為什么要有消息隊列
生活中有這樣的場景

快遞員將包裹送給買家。
我記得在小時候,收快遞是需要快遞員電話聯系上門時間的。這非常不方便,一方面快遞員手中可能有多個包裹,另一方面買家可能在上班時間抽不出身。
后來有了驛站,快遞員只需要將包裹放入驛站,并通知買家按時取走。這種模式便捷了快遞員和買家雙方。
驛站的作用類似于“中間件”,它的出現有這些好處
1.解耦系統組件
快遞員和收貨人無需接觸也能完成事件,解放了快遞員和收貨人的時間。
2.異步處理
異步允許事情獨立發生,相互之間不需要等待對方完成。快遞員不需要詢問收貨人是否在家,收貨人不需要等待快遞員上門。
3.流量削峰
收貨人不用面對多個快遞同時抵達在不同位置的尷尬情況。
4.失敗重試與可靠性
允許收貨人因特殊原因當天無法取件(處理失敗),驛站可以將包裹保留幾日。
消息隊列通信的模式
上面的例子中引出了“中間件”的概念,驛站就類似于消息隊列,但消息隊列有不同模式。
兩種模式
1.點對點模式
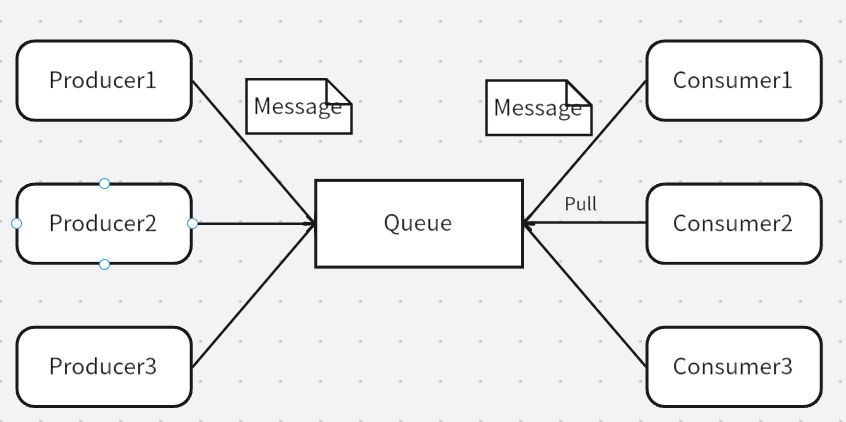
Producer將Message放于Queue中,Consumer從中拉取信息。該模式下,發送到隊列的消息被一個且只有一個消費者進行處理,消費者主動拉取消息的好處是頻率可控,弊端是消費者不知是否有未處理的信息。
2.發布-訂閱模式
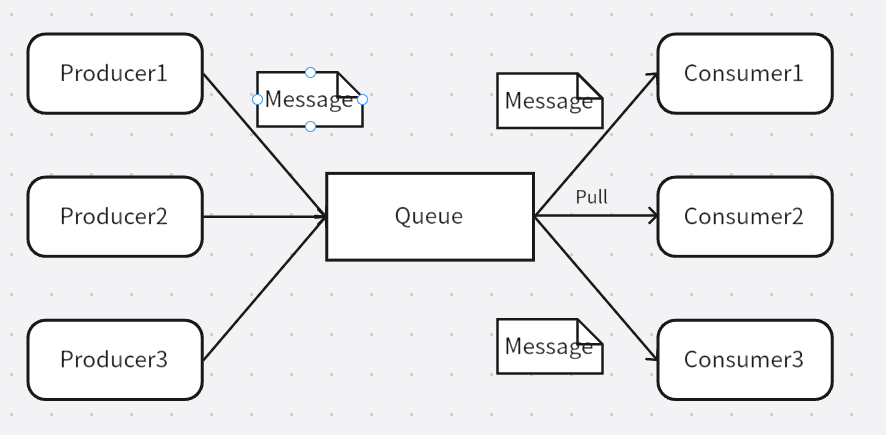
該模式類似于公眾號,新消息發送給所有關注的用戶。消費者無需考慮是否有未處理的消息。弊端是消費者之間性能的差異帶來的木桶效應,如Consumer1的處理速度為10,而Consumer2的處理速度為3,最后的推送速度只能小于3。但這極大浪費了Cinsumer1的性能。
Kafka
Kafka 本質上是一個 基于發布/訂閱模型 的消息系統。作為一種高吞吐、可水平擴展、持久化、分布式提交日志服務。要想理解Kafka我們要先知道其基礎架構及術語。
基礎架構及術語
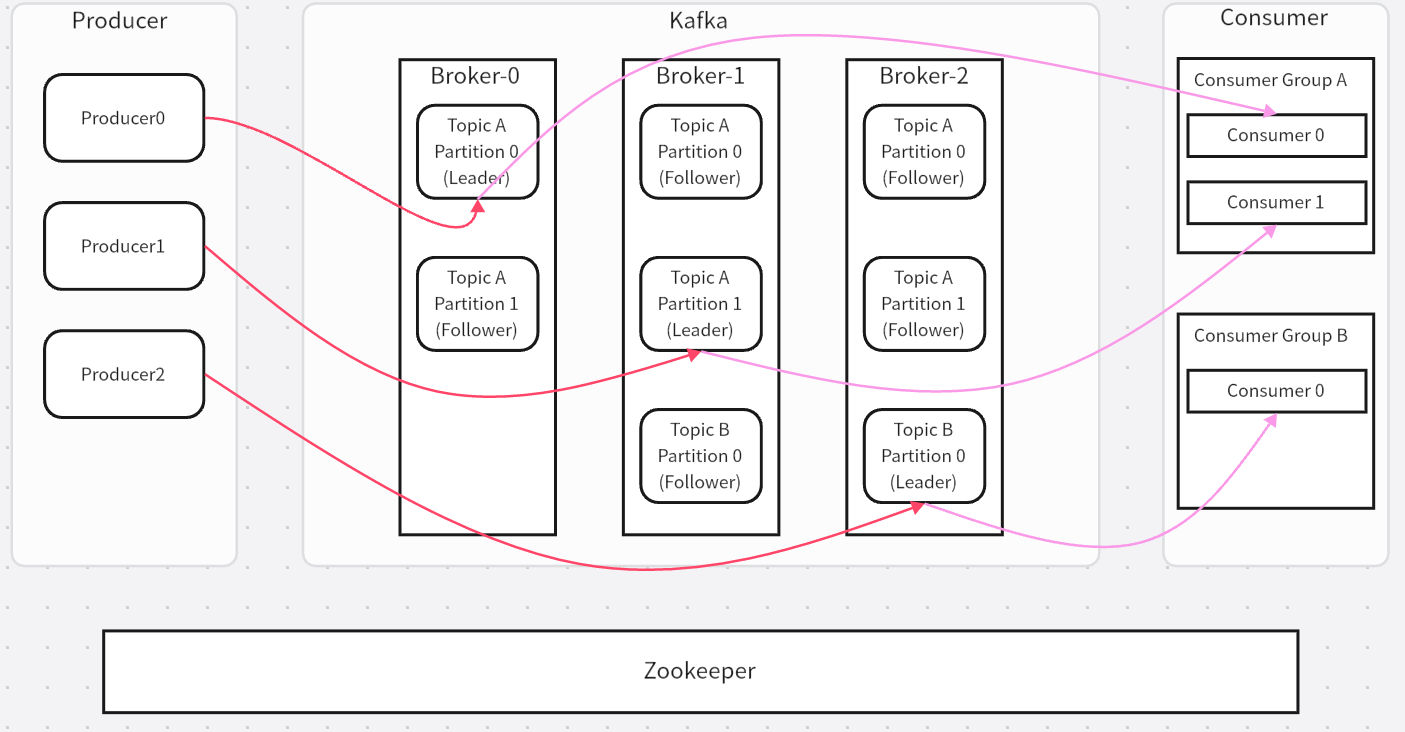
Broker
Broker是Kafka中的單個服務器節點,一個Kafka可以包含多個Broker,多個Broker組成Kafka集群。每個Broker都可以處理一部分數據(消息的接收、存儲、傳輸)
Topic
消息的邏輯類別或數據流名稱。對消息進行分類和組織,可以把它想象成文件夾名稱。
Partition
是Topic的分區,一個Topic可能有多個分區。Partition 是 Kafka 實現并行處理和高吞吐的關鍵。生產者和消費者可以并行地與多個 Partition 交互。
Replica
Partition 的副本。每個 Partition 可以有多個 Replica,分布在不同的Broker上,用于容錯。
Leader Replica/Follower Replica
每個 Partition 在某一時刻只有一個 Leader。所有針對該 Partition 的讀寫請求(生產和消費)都必須由 Leader 處理。
從 Leader Replica 復制數據。如果 Leader 失效,其中一個 Follower 會被選舉為新的 Leader。
In-Sync Replica (ISR)
指那些與 Leader Replica 保持足夠同步的 Replica 集合(包括 Leader 自身)。只有 ISR 中的 Follower 才有資格在 Leader 失效時被選舉為新的 Leader。
Producer
向 Kafka Topic 發布消息的客戶端應用程序,即是生產者,是消息的入口。
Consumer
從 Kafka Topic 訂閱并讀取消息的客戶端應用程序,即是消費者,是消息的出口。
Consumer Group
將多個消費組組成一個消費者組。同一個分區的數據只能被消費者組中某一個用戶消費,同一個消費者組的消費者可以在同一個Topic上消費不同分區(并行)。
ZooKeeper
Kafka 集群依賴 ZooKeeper 集群來存儲和管理關鍵的元數據。
流程分析
發送數據
寫入數據時,Producer先找到Leader,將數據寫入Leader。這個過程展開來說如此:
1.將消息發給Leader
2.Leader寫入數據
3.Follower同步Leader的消息
4.Follower發送ack表示同步完成
5.Leader收到所有Follwer的ack后向Producer發送ack,表示過程結束
ack是什么?
acks(Acknowledgments)是生產者(Producer)配置的核心參數之一,用于控制消息寫入的可靠性級別。 它決定了生產者認為消息“成功發送”之前,需要多少個分區副本(Replica)確認收到該消息。
通常ack有三種配置:0、1、all
0代表不等待確認,生產者發送消息后立即認為成功,不等待Broker回應。可靠性最低但效率最高。
1代表Leader確認,生產者等待Leader將消息寫入本地。可靠性和效率都是中等。
all代表全副本確認,等待ISR中所有副本都成功寫入消息。可靠性最高但效率最低。
保存數據
Kafka會單獨開辟一塊磁盤空間,順序寫入數據。
Partition 結構
每個 Partition 是一個 追加寫入的日志文件(Append-only Log),存儲在磁盤上。Kafka 使用日志文件來持久化消息,每個 Partition 對應一個目錄,目錄下包含多個日志文件(Segment)。
<topic-name>-<partition-id>/
├── 00000000000000000000.index
├── 00000000000000000000.log
├── 00000000000000000000.timeindex
├── 00000000000000000001.index
├── 00000000000000000001.log
├── 00000000000000000001.timeindex
└── ...
Partition 的選擇策略
當生產者發送消息到某個 Topic 時,Kafka 會根據以下策略選擇將消息寫入哪個 Partition:
1.指定 Partition:生產者可以顯式指定 Partition
2.Key Hash:如果消息有 Key,則默認使用 Key 的 Hash 值取模 Partition 數量
3.輪詢:沒有 Key 時,默認輪詢方式分配 Partition
數據保留策略
Kafka可以通過配置來設置數據的保留策略,包括基于時間的保留(如7天)和基于大小的保留(如1GB)。一旦數據超過了這些限制,就會被刪除以釋放空間。
消費數據
Kafka支持點對點和發布訂閱兩種模式。當單個消費者時,采取類似點對點模式;消費群組時,采用發布訂閱模式。
前文提到過多個消費者組成的消費者組,每個消費者組有其獨特的編號,同一個消費者組的消費者可以消費同一Topic下不同分區的數據,但是不會組內多個消費者消費同一分區的數據。
如果消費者數量和分區數量不一致:
消費者數量<分區數量 —— 有的消費者會消費多個分區,效率低于消化單個分區的消費者
消費者數量>分區數量 —— 多出來的消費者不消化數據
查找數據
Kafka 的查找數據過程是其高性能和高吞吐量的核心機制之一。Kafka 通過稀疏索引、日志段(Log Segment) 和 二分查找算法 實現高效的數據檢索。
Kafka查找數據過程分為兩個主要步驟:
- 定位目標日志段(Log Segment)
- 在日志段中查找具體消息
定位日志段
是 Kafka 存儲消息的基本單元,每個 Partition 被劃分為多個日志段(00000000000000000000.log 和 00000000000000000099.log)。
第一個日志段的起始偏移量為 0,后續日志段的起始偏移量為上一個日志段的最后一條消息的 offset。
Kafka使用二分查找算法在日志段列表中定位目標。
offset
即是偏移量,用于標識消息在 Kafka 分區(Partition)中的唯一位置。它是 Kafka 實現消息順序性、消費進度追蹤和數據可靠性管理的關鍵機制。
它有如下作用:
1.標識消息在分區中的位置
2.保證消息在分區內有序性
3.跟蹤消費者的消費進度
查找具體消息
Kafka 的每個日志段包含兩個關鍵文件:.log 文件 和.index 文件(稀疏索引)
稀疏索引:每隔一定字節數(默認 4KB)為一條消息創建索引項。如1、2、3、4、5… ——> 1、3、5…
整體流程概括為:稀疏索引 + 二分查找 + 順序寫入 + 內存映射
















自用)


