NC 2025 | 一種基于端到端注意力機制的圖學習方法
Nature Communications IF=15.7 綜合性期刊 1區

參考:https://mp.weixin.qq.com/s/cZ-d8Sf8wtQ9wfcGOFimCg
今天介紹一篇發表在 Nature Communications 的圖學習論文《An end-to-end attention-based approach for learning on graphs》。該工作提出了一種全新范式的圖學習方法 ESA(Edge-Set Attention),不再依賴傳統的節點消息傳遞機制,而是將圖建模為邊集合,并通過純注意力機制進行信息交互。該方法無需結構先驗和位置編碼,模型結構簡潔卻具備強表達力,在70項圖與節點任務中大幅超越GNN與圖Transformer,展現出優異的性能、魯棒性與遷移能力,是一項值得關注的圖學習基礎模型探索工作。
摘要:
近年來,基于 Transformer 的圖學習架構迅速興起,主要受到注意力機制作為高效學習方法的推動,以及希望取代消息傳遞機制中手工設計算子的需求。然而,也有研究對這些方法在實際效果、可擴展性以及預處理步驟的復雜性方面提出質疑,尤其是相較于那些結構更簡單、但在各種基準測試中表現相當的圖神經網絡(GNNs)。
為了解決這些問題,我們將圖視為一組邊,提出了一種純粹基于注意力機制的方法,由編碼器和注意力池化模塊組成。編碼器交替使用掩蔽和標準的自注意力模塊,能夠有效地學習邊的表示,并應對輸入圖中可能存在的不規范結構。
盡管方法結構簡單,我們的方法在70多個節點級和圖級任務上(包括具有挑戰性的長距離依賴任務)均超越了經過精調的消息傳遞模型和近期提出的 Transformer 方法。此外,我們在多個任務上取得了當前最先進的性能,涵蓋了從分子圖到視覺圖,以及異質圖節點分類等不同類型任務。
在遷移學習任務中,該方法也優于主流的圖神經網0絡和 Transformer,并且在保持相似性能或表達能力的同時,具備更強的可擴展性。
Introduction
我們從實證角度出發,研究了一種純基于注意力機制的方法在學習圖結構數據有效表示方面的潛力。傳統上,圖上的學習通常采用“消息傳遞”(message passing)框架建模,它是0.
一種迭代過程,依賴于消息函數來聚合一個節點鄰居的信息,并利用更新函數將編碼后的消息整合到節點的輸出表示中。生成的圖神經網絡(GNN)通常會堆疊多個這樣的層,以基于節點為根的子樹結構學習節點表示,這一過程本質上模仿了一維 Weisfeiler-Lehman(1-WL)圖同構判別測試 [wl79, wlneural24]。消息傳遞的變種已被成功應用于多個領域,如生命科學 [STOKES2020688, Wong2023 等]、電氣工程 [Chien2024] 和天氣預測 [doi:10.1126/science.adi2336]。
盡管圖神經網絡(GNN)在實踐中取得了廣泛成功和廣泛應用,但隨著時間推移,人們也發現了其若干實際挑戰。盡管消息傳遞框架具有很高的靈活性,設計新的 GNN 層仍是一項具有挑戰性的研究問題,通常需要多年才能實現改進,并常常依賴于手工設計的算子。這種情況在不利用其他輸入模態(例如原子坐標)的通用圖神經網絡中尤為明顯。例如,主鄰域聚合(PNA)被認為是最強大的消息傳遞層之一,但它是通過一組手動選擇的鄰域聚合函數構建的,并且需要預先計算數據集的度直方圖,還使用了手動設定的度縮放因子。
消息傳遞機制的本質也帶來了一些限制,這些限制在現有文獻中占據主導地位。其中一個最突出的例子是 readout 函數,它被用于將節點級特征匯聚成圖級表示,并且要求對節點順序具備置換不變性。 因此,在 GNN 和圖 Transformer 中,默認的 readout 函數通常是簡單且不可學習的函數,例如 sum(求和)、mean(平均)或 max(最大值)。Wagstaff 等人指出,這種方法存在局限性,簡單的 readout 函數可能需要復雜的項嵌入函數,而這些函數難以用標準神經網絡學習得到。
此外,圖神經網絡在“過平滑”(over-smoothing)和“過壓縮”(over-squashing)方面也表現出一定的局限性。“過平滑”是指隨著網絡層數增加,節點表示變得越來越相似,進而降低模型在異質圖節點分類任務中的性能。 有研究假設這源于 GNN 表現得像低通濾波器。近期,Di Giovanni 等人通過研究圖上的梯度流,進一步表明某些時間連續的 GNN 確實受到低頻成分的主導。
相對的,“過銳化”(over-sharpening)也被觀察到,尤其是在使用線性圖卷積和對稱權重的情形中,這是由權重矩陣負特征值所引起的“排斥”效應導致的。而“過壓縮”則會在需要遠距離節點信息的預測任務中影響性能,這被歸因于圖結構中的瓶頸邊,即當 k 值(k-hop)或網絡層數增加時,k 鄰域的數量迅速增加。Topping 等人對“過壓縮”進行了理論刻畫,并引入了圖曲率的概念來量化該問題,同時提出了一種圖重構算法——隨機離散 Ricci 流(stochastic discrete Ricci flow),用于緩解這些瓶頸效應。
針對上述兩個問題,研究者提出了一些替代方案,主要是基于消息正則化(message regularisation)的方法,例如 Simple Graph Convolution、PairNorm 和 GraphNorm 等。
然而,目前尚無公認的最佳架構選擇可以用來構建有效的深度消息傳遞神經網絡,也無法同時有效地解決這些挑戰。此外,與大型語言模型不同,圖神經網絡中遷移學習、預訓練和微調等策略的效果有限或存在爭議,因此使用并不廣泛。
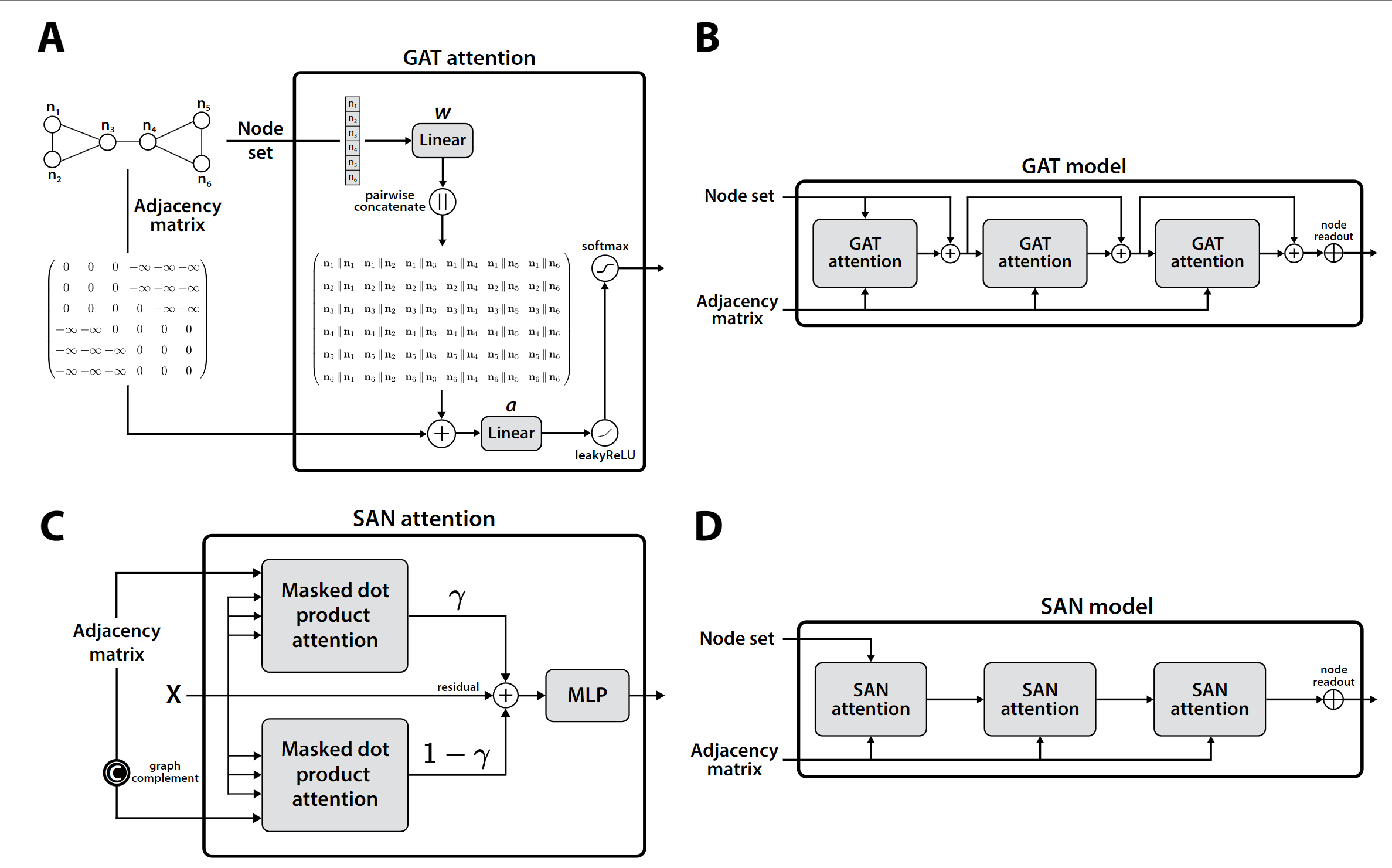
圖


」2025年7月4日)








|SVM-拉格朗日函數構造)

-day24)

)



