1.緒論
1.1研究背景與意義
1.1.1研究背景
隨著旅游業的快速發展,滿意度分析成為評估旅游景點質量和提升游客體驗的重要手段。作為中國的旅游城市之一,其旅游景點吸引了大量游客。然而,如何科學評估和提升旅游景點的滿意度,成為當前旅游管理和發展中的重要問題。
傳統的滿意度分析方法主要依賴于人工調查和統計分析,這種方法存在著調查樣本有限、統計結果不夠客觀等問題。因此,基于自然語言處理技術的情感分析成為了一種新的研究方法,能夠從大量的網絡評論中挖掘出游客的情感傾向,對景點的滿意度進行客觀評估。同時,利用先進的技術如 CNN 算法、LDA 主題模型和 jieba 分詞等,結合數據采集工具 requests 和可視化工具 Matplotlib,可以對旅游景點的滿意度進行深入分析,幫助管理者更好地了解游客反饋和情感傾向,進而提升景點服務質量和游客滿意度。
因此,結合Python編程技術,利用情感分析和自然語言處理技術對旅游景點的滿意度進行研究具有重要的理論和實踐意義。這不僅能夠為旅游景點的管理和發展提供科學依據,也可以為基于自然語言處理技術的旅游滿意度分析提供新的方法和實踐案例。
1.2.2研究意義
本研究基于Python的旅游景點滿意度分析具有重要的研究意義和實踐價值。首先,通過運用Python編程技術,結合 CNN 算法、LDA 主題模型,本研究為旅游景點提供了一種全新的評估方法,使得景點管理者和決策者能夠更加客觀地了解游客的感受和評價。其次,通過對旅游景點的滿意度進行深入分析,可以幫助管理者發現景點的優勢和不足之處,有針對性地提出改進措施。此外,本研究還為其他類似旅游目的地的滿意度分析提供了借鑒和參考。最重要的是,通過科學地評估景點的滿意度,可以為旅游業的可持續發展提供重要支撐,促進旅游業的健康發展。因此,本研究可促進旅游業的發展,提升景點管理水平。
1.2國內外研究現狀
1.2.1國內研究現狀
國內在旅游滿意度分析領域已有多位專家做出了重要貢獻。在此背景下,羅俊杰等提出了利用情感分析方法評價旅游者對景點的情感傾向的觀點[1]。王國惠指出,情感分析可以幫助理解游客對景點的情感態度,從而為景點管理者提供改進和優化的方向[2]。同時,王雨欣在其研究中強調了情感分析與主題模型的結合應用,以挖掘出游客在旅游評論中所表達的情感傾向和主題特征[3]。此外,HATSADONG等提出自然語言處理技術在景區滿意度分析中的重要性,他們提出,通過主題模型分析用戶評論的主題分類,從而更加直觀的獲取評論文本中的有用信息,通過分別分析正面評論與負面評論主題,得到了游客重點關注的事項,對游客出行的旅游景點選擇以及出行時間點提出了一些參考性建議[4]。在國內研究中,還有葉海燕等構建了基于卷積神經網絡的特定目標文本情感分析模型(文本分析模型).根據情感差異分析特定目標文本序列,在輸入層將文本特征矩陣作為卷積神經網絡語言模型的輸入數據,拼接成詞性序列矩陣,加入dropout機制完成特定目標文本情感分類,確定文本中每個詞的重要度信息,實現特定目標文本情感分析[5]。劉云霞等對景點滿意度進行了深入研究,發現了景點管理中的問題并提出了改進措[6]。此外,徐惠娟,劉生敏等提出了利用Python進行文本挖掘和情感分析的方法[7]。李經龍,王海桃為旅游滿意度分析提供了技術支持和實施路徑[8]。綜上所述,國內專家們在旅游滿意度分析領域的研究中不斷探索,提出了多種方法和觀點,為我國旅游業的發展和景點管理提供了理論和實踐指導。
1.2.2國外研究現狀
在國外的旅游滿意度分析領域,也有多位專家做出了重要貢獻。Pizam第一次提出旅游滿意度相關的概念開創了游客滿意度研究的理論基礎,游客對旅游地的期望和實地旅游體驗相二者相比較之下的結果就是游客滿意度,假如事先的期望值高于實地旅游體驗,則游客是不滿意的;否則游客是滿意的,得出海灘、成本、環境、住宿飲食條件以及景區商業化程度等是影響滿意度的主觀因素[9]。Kim識別和評估游客在旅游評論中表達的情感傾向,研究強調了情感分析在理解游客滿意度和不滿意度方面的重要性,并指出了其在旅游管理中的潛在應用[10]。此外,AcharyaS等人探討了旅游評論中情感詞匯和否定詞對滿意度評價的影響,發現不同情感詞匯和否定詞的使用對最終評價結果有著顯著影響,為深入理解旅游評論提供了新的視角[11]。在情感分析領域,提出了一種基于機器學習的情感分析模型,以提高對游客評論的情感傾向識別準確度和效率。他們的研究為情感分析技術的發展提供了新的方法和思路[12]。此外, Chiang-Ming Chen將情感分析與文本挖掘技術相結合,對旅游評論進行了主題建模和情感傾向分析以揭示游客對不同景點和服務的情感態度和滿意度水平[13]。最后,Qingqing Wang提出了一種基于CNN-BGRU的混合神經網絡模型來解決精確分類問題。該算法首先利用卷積神經網絡提取輸入文本向量的局部特征,然后利用BGRU獲取該層前后的信息,進而得到全局特征。最后通過Softmax分類器得到情感分類結果[14]。這些國外專家的研究為旅游滿意度分析提供了豐富的理論和方法,為我國旅游業的發展和景點管理提供了借鑒和啟示。
1.3主要研究內容與技術路線
1.3.1研究內容
基于Python的旅游景點滿意度分析的主要研究方法如下:
(1)文本預處理:對旅游景點的評論文本進行清洗和分詞處理,去除無關字符和標點符號,利用 jieba 庫進行中文分詞操作。
(2)構建情感詞典:建立旅游景點評論的情感詞典,篩選出其中包含有消極情感的詞和積極情感詞。
(3)情感分析:對表格中評論利用CNN算法分析,找到里面的情感傾向,把詞匯分為積極評論與消極評論兩種類型來研究。
(4)主題分析:將LDA主題模型運用進評論中,找出其中不容易發現的主題信息,幫助理解評論的關鍵話題。
(5)可視化展示:利用 Matplotlib 進行可視化展示,繪制情感分析結果圖表和主題分布圖,直觀呈現評論情感和主題分析結果。
(6)詞云展示:利用 jieba 分詞工具提取評論中的積極和消極關鍵詞,制作詞云展示,以直觀方式展示評論中的關鍵詞信息。?
1.3.2技術路線
本次研究擬采用pycharm開發平臺,選擇python作為編程語言,旅游景點滿意度分析的技術路線如下:使用 requests 庫進行數據采集,獲取鳳凰古城旅游景點的評論。運用python中的jieba庫來將評論內容進行分詞和去停用詞等文本預處理步驟。對評論利用CNN算法分析,找到里面的情感傾向。將LDA主題模型運用進文本中,找出其中不容易發現的主題信息。采用Matplotlib 來進行可視化,得出主題分布表以及情感分析結果。結合 jieba 分詞工具,制作消極和積極詞云,直觀展示評論情感和關鍵詞信息。通過這一技術路線,可以全面分析旅游景點的滿意度,為景點管理者提供深入洞察和決策支持。研究擬進行主要步驟如下流程如圖 1-1所示:
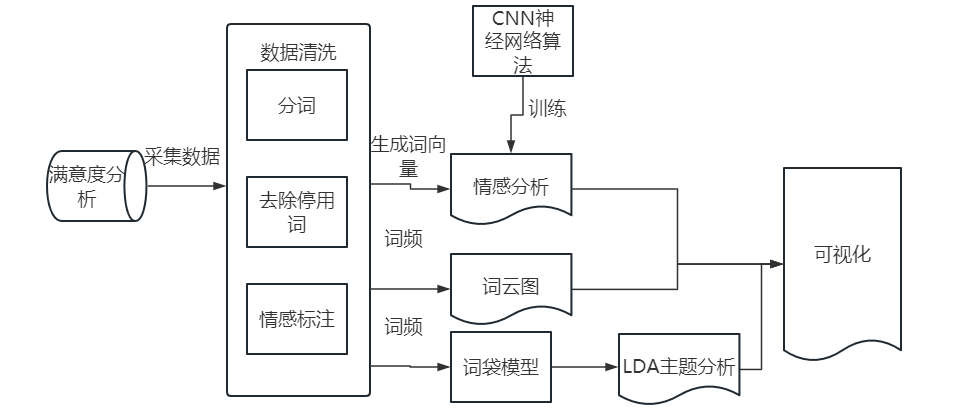
圖 1-1?主要步驟
1.4創新之處
本文創新之處如下所示:
(1)數據處理創新:LDA主題模型揭示了游客關注的焦點,有助于景點管理。同時,jieba分詞配合詞云技術,直觀呈現了評論中情感色彩,助力于優化服務策略。整體設計實現了數據驅動的精細化運營決策。
(2)模型創新:采用Python的強大支持,結合深度學習的CNN(卷積神經網絡)算法,對海量游客評論進行情感挖掘,實現了精準的情感分析,提高了評價理解的深度。
2.基本原理
2.1文本處理技術
旅游景點滿意度分析是一個復雜的領域,其中文本處理技術可以用來分析游客對景點的評論、評價等文本信息,從而獲取對旅游景點的滿意度。在Python中,可以使用自然語言處理(NLP)庫來進行文本處理和情感分析。
文本處理技術原理:
文本預處理、特征提取與表示、情感分析等是文本處理技術主要步驟。第一步進行文本預處理要經過去除停用詞和詞干提取以及去除標點符號。而第二步特征提取與表示,是使用詞袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)等方法轉換成特征向量。情感分析是文本處理最后一步,要進行文本情感判斷這當中就要運用到機器學習或深度學習技術,以此來推測游客的情緒態度。
詞袋模型(Bag of Words):
詞袋模型是根據文本中詞語出現的頻率來表示文本。第一步,創建文本詞匯表,然后對每個文檔進行詞頻統計,最終得到一個文檔-詞頻的矩陣。假設有N個文檔和M個詞匯,則第i個文檔中第j個詞匯的詞頻可以表示為矩陣中的元素X[i, j]。詞袋模型可用于文本分類、情感分析等任務。
TF-IDF方法(Term Frequency-Inverse Document Frequency):
TF-IDF是一種用于評估單詞在文檔集合或語料庫中重要程度的統計方法。它由兩部分組成:詞頻(TF)和逆文檔頻率(IDF)。TF表示某個詞在文檔出現的頻率,而IDF表示包含這個詞的文檔頻率的倒數的對數值。
2.2神經網絡CNN模型基本原理
CNN(Convolutional Neural Network)是一種深度學習模型,特別適用于處理圖像數據,但也可用于文本數據的情感分析等任務。其原理如下:
卷積層(Convolutional Layer):卷積操作通過滑動卷積核(filter)在輸入數據上提取特征。
激活函數(Activation Function):通常在卷積層后會加上激活函數,如ReLU(Rectified Linear Unit),用于引入非線性。
池化層(Pooling Layer):池化操作用于降低特征圖的維度,減少參數數量并提取主要特征。常用的池化方式為最大池化(Max Pooling).
全連接層(Fully Connected Layer):最終通過全連接層將提取的特征傳遞給輸出層進行分類。
在情感分析任務中,CNN 模型會學習文本中的特征,識別評論中的情感傾向。通過不斷調整卷積核參數和權重,最終實現對評論情感的準確預測。
3.景點評論數據處理及LDA主題分析
3.1數據準備
本次研究以鳳凰古城景點為例,采集景點的評論信息,分為好評和差評,采集共2714條評論,其中好評2439條,差評275條。通過向指定 URL 發送 POST 請求來獲取景點的評論數據,并將評論信息存儲到 CSV 文件中。其中先請求頭 headers 和 POST 請求的參數 request,包括評論相關的參數如頁碼、景點ID等。通過循環遍歷頁數,發送 POST 請求獲取每一頁的評論數據。每次請求后會暫停3秒以避免請求過于頻繁。解析返回的 JSON 數據,提取評論相關信息如內容、地區、時間、用戶名等。采集主要代碼如圖3-1所示:
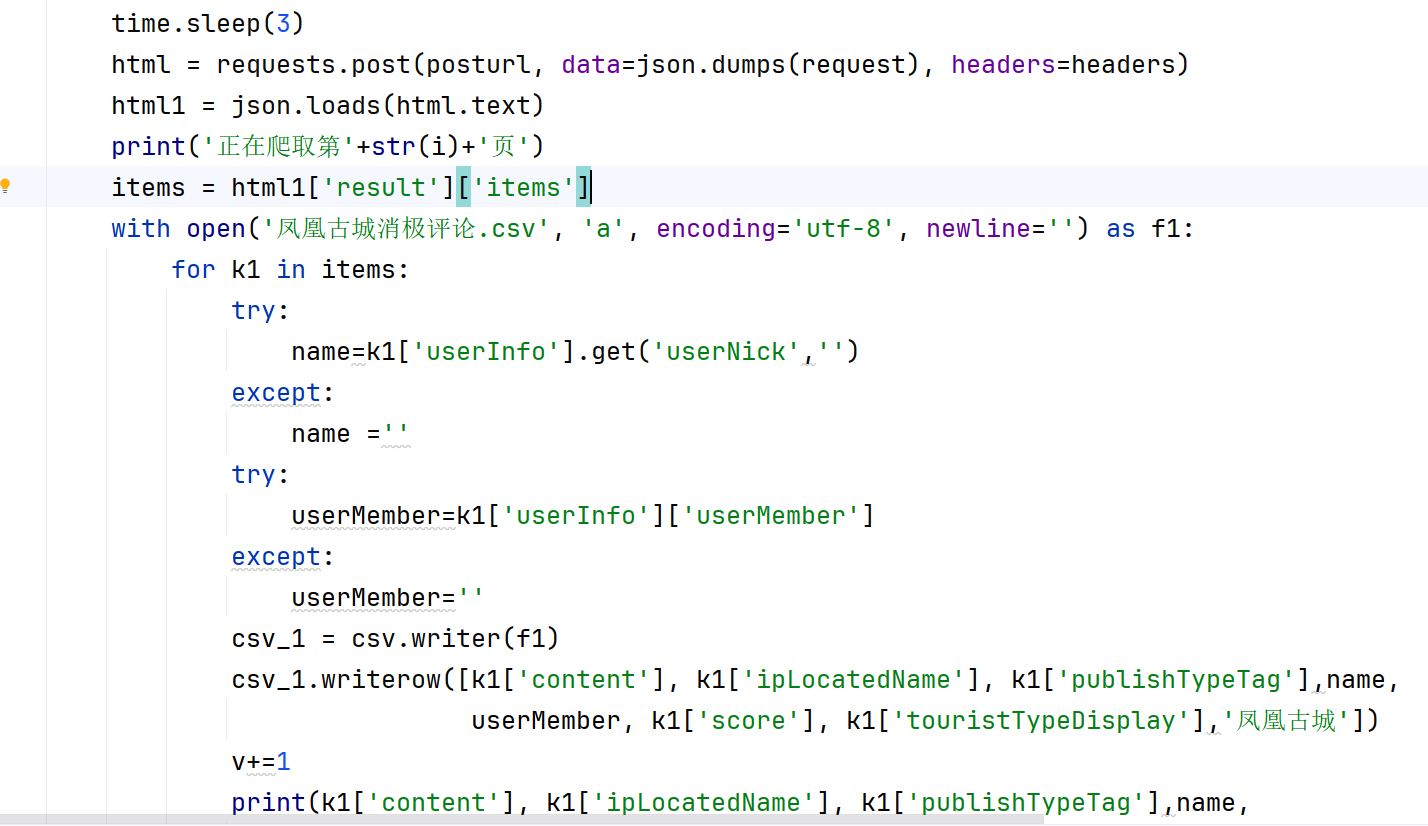
圖3-1??采集主要代碼
將解析的評論信息以列表形式寫入 CSV 文件中,每行對應一條評論數據。采集存儲為csv結果如圖3-2所示:

圖3-2??采集存儲為csv結果
數據采集部分結果如表3-1所示。
表3-1 ?采集結果
序號 | 評論 |
1 | 游覽鳳凰古城的時候,天空開始下雨,一開始是毛毛雨,再一會兒就下大了! |
2 | 人文與自然景觀都不錯,時尚的旅拍也隨處可見。 |
3 | 鳳凰古城位于湖南省湘西土家族苗族自治州的西南部。 |
4 | 鳳凰古城是屬于那種苗族少數民族的一種習俗。夜景超美,感覺是在古城一樣 |
3.2數據預處理
3.2.1 文本清洗
在文本預處理階段,通過使用drop_duplicates函數對原始數據進行去重操作。在代碼中,根據內容這一列進行去重,并將去重后的結果重新賦值給新的DataFrame。這樣可以確保每條內容的唯一性,避免出現重復的數據。積極評論去重前后結果如圖3-3所示,去重前有2439條,去重后2371條,共有68條重復數據:

接下來,進行正則清洗的步驟。正則清洗主要是針對內容,去除除了中英文字符和數字以外的其他字符。具體實現通過使用正則表達式的方式,調用re.sub函數進行替換。用[^\u4e00-\u9fa5^a-z^A-Z^0-9^,.,。!:]這條表達式,將文全文中除了中英文字符、數字和部分標點符號(逗號、句號、感嘆號、冒號)以外的字符都替換為空格,從而實現清洗效果,最后得到如表3-2的清洗結果。
表3-2 清洗結果(部分)
序號 | 清洗內容 |
1 | 游覽, 鳳凰古城, 的, 時候, ,, 天空, 開始, 下雨, ,, 一, 開始, 是, |
2 | 人文, 與, 自然景觀, 都, 不錯, ,, 時尚, 的, 旅拍, 也, 隨處可見 |
3 | 鳳凰古城, 位于, 湖南省, 湘西土家族苗族自治州, 的, 西南部 |
4 | 鳳凰古城, 是, 屬于, 那種, 苗族, 少數民族, 的, 一種, 習俗, 。, 夜景, |
3.2.2 文本分詞和停用詞處理

圖3-4??文本分詞和停用詞處理主要流程
如圖3-4文本分詞和停用詞處理流程,使用 jieba 庫對文本內容進行分詞處理。將不為空的內容列取出,并轉換為列表。對每一行文本進行分詞操作,使用 jieba.lcut() 方法將文本分詞為單詞列表。將分詞后的結果添加到 content_S 列表中。分詞后結果如圖3-5所示:
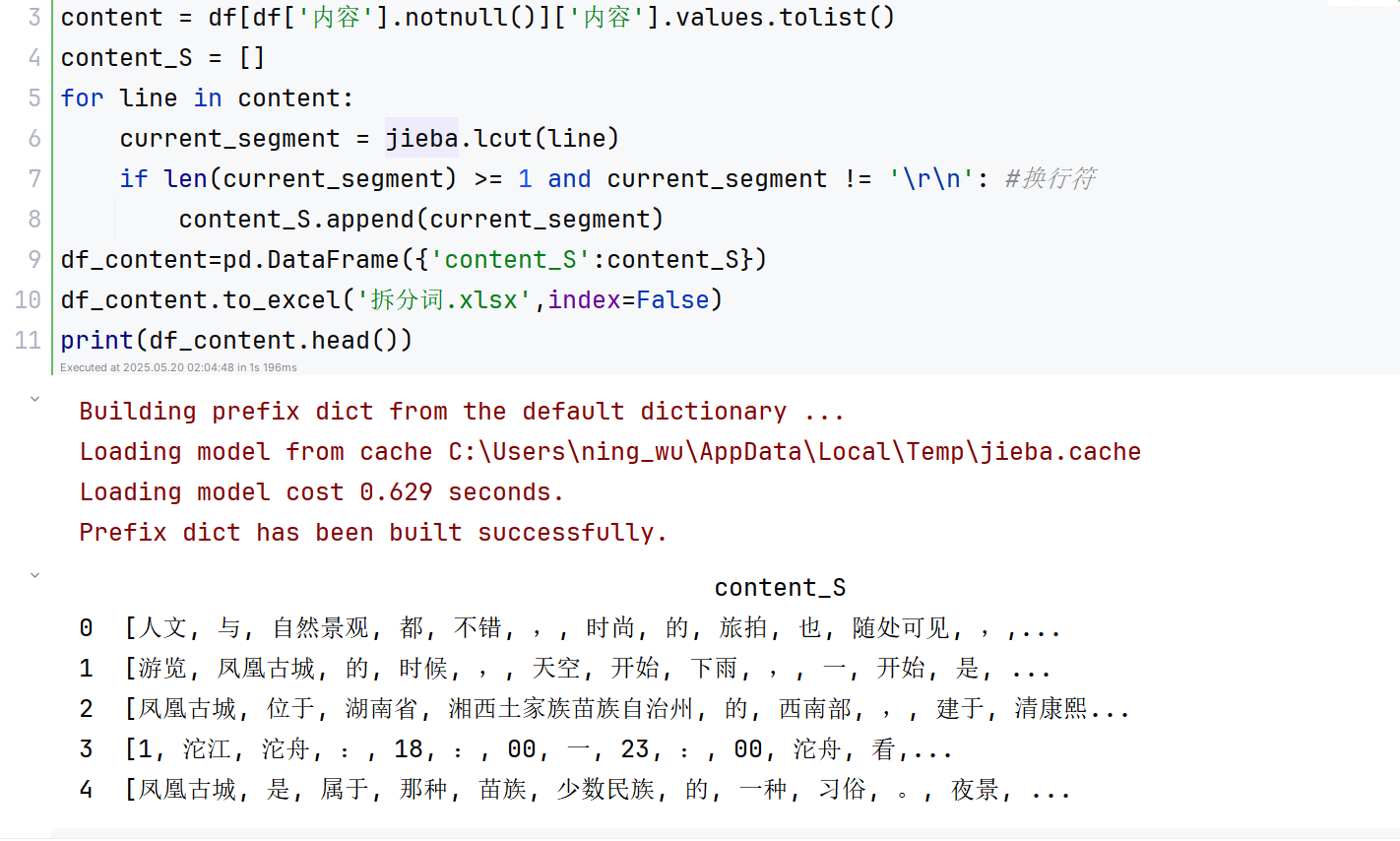
圖3-5??文本分詞后結果
將"停用詞.txt"列表加載到文本中去除停用詞。遍歷文本內容列表,判斷其中每個詞在不在停用詞列表里面,不在則保留,否則跳過。去停用詞后的文本存儲到 contents_clean 列表中,并將所有詞存儲到 all_words 列表中。將去除停用詞后的文本內容存儲到 DataFrame df_content 中,并保存為 Excel 文件 去除停用詞后內容.xlsx。去停用詞后結果如圖3-6所示:
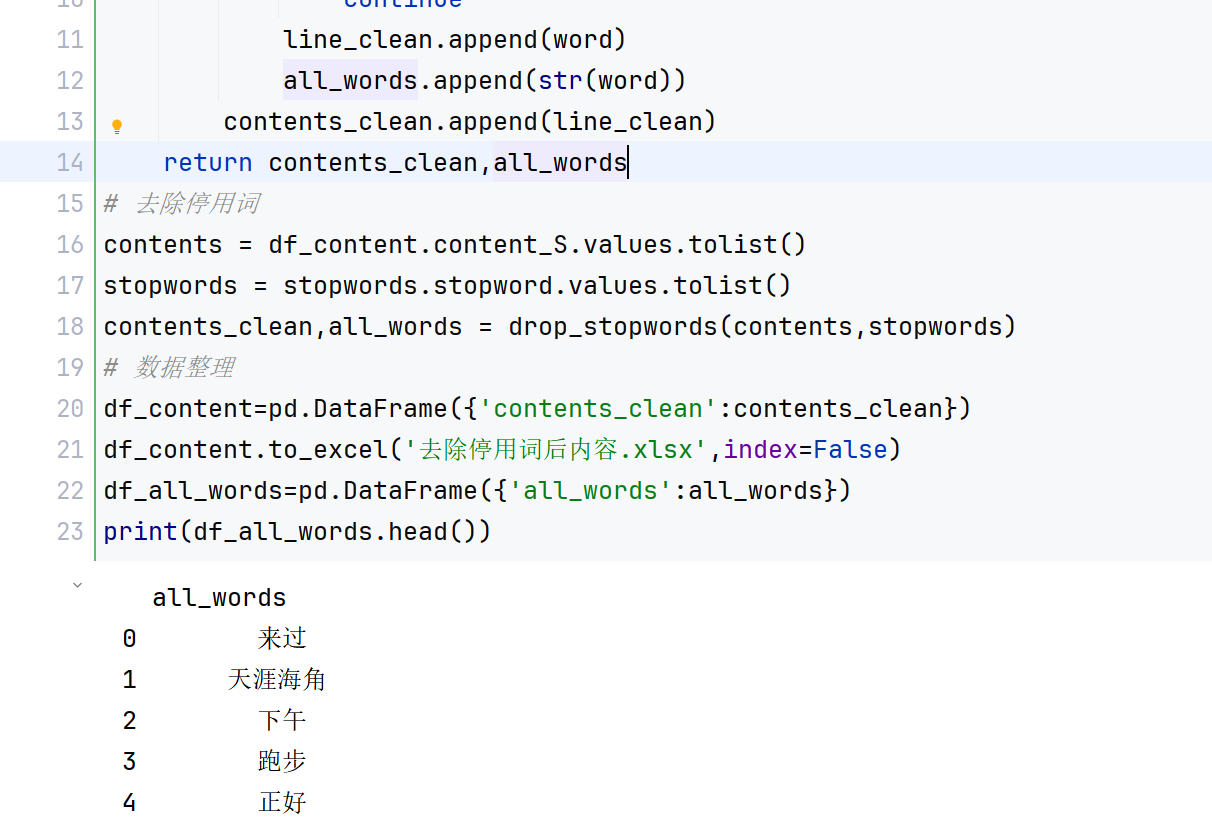
圖3-6??去停用詞后結果
3.2.3 詞頻統計
每條評論內容則采用jieba庫來進行分詞,對分詞進行遍歷并且結果列表,對每個詞語進行詞頻匯總,其中的詞匯以及詞匯出現次數加到匯總里面,對其進行降序處理。篩選出與該主題相關的詞語。對匯總結果可視化,運用詞云圖等圖表進行分析,根據高頻詞語來了解內容的關鍵關注點和問題。
通過詞頻分析,可以了解內容的關注度和熱度,找出內容被用最多的關鍵詞,從而揭示出內容的主要關注點和議題。詞頻統計結果如圖3-7所示,生成的積極詞云和消極詞云如圖3-8和圖3-9所示:
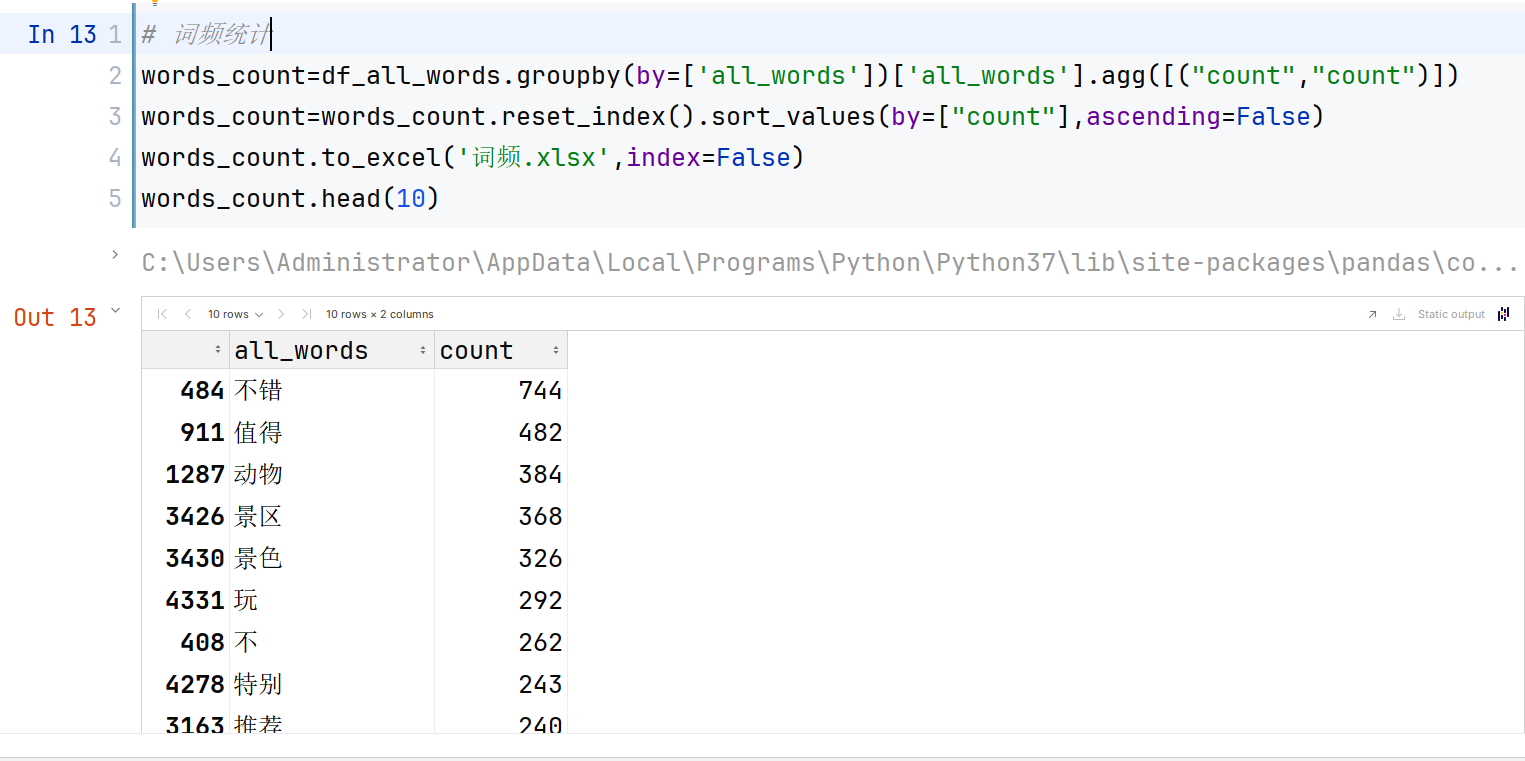
圖3-7??詞頻統計結果
(1)積極詞頻分析

圖3-8?積極詞頻結果
由積極詞云圖3-8所示可知:“夜景”等詞頻較高,顯示了游客對景區和夜間景色的高度關注。許多游客對當地的“風景”、“文化”和“歷史”給予了積極評價,表現出其獨特的旅游吸引力。同時,“不錯”、“值得”、“漂亮”等評價性詞語頻繁出現,表明游客對整體體驗感到滿意。然而,也有“商業化”一詞出現,提示一些游客對于過度商業化有一定的負面看法。
此外,評論中頻繁提到“性價比”、“推薦”、“景區”等,表明游客對旅游性價比和是否值得推薦有較高的關注。評論傾向于正面評價,認為鳳凰古城是一個“美麗”、“有趣”的旅游勝地,尤其適合拍照、游玩和體驗當地文化的游客。
- 消極詞頻分析

圖3-9??消極詞頻結果
由消極詞云圖3-9可知:可以看到一些負面情緒的詞匯頻繁出現,負面評論也相對較為顯著,尤其是“商業化”、“差評”、“不值”、“收費”和“垃圾”等詞匯,這些詞匯反映出游客對景區商業化和高消費的強烈不滿,認為性價比不高。其次,關于服務的負面評價,如“服務態度”、“推銷”和“客服”也表明游客對當地服務質量存在不滿。此外,游客對“衛生”、“環境”和“管理”等方面也有批評,尤其是“臟亂差”和“污染”等詞語的出現,凸顯出環境衛生問題。消極詞頻高的詞匯反映了一些游客在游覽過程中遇到的問題和不滿意,因此,建議鳳凰古城在保持其文化魅力的同時,優化商業模式,改善服務質量和環境衛生,以提升游客的整體滿意度和體驗感。
3.3?LDA主題模型設計
3.3.1 數據預處理與特征提取
第一步:文本內數據經過分詞處理與去除停用詞兩個步驟,得到數據。
第二步:創建詞袋模型,將文本轉化為詞袋形式,為LDA模型準備輸入數據。
第三步:對詞袋采用TF-IDF模型進行加權處理,得到數據來訓練LDA模型。主要代碼如下圖3-10所示:

圖3-10?訓練模型
3.3.2 LDA主題建模
第一步:將Gensim庫中的LdaModel運用到LDA模型中去,設置主題數等參數。
第二步:計算困惑度和一致性評分,根據主題數的范圍迭代訓練LDA模型,計算困惑度和一致性評分,選擇最佳主題數。
第三步:計算單詞的先驗分布,獲取每個單詞在不同主題下的分布概率。主要代碼如圖3-11所示。
圖3-11??LDA模型
3.3.3 模型訓練
第一步:使用PyLDAvis進行LDA主題模型的可視化,生成交互式HTML文件,展示主題之間的關聯性和單詞分布。
第二步:繪制困惑度和一致性曲線,通過曲線觀察不同主題數下的模型性能表現,選擇最優的主題數。
第三步:輸出每個主題下的關鍵詞,幫助理解每個主題所代表的內容和主題之間的區別,主題輸出結果如圖3-12所示。

圖3-12?LDA模型關鍵詞
3.4 LDA主題結果分析
一致性和困惑度分析曲線圖是用來評估景點內容主題信度和效度的重要工具。通過一致性分析曲線,可以了解景點評論內部各項問題之間的一致性程度,而困惑度分析曲線則幫助我們評估內容的難度及區分度。一致性分析曲線曲線越接近1,表示評論內容內部各項問題之間的一致性越高說明內容的主題效果較高。由圖3-13可知,積極評論最佳主題數是2,積極評論可以劃分2個主題。
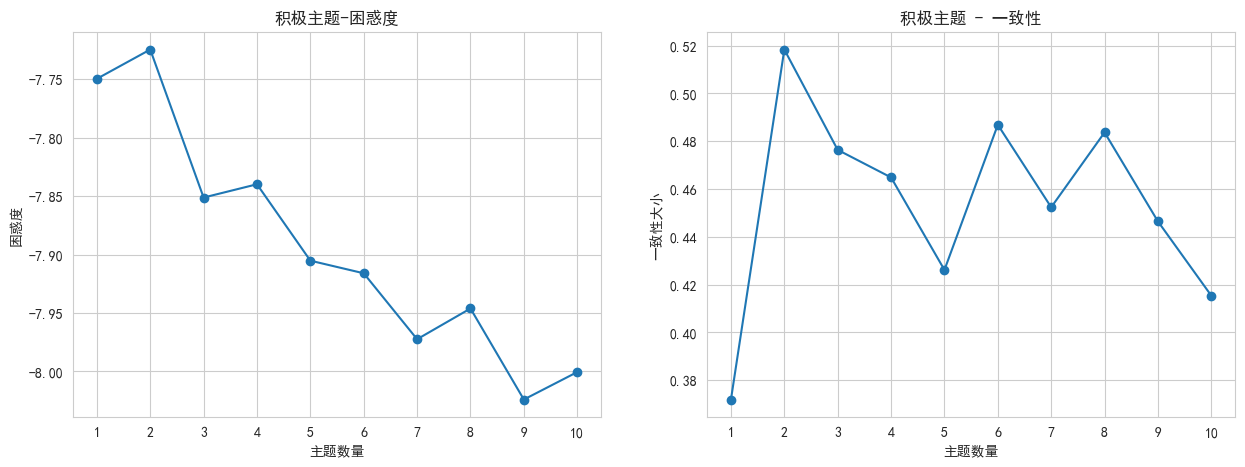
圖3-13?一致性和困惑度曲線
根據最優主題數,使用IDA建模,生成IDA可視化效果,如下圖3-14所示:
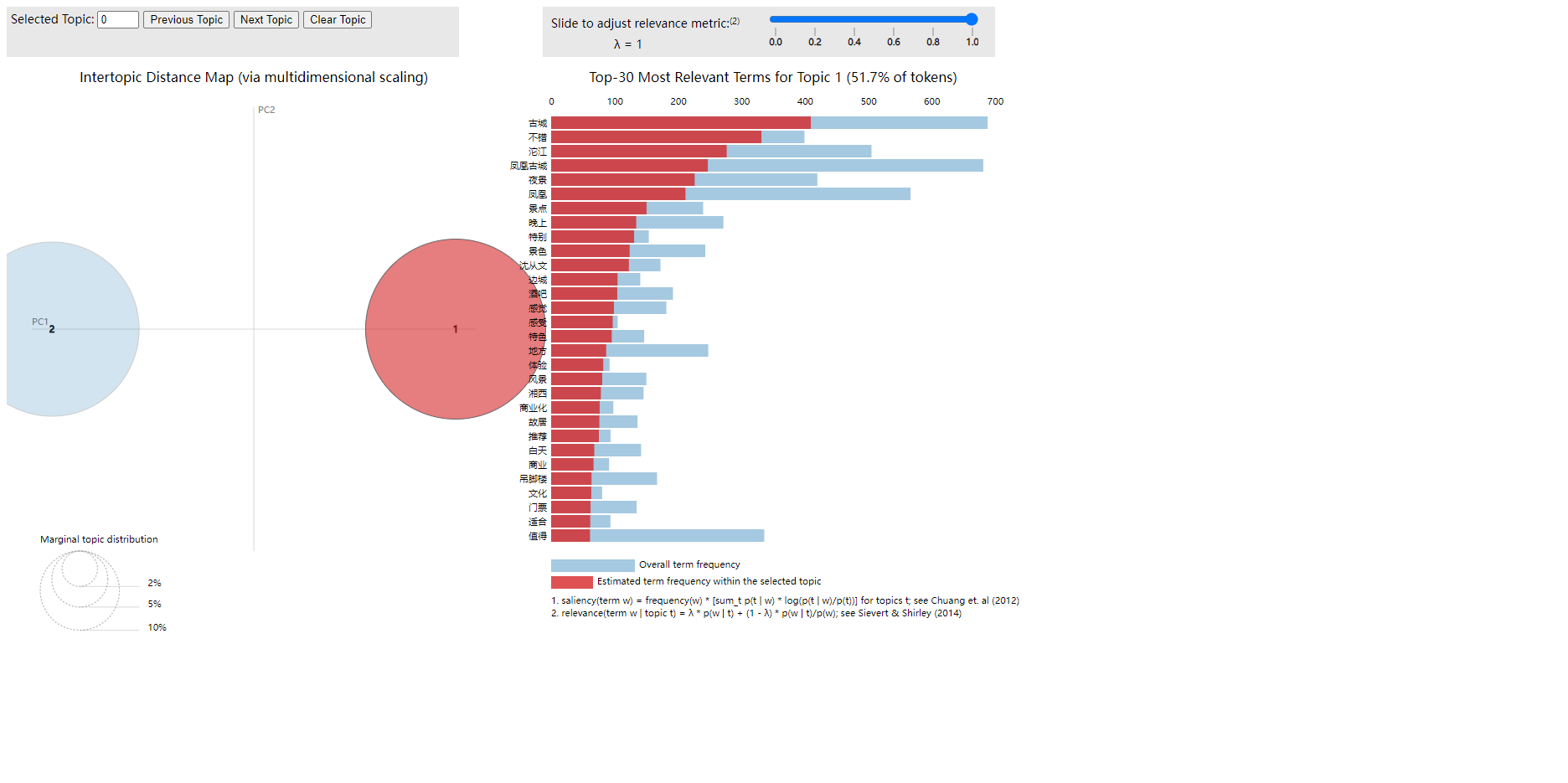
圖3-14??可視化結果
積極評論的主題分析:
主題一關鍵詞權重分布為“古城”(0.021)、“不錯”(0.017)、“沱江”(0.014)、“鳳凰古城”(0.013)、“夜景”(0.012);主題二突出“鳳凰古城”(0.024)、“鳳凰”(0.019)、“古城”(0.015)、“值得”(0.015)、“沱江”(0.012)。兩大主題均聚焦古城自然景觀與夜間體驗,“夜景”“沱江”“晚上”高頻出現,反映游客對燈光秀、江景游覽關注度高;“值得”“不錯”體現整體滿意度較高。
主題差異顯著:主題一強調感官體驗,“景色”“特別”指向景觀獨特性;主題二突出文化價值認同,“古鎮”“地方”隱含對歷史建筑保護與地域特色的認可。游客評論隱含潛在問題:商業化相關詞匯未進入高頻詞表,可能反映過度開發尚未成為主要負面感知;但“景點”“古鎮”等泛化表述暗示文化展示深度不足。
建議:需強化沱江夜景配套服務,延長夜間消費場景;挖掘苗族文化元素,增加非遺互動體驗;控制商業設施密度,避免同質化商鋪影響古城風貌。
由圖3-15可知,消極評論最佳主題數是7,消極評論可以劃分7個主題。
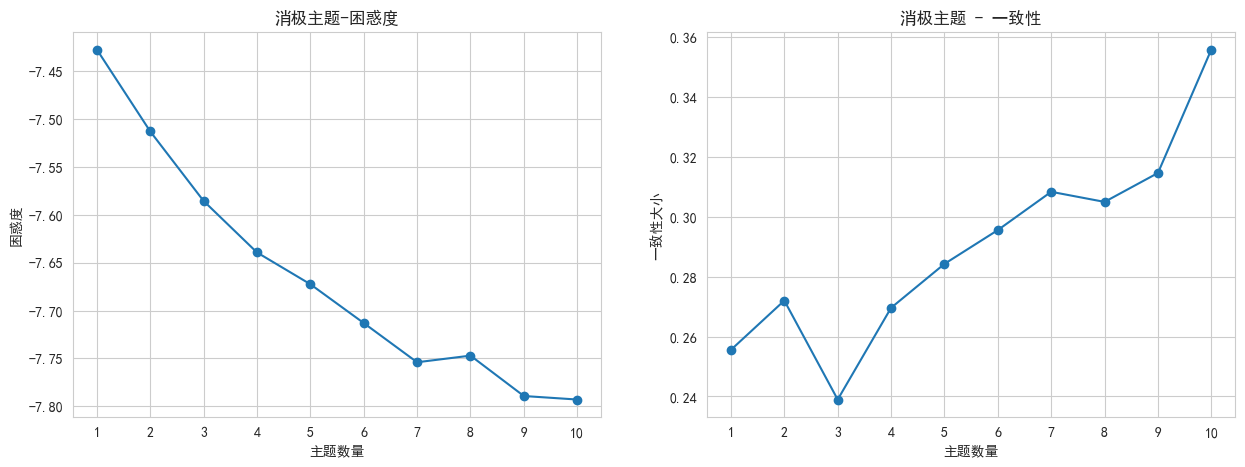
圖3-15?消極一致性和困惑度曲線
根據最優主題數,使用IDA建模,生成IDA可視化效果,如下圖3-16所示:
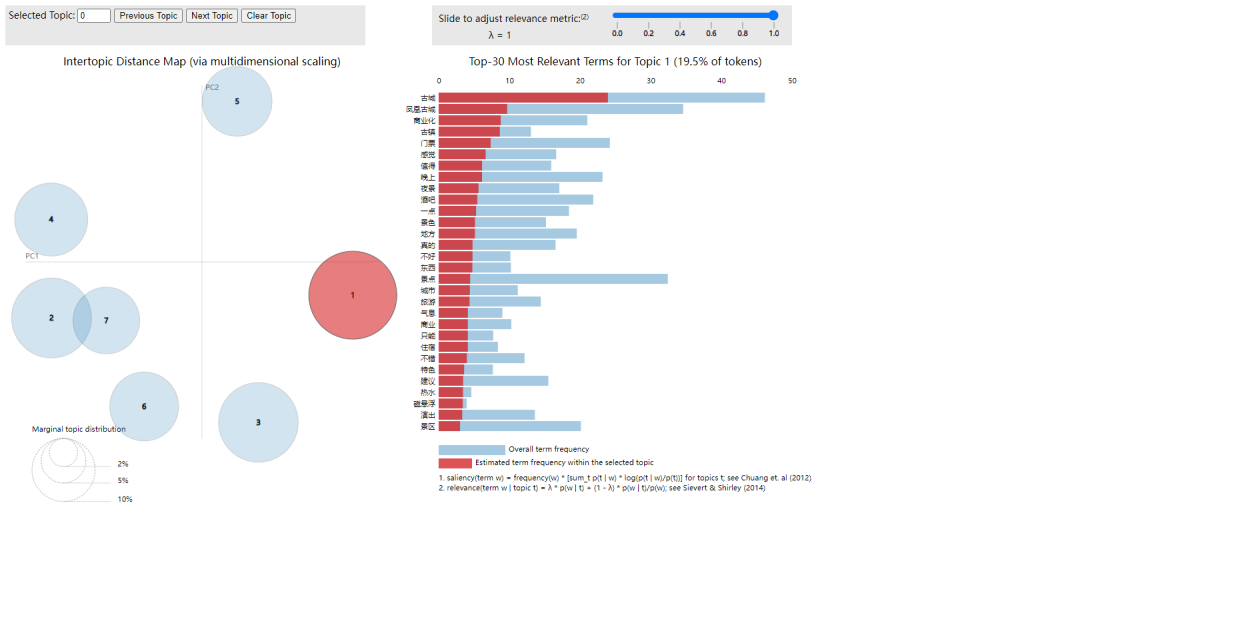
圖3-16??消極可視化結果
消極評論的主題分析:
LDA主題模型提取鳳凰古城游客評論形成七類核心主題。主題0(權重前五:“鳳凰”0.010、“小時”0.007、“景區”0.007、“攜程”0.006、“消費”0.005)反映游客對景區服務時效性與平臺消費的敏感;主題1(“攜程”0.013、“酒店”0.010、“停車場”0.006)凸顯住宿配套與票務管理痛點;主題2(“坐船”0.009、“推銷”0.009、“宰客”0.006、“不值”0.006)揭示游船服務強制推銷引發的體驗爭議;主題3(“商業化”0.011、“酒吧”0.007、“夜景”0.007)聚焦古城業態同質化現象;主題4(“演出”0.015、“酒吧”0.016、“沒什么”0.006)暴露夜間娛樂內容單薄問題;主題5(“游船”0.011、“建議”0.011、“沱江”0.007)體現游客對沱江游覽的優化期待;主題6(“門票”0.015、“沱江”0.012、“商業化”0.010)強調門票經濟與景觀原真性矛盾。
高頻負面詞匯集中主題2、3、6,“宰客”“不值”“商業化”重復出現,指向過度商業開發已實質性損害游客體驗;“攜程”“客服”跨主題分布,顯示第三方平臺服務質量影響整體滿意度。
核心矛盾體現為:沱江游船等特色項目因強制消費降低口碑,夜間經濟過度依賴酒吧業態削弱文化特色,門票管理粗放加劇商業化感知。
建議:改進需優先規范游船服務流程,建立商戶黑名單制度;差異化開發苗族銀飾鍛造、巫儺文化展演等非遺體驗項目;推行分時段門票與聯票系統緩解擁擠壓力;建立網絡評論實時監測機制,針對“推銷”“宰客”等高頻負面詞實施定向整改。
4.基于神經網絡CNN算法的情感分析
4.1模型設計
基于神經網絡的情感分析模型想要將文本序列轉換為密集向量表示這其中得運用到嵌入層,提取特征是卷積層來負責,分類則是全連接層負責[15]。模型使用 Embedding 層將詞匯映射到向量空間,通過 Conv1D 層捕獲局部特征,MaxPooling1D 層提取最顯著特征,Flatten 層將特征展平,Dense 層實現分類,輸出層使用 softmax 激活函數。
模型具體包括一個Embedding層,用于將文本轉換為300維的詞嵌入向量表示;一個1維卷積層,其中包含128個卷積核,每個卷積核的大小為5,采用ReLU激活函數;一個MaxPooling1D層,用于下采樣,降低特征維度;另一個1維卷積層,包含64個卷積核,每個卷積核的大小為5,同樣采用ReLU激活函數; Flatten層用于展平輸出,一層全連接的Dense層包含64個神經元,再連接到一個輸出層,使用softmax激活函數輸出分類概率。整個模型使用Adam優化器和交叉熵損失函數進行訓練,標簽進行了獨熱編碼處理。模型流程圖如圖4-1所示。
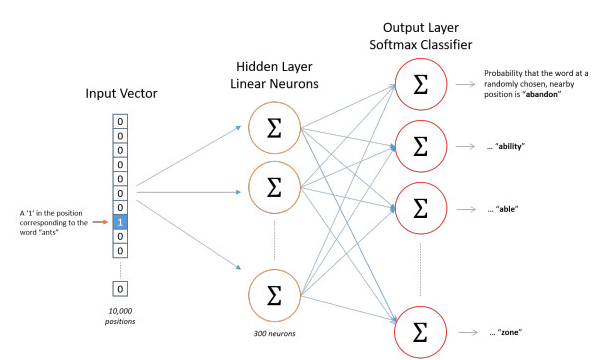
圖4-1 模型流程
4.2訓練
在訓練階段,將處理后的文本數據轉換為序列,使用 Tokenizer 對文本進行編碼,通過 pad_sequences 填充序列到相同長度。將標簽進行獨熱編碼,定義并編譯模型,將 fit方法加入模型中去,設置 epochs、batch_size 和驗證集比例。具體為:epochs 設置為100,表示要對整個數據集進行100次迭代訓練;batch_size 可以設定為32,表示每次訓練傳入模型的樣本數為32;驗證集比例可以設置為0.2,表示將20%的訓練數據作為驗證集用于驗證模型的性能。訓練完成后,得到神經網絡模型。中間過程如圖4-2所示。

圖4-2 ?模型訓練
4.3評估
通過模型預測得到分類結果,計算準確率作為性能評估指標。同時,利用 sklearn 提供的函數計算 ROC 曲線和 AUC 值,評估分類器性能則用ROC曲線;計算混淆矩陣并繪制熱力圖,幫助分析模型在不同類別上的分類效果。這些評估指標和可視化結果能夠全面評價神經網絡情感分析模型的表現。評估結果如圖4-3和4-4所示。
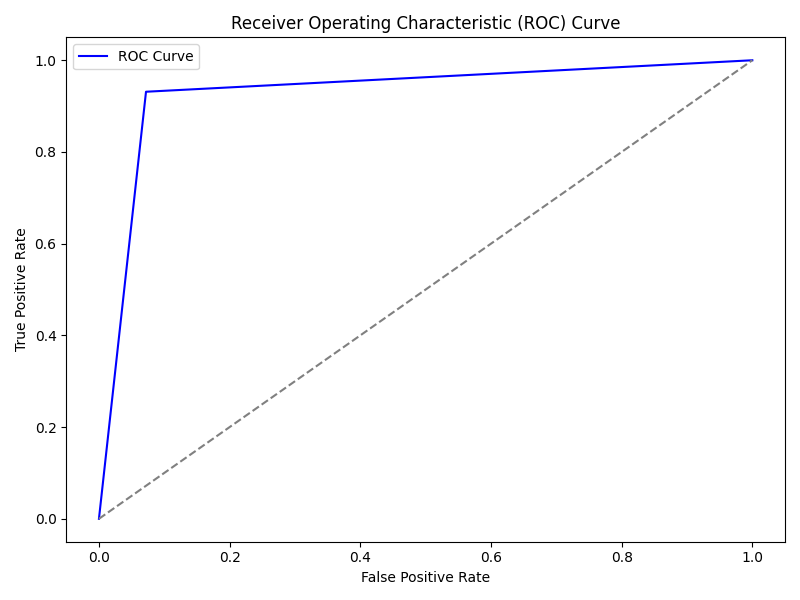
圖4-3模型評估
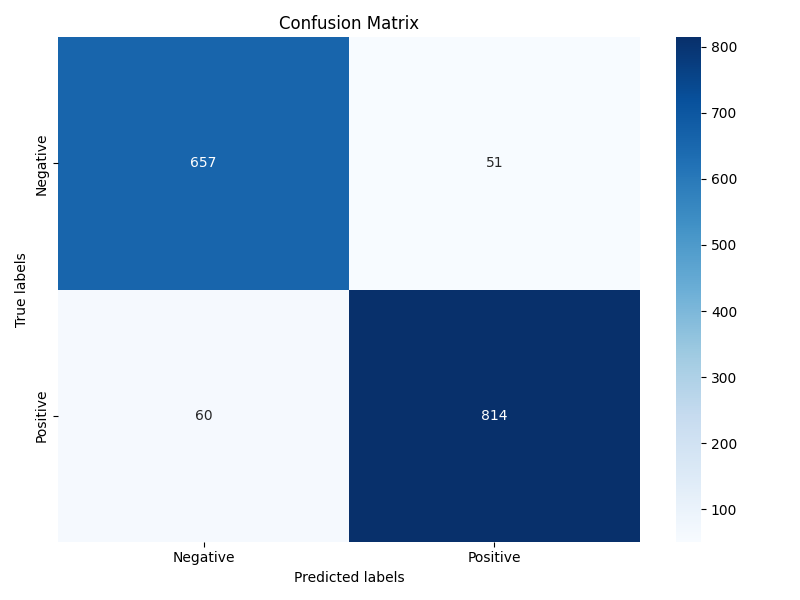
圖4-4 ?模型評估
4.4模型訓練結果分析與評估
根據提供的訓練結果,模型在最后一個epoch(第5個epoch)結束后的驗證集上的準確率為92.92%,這表明模型對于給定的數據集能夠正確分類92.92%的樣本。觀察其中指標變化,訓練步數的增加而其中的損失函數和準確率也跟著變化。損失函數(loss)一開始則是為0.0321,訓練集準確率為98.44%,而隨著訓練步數變化,損失函數也開始下降,而準確率逐漸上升。直到第5個epoch結束后,損失函數為0.0286,訓練集準確率為99.12%。訓練集上模型表現則是在穩穩提升。
訓練變化更新過程中驗證集的損失函數和準確率(val_loss和val_acc)也在不斷變化著。從結果來看,驗證集上的損失函數在整個訓練過程中一直在上升,而準確率則在逐步下降。由此可見,模型在驗證集上存在一定的過擬合現象,即模型在訓練集上表現良好,但泛化能力較差。
4.5模型優化與情感分析
根據訓練結果,使用GridSearchCV進行超參數調優、訓練最佳模型、評估性能、繪制ROC曲線和混淆矩陣、從而實現模型優化:
首先,通過GridSearchCV搜索最佳超參數組合,然后使用最佳超參數重新訓練模型。再根據訓練結果評估最佳模型的性能,包括在訓練集和測試集上的準確率、損失等指標。最后,繪制訓練和驗證集的損失率變化圖,計算并繪制ROC曲線以及繪制混淆矩陣,以更全面地評估模型性能。主要代碼如下圖4-5所示:

圖4-5 ?模型優化主要代碼
最終優化后Roc曲線、混淆矩陣如圖4-6和圖4-7所示:

圖4-6 ?模型優化后ROC曲線
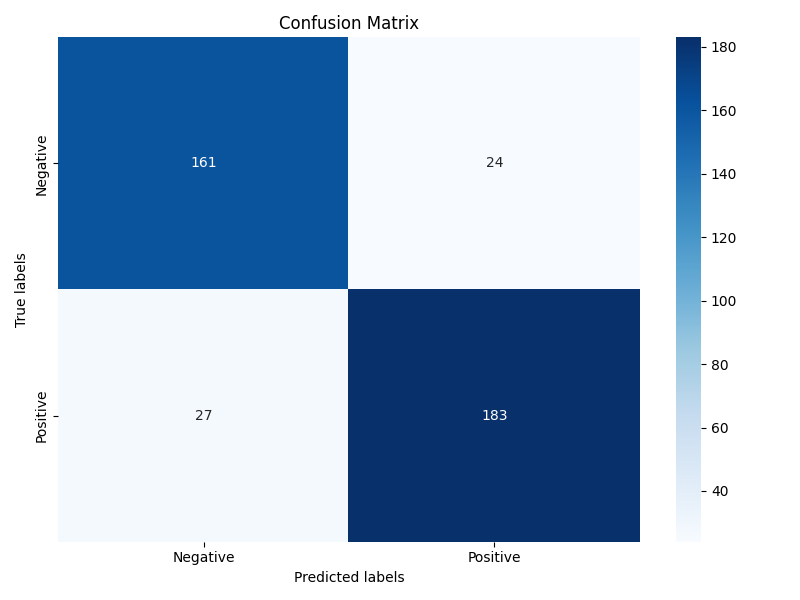
圖4-7 ?模型優化后混淆矩陣
根據優化后的混淆矩陣和roc曲線以及準確率可以發現訓練準確率為93.9%,相比沒有優化的模型得到一定提升。最終通過優化后的模型對評論內容進行情感分析,得到如圖4-8所示情感分析結果:
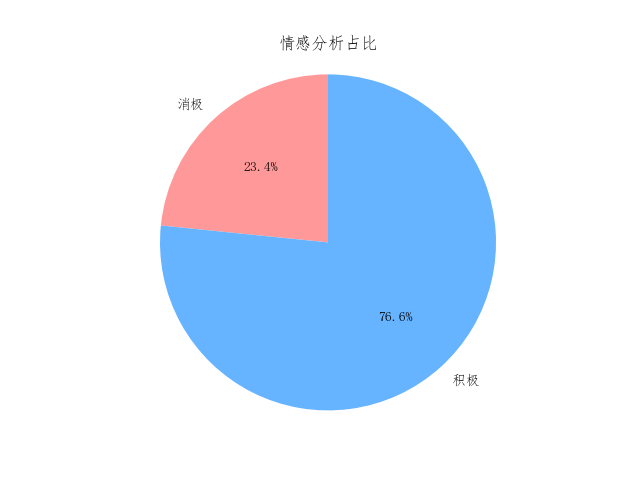

)


優化算法簡介)
)

)
)
![數學建模算法-day[14]](http://pic.xiahunao.cn/數學建模算法-day[14])









