一、哈希的概念
哈希,也稱「 散列 」是一種用來進行高效查找的數據結構,查找的時間復雜度平均為O(1),其本質就是依賴哈希函數這個算法來將 key 和該 key 存儲位置建立一個映射關系。
而因為是有著映射關系,所以哈希的事件復雜度為 O (1)
key => hash function => position采用哈希處理時,一般所需空間都會比元素個數多,否則產生沖突的概率就比較大,影響哈希的性能 => 因此哈希是以空間的代價換取較高的效率
二、相關名詞解釋
哈希沖突:也稱哈希碰撞,也就是不同的key映射到了同一個位置
實際上任何哈希函數都可能發生哈希沖突,我們能做的就是設計出一個好的哈希函數盡可能的減少哈希沖突發生的概率
負載因子:假設哈希表中已經映射存儲了N個值,哈希表的??為M,則負載因子為 NM{\frac{N}{M}}MN?
負載因子的值越大,意味著哈希沖突的發生率越高,空間使用率高。反之負載因子越小,哈希沖突的發生率越低,空間使用率低。因此負載因子也是后續模擬實現當中用來判斷是否要擴容的一個標準
三、哈希函數的定義
3.1 直接定址法
直接定址法適用于 key ( 或稱關鍵字 => 非C++中定義的關鍵字 ) 范圍較集中的情況
直接定址法本質就是? key 計算出?個絕對位置或者相對位置
leetcode-387 題目描述如下
我們可以手動模擬哈希
class Solution {public:int firstUniqChar(string s) {int hash[26] = {0}; // 26 對應26個字母for(int i = 0;i<s.size();++i){hash[s[i] - 'a']++; // 直接通過 s 中每一個字符的值 去映射一個位置}for(int i = 0;i<s.size();++i){if(hash[s[i] - 'a'] == 1){return i;}}return -1;} };

3.2 除法散列法
除法散列法也叫做除留余數法,假設哈希表的??為M,那么通過key除以M的余數作為映射位置的下標
也就是哈希函數為:h(key) = key % M
在使用除法散列法時應避免 M 的大小取 2 的冪次或 10 的冪次
如果 M 取的大小是 2x{2^x}2x 那么key % 2x{2^x}2x 本質相當于保留key的后X位,那么后x位相同的值,計算出的哈希值都是?樣的就沖突了。
如:{63 , 31}看起來沒有關聯的值,如果M是16,那么計算出的哈希值都是15
因為63的?進制后4位是 1111,31的?進制后4位是 1111。如果是10x{10^x}10x,就更明顯了,保留的都是
10進值的后x位,如:{112, 12312},如果M是100,那么計算出的哈希值都是12為了避免前面提到的問題,當使用除法散列法時建議M取不太接近2的整數次冪的?個質數
散列函數有一個共同性質,即函數值應按同等概率取其值域的每一個值
四、哈希碰撞的解決方法
4.1 開放定址法
在開放定址法中所有的元素都放到哈希表?,當?個關鍵字key?哈希函數計算出的位置沖突了
則按照某種規則找到?個沒有存儲數據的位置進?存儲,開放定址法中負載因??定是?于的
這?有三種:線性探測、?次探測、雙重探測
4.1.1 線性探測
從發?沖突的位置開始,依次線性向后探測,直到尋找到下?個沒有存儲數據的位置為?,如果?
到哈希表尾,則回繞到哈希表頭的位置采用線性探測法處理散列時的沖突,當從哈希表刪除一個記錄時,不應將這個記錄的所在位置置空,因為這會影響以后的查找
4.1.2 二次探測
從發?沖突的位置開始,依次左右按?次?跳躍式探測,直到尋找到下?個沒有存儲數據的位置為
?,如果往右?到哈希表尾,則回繞到哈希表頭的位置;如果往左?到哈希表頭,則回繞到哈希表
尾的位置
4.1.3 開放定址法代碼實現
開放定址法在實踐中,不如鏈地址法,因為開放定址法解決沖突不管使?哪種?法,占?的都是哈希表中的空間
始終存在互相影響的問題。所以開放定址法,我們簡單選擇線性探測進行實現
#include <iostream>
using namespace std;namespace OpenAddress {// 仿函數template <class K> struct HashFunc {size_t operator()(const K &key) {return (size_t)key; // 把 key 轉成整數 ( 為了處理 key 非整的情況 =>// 因為要取模,非整沒辦法取模 )// 如果是自定義類型,也可以將賅仿函數進行特化 來處理自定義類型轉整的問題}};// 特化 處理stringtemplate <> struct HashFunc<string> {size_t operator()(const string &key) {size_t hash = 0;for (auto ch : key) {hash = hash * 131 + ch;}return hash;}};enum State { EMPTY, EXISTED, DELETED };template <class K, class V> struct HashData {pair<K, V> _kv;State _state = EMPTY;};template <class K, class V, class Hash = HashFunc<K>> class HashTable {public:// 這里提供sgi版本的哈希表使?的?法,給了?個近似2倍的質數表,每次去質數表獲取擴容后的??inline unsigned long __stl_next_prime(unsigned long n) {// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] = {53, 97, 193, 389, 769, 1543,3079, 6151, 12289, 24593, 49157, 98317,196613, 393241, 786433, 1572869, 3145739, 6291469,12582917, 25165843, 50331653, 100663319, 201326611, 402653189,805306457, 1610612741, 3221225473, 4294967291};const unsigned long *first = __stl_prime_list;const unsigned long *last = __stl_prime_list + __stl_num_primes;const unsigned long *pos = lower_bound(first, last, n);// 如果 n 的值超出 [first,last) 的最大值 => return 最后一個元素的下一個位置;// 如果小于 return 第一個元素的位置return pos == last ? *(last - 1) : *pos;}HashTable() { _table.resize(__stl_next_prime(0)); }bool insert(const pair<K, V> &kv) {// 插入時先確定該值是否已存在表中if (find(kv.first)) {return false;}// 先判斷當前的負載因子大小( N(數據個數) / M(表大小) )if (_n * 10 / _table.size() >= 7) { // 這里我們將負載因子控制在0.7// 擴容的邏輯就是先開空間 把元素 _table 中的元素插入到新開的空間中// 再將新的空間和舊的空間交換HashTable<K, V, Hash> newht;newht._table.resize(__stl_next_prime(_table.size() + 1));for (size_t i = 0; i < _table.size(); ++i) {if (_table[i]._state == EXISTED) {newht.insert(_table[i]._kv);}}_table.swap(newht._table);}// 如果負載因子小于0.7 則直接插入Hash hash;size_t hash0 = hash(kv.first) % _table.size();size_t hashi = hash0;size_t i = 1;while (_table[hashi]._state == EXISTED) {// 線性探測hashi = (hash0 + i) % _table.size();// 如果是二次探測 就改成 +- i^2++i;}_table[hashi]._kv = kv;_table[hashi]._state = EXISTED;++_n;return true;}HashData<K, V> *find(const K &key) {Hash hash;size_t hash0 = hash(key) % _table.size();size_t hashi = hash0;size_t i = 1;while (_table[hashi]._state != EMPTY) {// 如果找到if (_table[hashi]._state == EXISTED && _table[hashi]._kv.first == key) {return &_table[hashi];}// 如果當前的 index 不是目標值 ( 可能是原本就被占用了,所以要往后找// 直到找完整個 _table) => 所以其實開放定址法的效率不及鏈定址法hashi = (hash0 + i) % _table.size();++i;}// while 結束代表沒有找到目標值return nullptr;}bool erase(const K &key) {HashData<K, V> ret = find(key);if (ret == nullptr) {return false;}ret->_state = DELETED;--_n;return true;}private:vector<HashData<K, V>> _table;size_t _n = 0; // 哈希表中存儲的數據個數};void HashTest1() {HashTable<int, int> ht;ht.insert(make_pair(1, 1));ht.insert(make_pair(2, 2));ht.insert(make_pair(3, 3));ht.insert(make_pair(4, 4));ht.insert(make_pair(5, 5));ht.insert(make_pair(6, 6));ht.erase(2);ht.erase(3);}
}
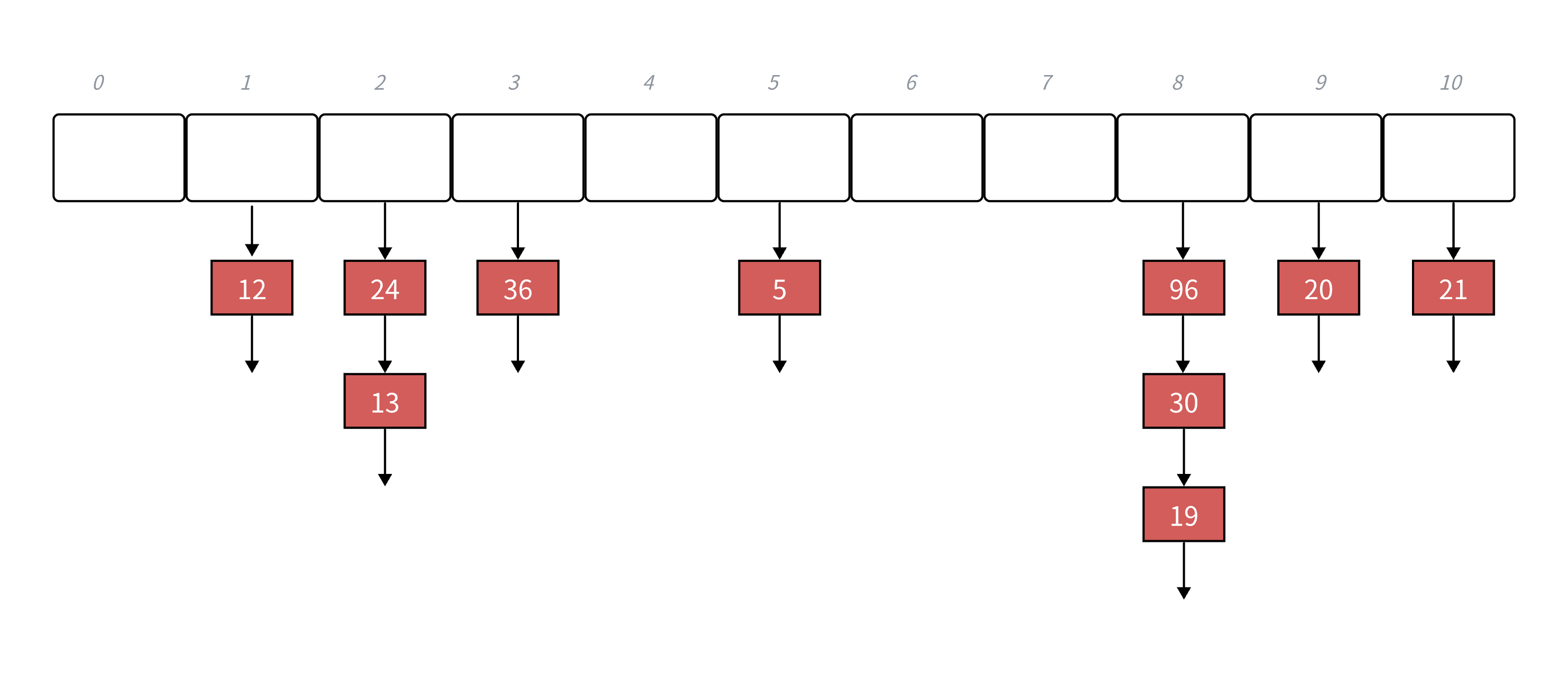
4.2 鏈定址法
鏈定址法的思想:開放定址法中所有的元素都放到哈希表?,鏈地址法中所有的數據不再直接存儲在哈希表中
哈希表中存儲?個指針,沒有數據映射這個位置時,這個指針為空,有多個數據映射到這個位置時**
把這些沖突的數據鏈接成?個鏈表,掛在哈希表這個位置下?,鏈地址法也叫做拉鏈法或者哈希桶
namespace HashBucket {
// 仿函數
template <class K> struct HashFunc {size_t operator()(const K &key) { return (size_t)key; }
};
template <class K, class V> struct HashData {pair<K, V> _kv;HashData<K, V> *_next;HashData(const pair<K, V> &kv) : _kv(kv), _next(nullptr) {}
};template <class K, class V, class Hash = HashFunc<K>> class HashTable {typedef HashData<K, V> Node;public:inline unsigned long __stl_next_prime(unsigned long n) {// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] = {53, 97, 193, 389, 769, 1543,3079, 6151, 12289, 24593, 49157, 98317,196613, 393241, 786433, 1572869, 3145739, 6291469,12582917, 25165843, 50331653, 100663319, 201326611, 402653189,805306457, 1610612741, 3221225473, 4294967291};const unsigned long *first = __stl_prime_list;const unsigned long *last = __stl_prime_list + __stl_num_primes;const unsigned long *pos = lower_bound(first, last, n);// 如果 n 的值超出 [first,last) 的最大值 => return 最後一個元素的下一個位置;// 如果小於 return 第一個元素的位置return pos == last ? *(last - 1) : *pos;}// 初始化HashTable() { _table.resize(__stl_next_prime(0)); }~HashTable() {for (size_t i = 0; i < _table.size(); ++i) {Node *cur = _table[i];while (cur) {Node *next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}bool insert(const pair<K, V> &kv) {Hash hs;size_t hashi = hs(kv.first) % _table.size();// 擴容// 這路就不用判斷負載因子了,因為相同的位置都會像鏈表一樣串接起來if (_n == _table.size()) {// 怎么擴?vector<Node *> newht(__stl_next_prime(_table.size() + 1), nullptr);for (size_t i = 0; i < _table.size(); ++i) {// 挪動數據Node *cur = _table[i];while (cur) {// 先保留_next;Node *next = cur->_next;// 將舊表的數據挪動到新表size_t hashi = hs(cur->_kv.first) % newht.size();cur->_next = newht[hashi];newht[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newht);}// 如果有其他數據 => 直接頭插Node *newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;}Node *find(const K &key) {Hash hs;size_t hash0 = hs(key) % _table.size();Node *cur = _table[hash0];while (cur) {if (cur->_kv.first == key) {return cur;}cur = cur->_next;}return nullptr;}bool erase(const K &key) {Hash hs;size_t hash0 = hs(key) % _table.size();Node *cur = _table[hash0];Node *prev = nullptr;while (cur) {if (cur->_kv.first == key) {if (prev == nullptr) { // prev 為空 代表刪除的是第一個數據_table[hash0] = cur->_next;} else {prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node *> _table;size_t _n = 0; // 數據個數
};
void HashBucketTest1() {HashTable<int, int> ht;ht.insert(make_pair(1, 1));ht.insert(make_pair(2, 2));ht.insert(make_pair(3, 3));ht.insert(make_pair(4, 4));ht.insert(make_pair(5, 5));ht.insert(make_pair(6, 6));ht.insert(make_pair(7, 7));ht.insert(make_pair(8, 8));ht.insert(make_pair(9, 9));ht.insert(make_pair(10, 10));
}
void HashBucketTest2() {HashTable<int, int> ht;ht.insert(make_pair(1, 1));ht.insert(make_pair(2, 2));ht.insert(make_pair(3, 3));ht.insert(make_pair(4, 4));ht.insert(make_pair(5, 5));ht.erase(2);ht.erase(3);ht.erase(4);ht.erase(5);ht.erase(6);ht.erase(7);ht.erase(8);ht.erase(9);
}
} // namespace HashBucket
五、選擇題解析
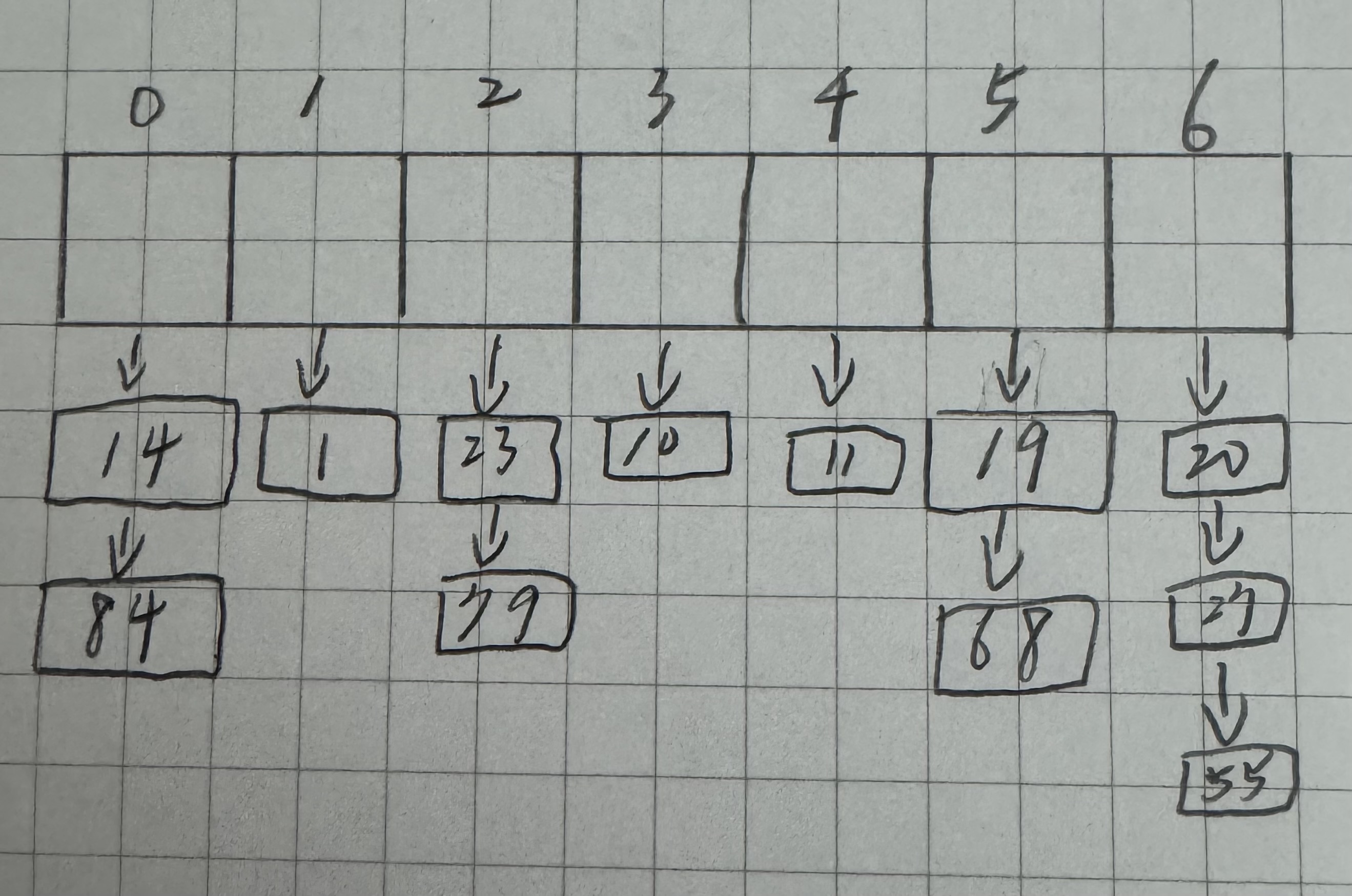
已知有一個關鍵字序列:(19,14,23,1,68,20,84,27,55,11,10,79)散列存儲在一個哈希表中
若散列函數為H(key)=key%7,并采用鏈地址法來解決沖突,則在等概率情況下查找成功的平均查找長度為?
其呈現如上圖14,1,23,10,11,19,20 比較 1 次就可以找到
84,79,68,27 2次
55 3 次
總共:1 * 7 + 2 * 4 + 3 * 1 = 18 數據個數:12
18 / 12 =1.5
已知某個哈希表的n個關鍵字具有相同的哈希值,如果使用二次探測再散列法將這n個關鍵字存入哈希表,至少要進行幾次探測
有 n 個數據,第一個數據 1 次,第二個數據 2 次,。。。第 n 個數據 n 次
總共:1 + 2 + 。。。 + n = n?(n+1)2{\frac{n*(n+1)}{2}}2n?(n+1)?
用哈希(散列)方法處理沖突(碰撞)時可能出現堆積(聚集)現象,會受堆積現象直接影響的是平均查找長度
)


:Redis高級特性和應用(慢查詢、Pipeline、事務))





)









