1.基礎概念
1.1 AI的概念:
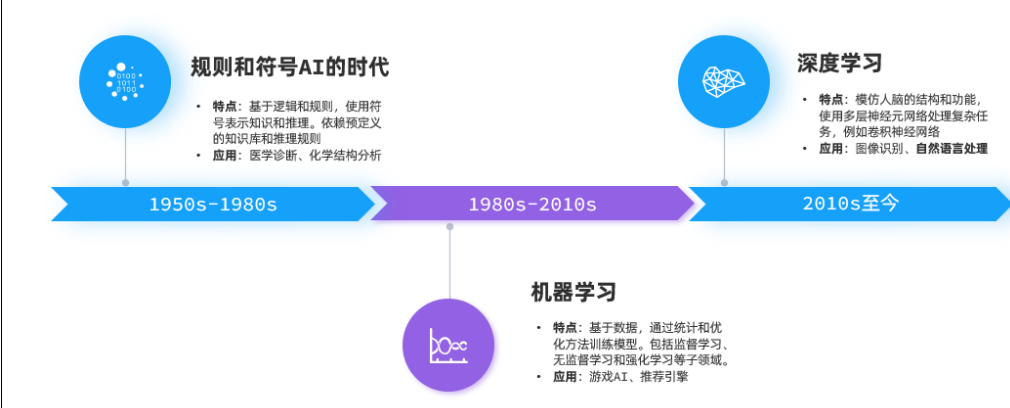
1.2 神經網絡的基本概念
如果我們想通過模擬人腦的方式實現人工智能,首先就要模擬出一個神經元,于是人們提出感知機模型,用于模擬神經元,在感知機模型中,有輸入,權重,激活函數,假設輸入和激活函數都不變的情況下,我們可以通過調整權重值,得到不同輸出。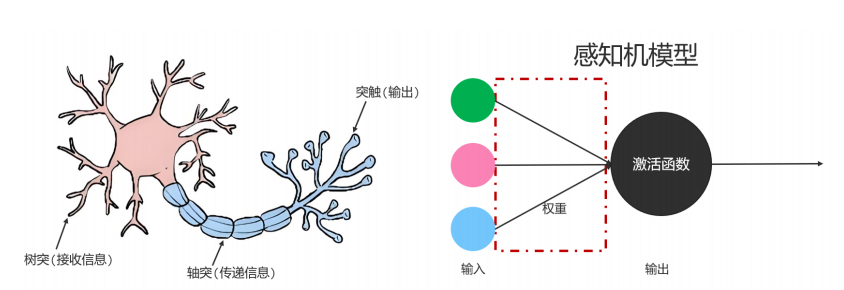
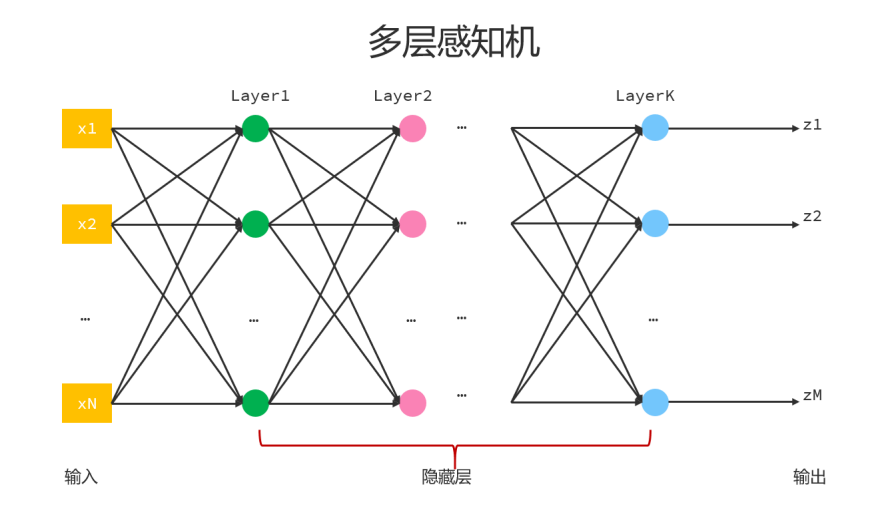
單個感知機模型只能模擬單個神經元,每個感知機上都有輸入,輸出,激活函數,將來會結合用戶的輸入和權重以及激活函數,再與閾值(偏置)比較,最終得到輸出,每個神經元上使用的權重和閾值都稱為參數,每個神經元上的參數數量=權重數量+1,這里的1指的是偏置。
大模型的大指參數規模,現在我們通常將參數規模在1000億以上的模型稱為大模型。
1.3?大模型的基本概念
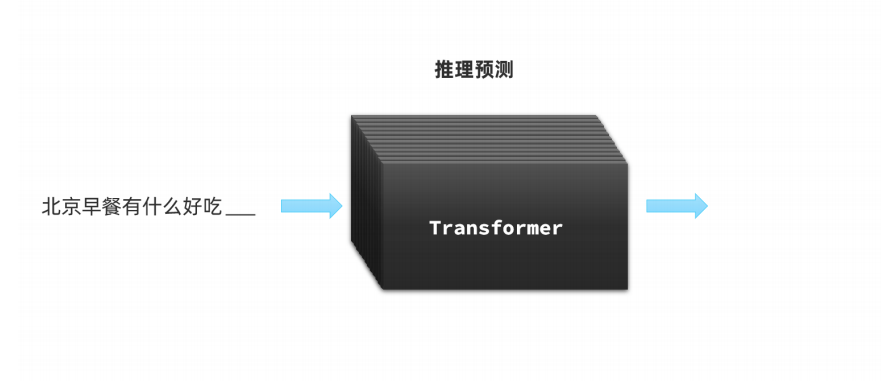
2.大模型基本使用
2.1 模型使用方案
我們要使用一個可訪問的大模型通常有三種方案:
使用開放的API,在云平臺部署私有大模型,在本地服務器部署私有大模型
開放API沒有運維成本,按調用收費,但是長期使用成本較高且數據存在第三方,存在隱私和安全問題。云平臺部署私有模型部署和運維方便,前期投入成本低,但是長期使用成本高,且同樣存在安全問題。本地部署私有大模型數據完全自主掌控,安全性高,但硬件投入成本極高且維護困難。
2.2 Ollama本地部署
下載Ollama客戶端并根據指令進行模型部署等操作
一、基礎操作指令
| 指令 | 功能 | 示例 |
|---|---|---|
ollama run <模型名> | 運行指定模型(自動下載若不存在) | ollama run llama3 |
ollama list | 查看本地已下載的模型列表 | ollama list |
ollama pull <模型名> | 手動下載模型 | ollama pull mistral |
ollama rm <模型名> | 刪除本地模型 | ollama rm llama2 |
ollama help | 查看幫助文檔 | ollama help |
二、模型交互指令
1. 直接對話
ollama run llama3 "用中文寫一首關于秋天的詩"2. 進入交互模式
ollama run llama3
# 進入后輸入內容,按 Ctrl+D 或輸入 `/bye` 退出3. 從文件輸入
ollama run llama3 --file input.txt4. 流式輸出控制
| 參數 | 功能 | 示例 |
|---|---|---|
--verbose | 顯示詳細日志 | ollama run llama3 --verbose |
--nowordwrap | 禁用自動換行 | ollama run llama3 --nowordwrap |
三、模型管理
1. 自定義模型配置(Modelfile)
創建 Modelfile 文件:
FROM llama3 ?# 基礎模型
PARAMETER temperature 0.7 ?# 控制隨機性(0-1)
PARAMETER num_ctx 4096 ? ? # 上下文長度
SYSTEM """ 你是一個嚴謹的學術助手,回答需引用論文來源。""" ? ? ? ? ? ? ? ?# 系統提示詞構建自定義模型:
ollama create my-llama3 -f Modelfile
ollama run my-llama32. 查看模型信息
ollama show <模型名> --modelfile ?# 查看模型配置
ollama show <模型名> --parameters # 查看運行參數四、高級功能
1. API 調用
啟動 API 服務
ollama serve通過 HTTP 調用
curl http://localhost:11434/api/generate -d '{"model": "llama3","prompt": "你好","stream": false
}'2. GPU 加速配置
# 指定顯存分配比例(50%)
ollama run llama3 --num-gpu 502.3 API調用大模型接口
目前大多數大模型都遵循OpenAI的接口規范,是給予http協議的接口,具體規范可查看相關大模型官方API文檔。
大模型接口規范:
這是DeepSeek官方文檔給出的調用示例:
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
# 1.初始化OpenAI客?端,要指定兩個參數:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>",
base_url="https://api.deepseek.com")
# 2.發送http請求到?模型,參數?較多
response = client.chat.completions.create(
model="deepseek-chat", # 2.1.選擇要訪問的模型
messages=[ # 2.2.發送給?模型的消息
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False # 2.3.是否以流式返回結果
)
print(response.choices[0].message.content)接口說明:
請求路徑:與平臺有關
安全校驗:開放平臺提供API_KEY校驗權限,Ollama不需要
請求參數:
model(訪問模型名稱)
message(發送給大模型的消息,是一個數組)
stream(true代表響應結果流式返回,false代表響應結果一次性返回,但需要等待)
temperature(取值范圍[0,2),代表大模型生成結果的隨機性,值越小隨機性越低,deepseek-r1不支持此參數)
message數組中兩個屬性:role和content,通常,role有三種:
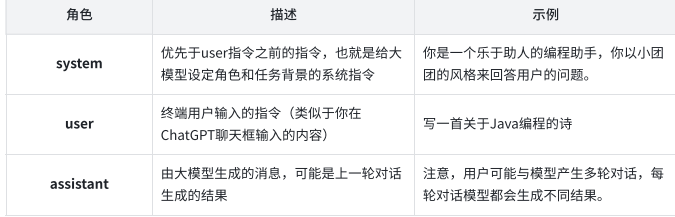
3.大模型應用
大模型應用是基于大模型的推理,分析,生成能力,結合傳統編程能力,開發出的各種應用。
大模型是基于數據驅動的概率推理,擅長處理模糊性和不確定性,如自然語言處理(文本翻譯),非結構化數據處理(醫學影像診斷),創造性內容生成(生成圖片),復雜模式預測(股票預測)等,而上述內容正式我們傳統應用所不擅長處理的部分,因此,可以將傳統編程和大模型整合起來,開發智能化的大模型應用。
大模型本身只是具備生成文本的能力,基本推理能力,我們平時使用的ChatGPT等對話產品除了生成和推理外,還有會話記憶,聯網等功能,這些是大模型本身所不具備的,是需要額外程序去完成的,也就是基于大模型的應用。
常見的一些大模型產品及其模型關系:
| 大模型 | 對話產品 | 公司 | 地址 |
|---|---|---|---|
| GPT-3.5、GPT-4o | ChatGPT | OpenAI | https://chatgpt.com/ |
| Claude 4.0 | Claude AI | Anthropic | App unavailable \ Anthropic |
| DeepSeek-R1 | DeepSeek | 深度求索 | DeepSeek | 深度求索 |
| 文心大模型 3.5 | 文心一言 | 百度 | 文心一言 |
| 星火 3.5 | 訊飛星火 | 科大訊飛 | 訊飛星火-懂我的AI助手 |
| Qwen-Max | 通義千問 | 阿里巴巴 | 通義 - 你的實用AI助手 |
| Moonshoot | Kimi | 月之暗面 | Kimi - 會推理解析,能深度思考的AI助手 |
| Yi-Large | 零一萬物 | 零一萬物 | 零一萬物-大模型開放平臺 |
大模型應用的常見領域:
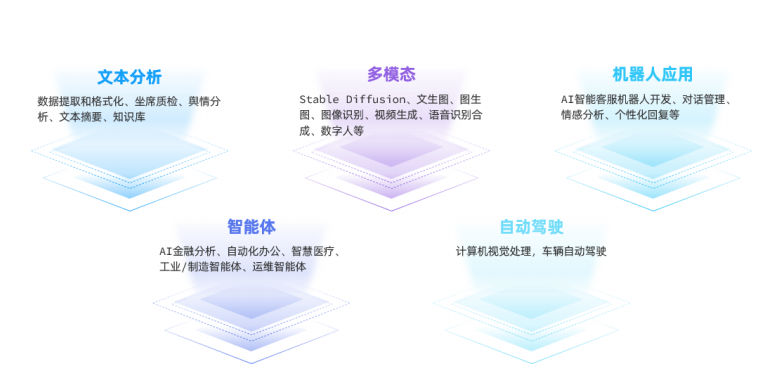


)




—模板方法模式)






:快速入門操作系統常見基礎概念)
)


)
 技術報告--2025.7.23--字節跳動 Seed)