引言
n8n簡介:自動化工作流利器
n8n是一款功能強大的開源自動化工具,采用獨特的“公平代碼”(Fair-Code)許可模式,旨在幫助用戶連接各種應用程序和服務,從而實現工作流的自動化。它通過直觀的可視化界面,使用戶能夠以低代碼甚至無代碼的方式構建復雜的自動化流程,極大地提升了日常運營效率并減少了重復性任務。n8n的開放性體現在其源代碼對公眾可見,并且可以進行自托管,同時其活躍的社區為用戶提供了持續的支持和幫助 。 ?
這種開放的特性對于需要長期穩定運行的每日自動化任務尤為重要。相較于閉源的SaaS平臺,n8n的透明開發過程和強大的社區支持降低了長期維護和故障排除的門檻。用戶不僅能夠查看底層代碼以更好地理解其運作機制,還能從社區中獲得豐富的經驗分享和解決方案 。這種可靠性和靈活性使得n8n成為構建復雜、定制化每日自動化任務的理想選擇,而不僅僅是簡單的集成工具。 ?
本教程目標與價值
本教程旨在為用戶提供一個全面、深入且詳細的n8n使用指南,指導用戶從零開始構建一個端到端的信息聚合與分發系統。核心目標是實現每日自動獲取AI領域的最新資訊、GitHub上最新的AI代碼、最新的AI工具,以及Bilibili、知乎、微信公眾號、YouTube等熱門中文平臺的最新最熱的10條信息。獲取到的內容將經過整理,形成一份結構化的“最新AI快訊”,并通過微信群或微信公眾號進行分發,同時存儲到Notion數據庫中,以實現信息的高效觸達與管理。
本教程的價值在于,它將幫助用戶節省大量手動收集和整理信息的時間,確保所獲取信息的時效性和準確性。通過自動化流程,用戶能夠實現多平臺、多渠道的信息管理與分發,從而更高效地掌握AI領域的前沿動態和熱門趨勢,提升個人或團隊的信息競爭力。
n8n基礎環境搭建與核心概念
安裝與部署n8n
n8n提供了多種靈活的安裝和部署方式,以適應不同用戶的技術背景和實際需求。
本地安裝指南 (npm/Docker)
對于希望在本地環境中運行n8n的用戶,主要有兩種推薦的安裝方法:
-
通過npm安裝: 這種方法適合快速啟動和測試,尤其對于熟悉Node.js環境的用戶。
-
先決條件: 確保系統已安裝Node.js LTS版本(v18或更高版本)及其捆綁的npm(Node Package Manager)。 ?
-
安裝步驟: 打開命令行工具(Windows用戶可使用PowerShell或Command Prompt,macOS/Linux用戶使用Terminal),運行以下命令全局安裝n8n:
npm install -g n8n。 ? -
啟動與訪問: 安裝完成后,在命令行中輸入
n8n即可啟動n8n服務。系統會提示按O鍵在默認瀏覽器中打開n8n的用戶界面 。 ? -
更新: 首次安裝后,建議運行
npm update -g n8n命令以確保n8n版本為最新 。 ?通過npm安裝的優點在于其快速簡便,能夠讓用戶迅速體驗n8n的功能 。 ?
-
-
通過Docker安裝: 對于需要長期穩定運行的工作流,Docker安裝是更推薦的方式。它提供了隔離的運行環境和便捷的數據持久化能力。
-
先決條件: 在Windows、macOS或Linux系統上安裝Docker Desktop(或遵循官方指南安裝Docker引擎)。 ?
-
拉取與運行: 打開終端或命令行,執行以下命令拉取并運行n8n Docker鏡像:
docker run -it --rm -p 5678:5678 n8nio/n8n。這將把n8n的用戶界面暴露在本地的5678端口。 ? -
訪問: 在瀏覽器中訪問
http://localhost:5678即可使用n8n 。 ?為了確保工作流和憑證數據在Docker容器重啟后不會丟失,強烈建議配置數據持久化。這可以通過在運行命令中掛載本地卷實現:
docker run -it --rm -p 5678:5678 -v ~/.n8n:/home/node/.n8n n8nio/n8n。此命令將用戶主目錄下的.n8n文件夾映射到容器內部,從而保存所有配置和數據 。這種數據持久化能力對于每日自動化任務的穩定性和數據完整性至關重要。 ?
對于更復雜或接近生產環境的設置,可以考慮使用Docker Compose。Docker Compose允許通過一個YAML文件定義和管理多個Docker容器的服務,包括n8n及其數據庫、Redis等。它還支持在環境變量中配置基本認證,例如設置
N8N_BASIC_AUTH_ACTIVE=true、N8N_BASIC_AUTH_USER和N8N_BASIC_AUTH_PASSWORD,為n8n實例添加一層訪問安全保障 。雖然用戶查詢未明確提及安全性,但考慮到自動化任務可能涉及敏感數據流出,并在未來可能需要外部訪問(例如Webhook觸發),在部署階段就引入基本的安全配置是至關重要的。 ? -
云端部署考量
除了本地自托管,n8n還提供云端托管服務(n8n Cloud)。n8n Cloud的優勢在于用戶無需進行任何技術設置或基礎設施維護,即可獲得持續的正常運行時間監控和一鍵升級到最新版本等便利 。對于希望快速上線每日自動化任務,但缺乏服務器管理或運維經驗的用戶而言,n8n Cloud是一個極具吸引力的選項。它將底層基礎設施的復雜性抽象化,使用戶能夠專注于工作流的設計和實現,從而更快地達到自動化目標 。 ?
工作流基礎:節點、觸發器、憑證
理解n8n工作流的核心組成部分是高效構建自動化的基礎。
-
節點 (Nodes): 節點是n8n工作流的基本構建塊,每個節點都執行特定的任務,例如獲取數據、處理數據或將數據發送到其他服務。n8n的節點分為內置節點(包括核心節點和應用節點)和社區節點 。 ?
-
核心節點 (Core Nodes): 這些節點提供基礎且通用的功能,如HTTP Request(用于發送HTTP請求)、RSS Read(用于讀取RSS訂閱)、Filter(用于數據篩選)、Set(用于數據轉換和設置)和Code(用于執行自定義JavaScript代碼)等 。 ?
-
應用節點 (App Nodes): 這些節點專門用于與特定的第三方服務進行集成,例如GitHub(用于代碼倉庫操作)、Notion(用于數據庫和頁面管理)和YouTube(用于視頻和頻道操作)。 ?
-
-
觸發器 (Triggers): 觸發器是啟動工作流的特殊節點。它們定義了工作流何時以及如何被激活。常見的觸發器類型包括Schedule Trigger(定時觸發,用于每日執行任務)、Webhook(通過接收HTTP請求觸發)和Manual Trigger(手動觸發,用于測試和按需運行)。 ?
-
憑證 (Credentials): 憑證是存儲用于連接外部服務的認證信息的安全機制,例如API密鑰、OAuth令牌等。它們確保n8n能夠安全地訪問和操作第三方服務的數據 。憑證在n8n的用戶界面左側菜單的“Credentials”選項卡中進行管理,支持創建、編輯和在團隊成員之間共享,從而提高了工作流的安全性與可維護性 。 ?
n8n的模塊化節點設計以及觸發器和憑證的明確分離,是其能夠實現復雜自動化任務的關鍵。這種設計使得用戶能夠像搭積木一樣構建工作流,同時將敏感信息集中安全管理,從而提高了工作流的可維護性和整體安全性。清晰地理解這些核心概念及其在工作流設計中的作用,將幫助用戶更快地掌握和應用n8n,從而實現快速搭建自動化流程并確保其穩定運行。
創建與執行第一個工作流
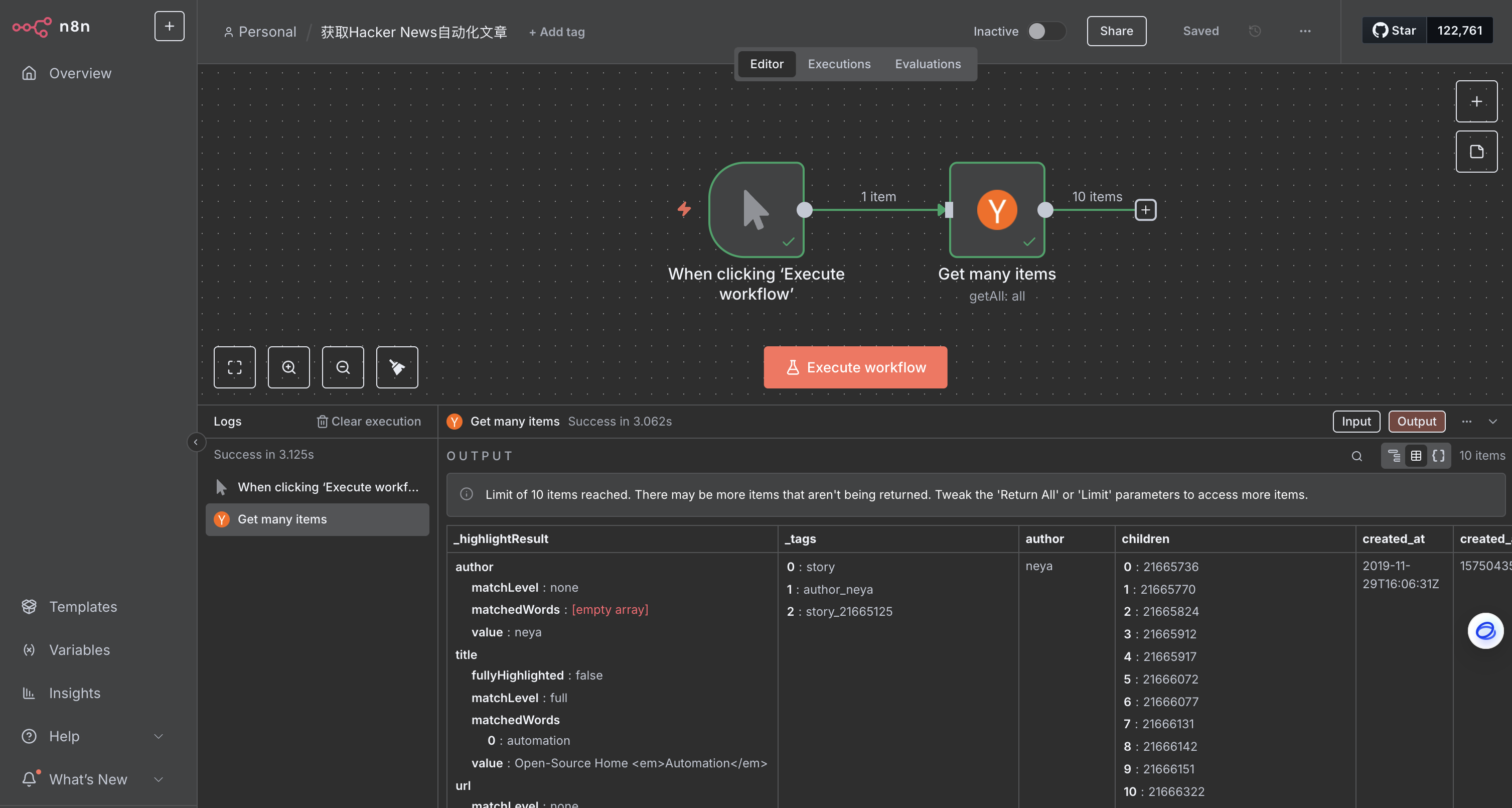
為了幫助用戶快速上手,本節將以一個簡單的示例工作流——“獲取Hacker News自動化文章”——來演示n8n工作流創建的基本步驟。
-
添加觸發器節點: 在n8n畫布上,點擊右上角的“+”圖標或按下“Tab”鍵打開節點面板。搜索并選擇“Manual Trigger”節點。這個節點允許用戶隨時通過點擊“Execute workflow”按鈕手動運行工作流 。 ?
-
添加應用節點: 在Manual Trigger節點的右側點擊“+”圖標,再次打開節點面板。搜索并選擇“Hacker News”節點。在“Actions”部分,選擇“Get many items”操作 。Hacker News節點將被添加到畫布上,其配置詳情窗口也會自動打開。 ?
-
配置節點參數: 在新添加的節點配置窗口中,用戶將看到“Parameters”、“Settings”和“Docs”選項。
-
Parameters(參數): 這些是特定于節點功能的設置。對于Hacker News節點,配置以下參數:
-
Resource(資源): 設置為“All”以選擇所有數據記錄(文章)。
-
Operation(操作): 設置為“Get Many”以獲取選定的文章。
-
Limit(限制): 輸入“10”以限制結果數量為10條。
-
Additional Fields(附加字段)> Add Field(添加字段)> Keyword(關鍵詞): 輸入“automation”。這將過濾結果,只包含含有關鍵詞“automation”的文章 。 ?
-
-
Settings(設置): 這些是所有節點通用的設置,控制設計和執行。例如,可以在“Notes”中添加簡短描述,并在“Display note in flow?”中選擇顯示在畫布上 。 ?
-
-
執行節點: 在節點詳情窗口中,點擊“Execute step”按鈕。用戶應該會看到10條結果顯示在“Output Table”視圖中。成功執行后,畫布上該節點上方會出現一個小的綠色對勾 。請求的數據將以表格、JSON和Schema格式顯示在節點窗口中,用戶可以根據需要切換視圖。節點窗口還會顯示“Start Time”、“Execution Time”和返回的“items數量” 。 ?
-
保存工作流: 完成節點編輯后,選擇“Back to canvas”返回主畫布。默認情況下,工作流保存為“My workflow”。用戶可以通過點擊編輯器UI頂部的名稱,將其重命名為“Hacker News workflow”。最后,通過按下“Ctrl + S”或“Cmd + S”或點擊編輯器UI右上角的“Save”按鈕來保存工作流 。 ?
n8n的可視化編輯界面和“逐步執行”功能是其實現“快速搭建工作流”的關鍵優勢。用戶可以即時查看每個節點的數據輸出和執行狀態,這種即時反饋機制極大地簡化了調試過程,尤其是在構建本教程中涉及的復雜多步驟自動化任務時。通過在每個小步驟中驗證邏輯,用戶能夠更快地理解和應用n8n,從而加速實現其自動化方案。
核心數據獲取工作流:多源信息聚合
本節將詳細介紹如何利用n8n從各種來源獲取AI相關資訊、GitHub代碼、AI工具以及熱門平臺信息。
每日AI快訊獲取
AI相關最新資訊
獲取AI相關最新資訊是構建“AI快訊”系統的核心。n8n提供了多種方法來收集這些信息。
-
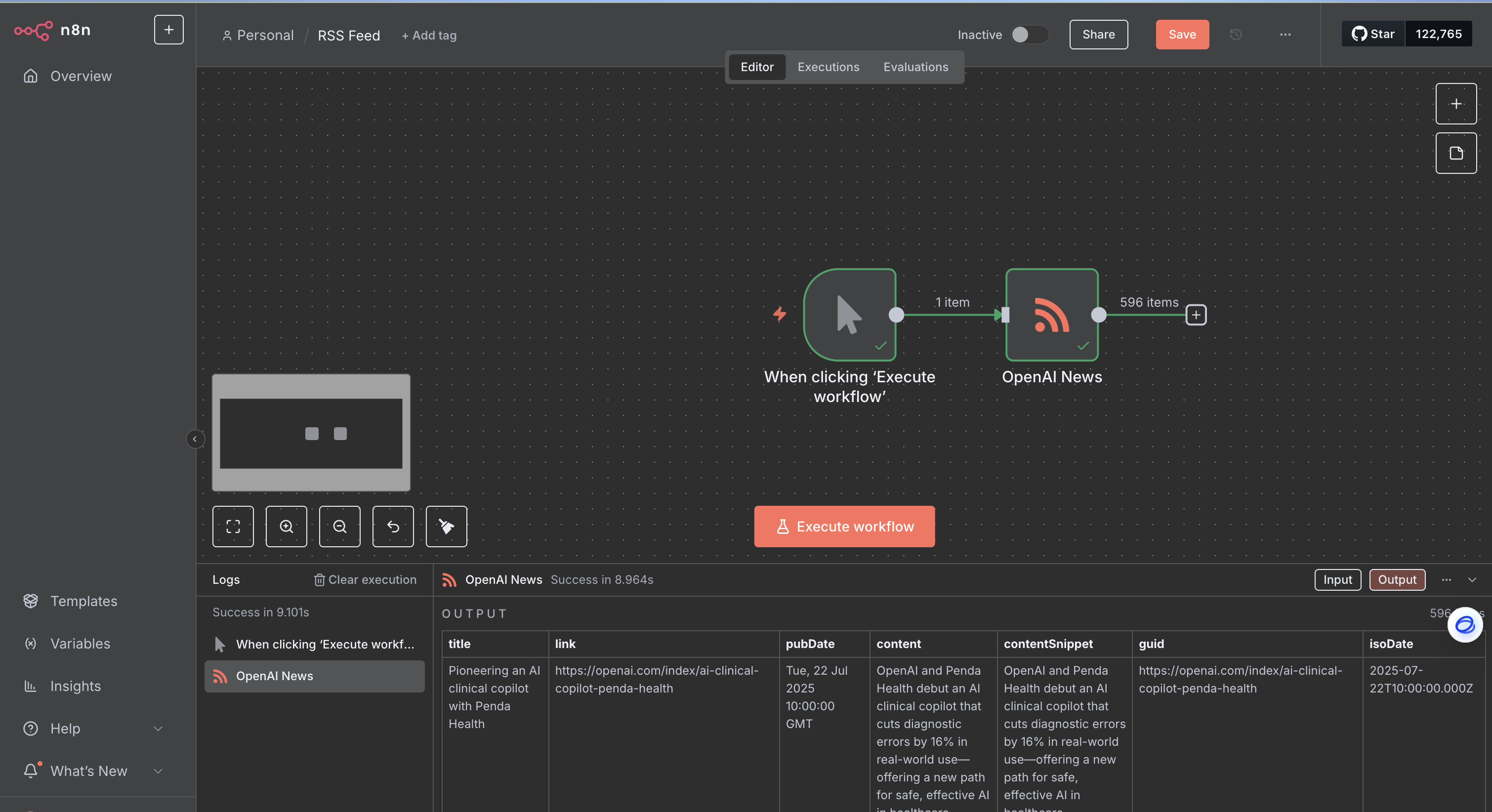
使用RSS Read節點訂閱AI博客與媒體 RSS Read節點是獲取結構化新聞內容的理想選擇,它通過訂閱RSS Feed URL來讀取數據 。在RSS Read節點中,只需簡單地輸入目標RSS Feed的URL即可 。該節點將輸出包含文章標題、鏈接、內容摘要和發布日期等字段的結構化數據 。 ?
RSS是新聞聚合的有效方式,因為它提供了預先結構化的標準化數據,省去了復雜的網頁解析工作,從而提高了數據獲取的效率。然而,需要注意的是,并非所有目標平臺(如Bilibili、知乎、微信公眾號、YouTube)都直接提供易于訪問的RSS源,這要求我們結合其他方法來彌補。
為了方便用戶快速搭建工作流,以下表格提供了一份精選的AI新聞RSS源列表,這些來源涵蓋了官方博客、知名科技媒體以及社區聚合平臺,能夠直接滿足用戶獲取“最新AI相關資訊”的需求:
| 來源名稱 | RSS Feed URL | 簡要描述 | |
| OpenAI News |
| OpenAI的最新研究、產品發布和安全倡議 | |
| Google Research Blog |
| Google研究團隊在AI、機器學習等領域的最新創新和突破? | |
| DeepMind Blog |
| DeepMind的AI突破、項目和更新 | |
| MIT Technology Review ? Artificial Intelligence |
| 專注于機器學習、神經網絡和機器人領域的最新進展 | |
| TechCrunch ? AI |
| TechCrunch關于人工智能的最新文章和分析 ? | |
| VentureBeat ? Artificial Intelligence |
| VentureBeat關于AI、機器學習的深度報道和行業趨勢 | |
| Synced Review |
| 提供AI、機器學習及新興技術的深度分析和研究文章 | |
| AI News (artificialintelligence-news.com) |
| 人工智能新聞聚合,涵蓋機器人、計算機模型等 | |
| Data Machina |
| 每周深入探討AI/ML研究、項目和倉庫的新進展 | |
| AIModels.fyi |
| 新AI研究、操作指南和熱門模型的摘要 |
-
通過HTTP Request節點進行網頁抓取 當目標網站不提供RSS Feed時,HTTP Request節點是獲取網頁內容的通用方法 。 ?
HTTP Request節點雖然通用,但也存在局限性,例如它可能無法繞過Cloudflare等高級反爬保護,也不支持JavaScript動態渲染的網站內容 。這意味著對于高度動態或受保護的網站,可能需要更復雜的解決方案。 ?
值得注意的是,n8n在AI代理和網頁抓取結合方面提供了相關模板 。這意味著人工智能可以輔助抓取過程,例如進行內容提取或摘要,甚至生成抓取邏輯。例如, ?
ScrapeNinja n8n node提供了提取網頁主要內容和清理HTML的功能,能夠自動去除不必要的標簽(如腳本、iframe、HTML注釋和空白),從而獲得更精簡、更適合后續LLM處理的數據 。這種結合使得獲取的數據質量更高,更適合后續的“AI快訊”生成。 ?-
配置: 通常選擇
GET方法來獲取網頁內容 。在配置URL時,輸入目標網頁的完整地址 。 ? -
Headers(請求頭): 建議設置
User-Agent字段,模仿真實瀏覽器的請求頭,以避免被網站的反爬機制阻止 。 ? -
Retry Settings(重試設置): 配置重試機制以應對臨時網絡問題或API限流,這有助于提高數據獲取的穩定性 。 ?
-
-
HTML節點與CSS選擇器應用 通過HTTP Request節點獲取到網頁的HTML內容后,需要使用HTML節點(或Code節點結合Cheerio等庫)來解析和提取所需數據 。 ?
-
HTML節點操作:
-
Extract HTML Content(提取HTML內容): 此操作用于從HTML源中提取特定內容。用戶需要指定“Source Data”(數據來源,可以是JSON或二進制文件)和“Extraction Values”(提取值)。 ?
-
Extraction Values(提取值): 定義要提取的具體內容,包括“Key”(保存提取值的名稱)、“CSS Selector”(用于定位HTML元素的CSS選擇器)和“Return Value”(返回的數據類型,可以是屬性值、HTML內容、純文本或表單元素的值)。 ?
-
Options(選項): 可選擇“Trim Values”(去除值兩端的空格和換行符)和“Clean Up Text”(清理文本格式,如去除多余空白和換行)。 ?
HTML節點通過CSS選擇器提供了一種直觀且強大的方式來定位和提取頁面元素,這比使用正則表達式進行文本清理更為可靠和高效,尤其是在處理復雜或動態變化的網頁結構時。通過“Trim Values”和“Clean Up Text”選項對提取的文本進行預處理,可以使其更適合后續的“AI快訊”格式化。
-
-
GitHub上最新的AI代碼
獲取GitHub上最新的AI代碼通常需要利用GitHub的API搜索功能。
-
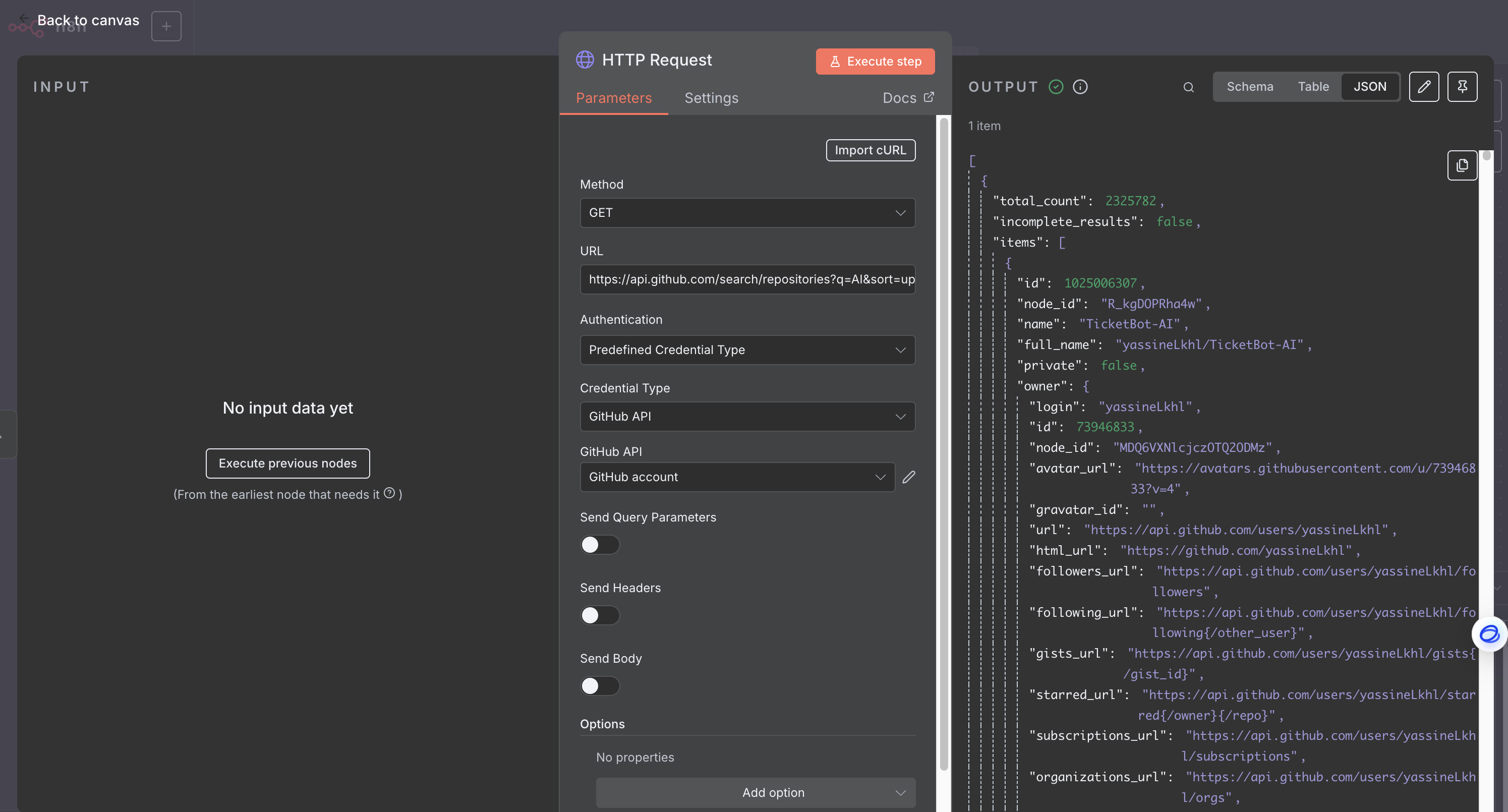
GitHub節點或HTTP Request調用API n8n內置的GitHub節點支持多種操作,如獲取倉庫、問題、文件等 。然而,對于獲取“最新的AI代碼倉庫”這一精確需求,直接通過HTTP Request節點調用GitHub API通常能提供更大的靈活性和精確性。 ?
GitHub API提供了強大的搜索功能,可以按關鍵詞(如“AI”、“machine learning”)和更新日期(
pushed或updated限定符)搜索倉庫 。 ?-
API Endpoint(API端點): 可以使用類似
https://api.github.com/search/repositories?q=AI&sort=updated&order=desc的URL來搜索包含“AI”關鍵詞且按更新時間降序排列的倉庫 。 ? -
認證: 調用GitHub API需要GitHub Personal Access Token。在n8n的HTTP Request節點中,可以選擇“Authentication”為“Predefined Credential Type”,然后選擇“GitHub”并選擇已創建的憑證進行認證 。 ?
直接調用GitHub API能夠更精確地滿足用戶對“最新AI代碼”的需求,因為它可以利用API提供的豐富搜索參數和排序選項,從而獲取最相關和最新的代碼倉庫信息。
-
最新的AI工具
獲取最新的AI工具通常需要通過HTTP Request和HTML節點從專門的AI工具目錄網站(例如aitoptools.com )進行網頁抓取,因為這類網站通常不提供RSS Feed。 ?
-
策略:
-
HTTP Request: 首先,使用HTTP Request節點獲取目標AI工具目錄網站的HTML內容。
-
HTML節點: 接著,利用HTML節點和CSS選擇器,從獲取的HTML中提取工具名稱、描述、鏈接、更新日期等關鍵信息。
-
篩選: 最后,根據網站上可能存在的“New”標簽或工具的發布日期,篩選出最新的AI工具。 網頁抓取是處理這類非標準化數據源的有效方法,它強調了HTTP Request和HTML節點在數據獲取中的重要作用。
-
熱門平臺信息獲取:Bilibili, 知乎, 微信公眾號, YouTube
針對Bilibili、知乎、微信公眾號和YouTube等熱門平臺,由于其API開放程度和反爬機制各異,獲取最新最熱信息需要采取不同的策略。
Bilibili最新最熱信息獲取
-
通過RSSHub: RSSHub是一個開源的RSS生成器,能夠為許多不提供原生RSS的網站生成RSS Feed 。這對于獲取Bilibili的最新最熱信息是一個非常有效的解決方案。 ?
-
Bilibili路由示例:
-
UP主投稿:
/bilibili/user/video/:uid/:embed?(替換:uid為UP主ID) -
UP主動態:
/bilibili/user/dynamic/:uid/:routeParams?(替換:uid為UP主ID) -
分區視頻排行榜:
/bilibili/ranking/:rid(替換:rid為分區ID)
-
-
使用: 在n8n的RSS Read節點中,輸入RSSHub生成的Bilibili RSS URL即可。例如,要獲取Bilibili熱搜,可以使用
https://rsshub.app/bilibili/search/hot(假設RSSHub部署在rsshub.app) 。 ?RSSHub將復雜的網頁解析或API調用抽象化,直接生成可供RSS Read節點使用的標準化RSS Feed,極大地降低了獲取Bilibili“最新最熱信息”的難度,使其成為快速搭建此部分工作流的首選方案。
-
-
通過API調用: Bilibili雖然有官方API,但通常需要開發者權限或進行逆向工程,其復雜性較高且可能不穩定 。因此,對于一般用戶而言,通過RSSHub獲取信息更為便捷和推薦。 ?
知乎最新最熱信息獲取
-
通過RSSHub: RSSHub同樣為知乎提供了多種路由,可以方便地獲取知乎的熱門內容 。 ?
-
知乎路由示例:
-
知乎熱榜:
/zhihu/hot? -
用戶動態:
/zhihu/people/activities/:id? -
專欄:
/zhihu/zhuanlan/:id(替換:id為用戶ID) ?
-
-
注意: 某些知乎路由可能需要配置
ZHIHU_COOKIES環境變量,以應對知乎的反爬措施 。這意味著用戶可能需要登錄知乎并獲取 ?z_c0cookie,然后將其添加到n8n的環境變量中,以確保數據獲取的穩定性。 知乎的“熱榜”和“日報”是獲取熱門信息的關鍵渠道 。RSSHub能夠直接提供這些內容的標準化RSS Feed,但用戶需留意并配置必要的cookie信息,以確保穩定地繞過反爬機制。 ?
-
微信公眾號最新最熱信息獲取
獲取微信公眾號的最新最熱信息是所有目標平臺中最具挑戰性的任務,因為微信公眾號沒有公共API或RSS Feed,且反爬機制非常嚴格 。 ?
-
挑戰: 微信公眾號的封閉性意味著無法簡單地使用內置節點或通用的RSSHub路由。
-
解決方案:
-
第三方工具/服務: 依賴第三方解決方案是目前最可行的途徑。例如,WeRSS是一個開源解決方案,它通過模擬登錄(QR碼認證)和后端調度,從用戶訂閱的公眾號中獲取內容并轉換為RSS Feed 。用戶可以部署WeRSS服務,然后將生成的RSS URL輸入到n8n的RSS Read節點中。此外,Apify上曾有WeChat Official Account RSS Service,但可能已棄用或變為付費服務 。 ?
-
自定義n8n節點或HTTP Request調用非官方API: n8n社區中存在一些自定義的微信公眾號節點 或WeChat Work節點 ,但其穩定性和功能可能受微信反爬策略影響,需要持續維護。此外,有社區用戶分享了使用HTTP Request節點調用微信公眾號API實現文章發布的案例,這需要公眾號的AppID和AppSecret,并可能涉及媒體上傳等復雜步驟 。需要明確的是,微信公眾號的API主要用于“發布”內容和管理賬號,而非公開“獲取”熱門文章列表。因此,用于獲取信息的方案(如WeRSS)與用于發布信息的方案(如HTTP Request調用發布API)是獨立的。 ?
-
YouTube最新最熱視頻獲取
YouTube提供了成熟的Data API,并且n8n內置了YouTube節點,這使得獲取YouTube熱門視頻相對容易 。 ?
-
YouTube節點: n8n內置的YouTube節點支持獲取視頻、頻道、播放列表等信息 。 ?
-
獲取熱門視頻: 使用YouTube節點的“Video”資源,選擇“Retrieve all videos”操作,并配置參數以獲取“mostPopular”視頻。用戶可以指定
regionCode(地區代碼)和videoCategoryId(視頻分類ID)來精確定位熱門內容 。 ? -
認證: 調用YouTube API需要YouTube Data API憑證,通常是OAuth 2.0認證 。用戶需要在Google Cloud Console中創建API項目并啟用YouTube Data API v3,然后獲取OAuth客戶端ID和密鑰,并在n8n中配置相應的憑證。 ?
雖然YouTube API提供了便捷的訪問,但需要注意其API使用限制(例如每日配額)。 ?
-
數據源API/RSSHub路由概覽
下表匯總了本教程中涉及的各種數據源的推薦獲取方法、示例端點/路由以及關鍵注意事項,為用戶構建多源信息聚合工作流提供清晰的指引:
| 平臺 | 數據類型 | 推薦獲取方法 | 示例Endpoint/路由 | 關鍵注意事項 | ||
| AI資訊 (通用) | 最新AI新聞 | RSS Read節點 | 見“推薦AI新聞RSS源列表” ? | 最直接高效,提供結構化數據 | ||
| 非RSS網站新聞 | HTTP Request + HTML節點 | 目標網站URL | 需處理反爬機制 (User-Agent),不支持JS動態渲染 ? | |||
| GitHub | 最新AI代碼 | HTTP Request調用GitHub API |
| 需GitHub Personal Access Token認證 ? | ||
| AI工具目錄 | 最新AI工具 | HTTP Request + HTML節點 |
| 需CSS選擇器提取數據,可能需根據“New”標簽或日期篩選 ? | ||
| Bilibili | 最熱信息 (熱門) | HTTP Request調用GitHub API | ?https://api.bilibili.com/x/web-interface/popular | 獲取熱門信息 | ||
| 知乎 | 最新最熱信息 (熱榜, 日報, 用戶回答) | RSS Read節點 + RSSHub |
| 某些路由可能需要配置 | ||
| 微信公眾號 | 最新最熱信息 | 第三方工具 (如WeRSS) | WeRSS生成的RSS URL | 獲取難度高,需部署WeRSS或使用第三方服務,可能涉及QR碼認證 ? | ||
| YouTube | 最新最熱視頻 | YouTube節點 | Video資源 -> Retrieve all videos -> | 需YouTube Data API憑證 (OAuth 2.0),注意API配額限制 ? |
數據處理與整合:構建“最新AI快訊”
從不同來源獲取的數據格式各異,需要進行清洗、標準化、篩選、去重和格式化,才能構建出統一的“最新AI快訊”。
數據清洗與標準化
Set節點:重塑數據結構
Set節點(Edit Fields (Set))是n8n中用于設置或覆蓋工作流數據的重要工具,它在數據標準化過程中扮演著核心角色 。通過Set節點,用戶可以將來自RSS、API、網頁抓取等不同格式的數據統一為“AI快訊”所需的標準格式。 ?
-
模式:
-
Manual Mapping(手動映射): 這種模式通過圖形用戶界面(GUI)進行操作,用戶可以拖放輸入值來配置字段。默認情況下,n8n會將值的名稱設置為字段名,并將表達式用于訪問值。用戶也可以選擇“Fixed”模式,直接設置固定的字段名和值 。 ?
-
JSON Output(JSON輸出): 這種模式允許用戶直接編寫JSON格式的數據,n8n會將其添加到輸入數據中。它支持在JSON中嵌入數組和表達式,提供了更靈活的數據結構定義能力 。 ?
-
-
關鍵操作:
-
統一字段名: 將不同來源的標題、鏈接、內容等信息映射到統一的字段名(例如:
title、url、content、source、date)。 -
保留必要字段: 啟用“Keep Only Set Fields”選項,可以只保留快訊所需的字段,丟棄所有不必要的數據,這有助于減少內存占用和簡化后續處理 。 ?
-
Set節點是實現數據“標準化”的關鍵,它允許用戶在可視化界面中直觀地重塑數據結構。這對于將來自不同來源的、格式不一的數據統一為“AI快訊”所需的標準格式至關重要,為后續的內容生成和分發奠定了堅實的基礎。
Code節點:高級文本處理與邏輯
Code節點允許用戶編寫自定義JavaScript代碼,進行更復雜的文本處理和數據轉換,彌補了標準節點在處理復雜文本、條件判斷和數據聚合方面的不足 。在構建“最新AI快訊”時,Code節點可以發揮以下作用: ?
-
字符串操作: n8n的Code節點提供了豐富的內置字符串處理函數,例如:
-
removeTags():用于去除HTML標簽,確保快訊內容純凈 。 ? -
toSentenceCase():將字符串轉換為句子大小寫格式 。 ? -
extractUrl():從字符串中提取URL 。 ? -
其他函數如
base64Encode()、base64Decode()、toSnakeCase()等也提供了強大的文本處理能力 。 ?
-
-
條件邏輯: 根據內容長度、關鍵詞等編寫自定義邏輯進行判斷,例如,如果文章內容過短則跳過,或根據關鍵詞對文章進行分類。
-
數據聚合: 將多個數據項的特定字段拼接成一個長字符串,例如將多條快訊內容合并成一個完整的每日報告。
Code節點是n8n中實現高級數據處理和定制化邏輯的“瑞士軍刀”。它能夠對抓取到的文章內容進行深度清理(例如去除多余HTML標簽),并根據需求對文本進行格式化,甚至實現簡單的摘要或關鍵詞提取,從而將原始數據轉化為更具可讀性的“快訊”內容。結合AI節點(如OpenAI GPT-4)對內容進行進一步總結或潤色,能夠顯著提升快訊的質量和閱讀體驗 。 ?
數據篩選與去重
從多個來源獲取數據時,可能會存在重復內容或不相關的信息,因此數據篩選和去重是確保“AI快訊”質量和精簡性的重要步驟。
Filter節點:條件篩選
Filter節點用于根據指定條件篩選數據項。如果數據項滿足條件,則通過并傳遞到下一個節點;否則,該數據項將被從輸出中移除 。 ?
-
配置: Filter節點允許設置一個或多個條件,并可以使用“AND”或“OR”邏輯組合這些條件 。它支持多種數據類型(如字符串、數字、日期、布爾、數組、對象)和豐富的比較操作(如等于、包含、大于、存在、為空等)。 ?
-
應用:
-
篩選“Top 10”: 例如,根據Bilibili或YouTube返回的點贊數、閱讀量、播放量等指標,篩選出前10條最熱門的信息。
-
篩選關鍵詞: 只保留包含特定AI關鍵詞(如“大模型”、“神經網絡”、“機器學習”)的文章,確保信息的強相關性。
-
篩選日期: 只保留最近24小時內發布的內容,確保“最新”性,避免推送過時信息。 Filter節點是實現“精確控制”工作流數據流的關鍵。它不僅能夠篩選出“最新最熱的10條信息”,還能通過組合條件實現復雜的業務邏輯,確保只處理最相關和高質量的數據。
-
Remove Duplicates節點應用
Remove Duplicates節點用于識別和刪除重復的數據項。它可以基于所有字段或特定字段進行去重 。 ?
-
應用: 當從多個RSS源或通過多種抓取方式獲取“最新資訊”時,很可能會出現重復的文章。例如,同一篇AI新聞可能被多個科技媒體轉載,并分別通過各自的RSS Feed推送。在這種情況下,使用Remove Duplicates節點可以有效清理重復內容,確保最終的“AI快訊”內容是獨一無二的,避免信息冗余,提升用戶閱讀體驗。
內容匯總與格式化
將篩選和去重后的數據整合成最終的“最新AI快訊”格式,是信息聚合流程的最后一步。
生成“最新AI快訊”內容
這一步的目標是將每條資訊的標題、鏈接、摘要等信息,按照預設的模板進行拼接和格式化,例如Markdown或HTML格式,以便在微信和Notion中良好展示。
-
使用Code節點或Set節點:
-
Code節點: 可以在Code節點中編寫JavaScript代碼,動態生成Markdown或HTML格式的快訊文本。這包括構建標題(例如“每日AI快訊 [日期]”)、使用列表格式呈現每條資訊(標題、來源、鏈接),并確保鏈接可點擊。Code節點提供了對文本格式的精細控制 。 ?
-
Set節點: 也可以使用Set節點,通過表達式將不同字段的內容拼接成預設的字符串模板。
-
-
結合AI節點進行內容優化: 可以進一步考慮引入AI節點(如OpenAI GPT-4或Google Gemini Pro)對獲取到的文章內容進行總結或潤色 。例如,將抓取到的長篇文章內容作為輸入,讓AI生成一個簡潔、吸引人的快訊摘要,或者對標題進行優化。這種結合能夠顯著提升快訊的質量和閱讀體驗,使其更符合“快訊”的特點。 ?
“最新AI快訊”的生成不僅僅是數據的簡單拼接,更是對原始內容的“再創造”。通過結合Code節點進行精細化格式控制,并潛在地利用AI節點進行內容摘要和潤色,能夠顯著提升快訊的質量和閱讀體驗。
內容分發與存儲:多渠道發布
完成“最新AI快訊”的生成后,下一步是將其分發到目標平臺并進行持久化存儲。
發送至微信群/公眾號
將“最新AI快訊”發送到微信群或微信公眾號是實現信息觸達的關鍵環節。
-
發送到微信群: 直接向微信群發送消息通常需要依賴微信群機器人或第三方服務,這些服務通常提供Webhook接收器。用戶可以將n8n工作流的最終輸出通過HTTP Request節點發送到群機器人的Webhook URL。然而,微信群的自動化接入相對復雜,可能需要自定義開發或使用特定的企業微信API。
-
發送到微信公眾號: 發送到微信公眾號是明確可行的,主要通過HTTP Request節點調用微信公眾號的官方API 。 ?
-
認證: 調用微信公眾號API需要公眾號的AppID和AppSecret 。這些憑證需要在n8n中配置為HTTP Request節點的認證信息。 ?
-
API流程: 微信公眾號的發布流程通常涉及多步,需要對微信API有一定了解:
-
獲取Access Token: 首先,需要通過AppID和AppSecret調用微信API獲取Access Token,這是后續所有API調用的憑證。
-
上傳媒體素材: 將快訊中可能包含的圖片(例如AI生成的封面圖 )和文章內容上傳到微信的素材管理接口,獲取對應的 ?
media_id。微信公眾號的API要求圖文消息的圖片和內容必須先作為素材上傳。 ? -
發布圖文消息或模板消息: 最后,使用獲取到的
media_id和整理好的快訊內容,調用微信API發布圖文消息或發送模板消息。 發送到微信公眾號的流程是整個工作流中最具挑戰性的環節之一,因為它涉及多步API調用和嚴格的認證要求。用戶需要仔細配置HTTP Request節點,并處理好每一步API調用的輸入和輸出。
-
-
存儲到Notion數據庫
將整理好的AI快訊存儲到Notion數據庫,便于長期管理、搜索和回顧,形成一個可追溯的知識庫。
-
Notion節點:數據庫操作與頁面創建 n8n內置的Notion節點支持多種數據庫操作,包括獲取數據庫、搜索、以及創建頁面等 。 ?
-
創建數據庫頁面: 使用Notion節點的“Database Page”資源,選擇“Create”操作 。 ?
-
參數: 此操作需要指定目標數據庫的
database_id,以及要創建頁面的屬性properties。這些屬性必須與用戶在Notion中預先創建的數據庫的Schema(即數據庫的列)嚴格匹配 。 ? -
屬性類型: Notion支持多種屬性類型,如Text(文本)、Numbers(數字)、Dates(日期)、URL(鏈接)和Rich Text(富文本)等 。用戶需要根據快訊內容的字段(如標題、鏈接、內容、日期、來源)選擇并映射到Notion數據庫中對應的屬性類型。 ?
-
-
認證: 調用Notion API需要Notion API Key。用戶需要在Notion中創建一個集成,并獲取API Key,然后在n8n中配置Notion憑證 。 ?
Notion數據庫的強Schema特性意味著數據在寫入前必須嚴格符合其預設結構。這強調了在數據處理階段(Set節點和Code節點)進行數據標準化和清洗的重要性,以確保數據能夠無縫地映射到Notion的字段中。
以下表格展示了“AI快訊”數據與Notion數據庫字段的映射示例,幫助用戶理解如何將n8n工作流中的數據項與Notion數據庫的列進行精確匹配:
-
| AI快訊字段 (n8n工作流輸出) | 對應Notion數據庫屬性名稱 (示例) | Notion屬性類型 (示例) | 描述 |
title | 標題 | Title | 快訊的標題,Notion數據庫的主標題字段 |
url | 鏈接 | URL | 快訊原文的鏈接 |
content_summary | 摘要內容 | Rich Text / Text | 快訊的精簡內容或摘要 |
published_date | 發布日期 | Date | 快訊的發布日期 |
source | 來源平臺 | Text / Select | 快訊的來源平臺 (如GitHub, 知乎, YouTube) |
category | 分類 | Multi-select / Select | 快訊的類別 (如AI新聞, AI代碼, AI工具) |
工作流調度與維護:確保穩定運行
構建一個每日運行的自動化工作流,不僅要關注其功能實現,更要確保其長期穩定運行。
定時觸發工作流
為了實現“每日獲取”信息的目標,工作流需要定時自動執行。
-
使用“Schedule Trigger”節點: n8n提供了“Schedule Trigger”節點,專門用于設置工作流的定時執行 。 ?
-
配置: 用戶可以根據需求配置工作流的執行頻率和具體時間。例如,可以設置為每天的特定時間運行,如每天早上9點,以確保每日“AI快訊”的及時性。 Schedule Trigger節點是實現“每日獲取”這一核心需求最直接、最可靠的方式,它確保了工作流的自動化和周期性執行,是構建自動化信息聚合系統的基石。
錯誤處理與調試策略
自動化工作流在生產環境中可能會遇到各種錯誤,例如網絡問題、API限流、數據格式異常等。因此,建立健壯的錯誤處理機制至關重要。
-
檢查失敗的工作流:
-
n8n的“Executions log”(執行日志)是診斷工作流問題的首要工具。它記錄了工作流的執行歷史、狀態和運行時間 。 ?
-
當工作流執行失敗時,用戶可以選中失敗的執行記錄,進入只讀模式,查看每個節點的執行路徑和具體的錯誤點 。 ?
-
n8n還支持將歷史執行數據加載到編輯器中進行調試,這使得用戶能夠重現特定問題并進行精確測試 。此外,在調試時,可以“停用”有問題的節點,從而隔離工作流的特定部分進行測試,而無需立即修復所有問題 。 ?
-
-
捕獲錯誤工作流 (Error Workflows): 為了主動管理工作流失敗,建議創建獨立的“Error Workflow”(錯誤工作流)。
-
創建: 錯誤工作流必須以“Error Trigger”節點開始 。 ?
-
設置: 在主工作流的“Workflow Settings”(工作流設置)中,指定此錯誤工作流為處理錯誤的流程 。 ?
-
功能: 當主工作流失敗時,錯誤工作流會自動執行,可以配置它發送通知(如通過郵件、Slack、Discord或Telegram)給團隊,及時告知錯誤發生及詳情 。 ?
-
注意: 錯誤工作流不能手動測試,它只在自動工作流遇到錯誤時觸發 。 ?
-
-
拋出異常 (Stop and Error Node): “Stop and Error”節點允許用戶在工作流的特定點主動拋出錯誤,通常用于數據驗證或當某些條件不滿足時終止流程 。 ?
-
自定義: 用戶可以自定義錯誤消息或錯誤對象 。 ?
-
用途: 檢查API返回的數據格式是否正確、數據類型是否符合預期、關鍵值是否缺失等。通過在問題檢測點立即拋出錯誤,可以防止問題進一步擴散,并更容易追蹤錯誤的根源 。 ?
-
-
節點級重試機制: 大多數n8n節點都提供重試設置。用戶可以配置在請求失敗時自動重試的次數,以應對臨時性錯誤,例如網絡瞬斷或API的臨時限流 。 ?
對于“每日”運行的自動化工作流,健壯的錯誤處理機制并非可選功能,而是確保系統“穩定運行”的強制要求。缺乏錯誤處理會導致生產環境中的靜默失敗或整個工作流中斷。通過上述策略,可以確保即使出現問題,系統也能及時響應并提供診斷信息,從而實現快速問題解決。
性能優化建議
對于每日獲取大量數據并進行處理和分發的工作流,性能優化至關重要,尤其是在自托管環境中。
-
減少內存消耗:
-
分批處理數據: 避免一次性處理大量數據,將數據拆分為更小的塊進行處理。例如,將10,000條記錄分批為每批200條進行處理 。 ?
-
謹慎使用Code節點: Code節點雖然功能強大,但可能內存密集型。應在必要時才使用,并優化代碼以減少內存占用 。 ?
-
優先自動執行: 對于大數據量處理,應優先選擇自動執行(如定時觸發)而非手動執行,因為手動執行會為前端創建數據副本,消耗更多內存 。 ?
-
拆分子工作流: 將復雜的工作流拆分為更小的子工作流。確保每個子工作流分批處理數據,并只返回有限的結果集給父工作流。這種方法可以確保子工作流只在內存中保留當前批次的數據,處理完成后即釋放內存 。 ?
-
-
持久化二進制數據: 默認情況下,n8n將二進制數據(如圖片、文檔)存儲在內存中,這可能導致處理大文件時出現內存溢出。建議將二進制數據存儲到文件系統或S3等外部存儲中,以避免此類問題 。 ?
-
配置并發控制: 對于自托管n8n實例,可以設置
N8N_CONCURRENCY_PRODUCTION_LIMIT環境變量來限制并發生產執行的數量,防止系統因同時運行過多工作流而過載 。 ? -
數據剪枝 (Data Pruning): 配置
EXECUTIONS_DATA_PRUNE和EXECUTIONS_DATA_MAX_AGE等環境變量,定期刪除舊的執行數據,以控制數據庫大小,尤其對于使用SQLite數據庫的用戶,這有助于提升性能 。 ?
這些性能優化措施對于處理大量數據和頻繁執行的任務至關重要,它們能夠確保自動化系統長期高效且穩定地運行。
總結與展望
總結
本教程為用戶提供了一個從n8n環境搭建到多源信息獲取、數據處理、內容分發與存儲的完整指南。通過深入探討n8n的核心概念(節點、觸發器、憑證)和部署選項,教程為用戶構建穩定可靠的自動化系統奠定了基礎。
在數據獲取方面,教程詳細闡述了如何利用RSS Read節點訂閱AI新聞源,以及如何通過HTTP Request和HTML節點進行網頁抓取,以應對缺乏RSS的網站。針對GitHub,推薦了直接調用其API獲取最新AI代碼的策略。對于Bilibili和知乎等中文熱門平臺,強調了RSSHub作為高效RSS生成器的作用。而微信公眾號作為最復雜的平臺,教程指出了其獲取信息的挑戰性,并推薦了WeRSS等第三方解決方案。YouTube則可利用其內置節點便捷地獲取熱門視頻。
在數據處理與整合階段,教程強調了Set節點在數據標準化中的關鍵作用,以及Code節點在高級文本處理、條件邏輯和內容優化方面的靈活性。Filter節點和Remove Duplicates節點則確保了數據的精確篩選和去重,保證了“AI快訊”的質量和獨一無二性。
最后,在內容分發與存儲環節,教程詳細指導了如何通過HTTP Request節點調用微信公眾號API進行多步發布,以及如何利用Notion節點將結構化快訊存儲到Notion數據庫,實現信息的高效管理。工作流調度(定時觸發)和全面的錯誤處理(執行日志、錯誤工作流、Stop and Error節點、節點重試)以及性能優化建議,共同確保了整個自動化系統的長期穩定與高效運行。
展望
n8n作為一款強大的自動化工具,其未來發展與人工智能的融合趨勢日益明顯。
-
AI與自動化融合: n8n正積極與AI技術集成,例如支持AI代理、AI輔助抓取和智能內容生成 。未來,可以進一步探索利用大型語言模型(LLM)進行更智能化的內容摘要、分類和個性化推薦,甚至實現自動化內容創作。這將使得“AI快訊”系統不僅能聚合信息,還能根據用戶偏好進行深度加工和定制化分發。 ?
-
社區與生態: n8n擁有一個活躍且不斷壯大的社區 。用戶可以通過社區獲取幫助、分享工作流模板和自定義節點,從而持續擴展n8n的自動化能力。這種開放的生態系統是n8n能夠適應不斷變化的需求和技術挑戰的重要保障。 ?
-
持續優化: 隨著數據源的變化、API接口的更新以及自身需求的發展,自動化工作流需要持續的監控、調試和優化。用戶應定期檢查工作流的執行日志,關注社區動態,并根據實際運行情況調整配置和邏輯,以確保系統能夠長期穩定、高效地運行,并適應新的挑戰。


之使用教程(3)配置)
——表結構介紹)









)

)
IO流:數據洪流中的航道設計)

)
)