溫馨提示:
本篇文章已同步至"AI專題精講" ViLT: 無卷積或區域監督的視覺-語言Transformer
摘要
視覺與語言預訓練(Vision-and-Language Pre-training, VLP)在多種聯合視覺與語言的下游任務中顯著提升了性能。目前的 VLP 方法在很大程度上依賴圖像特征提取過程,其中大多數涉及區域監督(例如,目標檢測)以及卷積結構(例如 ResNet)。盡管這一點在文獻中常被忽視,我們發現這在以下兩個方面存在問題:(1)效率/速度:僅提取輸入特征的計算開銷遠大于多模態交互步驟;(2)表達能力:受限于視覺嵌入器及其預定義視覺詞匯的表達上限。
本文提出了一種極簡的 VLP 模型——ViLT(Vision-and-Language Transformer),其特點是處理視覺輸入的方式被極大簡化,與處理文本輸入相同,完全不依賴卷積結構。我們展示了 ViLT 相比以往 VLP 模型的速度提升高達數十倍,同時在下游任務上仍保持競爭力甚至更優的性能。
我們的代碼與預訓練模型已開放獲取:https://github.com/dandelin/vilt。
1. 引言
預訓練-微調(pre-train-and-fine-tune)方案已經擴展到了視覺與語言的聯合領域,從而催生了視覺與語言預訓練(VLP)模型(Lu et al., 2019; Chen et al., 2019; Su et al., 2019; Li et al., 2019; Tan & Bansal, 2019; Li et al., 2020a; Lu et al., 2020; Cho et al., 2020; Qi et al., 2020; Zhou et al., 2020; Huang et al., 2020; Li et al., 2020b; Gan et al., 2020; Yu et al., 2020; Zhang et al., 2021)。這些模型通常使用圖文匹配(Image-Text Matching)和掩碼語言建模(Masked Language Modeling)作為預訓練目標,在圖像及其對齊的描述上進行訓練,并在輸入包含兩種模態的下游視覺-語言任務上進行微調。
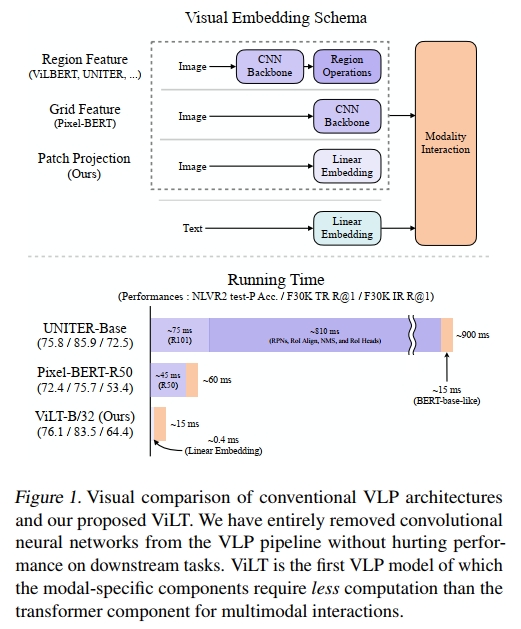
為了輸入到 VLP 模型,圖像像素需要與語言標記一起以密集形式進行嵌入。自從 Krizhevsky 等人(2012)的開創性工作以來,深度卷積網絡一直被視為該視覺嵌入步驟的核心。大多數 VLP 模型使用在 Visual Genome 數據集(Krizna et al., 2017)上預訓練的目標檢測器,后者標注了 1,600 個物體類別和 400 個屬性類別,如 Anderson 等人(2018)所示。PixelBERT(Huang 等人,2020)是這一趨勢的一個例外,它使用在 ImageNet 分類任務(Russakovsky 等人,2015)上預訓練的 ResNet 變種(He 等人,2016;Xie 等人,2017),將像素直接嵌入,而不是采用目標檢測模塊。
迄今為止,大多數 VLP 研究集中在通過增強視覺嵌入器的能力來提高性能。由于區域特征通常在訓練時提前緩存,以減輕特征提取的負擔,因此學術實驗中往往忽視了使用重型視覺嵌入器的缺點。然而,這些限制在實際應用中仍然顯而易見,因為現實中的查詢必須經過一個緩慢的提取過程。
為此,我們將注意力轉向輕量級且快速的視覺輸入嵌入。最近的研究(Dosovitskiy 等人,2020;Touvron 等人,2020)表明,使用簡單的線性投影來處理圖像塊足以在將其輸入到變換器之前進行像素嵌入。盡管變換器(Vaswani 等人,2017)已經成為文本處理的主流(Devlin 等人,2019),但直到最近,變換器才開始應用于圖像。我們假設,變換器模塊——在 VLP 模型中用于模態交互——也能夠代替卷積視覺嵌入器處理視覺特征,就像它處理文本特征一樣。
本文提出了視覺與語言變換器(ViLT),它以統一的方式處理兩種模態。與之前的 VLP 模型不同,它通過淺層、無卷積的方式來嵌入像素級輸入。去除專門處理視覺輸入的深層嵌入器,顯著減少了模型的規模和運行時間。圖 1 顯示,我們的參數高效模型比使用區域特征的 VLP 模型快數十倍,且至少比使用網格特征的模型快四倍,同時在視覺與語言下游任務中展現出相似甚至更好的性能。
我們的關鍵貢獻總結如下:
- ViLT 是迄今為止最簡潔的視覺與語言模型架構,它通過委托變換器模塊來提取和處理視覺特征,而不是使用單獨的深層視覺嵌入器。這一設計天然地帶來了顯著的運行時和參數效率。
- 首次,我們在沒有使用區域特征或深度卷積視覺嵌入器的情況下,成功地在視覺與語言任務上取得了競爭力的性能。
- 首次,我們通過實驗證明,VLP 訓練方案中前所未有的整體詞掩碼和圖像增強方法,進一步推動了下游任務的性能提升。
2. 背景
2.1 視覺與語言模型的分類
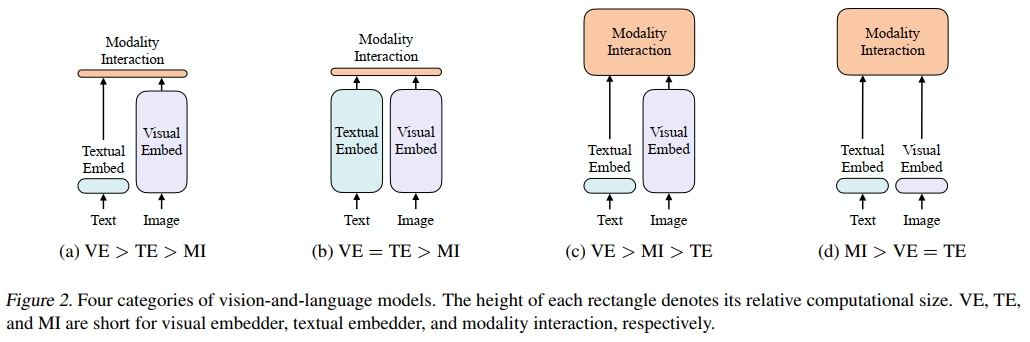
我們提出了一種基于以下兩個方面的視覺與語言模型分類法:
(1) 兩種模態是否在專門的參數和/或計算方面具有相等的表達能力;
(2) 兩種模態是否在深度網絡中進行交互。
這兩點的組合導致了圖 2 中的四種原型。
視覺語義嵌入(VSE)模型,如 VSE++(Faghri 等人,2017)和 SCAN(Lee 等人,2018),屬于圖 2a 類別。它們使用分別的圖像和文本嵌入器,其中圖像嵌入器通常更重。然后,它們通過簡單的點積或淺層注意力層來表示兩種模態的嵌入特征之間的相似性。
CLIP(Radford 等人,2021)屬于圖 2b 類別,因為它為每種模態使用了分別但同樣昂貴的變換器嵌入器。盡管圖像和文本向量的交互仍然較為淺顯(通過點積),CLIP 在圖像到文本檢索的零樣本性能上取得了顯著成績,但我們在其他視覺與語言下游任務上未能觀察到相同的性能水平。例如,使用 CLIP 從圖像和文本中提取的點積融合向量作為多模態表示,再對 NLVR2(Suhr 等人,2018)進行微調,得到了低開發集準確率 50.99 ± 0.38(使用了三種不同的隨機種子);由于機會水平的準確率為 0.5,我們得出結論認為這些表示無法學習這個任務。這與 Suhr 等人(2018)的發現一致,即所有僅通過簡單融合多模態表示的模型都未能學習 NLVR2。
這一結果支持了我們的推測,即即使是來自高性能單模態嵌入器的簡單融合輸出也可能不足以學習復雜的視覺與語言任務,進一步強調了需要一種更嚴格的模態交互方案。
與淺層交互模型不同,最近的 VLP 模型(圖 2c 類別)使用深度變換器來建模圖像和文本特征的交互。然而,除了交互模塊外,這些模型仍然需要卷積網絡來提取和嵌入圖像特征,這占用了大部分計算量,如圖 1 所示。基于調制的視覺與語言模型(Perez 等人,2018;Nguyen 等人,2020)也屬于圖 2c 類別,它們的視覺 CNN 核心對應視覺嵌入器,RNN 生成用于文本嵌入器的調制參數,調制后的 CNN 用于模態交互。
我們提出的 ViLT 是圖 2d 類別中的第一個模型,它的原始像素嵌入層與文本標記一樣淺且計算輕量。這種架構將大部分計算集中在建模模態交互上。
2.2 模態交互方案
當代 VLP 模型的核心是變換器。它們將視覺和文本嵌入序列作為輸入,在各層中建模模態間和可選的模態內交互,然后輸出上下文化的特征序列。
Bugliarello 等人(2020)將交互方案分為兩類:
(1) 單流方法(例如,VisualBERT(Li 等人,2019)、UNITER(Chen 等人,2019)),在這些方法中,各層共同作用于圖像和文本輸入的連接;
(2) 雙流方法(例如,ViLBERT(Lu 等人,2019)、LXMERT(Tan & Bansal,2019)),在這些方法中,兩種模態在輸入層級上并不連接。我們為我們的交互變換器模塊選擇了單流方法,因為雙流方法會引入額外的參數。
2.3 視覺嵌入方案
盡管所有高性能的 VLP 模型都共享來自預訓練 BERT 的相同文本嵌入器——包括詞匯和位置嵌入,這些嵌入與 BERT 類似——但它們在視覺嵌入器上有所不同。然而,在大多數(如果不是所有)情況下,視覺嵌入是現有 VLP 模型的瓶頸。我們通過引入補丁投影來簡化這一過程,而不是使用需要重型提取模塊的區域或網格特征。
區域特征
VLP 模型主要使用區域特征,也稱為自下而上的特征(Anderson 等人,2018)。這些特征是通過現成的物體檢測器(如 Faster R-CNN(Ren 等人,2016))獲得的。
生成區域特征的一般流程如下。首先,區域提議網絡(RPN)基于從 CNN 主干池化得到的網格特征提出興趣區域(RoI)。然后,非最大抑制(NMS)減少 RoI 的數量,最終只有幾千個。經過如 RoI Align(He 等人,2017)等操作池化后,RoI 通過 RoI 頭并變為區域特征。NMS 再次應用于每個類別,最終將特征數減少到一百個以內。
上述過程涉及幾個影響性能和運行時間的因素:主干網絡、NMS 風格、RoI 頭。先前的研究在控制這些因素時較為寬松,各自的選擇存在差異,如表 7.2 所示:
- 主干網絡:ResNet-101(Lu 等人,2019;Tan & Bansal,2019;Su 等人,2019)和 ResNext-152(Li 等人,2019;2020a;Zhang 等人,2021)是兩種常用的主干網絡。
- NMS:NMS 通常是按類別進行的。對每個類別應用 NMS 會在類別數量較多時成為主要的運行時瓶頸,例如在 VG 數據集中有 1.6K 類(Jiang 等人,2020)。最近引入了類別無關 NMS 來解決這一問題(Zhang 等人,2021)。
- RoI 頭:最初使用的是 C4 頭(Anderson 等人,2018),后來引入了 FPN-MLP 頭(Jiang 等人,2018)。由于頭部操作針對每個 RoI,因此它們會對運行時帶來較大的負擔。
然而,盡管物體檢測器比較輕量,但它們的速度不太可能超過主干網絡或單層卷積。凍結視覺主干并提前緩存區域特征僅在訓練時有幫助,而在推理時并無用處,此外,這可能會限制性能。
網格特征
除了檢測頭外,卷積神經網絡(如 ResNets)的輸出特征網格也可以作為視覺特征,用于視覺與語言預訓練。直接使用網格特征最早由 VQA 特定的模型提出(Jiang 等人,2020;Nguyen 等人,2020),主要目的是避免使用非常緩慢的區域選擇操作。
X-LXMERT(Cho 等人,2020)通過將區域提議固定為網格,而不是來自區域提議網絡的區域,再次審視了網格特征。然而,它們的特征緩存排除了對主干的進一步調整。
Pixel-BERT 是唯一一種將 VG 預訓練的物體檢測器替換為基于 ImageNet 分類預訓練的 ResNet 變體主干的 VLP 模型。與基于區域特征的 VLP 模型中凍結的檢測器不同,Pixel-BERT 的主干在視覺與語言預訓練期間會進行調整。盡管 Pixel-BERT 使用 ResNet-50 的下游性能低于基于區域特征的 VLP 模型,但在使用更重的 ResNeXt-152 時,其性能與其他競爭模型相當。
然而,我們認為網格特征并不是首選,因為深度 CNN 仍然較為昂貴,它們占用了大量計算資源,如圖 1 所示。
補丁投影
為了最小化開銷,我們采用了最簡單的視覺嵌入方案:對圖像補丁進行線性投影。補丁投影嵌入由 ViT(Dosovitskiy 等人,2020)為圖像分類任務引入。補丁投影將視覺嵌入步驟極大簡化,達到了與文本嵌入相同的簡單投影(查找)操作級別。我們使用的 32 × 32 補丁投影僅需 2.4M 參數。這與復雜的 ResNe(X)t 主干和檢測組件相比有很大差異。其運行時間也可以忽略不計,如圖 1 所示。我們將在第 4.6 節進行詳細的運行時分析。
3. 視覺與語言變換器
3.1. 模型概述
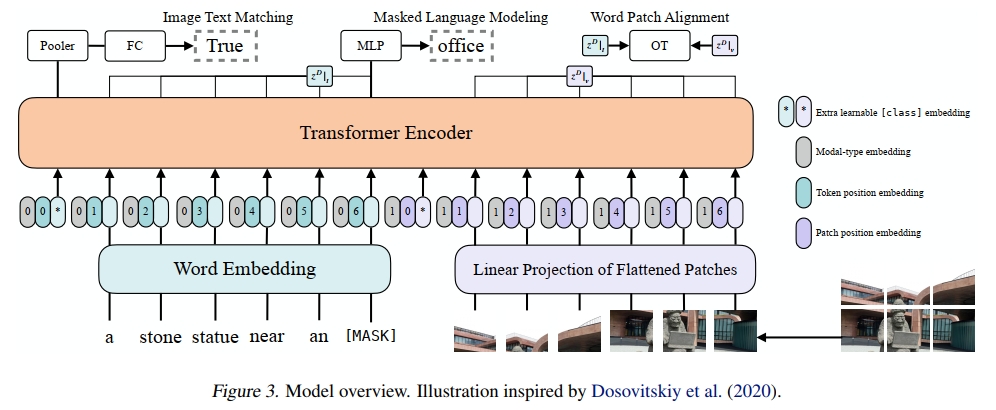
ViLT 作為一個 VLP 模型,具有簡潔的架構,采用最小化的視覺嵌入管道,并遵循單流架構。我們與文獻中的做法有所不同,選擇將交互變換器的權重從預訓練的 ViT 初始化,而非 BERT。這種初始化方式利用了交互層處理視覺特征的能力,同時避免了使用單獨的深度視覺嵌入器。
tˉ=[tclass;t1T;?;tLT]+Tpos(1)\bar { t } = [ t _ { \mathrm { c l a s s } } ; t _ { 1 } T ; \cdots ; t _ { L } T ] + T ^ { \mathrm { p o s } }\quad(1) tˉ=[tclass?;t1?T;?;tL?T]+Tpos(1)
vˉ=[vclass;v1V;?;vNV]+Vpos(2)\bar { v } = [ v _ { \mathrm { c l a s s } } ; v _ { 1 } V ; \cdots ; v _ { N } V ] + V ^ { \mathrm { p o s } }\quad(2) vˉ=[vclass?;v1?V;?;vN?V]+Vpos(2)
z0=[tˉ+ttype;vˉ+vtype](3)z ^ { 0 } = [ \bar { t } + t ^ { \mathrm { { t y p e } } } ; \bar { v } + v ^ { \mathrm { { t y p e } } } ]\quad(3) z0=[tˉ+ttype;vˉ+vtype](3)
z^d=MSA(LN(zd?1))+zd?1,d=1…D(4)\hat { z } ^ { d } = \mathbf { M } \mathbf { S } \mathbf { A } ( \mathbf { L } \mathbf { N } ( z ^ { d - 1 } ) ) + z ^ { d - 1 } , \qquad d = 1 \ldots D\quad(4) z^d=MSA(LN(zd?1))+zd?1,d=1…D(4)
zd=MLP(LN(z^d))+z^d,d=1???D(5)z ^ { d } = \mathrm { M L P } ( \mathrm { L N } ( \hat { z } ^ { d } ) ) + \hat { z } ^ { d } , \qquad \qquad d = 1 \cdot \cdot \cdot D\quad(5) zd=MLP(LN(z^d))+z^d,d=1???D(5)
p=tanh?(z0DWpool)(6)p = \operatorname { t a n h } ( z _ { 0 } ^ { D } W _ { \mathrm { p o o l } } )\quad(6) p=tanh(z0D?Wpool?)(6)
ViT 由堆疊的塊組成,每個塊包含一個多頭自注意力(MSA)層和一個 MLP 層。ViT 和 BERT 唯一的區別在于層歸一化(LN)的位置:在 BERT 中,LN 位于 MSA 和 MLP 之后(“post-norm”);而在 ViT 中,LN 位于 MSA 和 MLP 之前(“pre-norm”)。輸入文本 t∈RL×∣V∣t \in \mathbb{R}^{L \times |V|}t∈RL×∣V∣ 通過詞嵌入矩陣 T∈R∣V∣×HT \in \mathbb{R}^{|V| \times H}T∈R∣V∣×H 和位置嵌入矩陣 Tpos∈R(L+1)×HT_{pos} \in \mathbb{R}^{(L+1) \times H}Tpos?∈R(L+1)×H 被嵌入為 tˉ∈RL×H\bar{t} \in \mathbb{R}^{L \times H}tˉ∈RL×H。
輸入圖像 I∈RC×H×WI \in \mathbb{R}^{C \times H \times W}I∈RC×H×W 被切割成圖像塊并展平為 v∈RN×(P2?C)v \in \mathbb{R}^{N \times (P^2 \cdot C)}v∈RN×(P2?C),其中 (P,P)(P, P)(P,P) 是圖像塊的分辨率,N=HWP2N = \frac{HW}{P^2}N=P2HW?。然后通過線性投影 V∈R(P2?C)×HV \in \mathbb{R}^{(P^2 \cdot C) \times H}V∈R(P2?C)×H 和位置嵌入 Vpos∈R(N+1)×HV_{pos} \in \mathbb{R}^{(N+1) \times H}Vpos?∈R(N+1)×H,vvv 被嵌入為 vˉ∈RN×H\bar{v} \in \mathbb{R}^{N \times H}vˉ∈RN×H。
文本和圖像的嵌入通過各自的模態類型嵌入向量 ttype,vtype∈RHt_{type}, v_{type} \in \mathbb{R}^Httype?,vtype?∈RH 相加,然后合并為一個序列 z0z_0z0?。這個上下文化的向量 zzz 通過 D 層變換器迭代更新,直到最終的上下文化序列 zDz^DzD。ppp 是整個多模態輸入的池化表示,通過對序列 zDz^DzD 的第一個索引應用線性投影 Wpool∈RH×HW_{pool} \in \mathbb{R}^{H \times H}Wpool?∈RH×H 和雙曲正切激活函數得到。
在所有實驗中,我們使用在 ImageNet 上預訓練的 ViT-B/32 權重,因此稱之為 ViLT-B/32。隱藏層大小 HHH 為 768,層深度 DDD 為 12,圖像塊大小 PPP 為 32,MLP 大小為 3,072,注意力頭的數量為 12。
3.2. 預訓練目標
我們使用兩種常見的目標來訓練 ViLT:圖像-文本匹配(ITM)和掩蔽語言建模(MLM)。
圖像-文本匹配 (ITM)
我們以 0.5 的概率隨機將對齊的圖像替換為不同的圖像。一個線性層 ITM 頭將池化后的輸出特征 pp 投影到二分類的 logits 上,然后我們計算負對數似然損失作為 ITM 損失。
此外,受到 Chen 等人(2019)中詞區域對齊目標的啟發,我們設計了詞圖像塊對齊(WPA),計算兩個子集 zDz_DzD? 的對齊分數:zD∣tz ^ { D } | _ { t }zD∣t?(文本子集)和 zD∣vz ^ { D } | _ { v }zD∣v?(視覺子集),使用不精確近點方法(IPOT)進行最優傳輸(Xie 等,2020)。我們根據 Chen 等人(2019)設置了 IPOT 的超參數(β=0.5,N=50β=0.5,N = 50β=0.5,N=50),并將近似 Wasserstein 距離乘以 0.1 加到 ITM 損失中。
溫馨提示:
閱讀全文請訪問"AI深語解構" ViLT: 無卷積或區域監督的視覺-語言Transformer



)
)



)
的隨機訪問)



![[特殊字符] GitHub 2025年7月月度精選項目 Top5](http://pic.xiahunao.cn/[特殊字符] GitHub 2025年7月月度精選項目 Top5)





