概述
這篇題為"NAS-Bench-101: Towards Reproducible Neural Architecture Search"的論文由Chris Ying等人合作完成,旨在解決神經網絡架構搜索(NAS)領域面臨的重大挑戰:計算資源需求高和實驗難以復現的問題。
論文提出了NAS-Bench-101,這是第一個公開的NAS研究架構數據集。通過精心構建一個緊湊但表達力強的搜索空間,并利用圖同構識別423k個獨特的卷積架構,作者訓練并評估了這些架構在CIFAR-10上的表現,最終編譯成一個包含超過500萬訓練模型結果的大型數據集。
貢獻
??NAS-Bench-101數據集??:首個大規模開源的NAS架構數據集,使研究人員能夠在毫秒級別評估各種模型的質量,而無需實際訓練模型。
??搜索空間分析??:首次全面分析NAS搜索空間的特性,揭示了可能指導NAS算法設計的見解。
??算法基準測試??:展示了如何使用該數據集對各種開源NAS優化算法進行快速基準測試。
架構設計
- 采用細胞(cell)結構,每個細胞由最多7個節點組成的有向無環圖(DAG)
- 使用三種基本操作:3×3卷積、1×1卷積和3×3最大池化
- 限制最大邊數為9
- 通過圖同構識別出423k個獨特架構
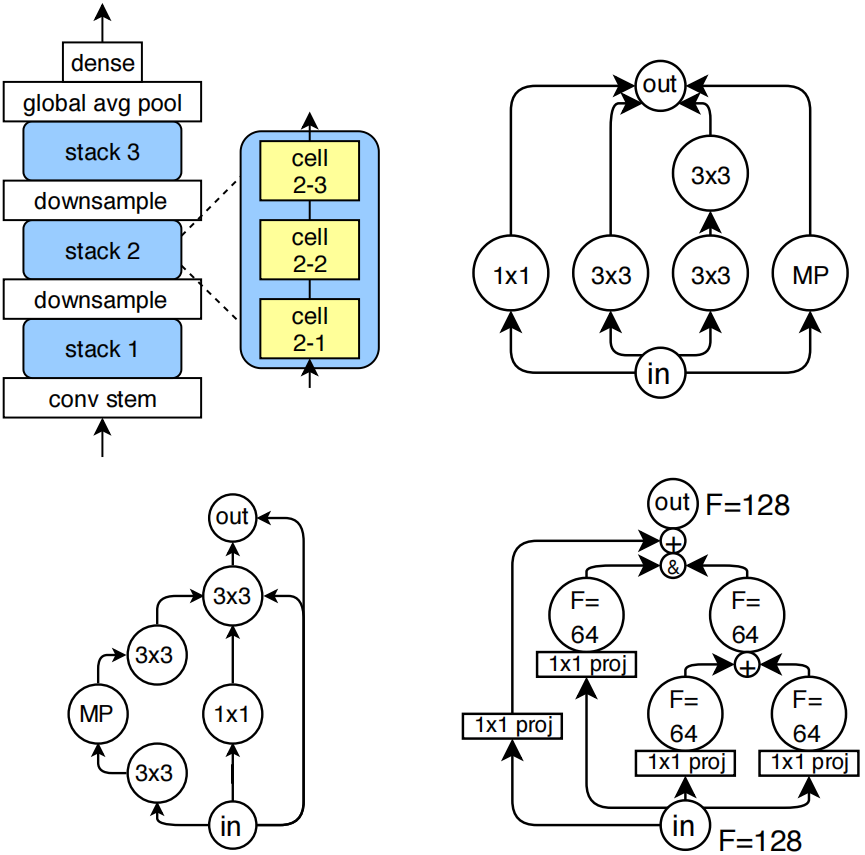
圖1:(左上)各模型的外部架構示意圖。(右上)一個類似Inception的卷積單元,其原始5x5卷積結構通過兩個3x3卷積進行近似處理(省略了拼接和投影操作)。(左下)測試誤差均值最低的卷積單元(省略了投影層)。(右下)展示通道計數自動確定方式的典型單元示例(“+”表示加法運算,“&”表示拼接;使用1×1投影來縮放通道計數)。
(右上和左下都是左上這個架構圖內部的cell的結構,右上是inception cell,左下是最佳cell,右下是每個cell的更細節展示,包括了他們的輸入輸出的連接方式。根據后面論文的描述,每個cell最多有7個節點、9條邊,輸入都是&操作,輸出都是&操作。)
訓練過程
- 所有模型在CIFAR-10上訓練和評估
- 使用固定超參數集,通過RMSProp優化器訓練
- 每個架構重復訓練3次以獲得方差測量
- 采用四種不同的epoch預算(4,12,36,108)來支持多保真度優化方法
數據集指標
數據集映射每個架構到以下指標:
- 訓練準確率
- 驗證準確率
- 測試準確率
- 訓練時間(秒)
- 可訓練模型參數數量
數據集分析發現
性能分布
- 大多數架構能達到100%的訓練準確率
- 驗證和測試準確率多數超過90%
- 最佳架構平均測試準確率達到94.32%
- ResNet-like和Inception-like細胞分別達到93.12%和92.95%
架構設計影響
- 用1×1卷積或3×3最大池化替換3×3卷積通常會導致絕對最終驗證準確率下降
- 深度為3時平均驗證準確率最優
- 寬度增加似乎會提高驗證準確率,最高達到5(數據集中的最大寬度)
局部性特征
- 搜索空間表現出局部性,即"相近"架構往往具有相似性能
- 隨機游走自相關(RWA)顯示低距離時相關性高
- 全局最大值周圍的鄰域也顯示出局部性
算法基準測試結果
論文比較了多種NAS和超參數優化算法:
- 隨機搜索(RS)
- 正則化進化(RE)
- SMAC
- TPE
- Hyperband(HB)
- BOHB
- 強化學習(RL)
主要發現:
- RE、BOHB和SMAC表現最佳,在約50000 TPU秒后開始優于RS
- SMAC作為貝葉斯優化方法表現良好,盡管存在無效架構問題
- TPE表現不佳,性能回落到隨機搜索水平
- 多保真度優化算法HB和BOHB未顯示出常見加速效果
- RL雖然最終優于RS,但收斂到全局最優的速度慢得多
論文的第二節詳細介紹了nas的架構。
2. The NASBench Dataset
NAS-Bench-101數據集是一張將神經網絡架構與訓練評估指標對應起來的表格。目前大多數神經架構搜索方法都選擇在CIFAR-10分類數據集上訓練模型,因為該數據集的小尺寸圖像能讓神經網絡快速完成訓練。此外,那些在CIFAR-10上表現優異的模型,在擴展到更難的基準測試(如ImageNet,克里熱夫斯基等人,2012年)時通常也能取得好成績(佐普等人,2018年)。基于這些原因,我們也將CIFAR-10作為CNN訓練的基礎,構建了NAS-Bench-101數據集。
2.1. Architectures
與其它神經架構搜索方法類似,我們把神經網絡拓撲結構的探索范圍[search space]限定在小型前饋結構[small feedforward structures](通常稱為單元[cells])的空間內,具體描述如下。每個單元堆疊三次后接一個下采樣層[a downsampling layer],通過最大池化操作將圖像的高度和寬度各減半,同時通道數翻倍。這種模式重復三次后接全局平均池化層[global average pooling],最終連接一個密集型softmax層[a final dense softmax layer]。模型的初始層是一個包含一個3×3卷積核、輸出128個通道的干層[conv stem]。圖1左上角展示了整個網絡結構示意圖。值得注意的是,干層后接單元堆疊的布局模式,在人工設計的圖像分類器(何等人,2016;黃等人,2017;胡等人,2018)以及圖像分類的神經架構搜索空間中都十分常見。因此,架構差異主要源于單元本身[cell]的創新設計。
細胞[cell]架構空間由所有可能的有向無環圖[directed acyclic graphs]構成,這些圖包含V個節點,每個節點都帶有L種標簽之一,分別代表對應的操作[operation]。其中兩個頂點被特別標記為輸入和輸出操作,分別表示細胞的輸入張量和輸出張量[input and output tensors]。然而,這種帶標簽的有向無環圖空間在節點數V和標簽數L上都呈指數級增長。為了限制該空間的規模以實現窮舉枚舉,我們施加了以下約束條件:
?我們設定L = 3,僅使用以下操作:(這里的操作可以理解節點上的標簽,3種操作=3個標簽)
????????– 3×3卷積
????????– 1×1卷積
????????– 3×3最大池化
?將V限制在7以內。
?將邊的最大數量限制為9條。
所有卷積層[convolutions]均采用批量歸一化[batch normalization]后接ReLU激活函數[ReLU]。這種設計選擇旨在確保搜索空間仍包含ResNet式和Inception式單元(何等人,2016;塞格迪等人,2016)。圖1右上角展示了Inception式單元的典型示例。我們特意選用卷積層[convolutions]而非可分離卷積層[separable convolutions]來復現ResNet和Inception的原始架構設計,盡管這會導致參數量比AmoebaNet(瑞爾等人,2018)等最新前沿架構更為龐大。
2.2. Cell encoding
對細胞進行編碼存在多種方式,不同的編碼方式可能通過調整搜索空間來優化特定算法的性能。在多數實驗中,我們選擇采用一種通用編碼方案:即使用7×7上三角二進制矩陣表示的7頂點有向無環圖,以及包含5個標簽的列表(每個中間頂點對應一個標簽,需注意輸入輸出頂點是固定的)。由于矩陣中存在211種可能的邊連接方式,每個標簽對應3種操作模式,因此該編碼方案總共可生成221?3?≈51?M個獨特模型。補充材料S3中我們還討論替代編碼。
然而,該空間中存在大量無效模型(即輸入頂點之間不存在路徑,或總邊數超過9條)。此外,不同圖在該編碼方式下可能不具備計算唯一性。我們用于識別和枚舉唯一圖的方法詳見補充材料S1。經過去重處理后,搜索空間中共有約42.3萬個唯一圖。
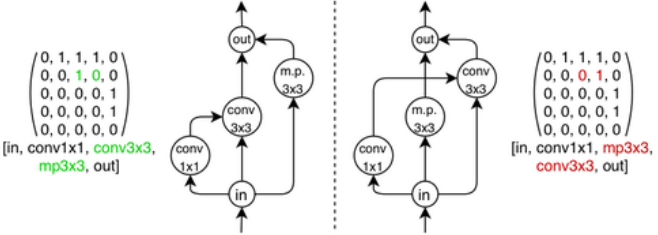
在NAS-Bench-101模型搜索空間中,存在具有不同鄰接矩陣或標簽但計算等效的模型(如圖1所示)。我們將這類單元稱為同構單元。此外,不在輸入節點到輸出節點路徑上的頂點不會對單元計算產生貢獻。對于包含此類頂點的單元,可以通過剪枝操作將其縮減為更小的單元,而不會改變該單元在網絡中的有效行為。由于搜索空間規模龐大,若不考慮同構性而逐一評估所有可能的圖表示方式,將會導致計算復雜度過高且效率低下。
圖1:兩個單元,根據它們的鄰接矩陣和標簽的不同而表示不同,但編碼相同的計算。
2.3. Combine semantics
將圖結構轉換為對應的神經網絡架構相對簡單,但存在一個例外情況:當多條邊指向同一節點時,需要對傳入的張量進行合并處理。此時采用加法[+]或拼接[&]操作都是常規做法。為兼容ResNet和Inception類網絡單元,同時保持計算空間的可擴展性,我們制定了固定規則:輸出節點的張量采用拼接方式處理,而其他節點的輸入則進行求和運算。輸入節點的輸出張量會按順序投影[projected in order],以匹配后續操作所需的輸入通道數量。該機制如圖1右下角所示。
2.4. Training
訓練流程是架構搜索基準測試中的關鍵環節,因為不同的訓練方法會導致性能出現顯著差異。為解決這一問題并確保NAS算法在公平條件下進行對比,我們為數據集中的所有模型設計并開源了一個通用訓練流程。
超參數選擇方面[Choice of hyperparameters.],我們為NAS-Bench-101的所有模型采用統一固定超參數集。該參數集通過粗網格搜索優化了從空間中隨機抽取的50個架構的平均準確率,從而確保其在不同架構間的魯棒性。這種做法與文獻中的標準做法(Zoph等人,2018;Liu等人,2018a;Real等人,2018)相似,并在第5.1節的實驗分析中得到了進一步驗證。
模型訓練與評估細節[Implementation details.]。所有模型均在CIFAR-10數據集(包含4萬訓練樣本、1萬驗證樣本和1萬測試樣本)上進行訓練與評估,采用標準數據增強技術(He等人,2016)。通過余弦衰減算法(Loshchilov & Hutter,2017)將學習率逐步降至零,以降低多次獨立訓練產生的方差波動。訓練過程使用RMSProp優化器(Tieleman & Hinton,2012)配合交叉熵損失函數,并采用L2正則化。所有模型均在TPU v2加速器上完成訓練。基于TensorFlow開發的代碼及相關超參數配置已公開發布于https: //github.com/google-research/nasbench。
我們設置了3次重復實驗和4個訓練輪次預算[3 repeats and 4 epoch budgets.]。所有架構均進行三次重復訓練與評估以獲取方差度量。為評估多保真優化方法(如Hyperband算法,Li等人,2018),我們采用四個遞增訓練輪次預算進行訓練:Estop∈{Emax/3 3,Emax/3 2,Emax/3,Emax} = {4,12,36,108}輪次。每次訓練時,學習率在Estop輪次達到最大值后逐步衰減至零。因此,針對每個Estop參數值,我們分別訓練了3×423k~1.27M個模型,總計獲得4×1.27M~5M個模型。
2.5.Metrics
我們對每個架構A進行了三次不同隨機初始化的訓練測試,針對上述四個預算參數Estop逐一進行。最終數據集包含以下維度:
?訓練準確率;
?驗證準確率;
?測試準確率;
?訓練耗時(秒);
?可訓練模型參數數量。
在單一NAS算法中,僅需使用訓練集和驗證集的指標來搜索模型,測試準確率僅用于離線評估。訓練耗時指標既可用于基準測試算法在時間限制下的精度優化(見第4節),也可評估多目標優化方法。其他無需重新訓練的指標可通過公開代碼計算得出。
2.6. Benchmarking methods
該數據集的核心目標之一是為NAS算法提供基準測試支持。本節將詳細闡述使用NAS-Bench-101的推薦最佳實踐方案,這些方案在后續分析中均被采用;若需獲取完整的基準測試操作指南,請參閱補充材料S6。
NAS算法的目標是在Emax輪次時找到具有高測試準確率的架構。為此,我們會在(A,Estop)配對點上反復查詢數據集,其中A是搜索空間中的一個架構,Estop表示允許的輪次數(Emstop∈{4,12,36,108})。每次查詢都會通過隨機試驗索引進行查找,該索引是均勻分布的從{1,2,3}中隨機選取,以模擬SGD訓練的隨機性。
在搜索過程中,我們會記錄算法在每次函數評估后找到的最佳架構A?i,并根據其驗證準確率進行排序。為了更好地模擬現實世界的計算約束,當總“訓練時間”超過固定限制時,我們會終止搜索運行。每次完整搜索結束后,我們會查詢該模型對應的平均測試準確率f(A?i)(測試準確率本身不應作為搜索的指導依據)。隨后計算即時測試遺憾值:r(A?i)=f(A?i)?f(A?),其中A?表示整個數據集中平均測試準確率最高的模型。該遺憾值即為本次搜索運行的得分。為了評估不同搜索算法的魯棒性,需要進行大量獨立的搜索運行測試。
3. NASBench as a Dataset
在本節中,我們將對NAS-Bench-101數據集進行全面分析,以深入理解神經網絡操作和細胞拓撲結構對卷積神經網絡性能的影響。通過這一研究,我們希望揭示NAS算法所經歷的損失函數變化軌跡。



)


:Redis高級特性和應用(慢查詢、Pipeline、事務))





)






