目錄
Dolphin簡介
Dolphin 中共有 4 個模型,其中 2 個現在可用。
使用demo
Dolphin簡介
Dolphin 是由 Dataocean AI 和清華大學合作開發的多語言、多任務語音識別模型。它支持東亞、南亞、東南亞和中東的 40 種東方語言,同時支持 22 種漢語方言。該模型在超過 210,000 小時的數據上進行訓練,包括 DataoceanAI 的專有數據集和開源數據集。該模型可以執行語音識別、語音活動檢測(VAD)、分割和語言識別(LID)。
small版本與Whisper large v3相比,平均WER降低54.1%,模型大小只有Whisper large v3的約1/4 ?除了語音識別,還能進行語音活動檢測、音頻分割以及語言識別 ?目前開源了兩個基礎版本,一個base版,一個small版
方法
Dolphin 主要遵循 Whisper 和 OWSM 的創新設計方法。采用基于 E-Branchformer 的編碼器和基于標準 Transformer 的解碼器的聯合 CTC-Attention 架構。針對 ASR 的特定關注,引入了幾個關鍵修改。Dolphin 不支持翻譯任務,并消除了對先前文本及其相關標記的使用。
在 Dolphin 中,引入了二級語言標記系統,以更好地處理語言和區域多樣性,尤其是在 Dataocean AI 數據集中。第一個標記指定語言(例如,?<zh>?,?<ja>?),而第二個標記表示區域(例如,?<CN>?,?<JP>?)。詳細信息請參閱論文。
https://github.com/DataoceanAI/Dolphin/blob/main/languages.md
Dolphin 中共有 4 個模型,其中 2 個現在可用。
| Model | Parameters??參數 | Average WER??平均詞錯誤率 | Publicly Available??公開可用 |
|---|---|---|---|
| base??基礎 | 140 M | 33.3 | ? |
| small??小型 | 372 M | 25.2 | ? |
| medium??中等 | 910 M??910 兆 | 23.1 | |
| large??大型 | 1679 M | 21.6 |
沒有開源微調 finetune
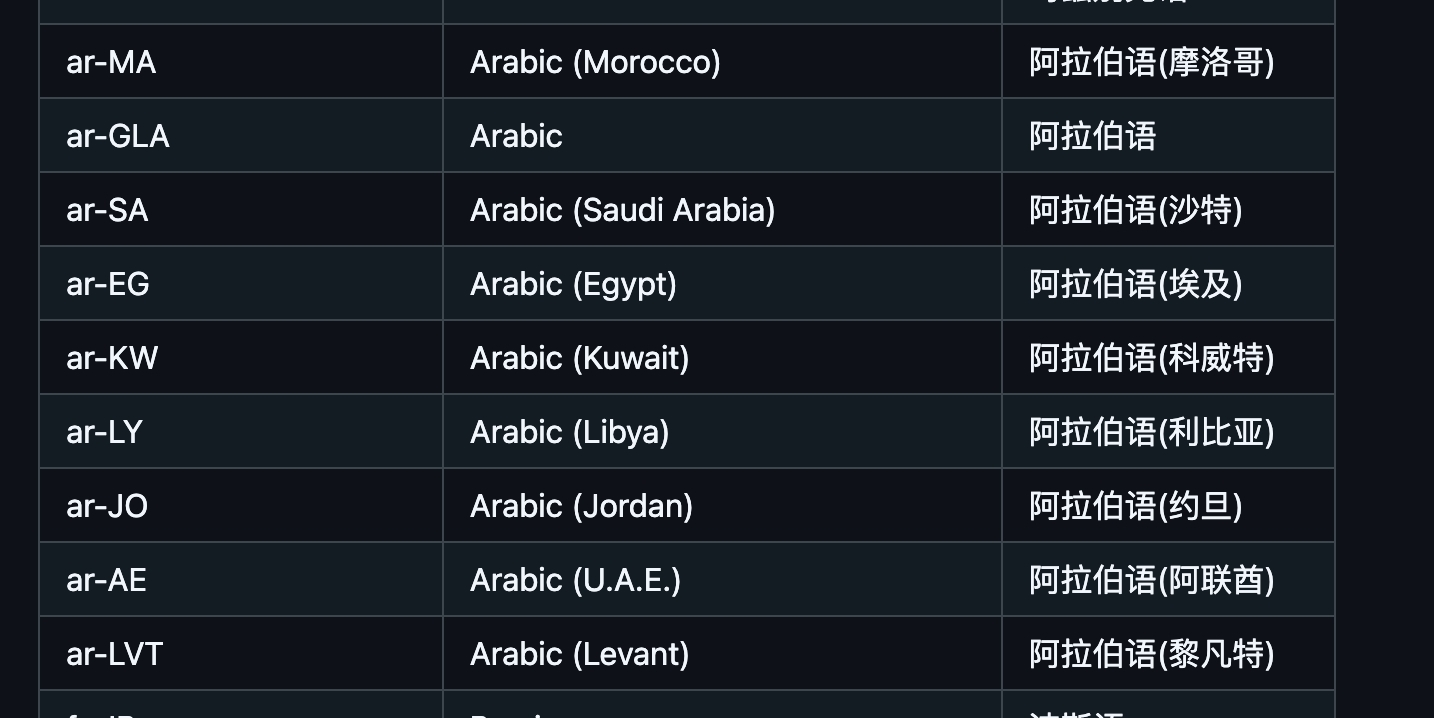
支持阿拉伯語,但是不支持
安裝:
pip?install -U dataoceanai-dolphin使用demo
可以自動識別語言
import dolphinwaveform = dolphin.load_audio("audio.wav")
model = dolphin.load_model("small", "/data/models/dolphin", "cuda")
result = model(waveform)# Specify language
result = model(waveform, lang_sym="zh")# Specify language and region
result = model(waveform, lang_sym="zh", region_sym="CN")
print(result.text)import dolphin
import os
# waveform = dolphin.load_audio("/nas/lbg/project/Whisper-Finetune/dataset/test_long.wav")waveform = dolphin.load_audio("/nas/ASR_DATA/cv-corpus-21.0-2025-03-14/ar/clips/common_voice_ar_24146339.mp3")os.makedirs("/nas/lbg/models/dolphin", exist_ok=True)
model = dolphin.load_model("base", "/nas/lbg/models/dolphin", "cuda")
result = model(waveform)# Specify language
# result = model(waveform, lang_sym="zh")# # Specify language and region
# result = model(waveform, lang_sym="zh", region_sym="CN")
# print(result.text)result = model(waveform)# Specify language and region
result = model(waveform)
print(result.text)



)
行為型:訪問者模式詳解)

![P4568 [JLOI2011] 飛行路線](http://pic.xiahunao.cn/P4568 [JLOI2011] 飛行路線)







)

組件和進度條 (Progress)組件的使用)

:docker-compose.yml (ThinkPHP))