目錄
前言
一、vector 的框架
二、基礎實現
1、無參的構造:
2、析構函數
?3、size
4、capacity
5、reserve擴容
?6、push_back
?7、迭代器
?8、?operator[ ]?
?9、pop_back
10、insert 以及 迭代器失效問題
11、erase 以及 迭代器失效問題
12、resize
13、 拷貝構造
14、賦值運算符重載
15、initializer_list 構造
16、迭代器區間初始化
?17、n個val 構造
前言
路漫漫其修遠兮,吾將上下而求索;
一、vector 的框架
此處框架的實現,參考?sgi slt3.0 中vector 底層源碼;
由于尚未學習空間配置器的相關知識,在模擬實現vector時暫時使用?new?進行替代(注:這種做法雖然不會產生實質性影響,但相比使用空間配置器,new在效率方面會稍遜一籌)。
namespace zjx
{template<class T>class vector{public:typedef T* iterator;private:iterator _start;iterator _finish;iterator _end_of_storage;};
}我們可以將迭代器理解為像指針一樣的東西,但其本質可能并不是指針;在?vector 、string 中,用指針實現,但是也不一定其迭代器就是指針(在有些平臺下不是,eg. VS庫、Linux 中實現);可以利用 typeid 在VS中看一下vector 的迭代器類型,如下:
int main()
{std::vector<int> v;cout << typeid(std::vector<int>::iterator).name() << endl;return 0;
}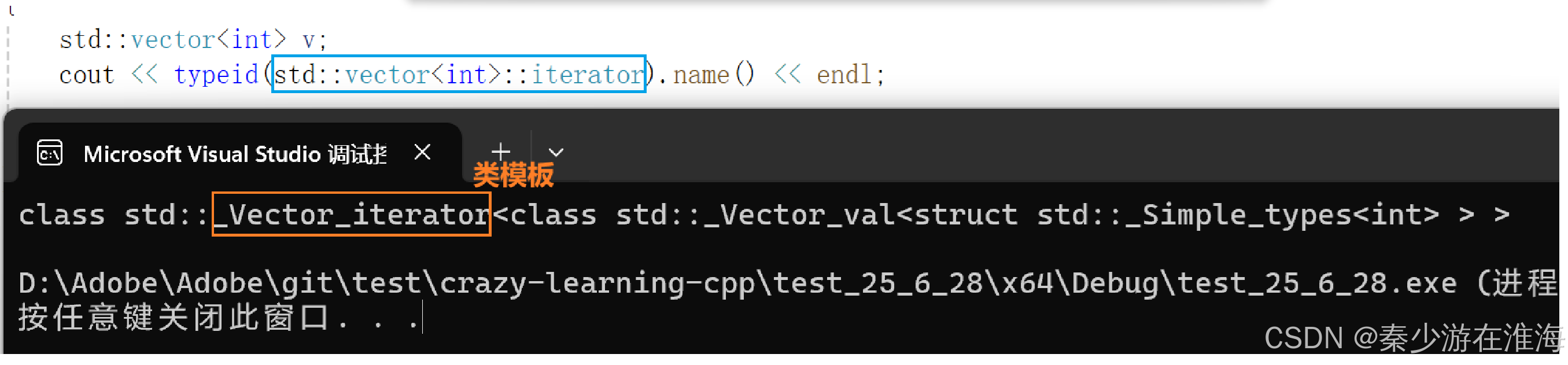
可見,在VS庫中vector 的迭代器用一個自定義類型去封裝了原始指針;
- 注:在typeid() 中給一個對象或者類型,可通過 typeid 看其真實類型;
還需要注意的是,const迭代器并不是指在 iterator 的基礎上前面加 const ,如下:
const zjx::vector<int>::iterator it = v.begin();int* const it = v.begin();//const 修飾了指針本身這兩個const表達的含義相同。無論是在原始類型前還是typedef后的類型前添加const,只要是在類型前面添加 const ,修飾的都是迭代器本身。但需要注意的是,const迭代器的作用不是防止迭代器自身被修改,而是限制其所指向內容不可被修改。因此,針對?const迭代器需要專門定義一個新的類型,如下:
typedef const T* const_iterator;修改后 vector的框架:
namespace zjx
{template<class T>class vector{public:typedef T* iterator;typedef const T* const_iterator;private:iterator _start;iterator _finish;iterator _end_of_storage;};
}二、基礎實現
1、無參的構造:
vector():_start(nullptr),_finish(nullptr),_end_of_storage(nullptr){}2、析構函數
~vector(){delete[] _start;_start = _finish = _end_of_storage = nullptr;}?3、size
需要加上const 來修飾this指針,保證this 指針是否被const修飾均可以調用;?
size_t size()const{return _finish - _start;}4、capacity
需要加上const 來修飾this指針,保證this 指針是否被const修飾均可以調用;?
size_t capacity() const{return _end_of_storage - _start;}5、reserve擴容
需要注意的是,不能直接使用realloc 進行擴容,必須用new 手動實現realloc異地擴容的邏輯;
這是因為:
- 當 T 為內置類型的時候,reserve 使用realloc 、new 都是沒有問題的;即使使用realloc 開辟空間 delete[] 釋放空間也是不會報錯的;
- 當T 為自定義類型時,開辟的空間就需要調用該自定義類型的構造函數進行初始化(必須進行初始化,eg.T為string 時,如果不初始化,那么string里面的指針、_size、_capacity 均為隨機值,沒初始化就沒有辦法正常使用string);同樣地,當T為自定義類型,釋放此塊的空間不能使用free ,而是應該使用 delete[] ,這是因為內置類型可能會涉及資源,需要調用析構函數否則就會造成內存泄漏;
reserve代碼:
void reserve(size_t n){if (n > capacity()){T* tmp = new T[n];//開辟新空間memcpy(tmp, _start, sizeof(T) * size());//拷貝數據delete[] _start;//釋放舊空間//因為size() 的是通過 _finish-_start 計算的來的_finish = tmp + size();//所以需要先更新_finish ,然后才是 _start_start = tmp;_end_of_storage = _start + n;}}上述代碼在處理變量 _start 和 _finish 的時候,必須先處理 _finish ,因為_finish = tmp + size(); 而 size() 通過 _finish - _start 計算得來的;如果先處理 _start 就會影響 size() 的計算;還有一種處理方式,提前通過變量保存擴容之前size() 的值,這樣在處理變量的時候就不用顧及處理的先后順序,更推薦使用這種方式;
reserve 參考代碼:
void reserve(size_t n){if (n > capacity()){size_t oldSize = size();T* tmp = new T[n];memcpy(tmp, _start, sizeof(T) * oldSize);delete[] _start;_start = tmp;_finish = _start + oldSize;_end_of_storage = _start + n;}}實際上,此處實現的reserve 還存在一些小 bug , 如果想要快速了解,請跳轉到 下文 "14、賦值運算符重載";
?6、push_back

和 string 一樣,vector 也沒有提供push_front、pop_front ;因為對于vector 這種數組結構而言,頭插、頭刪需要挪動數據,其效率很低 , 提供頭插、頭刪沒有意義并且完全可以使用insert 、erase 來間接實現頭插、頭刪,所以沒有單獨實現的必要;
push_back 的參考代碼:
void push_back(const T& x){//判斷是否需要擴容if (size() + 1 > capacity()){reserve(capacity() == 0 ? 4 : 2 * capacity());}*_finish = x;++_finish;}?7、迭代器
Q: 為什么會有迭代器這樣的用法?
- 1、下標 + [ ] 這種訪問形式不能適用于所有容器;eg.list?
- 2、迭代器是STL的六大組件之一;
借助迭代器可以實現算符與容器之間的解耦,用迭代器訪問數據的方式在各個容器之中均是相通的;
7.1 begin

iterator begin(){return _start;}const_iterator begin() const{return _start;//權限的縮小}
7.2 end

iterator end(){return _finish;}const_iterator end()const{return _finish;//權限的縮小}?8、?operator[ ]?
運算符重載的意義:可以通過運算符重載來控制整個運算符的行為;
普通版本的operator[ ]:
T& operator[](size_t i){assert(i < size());return _start[i];}const 版本的operator[ ]:
const T& operator[](size_t i) const{assert(i < size());return _start[i];}?9、pop_back
刪除尾部的數據不能直接將尾部的空間直接釋放掉,在C++中,開辟的空間不能局部釋放,只能整體釋放;所以pop_back 的實現: --_finish;?
void pop_back(){assert(_finish > _start);//確保有數據可以刪除--_finish;}?10、insert 以及 迭代器失效問題

vector 的insert 并不像 string 中的insert 那樣提供下標就可以插入,在vector 中使用insert 需要傳迭代器;
insert 實現的思路:1、首先確保pos 合法; 2、判斷空間是否足夠,是否需要擴容; 3、挪動數據;4、插入數據; 5、維護成員變量;
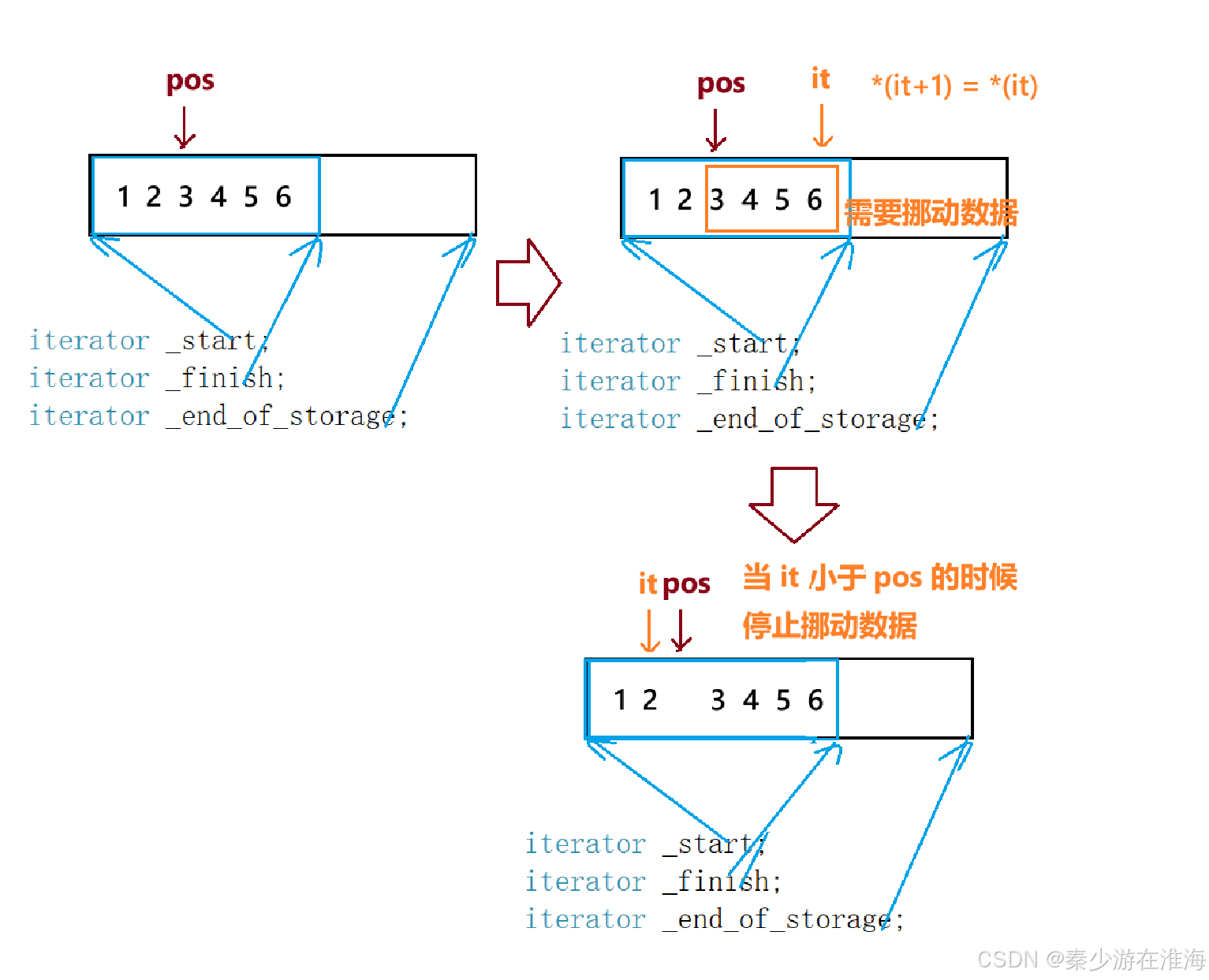
insert 代碼:
void insert(iterator pos, const T& x){assert(pos >= _start);assert(pos <= _finish);//判斷是否需要擴容if (_finish + 1 > _end_of_storage){reserve(capacity() == 0 ? 4 : 2 * capacity());}//挪動數據iterator it = _finish -1 ;while (it >= pos){*(it + 1) = *it;--it;}*pos = x;//放入數據++_finish;//維護成員變量}測試一下:
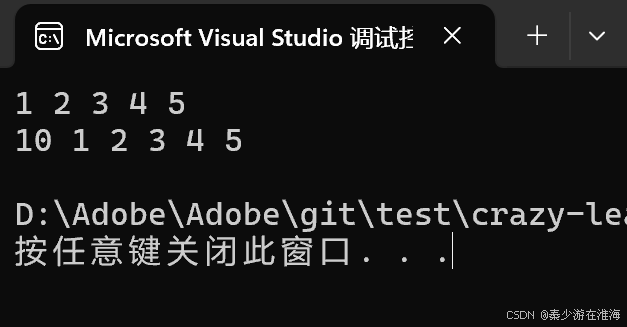
void test3()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;v.insert(v.begin(), 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}
在實現string 的insert的時候,此處的形參pos 不是迭代器而是下標,其類型為size_t ;當pos 為0 的時候,即頭插,如果指針end 等于 _size,那么只有當end<0 循環才能停止;而問題就是因為end 的類型為 size_t ,不會小于0而導致了死循環,即便將end 的類型改為 int , 由于pos 的類型為size_t ,在計算的時候發成隱式類型轉換同樣也會導致死循環;于是乎就有一種十分難受的解決方法:while(end >= (int) pos) .... 而在vector 之中,使用迭代器就沒有像在string 中出現的問題,因為迭代器有可能是自定義類型(eg. list) 也有可能是指針,但不可能會有空指針的;
實際上此處還有一個坑:迭代器失效;
第一層的迭代器失效:
Q:什么是迭代器失效?
上述的測試沒有出錯,但是只需要稍微更改一下:
void test3()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);//v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;v.insert(v.begin(), 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}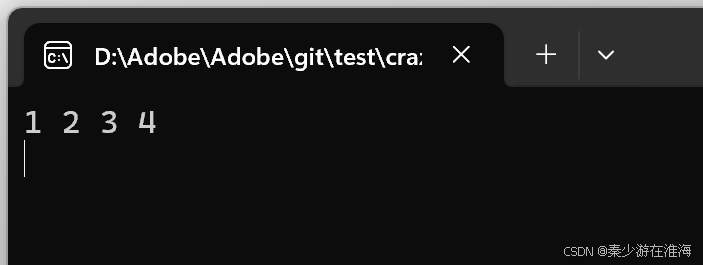
在這個例子之中,insert 第5個數據的時候掛掉了;
Q:為什么在insert 第5個數據的時候程序崩潰了?
- 在第插入第5個數據的時候進行了擴容;
調試看一下:
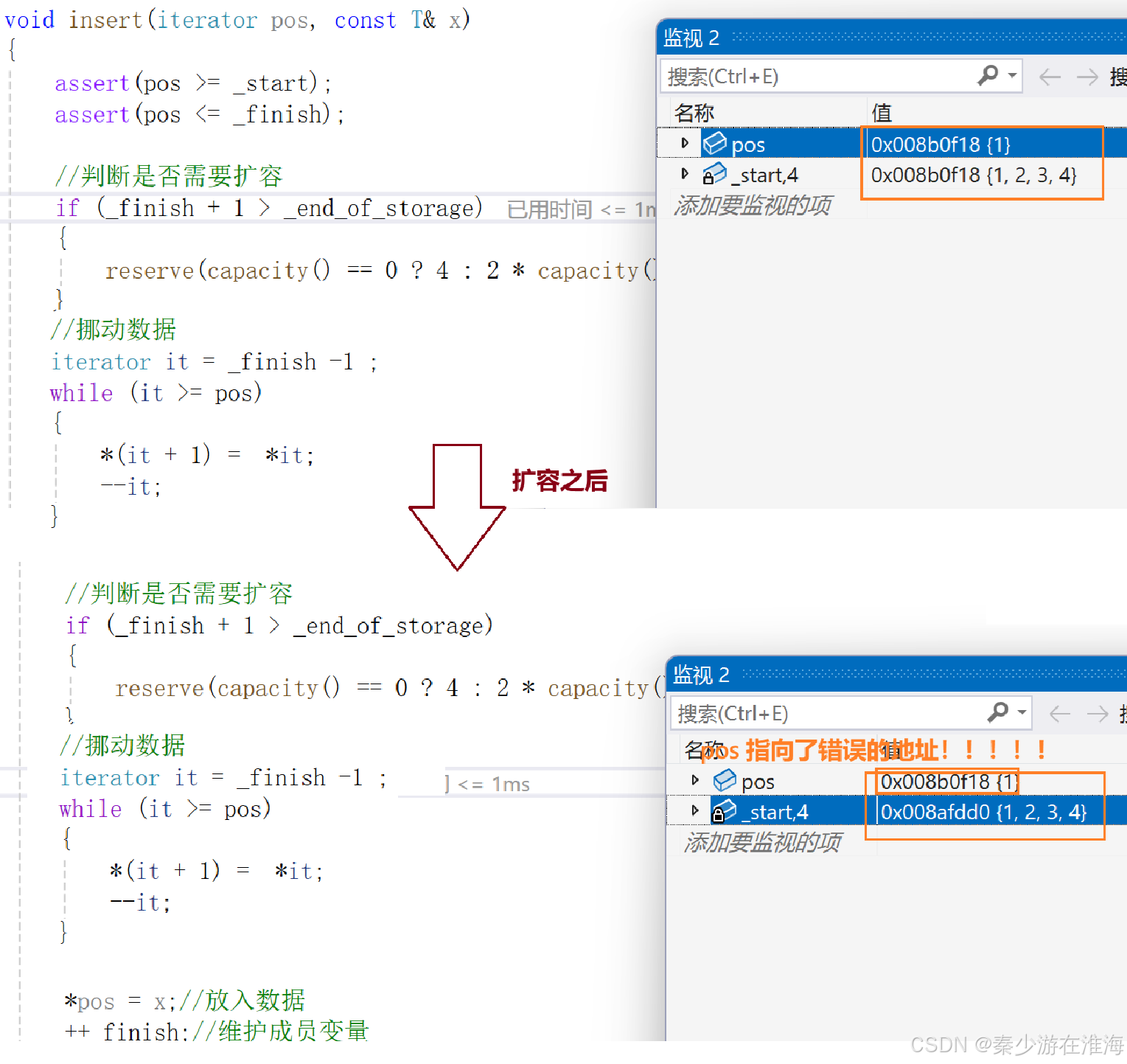
擴容導致pos指向的地址錯誤;
因為reserve 中實現的擴容邏輯是異地擴容,將舊空間中的數據拷貝放入新空間中,然后釋放舊空間,故而 導致 pos 指向的空間不屬于當前數組的空間,pos 變為了野指針;
經典的迭代器失效問題:因為擴容而導致的迭代器失效;
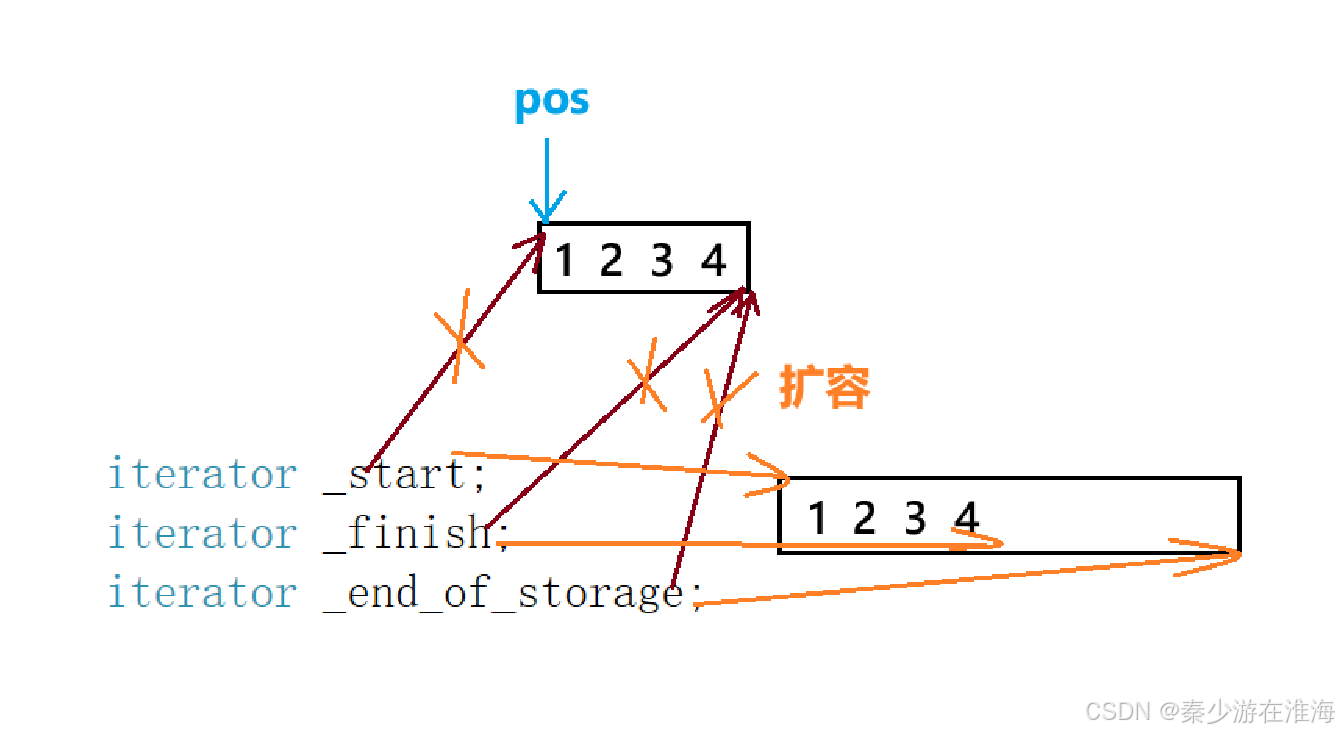
為了解決這個問題,在擴容之后應該更新pos ,那么就需要在擴容之前記錄所要插入位置的下標:
insert 修改代碼如下:
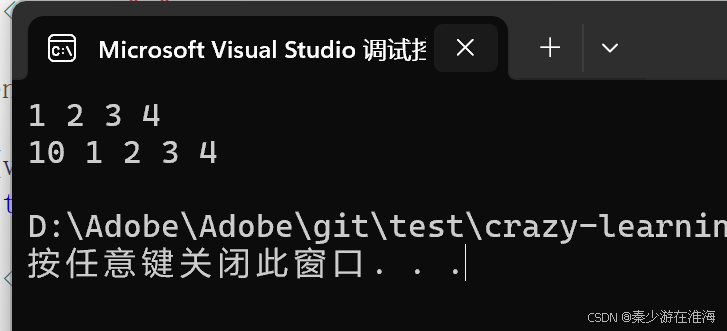
void insert(iterator pos, const T& x){assert(pos >= _start);assert(pos <= _finish);//判斷是否需要擴容if (_finish + 1 > _end_of_storage){size_t len = pos - _start;reserve(capacity() == 0 ? 4 : 2 * capacity());pos = _start + len;//擴容之后更新pos}//挪動數據iterator it = _finish - 1;while (it >= pos){*(it + 1) = *it;--it;}*pos = x;//放入數據++_finish;//維護成員變量}此時再測試一下:
void test3()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);//v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;v.insert(v.begin(), 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}
11、erase 以及 迭代器失效問題
erase 的實現邏輯:1、判斷pos 是否合法;2、空間中有數據可以刪;3、挪動數據;4、維護成員變量
erase代碼:
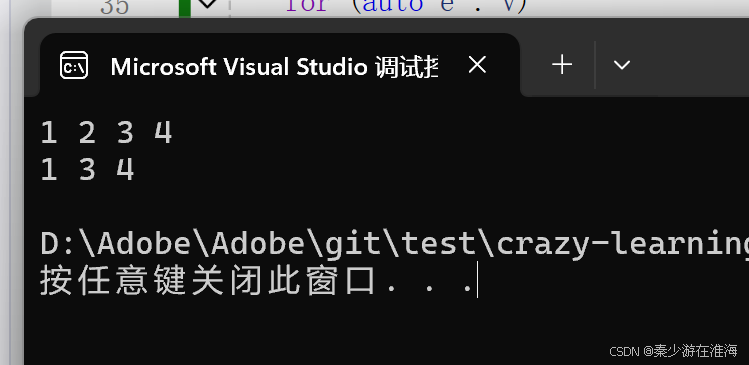
void erase(iterator pos){assert(pos >= _start && pos < _finish);assert(_finish >= _start);//挪動數據iterator it = pos + 1;while (it < _finish){*(it - 1) = *it;++it;}--_finish;//維護成員變量}測試一下:
void test2()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);for (const auto& e : v){cout << e << " ";}cout << endl;//刪除v.erase(v.begin() + 1);for (const auto& e : v){cout << e << " ";}cout << endl;
}
第二層迭代器失效:
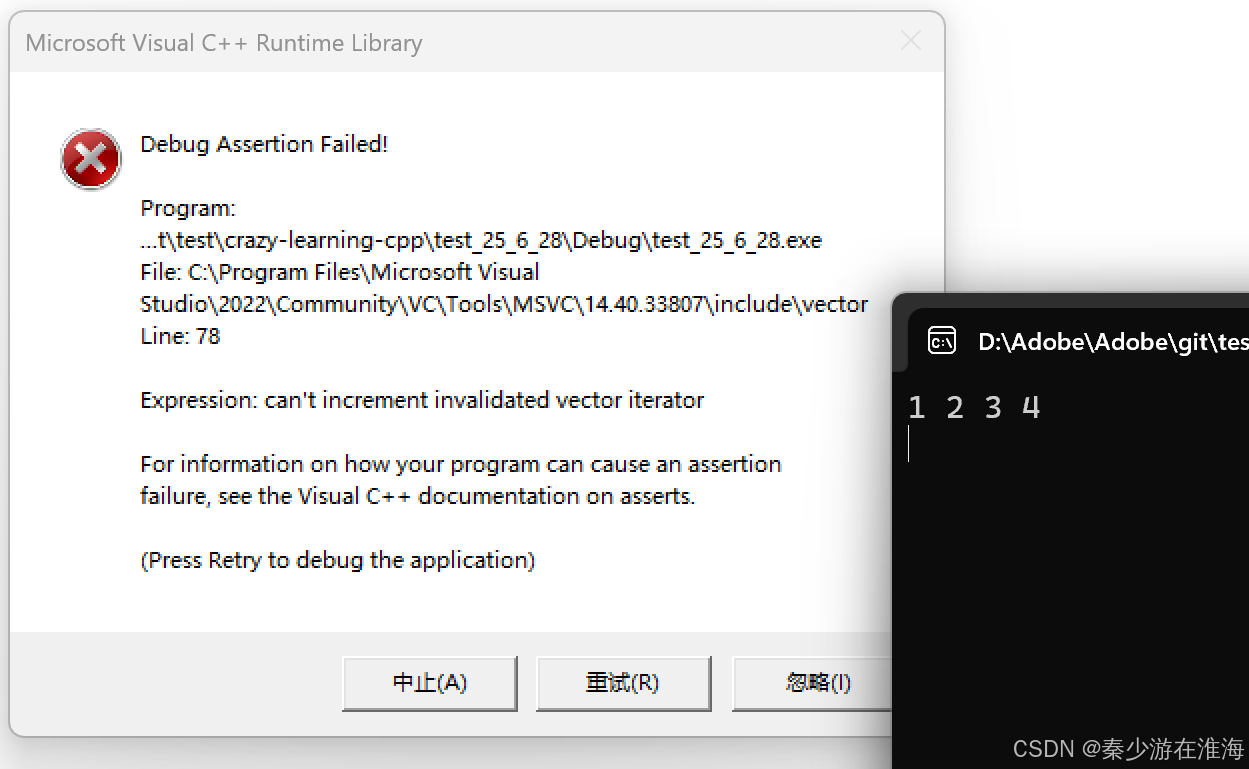
我們先利用庫中的vetcor 來演示迭代器失效,eg.有一堆數據,要求將這些數據中所有的偶數均刪除掉:
void test5()
{std::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;//刪除所有的偶數auto it = v.begin();while (it != v.end()){if (*it % 2 == 0){v.erase(it);}++it;}for (const auto& e : v){cout << e << " ";}cout << endl;
}
在Linux 下運行呢?

在Linux 中運行沒有出現迭代器失效的問題,這是由于在不同的平臺中實現的方式不同;
也正是由于不同的平臺底層的實現上存在差異的,我們在寫代碼的時候并不能依靠這些差異,倘若依賴了這些差異就會導致寫出來的代碼不具有跨平臺性;
Q:為什么這兩個平臺中出現了這么大的差異呢?
代碼邏輯:
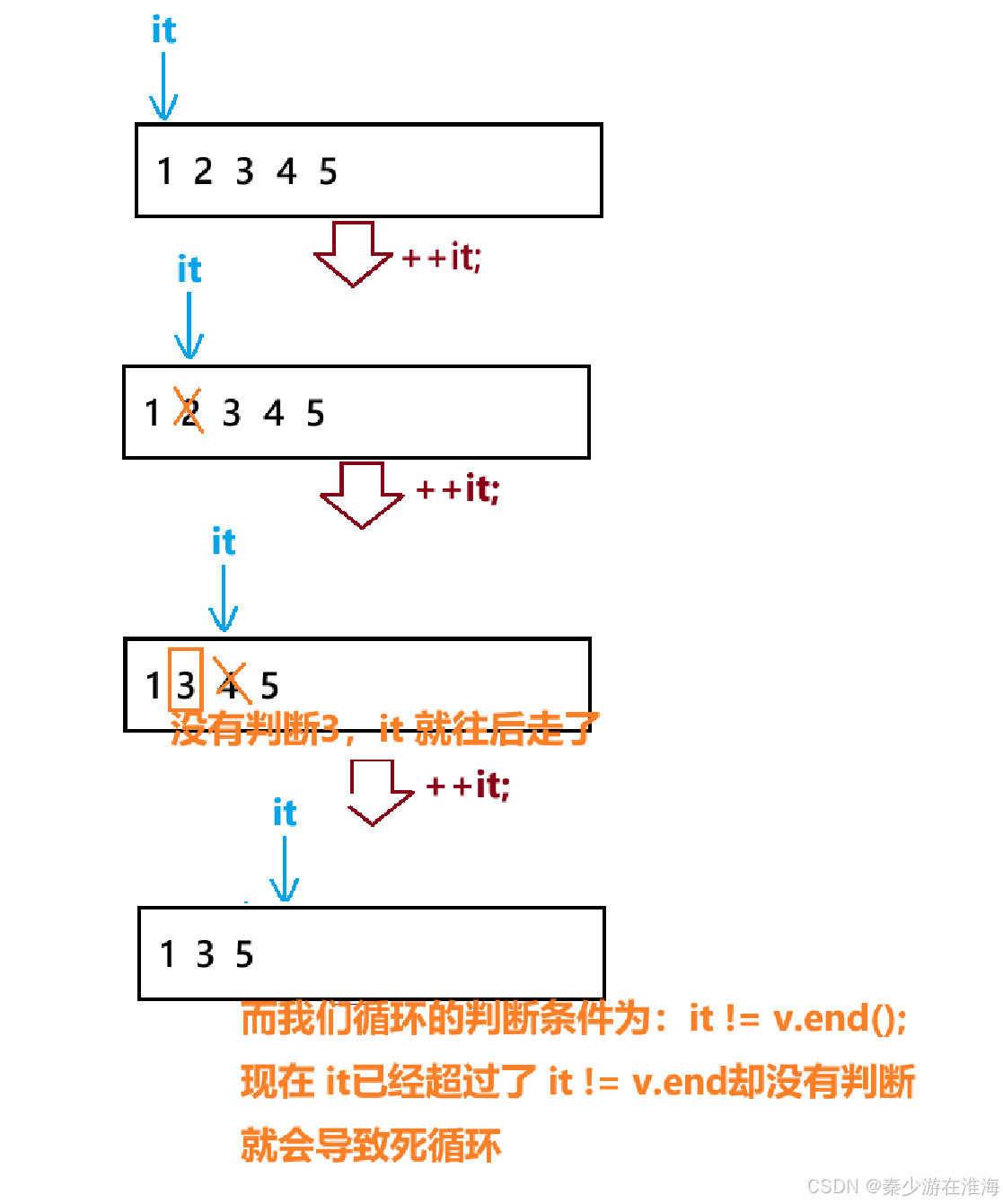
之所以在VS中會報錯,因為VS中有嚴格的檢查機制;而在Linux 中沒有;
并沒有判斷 '3' 這個數據就去判斷 “4‘ ,也就意味著如果該數組中全為偶數,即使在Linux 下能跑,但是不能刪除所有的偶數:

Q:如果最后一個數據為偶數呢?

在Linux中如果最后一個數據為偶數,會發生越界訪問;Linux 中的段錯誤就是越界訪問;
顯然,通過上述分析,我們在刪除偶數的時候,it 指向的數據是偶數,刪除之后 it 就不要再向前走;如果不是偶數, 則++it; 修改如下:
//刪除所有的偶數auto it = v.begin();while (it != v.end()){//分情況討論if (*it % 2 == 0){v.erase(it);}else{++it;}}
在Linux 中測試一下:

成功完成了任務!
在VS中呢?
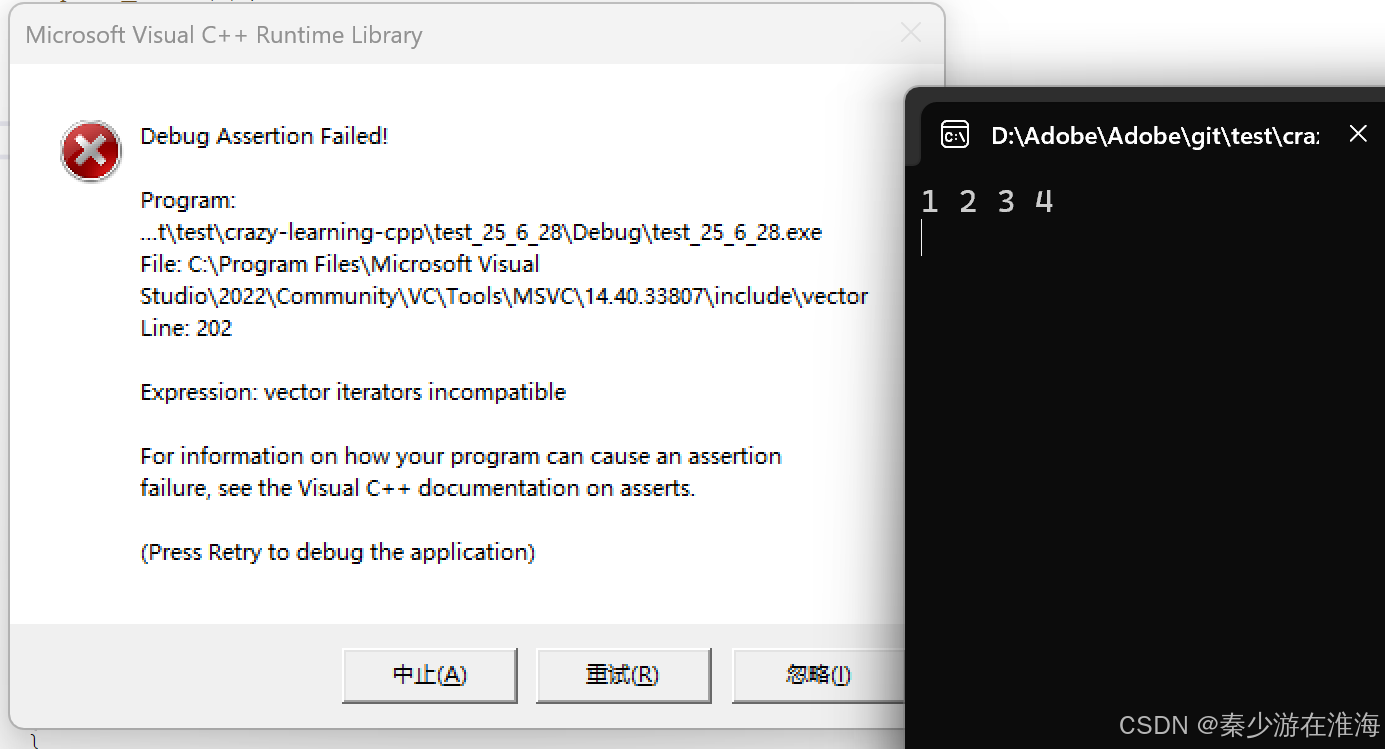
程序還是崩潰的;這是因為在VS中對迭代器的檢查非常嚴酷;
在VS中,insert、erase 之后,均認為其迭代器失效了;而在Linux 中,可以認為erase 之前的迭代器在erase 之后不會失效;
VS并不是單純地使用了一個指針,而是用了一個復雜的類型(自定義類型)進行封裝實現的,在該類中進行了標記,當erase、insert之后,便會認為該迭代器失效,將其標記更改;強制你不能使用該迭代器;
所以erase 之后,不同的平臺實現存在差異,但是統一認為 , erase 之前的指針it 在erase 之后失效了:
- 1、erase(it); 在g++ 下沒有問題,但是在vs 中有問題;
- 2、erase 還存在潛在的問題;
除了g++ 和 vs 這兩個較為常見的C++的兩個編譯器的平臺可能還有其他平臺;例如:在軍工中的項目,他們使用的編譯器是他們自己經過改造過的編譯器,也得認為erase 是失效的;并不知道我們所寫的代碼未來會在哪種平臺上跑,而又要保證每個平臺上運行都沒有問題,就得統一認為erase 前的迭代器在erase 之后就失效了;在有些平臺下不排除erase 還有一種實現:縮容;一般的erase 只挪動數據,但縮容的erase 并不會直接釋放空間,因為內存申請釋放的機制:整個申請整個釋放,所以erase 縮容就需要另外開辟一個更小的空間,將舊空間中刪除過后的數據放入新空間中,然后釋放舊空間,所以erase 也不排除會有野指針的問題,只是我們當前看到的兩個主流平的erase 并未進行縮容;
Q:那我們此時該如何修改?

- 在庫函數中erase 的返回值為iterator ;

erase返回 剛剛被刪除的最后一個數據的下一個位置;
所以erase 的修改如下:
iterator erase(iterator pos){assert(pos >= _start && pos < _finish);assert(_finish >= _start);//挪動數據iterator it = pos + 1;while (it < _finish){*(it - 1) = *it;++it;}--_finish;//維護成員變量return pos;}這樣實現的erase ,無論哪個平臺怎樣實現erase ,均可以更新迭代器以避免迭代器失效的問題;
刪除邏輯的代碼修改如下:
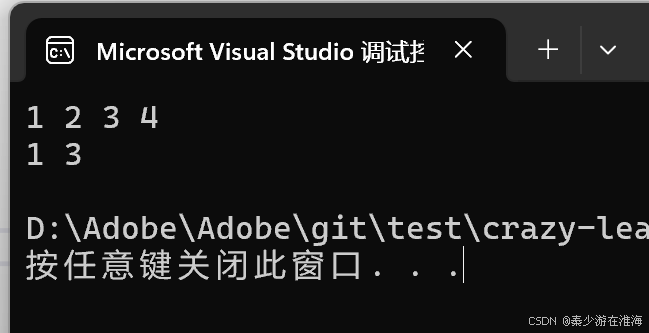
//刪除所有的偶數auto it = v.begin();while (it != v.end()){if (*it % 2 == 0){it = v.erase(it);}else{++it;}}再次測試:
在VS下:
在Linux 下:

將erase 修改之后,兩個平臺均可以跑;
Q:是否還存在其他迭代器失效的情況?
void test4()
{zjx::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);//v.push_back(5);for (const auto& e : v){cout << e << " ";}cout << endl;int i = 0;cin >> i;auto it = v.begin() + i;v.insert(it, 10);for (const auto& e : v){cout << e << " ";}cout << endl;
}
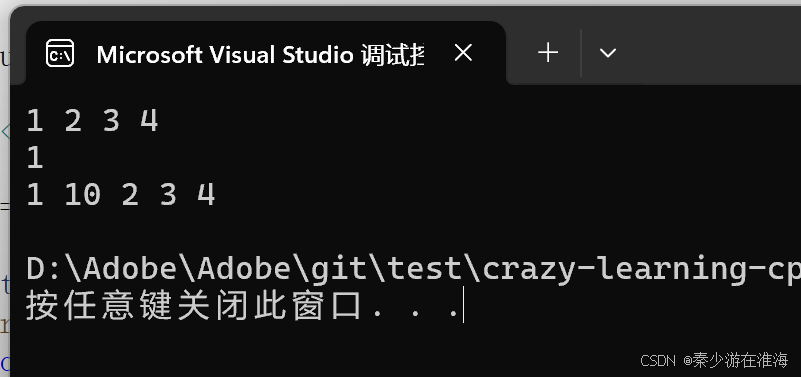
此處的結果看似運行正常,實際上還是存在迭代器失效的問題,當insert 結束之后我們去打印 it 中的值:
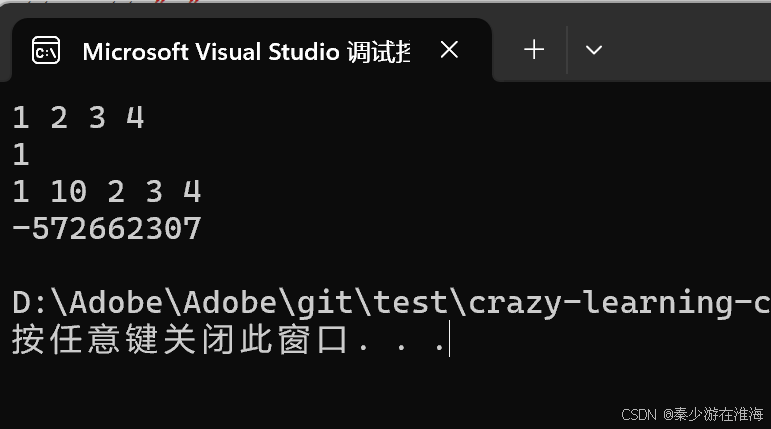
it 指向空間中的數據為隨機值,這是因為 it 已經是一個野指針了,只不過是在使用的過程中編譯器沒有報錯;
將it 傳值傳參給insert 的形參,insert 內部在擴容之后會去維護pos ,但是傳值傳參,修改形參并不會影響實參;此時你應該就有疑問了,既然傳值傳參形參的改變不會影響實參,那如果我們使用引用傳參呢?insert 的內部維護 pos 的同時也維護了實參it ?可以這樣做嗎?不能,因為我們在傳迭代器的時候有時會傳左值(可修改),也有可能會傳右值(不可修改,常見的右值有常量、表達式...),而對于右值來說具有常性,不可被修改,也就是說不可以傳引用傳參;可能你還有疑問,既然對于右值不能被修改,形參能否使用const 引用呢?顯然也是不可以的,最然這樣做迎合了右值傳參,但是對于左值呢?左值是需要修改的;正是因為邏輯的前后矛盾,所以insert 不可以傳引用傳參,并且庫中的insert ,其形參也并未使用引用:
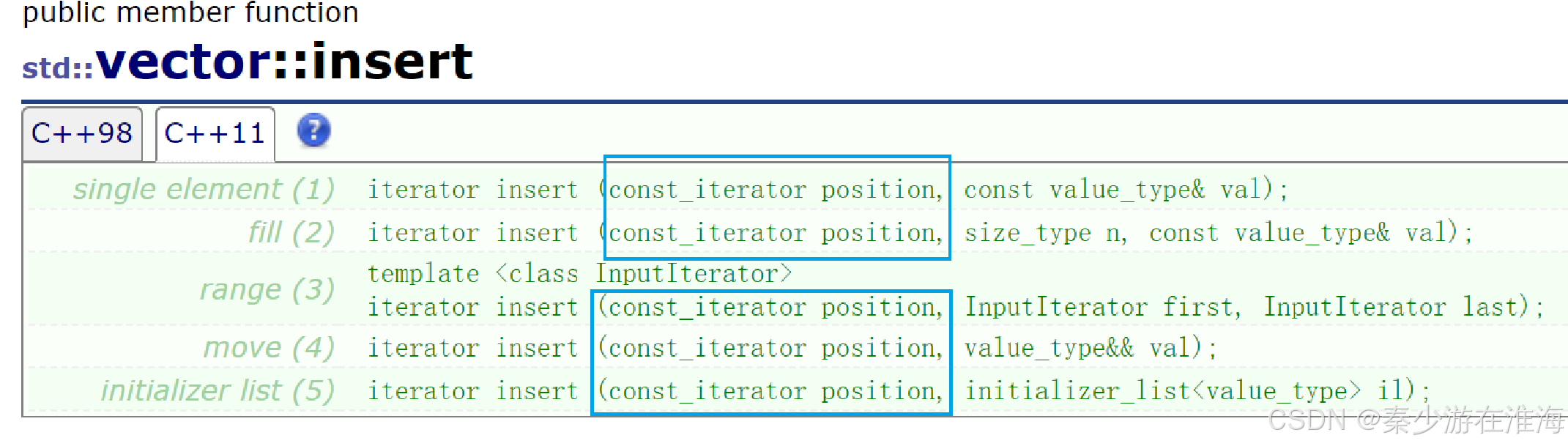
直接認為insert 之后,insert 前的迭代器均失效;
Q:要是沒有擴容呢?
- 使用insert 插入數據,其中是否擴容我們是不知道的,并且在不同平臺下的擴容規則不同,所以此處我們默認不再使用insert 之前的迭代器;
迭代器失效,即在有些場景下是好的,但由于去做了一些動作,調用了一些接口(eg. insert、erase等)導致迭代器不能再用了;迭代器失效可能是野指針的失效,也有可能是一些強制檢查的標記(eg.VS),也有可能是縮容(本質也是野指針問題);原則上,insert、erase 之前的迭代器在insert 、erase 之后要么更新之后再使用,要么就不使用;
12、resize
reserve 是擴容,但是一般不會縮容;
而resize:
- ?n > capacity ,擴容;
- ?size<n<capacity , 進行填充;
- n<size , 刪除數據;

其中的 value_type 本質上就是模板參數?T?,一般成員類型有兩種,要么在類中經過了typedef,要么就是內部類;?
resize 的第二個參數為 T?val = T();
為了兼容模板的泛型,內置類型也被迫升級了默認構造這個概念;所以無論T為內置類型還是自定義類型,T() 均會去構造對應的數據;若 T 為 int ,則T() 就是0 , 若T為int* ,則T() 就是空指針……
resize 的常見用法:在創建vector 之后使用resize 開辟空間并進行初始化;
resize 的參考代碼:
void resize(size_t n, const T& val = T()){if (n < size()){//刪除數據_finish = _start + n;}else// n>=size(){reserve(n);//reserve會去判斷是否需要擴容//填充數據while (_finish != _start + n){*_finish = val;++_finish;}}}測試一下:
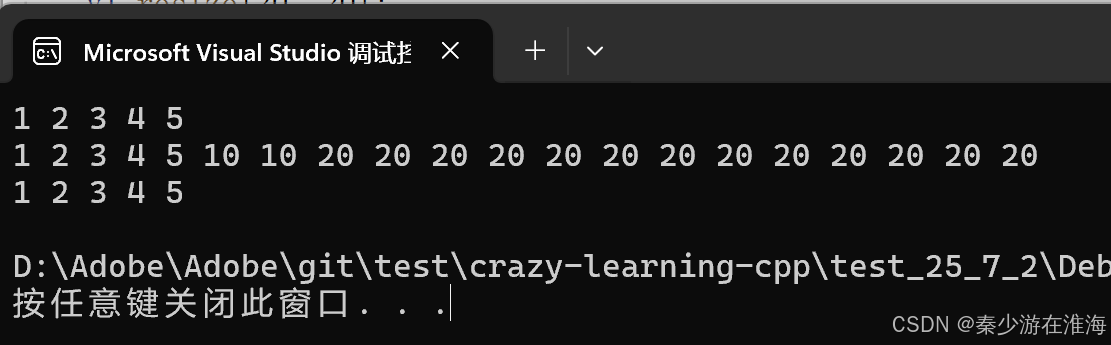
void test3()
{zjx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (const auto& e : v1){cout << e << " ";}cout << endl;v1.resize(7, 10);v1.resize(20, 20);for (const auto& e : v1){cout << e << " ";}cout << endl;v1.resize(5);for (const auto& e : v1){cout << e << " ";}cout << endl;
}int main()
{test3();return 0;
}
13、 拷貝構造

需要注意的是庫中拷貝構造中參數類型為 const vector&;在類外,使用模板的類型必須是 vector<T> ,但是在類中,可以直接使用 vector 即模板名當作類型使用;
我們此處實現還是使用 vector<T> ,嚴謹一些;
若我們沒有顯式實現拷貝構造,那么編譯器自動生成的拷貝構造函數就是淺拷貝,因為vectot 涉及資源,淺拷貝就會導致多次析構而報錯;所以拷貝構造函數需要我們顯式實現;
//拷貝的兩種寫法//zjx::vector<int> v2 = v1;zjx::vector<int> v2(v1);v2(v1): --> v2 拷貝構造v1
- 方法一:按照v1 的大小開辟空間,將 v1 的數據拷貝放入新空間中;
- 方法二:復用reserve 與 push_back; 先利用reserve 為v2 開辟空間,再遍歷v1 ,將v1 中的數據一個一個地push_back 到 v2 當中;
參考代碼:
vector(const vector<T>& v){reserve(v.capacity());for (const auto& e : v){push_back(e);}}但是有一點需要注意的是,拷貝構造也是一種構造,如果vector 的成員變量沒有初始化,那么reserve 就會出錯;在VS中,內置類型未初始化那么該數據便為隨機值,會嚴重影響reserve 開辟空間;有兩種處理方式:
處理方式一:在拷貝構造中使用參數列表為成員變量初始化,如下:
vector(const vector<T>& v):_start(nullptr),_finish(nullptr),_end_of_storage(nullptr){reserve(v.capacity());for (const auto& e : v){push_back(e);}}處理方式二:在成員變量聲明處給缺省值,如下:
private:iterator _start = nullptr;iterator _finish = nullptr;iterator _end_of_storage = nullptr;};倘若在成員變量聲明處給了缺省值,那么默認構造完全什么都可以不寫,如下:
//默認構造函數vector(){}注:當我們在初始化列表中顯式地寫了的時候,便用你寫的值進行初始化,如果啥都沒寫,就是用缺省值;
還需要注意的是,雖然我們的默認構造函數中可以什么都不寫,并不意味著它就可以省略!即使構造函數內部為空,它的存在仍然具有意義,因為我們可以通過初始化列表為成員變量賦初值。如果不定義構造函數,程序就不會執行初始化列表的操作。雖然編譯器會在沒有顯式定義構造函數時自動生成默認構造函數,但需要注意拷貝構造函數也屬于構造函數范疇。對于像vector這樣涉及資源管理的類,必須顯式實現拷貝構造函數,此時編譯器就不會再自動生成默認構造函數。因此,即使構造函數內容為空,也必須明確寫出這個構造函數!
14、賦值運算符重載
vector 的底層涉及資源,所以其拷貝構造、賦值運算符重載、析構函數均需要我們自己顯式實現;
傳統寫法:釋放舊空間、按照賦值對象的空間大小開辟新的空間、拷貝數據;
傳統寫法代碼如下:
//賦值運算符重載的傳統寫法vector<T>& operator=(const vector<T>& v){delete[] _start;//釋放舊空間_start = _finish = _end_of_storage = nullptr;//置空reserve(v.capacity());//開辟新空間for (auto& e : v)//push_back{push_back(e);}return *this;}測試一下:
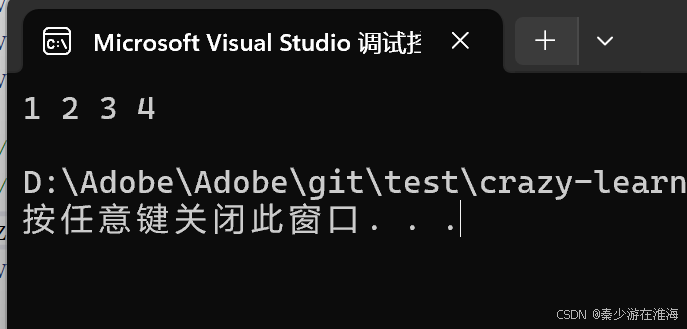
void test6()
{zjx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);//拷貝構造兩種寫法//zjx::vector<int> v2 = v1;zjx::vector<int> v2;v2 = v1;for (const auto& e : v2){cout << e << " ";}cout << endl;
}
現代寫法:借助拷貝構造 + swap
在此之前我們先實現swap,代碼如下:
void swap(vector<T>& v){std::swap(_start, v._start);std::swap(_finish, v._finish);std::swap(_end_of_storage, v._end_of_storage);}注:我們最好是在vector 中實現一個swap ,如果直接使用算法庫中的swap 需要實例化,并且走深拷貝的效率非常低;
現代寫法代碼如下:
//現代寫法vector<T>& operator=(vector<T> v){swap(v);return *this;}現代寫法的優勢在于:傳值傳參會調用拷貝構造,而形參v 作為一個局部變量,出了作用域就會被銷毀,自動調用其析構函數釋放 v 的空間;而 this 就是需要和實參一樣的空間,按照傳統寫法本身也需要釋放舊空間,所以不如將 this 指向的空間與 v 中的空間進行交換,讓 v 這個局部變量在出函數棧幀的時候自動調用析構函數釋放原本 this 指向的空間,而 v 原來的空間給給了 this;現代寫法的邏輯非常巧妙~
測試一下:
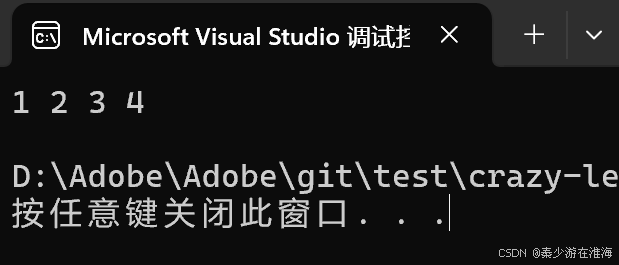
void test6()
{zjx::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);//拷貝構造兩種寫法//zjx::vector<int> v2 = v1;zjx::vector<int> v2;v2 = v1;for (const auto& e : v2){cout << e << " ";}cout << endl;
}
當我們在vector 中放string 的時候:
void test7()
{zjx::vector<string> v1;v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");for (const auto& e : v1){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}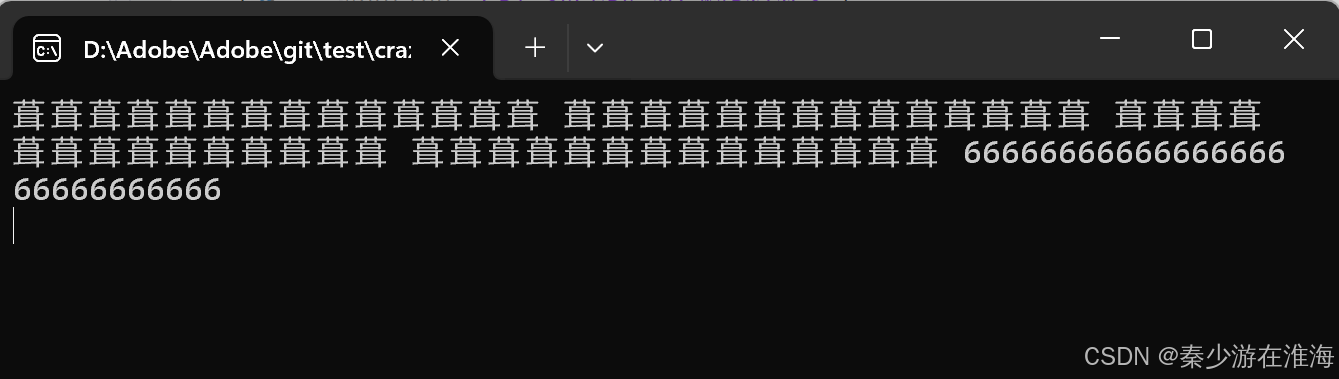
出現了亂碼通常就是野指針的問題,隨機值所對應的編碼正好是“葺”;
剛好是5次push_back , 就導致了野指針的問題,初步懷疑這是擴容帶來的問題,但是又不確定,如果少push_back 一個呢?
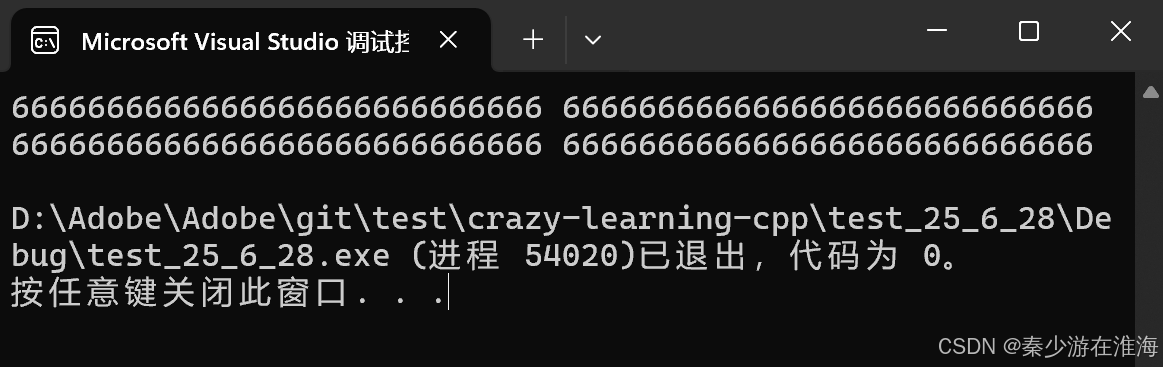
如上,當我們push_back 4 個數據的時候,程序正常運行,但當push_back 5 個數據的時候卻出現了野指針的問題,剛好就卡在擴容這里;我們先調試一下:
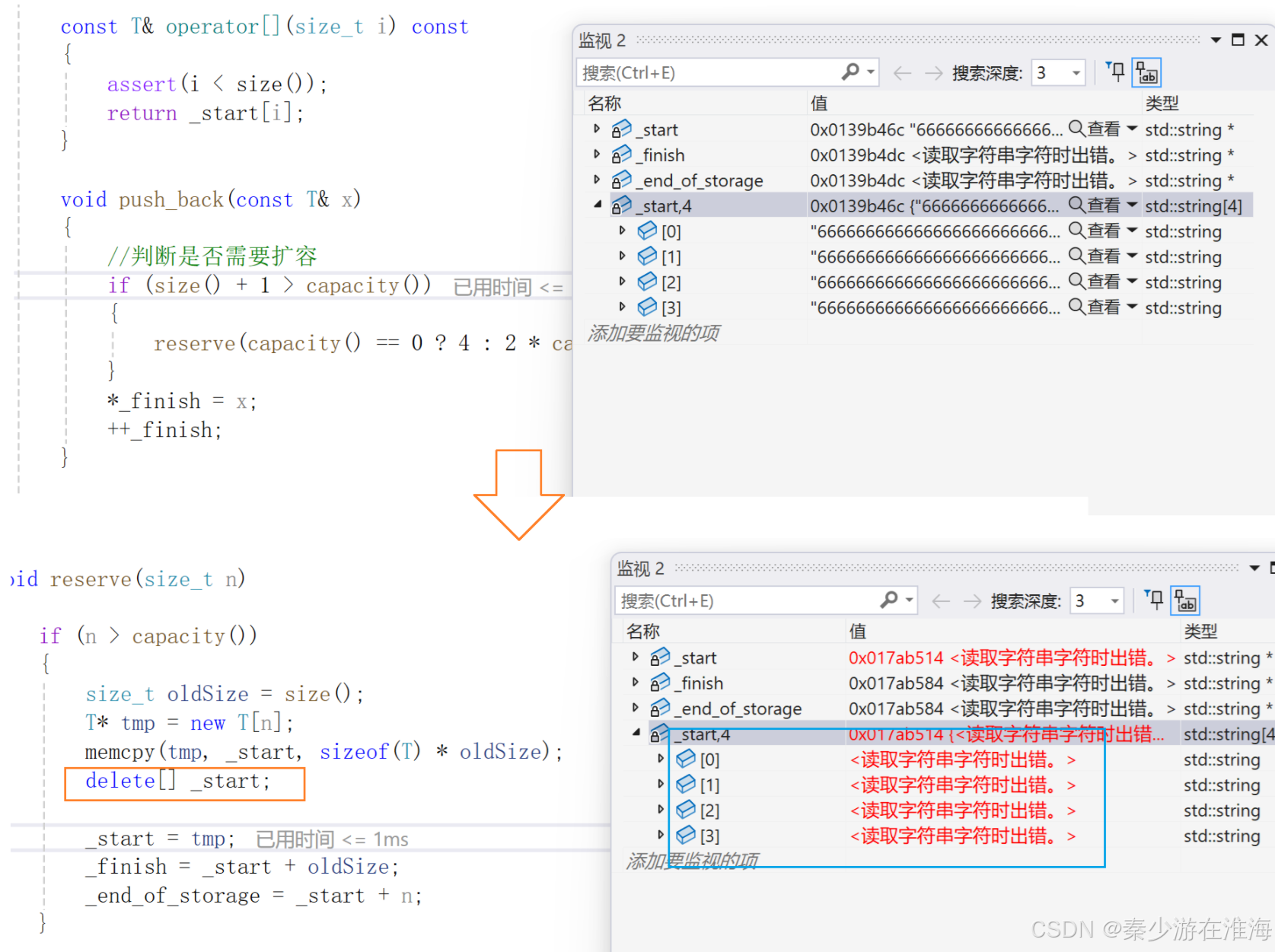
似乎是delete[] _start的時候影響了 tmp 中的數據?需要注意的是,根據調試經驗,當前代碼出問題不一定是當前位置出錯!況且 delete 通常是不會出錯的,即使delete 出錯也是因為不匹配或者釋放的位置不對;此處delete 使用是正確的,錯誤另有他處;
此處錯因源于 memcpy 的淺拷貝,導致同一塊空間多次析構故而報錯;memcpy 是將 _start 中往后 sizeof(T)*oldSize 字節空間中的數據一個字節一個字節拷貝放入 tmp 中,而vector 中的string 涉及資源,就不能只單純地進行淺拷貝;
注:在VS中,當字符數組較小的時候會存放在string 的_buffer 之中,比較大的才會存放在堆上,故而我們故意將字符串寫得比較長,就是為了讓他將數據存放到堆上;
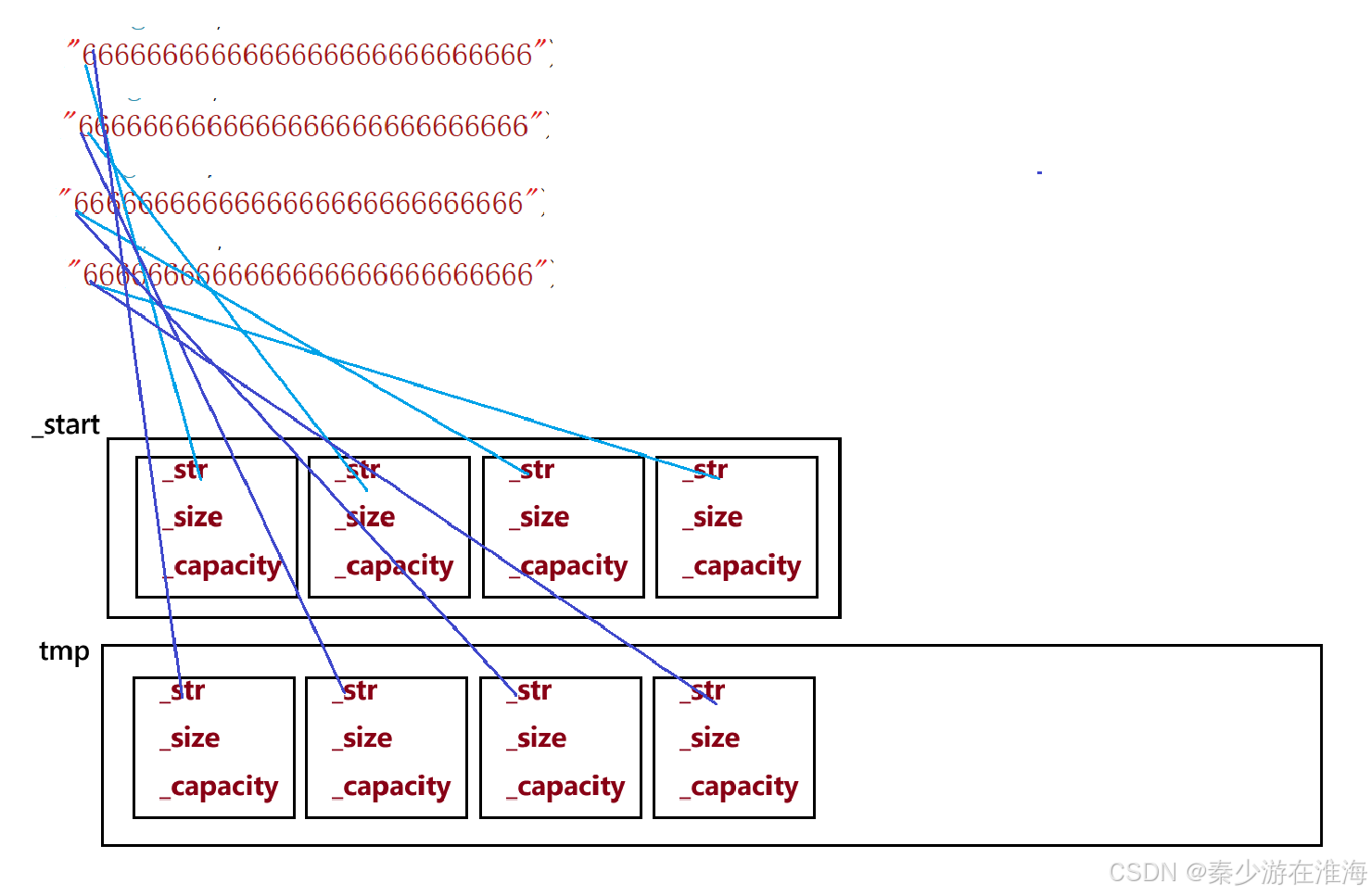
觀察調試后 _start 與 tmp 指向的空間:
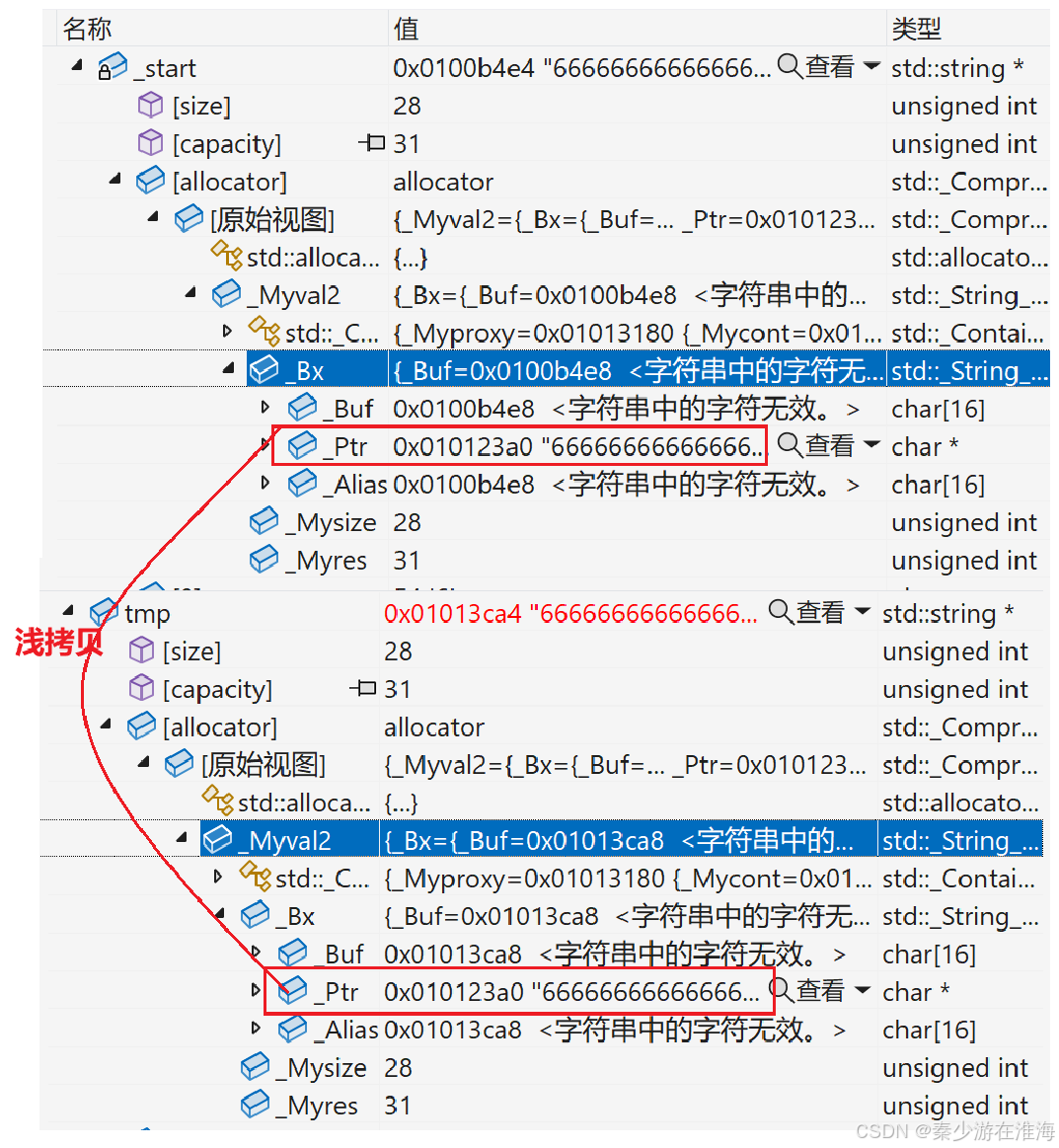
而至于在delete 的時候報錯,這是因為delete[] 對于自定義類型的空間會做兩件事:
- 1、調用析構函數;
- 2、調用operator delete (本質上就是free)
而此處有兩個自定義類型對象指向同一塊空間,那么對同一塊空間調用兩次析構函數,于是乎就報錯了;
修改:不使用memcpy ,需要進行深拷貝,讓這個 string 走深拷貝,但倘若 T 為內置類型呢?因為模板是泛型,也就是說需要做到面面俱到,是否可以直接訪問string 中的 _str ,看其 _size 、_capacity 的大小來決定開辟多大的空間呢?不能,我們不能直接在類外訪問一個類的私有成員變量;況且, T也不一定是 string , 實際當中,我們并不知道T究竟為什么類型;
解決:利用賦值,即使T為涉及資源的類,賦值運算符重載一定是深拷貝實現的,倘若T為自定義類型,也沒有關系,賦值也可以解決問題;
參考代碼如下:
void reserve(size_t n){if (n > capacity()){size_t oldSize = size();T* tmp = new T[n];//memcpy(tmp, _start, sizeof(T) * oldSize);//memcpy 是淺拷貝//我們需要自己實現深拷貝for (size_t i = 0; i < oldSize; i++){//將數據一個一個賦值過去tmp[i] = _start[i];}delete[] _start;_start = tmp;_finish = _start + oldSize;_end_of_storage = _start + n;}}測試一下:
void test7()
{zjx::vector<string> v1;v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");v1.push_back("6666666666666666666666666666");for (const auto& e : v1){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}
15、initializer_list 構造
另外,在vector 之中還可以使用迭代器區間進行初始化:

在C++11 之后,為了更好地去初始化這些容器,就自己創造了一個類型:initializer_list:

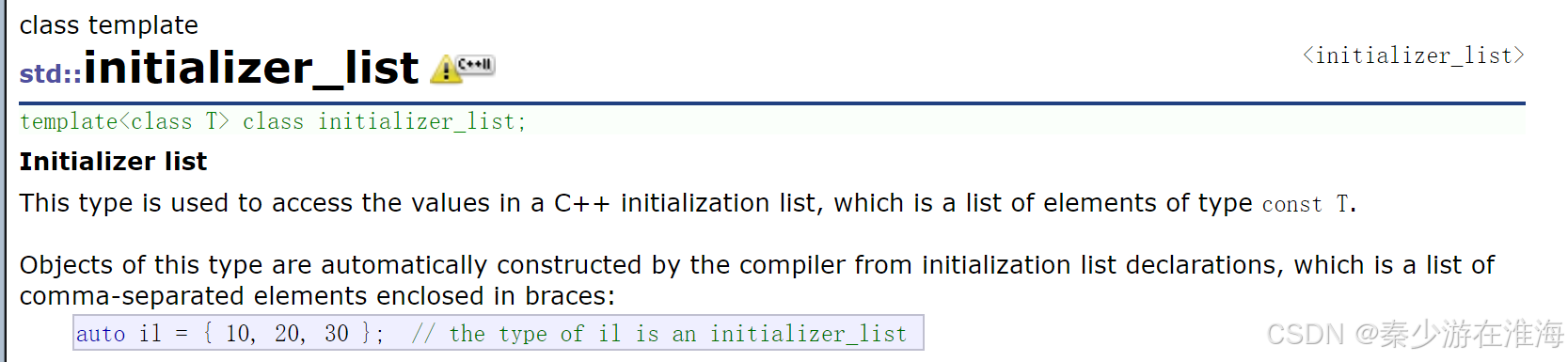
initializer_list 是一個模板,將 {} 括起來地數據傳遞給一個對象,它會默認將這個對象 il 的類型為 initializer_list<int>;可以認為initializer_list 是系統庫中支持的容器;
Q:initializer_list 支持哪些功能?

intializer_list 支持迭代器;
Q: initializre_list 的原理是什么?
簡單來說,initializer_list 與 C語言中數組的原理類似;

Q: initializer_list 所開辟的空間在哪里呢?會在常量區嗎?還是和數組一樣,存放在棧上?
- 打印地址,觀察 il 的迭代器所指向的地址離哪一個區域的地址比較近;

從上例中便可以得知 initializer_list 在棧上開辟空間;
對于 initialzer_list ,重點需要理解的是: initializer_list 中有兩個指針,一個指向開始,一個指向結束,調試觀察如下:
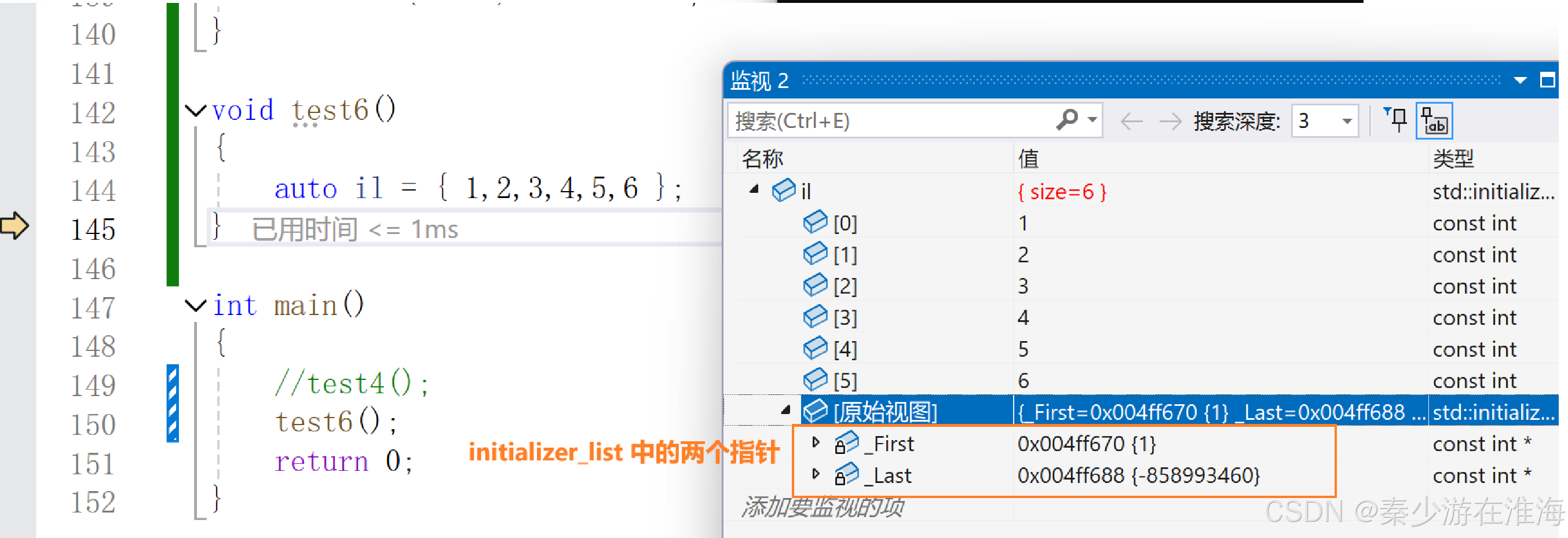
C++11 中增加了這種初始化方式,同時也對編譯器進行了處理;當我們想要支持任意一個數據利用 {} 去初始化,那我們就可以去寫一個對應版本的構造;
我們還可以使用隱式類型轉化,和initializer_list 的效果一樣,但是其語法邏輯不同,如下:
vector<int> v1({ 1,2,3,4,5,6 }); //隱式類型轉換vector<int> v2 = { 1,2,3,4,5,6 };//initializer_list- 對于 v1 , 單參數的構造函數支持隱式類型轉換,語法上來說,要用 {1,2,3,4,5,6} 去構造一個vector的臨時對象,再使用該臨時對象去拷貝構造v1 ,而編譯器在此基礎上直接做了優化,即直接構造;
- 對于v2, 是直接調用構造函數;
Q:如何實現 initializer_list 呢?
- 1、initializer_list 作為構造的一種,在構造的時候編譯器也會走初始化列表;
- 2、調用 reserve 開辟空間
- 3、initializer_list 有迭代器那么便就支持范圍for ,直接依靠范圍for 依次去取到 initializer_list<T> il 中所有的數據,然后進行push_back便可;
參考代碼:
//initializer_listvector<T>(initializer_list<T> il){reserve(il.size());for (auto& e : il){push_back(e);}}測試:
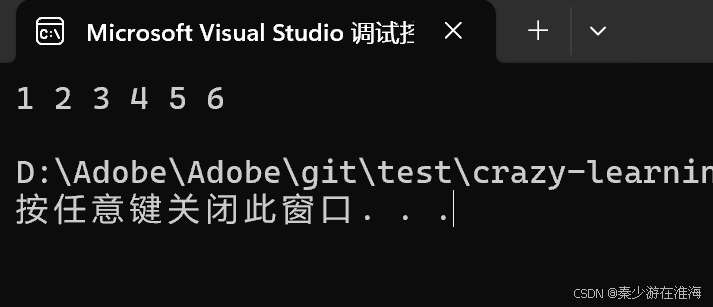
void test6()
{zjx::vector<int> v1 ={ 1,2,3,4,5,6 };for (const auto& e : v1){cout << e << " ";}cout << endl;
}
16、迭代器區間初始化

在庫中,迭代器區間的初始化寫成了一個模板,在類中成員函數是可以寫成模板的 --> 多重模板:
類默認定義的模板參數(eg.T)是給我們整個類使用的,而類中的成員函數模板中也可以用類模板參數T,但是成員函數模板不想用T,并且想實現泛型編程,就可以在類中將此函數實現為函數模板;至于為什么不直接使用 iterator ,是因為 iterator 是屬于vector 的,如果直接用vector 中的迭代器那么就只能用vector 的迭代器去初始化,就不支持使用其他類型迭代器區間來進行初始化;
參考代碼:
//迭代器區間的構造template<class InputIterator>vector(InputIterator first, InputIterator last){while (first != last){push_back(*first);++first;}}測試:
 ?可以使用其他類型數據的迭代器進行初始化:
?可以使用其他類型數據的迭代器進行初始化:
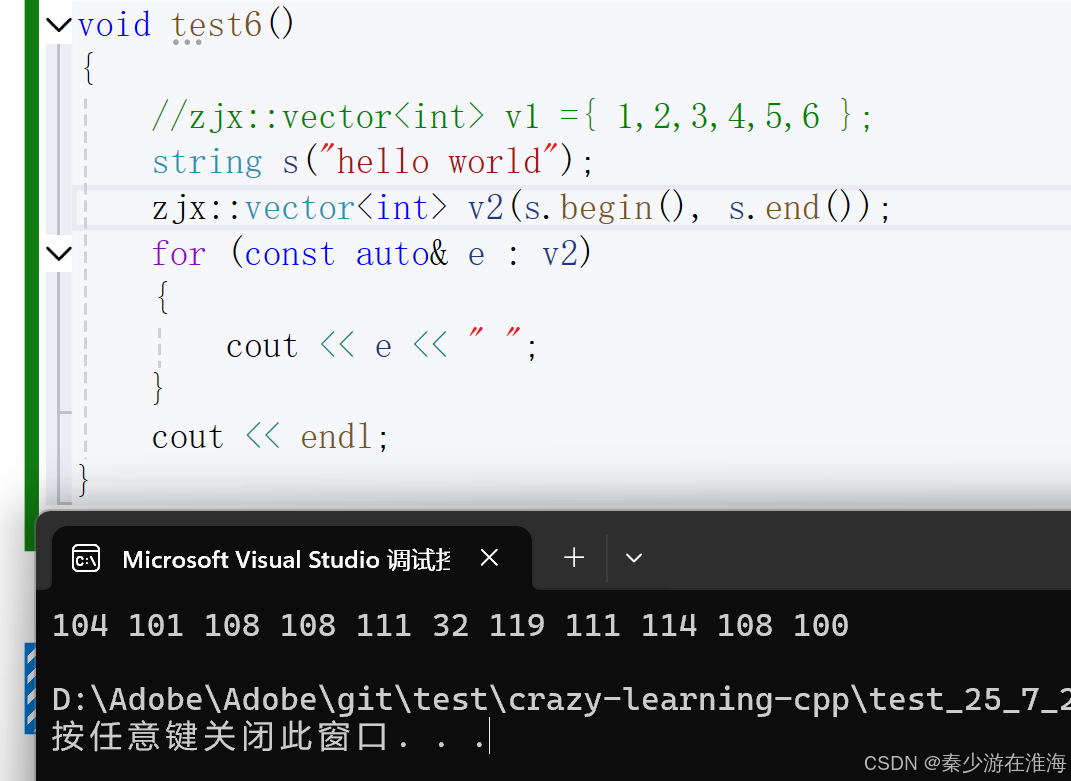
還可以傳原生指針:
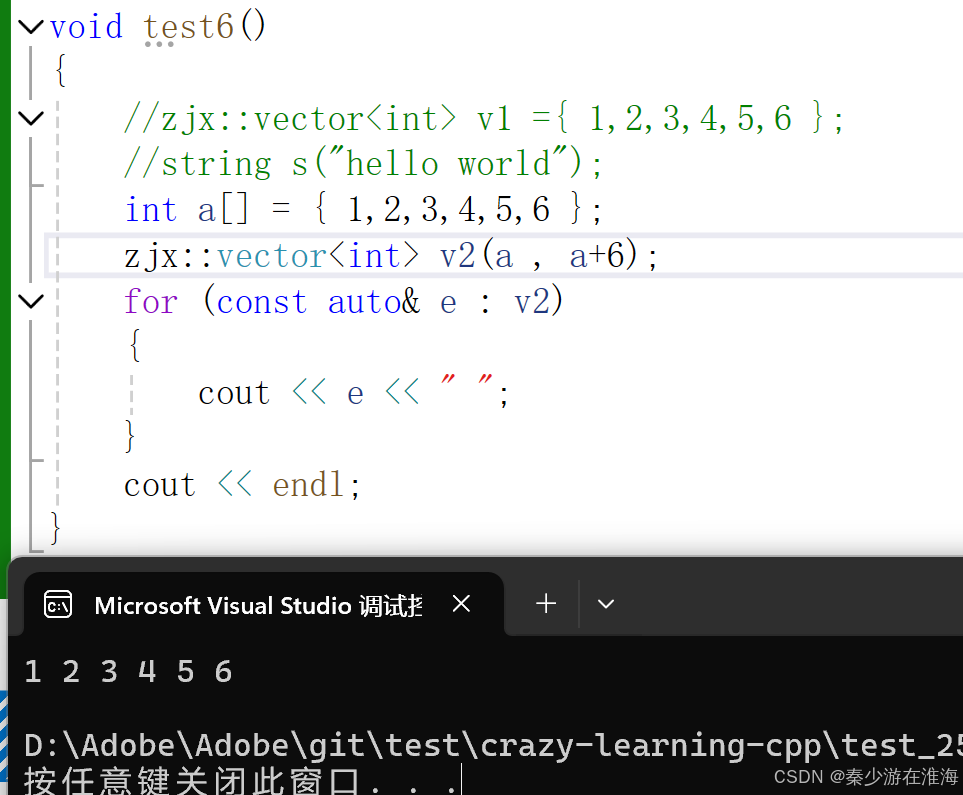
Q: 為什么可以傳原生指針?
- 迭代器本身就是在模擬指針的行為,當指針所指向數據的空間是連續的就可以將指針當作迭代器使用;
說到這里,不得不再說一下算法庫中的sort , 如下:

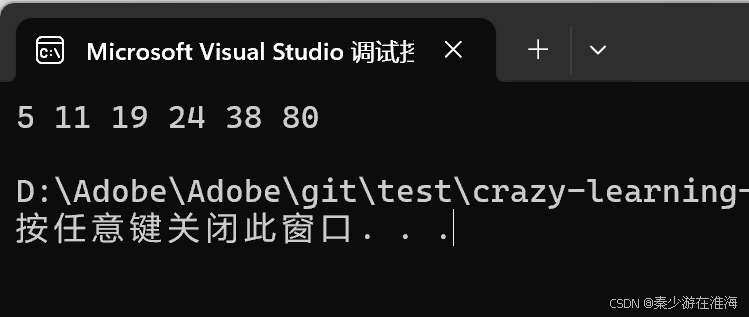
sort 是一個函數模板,也要求參數傳遞待排序數據的迭代器區間,對于vector 這種空間連續存在的容器進行排序時完全沒有問題的,當然也可以對數組進行排序,即可以向sort 傳遞數組指針,使用如下:
void test7()
{int a[] = { 19,80,11,5,38,24 };sort(a, a + 6);for (auto e : a){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}
?17、n個val 構造

其中size_type 就是size_t ,庫中的第三個參數時空間配置器,目前不管;
注:空間配置器:STL中的容器為了提高效率,它在申請內存的時候并沒有直接向我們的堆調用malloc 、new 去申請,而是直接使用內存池中的空間;此處作為形參,是期望使用者在構造的時候,如果使用者對STL中的內存池(空間配置器)不滿意,那么使用者可以自己去實現一個空間配置器,然后作為參數傳給vector ,那么此時構造的時候就不再使用vector默認STL中的內存池,而是用你實現的內存池去申請空間;
實現:reserve + 填值,也可以直接去復用resize
//n個val 的構造vector(size_t n, const T& val = T()){//直接復用resizeresize(n, val);}//vector(size_t n, const T& val = T())//{// //reserve + 填值// reserve(n);// for (int i = 0; i < n; i++)// {// *_finish = val;// ++_finish;// }//}測試:
void test7()
{zjx::vector<int> v1(10, 1);for (auto e : v1){cout << e << " ";}cout << endl;
}int main()
{test7();return 0;
}
再測試一下:
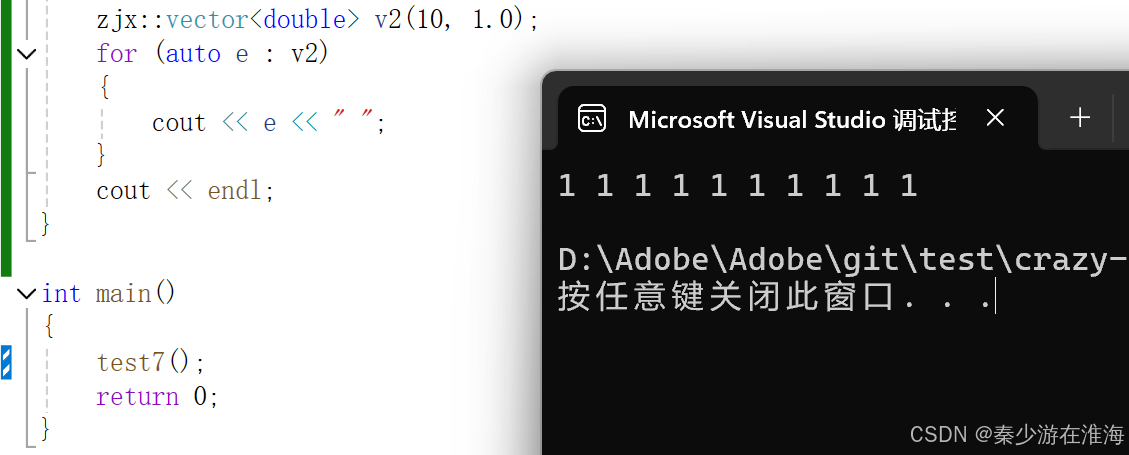
Q:為什么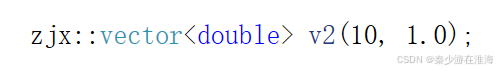 可以正常運行,而
可以正常運行,而 卻會報錯呢?
卻會報錯呢?
報錯原因:編譯器對![]() 去調用了我們實現的迭代器區間構造函數模板;
去調用了我們實現的迭代器區間構造函數模板;
Q:為什么呢?
- C++編譯器在進行類型傳參(函數模板參數匹配)的原則:匹配更匹配的;即編譯器會在有選擇的情況下,去“吃”自己更喜歡“吃”的;如果沒有自己喜歡“吃”的,也可以“將就”;并且在這兩點的基礎上,“有現成吃現成”;對于
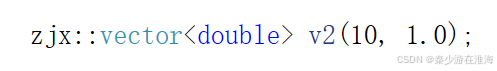 ;來說,編譯器沒有選擇,匹配不上用迭代器區間初始化的構造,就只能去調用 n 個val 的構造;簡單從字面量的角度來說就是:給整型的變量編譯器就默認它為int 類型,給浮點數字面量編譯器默認它的類型為double;當所傳參數類型為 int 、double 的時候,就只能“勉強”地去匹配使用 n 個val 完成初始化地函數,因為倘如調用迭代器區間地函數模板,T被實例化為了double ,雖然size_t 與 int 有一點不匹配,但是也可以勉強使用;
;來說,編譯器沒有選擇,匹配不上用迭代器區間初始化的構造,就只能去調用 n 個val 的構造;簡單從字面量的角度來說就是:給整型的變量編譯器就默認它為int 類型,給浮點數字面量編譯器默認它的類型為double;當所傳參數類型為 int 、double 的時候,就只能“勉強”地去匹配使用 n 個val 完成初始化地函數,因為倘如調用迭代器區間地函數模板,T被實例化為了double ,雖然size_t 與 int 有一點不匹配,但是也可以勉強使用; - 但是對于?
 來說,它是有選擇地;相較于用 n 個val 初始化的構造,將 T實例化為int , 但size_t 與int 稍微不太匹配即“能吃但是不太對味口”;對于迭代器區間初始化的構造,它是一個函數模板,v1 的兩個實參均為 int 類型的數據,那么InputIterator 就被實例化為了int , 顯然相較于用 n 個val 初始化的構造函數,v1 更“喜歡”去調用更適合自己的用迭代器區間初始化的構造函數;
來說,它是有選擇地;相較于用 n 個val 初始化的構造,將 T實例化為int , 但size_t 與int 稍微不太匹配即“能吃但是不太對味口”;對于迭代器區間初始化的構造,它是一個函數模板,v1 的兩個實參均為 int 類型的數據,那么InputIterator 就被實例化為了int , 顯然相較于用 n 個val 初始化的構造函數,v1 更“喜歡”去調用更適合自己的用迭代器區間初始化的構造函數;

而int 類型的數據不可以進行解引用;
Q:如何解決呢?
- 理論上而言,可以將實現n 個val 的構造第一個參數類型size_t 修改為int ,但是庫中仍然使用的size_t ,并且即使是修改為int 也還存在其他問題;
首先我們先來看一下庫中是如何解決的,如下:
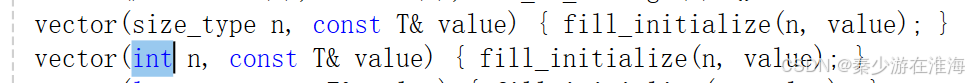
庫中實現為了兩個函數,按照庫中給的進行修改:
參考代碼:
//n個val 的構造vector(size_t n, const T& val = T()){//直接復用resizeresize(n, val);}vector(int n, const T& val = T()){//直接復用resizeresize(n, val);}Q:那既然vector 的底層實現中,其第一個參數類型還有用int 實現的,為什么在文件中標明其第一個參數的默認類型為 size_type(size_t) 呢?

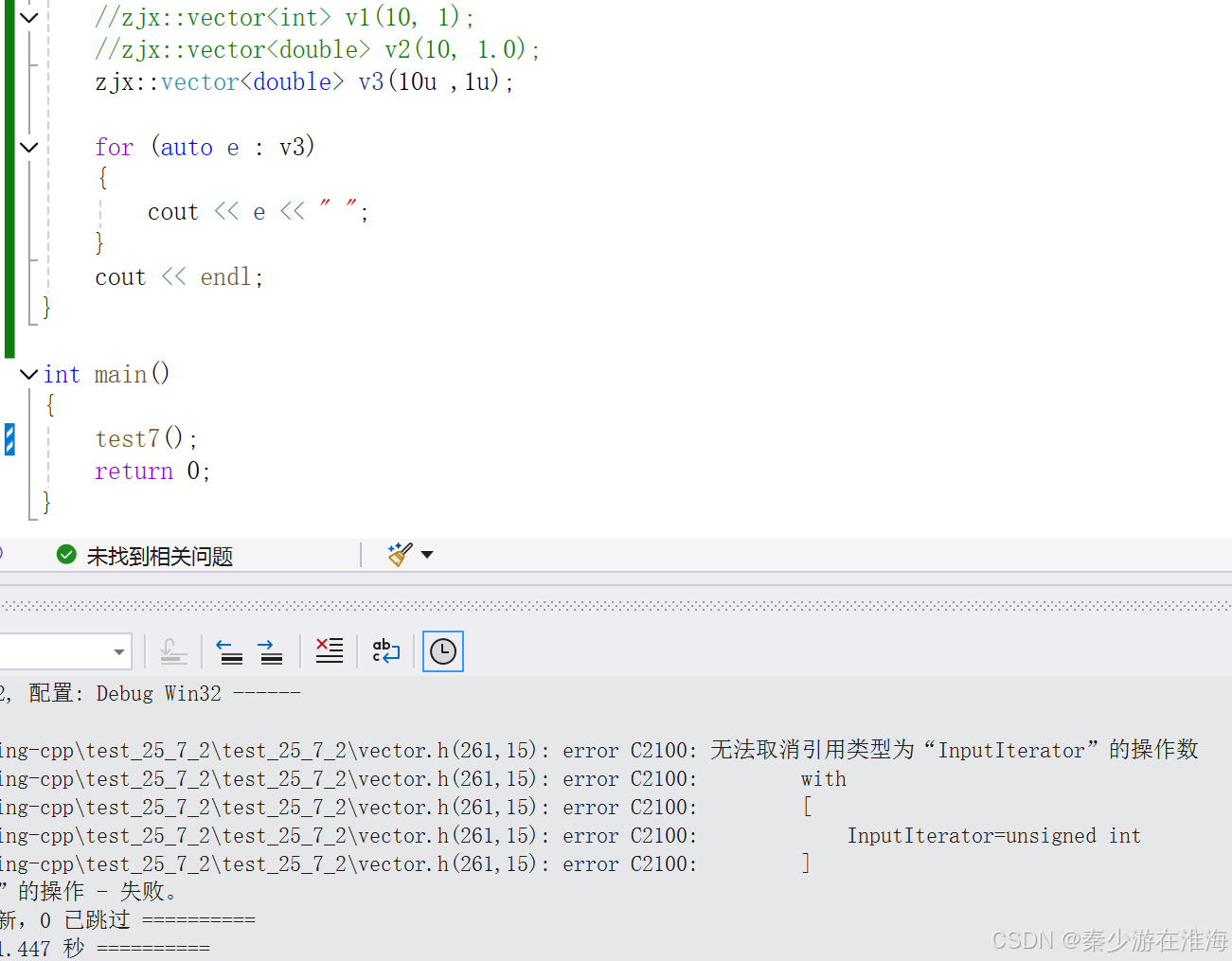
- 1、一般在STL的慣例:只要是個數,就不會出現負數的情況,均會給size_t 類型,且用size_t 可以表達的數據會更多一些;
- 2、將size_t 改為 int ,在極端情況下也會出現非法間接尋址的問題;(eg. 傳參類型為兩個無符號整型,例子如下:還是去調用了用迭代器區間初始化的構造,由于不能對整數進行解引用操作,故而報錯)







|如何以實踐破解數據挖掘教學痛點)



)
?)


)



