于多源信息的趨勢預判;
- 在客服場景中,可結合用戶歷史交互記錄與產品知識庫,生成貼合需求的精準回復,優化服務體驗;
- 在科研領域,助力研究者整合跨學科文獻、實驗數據,生成具有針對性的研究思路與文獻綜述框架。
隨著LLM的興起,以RAG技術為核心驅動力的新一代智能搜索系統迅猛發展,深刻重塑著信息獲取模式。與傳統搜索引擎不同,微軟Bing Chat、百度文心一言等基于RAG的系統,不僅能更智能地理解用戶意圖,更能提供高度個性化、上下文關聯的交互體驗,其角色也從單純的信息檢索工具,演進為可直接輸出經信息整合與分析的精確答案的智能系統。
1.2 RAG系統簡介
RAG系統工作流程概覽
RAG系統的核心在于檢索與生成流程的深度融合,其核心邏輯是通過動態引入外部知識,大幅提升輸出內容的準確性與相關性。具體工作流程以用戶查詢為起點:首先,檢索模塊借助向量檢索等技術,將用戶查詢轉化為向量形式,從文檔庫、知識圖譜或搜索引擎等外部知識源中快速定位、篩選并提取高度相關的信息片段;隨后,以LLM為基礎的生成模塊會整合查詢內容與檢索到的上下文信息,經推理、整合與重組,最終生成連貫且精準的答案。
例如,當用戶詢問“2024年夏季奧運會的舉辦城市是哪里,有哪些特色比賽項目?”時,RAG系統會率先檢索2024年奧運會的相關資料,獲取舉辦城市為巴黎,以及新增的沖浪、滑板等特色項目,還有巴黎奧運會在塞納河舉辦公開水域比賽等信息。接著,將這些信息整合,生成“2024年夏季奧運會的舉辦城市是法國巴黎。該屆奧運會新增了沖浪、滑板等深受年輕人喜愛的項目”的回答。
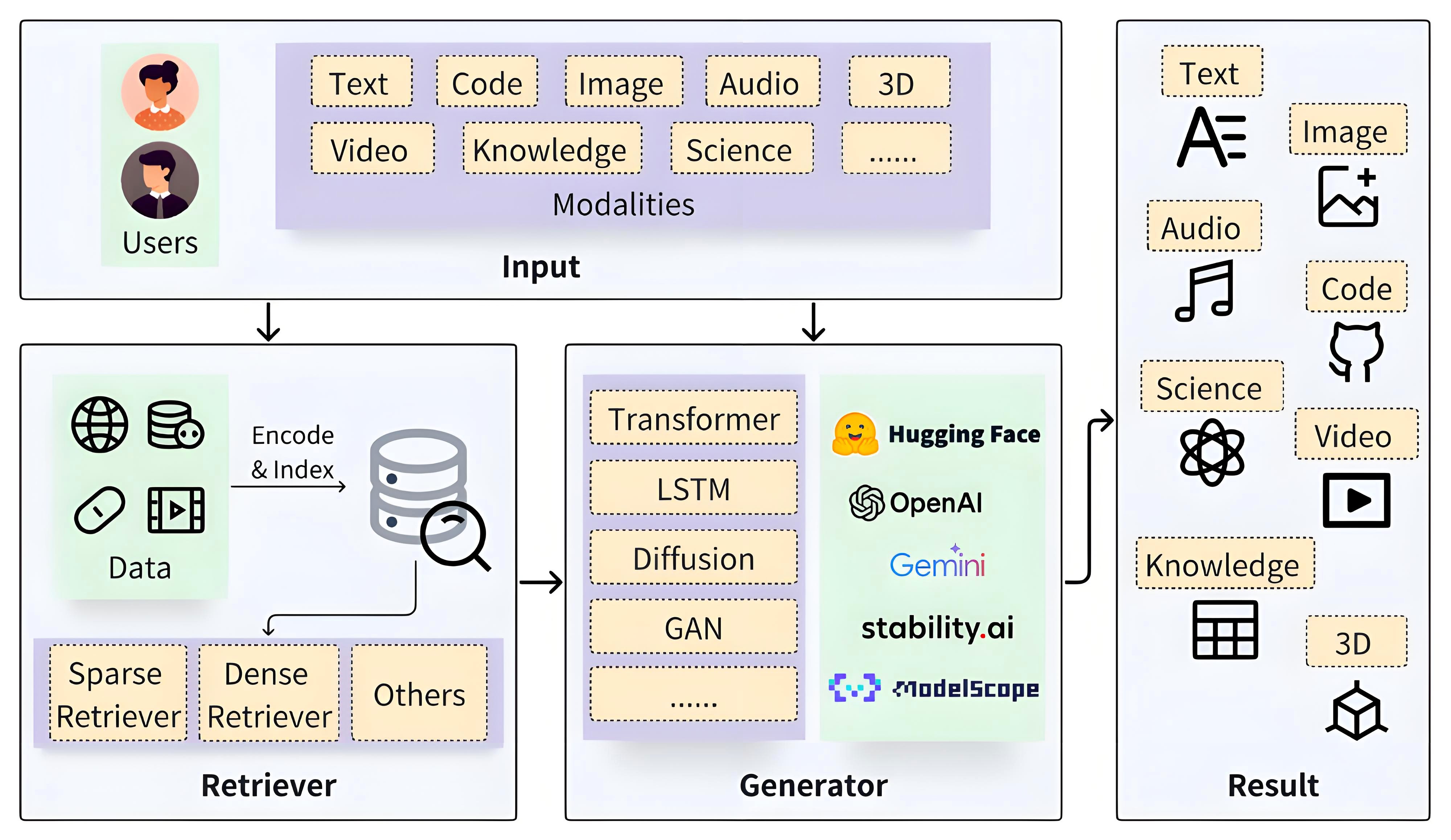
基礎的RAG系統
為清晰闡述RAG系統的基本原理與實現邏輯,本部分聚焦其核心流程(檢索+生成)的簡化模型展開說明。
RAG系統的核心機制是在生成答案前,先從知識庫中檢索相關信息,再以這些信息為依據引導生成過程。這一機制帶來多重優勢:既能顯著提升結果的準確性與相關性,有效緩解模型幻覺問題;又能通過僅更新知識庫即可納入新知識(無需重新訓練模型),實現快速迭代;同時增強結果可追溯性,大幅提升大模型應用的可靠性與實用性。基礎RAG系統更加詳細介紹可以參考:RAG到底咋工作的。
一個基礎的RAG系統通過以下核心模塊協同實現上述流程:
- 文檔處理模塊:負責加載文章、書籍、對話、代碼等各類原始文本,并將其切分為便于處理的片段。切分通常以句子為單位,且會特意保留片段間的部分重疊內容。此舉可避免語義被生硬割裂,從而提高后續檢索準確性。
- 向量編碼器:借助Embedding模型將文本片段轉化為向量。通俗而言,就是將文字“翻譯”為計算機可理解的數字向量,使文本語義轉化為可計算的數值特征。
- 向量數據庫:作為專門存儲文檔片段及其對應向量的載體,在文本切分與向量編碼完成后,會集中存儲這些數據,為后續快速檢索奠定基礎。
- 檢索器:作為連接用戶查詢與數據庫的“橋梁”,接收用戶查詢(Query)后,通過計算查詢向量與數據庫中向量的相似度,快速定位最相關的文檔片段。
- LLM:以檢索到的相關文檔片段為上下文,結合自身語言理解能力生成貼合用戶需求的自然語言答案,最終實現“基于事實的智能回答”。
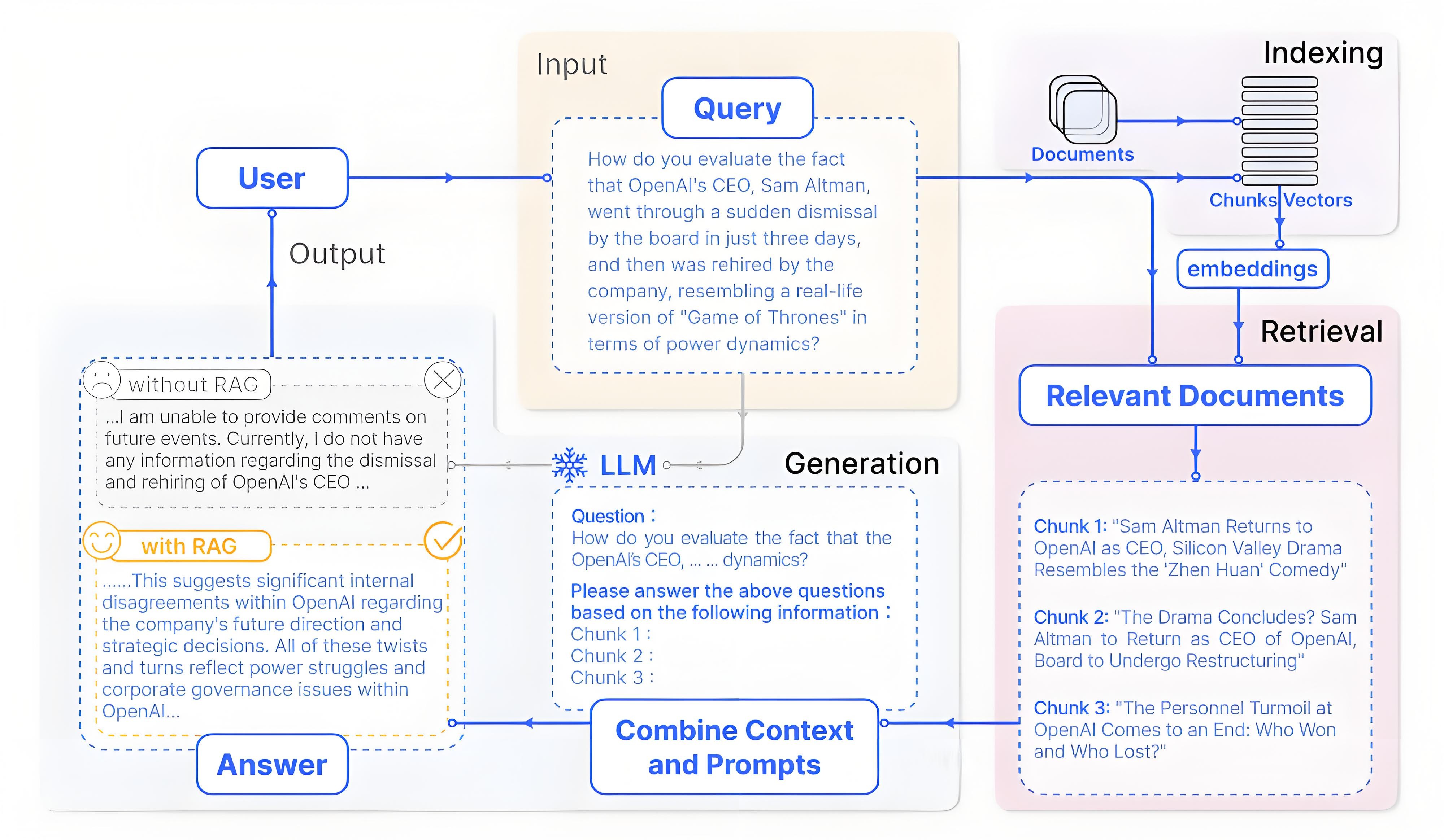
上述模塊的協作可梳理為RAG的基礎流程,即索引、檢索、生成三個核心環節,各環節與模塊的對應關系如下:
- 索引:借助文檔處理模塊、向量編碼器、向量數據庫,將文檔庫分割為較短片段,再通過編碼器構建向量索引。
- 檢索:依托上述三者,根據問題與片段的相似度檢索相關文檔片段。
- 生成:由LLM以檢索到的上下文為條件,生成問題的回答。
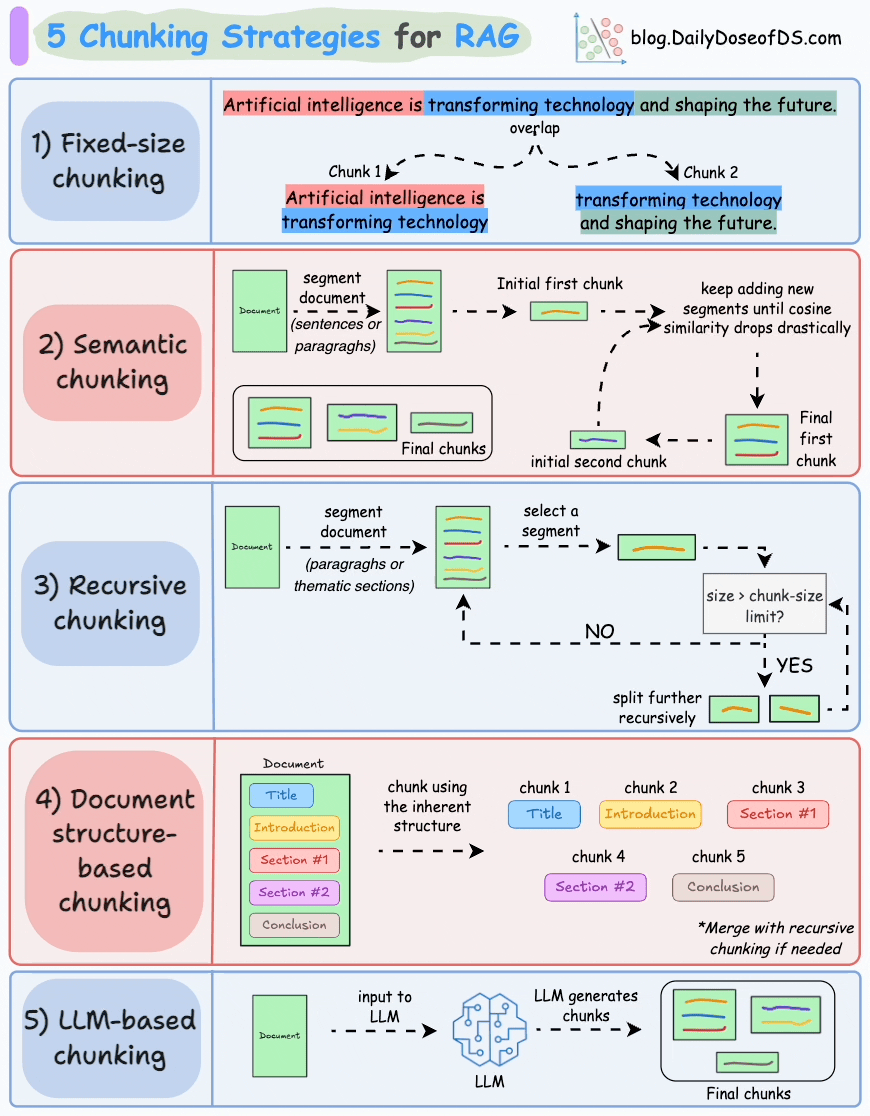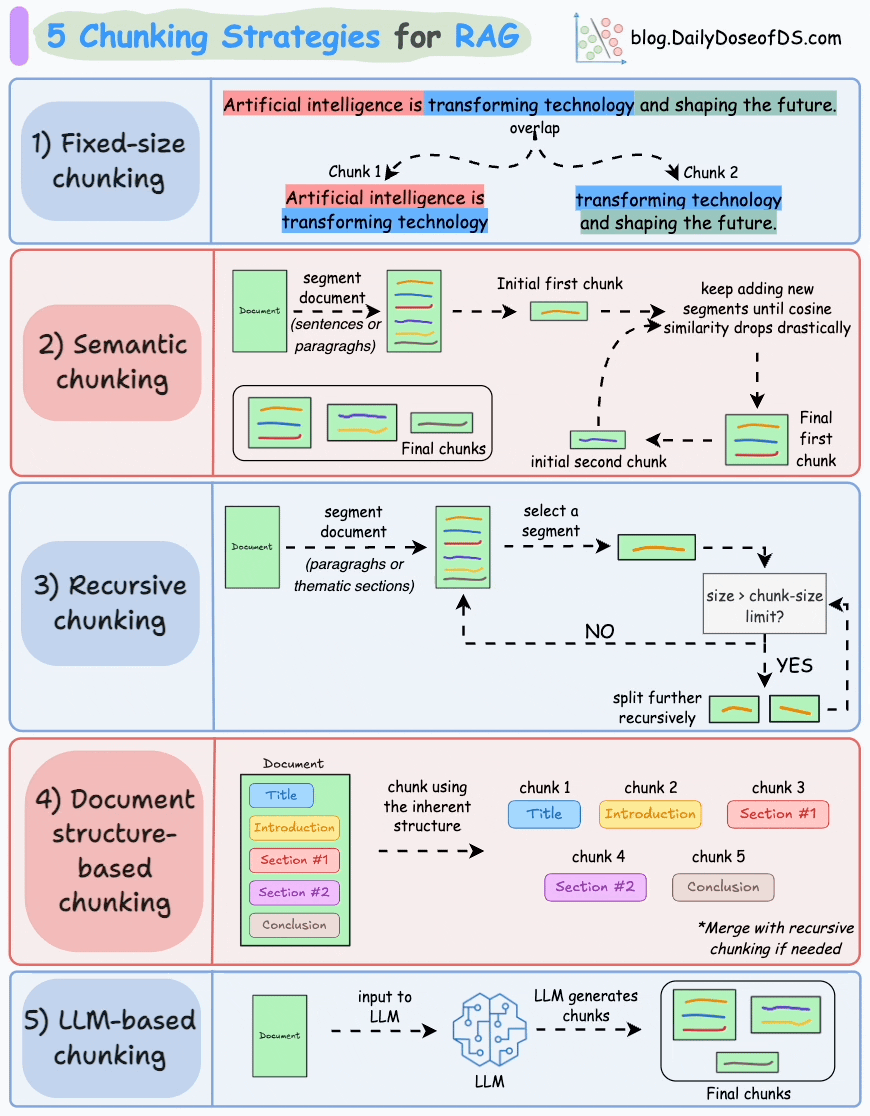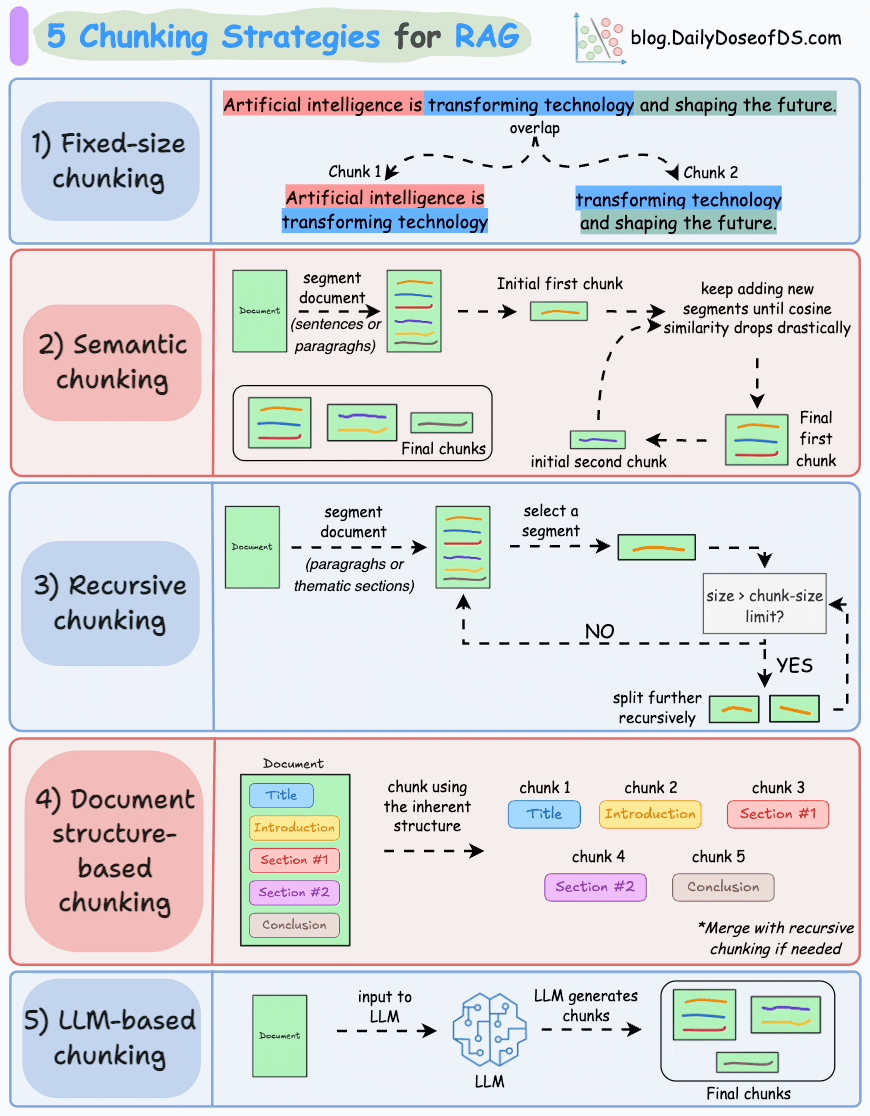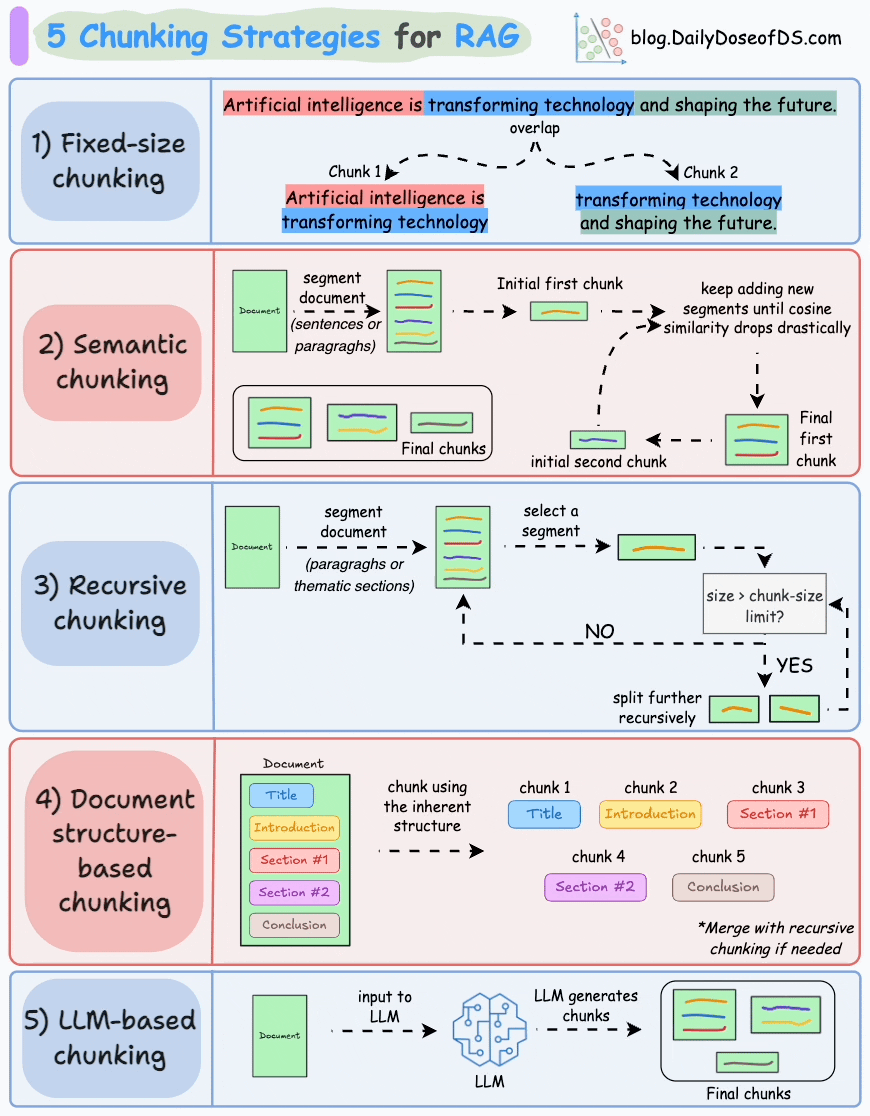
1.3 RAG系統工作流程詳細介紹
本節主要在1.2節基礎上詳細介紹RAG系統的工作流程,相關內容更加詳細的介紹可以見:16 Techniques to Supercharge and Build Real-world RAG Systems。
1.文本分段
文檔處理模塊首先將外部文檔拆分為文本片段,目的是避免因文檔過長導致的檢索效率低、語義理解受限、資源浪費、生成質量下降及歧義風險增加等問題。合理分段是保障后續檢索上下文有效性的前提。?
- 文本片段向量化?
完成文本分段后,借助向量編碼器將各文本片段轉化為語義向量。目前主流的做法是采用Transformer模型,其強大的上下文理解能力,正是生成高質量語義向量的關鍵。關于文本向量的提取方法,可參考文章:Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring。
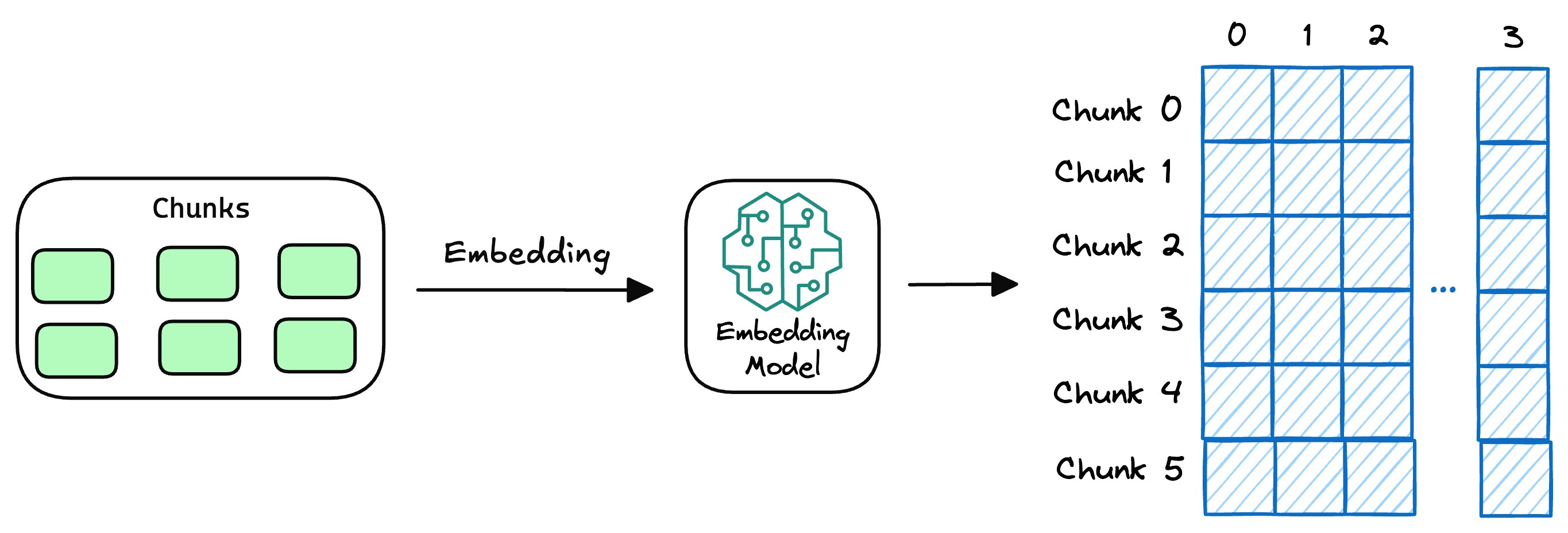
- 向量存儲與知識庫構建?
將文本向量存入向量數據庫,數據庫通過關聯存儲原始內容與對應向量構建外部知識文本庫。作為RAG的知識存儲層,向量數據庫聚合各類知識,為查詢響應提供精準依據。
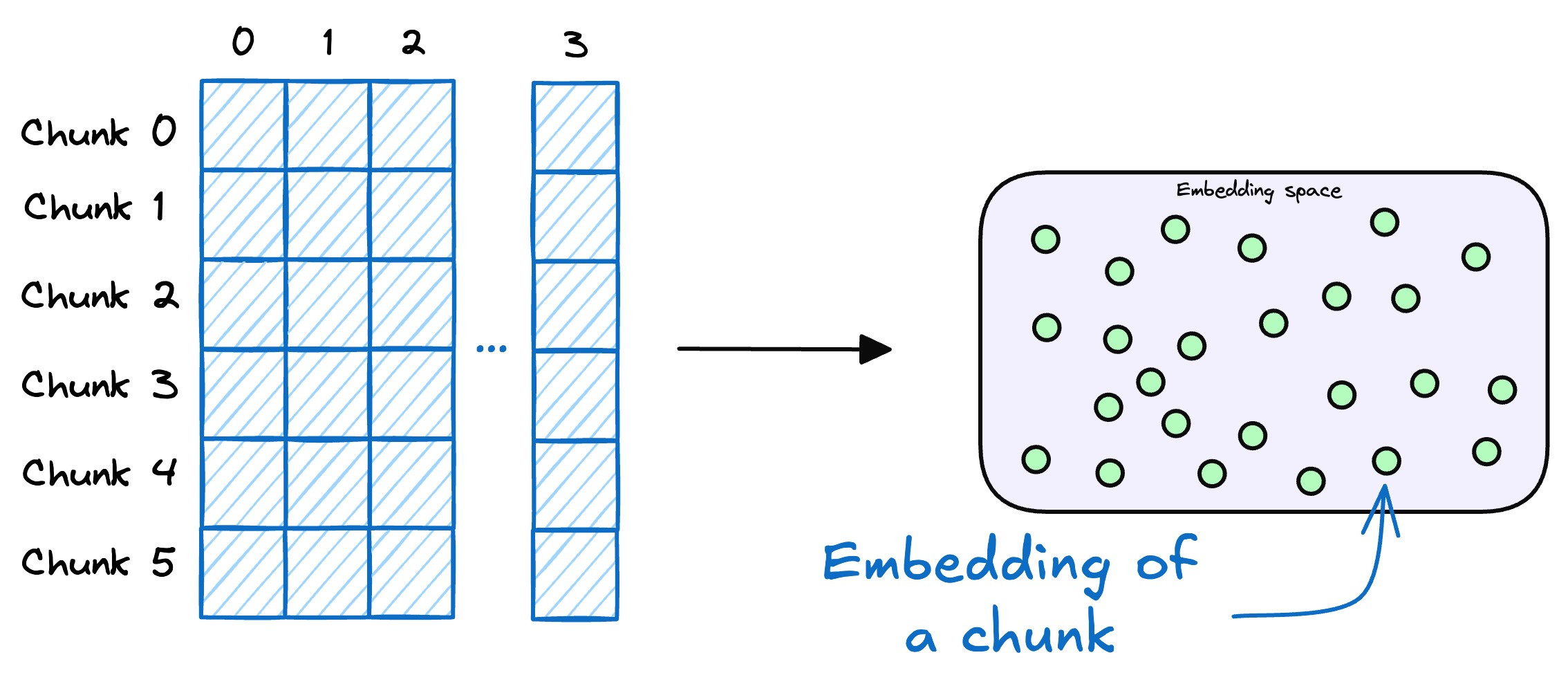
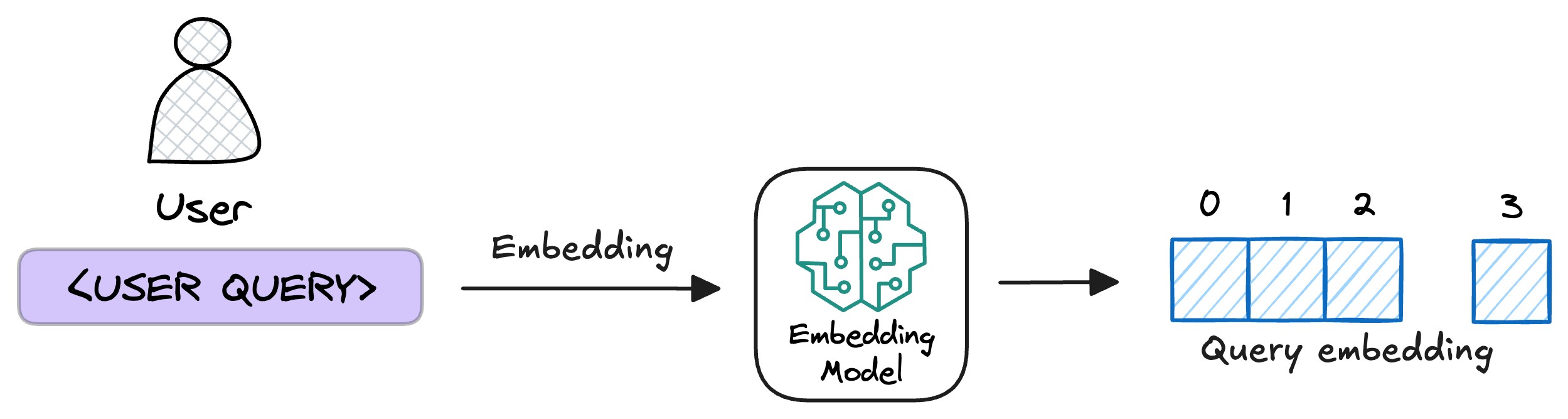
- 用戶查詢向量化?
用戶輸入查詢文本(query)后,系統使用與構建知識庫時一致的向量編碼器將其轉化為向量,確保語義空間一致性。?
- 相似片段檢索
檢索器通過比對查詢向量與數據庫中存儲的文本向量,定位相似度最高的信息。
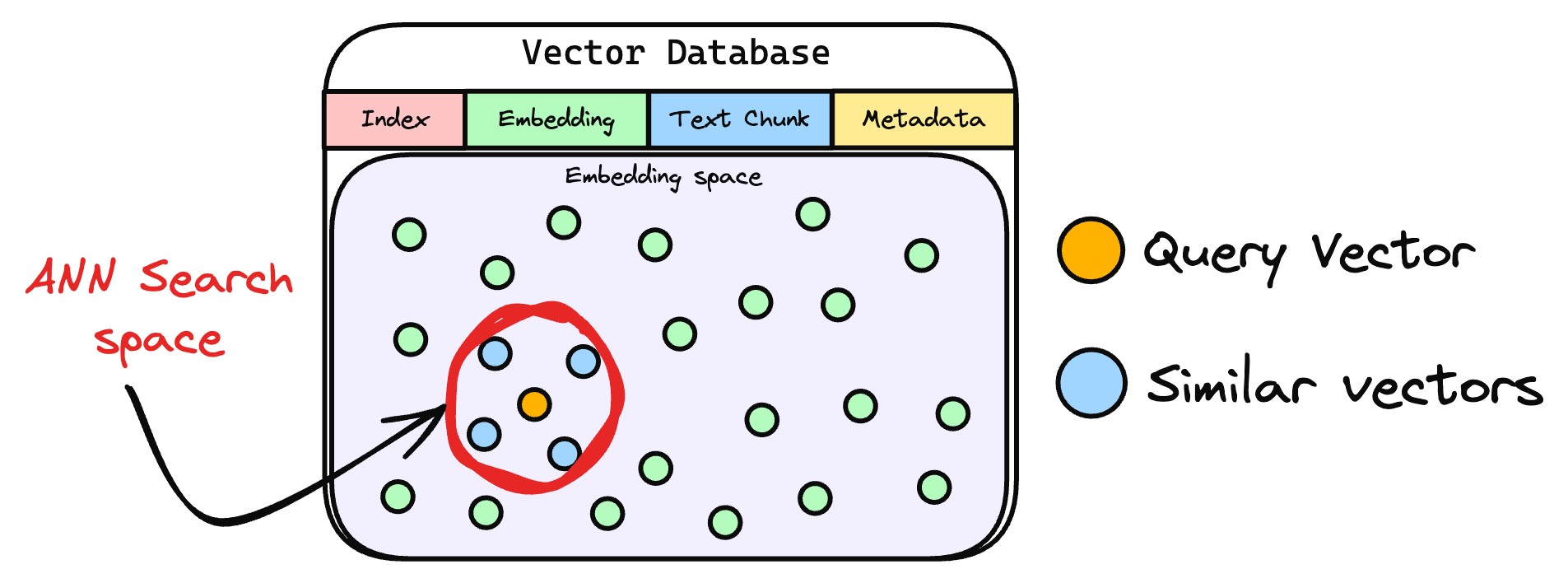
實際應用中,檢索器通過近似最近鄰搜索返回前k個(topk)最相似片段,這是因為復雜查詢常關聯多個相關內容,多結果能避免關鍵信息遺漏,為響應生成提供全面依據。
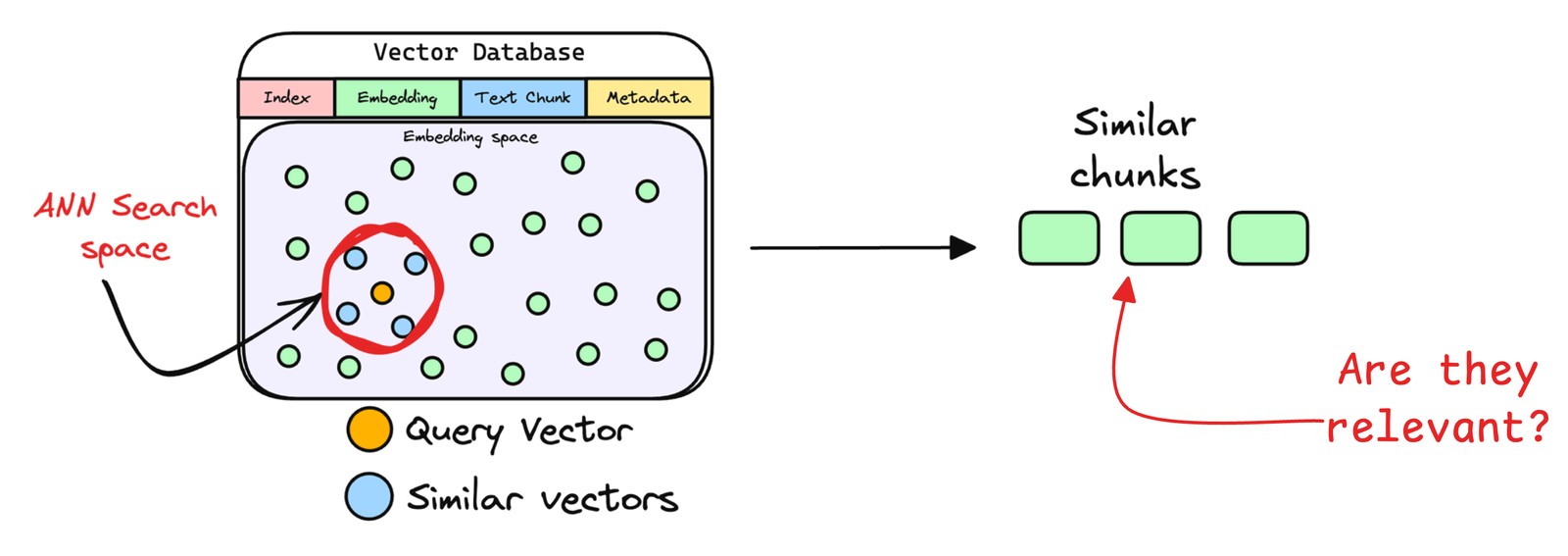
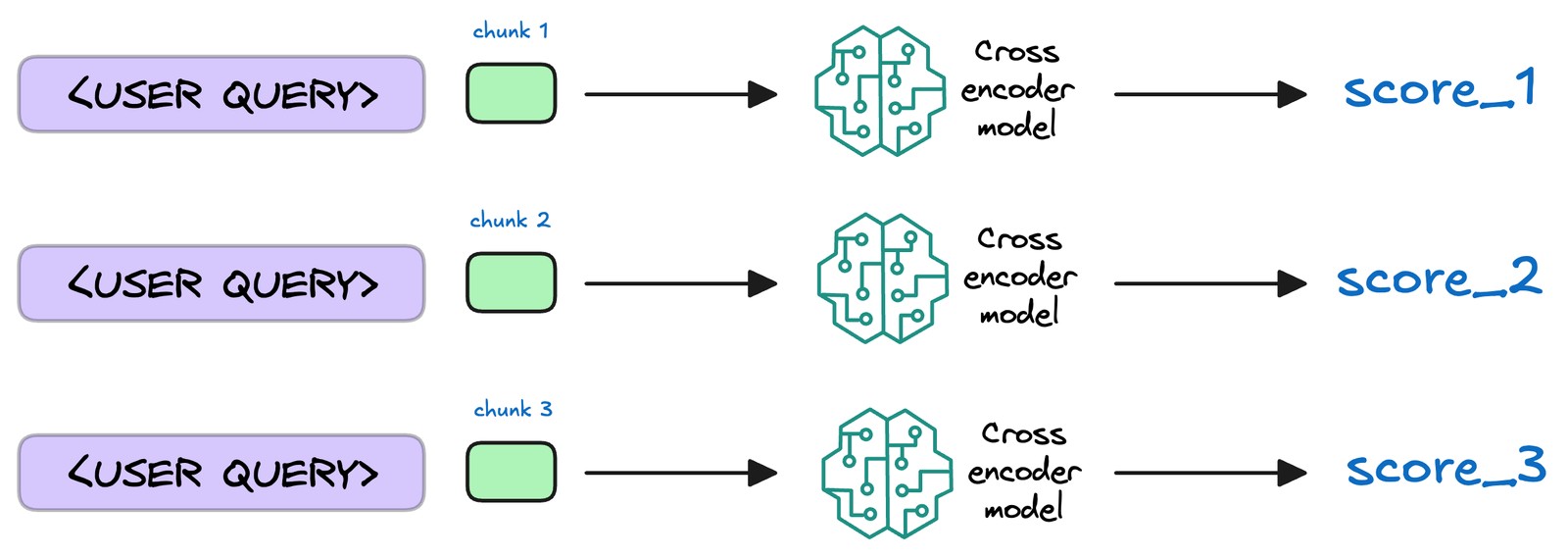
- 文本片段重排序
檢索完成后,需進一步處理挑選出的文檔片段,將相關性最高的文本段落置于最前,這一過程稱為重排序。此步驟通常使用Reranker模型,這類模型多為交叉編碼器,會評估查詢與各候選段落的相關性并給出精確相關度分數,隨后依分數重新排序,將最相關段落置于前列,便于生成模型優先選用。
這樣做能提升后續生成內容的準確性和針對性,不過并非所有RAG應用都包含此步驟。
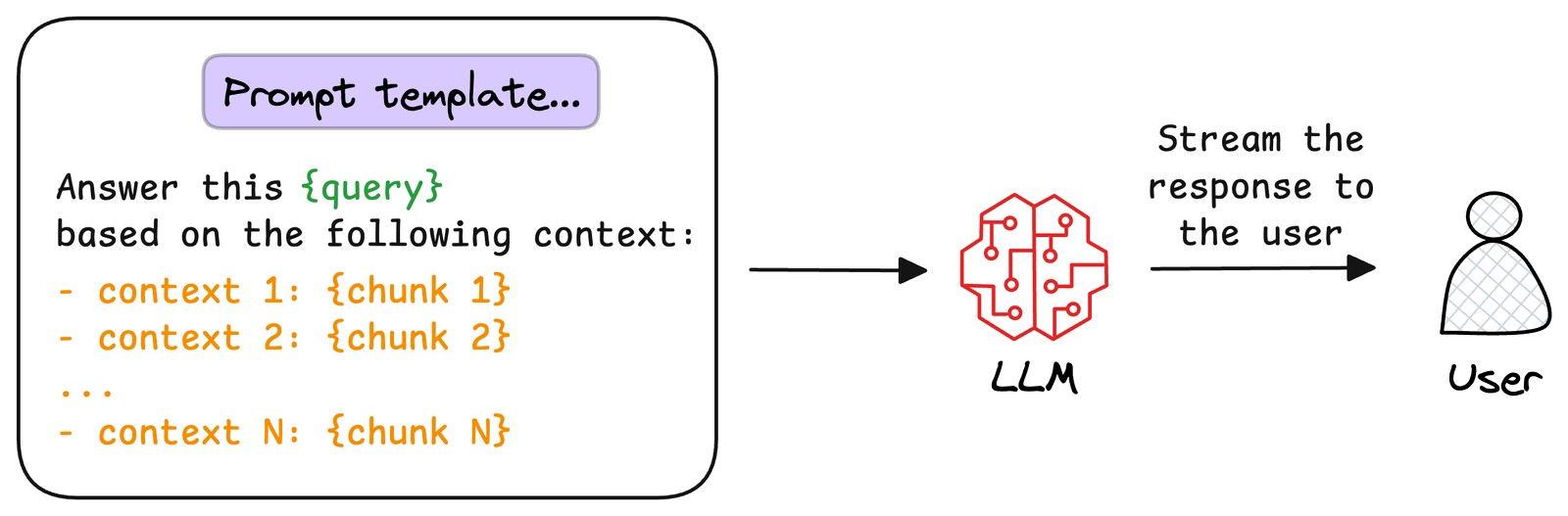
- 生成回答
將用戶原始查詢與檢索到的文本片段整合為提示模板,輸入至LLM。模型以文本片段為上下文,生成既融合文檔信息、又具備連貫性和相關性的回答,直接回應用戶查詢。?
2 RAG技術演進趨勢和常見問題
2.1 RAG技術優化與演進趨勢
2.1.1 RAG技術增強路徑
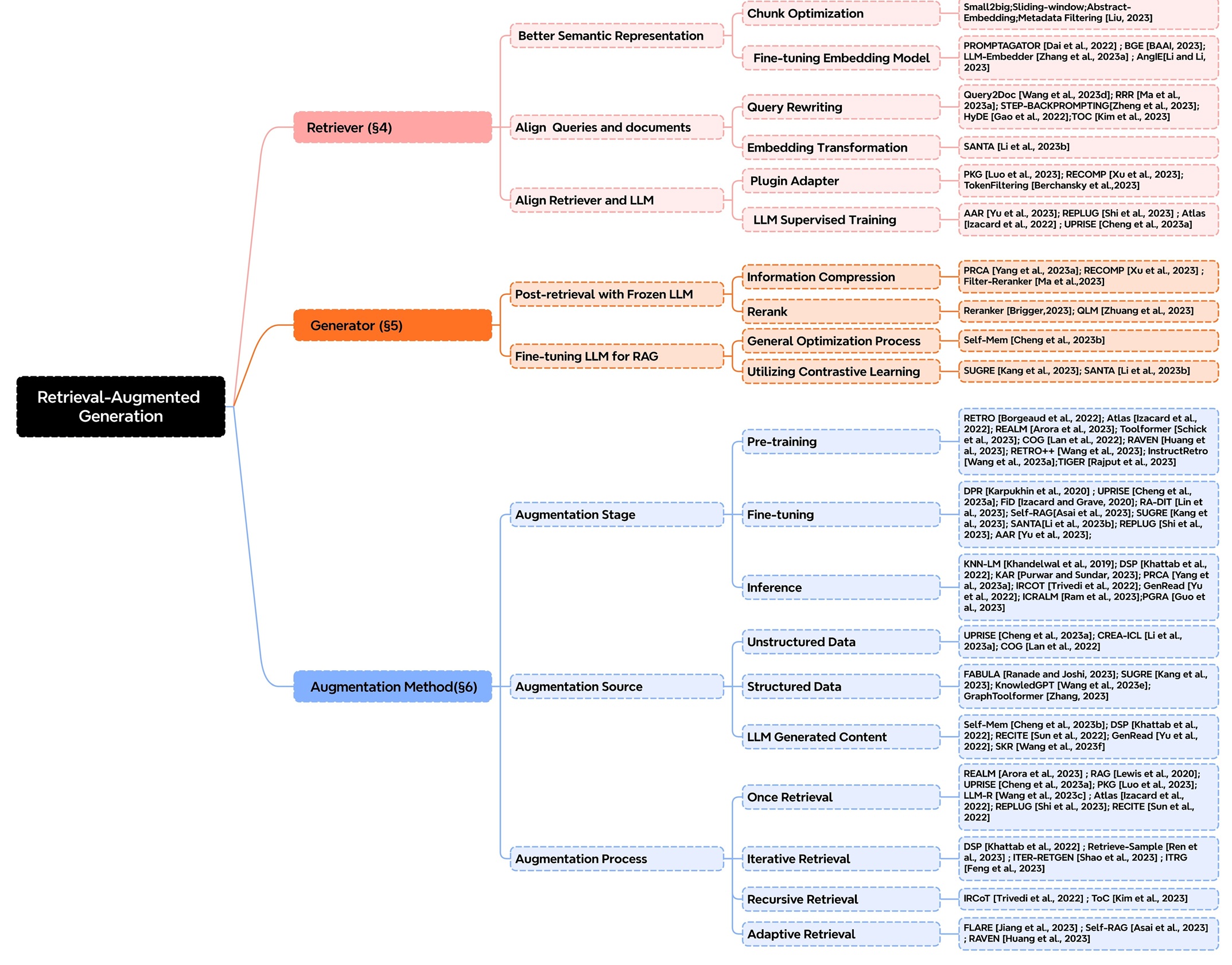
隨著LLM的迅猛發展,RAG技術同步進入快速演進階段。目前,已有大量研究與實踐從多維度切入。下面將從增強階段、增強來源和增強過程三個方面,介紹現有技術如何通過多樣化手段提升RAG的檢索精度并優化運行效率。
增強階段
從技術增強的階段特性來看,LLM在預訓練、微調和推理環節的優化方式具體如下:
- Pre-training(預訓練階段):引入檢索增強機制,強化模型對外部知識的融合能力
- Fine-tuning(微調階段):依托檢索優化手段,提升模型對特定任務的適配性能
- Inference(推理階段):通過動態檢索知識輔助生成過程,這也是RAG技術最核心的應用場景
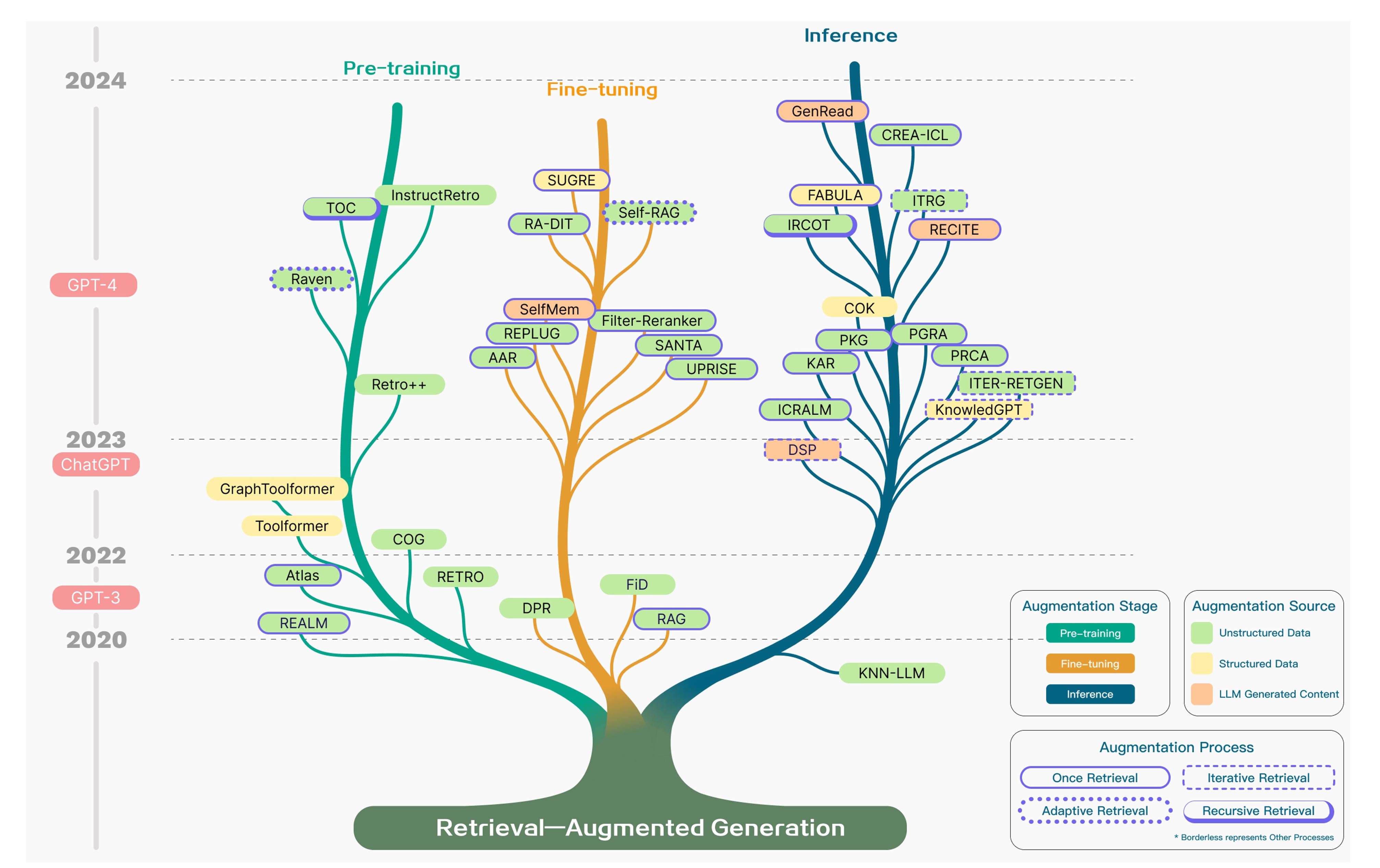
增強來源
在RAG技術中,增強來源指通過外部數據彌補模型固有缺陷的信息渠道,主要包括三類:
- 非結構化數據(天然文本形式,如文章、小說)
- 定義:無固定格式的文本內容,涵蓋新聞、論文、小說、網頁段落等。
- 示例:
- 模型預訓練時學習的百科“李白生平”純文字詞條;
- 推理階段檢索的問答網站“如何評價李白”的散文式用戶回答。
- 特點:人類可直接閱讀,但提取關鍵信息需“大海撈針”(例如從一篇論文中定位某句話)。
- 結構化數據(規整格式呈現,如表格、數據庫)
- 定義:格式明確的數據形態,包括Excel表格、數據庫表、知識圖譜(含節點與關系)等。
- 示例:
- 模型預訓練時學習的“中國詩人朝代表”(表格中包含“姓名-朝代-代表作”字段);
- 推理時查詢知識圖譜中“李白→好友→杜甫”的關聯關系。
- 特點:數據排列規整,可精準提取信息(如直接獲取表格中的“李白生卒年”),但要求模型具備解析格式的能力(如表格解析能力)。
- LLM生成內容(模型實時生成的思考草稿)
- 定義:模型在推理過程中臨時產生的文本(非外部現成信息,屬于思考階段的動態產物)。
- 示例:
- 回答“李白與杜甫的關系”時,模型先自主生成假設:“他們是好友,杜甫曾作《贈李白》”(此為模型實時構思的內容);
- 隨后以該假設為線索,檢索《杜工部集》中的詩句進行驗證。
- 特點:具備動態性與靈活性(模型邊思考邊生成),但可能存在誤差(如假設錯誤需通過檢索修正)。
一句話總結差異:
- 非結構化數據與結構化數據:借助外部現成的“知識儲備”(他人撰寫的文章、表格等);
- LLM生成內容:借助自身臨時的“腦暴草稿”(模型推理中動態生成的內容,用作檢索線索)。
增強過程
增強過程指模型通過檢索知識輔助生成內容的機制,核心在于檢索策略的邏輯設計,具體包括以下幾類:
- 一次檢索(Once Retrieval)
- 定義:針對問題僅執行單次檢索,直接用結果生成答案。
- 類比:查字典時只翻一次頁碼,不論解釋是否準確便直接引用。
- 特點:操作簡單、效率高,但可能因檢索結果不全或問題需多維度知識而遺漏信息。
- 迭代檢索(Iterative Retrieval)
- 定義:基于首次生成的內容反復檢索補充知識,逐步優化答案。
- 類比:寫作文時先列大綱(首次生成),發現“李白的好友”僅提及杜甫,便再查高適、王昌齡等資料(迭代檢索)以補充內容。
- 特點:形成“生成→反饋→再檢索”的循環,類似“游戲中復活后繼續闖關”。
- 自適應檢索(Adaptive Pattern)
- 定義:根據任務類型或生成狀態動態調整檢索策略,例如切換數據庫、調整檢索范圍等。
- 類比:玩游戲時,遇“歷史題”切換至歷史數據庫,遇“數學題”切換至公式庫;或發現生成內容模糊時,擴大檢索范圍。
- 特點:靈活性強,如同“智能切換武器”,但需模型具備判斷“何時使用何種策略”的能力。
- 遞歸檢索(Recursive Retrieval)
- 定義:將復雜問題拆解為子問題,逐層遞歸檢索,像“俄羅斯套娃”般深入探究。
- 類比:破案時,先查“李白的死因”(主問題),拆解為“李白晚年健康狀況”(子問題1),再拆解為“唐朝醫療水平”(子問題2),每層均進行檢索。
- 核心邏輯:遵循“問題→拆解→子檢索→再拆解→深層檢索”的路徑,與遞歸函數思路一致。
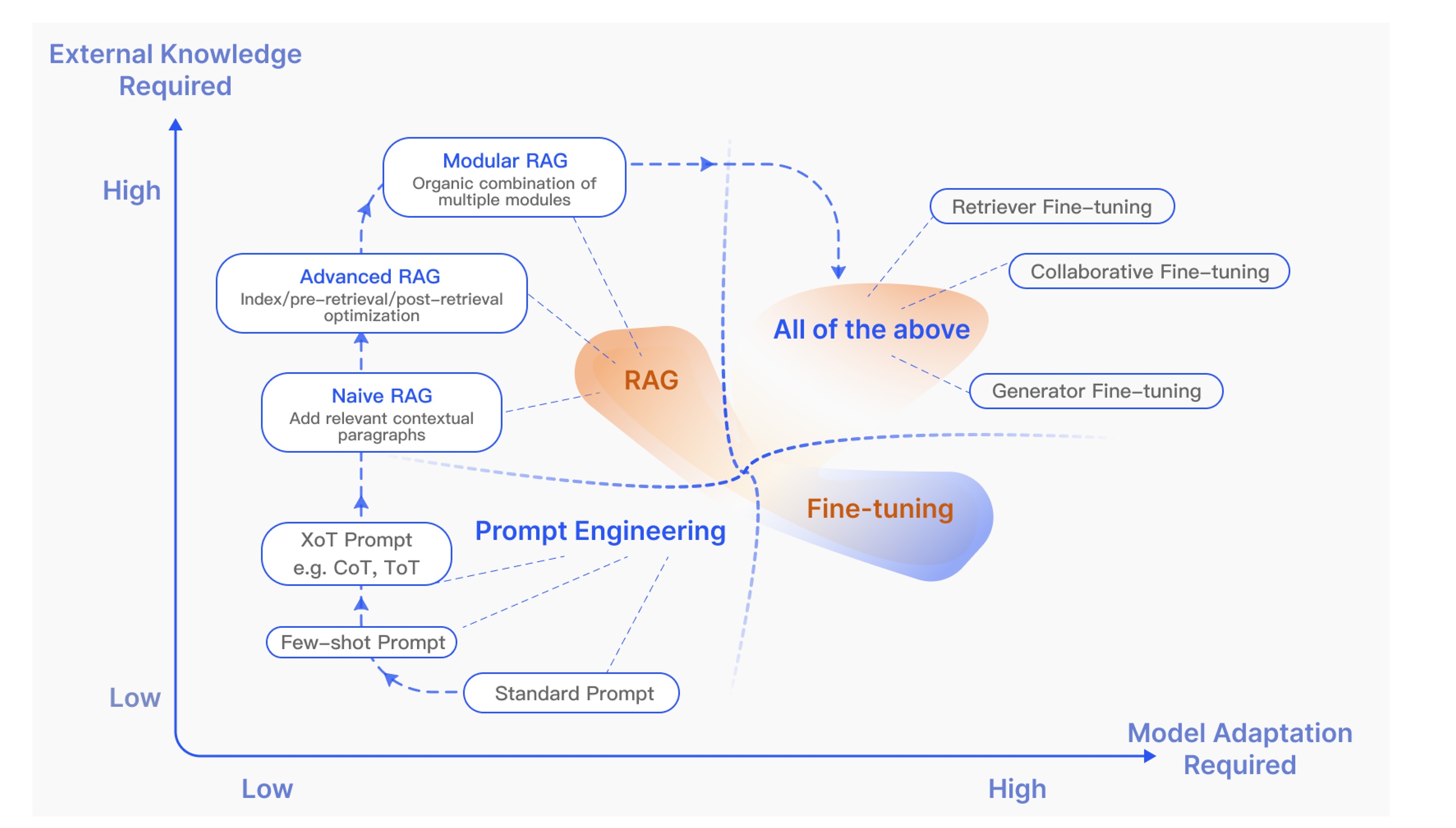
總之,RAG發展的三大關鍵技術包括增強階段、數據來源及處理過程,這三大技術能夠清晰呈現RAG核心組件的分類體系,同時RAG的實現模式也在不斷演變。早期的RAG可能只是 “簡單檢索+直接生成” 的模式,而隨著技術進步,其實現中已融入更復雜的環節,這些具體實現方法始終處于動態變化中,愈發精細且能更好地適配不同場景。
搭建RAG系統時,技術選型的應該以需求適配為導向,兼顧效果的評估與優化,選擇能高效支撐目標場景且表現更優的方案。關于RAG系統的構建和技術選型可以參考:文章17種RAG架構實現原理與選型或參考下一節內容。
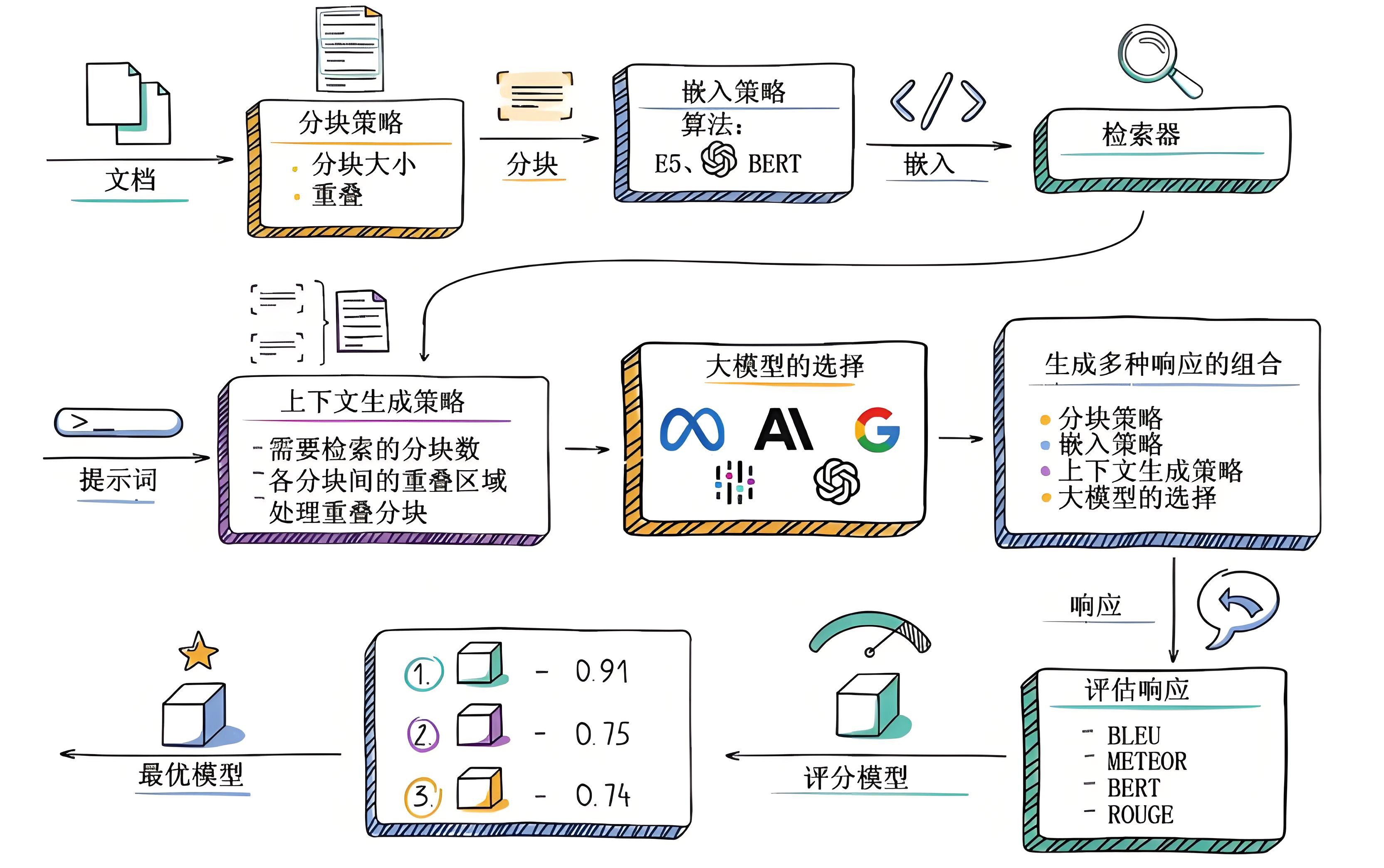
2.1.2 RAG系統實現模式的演化
實現高效文檔檢索需要解決三大核心問題:
- 構建精確的語義表示,確保文檔和查詢的嵌入能準確捕捉其含義。
- 對齊查詢與文檔的語義空間,縮小檢索模型理解的查詢意圖與文檔實際內容之間的語義鴻溝。
- 適配檢索器輸出與LLM偏好,使檢索到的上下文信息更符合下游大型語言模型的生成需求。
為應對上述挑戰,在RAG架構之上引入了檢索前優化和檢索后優化的策略。
- 檢索前優化,提升索引質量如文檔切分粒度優化、元數據增強和查詢處理如語義轉換、關鍵詞擴展,旨在改善檢索相關性。
- 檢索后優化,對檢索結果進行過濾、去冗余、重排序按重要性和信息壓縮整合,確保輸入LLM的上下文信息更精煉相關。
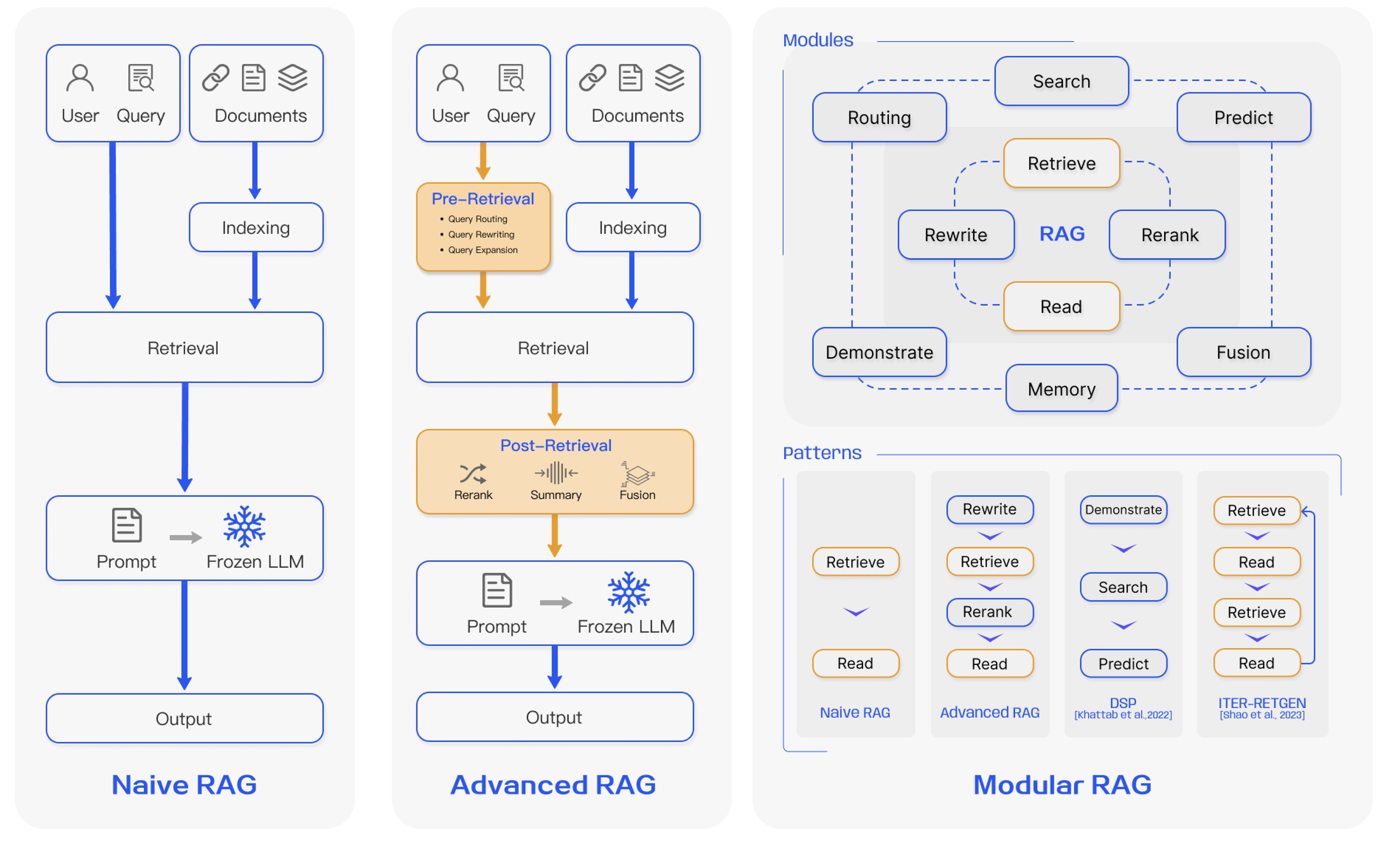
基于優化策略的應用深度,當前RAG研究形成了三種主要范式:
-
基礎RAG(Naive RAG)
- 遵循基礎流程索引、檢索、生成。
- 主要痛點:
- 檢索質量低,導致檢索結果不精準不全面。
- 生成質量受限,LLM易產生幻覺,難以有效融合檢索到的上下文與當前生成任務。
- 信息冗余與風格沖突,檢索結果常包含重復冗余信息,且不同來源文本風格語氣不一致,影響生成連貫性。
- 過度依賴風險,LLM可能過度依賴有時不準確的檢索信息。
-
進階RAG(Advanced RAG)
- 通過強化檢索前和檢索后優化的流程,并改進索引如滑動窗口、細粒度分割、元數據利用,以解決基礎RAG的缺陷。
- 檢索前優化:包括數據粒度優化、索引結構調整、元數據注入、向量對齊、混合檢索如結合稀疏與稠密檢索等。
- 檢索核心:依賴嵌入模型計算查詢與文檔塊的相似度。
- 檢索后優化:采用重排序和提示壓縮技術,克服上下文窗口限制,提煉關鍵信息。
- 潛在挑戰:以復雜度換效果,提升了基礎RAG性能,但其額外模塊的引入也帶來了效率、泛化性和可維護性的新挑戰。
-
模塊化RAG(Modular RAG)
- 強調框架的高度靈活性與適應性,可將RAG流程拆解為可替換可重組的模塊,以解決特定問題。
- 優化方向:
- 提升信息效率與質量,整合多種檢索技術,優化檢索步驟如引入認知回溯機制,實施多樣化查詢策略,有效利用嵌入相似性。
- 支持復雜交互,模塊化設計便于處理迭代檢索與多輪生成,如對回溯提示的響應。
- 潛在挑戰:當LLM對主題知識匱乏時,依賴檢索信息可能導致錯誤率上升。
事實上除了這三種RAG范式,還有其他更多的范式,具體可參考:一篇搞明白RAG的幾種不同類型。
總之,RAG技術及其構成體系具有較強的復雜性,涵蓋知識獲取、數據預處理、索引構建、檢索策略優化、生成模型調優等多個環節。對于應用層面者而言,優先聚焦于檢索模塊的精準性提升(如向量數據庫選型、相似度算法優化)與生成模塊的語義連貫性構建(如提示詞工程、大模型適配)這兩大核心基礎,是快速掌握技術應用邏輯的有效路徑。
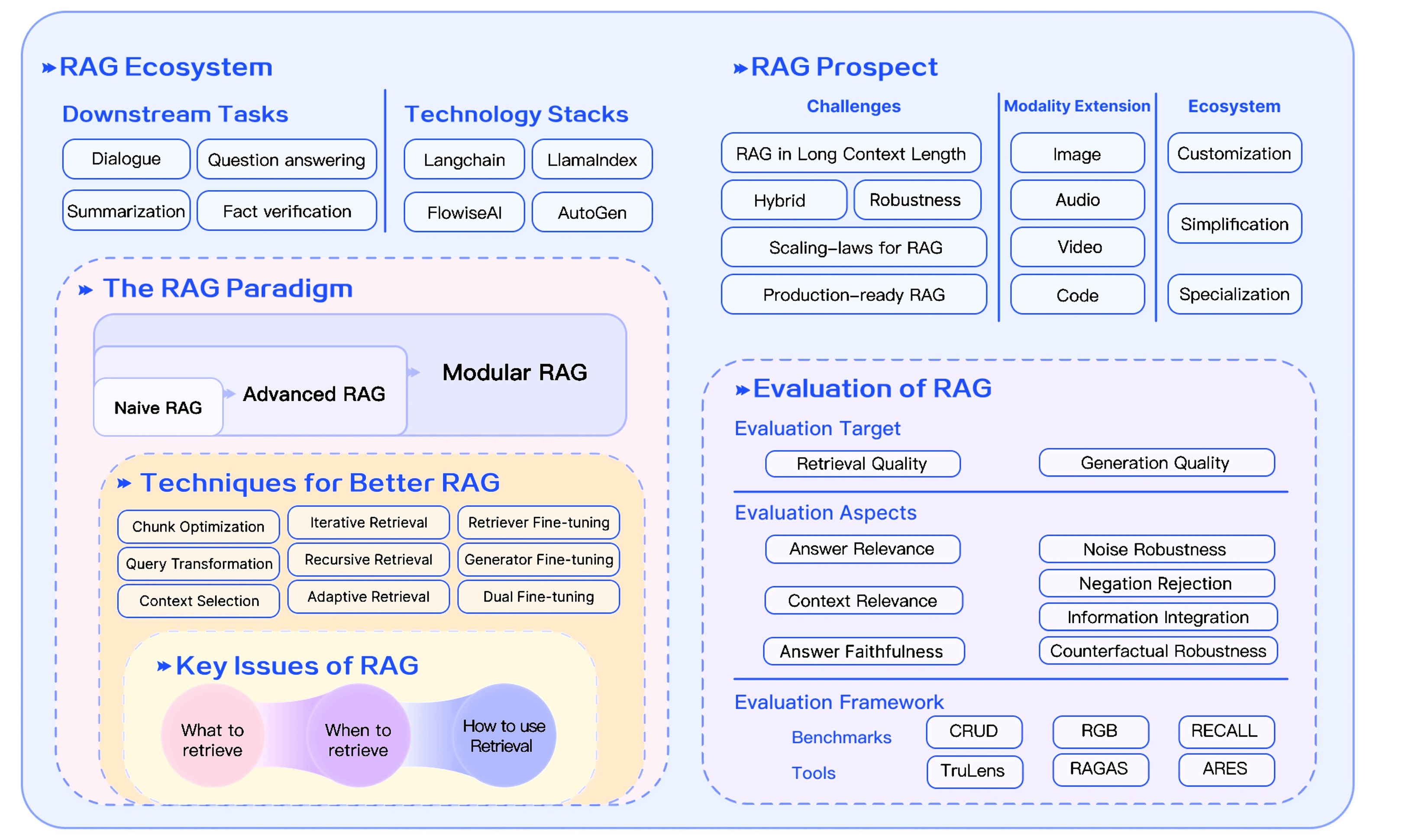
2.2 RAG技術典型問題與優化方案
2.2.1 RAG技術常見問題及解決辦法
本節主要介紹RAG技術的常見問題及相應解決辦法,更詳細的內容可參考文章Traditional RAG vs. HyDE。
- 問題與答案語義不匹配
檢索到的文檔可能與問題無關,甚至無關文檔的余弦相似度可能高于含答案的文檔。
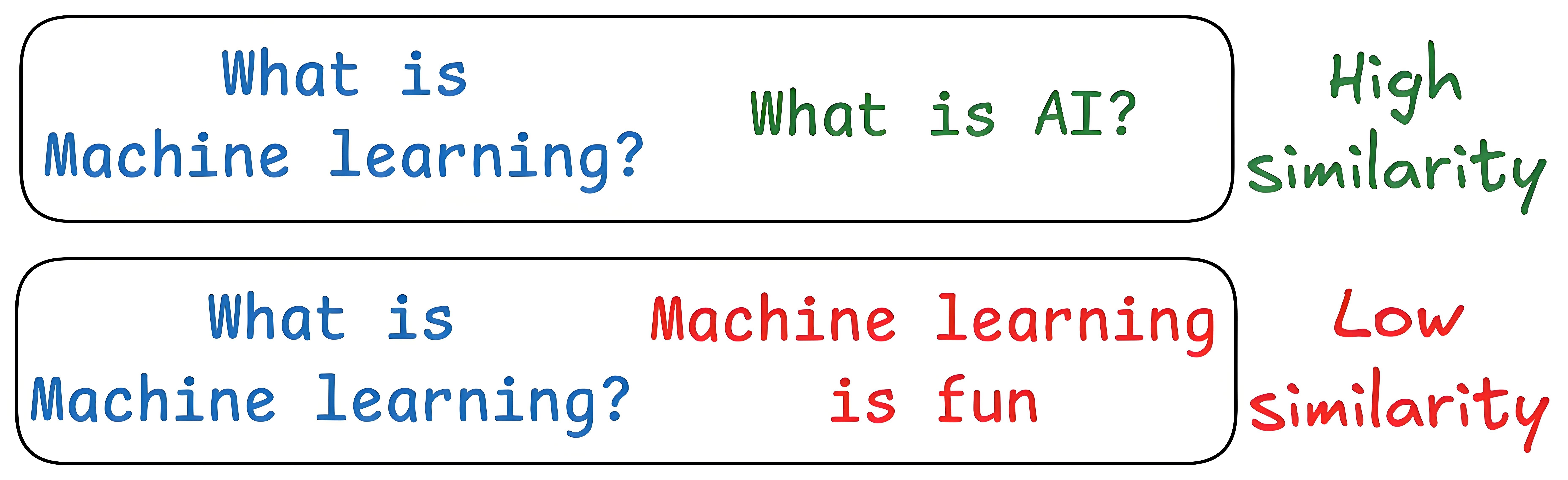
一種優化方案為:先用LLM針對問題生成假設答案,彌補表述模糊以明確語義指向;再將問題與假設答案轉化為文本向量,通過向量拼接或加權求和等方式;最后用該文本向量查詢向量數據庫,提升匹配精度。
例如,對于問題“需要適合新手,考慮學習難度低,入門成本適中,便于攜帶的入門樂器”,LLM可生成假設答案以明確指向;再結合該問題與假設答案的語義向量查詢數據庫,就能精準匹配到“尤克里里學習難度低,入門成本低,體積小便于攜帶,適合新手入門”這類結果。
需注意這種方法只能在一定程度上減輕問題影響,無法完全消除問題本身的局限性。
- 語義相似性可能被弱化
部分含重要信息的長文本常夾雜背景描述、細節補充等無關內容,會稀釋核心信息。如同糖水加水后味道變淡,導致RAG計算語義相似度時,與搜索內容的匹配度下降。反觀短文本,即便內容不重要,若含少量相關詞,因干擾少且相關詞集中,與搜索內容的相似度反而更高。最終可能導致系統輸出無關信息或遺漏關鍵信息,影響整體效果。
采用文本摘要或關鍵句抽取技術預處理長文檔,同步進行精準分段、冗余清洗與核心內容提取,僅將濃縮后的核心信息存入語義向量庫,再結合優化的檢索策略精準匹配相關片段,是應對該問題的有效方法。
- 檢索文檔的關注偏差
基于相似性搜索從數據庫檢索文檔時,通常按相似性度量排序,但LLM基于這些文檔生成回答時,雖能通過位置編碼明確感知輸入順序,其關注重點卻不遵循人類“前序優先”的主觀傾向,而是由注意力機制與上下文長度共同決定,短上下文時處理更均勻,長上下文則因“注意力稀釋”更關注首尾文檔。若高相似文檔因位置靠后被忽略,會造成“檢索優質但利用低效”,最終降低回答質量。
例如問“緩解頸椎痛的好辦法”,數據庫檢索出6篇文檔,按相似性從高到低排序,第4篇最相關,寫了具體的穴位按摩法,第1篇只說“別久坐”。LLM處理這6篇長上下文時,注意力稀釋,主要關注首尾,未太關注第4篇,最終回答只提“別久坐”,遺漏了最有效的穴位按摩法。明明檢索到了優質信息卻沒用好,回答自然不夠好。
應對方案可采用“關鍵文檔首尾雙曝光”策略:將檢索結果中最相關的文檔交替置于輸入序列的頭部和尾部,如復制最關鍵的1-3篇文檔到首尾位置;利用LLM在長上下文中天然關注首尾的“注意力錨點效應”,首尾信息稀釋度最低;確保高價值內容不被中間位置淹沒,同時輔以文檔內容濃縮,通過摘要壓縮文本減少冗余干擾,以及顯式指令引導,在輸入中標注“請重點參考以下高相關文檔”。三重措施協同突破注意力稀釋瓶頸,顯著提升優質檢索結果的利用率。
- 需避免詢問需整合全局信息的問題
使用RAG系統時,需避免需要全局信息匯總的問題,這類問題需整合大量分散數據,而RAG系統依賴的相似性搜索通常只能定位少數最相關文檔,難以覆蓋全部必要信息源,導致答案常出錯。若答案集中在一兩份文檔中,相似性搜索精準高效,RAG系統表現良好,但若答案需遍歷所有文檔、聚合分散信息,相似性搜索則力不從心。本質上,RAG系統是檢索增強工具,而非全局數據聚合器,處理跨文檔匯總和統計類問題時存在天然局限。
在RAG系統中緩解全局匯總問題,核心是結合混合檢索向量+關鍵詞提升覆蓋度,并通過查詢分解讓RAG系統分步處理子問題,最后聚合結果。若需強統計能力,需整合傳統數據庫執行聚合計算。
2.2.2 RAG系統固有挑戰
除上述問題外,RAG系統還存在以下固有挑戰:
- 檢索效率與延遲問題:面對百萬級文檔等大規模知識庫時,檢索易產生高延遲,難以滿足實時交互需求。
- 對知識庫質量的高度依賴:生成結果直接受檢索內容影響。若知識庫存在數據過時、信息不完整或包含噪聲等問題,會導致輸出錯誤;同時,在小眾領域等未覆蓋場景中,其領域適應性較差。
- 上下文窗口限制:受生成模型上下文窗口容量所限,檢索到的長文檔可能被截斷,造成關鍵信息丟失。
- 生成與檢索的協同問題:
- 模型可能忽略檢索結果,僅依賴自身參數生成錯誤信息(即"檢索無用");
- 或過度依賴檢索內容,機械復制片段而缺乏邏輯整合。
- 評估體系缺失:目前缺乏統一的量化指標來評估檢索與生成的協同效果,人工評估成本高且難以標準化,阻礙了模型迭代優化。
RAG的這些固有挑戰,源于檢索與生成這兩個復雜系統的耦合,其中涉及算法、數據及工程等多方面的權衡。由于目前這些挑戰尚無法完全解決,因此在使用RAG技術時需要加以考量。關于這些固有挑戰的詳細介紹,可參考論文:Seven Failure Points When Engineering a Retrieval Augmented Generation System。
2.2.3 RAG技術與模型指令微調的對比
在構建LLM應用時,除了RAG技術,模型指令微調也是一種被廣泛采用的技術路徑。關于這兩種技術的詳細對比,可以參考文章Full-model Fine-tuning vs. LoRA vs. RAG。
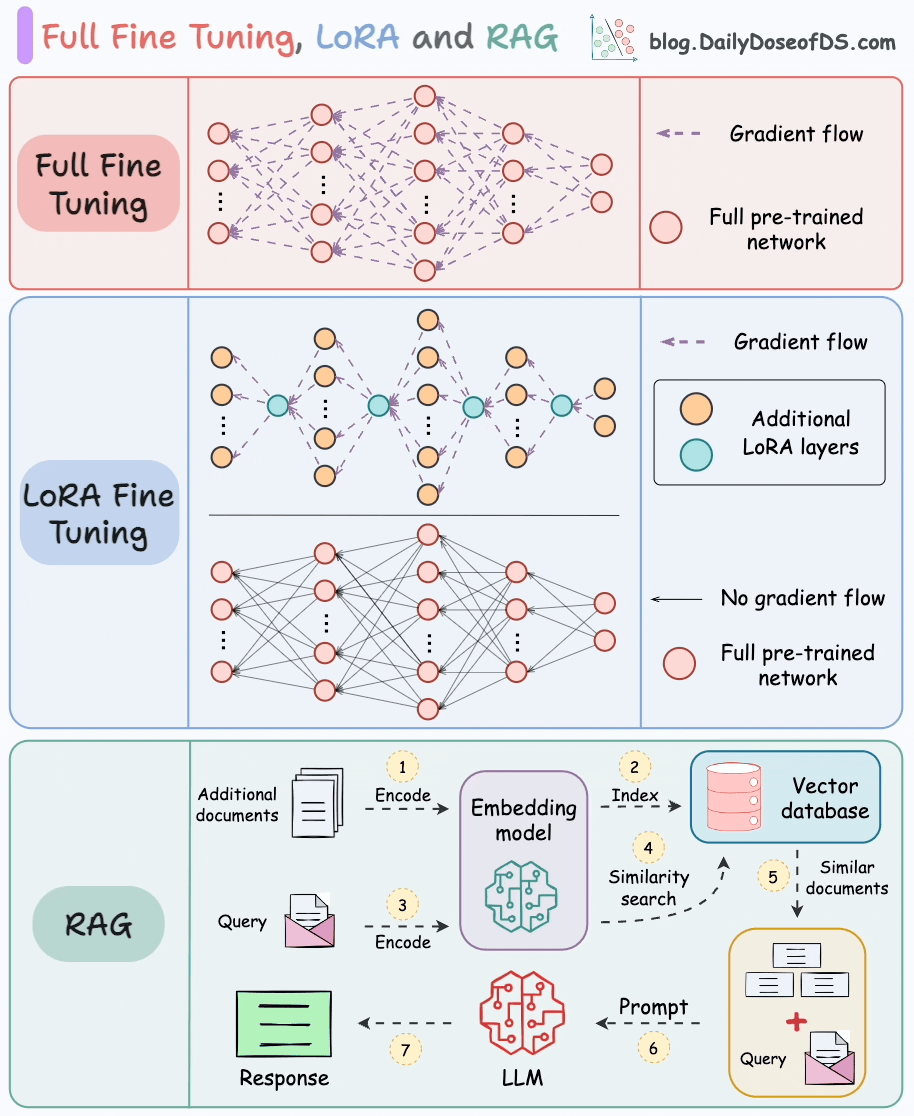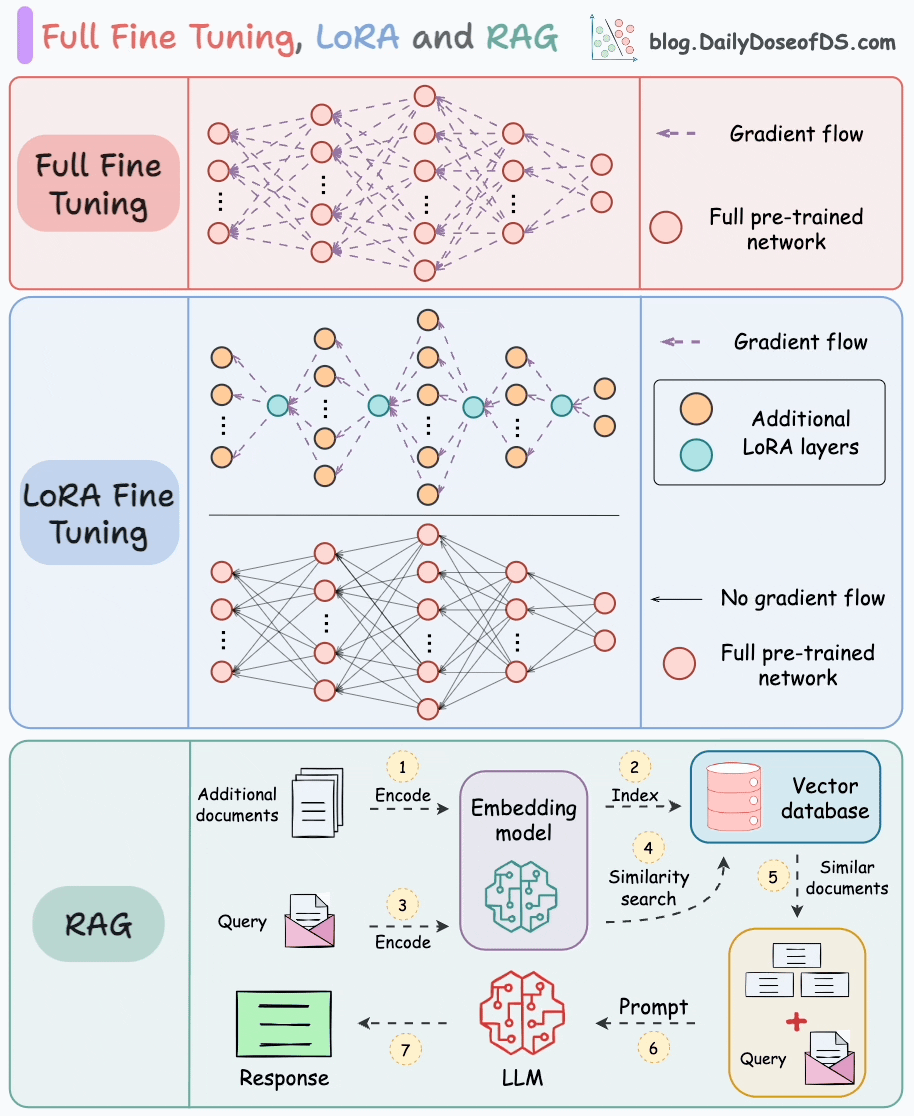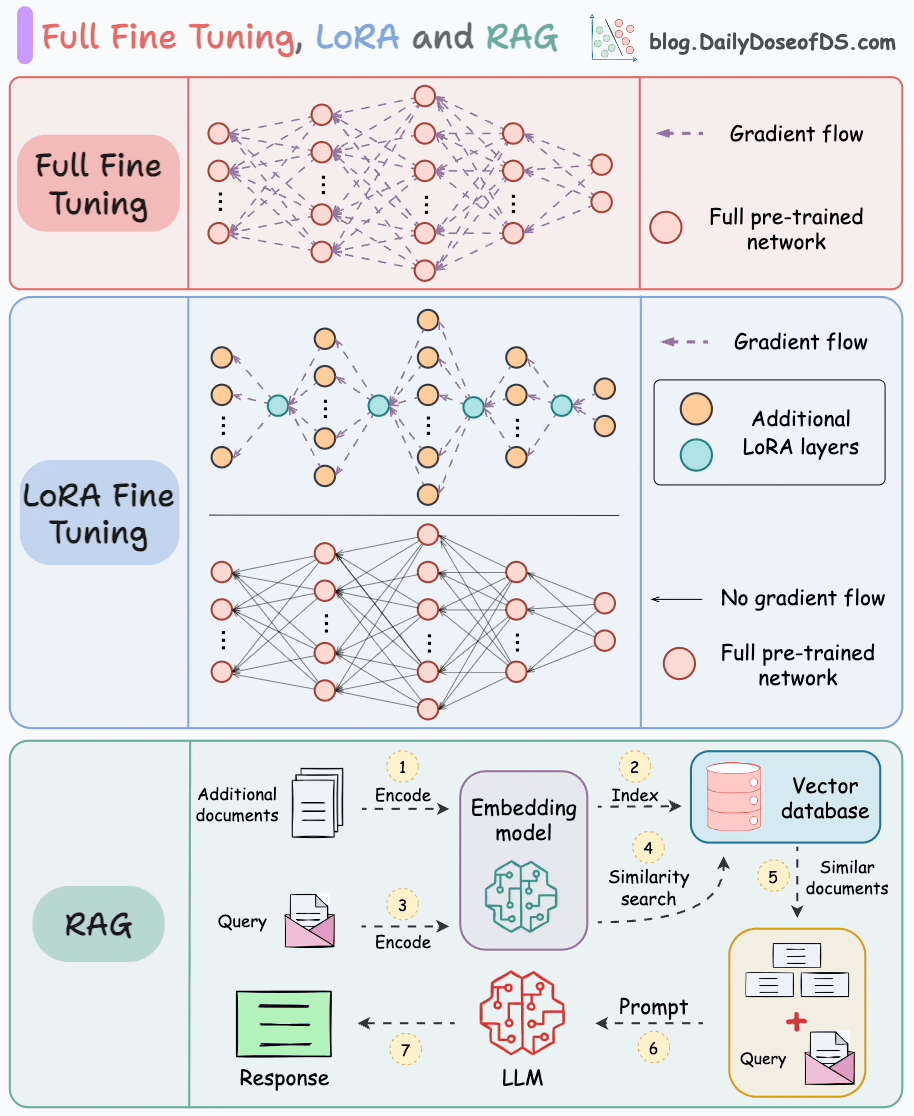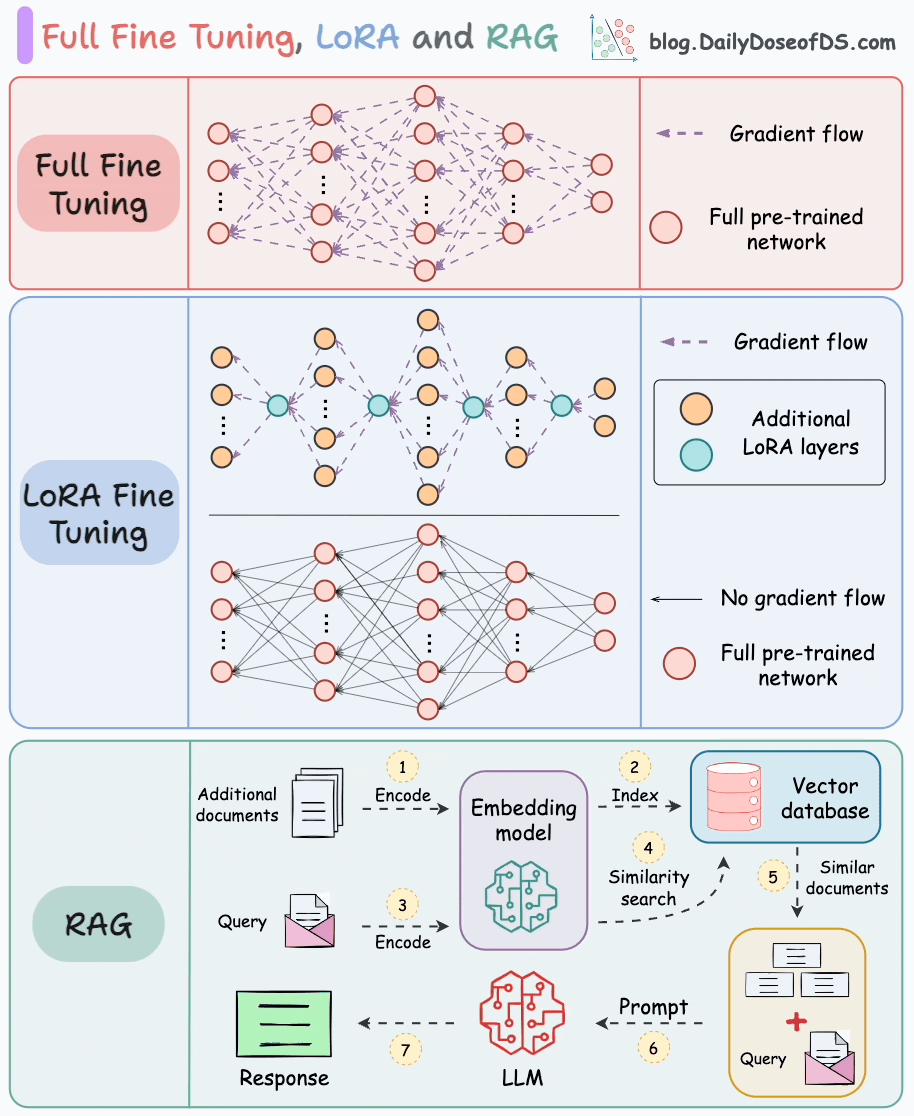
對比內容概覽如下:
- 基礎機制與數據需求
- RAG :通過檢索外部知識庫(文檔、數據庫等)獲取信息,結合生成模型輸出答案;無需修改模型參數,依賴知識庫質量,無需標注訓練數據。
- 指令微調 :在特定標注數據集上調整預訓練模型參數,適配特定任務/領域;需高質量標注數據,直接修改模型參數。
- 更新機制與成本
- RAG :支持實時更新知識庫,模型無需重新訓練;僅涉及檢索+生成,推理成本低。
- 指令微調 :知識更新需重新微調或增量訓練,成本高(依賴GPU資源);無檢索步驟,推理速度快。
- 優勢與局限
- RAG :
? 優勢:靈活適應新知識、降低幻覺風險(依賴權威數據源)、無需訓練數據。
? 局限:檢索延遲可能影響響應速度、依賴知識庫質量、生成邏輯受限于檢索片段。 - 指令微調 :
? 優勢:輸出風格可控、領域內任務性能更優、推理速度快(無檢索步驟)。
? 局限:數據不足時易過擬合、知識更新需重新訓練、可能產生事實性幻覺。
- 適用場景與典型應用
- RAG :適用于知識密集型任務(需動態/領域外知識),如開放域問答、醫療咨詢、產品文檔客服。
- 指令微調 :適用于需特定輸出風格或領域專精的任務,如代碼生成、情感分析、法律文本生成、專業術語翻譯。
- 技術代表
- RAG :FAISS + GPT、DPR + BART
- 指令微調 :LoRA、Adapter、全參數微調
3 實戰
3.1 RAG系統示例代碼
本文第一章已詳細闡述了RAG系統的基本工作流程,其核心環節涵蓋:文本分段、文本片段向量化?、向量存儲與知識庫構建、用戶查詢向量化?、相似片段檢索、文本片段重排序以及生成回答。
為了更好地解釋RAG模型的原理和實現,本章將提供完整的示例代碼,系統性地演示如何實現上述各個環節,從而構建一個可運行的最小化RAG應用系統。該部分內容參考自:Happy-LLM。
下面將介紹該示例各部分代碼。所有代碼需放在同一文件夾中,最后一個模塊,即生成回答的代碼為運行入口。請注意,代碼中使用的均為基礎版模型。
若回答效果欠佳,可能源于多方面因素:文檔分塊不合理、向量提取模型對領域語義捕捉不足、檢索策略未返回最相關上下文、大語言模型對檢索內容利用不充分,或測試文件與問題相關性低、對話歷史累積造成干擾等。這些環節都會影響最終回答的準確性和針對性。實際搭建RAG系統可參考本文3.2節內容
0. 生成示例數據
這段代碼文件是一個用于生成RAG系統測試文件的Python腳本,主要功能是創建幾個包含特定內容的文本文件,注意輸出文件都為txt格式。
# Generate.py
import osdef generate_rag_test_files(folder_name:str ="rag_test_files"):"""生成RAG測試文件并保存到指定文件夾"""# 創建存放文件的文件夾if not os.path.exists(folder_name):os.makedirs(folder_name)# 定義文件內容planets_content = """太陽系行星基礎知識1. 水星(Mercury)
- 位置:距離太陽最近的行星(約0.39天文單位)
- 特征:表面布滿隕石坑,沒有大氣層保護,晝夜溫差極大(白天約430℃,夜晚約-180℃)
- 自轉周期:58.6地球日,公轉周期:88地球日2. 金星(Venus)
- 位置:距離太陽第二近(約0.72天文單位)
- 特征:被濃密的二氧化碳大氣層覆蓋,產生強烈溫室效應,表面溫度約467℃(太陽系中最熱的行星)
- 特殊點:自轉方向與其他行星相反(自東向西),自轉周期243地球日,公轉周期225地球日3. 地球(Earth)
- 位置:距離太陽第三近(約1天文單位)
- 唯一已知存在液態水和生命的行星,大氣層以氮和氧為主
- 自轉周期23小時56分,公轉周期365.24天4. 火星(Mars)
- 位置:距離太陽第四近(約1.52天文單位)
- 特征:表面呈紅色(因富含氧化鐵),有稀薄的二氧化碳大氣層,存在極地冰蓋(主要是干冰和水冰)
- 地標:奧林匹斯山(太陽系最高山峰,約21千米)、水手谷(長約4000千米的峽谷)5. 木星(Jupiter)
- 位置:距離太陽第五近(約5.2天文單位)
- 特征:太陽系中最大的行星(質量是其他所有行星總和的2.5倍),由氫和氦組成,表面有明顯的條紋和“大紅斑”(持續數百年的風暴)
- 衛星:已知有95顆衛星,其中最大的4顆是“伽利略衛星”(木衛一至木衛四)
"""purifier_content = """家用空氣凈化器(型號:CleanAir X5)使用指南一、核心功能
1. 凈化范圍:適用面積20-30㎡(密閉空間)
2. 過濾系統:- 初級濾網:攔截毛發、灰塵等大顆粒- HEPA濾網:過濾PM2.5、花粉、細菌(效率99.97%@0.3μm)- 活性炭濾網:吸附甲醛、TVOC等有害氣體
3. 運行模式:- 自動模式:根據內置傳感器檢測的空氣質量自動調節風速- 睡眠模式:風速最低,噪音≤30分貝,適合夜間使用二、操作步驟
1. 首次使用:- 拆除濾網外層的塑料包裝(否則會影響凈化效果)- 連接電源,按機身“電源鍵”開機(默認進入自動模式)
2. 更換濾網提示:- 當機身“濾網指示燈”亮起時,需更換對應濾網(HEPA濾網建議6-8個月更換一次,活性炭濾網建議3-4個月更換一次)- 更換方法:打開機器背部面板,取出舊濾網,按標識方向裝入新濾網三、注意事項
1. 避免在潮濕環境(如浴室)使用,以免濾網受潮發霉
2. 長期不使用時,需斷開電源并清潔機身表面
3. 若出現異響或凈化效果下降,檢查是否濾網安裝錯誤或風扇故障
"""reimbursement_content = """HelloWorld公司員工報銷流程指南(2024版)一、可報銷費用類型
1. 差旅費用:- 包含:交通(機票/高鐵票需提供行程單)、住宿(需提供酒店發票和住宿清單)、市內交通(地鐵/打車票,單日上限200元)- 標準:一線城市住宿上限800元/晚,二線城市600元/晚
2. 辦公采購:- 需提前在OA系統提交“采購申請單”,審批通過后憑發票報銷(單筆超過5000元需走對公轉賬)
3. 業務招待:- 需注明招待對象、事由,單次招待金額超過2000元需部門總監審批二、報銷流程步驟
1. 收集憑證:保留所有費用的原始發票(電子發票需打印紙質版并簽字)
2. 提交申請:在OA系統“報銷模塊”填寫報銷單,上傳發票照片并關聯對應項目編號
3. 審批環節:- 單筆≤1000元:部門經理審批→財務審核→打款- 單筆>1000元:部門經理→財務主管→總經理→財務審核→打款
4. 到賬時間:財務審核通過后3個工作日內,款項將打入員工工資卡三、常見問題
1. 發票抬頭必須為“XX科技有限公司”,否則不予報銷
2. 差旅報銷需在出差結束后15天內提交,逾期視為自動放棄
3. 虛報費用將扣除當月績效20%,并記錄違規一次
"""# 定義要創建的文件列表files = [{"name": "太陽系行星知識.txt", "content": planets_content},{"name": "家用空氣凈化器使用指南.txt", "content": purifier_content},{"name": "公司報銷流程指南.txt", "content": reimbursement_content}]# 將內容寫入文件for file in files:file_path = os.path.join(folder_name, file["name"])with open(file_path, "w", encoding="utf-8") as f:f.write(file["content"])print(f"已生成3個RAG測試文件,存放于:{os.path.abspath(folder_name)}")return folder_name# 調用函數生成文件
if __name__ == "__main__":generate_rag_test_files()
1. 文本分段
以下代碼文件實現了ReadFiles類,用于文檔加載與切分:讀取指定文件夾中的所有txt文件,以最大token長度為依據,先按換行符初步切分,單行token超限時則進一步按token分割,同時保留相鄰片段的重疊內容以提升后續檢索準確性。此外,該文件還包含Documents類,用于將數據解析結果存入JSON格式文檔,并返回相應接口。
# Utils.py
import os
import json
import tiktoken # 導入tiktoken庫,用于計算文本的token數量# 初始化編碼器,使用cl100k_base編碼方式
enc = tiktoken.get_encoding("cl100k_base")class ReadFiles:"""讀取指定目錄下的文本文件,并根據token長度進行分塊處理的類主要用于將長文本分割為適合大語言模型處理的小塊"""def __init__(self, path: str) -> None:"""初始化ReadFiles實例:param path: 目標文件夾路徑,用于讀取其中的文本文件"""self._path = path # 存儲目標文件夾路徑self.file_list = self.get_files() # 獲取文件夾中所有符合條件的文件路徑列表def get_files(self):"""遍歷指定文件夾及其子文件夾,收集所有.txt后綴的文件路徑:return: 包含所有txt文件絕對路徑的列表"""file_list = []# os.walk遞歸遍歷文件夾:返回當前路徑、子文件夾列表、文件列表for filepath, dirnames, filenames in os.walk(self._path):for filename in filenames:# 篩選出后綴為.txt的文件if filename.endswith(".txt"):# 拼接完整文件路徑并添加到列表file_list.append(os.path.join(filepath, filename))return file_listdef get_content(self, max_token_len: int = 600, cover_content: int = 150):"""讀取所有文件內容,并按指定token長度進行分塊處理:param max_token_len: 每個塊的最大token長度,默認600:param cover_content: 塊之間重疊的內容長度(字符數),用于保持上下文連貫性,默認150:return: 所有文件分塊后的內容列表"""docs = []# 遍歷每個文件并處理for file in self.file_list:# 讀取文件內容content = self.read_file_content(file)# 對內容進行分塊chunk_content = self.get_chunk(content, max_token_len=max_token_len, cover_content=cover_content)# 將分塊結果添加到總列表docs.extend(chunk_content)return docs@classmethoddef get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):"""將文本按token長度分塊,處理長文本并保持塊之間的重疊:param text: 要分塊的原始文本:param max_token_len: 每個塊的最大token長度:param cover_content: 塊之間重疊的內容長度(字符數):return: 分塊后的文本列表"""chunk_text = [] # 存儲分塊結果curr_len = 0 # 當前塊的token長度curr_chunk = '' # 當前塊的文本內容# 實際可用的token長度 = 最大長度 - 重疊部分(為重疊內容預留空間)token_len = max_token_len - cover_content# 按行分割文本(假設行是有意義的文本單元)lines = text.splitlines()for line in lines:# 去除行首尾空格,但保留行內空格line = line.strip()# 計算當前行的token長度line_len = len(enc.encode(line))# 情況1:當前行的token長度超過最大限制if line_len > max_token_len:# 如果當前塊有內容,先保存if curr_chunk:chunk_text.append(curr_chunk)curr_chunk = ''curr_len = 0# 將超長行按token長度分割成多個塊line_tokens = enc.encode(line)# 計算需要分成多少塊num_chunks = (len(line_tokens) + token_len - 1) // token_lenfor i in range(num_chunks):# 計算當前塊的token起始和結束位置start_token = i * token_lenend_token = min(start_token + token_len, len(line_tokens))# 將token片段解碼回文本chunk_tokens = line_tokens[start_token:end_token]chunk_part = enc.decode(chunk_tokens)# 除了第一個塊,其他塊都添加前一個塊的結尾作為重疊內容if i > 0 and chunk_text:prev_chunk = chunk_text[-1]# 取前一個塊的最后cover_content個字符作為重疊內容cover_part = prev_chunk[-cover_content:] if len(prev_chunk) > cover_content else prev_chunkchunk_part = cover_part + chunk_partchunk_text.append(chunk_part)# 重置當前塊狀態curr_chunk = ''curr_len = 0# 情況2:當前行可以加入當前塊(加上換行符的1個token)elif curr_len + line_len + 1 <= token_len: # +1 是為換行符預留的tokenif curr_chunk: # 如果當前塊已有內容,先加換行符curr_chunk += '\n'curr_len += 1 # 換行符算1個tokencurr_chunk += line # 添加當前行文本curr_len += line_len # 更新當前塊的token長度# 情況3:當前行無法加入當前塊,需要開始新塊else:# 保存當前塊if curr_chunk:chunk_text.append(curr_chunk)# 開始新塊,添加與前一塊的重疊內容if chunk_text: # 如果已有塊,添加重疊部分prev_chunk = chunk_text[-1]cover_part = prev_chunk[-cover_content:] if len(prev_chunk) > cover_content else prev_chunkcurr_chunk = cover_part + '\n' + line# 計算新塊的初始token長度(重疊部分+換行符+當前行)curr_len = len(enc.encode(cover_part)) + 1 + line_lenelse: # 如果是第一個塊,直接添加當前行curr_chunk = linecurr_len = line_len# 添加最后一個未處理的塊(如果有內容)if curr_chunk:chunk_text.append(curr_chunk)return chunk_text@classmethoddef read_file_content(cls, file_path: str):"""根據文件類型讀取內容(目前僅支持txt文件):param file_path: 文件路徑:return: 文件內容字符串:raises ValueError: 如果文件類型不支持"""if file_path.endswith('.txt'):return cls.read_text(file_path)else:raise ValueError("Unsupported file type") # 拋出不支持文件類型的異常@classmethoddef read_text(cls, file_path: str):"""讀取文本文件內容:param file_path: txt文件路徑:return: 文件內容字符串"""# 使用utf-8編碼打開并讀取文件with open(file_path, 'r', encoding='utf-8') as file:return file.read()class Documents:"""讀取已分類的JSON格式文檔的類用于獲取預先處理好的JSON格式內容"""def __init__(self, path: str = '') -> None:"""初始化Documents實例:param path: JSON文件路徑,默認為空字符串"""self.path = path # 存儲JSON文件路徑def get_content(self):"""讀取并解析JSON文件內容:return: 解析后的JSON數據(通常為字典或列表)"""with open(self.path, mode='r', encoding='utf-8') as f:content = json.load(f) # 加載并解析JSON數據return content
2. 文本片段向量化?
以下代碼文件主要實現了文本片段向量化相關功能,核心是將文本轉換為數值向量并提供向量相似度計算能力,具體包括:
-
定義了抽象基類
BaseEmbeddings,規定了向量提取模型(嵌入模型)的基本接口:- 存儲模型路徑的初始化方法
- 抽象方法
get_embedding(需子類實現文本到向量的轉換) - 類方法
cosine_similarity(計算兩個向量的余弦相似度,衡量文本相似度)
-
實現了具體子類
SentenceEmbedding:- 基于Sentence-BERT模型實現文本嵌入功能
- 支持從Hugging Face或ModelScope加載預訓練模型
- 實現
get_embedding方法,將文本預處理后轉換為向量
-
提供了測試代碼:
- 初始化默認模型(sentence-transformers/all-MiniLM-L6-v2)
- 演示文本嵌入過程并輸出向量維度和示例值
- 向量輸出維度默認為384
總之,該代碼整體功能是將文本轉化為計算機可理解的向量表示,為后續的文本相似度計算、語義搜索等任務提供基礎。
# Embeddings.py
from typing import List
import numpy as npclass BaseEmbeddings:"""嵌入模型的基類,定義了所有嵌入模型應實現的基本接口作為抽象基類,不能直接實例化,需通過子類實現具體功能"""def __init__(self, path: str) -> None:"""初始化嵌入基類,存儲模型或數據的路徑Args:path (str): 模型或數據的路徑,可以是本地路徑或遠程倉庫地址"""self.path = path # 存儲模型路徑供后續使用def get_embedding(self, text: str) -> List[float]:"""獲取文本的嵌入向量表示的抽象方法子類必須實現此方法以提供具體的嵌入計算邏輯Args:text (str): 需要轉換為嵌入向量的輸入文本Returns:List[float]: 文本對應的嵌入向量,以浮點數列表形式返回Raises:NotImplementedError: 如果子類未實現此方法則會拋出此異常"""# 拋出未實現異常,強制子類實現該方法raise NotImplementedError@classmethoddef cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:"""計算兩個向量之間的余弦相似度余弦相似度是衡量兩個向量方向相似性的指標,值越接近1表示方向越相似Args:vector1 (List[float]): 第一個向量vector2 (List[float]): 第二個向量Returns:float: 兩個向量的余弦相似度,范圍在[-1, 1]之間1表示完全相似,-1表示完全相反,0表示正交"""# 將輸入的Python列表轉換為numpy數組,并指定數據類型為float32以節省內存v1 = np.array(vector1, dtype=np.float32)v2 = np.array(vector2, dtype=np.float32)# 檢查向量中是否包含無窮大或NaN值,這些值會導致計算錯誤if not np.all(np.isfinite(v1)) or not np.all(np.isfinite(v2)):return 0.0 # 存在無效值時返回0表示無相似性# 計算兩個向量的點積(內積)dot_product = np.dot(v1, v2)# 計算每個向量的L2范數(歐幾里得長度)norm_v1 = np.linalg.norm(v1)norm_v2 = np.linalg.norm(v2)# 計算兩個向量范數的乘積作為分母magnitude = norm_v1 * norm_v2# 處理分母為0的特殊情況(避免除以零錯誤)if magnitude == 0:return 0.0 # 零向量之間的相似度定義為0# 返回余弦相似度:點積除以范數乘積return dot_product / magnitudeclass SentenceEmbedding(BaseEmbeddings):"""基于Sentence-BERT的句子嵌入實現類繼承自BaseEmbeddings,實現了具體的句子嵌入計算功能"""def __init__(self, path: str = "sentence-transformers/all-MiniLM-L6-v2") -> None:"""初始化SentenceEmbedding實例,加載指定的句子嵌入模型Args:path (str, optional): 模型路徑,默認為預訓練模型"sentence-transformers/all-MiniLM-L6-v2"可以是modelscope模型倉庫名稱或本地模型路徑"""# 調用父類的初始化方法,存儲模型路徑super().__init__(path)try:from sentence_transformers import SentenceTransformer# 利用modelscope加速下載from modelscope import snapshot_downloadmodel_name = path # 模型名稱/路徑# 從模型倉庫下載模型到本地(如果本地已存在則直接使用)model_dir = snapshot_download(model_name)# 初始化SentenceTransformer模型實例self.model = SentenceTransformer(model_dir)except Exception as e:# 捕獲所有可能的異常并包裝為運行時錯誤,提供更明確的錯誤信息raise RuntimeError(f"加載SentenceTransformer模型失敗: {str(e)}")def get_embedding(self, text: str) -> List[float]:"""實現父類的抽象方法,獲取文本的嵌入向量Args:text (str): 需要轉換為嵌入向量的輸入文本Returns:List[float]: 文本對應的嵌入向量,以浮點數列表形式返回"""# 文本預處理:將換行符替換為空格,避免模型處理換行符可能帶來的問題text = text.replace("\n", " ")# 使用加載的模型對文本進行編碼,獲取嵌入向量(numpy數組格式)embedding = self.model.encode(text)# 將numpy數組轉換為Python列表并返回return embedding.tolist()# 當腳本作為主程序運行時執行以下代碼
if __name__ == "__main__":# 創建SentenceEmbedding實例,使用默認模型embedding = SentenceEmbedding()# 定義測試文本text = "這是一個測試文本"# 獲取文本的嵌入向量vectors = embedding.get_embedding(text)# 打印嵌入向量的維度和前10個元素,驗證功能是否正常print(f"嵌入向量維度: {len(vectors)}")print(f"嵌入向量示例: {vectors[:10]}...")
3. 向量存儲與知識庫構建?
完成文檔切分與Embedding模型加載后,需構建向量數據庫存儲文檔片段及其向量表示,并設計檢索模塊實現查詢響應。以下代碼文件實現了一個向量存儲與知識庫構建類,主要功能如下:
- 管理文檔及其對應的向量:存儲文本文檔及其對應的向量表示
- 向量生成:通過文本片段向量化將文檔轉換為向量
- 持久化存儲:將文檔和向量數據保存到本地文件系統,也可從本地加載
- 相似度計算:提供向量間的余弦相似度計算功能
- 相似性查詢:根據輸入的查詢文本,找到最相似的前k個文檔
# VectorBase.py
import os
from typing import List
import json
from Embeddings import BaseEmbeddings
import numpy as np
# 導入進度條庫,用于顯示處理進度
from tqdm import tqdmclass VectorStore:"""向量存儲類,用于管理文檔及其對應的向量表示提供向量計算、持久化存儲、相似度查詢等功能"""def __init__(self, document: List[str] = ['']) -> None:"""初始化向量存儲實例參數:document: 初始文檔列表,默認為包含一個空字符串的列表"""self.document = document # 存儲文檔內容的列表self.vectors = [] # 存儲文檔對應的向量表示def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:"""使用嵌入模型為文檔生成向量表示參數:EmbeddingModel: 用于生成嵌入向量的模型實例,需繼承自BaseEmbeddings返回:文檔列表對應的向量列表,每個向量是一個浮點數列表"""self.vectors = []# 使用tqdm顯示處理進度,desc設置進度條描述for doc in tqdm(self.document, desc="Calculating embeddings"):# 為每個文檔生成嵌入向量并添加到列表self.vectors.append(EmbeddingModel.get_embedding(doc))return self.vectorsdef persist(self, path: str = 'storage'):"""將文檔和向量數據持久化存儲到文件系統參數:path: 存儲目錄路徑,默認為'storage'"""# 如果目錄不存在則創建if not os.path.exists(path):os.makedirs(path)# 保存文檔內容到JSON文件with open(f"{path}/doecment.json", 'w', encoding='utf-8') as f:json.dump(self.document, f, ensure_ascii=False)# 如果存在向量數據,則保存向量到JSON文件if self.vectors:with open(f"{path}/vectors.json", 'w', encoding='utf-8') as f:json.dump(self.vectors, f)def load_vector(self, path: str = 'storage'):"""從文件系統加載已持久化的文檔和向量數據參數:path: 存儲目錄路徑,默認為'storage'"""# 加載向量數據with open(f"{path}/vectors.json", 'r', encoding='utf-8') as f:self.vectors = json.load(f)# 加載文檔內容with open(f"{path}/doecment.json", 'r', encoding='utf-8') as f:self.document = json.load(f)def get_similarity(self, vector1: List[float], vector2: List[float]) -> float:"""計算兩個向量之間的余弦相似度參數:vector1: 第一個向量vector2: 第二個向量返回:兩個向量的余弦相似度,值越接近1表示越相似"""return BaseEmbeddings.cosine_similarity(vector1, vector2)def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:"""根據查詢文本,返回最相似的k個文檔參數:query: 查詢文本EmbeddingModel: 用于生成嵌入向量的模型實例k: 返回的相似文檔數量,默認為1返回:與查詢文本最相似的k個文檔列表"""# 生成查詢文本的向量表示query_vector = EmbeddingModel.get_embedding(query)# 計算查詢向量與所有文檔向量的相似度result = np.array([self.get_similarity(query_vector, vector)for vector in self.vectors])# 對相似度排序,取前k個最相似的文檔并返回# argsort()[-k:][::-1] 用于獲取相似度最高的k個文檔的索引return np.array(self.document)[result.argsort()[-k:][::-1]].tolist()
4. 生成回答
這段代碼實現了基于DeepSeek模型的RAG問答助手,可結合上下文按規則生成回答,包含模型加載與對話示例。為便于擴展,定義了含chat和oad_model法的基類BaseModel,本地開源模型需實現load_model方法。
# LLM.py
from typing import List
from unsloth import FastLanguageModel
# torch2.5版本以下防止unsloth加載出問題
from transformers import modeling_utils
if not hasattr(modeling_utils, "ALL_PARALLEL_STYLES") or modeling_utils.ALL_PARALLEL_STYLES is None:modeling_utils.ALL_PARALLEL_STYLES = ["tp", "none","colwise",'rowwise']from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())RAG_PROMPT_TEMPLATE="""# 你是一個專業的RAG回答助手## 可參考的上下文:{context}## 請嚴格按以下規則回答:1. 必須優先使用上下文信息,禁止主動引入外部知識
2. 必須對問題和上下文進行理解,而不僅僅是憑借字面意思回答。在提供的上下文中,仔細查找與問題核心直接相關的語句。同時,注意查找能支持推理出答案的信息(例如:因果關系、定義、屬性描述、時間順序、比較關系等)
3. 回答邏輯:- 若上下文直接包含問題答案:輸出答案并引用原文- 若上下文否定問題陳述:回答"不對"并引用原文- 若不能通過上下文回答問題: 回答"上下文未提供相關信息"- 注意代詞(它、他、他們、這個、那個)在上下文中的具體指代對象
4. 輸出格式:- 僅用中文回答- 答案應簡潔直接,聚焦于回答問題本身- 禁止主觀解釋- 必須標注引用位置(例:據上下文第X段)
"""class BaseModel:def __init__(self, model_name) -> None:self.model_name = model_namedef chat(self, prompt, history, content) -> str:passdef load_model(self):passclass DeepSeekChat(BaseModel):def __init__(self, model_name: str = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B") -> None:super().__init__(model_name)self.model, self.tokenizer = self.load_model()self.max_length = 2048self.temperature = 0.1def load_model(self):try:# 原始模型地址:https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-1.5B# 1. 利用modelscope庫下載模型到本地,然后通過unsloth加載模型from modelscope import snapshot_download# 加載預訓練模型 ,利用modelscope庫model_name = self.model_name # 假設這是支持分詞的模型名稱# 下載模型model_dir = snapshot_download(model_name)# 從huggingface的鏡像https://hf-mirror.com/中下載模型到本地# model_dir= "./DeepSeek-R1-Distill-Qwen-1.5B"# 設置最大序列長度,表示模型在一次前向傳遞中可以處理的最大令牌數量。max_seq_length = 2048 # https://hf-mirror.com/# 調用FastLanguageModel.from_pretrained()方法加載預訓練的模型和對應的Tokenizer(分詞器)。model, tokenizer = FastLanguageModel.from_pretrained(model_name = model_dir, # 從hf中直接調用:model_name = unsloth/DeepSeek-R1-Distill-Qwen-1.5Bmax_seq_length = max_seq_length, # 最大序列長度,表示模型在一次前向傳遞中可以處理的最大令牌數量。dtype = None, # 自動檢測(BF16或FP16)。BF16范圍大,FP16精度高local_files_only=True # 只用本地文件)except Exception as e:raise RuntimeError(f"加載 DeepSeek 模型失敗")return model, tokenizerdef chat(self, prompt: str, history: List[dict], content: List[str]) -> str:# 構建上下文(優化格式)formatted_context = "\n".join([f"【上下文第{idx}段】{text}" for idx, text in enumerate(content, 1) if text.strip()])# 構建系統提示system_prompt = RAG_PROMPT_TEMPLATE.format(context=formatted_context.strip())# 構建完整消息隊列messages = []# 1. 添加當前系統提示messages.append({"role": "system", "content": system_prompt})# 2. 添加歷史對話(過濾舊系統消息)for msg in history:if msg["role"] != "system": # 過濾歷史中的系統消息messages.append(msg)# 3. 添加當前用戶問題messages.append({"role": "user", "content": prompt})# 應用對話模板,添加生成引導符inputs = self.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = self.tokenizer(inputs, return_tensors="pt", padding=True, truncation=True).to("cuda")input_length = inputs["input_ids"].shape[1] # 記錄輸入長度用于截取生成內容outputs = self.model.generate(**inputs,max_new_tokens=self.max_length,temperature=self.temperature,pad_token_id=self.tokenizer.eos_token_id )# 只返回新生成的文本(去掉輸入提示)generated_tokens = outputs[0][input_length:] # 直接截取生成的tokenresponse = self.tokenizer.decode(generated_tokens, skip_special_tokens=True).strip()return response# 示例:使用 DeepSeekChat 進行對話
def main():# 初始化模型print("正在加載 DeepSeek 模型...")chat_model = DeepSeekChat() # 也可以嘗試其他 DeepSeek 模型# 示例上下文,內容為假數據context = ["""DeepSeek 是深度求索公司開發的大語言模型。當前最新版本是 DeepSeek-V3,知識截止日期為2024年7月。該模型支持最大128K上下文長度,擅長中文和英文任務。"""]# 示例對話歷史history = [{"role": "system", "content": "你是一個樂于助人的AI助手。"},{"role": "user", "content": "你好,請介紹一下你自己"},{"role": "assistant", "content": "我是基于DeepSeek模型構建的AI助手,很高興為您服務。"}]# 第一個問題question1 = "DeepSeek模型最新版本的知識截止日期是什么?"print(f"\n用戶提問: {question1}")response1 = chat_model.chat(question1, history, context)print(f"AI回答: {response1}")# 將回答添加到歷史記錄中history.append({"role": "user", "content": question1})history.append({"role": "assistant", "content": response1})# 第二個問題(測試歷史對話+上下文)question2 = "它支持最大的上下文長度是多少?" # "它"指代歷史對話中的DeepSeek模型print(f"\n用戶提問: {question2}")response2 = chat_model.chat(question2, history, context)print(f"AI回答: {response2}")if __name__ == "__main__":main()
5. 調用代碼
以下代碼實現了一個簡單RAG系統的調用流程:生成測試文件后,智能加載或新建向量數據庫,再通過DeepSeek模型結合檢索到的相關上下文與對話歷史,依次處理預設問題并生成回答,核心是借助向量檢索提升回答準確性。
# main.py
import os
from Generate import generate_rag_test_files
from VectorBase import VectorStore
from Utils import ReadFiles
from LLM import DeepSeekChat
from Embeddings import SentenceEmbeddingdef main():# 生成測試文件folder_name = generate_rag_test_files()# 向量存儲路徑vector_path = 'storage'# 初始化嵌入模型embedding = SentenceEmbedding()# 智能加載向量存儲:存在則加載,否則生成并持久化if os.path.exists(vector_path):print("加載本地向量數據庫...")vector = VectorStore([]) # 空文檔初始化,后續加載本地數據vector.load_vector(vector_path)else:print("生成新的向量數據庫...")# 讀取并分割文檔docs = ReadFiles(folder_name).get_content(max_token_len=600, cover_content=150)vector = VectorStore(docs)# 生成并持久化向量vector.get_vector(EmbeddingModel=embedding)vector.persist(path=vector_path)# 初始化對話模型chat = DeepSeekChat()# 初始化對話歷史chat_history = []# 待處理的問題列表questions = ["HelloWorld公司三線城市住宿上限是多少?","HelloWorld公司差旅報銷在出差結束后20天提交,有什么后果?",# "CleanAir X5空氣凈化器若凈化效果下降,怎么解決?",# "地球自轉周期是48小時嗎?",# "太陽系行星距離太陽第四近的是哪個?"]# 依次處理每個問題,維護對話歷史for idx, question in enumerate(questions, 1):print(f"\n===== 問題 {idx} =====")print(f"用戶: {question}")# 檢索相關上下文content = vector.query(question, EmbeddingModel=embedding, k=2)# 調用模型生成回答(傳入歷史記錄)response = chat.chat(question, chat_history, content)print(f"AI: {response}")# 更新對話歷史chat_history.append({"role": "user", "content": question})chat_history.append({"role": "assistant", "content": response})if __name__ == "__main__":main()
3.2 主流開源RAG框架概覽
前文介紹的自建RAG系統更適用于學習與演示場景;而在實際開發過程中,基于成熟的開源框架搭建RAG系統則是更優選擇。以下為當前主流的15個開源RAG框架排名及核心特性解析:
| 排名 | 框架 | 核心聚焦 | 最佳適用場景 | 核心功能 | 部署復雜度 | GitHub星標數 |
|---|---|---|---|---|---|---|
| 1 | LangChain | 組件鏈合 | 通用RAG應用 | 數據連接、模型靈活性 | 中 | 105k |
| 2 | Dify | 可視化開發 | 非技術用戶、企業 | 可視化編輯器、多模型支持 | 低 | 90.5k |
| 3 | RAGFlow | 文檔處理 | 復雜文檔handling | 深度文檔理解、GraphRAG | 中 | 48.5k |
| 4 | LlamaIndex | 數據索引 | 自定義知識源 | 靈活連接器、自定義索引 | 低 | 40.8k |
| 5 | Milvus | 向量存儲 | 大規模向量搜索 | 高級向量搜索、水平擴展 | 中 | 33.9k |
| 6 | mem0 | 持久記憶 | 需上下文保留的助手 | 多級記憶、自動處理 | 低 | 27.3k |
| 7 | DSPy | 提示優化 | 需自我改進的系統 | 自動優化、模塊化 | 中 | 23k |
| 8 | Haystack | 管道編排 | 生產應用 | 靈活組件、技術無關 | 中 | 20.2k |
| 9 | LightRAG | 性能 | 速度關鍵應用 | 簡單架構、高效檢索 | 低 | 14.6k |
| 10 | LLMWare | 資源效率 | 邊緣/CPU部署 | 小型模型、并行解析 | 低 | 12.7k |
| 11 | txtai | 一體化解決方案 | 簡化實現 | 嵌入數據庫、多模態 | 低 | 10.7k |
| 12 | RAGAS | 評估 | RAG系統測試 | 客觀指標、測試生成 | 低 | 8.7k |
| 13 | R2R | 代理式RAG | 復雜查詢 | 多模態攝入、代理推理 | 中 | 6.3k |
| 14 | Ragatouille | 高級檢索 | 高精度搜索 | 晚期交互檢索、微調 | 中 | 3.4k |
| 15 | FlashRAG | 研究 | 實驗與基準測試 | 預處理數據集、多算法 | 中 | 2.1k |
以上內容參考自:15 Best Open-Source RAG Frameworks in 2025。不同開源RAG框架的核心差異主要體現在技術定位與功能特性上,在進行框架選型時,需結合應用規模、性能指標、開發周期等實際需求綜合判斷。需要特別強調的是,無論選擇何種框架,知識庫的質量始終是決定RAG系統效果的核心因素。
具體選型建議如下:
- 若以易用性為優先考量:推薦Dify、LlamaIndex、mem0、LightRAG、txtai
- 針對文檔密集型應用:優先考慮RAGFlow、LLMWare
- 面向大規模生產部署:適合選擇Milvus、Haystack、LangChain
- 硬件資源受限場景:優先選用LLMWare、LightRAG
- 存在復雜推理需求的場景:建議探索R2R、DSPy
- 需進行系統評估的場景:推薦使用RAGAS
- 研究與實驗場景:適合選擇FlashRAG
4 參考
- 大語言模型基礎知識
- Retrieval-Augmented Generation for AI-Generated Content: A Survey
- Retrieval-Augmented Generation for Large Language Models: A Survey
- RAG起源、演進與思考
- RAG到底咋工作的
- 16 Techniques to Supercharge and Build Real-world RAG Systems
- Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring
- 17種RAG架構實現原理與選型
- 一篇搞明白RAG的幾種不同類型
- Traditional RAG vs. HyDE
- Seven Failure Points When Engineering a Retrieval Augmented Generation System
- Full-model Fine-tuning vs. LoRA vs. RAG
- Happy-LLM
- 15 Best Open-Source RAG Frameworks in 2025

)
)




、隨機搜索)


)

)






