0. 前言
前兩天字節發布了GR-3,粗略的看了一下,在某些方面超過了SOTA pi0,雖然不開源,但是也可以來看一看。
官方項目頁

1. GR-3模型
1.1 背景
在機器人研究領域,一直以來的目標就是打造能夠幫助人類完成日常任務的智能通用機器人。一個核心挑戰在于現實世界的多樣性極高,因此機器人策略需要具備很強的泛化能力,才能應對各種新場景。而且,許多日常任務本質上是長周期的,需要復雜的靈巧操作,這就要求機器人策略必須非常穩健可靠。
最近在視覺-語言-動作(VLA)模型方面的進展,為開發智能通用機器人策略開辟了有希望的道路。這些模型以預訓練的視覺-語言模型(VLMs)為基礎,并融合了動作預測功能,使機器人能夠根據自然語言指令執行各類任務。盡管取得了這些進展,機器人執行指令依然是個重大挑戰,尤其是對于“分布外”指令(即含有機器人軌跡數據中未見過的新物體類別和/或需要復雜推理的概念)更是難上加難。
此外,VLA 模型通常需要大量示范數據來訓練策略,這給高效適應新環境帶來了巨大挑戰。最后,在復雜的長周期任務中確保穩健性仍然具有挑戰性,因為誤差會累積,尤其是在處理可變形物體等需要靈巧技能的任務中。
1.2 相關技術
通用操作策略
構建能按照指令與真實世界高效交互的通用操作策略,一直是機器人學研究中的老大難問題,先前工作 [33,53,61,74] 建議先從大規模數據中學習通用表征,再用于后續策略學習,以在復雜任務中獲得更魯棒的機器人行為。
最近在視覺-語言-動作(VLA)模型上取得的進展,通過多種手段加強策略的泛化能力與操作能力。一大波研究 [9,18,29,37,41,49,55,58,60,68,70] 使用“跨載體數據”訓練策略——即收集自不同機器人平臺的軌跡數據。
除了真實軌跡數據,還有研究 [9,11,29] 借助預訓練的視覺-語言模型來構建機器人策略,展現了對未見場景的強大泛化能力。另一種提升泛化的方法是:在海量網絡視頻上進行未來幀預測 [8,13,20,28,40,73],或從無動作標簽的視頻中學習潛在動作(latent actions)[7,12,77]。
本工作提出了 GR-3——一個在機器人軌跡和視覺-語言數據上聯合訓練的 VLA 模型,并可通過少量人類演示實現高效微調。
通過大量實驗,作者證明 GR-3 能:1)嚴格跟隨指令,并對新物體、新環境和新指令實現泛化;2)借助少樣本人類軌跡高效適應新場景;3)以高魯棒性執行長序列與靈巧任務。
機器人操作的多模態聯合訓練
真實機器人軌跡采集成本高、耗時久。因此,要擴展策略訓練規模,多元化數據源就尤為關鍵。
一個常用思路是:先用預訓練視覺編碼器 [33,50,53,61,74] 或視覺-語言模型 [7,9,11,29] 初始化策略網絡。在這一框架基礎上,自然會在訓練中引入除機器人軌跡外的多模態數據 [11,29,58,63,76]。
例如 GATO [63] 構建了一個通用智能體,能執行圖像描述、用真實機器人堆積積木等多種任務。它將不同模態的數據轉為統一的 token 序列,并用大型 Transformer 進行下一個 token 預測。
RT-2 [11] 表明:同時用機器人軌跡和視覺-語言數據微調大型視覺-語言模型,可顯著增強泛化能力。通過對異構數據聯合訓練,π0.5 在多環境、多物體上展現出卓越的泛化性能,可有效部署于真實未見場景。
我有一個疑問,機器人軌跡可以轉成lerobot格式去微調模型,視覺語言數據怎么使用呢?
本工作中,GR-3 也采用了類似共訓練策略——從多源構建了精心設計的網絡級視覺-語言數據集,并在諸多視覺-語言任務上進行了大規模聯合訓練。通過大規模聯合訓練,GR-3 在零樣本泛化方面表現強勁——無論是新物體,還是需要抽象概念推理的復雜指令。
利用人類數據進行策略訓練
為提升數據效率,將人類數據引入策略訓練已成為機器人研究的熱門思路。一系列研究 [1,5,51,72] 從人類視頻中提取多種表征,用于豐富策略學習。Wu 等 [73] 與 Cheang 等 [13] 建議利用大規模人類視頻 [16,23,24] 進行生成式視頻預訓練。
近期,隨著手部跟蹤和 VR 設備的發展,Qiu 等 [59] 與 Kareer 等 [34] 發現在少量機器人數據配合下,用含手部軌跡的人類視頻聯合訓練,可提升策略在機器人平臺上的表現。
在本報告中,我們沿襲這一研究思路,證明了 GR-3 可通過少樣本人類軌跡學習,有效適應新場景。
同樣的疑問,這種人類視頻怎么使用呢?
1.3 GR-3概述
在本報告中,字節匯報了在構建通用機器人策略方面的最新進展,即開發了 GR-3。
GR-3 是一個大規模的視覺 - 語言 - 動作(VLA)模型,如圖1所示。
- 它對新物體、新環境以及含抽象概念的新指令展現出較好的泛化能力。
- 此外,GR-3 支持少量人類軌跡數據的高效微調,可快速且經濟地適應新任務。
- GR-3 在處理長周期和靈巧性任務(包括需要雙手操作和底盤移動的任務)上也展現出穩健且可靠的性能。
這些能力源自—種多樣的訓練方法,具體包括:利用大規模的視覺 - 語言數據聯合訓練、征集了用戶授權的基于 VR 設備的人類軌跡數據進行高效微調,以及基于機器人軌跡數據進行有效地模仿學習。此外,他們還推出了一款雙臂移動機器人 ByteMini。ByteMini 兼具靈巧性和可靠性,集成了 GR-3 后,能完成各式各樣的復雜任務。
GR-3 的輸入包括自然語言指令、環境觀測和機器人狀態;它輸出一段動作序列,用于端到端地控制雙臂移動機器人。具體來說,GR-3 構建在一個預訓練視覺-語言模型基礎上,并通過流匹配(flow-matching)方法預測動作。
作者對模型架構進行了細致研究,并引入了一系列精心挑選的設計方案,這些對執行指令能力和長周期任務性能至關重要。為了提升泛化能力,在機器人軌跡數據和涵蓋多種視覺-語言任務的大規模數據上對 GR-3 進行聯合訓練。
這種訓練方法使 GR-3 不但能處理新類別的物體,還能理解與大小、空間關系和常識相關的抽象概念(見圖?2),而這些在機器人軌跡數據中并未出現過。

此外,作者展示了 GR-3 能通過 VR 設備收集的少量人類示教數據進行高效微調,從而快速且低成本地適應新環境。
通過在三個具有挑戰性的真實場景任務中進行了大量實驗:
- 通用的抓取與放置
- 長周期的桌面收拾(table?bussing)
- 靈巧的布料操作。
他們證明 GR-3 在眾多具有挑戰性的任務上都超越了最先進的基準方法 π0。它展現出將新類別物體泛化及理解復雜語義的強大能力。此外,它僅需每個新物體 10 條人類示教軌跡就能高效適應。
最后,GR-3 在長周期和靈巧任務中表現出顯著穩健,在桌面收拾和布料操作等挑戰性任務中取得了高平均任務進度。
1.4 GR-3模型
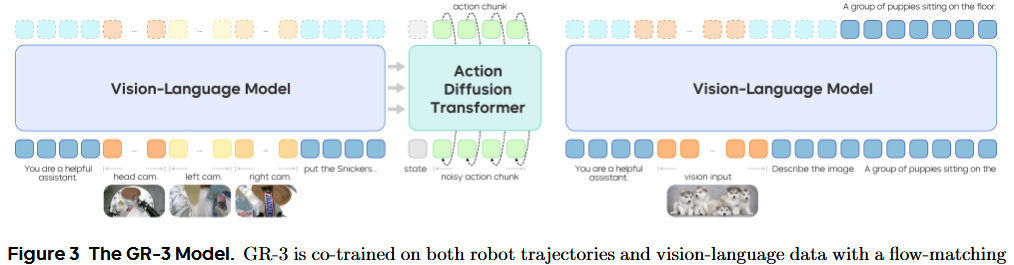
GR-3 是一個端到端的視覺-語言-動作(VLA)模型 πθπ_θπθ?,它通過生成一段長度為 k 的動作序列 a?:??? 來控制帶輪子的雙手機器人,該生成過程依賴于輸入的語言指令 l、時刻 t 的環境觀測 o? 和機器人狀態 s?;即 a? = π?????(l, o?, s?)。
GR-3 采用了“混合變換器”(mixture-of-transformers)架構。它先用預訓練視覺-語言模型(VLM)Qwen2.5?VL?3B?Instruct處理來自多路相機的觀測圖像和語言指令,然后用**動作擴散變換器(DiT)**來預測動作序列。具體來說,GR-3 在動作預測時采用了流匹配(flow matching)方法。
流匹配的預測依賴于當前的機器人狀態 s? 以及視覺-語言主干網絡(backbone)輸出的鍵值緩存(KV cache)。長度為 k 的動作序列 a? 會被分成 k 個 token,再與機器人狀態的 token 拼接,形成動作 DiT 的輸入序列。作者在動作 DiT 中使用因果注意力掩碼(causal attention mask),以建模動作序列內部的時間依賴關系。
因果注意力掩碼:確保模型預測第 i 步動作時,只能“看到”前面 i?1 步,而不會竊取未來信息,就像寫小說只能先寫前面再寫后面。
為了保證推理速度,動作 DiT 的層數只有視覺-語言主干網絡的一半,且只使用后半部分 VLM 層輸出的 KV cache。整體來說,GR-3 擁有大約 40 億(4?B)個參數。
在早期嘗試中,發現訓練過程常出現不穩定現象。受到 QK norm 方法【26】的啟發,在 DiT 模塊中的注意力層和前饋網絡(FFN)內部的線性層后,額外使用了 RMSNorm 歸一化【78】。
RMSNorm:一種比傳統 LayerNorm 更簡單高效的歸一化技巧,有助于平穩梯度,提升訓練穩定度。
這一設計顯著提升了整個訓練過程的穩定性。此外,作者發現在下游任務實驗中,這一改進也大幅增強了模型對語言指令的執行能力(詳見第?4 節)。
2. 訓練流程
作者在多種數據源上訓練 GR-3 模型,包括用于模仿學習的機器人軌跡數據、用于聯合訓練的海量視覺-語言數據,以及用于少樣本泛化的人類軌跡數據。
這種訓練方案使 GR-3 能
- 泛化到新物體、新環境和新指令
- 以低成本高效地適應未見場景
- 穩健地執行長周期和靈巧任務
2.1 用機器人軌跡數據進行模仿學習
通過最大化策略在專家示范集 D 上的對數似然來訓練 GR-3 的模仿學習目標:

具體地,我們在訓練中用流匹配損失來監督動作預測:

其中 τ~U(0,1)表示流匹配的時間步,atτ是加噪動作,其中 ?~N(0,I)是隨機噪聲,u=at??是流預測的真實標簽。
為了加快訓練,在一次 VLM 主干網絡前向過程中,對多個隨機抽樣的流匹配時間步計算損失。推理時,動作序列以隨機噪聲初始化,然后用歐拉方法從 τ=0積分到 τ=1。實驗中 Δτ=0.2。
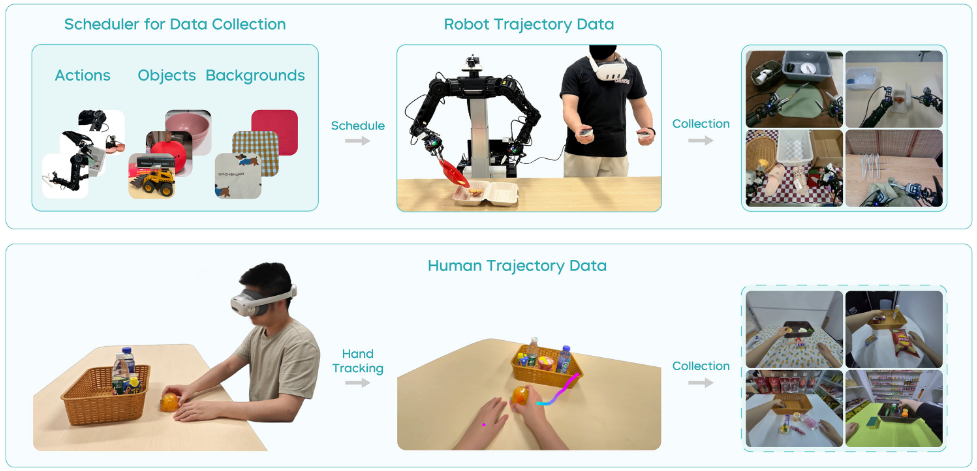
通過遠程操控采集真實機器人軌跡。為了讓采集更可控并最大化數據多樣性,他們開發了一個數據采集調度程序(見圖?4),向操作者提示 1)要執行的動作,2)物體組合,3)背景設置。
在每次軌跡采集開始時,系統會生成新的環境配置,操作者據此布置場景。該調度程序的實現能有效管理數據分布并徹底隨機化采集數據,大大提升了數據集的豐富性和多樣性。此外,采集后還需進行質量檢查,過濾掉無效或低質量的數據,以優化數據集。
以往研究指出,策略可能利用來自多視角的“虛假關聯”進行動作預測,而非真正關注語言指令。為了解決這一問題,引入“任務狀態”作為額外動作維度,用于輔助監督。任務狀態有三種:Ongoing(進行中,0),Terminated(已完成,1),Invalid(無效,?1)。
訓練時,會隨機用無效指令替換真實指令,并只讓模型預測 Invalid 狀態,而不監督其他動作維度。這一設計迫使動作 DiT 必須關注語言指令并判斷任務狀態,大幅提升了模型執行語言指令的能力(詳見第?5.2 節)。
2.2 視覺-語言數據上進行聯合訓練
為了賦予 GR-3 對分布外(OOD)指令的泛化能力,在機器人軌跡數據和視覺-語言數據上對其進行聯合訓練(見圖?3)。機器人軌跡數據用流匹配目標訓練 VLM 主干網絡和動作 DiT。
視覺-語言數據僅用下一個 token 預測目標訓練 VLM 主干網絡。為了簡單起見,在每個小批次中以等比例動態混合視覺-語言數據和機器人軌跡。因此,聯合訓練的目標就是下一個 token 預測損失與流匹配損失之和。
通過與視覺-語言數據的聯合訓練,GR-3 能夠以零樣本方式有效泛化到未見物體,并理解復雜概念的新語義。
作者從多種來源整理出一個大型視覺-語言數據集。該數據集涵蓋了多種任務(見圖?4),包括圖像描述、視覺問答、圖像定位和交叉定位描述。
他們還開發了過濾和重新標注流程,以提高數據集質量,確保聯合訓練效果。聯合訓練不僅幫助 GR-3 保留預訓練 VLM 的強大視覺-語言能力,還使動作 DiT 在動作預測中利用這些能力,從而有效提升下游操作任務的泛化能力。
2.3 用人類軌跡數據進行少樣本泛化
GR-3 是一款多功能的 VLA 模型,可以輕松微調以適應新場景,然而采集真實機器人軌跡既耗時又昂貴。VR 設備與手部追蹤技術的最新進展帶來了直接從人類軌跡數據學習動作的良好機會。本報告中,將 GR-3 高效微調能力擴展到從極少人類軌跡中進行少樣本學習的挑戰場景。
具體來說,在新場景下使用 PICO?4 Ultra Enterprise 收集少量人類軌跡數據。借助 VR 設備,人類軌跡可達每小時約?450 條,遠超遠程操控機器人每小時?250 條的速度。這種高效率促成了對新環境的快速且低成本適應。
具體來說,采集到的人類軌跡數據包括第一人稱視角視頻和手部軌跡。沿用機器人軌跡的標注流程,為人類軌跡數據添加語言標簽。在完成第一階段的視覺-語言數據和機器人軌跡訓練后,加入人類軌跡數據,對三種數據同時進行聯合訓練。
與機器人軌跡不同,人類軌跡僅包含第一人稱視角和手部軌跡,不含手臂關節狀態或夾爪狀態。因此,需要為缺失的腕部視角填充空白圖像,并僅用手部軌跡來訓練模型處理人類軌跡數據。
3. 硬件與系統
3.1 ByteMini Robot
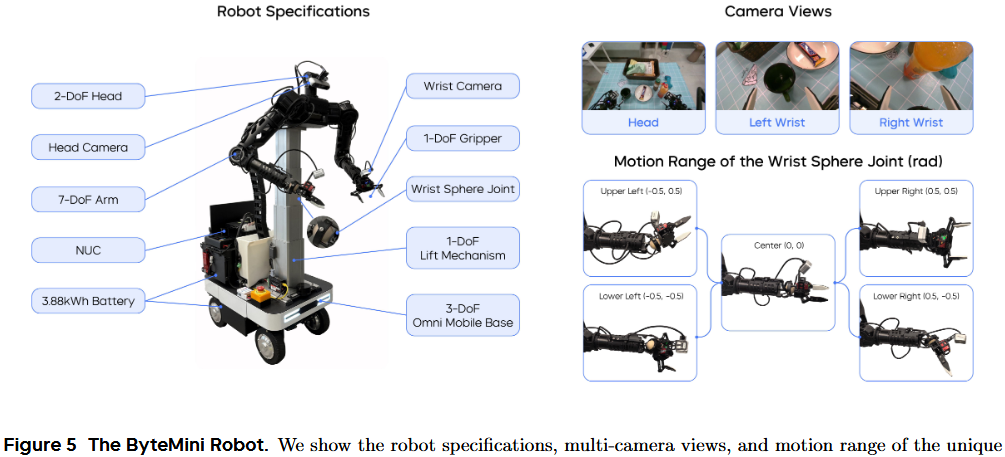
ByteMini 機器人(見圖?5)被用于數據采集和策略執行。這款擁有 22 個自由度的雙手機動機器人,圍繞三個核心目標設計:靈活操作、高可靠性和易用性。這只擁有 7 個自由度的無偏置機械臂,采用了獨特的球形腕關節設計,實現了類似人手的靈巧度。
緊湊的球形腕設計(見圖?5)克服了傳統 SRS 結構機械臂腕部體積過大、在狹小空間難以靈活操作的問題。機械臂肘部特別設計,可向內大幅度收攏至 2.53?弧度,使兩臂能在機器人胸前區域完成精細操作。在數據采集和策略執行時,繁重任務要求 ByteMini 必須具備極高的穩定性和一致性。
采用帶升降機構的全向移動平臺,實現了平面移動和垂直高度調整的穩定控制。為進一步提升可靠性并確保運動一致性,臂部執行器采用了準直接驅動(QDD)原理設計,該原理以穩定和高響應性著稱。
為提高易用性,在機器人上集成了便攜式屏幕和一臺 NUC(小型電腦),并配備雙鋰電池,可在多種場景下持續工作超過 10?小時。此外,ByteMini 配備了無線緊急停止裝置(E-stop),可在緊急情況下迅速斷電停機。在機器人頭部和兩只手腕上安裝了 RGBD 相機。腕部相機可進行近距離觀測,以輔助精細操作。
3.2 系統與控制
Whole-body compliance control
基于全身順應性控制框架,將所有自由度作為一個整體結構,將任意遠程操控的人體動作映射到機器人可行的運動上。在實時最優控制問題中,同時考慮可操縱性優化、奇異位置避免和關節物理極限,以最大化機器人靈巧度。
這樣可以在大工作空間中生成流暢連續的動作,用于各種長周期操作任務,并產出高質量的專家級軌跡供策略訓練。順應性力控制器使機器人能進行高動態動作并與環境發生物理交互,提升安全性和數據采集效率。
全身遠程操控
采集時通過 Meta?VR?Quest 實現全身動作映射,直觀易用地將人類動作直接傳遞給機器人末端執行器。操作者可同時控制機械臂、升降機構、夾爪和底盤移動,使在真實環境下對復雜長周期任務的數據采集更加無縫順暢。
策略執行的軌跡優化
用預測得到的動作序列來控制機器人的 19 個自由度(不含升降機構和頭部的 3 個自由度)進行策略執行。引入純追蹤算法和軌跡優化方法,以提升 GR-3 在策略執行時生成軌跡的穩定性和平滑度。實時參數化優化可最小化加速度突變(jerk),并確保在路徑點之間及各條軌跡間的平滑銜接。
4. 實驗
在真實環境中進行了大量實驗,以全面評估 GR-3 的性能。在這些實驗中,希望回答以下四個問題:
- GR-3 是否能嚴格執行指令,包括訓練時沒見過的新指令?
- GR-3 能否泛化到分布外場景,比如新物體、新環境、新指令?
- GR-3 是否能通過少量人類軌跡學習并遷移到機器人身體?
- GR-3 是否能學到穩健策略,勝任長周期且靈巧的任務?
作者設計了三項任務:可泛化的抓取放置、長周期餐桌整理,以及靈巧的布料掛放。歡迎訪問項目主頁觀看演示視頻。作者將方法與最先進基線 π? 進行了對比。他們按照官方 GitHub 中的說明,對 π? 基于其在大規模機器人數據上預訓練的基礎模型,分別在三項任務上進行微調。
4.1 可泛化的 Pick-and-Place
為了評估 GR-3 在分布外場景下的泛化能力,我們在一個以泛化為目標的抓取放置任務上進行測試。作者共采集了 3.5 萬條機器人軌跡,涵蓋 101 種物體,總時長約 69?小時。為軌跡標注了“將?A?放入?B”指令,其中 A 是物體類別,B 是容器。
對于基線 π?,僅用機器人軌跡數據微調;而 GR-3 則用機器人軌跡和視覺-語言數據一起聯合訓練。訓練時,對軌跡圖像進行光度增強,以提升對環境變化的魯棒性。還對比了不做聯合訓練的 GR-3?w/o?Co-Training,僅用機器人軌跡訓練。該消融研究可評估視覺-語言聯合訓練的效果及其對性能的具體貢獻。
實驗設置
在四種設置下評估:1) 基礎場景、2) 未見環境、3) 未見指令、4) 未見物體
- 在基礎場景,他們在訓練中見過的環境里測試,用 54 種訓練時見過的物體(見圖?6(a))來檢驗基本執行指令能力。

- 在未見環境,用相同的 54 種物體,在四個訓練時未見過的現實環境中測試:收銀臺、會議室、辦公桌和休息室(見圖?6?)。物體布局保持與基礎場景一致。

- 在未見指令中,給模型下達需復雜概念推理的指令,如“把左邊的可樂放入紙箱”“把有觸手的動物放入紙箱”。
- 在未見物體設置下,用 45 種在軌跡數據中沒見過的物體測試(見圖?6(b))。

作者用“執行指令率(IF?rate)”和“成功率”來評估模型,分別衡量模型按指令行動的能力和完成任務的整體表現。
對于 IF?率,只要機器人正確靠近指令指定的物體,該次試驗即判成功。對于成功率,只有當機器人將目標物體放入容器后,才算成功。對于這兩項指標,得分越高表示能力越強。
基本指令跟隨
在基礎和未見環境設置中,將 54 種已見物體分為九個小批次,每個批次六個物體。在每一次試驗中,根據給定指令,要求模型從 6 個對象中挑選出一個。為了保證不同模型結果的可比性,采用預先拍攝的掩碼來固定物體位置,確保每個小批次的布局在評測中盡可能一致。
如圖 7(a) 所示,GR-3 在“基礎環境”和“未見環境”中,無論是 IF(Instruction Following)率還是成功率,都超越了 π0。
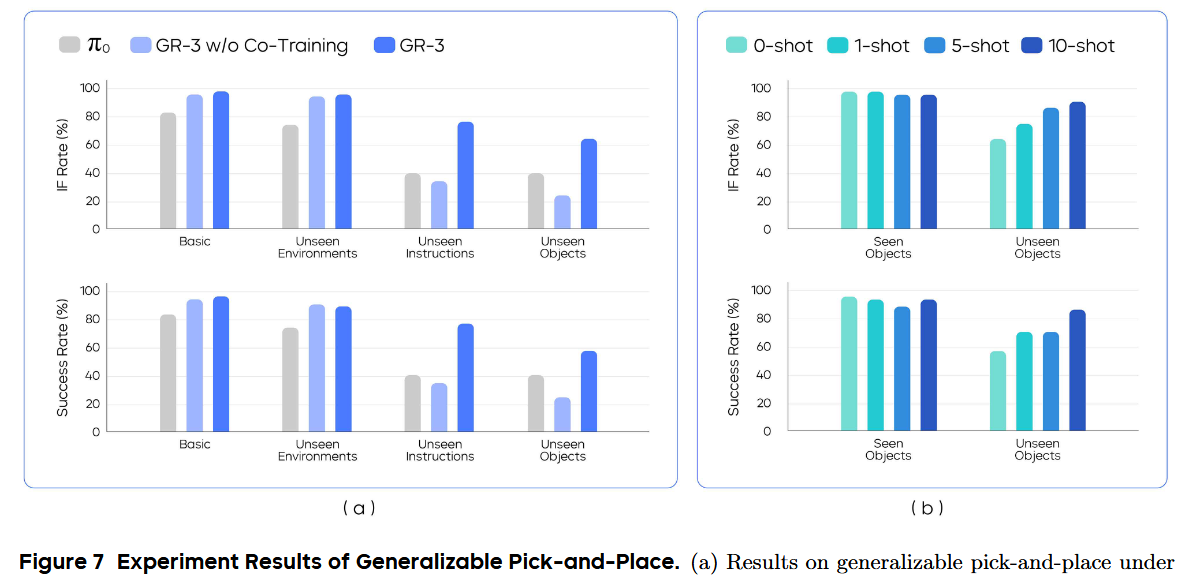
在“基礎環境”和“未見環境”之間僅有小幅性能下降,凸顯了 GR-3 對環境變化的魯棒性。此外,發現有無“聯合訓練”(Co-Training)時,GR-3 在這兩種設置下表現差異不大,說明對于已見對象,聯合訓練并不會影響其性能。
泛化指令跟隨
在“未見指令”(Unseen Instructions)中,測試模型理解抽象概念的能力——比如大小、空間關系和常識。示例指令包括“把可樂放到雪碧旁邊再放進箱子”、“把最大的物體放進箱子”,以及“把第 9 個海洋動物放進箱子”。這些指令在機器人軌跡數據中未曾出現,要求模型推理其中復雜的語義。
在“未見對象”(Unseen Objects)中,將 45 種新對象分成九個小批次,每批次 5 個,對應每次試驗要從 5 個對象中選一個。這個設置尤為具有挑戰性,因為在這 45 個對象中,有超過 70% 屬于機器人軌跡數據里未曾出現的類別。如圖 7(a) 所示,GR-3 在兩種設置中都大幅超越 π0,凸顯了其出色的泛化能力。
它將“未見指令”的成功率從 40% 提升到 77.1%,并將“未見對象”的成功率從 40% 提升到 57.8%。在這兩種設置下,GR-3 也明顯優于未做聯合訓練的版本,說明引入視覺-語言(VL)數據的聯合訓練,有助于增強泛化能力。
這種 VLA 模型能夠將大規模視覺-語言數據中的豐富知識有效遷移到策略學習中,并在新的場景下實現強大的零樣本(zero-shot)能力。
還發現,僅用機器人軌跡訓練的 GR-3,表現不如 π0 基線。π0 之所以更強,是因為它進行了大規模的跨載體(cross-embodiment)預訓練。
基于人類軌跡的少樣本泛化
使用 VR 設備收集的人類軌跡,評估模型的少樣本泛化能力。這很有挑戰性,原因有兩點:1)模型要從跨載體數據中學習;2)數據非常稀缺。具體而言,在“未見對象”設置中,為45個未見物體最多收集了 10 條人類軌跡(見圖 6(b))。這 450 條人類軌跡總時長約 30 分鐘。
在已有用機器人軌跡和 VL 數據訓練出的檢查點基礎上,進行增量訓練。再聯合訓練 20,000 步,將人類軌跡與原有機器人軌跡和 VL 數據一起融合訓練。
在已見和未見對象上,分別測試了 1、5、10 條示例(1-shot、5-shot、10-shot)下的表現(見圖 7(b))。相比基礎模型的零樣本表現,通過增加人類軌跡數據,持續提升 IF 率和成功率;僅用每個對象 10 條人類軌跡,就能將成功率從 57.8% 提升到 86.7%。
另外,可以發現已見對象的表現并未明顯下降,說明該少樣本微調策略既高效又經濟,能將預訓練的 VLA 模型快速適配到下游新場景。
4.2 長時序桌面清理
在“清理餐桌”任務上進行實驗,以評估 GR-3 在處理長時序 manipulation 時的魯棒性(見圖 8)。在該任務中,機器人需要收拾桌面上凌亂的餐具、食物、外帶餐盒和塑料清餐箱。

為完成此任務,機器人需:1)將食物裝入外帶餐盒;2)將所有餐具放入清餐箱;3)將所有垃圾投入垃圾桶。由于工作區較大,機器人要從外帶餐盒處移動底盤到清餐箱處,才能完成整個任務(見圖 8(a))。
在 Flat 設置(圖a)和“指令執行”(IF,圖b)設置下對模型進行評估。
Flat 設置
在 Flat 設置中,給機器人一個總任務指令“清理餐桌”,讓它在一次流程中自主完成全部子任務(見圖 8(a))。這種設置幫助我們評估模型處理長序列任務的魯棒性。
以“平均任務進度”作為評估指標,即已完成子任務數與總子任務數的比值。值為 1.0 表示完全成功,其他小于 1 的值表示部分成功。在五組不同的物體組合上進行了評測。
IF 設置
在 IF 設置中,進一步評估模型執行指定指令的能力。連續給出多個子任務描述,例如“把紙杯放進垃圾桶”,來指導機器人清理餐桌。機器人從“home”開始執行每條子任務。以“平均子任務成功率”作為評估指標。
IF 設置共包含六種指令場景(見圖 8(b))
- 基礎:物體布局與訓練時非常相似。
- 多物體:在場景中加入某些物體類別的多份實體,并下達“把所有該類別物體放入清餐箱或垃圾桶”的指令。
- 多目標:在場景中加入一個織物籃,并指令機器人將餐具放入織物籃或清餐箱。
- 多實例&多目標:把“多實例”和“多目標”結合,指令機器人將某類別的所有實例送往兩者之一。
- 新目標:讓機器人把物體放到訓練時未曾一起出現過的目的地,例如“把叉子放進垃圾桶”。
- 無效任務:實際應用中,機器人需識別并拒絕不合理指令。例如桌上沒藍碗,卻指令“把藍碗放進塑料箱”就應視為無效。在此情況下,希望策略能拒絕執行不合理的任務。在此設置中,下達與觀測不符的任務。只有當模型在 10 秒內不對任何物體動手時,才算該試驗成功。
開始實驗
為本任務,共收集了約 101 小時的機器人軌跡數據。在基線方法中,在這些軌跡數據上微調 π0。
我錄的一條夾3個橘子的回合只有20-50s,合著需要10000條左右才能有人家的數據量。但是他這一條肯定沒有我這么短
對于 GR-3,同時使用機器人軌跡和視覺-語言(VL)數據進行聯合訓練。還做了兩種消融實驗:GR-3 w/o Norm(去掉 RMSNorm)和 GR-3 w/o Task Status(去掉任務狀態輸入,簡稱 TS)。
GR-3 w/o Norm 去掉了 DiT 模塊中 attention 和 FFN 里的 RMSNorm。
GR-3 w/o TS 在訓練時不使用任務狀態輸入。
對所有方法,分別為 Flat 和 IF 設置訓練兩個獨立模型。在 Flat 設置下的訓練中,隨機采樣“總任務”或“子任務”作語言指令。在 IF 版訓練中,僅使用子任務作為指令。
結果
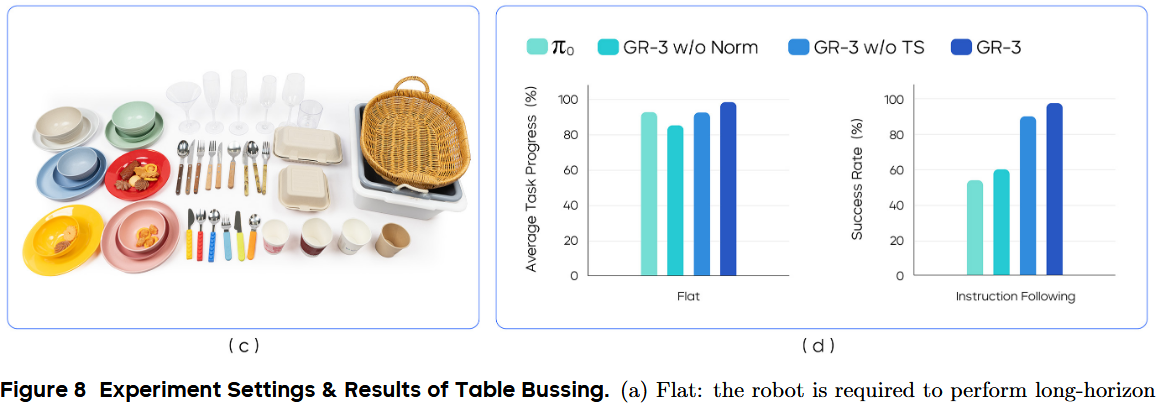
如圖 8(d) 所示,GR-3 在兩種設置中都優于 π0,尤以 IF 設置最明顯(成功率 53.8% vs 97.5%)。雖然 π0 能完成長序列清餐任務,但在指令執行上,特別是分布外場景中,表現較差。
它分不清叉子和勺子。在新目標場景中,它會把物體放到與該物體在訓練時出現過的容器里,而不是按指令行事。而 GR-3 在六種測試中都嚴格執行指令,對多實例和多目標場景泛化良好,并能在無效任務中拒絕操作。
去掉 RMSNorm 會降低兩種設置下的性能,尤以 IF 場景影響最大。GR-3 w/o Norm 無法很好地執行指令,特別是對新目標無法泛化。缺少任務狀態輸入時,IF 能力也會下降,凸顯了任務狀態對 VLA 模型執行指令的輔助作用。
4.3 靈巧操作-疊衣服
在此實驗中,評估 GR-3 在對可變形物體進行靈巧操作(dexterous manipulation)方面的表現。具體地,讓模型使用衣架將衣物掛到晾衣架上(見圖 2)。在此任務中,機器人需:1)抓起衣架;2)將衣物掛到衣架上;3)將掛好衣服的衣架掛到晾衣架上。
在最后一步,機器人需將底盤從桌邊轉向晾衣架所在位置,以便掛衣服。為本任務,我們共收集了約 116 小時的機器人軌跡數據。用這些數據微調 π0;而對 GR-3,則同時用機器人軌跡和視覺-語言數據進行聯合訓練。在三種評測設置下進行測試:Basic(基礎)、Position(位置變化)和 Unseen Instances(未見實例)。
實驗設置
在 Basic 設置中,測試六件訓練階段見過的衣物,且其擺放方式與訓練時相似。在 Position 設置中,我們如圖 9(b) 所示對衣物進行旋轉和揉皺處理。

Position 設置評估模型應對復雜衣物布局的魯棒性。在 Unseen Instances 設置中,測試模型對訓練中未見過衣物的泛化能力。具體地,我們在四件未曾見過的衣物上進行評測(見圖 9(a))。訓練數據中所有衣物都是長袖,但測試集里有兩件短袖。
以“平均任務進度”作為評估指標,完整掛好衣服(最終里程碑)對應 1.0。整個過程分為四個關鍵節點:1)抓起衣架;2)將右肩掛到衣架上;3)將左肩掛到衣架上;4)將衣架掛到晾衣架上(見圖 10(a))。每個里程碑都會對整體進度貢獻一個分數片段。
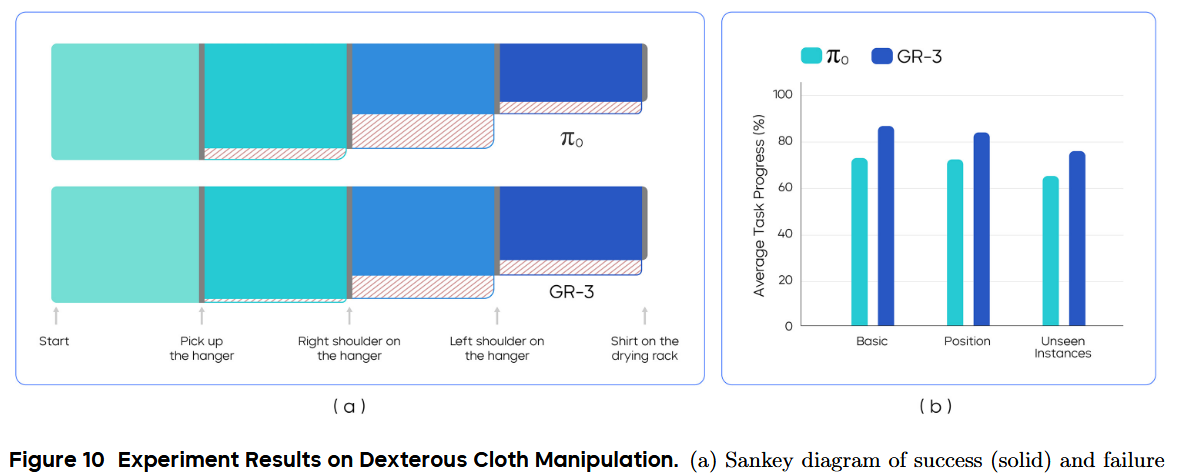
結果
結果見圖 10。GR-3 在三種設置下均優于 π0。它在 Basic 和 Position 中的平均任務進度分別達到 86.7% 和 83.9%,展現了對復雜靈巧操作的熟練度以及對布局變化的魯棒性。此外,GR-3 能泛化到擁有新圖案和不同袖長的未見衣物,平均任務進度達 75.8%。
為深入分析執行過程,在圖 10(a) 中繪制了 Basic 設置下四個里程碑成功與失敗的圖(Sankey diagram)。對兩種模型來說,最具挑戰的是在掛好右肩后再掛左肩這一步。這是因為機器人在手持衣架的同時,需要將左領部拉出——它常常折疊在衣架后面——才能抓取。
另一個失敗模式是,在掛左肩過程中衣架從爪手中滑落,導致最后一步失敗。
5. 結論與討論
5.1 限制與未來工作
盡管在多項高難度任務中表現強勁,GR-3 仍存在局限。雖然展現了出色的泛化能力,但在執行涉及新概念和新物體的未見指令時會出錯,并且在抓取未見形狀的物體時表現不佳。
他們計劃擴大模型規模和訓練數據,以持續提升其處理新場景的能力。此外,與所有模仿學習方法類似,GR-3 在執行過程中可能陷入分布外狀態,無法自我恢復導致失敗。
未來,將擬引入強化學習(RL),以增強在復雜與靈巧任務上的魯棒性,并突破模仿學習的固有局限。
5.2 結論
在本報告中,提出了 GR-3——一個能輸出動作指令以控制雙臂移動機器人的強力視覺-語言-動作(VLA)模型。seed深入研究模型架構,并制定了結合大規模視覺-語言數據聯合訓練、高效少樣本人類軌跡學習以及有效機器人軌跡模仿學習的全方位訓練方案。
在三項高難度真實任務上的大量實驗表明,GR-3 能:理解帶抽象概念的復雜指令;對新物體和新環境有效泛化;從極少人類演示中高效學習;以極高的魯棒性和可靠性執行長序列與靈巧任務。期望 GR-3 能成為構建通用機器人、在現實世界中為人類完成多樣任務的基石。


)










)


 詳細解釋,使用 PyTorch代碼示例說明)


