目錄
1、GPT的模型結構如圖所示
2、介紹GPT自監督預訓練、有監督下游任務微調及預訓練語言模型
2.1、GPT 自監督預訓練
2.1.1、 輸入編碼:詞向量與位置向量的融合
2.1.1.1、 輸入序列與詞表映射
2.1.1.2、?詞向量矩陣與查表操作
3. 位置向量矩陣
4. 詞向量與位置向量疊加
5. 最終輸入向量
2.1.2、?Masked 多頭注意力:禁止 “偷看” 未來信息
2.1.3、?損失函數:優化預測概率
2.2 有監督下游任務微調
2.2.1、 任務適配:從文本到標簽的映射
2.2.2、組合損失:平衡任務與預訓練知識
2.3 預訓練語言模型
2.3.1、?結構差異:從 “專用設計” 到 “通用基座”
2.3.2、 能力邊界:生成 vs 理解
3、模型驗證
3.1、?GPT 模型全流程
3.2、GPT 核心邏輯突出:
4、完整實現
4.1、完整代碼
4.2、實驗結果?
4.3、代碼“活起來”
一、準備數據集:給機器人找 “課本”
二、訓練詞元分析器:給機器人編 “字典”
三、預處理數據集:把 “課本” 翻譯成 “機器人能懂的語言”
四、訓練模型:教機器人 “學規律”
五、運用模型:讓機器人 “說句話試試”
總結:整個流程就像 “教小孩學說話”
?
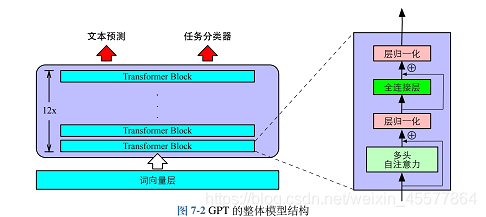
1、GPT的模型結構如圖所示
它是由多層Transformer組陳的單向語言模型,主要分為輸入層、編碼層和輸出層三個部分:?
2、介紹GPT自監督預訓練、有監督下游任務微調及預訓練語言模型
2.1、GPT 自監督預訓練
GPT 預訓練的核心是基于 Transformer Decoder 的因果語言建模,其計算過程可通過具體示例拆解為 “輸入編碼 - 注意力計算 - 損失優化” 三步驟。
2.1.1、 輸入編碼:詞向量與位置向量的融合
公式描述了輸入編碼過程,用示例說明:
- 假設輸入序列為 “貓吃魚”,分詞后為 3 個 token:x' = [貓, 吃, 魚];
- 詞向量查表:e_{貓}通過詞向量矩陣
(假設維度為 3×5)映射為向量
,同理 “吃”“魚” 分別映射為
和
;
- 位置向量疊加:位置 1(貓)的向量
,位置 2(吃)為
,疊加后
的第一個向量為
。
2.1.1.1、 輸入序列與詞表映射
假設我們有一個簡單的詞表,包含 3 個詞:
?詞表 = {"貓": 0, "吃": 1, "魚": 2}輸入文本 "貓吃魚" 被分詞為 3 個 token,對應的詞表索引為:
?x' = [0, 1, 2]2.1.1.2、?詞向量矩陣與查表操作
詞向量矩陣

查表過程:
- 對于 token "貓"(索引 0),其詞向量為
- 同理,"吃" 的詞向量為
- "魚" 的詞向量為
3. 位置向量矩陣
位置向量用于表示 token 在序列中的位置信息。假設位置向量維度同樣為 5,則 3 個位置的向量分別為:

4. 詞向量與位置向量疊加
根據公式
?,對每個 token 的詞向量和對應位置向量進行疊加:
第一個 token "貓"(位置 1):

第二個 token "吃"(位置 2):

第三個 token "魚"(位置 3):

5. 最終輸入向量
將上述三個疊加后的向量組合,得到最終輸入到 Transformer 的向量\(h^{[0]}\):
2.1.2、?Masked 多頭注意力:禁止 “偷看” 未來信息
文章詳細描述了掩碼注意力的計算邏輯,用 “貓吃魚” 示例:
-
步驟 1:線性變換拆分多頭 假設多頭注意力頭數h=2,每個頭維度
。輸入\
(維度 3×5),通過
(5×4)拆分后,每個頭的
、
、
維度為 3×2。
-
步驟 2:帶掩碼的縮放點積 計算注意力分數時,掩碼矩陣M遮擋未來位置(如下表,× 表示被遮擋):
關注對象→ 貓(位置 1) 吃(位置 2) 魚(位置 3) 貓(預測吃) √ × × 吃(預測魚) √ √ × 對應分數計算:
,被遮擋位置填充-∞,經 Softmax 后權重為 0。
-
步驟 3:殘差連接與層歸一化 注意力輸出與原始輸入
2.1.3、?損失函數:優化預測概率
公式的示例:
- 對于 “貓吃魚”,模型需預測:
- 已知 “貓”,預測 “吃” 的概率P(吃|貓);
- 已知 “貓、吃”,預測 “魚” 的概率P(魚|貓,吃)。
- 假設模型輸出概率為P(吃|貓)=0.8,P(魚|貓,吃)=0.7,則損失為:
,訓練目標是最小化該值。
2.2 有監督下游任務微調
微調的核心是組合損失函數,以 “電影評論情感分類” 為例說明:
2.2.1、 任務適配:從文本到標簽的映射
- 輸入:“這部電影劇情很棒!”→ 經預訓練模型編碼后,取最后一層輸出
;
- 輸出映射:通過公式
,其中
為分類權重矩陣(假設情感分 2 類,維度 5×2),輸出P(正面)=0.9,P(負面)=0.1。
2.2.2、組合損失:平衡任務與預訓練知識
公式的示例:
- 下游任務損失
:該評論標簽為 “正面”,計算交叉熵損失
;
- 預訓練損失
:用 “這部電影劇情很棒” 預測下一個詞(如 “!”),假設
,損失
;
- 組合損失:取
,則總損失=0.105 + 0.3×0.223≈0.172,既優化分類能力,又保留語言建模能力。
2.3 預訓練語言模型
GPT 是 “簡化的 Transformer Decoder”,通過與傳統模型對比理解其優勢:
2.3.1、?結構差異:從 “專用設計” 到 “通用基座”
- 傳統模型:如情感分類器需手動設計特征(如 “包含‘棒’‘好’等詞”),泛化能力弱;
- GPT(PLM):通過 12 層 Transformer Decoder 堆疊(文章圖 7.2),自動學習特征。例如同樣處理情感分類,無需人工設計規則,直接通過微調適配。
2.3.2、 能力邊界:生成 vs 理解
- GPT(自回歸):適合生成任務。輸入 “周末我想去____”,模型續寫 “爬山,呼吸新鮮空氣”(符合文章所述 “Mask 機制確保單向生成”);
- BERT(自編碼):適合理解任務。輸入 “周末我想 [MASK] 爬山”,補全 “去”(利用雙向注意力)。
通過具體示例可見,GPT 的預訓練是 “從數據學規律”,微調是 “從規律到任務”,而預訓練語言模型則是這一過程的 “通用載體”,三者通過數學公式和結構設計緊密銜接,實現從文本到能力的轉化。
3、模型驗證
3.1、?GPT 模型全流程
- 準備數據集:獲取原始文本并劃分訓練 / 測試集;
- 訓練詞元分析器:分析詞匯特征,構建子詞詞匯表;
- 預處理數據集:將文本轉換為模型可接受的整數序列;
- 訓練模型:基于 Transformer 架構訓練自回歸語言模型;
- 運用模型:通過提示文本生成連貫的新內容。
3.2、GPT 核心邏輯突出:
- 因果掩碼確保自回歸特性(只能看前文);
- 詞嵌入 + 位置嵌入融合語義和位置信息;
- 多頭注意力捕捉不同維度的依賴關系;
- 文本生成采用迭代采樣策略,支持溫度調節。
4、完整實現
4.1、完整代碼
"""
文件名: complete_gpt_pipeline.py
功能: GPT模型全流程實現(數據準備→詞元分析→預處理→訓練→生成)
"""
# 基礎庫導入
import os # 文件路徑操作
import glob # 批量文件查找
import random # 隨機采樣
import re # 正則表達式(文本清洗)
import pickle # 保存/加載詞元分析器
import torch # 深度學習框架
import torch.nn as nn # 神經網絡模塊
import torch.optim as optim # 優化器
import torch.nn.functional as F # 激活函數等
from torch.utils.data import Dataset, DataLoader # 數據集和數據加載器
from datasets import Dataset as HFDataset, concatenate_datasets # HuggingFace數據集工具
from tqdm import tqdm # 進度條
from collections import Counter # 計數工具# ---------------------------一、準備數據集(數據來源與劃分)---------------------------
def load_local_text_data(data_dir, file_pattern='*.txt', max_files=None, encoding='utf-8'):"""從本地目錄加載文本文件并轉換為數據集參數:data_dir: 文本文件所在目錄file_pattern: 文件名匹配模式(默認所有.txt文件)max_files: 最大加載文件數(控制數據量)encoding: 文件編碼(默認utf-8)返回:HuggingFace Dataset對象,包含'text'列"""print(f"加載本地數據:{data_dir}")# 查找目錄中所有匹配的文件路徑file_paths = glob.glob(os.path.join(data_dir, file_pattern))if not file_paths:raise ValueError(f"未找到匹配文件:{data_dir}/{file_pattern}") # 無文件時報錯# 若文件過多,隨機采樣(控制內存占用)if max_files and len(file_paths) > max_files:random.seed(42) # 固定隨機種子,確保結果可復現file_paths = random.sample(file_paths, max_files)texts = []for path in file_paths:try:with open(path, 'r', encoding=encoding) as f:text = f.read().strip() # 讀取并去除首尾空白if text: # 只保留非空文本(避免無效數據)texts.append(text)except Exception as e:print(f"跳過無效文件 {path}:{e}") # 單個文件錯誤不中斷整體流程# 轉換為HuggingFace Dataset(方便后續處理)return HFDataset.from_dict({'text': texts})def generate_sample_data(save_dir='./sample_data'):"""生成示例文本數據(當無本地數據時使用)參數:save_dir: 示例數據保存目錄返回:保存目錄路徑"""os.makedirs(save_dir, exist_ok=True) # 確保目錄存在(exist_ok=True避免重復創建報錯)# 加長示例文本(避免因過短導致后續預處理失敗)sample_texts = ["GPT是基于Transformer的生成式預訓練模型。它通過自監督學習從海量文本中學習語言規律。","預訓練后,模型可通過微調適配具體任務,如文本生成、問答系統、機器翻譯等。","訓練GPT需要大量計算資源和高質量文本數據,常見數據來源包括書籍、網頁和百科。","文本預處理是訓練前的關鍵步驟,包括分詞、清洗、歸一化等操作,直接影響模型性能。","Transformer架構的核心是自注意力機制,能有效捕捉文本中的長距離依賴關系。"]# 保存為多個文本文件(模擬真實數據分布)for i, text in enumerate(sample_texts):with open(os.path.join(save_dir, f"sample_{i}.txt"), 'w', encoding='utf-8') as f:f.write(text)return save_dirdef prepare_dataset():"""主函數:準備訓練集和測試集原始文本文件返回:train_raw: 訓練集文本文件路徑(train_raw.txt)test_raw: 測試集文本文件路徑(test_raw.txt)"""# 優先使用本地數據,否則生成示例數據if os.path.exists('./local_data') and os.path.isdir('./local_data'):dataset = load_local_text_data('./local_data')else:print("未找到本地數據,使用示例數據...")sample_dir = generate_sample_data()dataset = load_local_text_data(sample_dir)# 過濾空文本(避免后續處理出錯)dataset = dataset.filter(lambda x: len(x['text'].strip()) > 0)if len(dataset) == 0:raise ValueError("數據集為空,請檢查數據質量") # 無有效數據時終止流程# 劃分訓練集(90%)和測試集(10%),固定隨機種子確保劃分一致train_test = dataset.train_test_split(test_size=0.1, seed=42)train_dataset = train_test['train']test_dataset = train_test['test']# 保存為文本文件(每行一條數據,方便后續加載)with open('train_raw.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(train_dataset['text']))with open('test_raw.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(test_dataset['text']))print(f"數據集準備完成:訓練集{len(train_dataset)}條,測試集{len(test_dataset)}條")return 'train_raw.txt', 'test_raw.txt'# ---------------------------二、訓練詞元分析器(子詞提取與統計)---------------------------
class WordPieceAnalyzer:"""基于WordPiece算法的詞元分析器功能:從文本中學習子詞詞匯表,實現分詞,并統計詞頻特征"""def __init__(self, vocab_size=1000):self.vocab = set() # 子詞詞匯表(存儲學到的子詞)self.vocab_size = vocab_size # 目標詞匯表大小self.max_subword_len = 6 # 最大子詞長度(控制拆分粒度)def fit(self, text):"""從文本中學習子詞詞匯表(核心:迭代合并高頻子詞對)參數:text: 原始文本字符串"""# 初始詞匯表:單個字符(最小子詞單位)chars = list(set(text))self.vocab = set(chars)# 迭代合并子詞對,直到達到目標詞匯表大小while len(self.vocab) < self.vocab_size:# 統計所有子詞對的出現頻率pairs = Counter()tokens = self.tokenize(text, use_vocab=True) # 用當前詞匯表分詞for i in range(len(tokens)-1):pair = (tokens[i], tokens[i+1]) # 相鄰子詞對pairs[pair] += 1 # 計數if not pairs: # 無更多可合并的子詞對(提前終止)break# 合并頻率最高的子詞對(WordPiece核心邏輯)best_pair = pairs.most_common(1)[0][0] # 取頻率最高的對子new_subword = ''.join(best_pair) # 合并為新子詞self.vocab.add(new_subword) # 加入詞匯表print(f"新增子詞:{new_subword}(當前詞匯表大小:{len(self.vocab)})")def tokenize(self, text, use_vocab=False):"""將文本拆分為子詞(帶##前綴標識非起始子詞)參數:text: 輸入文本use_vocab: 是否使用已學習的詞匯表(False時僅按規則拆分)返回:子詞列表(如["GPT", "##模型", "##可以"])"""# 清洗文本:保留字母、數字、中文,去除其他符號text = re.sub(r'[^\w\s\u4e00-\u9fa5]', '', text)tokens = []i = 0while i < len(text):matched = False# 最長匹配原則:優先匹配長個子詞for l in range(min(self.max_subword_len, len(text)-i), 0, -1):subword = text[i:i+l] # 截取長度為l的子串# 若使用詞匯表,需檢查子詞是否在表中;否則直接拆分if (use_vocab and subword in self.vocab) or (not use_vocab):tokens.append(subword)i += l # 移動指針matched = Truebreakif not matched: # 未匹配到子詞,按單個字符拆分tokens.append(text[i])i += 1# 為非起始子詞添加##前綴(區分是否為詞的開頭)result = []for i, token in enumerate(tokens):if i > 0 and token in self.vocab: # 非第一個且在詞匯表中result.append(f"##{token}")else:result.append(token)return resultdef analyze(self, text):"""分析文本的詞頻和子詞分布特征參數:text: 輸入文本返回:包含詞頻統計的字典"""# 停用詞表(過濾無意義詞匯)STOPWORDS = {'的', '了', '在', '是', 'a', 'an', 'the'}tokens = self.tokenize(text) # 分詞filtered = [t for t in tokens if t not in STOPWORDS] # 過濾停用詞subword_counts = Counter(filtered) # 子詞頻率統計# 從子詞重構完整詞匯(合并##前綴的子詞)words = []current_word = []for t in filtered:if t.startswith('##'):current_word.append(t[2:]) # 去除##前綴else:if current_word: # 保存上一個完整詞words.append(''.join(current_word))current_word = [t] # 開始新的詞word_counts = Counter(words) # 完整詞頻率統計return {'total_tokens': len(filtered), # 有效詞元總數'unique_subwords': len(subword_counts), # 去重子詞數'top_subwords': subword_counts.most_common(10), # 高頻子詞TOP10'top_words': word_counts.most_common(10) # 高頻完整詞TOP10}def train_analyzer(train_file):"""訓練詞元分析器并生成分析報告參數:train_file: 訓練集文本文件路徑返回:訓練好的WordPieceAnalyzer實例"""# 加載訓練集文本with open(train_file, 'r', encoding='utf-8') as f:text = f.read()# 初始化分析器(小詞匯表,適合演示)analyzer = WordPieceAnalyzer(vocab_size=50)print("開始訓練詞元分析器...")analyzer.fit(text) # 學習子詞詞匯表# 生成分析報告report = analyzer.analyze(text)print("\n【詞元分析報告】")print(f"總有效詞元數:{report['total_tokens']}")print(f"去重子詞數:{report['unique_subwords']}")print("高頻子詞TOP10:", report['top_subwords'])print("高頻詞匯TOP10:", report['top_words'])# 保存分析器(供后續預處理使用)with open('wordpiece_analyzer.pkl', 'wb') as f:pickle.dump(analyzer, f)print("詞元分析器已保存至 wordpiece_analyzer.pkl")return analyzer# ---------------------------三、預處理數據集(適配模型輸入格式)---------------------------
class GPTDataset(Dataset):"""GPT模型專用數據集功能:將文本轉換為模型可接受的輸入格式(上下文窗口+下一個token預測)"""def __init__(self, file_path, analyzer, subword_to_idx, block_size=32):"""參數:file_path: 原始文本文件路徑analyzer: 訓練好的WordPieceAnalyzersubword_to_idx: 子詞到索引的映射表block_size: 上下文窗口大小(一次輸入的詞元數)"""self.block_size = block_size # 上下文窗口大小self.subword_to_idx = subword_to_idx # 子詞→索引映射self.analyzer = analyzer # 詞元分析器# 加載文本并轉換為詞元索引with open(file_path, 'r', encoding='utf-8') as f:text = f.read()# 分詞并轉換為索引(未知子詞用<unk>的索引)tokens = analyzer.tokenize(text)self.indices = [subword_to_idx.get(t, subword_to_idx['<unk>']) for t in tokens]# 處理文本過短問題if len(self.indices) < self.block_size:print(f"警告:{file_path} 文本過短({len(self.indices)}詞元),小于block_size({block_size})")# 重復文本以滿足最小長度(僅演示用,實際應增加數據)self.indices = self.indices * (self.block_size // len(self.indices) + 1)print(f"預處理完成:{file_path} 轉換為 {len(self.indices)} 個詞元索引")def __len__(self):"""返回數據集樣本數(確保非負)"""# 樣本數 = 總詞元數 - 窗口大小(每個窗口對應一個樣本)return max(0, len(self.indices) - self.block_size) # 確保≥0def __getitem__(self, idx):"""獲取單個樣本(輸入-目標對)參數:idx: 樣本索引返回:x: 輸入序列([idx, idx+1, ..., idx+block_size-1])y: 目標序列([idx+1, ..., idx+block_size])→ 預測下一個詞元"""x = self.indices[idx:idx+self.block_size] # 輸入窗口y = self.indices[idx+1:idx+self.block_size+1] # 目標窗口(輸入的偏移+1)return torch.tensor(x, dtype=torch.long), torch.tensor(y, dtype=torch.long)def prepare_dataloaders(train_file, test_file, analyzer, batch_size=8, block_size=32):"""準備訓練集和測試集的數據加載器參數:train_file/test_file: 訓練/測試文本文件路徑analyzer: 詞元分析器batch_size: 批次大小block_size: 上下文窗口大小返回:數據加載器、子詞映射表、詞匯表大小、窗口大小"""# 定義特殊符號(填充符和未知詞)special_tokens = {'<pad>': 0, '<unk>': 1}# 構建子詞列表(特殊符號+學到的子詞)subword_list = list(special_tokens.keys()) + list(analyzer.vocab)# 子詞→索引映射(用于將子詞轉換為模型輸入的整數)subword_to_idx = {t: i for i, t in enumerate(subword_list)}vocab_size = len(subword_to_idx) # 詞匯表大小print(f"預處理詞匯表大小:{vocab_size}(含特殊符號)")# 創建數據集train_dataset = GPTDataset(train_file, analyzer, subword_to_idx, block_size=block_size)test_dataset = GPTDataset(test_file, analyzer, subword_to_idx, block_size=block_size)# 檢查數據集是否為空if len(train_dataset) == 0:raise ValueError("訓練集為空,請增大block_size或增加數據量")if len(test_dataset) == 0:raise ValueError("測試集為空,請增大block_size或增加數據量")# 創建數據加載器(批量加載數據,支持打亂)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True # 訓練集打亂)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True # 測試集不打亂)print(f"數據加載器準備完成:訓練集{len(train_loader)}批,測試集{len(test_loader)}批")return train_loader, test_loader, subword_to_idx, vocab_size, block_size# ---------------------------四、訓練模型(GPT核心實現)---------------------------
class MultiHeadAttention(nn.Module):"""多頭自注意力模塊(Transformer核心組件)"""def __init__(self, embed_dim, num_heads, block_size):"""參數:embed_dim: 嵌入維度(模型隱藏層維度)num_heads: 注意力頭數(并行注意力機制)block_size: 上下文窗口大小(用于生成掩碼)"""super().__init__()self.embed_dim = embed_dim # 總嵌入維度self.num_heads = num_heads # 頭數self.head_dim = embed_dim // num_heads # 每個頭的維度(必須整除)# 線性變換:將輸入轉換為Q(查詢)、K(鍵)、V(值)self.qkv_proj = nn.Linear(embed_dim, 3 * embed_dim) # 一次性計算QKVself.out_proj = nn.Linear(embed_dim, embed_dim) # 注意力輸出投影self.dropout = nn.Dropout(0.1) # 防止過擬合# 因果掩碼(上三角矩陣):確保只能看到前文(核心!GPT是自回歸模型)self.register_buffer('mask', torch.triu(torch.ones(block_size, block_size), diagonal=1).bool())def forward(self, x):"""前向傳播:計算多頭自注意力參數:x: 輸入張量,形狀(B, T, C)→(批次, 時間步, 嵌入維度)返回:注意力輸出,形狀(B, T, C)"""B, T, C = x.shape # B:批次, T:時間步, C:嵌入維度# 計算Q、K、V并拆分多頭qkv = self.qkv_proj(x).view(B, T, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)q, k, v = qkv.unbind(0) # 拆分Q、K、V,形狀均為(B, H, T, D)→H:頭數, D:頭維度# 計算注意力分數:Q·K^T / sqrt(D)(縮放點積注意力)attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5)# 應用因果掩碼:遮擋未來位置(置為負無窮,softmax后為0)attn_scores = attn_scores.masked_fill(self.mask[:T, :T], -float('inf'))# 轉換為概率分布attn_probs = F.softmax(attn_scores, dim=-1)attn_probs = self.dropout(attn_probs) # dropout防止過擬合# 注意力加權求和:概率×Vout = attn_probs @ v # (B, H, T, D)# 拼接多頭結果并投影out = out.transpose(1, 2).contiguous().view(B, T, C) # 合并頭維度return self.out_proj(out) # 輸出投影class TransformerBlock(nn.Module):"""Transformer解碼器塊(自注意力+前饋網絡)"""def __init__(self, embed_dim, num_heads, block_size):super().__init__()self.attn = MultiHeadAttention(embed_dim, num_heads, block_size) # 多頭自注意力# 前饋網絡(兩層線性+激活函數)self.ffn = nn.Sequential(nn.Linear(embed_dim, 4 * embed_dim), # 升維nn.GELU(), # 激活函數(優于ReLU,有梯度平滑特性)nn.Linear(4 * embed_dim, embed_dim), # 降維回原維度nn.Dropout(0.1) # dropout)self.norm1 = nn.LayerNorm(embed_dim) # 層歸一化(穩定訓練)self.norm2 = nn.LayerNorm(embed_dim)self.dropout = nn.Dropout(0.1)def forward(self, x):"""前向傳播:殘差連接+層歸一化(Transformer標準結構)參數:x: 輸入張量(B, T, C)返回:輸出張量(B, T, C)"""# 自注意力+殘差連接x = x + self.dropout(self.attn(self.norm1(x)))# 前饋網絡+殘差連接x = x + self.dropout(self.ffn(self.norm2(x)))return xclass GPT(nn.Module):"""GPT模型主類(生成式預訓練Transformer)"""def __init__(self, vocab_size, embed_dim=64, num_heads=2, num_layers=2, block_size=32):"""參數:vocab_size: 詞匯表大小embed_dim: 嵌入維度num_heads: 注意力頭數num_layers: Transformer塊數量block_size: 上下文窗口大小"""super().__init__()self.embed_dim = embed_dimself.block_size = block_size # 用于生成限制# 嵌入層:詞嵌入+位置嵌入self.token_embedding = nn.Embedding(vocab_size, embed_dim) # 詞嵌入表self.pos_embedding = nn.Embedding(block_size, embed_dim) # 位置嵌入表(編碼位置信息)# Transformer解碼器塊堆疊self.layers = nn.Sequential(*[TransformerBlock(embed_dim, num_heads, block_size) for _ in range(num_layers)])# 輸出層:預測下一個詞元self.ln_final = nn.LayerNorm(embed_dim) # 最終層歸一化self.head = nn.Linear(embed_dim, vocab_size) # 投影到詞匯表空間def forward(self, idx, targets=None):"""前向傳播:計算輸出和損失參數:idx: 輸入詞元索引,形狀(B, T)targets: 目標詞元索引(用于計算損失),形狀(B, T)返回:logits: 預測概率對數,形狀(B, T, vocab_size)loss: 交叉熵損失(若targets不為None)"""B, T = idx.shape # B:批次, T:時間步# 詞嵌入 + 位置嵌入(兩者相加融合語義和位置信息)tok_emb = self.token_embedding(idx) # (B, T, C)pos_emb = self.pos_embedding(torch.arange(T, device=idx.device)) # (T, C)x = tok_emb + pos_emb # (B, T, C)# 通過Transformer塊x = self.layers(x)x = self.ln_final(x)logits = self.head(x) # (B, T, vocab_size)→預測每個位置的下一個詞元# 計算損失(交叉熵)if targets is None:loss = Noneelse:B, T, C = logits.shape# 展平為(B*T, C)和(B*T),計算交叉熵loss = F.cross_entropy(logits.view(B*T, C), targets.view(B*T))return logits, lossdef train_model(train_loader, test_loader, vocab_size, block_size, epochs=10):"""訓練GPT模型參數:train_loader/test_loader: 訓練/測試數據加載器vocab_size: 詞匯表大小block_size: 上下文窗口大小epochs: 訓練輪數返回:訓練好的模型"""# 選擇設備(GPU優先)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(f"使用設備:{device}")# 初始化模型并移動到設備model = GPT(vocab_size=vocab_size,embed_dim=64, # 小維度適合演示num_heads=2, # 注意力頭數num_layers=2, # Transformer塊數block_size=block_size).to(device)print(f"模型參數數量:{sum(p.numel() for p in model.parameters())/1e3:.1f}K") # 參數量統計# 優化器:AdamW(帶權重衰減的Adam,常用)optimizer = optim.AdamW(model.parameters(), lr=3e-4)# 訓練循環for epoch in range(epochs):model.train() # 切換到訓練模式(啟用dropout等)train_loss = 0.0# 檢查加載器是否為空if len(train_loader) == 0:print("訓練加載器為空,跳過本輪訓練")continue# 迭代訓練數據for x, y in tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}"):x, y = x.to(device), y.to(device) # 移動到設備optimizer.zero_grad() # 清零梯度logits, loss = model(x, y) # 前向傳播loss.backward() # 反向傳播計算梯度optimizer.step() # 更新參數train_loss += loss.item() # 累加損失# 測試集評估(不更新參數)model.eval() # 切換到評估模式(禁用dropout等)test_loss = 0.0if len(test_loader) == 0:print("測試加載器為空,跳過測試評估")test_loss = float('inf')else:with torch.no_grad(): # 禁用梯度計算(加速+省內存)for x, y in test_loader:x, y = x.to(device), y.to(device)_, loss = model(x, y)test_loss += loss.item()# 計算平均損失并打印train_loss /= len(train_loader)test_loss /= len(test_loader) if len(test_loader) > 0 else 1print(f"Epoch {epoch+1}:訓練損失 {train_loss:.4f},測試損失 {test_loss:.4f}")# 保存模型參數torch.save({'model_state_dict': model.state_dict(), # 模型參數'vocab_size': vocab_size,'block_size': block_size}, 'gpt_model.pt')print("模型已保存至 gpt_model.pt")return model# ---------------------------五、運用模型(文本生成)---------------------------
def generate_text(model, analyzer, subword_to_idx, prompt, max_length=50, temperature=0.7):"""使用訓練好的模型生成文本參數:model: 訓練好的GPT模型analyzer: 詞元分析器(用于分詞)subword_to_idx: 子詞→索引映射prompt: 提示文本(生成起點)max_length: 生成的最大詞元數temperature: 溫度參數(控制隨機性,越小越確定)返回:生成的文本字符串"""model.eval() # 評估模式device = next(model.parameters()).device # 獲取模型所在設備idx_to_subword = {v: k for k, v in subword_to_idx.items()} # 索引→子詞映射# 提示文本轉換為詞元索引tokens = analyzer.tokenize(prompt)indices = [subword_to_idx.get(t, subword_to_idx['<unk>']) for t in tokens]idx = torch.tensor(indices, dtype=torch.long, device=device).unsqueeze(0) # 增加批次維度(B=1)# 迭代生成新詞元for _ in range(max_length):# 截斷上下文至模型最大窗口(避免超出位置嵌入范圍)idx_cond = idx[:, -model.block_size:]# 預測下一個詞元with torch.no_grad(): # 不計算梯度logits, _ = model(idx_cond)# 取最后一個時間步的預測結果logits = logits[:, -1, :] / temperature # 溫度調節(降低溫度=提高確定性)probs = F.softmax(logits, dim=-1) # 轉換為概率分布next_idx = torch.multinomial(probs, num_samples=1) # 按概率采樣idx = torch.cat([idx, next_idx], dim=1) # 拼接新索引# 索引轉換為文本generated_indices = idx[0].tolist() # 取第一個批次generated_tokens = [idx_to_subword[i] for i in generated_indices]# 合并子詞(去除##前綴)text = []for token in generated_tokens:if token.startswith('##'):text.append(token[2:]) # 去除##else:text.append(token)return ''.join(text)# ---------------------------主流程執行---------------------------
if __name__ == '__main__':try:# 1. 準備數據集train_raw, test_raw = prepare_dataset()# 2. 訓練詞元分析器analyzer = train_analyzer(train_raw)# 3. 預處理數據集(減小窗口和批次,適合小數據)train_loader, test_loader, subword_to_idx, vocab_size, block_size = prepare_dataloaders(train_raw, test_raw, analyzer, batch_size=4, block_size=16 # 小窗口適合小樣本)# 4. 訓練模型(減少輪次,加快演示)model = train_model(train_loader, test_loader, vocab_size, block_size, epochs=5)# 5. 運用模型生成文本prompt = "GPT模型可以"generated = generate_text(model, analyzer, subword_to_idx, prompt, max_length=30)print(f"\n【文本生成結果】")print(f"提示:{prompt}")print(f"生成:{generated}")except Exception as e:print(f"執行失敗:{e}") # 捕獲全局異常,避免崩潰4.2、實驗結果?
未找到本地數據,使用示例數據...
加載本地數據:./sample_data
數據集準備完成:訓練集9條,測試集1條
開始訓練詞元分析器...【詞元分析報告】
總有效詞元數:50
去重子詞數:50
高頻子詞TOP10: [('數據預處理是', 1), ('訓練過程中的', 1), ('重要步驟包括', 1), ('分詞歸一化等', 1), ('操作\nGPT', 1), ('是基于Tra', 1), ('nsform', 1), ('er的生成式', 1), ('預訓練模型它', 1), ('通過自監督學', 1)]
高頻詞匯TOP10: [('數據預處理是', 1), ('訓練過程中的', 1), ('重要步驟包括', 1), ('分詞歸一化等', 1), ('操作\nGPT', 1), ('是基于Tra', 1), ('nsform', 1), ('er的生成式', 1), ('預訓練模型它', 1), ('通過自監督學', 1)]
詞元分析器已保存至 wordpiece_analyzer.pkl
預處理詞匯表大小:171(含特殊符號)
預處理完成:train_raw.txt 轉換為 50 個詞元索引
警告:test_raw.txt 文本過短(4詞元),小于block_size(16)
預處理完成:test_raw.txt 轉換為 20 個詞元索引
數據加載器準備完成:訓練集8批,測試集1批
Filter: 100%|██████████| 10/10 [00:00<00:00, 4155.66 examples/s]
使用設備:cuda
模型參數數量:123.2K
Epoch 1/5: 100%|██████████| 8/8 [00:00<00:00, 40.60it/s]
Epoch 2/5: ? 0%| ? ? ? ? ?| 0/8 [00:00<?, ?it/s]Epoch 1:訓練損失 4.3993,測試損失 3.4116
Epoch 2:訓練損失 2.8352,測試損失 2.1006
Epoch 2/5: 100%|██████████| 8/8 [00:00<00:00, 277.57it/s]
Epoch 3/5: 100%|██████████| 8/8 [00:00<00:00, 290.11it/s]
Epoch 4/5: ? 0%| ? ? ? ? ?| 0/8 [00:00<?, ?it/s]Epoch 3:訓練損失 1.7900,測試損失 1.3070
Epoch 4/5: 100%|██████████| 8/8 [00:00<00:00, 316.72it/s]
Epoch 5/5: ? 0%| ? ? ? ? ?| 0/8 [00:00<?, ?it/s]Epoch 4:訓練損失 1.1829,測試損失 0.8717
Epoch 5/5: 100%|██████████| 8/8 [00:00<00:00, 315.20it/s]
Epoch 5:訓練損失 0.8360,測試損失 0.6246
模型已保存至 gpt_model.pt【文本生成結果】
提示:GPT模型可以
生成:<unk><unk>各效斷<unk><unk><unk><unk>許<unk><unk>上管架心籍<unk><unk><unk><unk><unk><unk><unk><unk><unk><unk><unk><unk><unk><unk><unk>
?
4.3、代碼“活起來”
這個 GPT 全流程代碼就像 “教機器人學說話” 的完整流程,每一步都對應人類學習語言的某個環節。用通俗的話解釋各部分作用如下:
一、準備數據集:給機器人找 “課本”
作用:收集供模型學習的 “原材料”(文本數據),就像給學生準備課本和練習冊。
- load_local_text_data:從電腦本地文件夾里找文本文件(比如小說、文章),相當于從圖書館借書。
- generate_sample_data:如果沒找到本地文件,就自己寫一些簡單的示例文本(比如 “GPT 是生成式模型”),相當于老師手寫講義。
- prepare_dataset:把收集到的文本分成 “訓練集”(主要學習用)和 “測試集”(檢驗學習效果用),就像把課本分成正文和課后題。
二、訓練詞元分析器:給機器人編 “字典”
作用:讓模型理解 “詞語的組成規則”,比如 “蘋果” 可以拆成 “蘋” 和 “果”,方便模型記住更多詞。
- WordPieceAnalyzer 類:相當于一本 “子詞字典”,專門記錄常用的小詞片段(子詞)。
- fit 方法:從文本中學習哪些子詞最常見(比如 “GPT”“## 模型”),就像老師總結學生常寫錯的字,單獨整理成表。
- tokenize 方法:用這本字典把文本拆成子詞(比如 “GPT 模型”→“GPT”+“## 模型”),就像學生查字典給生字注音。
- train_analyzer:最終生成一本 “高頻子詞表”,告訴模型哪些子詞更重要,方便后續學習。
三、預處理數據集:把 “課本” 翻譯成 “機器人能懂的語言”
作用:把文本轉換成模型能計算的數字,因為模型只認數字,不認文字。
- GPTDataset 類:把文本拆成固定長度的 “短句”(比如每 32 個詞一段),每段的輸入和下一個詞作為 “問題” 和 “答案”,就像老師把課文切成短句,讓學生練習 “看前半句猜后半句”。
- prepare_dataloaders:給每個子詞編一個數字編號(比如 “GPT”=10,“## 模型”=23),然后把這些編號打包成批次(比如一次練 8 個短句),方便模型批量學習,就像把練習題整理成作業本。
四、訓練模型:教機器人 “學規律”
作用:讓模型通過大量練習,學會 “根據前文猜下一個詞” 的規律,就像學生通過大量閱讀和做題,學會句子的搭配規則。
- GPT 類:模型本身就像一個 “學生大腦”,由多個 “Transformer 塊” 組成(類似一層層的思考步驟)。
- 詞嵌入 + 位置嵌入:給每個詞的編號加一個 “意義”(比如 “貓” 和 “狗” 的編號意義相近),同時記錄詞的位置(比如 “我吃蘋果” 和 “蘋果吃我” 意義不同),就像學生不僅記單詞,還記單詞的意思和順序。
- 多頭注意力:讓模型學會 “關注重要的詞”(比如 “吃” 后面更可能接 “飯” 而不是 “書”),就像學生讀句子時重點看動詞和名詞。
- 前向傳播 + 損失計算:模型先猜下一個詞,再根據 “答案”(正確的下一個詞)調整自己的 “思考方式”,就像學生做題后看答案糾錯,不斷改進。
- train_model:通過多輪練習(epochs),讓模型的猜測越來越準,直到能熟練根據前文接出合理的下一個詞。
五、運用模型:讓機器人 “說句話試試”
作用:檢驗模型是否真的學會了,讓它根據一個開頭自己編出完整的句子,就像讓學生用學到的語法自己寫作文。
- generate_text:給模型一個開頭(比如 “GPT 模型可以”),模型根據訓練時學到的規律,一個詞一個詞往后接(先猜 “做”,再猜 “文本”,再猜 “生成”……),最后連成完整的句子,就像學生根據開頭 “我今天” 寫出 “我今天去公園玩”。
總結:整個流程就像 “教小孩學說話”
- 準備數據集 = 買繪本和故事書;
- 訓練詞元分析器 = 教孩子認字和拆字(比如 “森林”=“木”+“林”);
- 預處理數據集 = 把故事切成短句,讓孩子練習 “接話”;
- 訓練模型 = 孩子通過大量練習,慢慢學會句子的搭配規則;
- 運用模型 = 讓孩子自己編故事,檢驗學習效果。
每一步都是為了讓模型從 “看不懂文本” 到 “能自己寫文本”,核心是通過 “猜下一個詞” 的練習,學會人類語言的規律。










,日歷_睡眠記錄日歷示例(CalendarView01_30))


)

![[spring6: PointcutAdvisor MethodInterceptor]-簡單介紹](http://pic.xiahunao.cn/[spring6: PointcutAdvisor MethodInterceptor]-簡單介紹)



