1. 問題背景
模型剪枝是實現模型輕量化、加速推理的關鍵步驟。然而,在 Ultralytics YOLOv8 的生態中,在成功剪枝后,進行微調(Fine-tuning)時會遇到一個令人困惑的現象:明明加載的是剪枝后的模型(例如 20M 參數),但訓練啟動時打印的日志卻顯示為標準版模型的參數(例如 25M)。并且經過驗證,微調后的模型參數就是標準的yolo模型。
加載代碼如下:
model = YOLO("pruned.pt") # load a pretrained model (recommended for training)model.train(data=name_yaml, device=0, imgsz=640, epochs=50, batch=32, workers=16, name=path_fineturn) # train the model
原因是Ultralytics 的 Trainer 仍會先依據 原始 YAML 構建標準結構(約 25M 參數)。隨后僅將 .pt 文件中的權重加載到這張標準結構中。
2. 代碼觸發點與根本原因
問題的根源在于 Ultralytics 的 Trainer 在初始化模型時(get_model 方法)的執行順序。
在ultralytics/engine/model.py中的Model類的train()方法中,原始代碼如下:
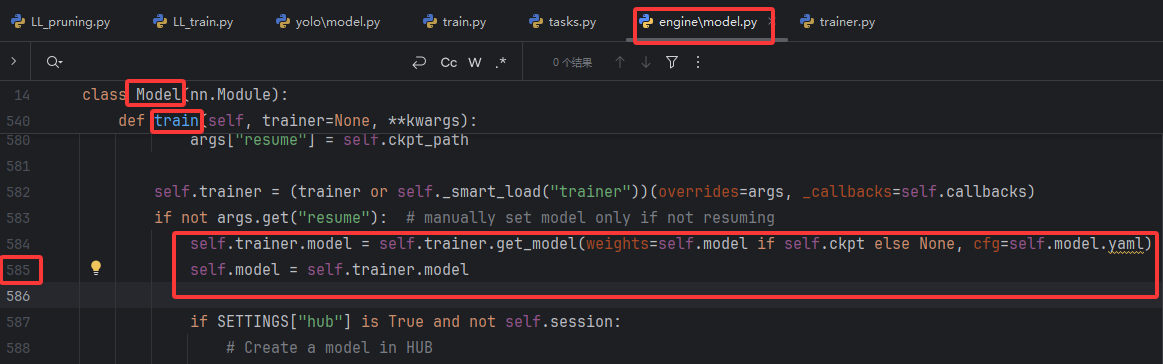
self.trainer.get_model 方法的執行流程如下:
優先使用
cfg參數構建模型:該參數接收 cfg=self.model.yaml。由于 pruned.pt 在保存時不會自動更新其內部的 YAML 配置(?model = YOLO("pruned.pt")會構造出一個實例,里面的self.model有很多屬性,其中self.model.model是模型網絡,這是真正的、由網絡層構成的可執行實體。我們的剪枝操作直接修改了這個對象,比如減少了某些卷積層的通道數,從而改變了它的實際結構。self.model.yaml是配置文件,剪枝時只修改了self.model.model,沒有更新原始的self.model.yaml),所以這里的self.model.yaml仍然是標準版 YOLOv8m 的網絡結構。創建標準結構并打印摘要:
get_model?會立即執行?model = DetectionModel(cfg)?通過self.model.yaml來構建一個完整的未剪枝模型(25.8M)。隨后調用?model.info()?方法,這就是日志中顯示"標準版"摘要的原因。完成標準結構創建后,get_model?才會處理 weights 參數,將 pruned.pt 中的權重加載到剛創建的標準結構中。PyTorch 的?load_state_dict?會按照名稱和形狀匹配的原則加載對應層的權重,跳過不匹配的層,此時模型仍保持標準骨架結構。
3. 改進寫法(實際切換到剪枝后結構)
為了解決這個問題,我們必須在 Trainer 開始訓練前,確保其內部持有的模型對象是我們剪枝后的那一個。
將代碼調整為:
if not args.get("resume"): # manually set model only if not resumingself.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)# ★ 關鍵修正:用我們剪枝后的模型對象,替換掉 Trainer 內部剛剛由 YAML 創建的模型self.trainer.model.model = self.model.modelprint("\n--- Verifying model after swapping in Trainer ---")# 打印替換后的模型參數量params_after_swap = sum(p.numel() for p in self.trainer.model.model.parameters()) / 1e6print(f"Parameters inside trainer: {params_after_swap:.2f}M\n") # 應顯示約 20.8Mself.model = self.trainer.modelif SETTINGS["hub"] is True and not self.session: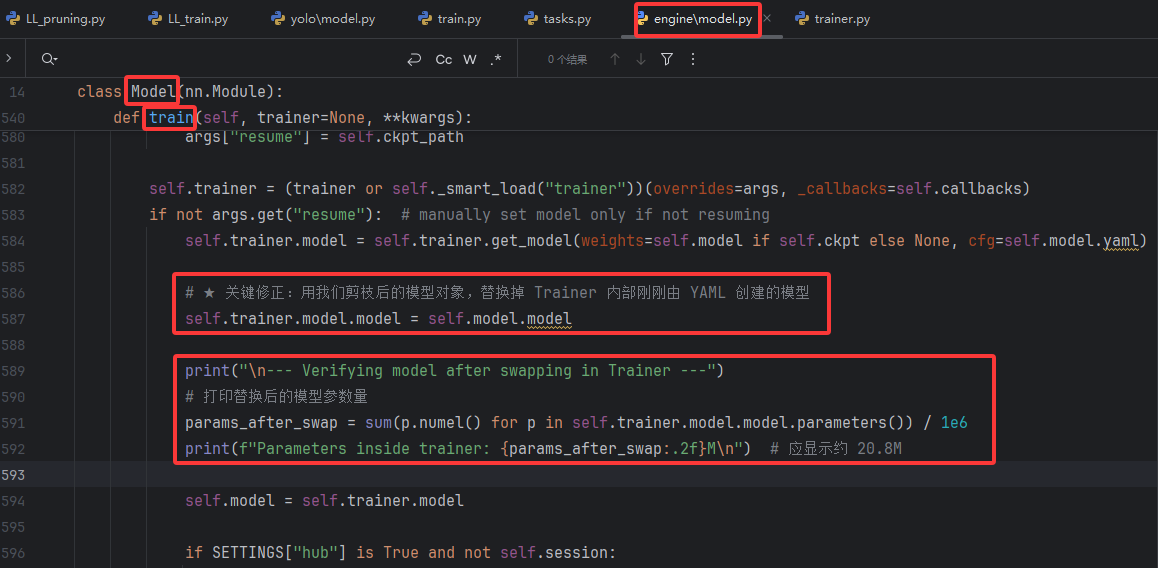
依然允許
get_model按部就班地完成它的初始化流程(包括打印那條“誤導性”的日志)。但在這之后,立即通過
self.trainer.model.model = self.model.model這行代碼,強行將Trainer內部的nn.Module對象替換為我們真正的、剪枝后的模型 (self.model.model)。啟動階段的日志已打印過標準版結構,因此顯示上仍是標準參數量,但通過打印替換后的模型對象的參數量可以看到已經替換為剪枝后的模型。
深度解析:為什么是替換?.model.model 而不是 .model?
yolo.model對象 (DetectionModel等BaseModel的實例)
它是一個“功能完備的檢測器”,不僅包含了網絡結構,還封裝了與之相關的元數據和方法(如.train(),.info(),.yaml等)。把它理解為一個高級接口。yolo.model.model對象 (純nn.Module實例)
這才是我們通常意義上所說的PyTorch 模型網絡。它是一個純粹的torch.nn.Module子類,由各種網絡層搭建而成。我們的剪枝操作,直接修改的就是這個對象。
為什么不寫成 self.trainer.model = self.model?
源(Source):
self.model.model是我們從加載的pruned.pt中取出的、那個已經被剪枝過的純粹網絡結構。目標(Destination):
self.trainer.model.model是Trainer內部那個標準結構的純粹網絡。
self.trainer.model 是一個高級的 BaseModel 對象,Trainer 在初始化時已經對其進行了一些配置(如設備分配等)。如果我們用self.trainer.model = self.model整個地替換掉它,可能會破壞這些已經完成的設置,存在潛在風險。只替換最底層的 nn.Module,既能保證網絡結構正確,又不會干擾 Trainer 的其他工作流程。
注意替換模型必須在self.trainer.model構建好之后,如果直接使用self.trainer.model.model = self.model.model會顯示self.trainer.model是個str,還不是對象。
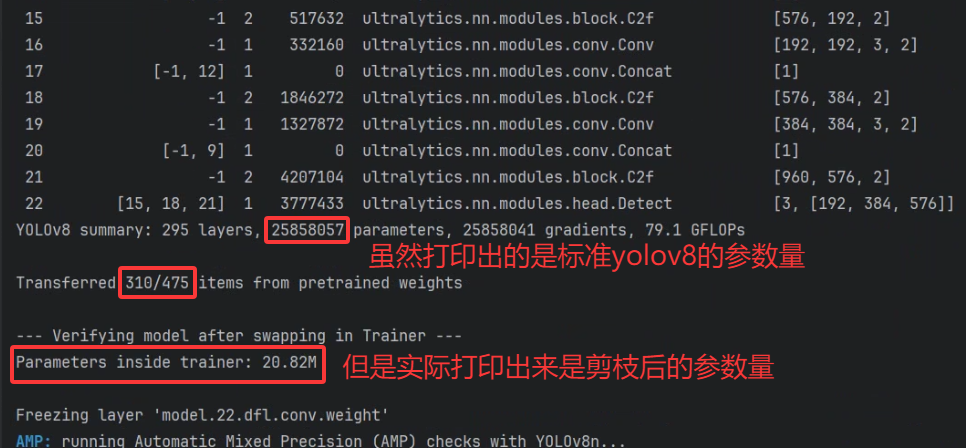
4. 顯示不一致的原因
Summary 打印時機:
get_model在構建標準結構后立即輸出層數與參數量。結構替換發生在 summary 之后:沒有重新打印,因此日志沒有更新為剪枝后的參數量。
保存階段:調用
model.save()或torch.save({'model': ...})時,寫入的是替換后的剪枝模型對象,所以最終.pt文件尺寸/參數量正確。
5. 驗證流程建議
為了確保操作是正確的,最好進行驗證。
步驟 1:驗證初始剪枝模型
在開始微調訓練前,先確認?pruned.pt 是真的被剪枝了。
from ultralytics import YOLO
initial_model = YOLO("pruned.pt")
print("--- Verifying initial pruned model ---")
initial_model.model.info(verbose=False) # 應顯示約 20.8M 參數
步驟 2:在替換后立即驗證
在修正代碼的核心行之后,立刻加入打印驗證,就是之前的代碼。
# ...
self.trainer.model.model = self.model.model
print("\n--- Verifying model after swapping in Trainer ---")
# 打印替換后的模型參數量
params_after_swap = sum(p.numel() for p in self.trainer.model.model.parameters()) / 1e6
print(f"Parameters inside trainer: {params_after_swap:.2f}M\n") # 應顯示約 20.8M
步驟 3:驗證最終保存的模型
訓練結束后,加載最終生成的權重文件,再次確認。
final_model = YOLO("runs/train/exp/weights/last.pt")
print("--- Verifying final saved model ---")
final_model.model.info() # 應顯示約 20.8M 參數
結果如圖:




常用類)




主頻和時鐘配置實驗(1))
創建型:生成器模式詳解)






分論壇圓滿舉行)


實現端到端乳腺癌放射治療計劃制定|文獻速遞-醫學影像算法文獻分享)