🧩 模塊總覽:
| 步驟 | 模塊 | 作用 |
|---|---|---|
| ① | 麥克風錄音(VAD支持) | 獲取語音并判斷是否有人說話 |
| ② | Whisper語音識別 | 把語音內容識別為文字 |
| ③ | DeepSeek 聊天接口 | 發送用戶提問并獲取 AI 回復 |
| ④ | edge-tts 朗讀回答 | 把 DeepSeek 回答讀出來 |
| ⑤ | 整合成語音助手主循環 | 全流程結合:說話 → 回答 → 播報 |
?以下是構建語音助手所用的 每個依賴庫的功能介紹
📦 所有依賴包及其作用
| 庫名稱 | pip 安裝命令 | 功能描述 |
|---|---|---|
| sounddevice | pip install sounddevice | 🎤 通過麥克風錄音,支持 NumPy 格式的音頻流 |
| scipy | pip install scipy | 🧪 用于將音頻保存為 .wav 文件格式(scipy.io.wavfile.write) |
| numpy | pip install numpy | 🔢 音頻處理的核心庫,存儲錄音數據等數組操作 |
| webrtcvad | pip install webrtcvad | 🛑 判斷當前音頻中是否“有人在說話”(VAD:語音活動檢測) |
| whisper | pip install openai-whisper | 🧠 OpenAI 的語音識別模型,支持中英文轉文字 |
| ffmpeg | brew install ffmpeg(Mac 必裝) | 🎞 Whisper 使用 ffmpeg 處理音頻格式,它是底層音視頻工具 |
| requests | pip install requests | 🌐 與 DeepSeek 的接口通信(發送問題,獲取回復) |
| edge-tts | pip install edge-tts | 🗣? 使用微軟 Edge 瀏覽器的 TTS 引擎,把文本朗讀成語音(保存為 mp3) |
| subprocess | Python 標準庫 | 🧾 用于調用系統命令(如播放 mp3 文件) |
| cv2(可選) | pip install opencv-python | 📷 攝像頭圖像捕捉(如啟用視覺功能時使用) |
| tempfile | Python 標準庫 | 🧹 自動管理臨時音頻文件或圖片文件 |
| threading | Python 標準庫 | 🔁 異步執行任務(如邊錄音邊播放,防止阻塞) |
| queue | Python 標準庫 | 🧺 用于線程間音頻數據的傳遞或控制 |
🧩 每個模塊與依賴關系圖示:
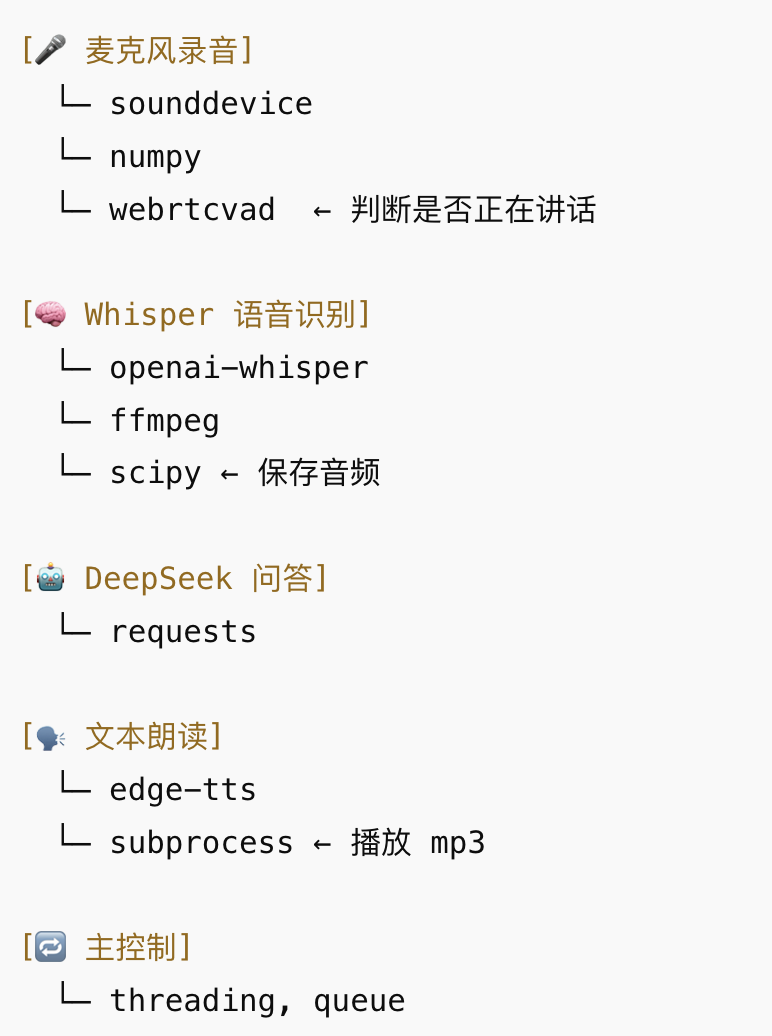
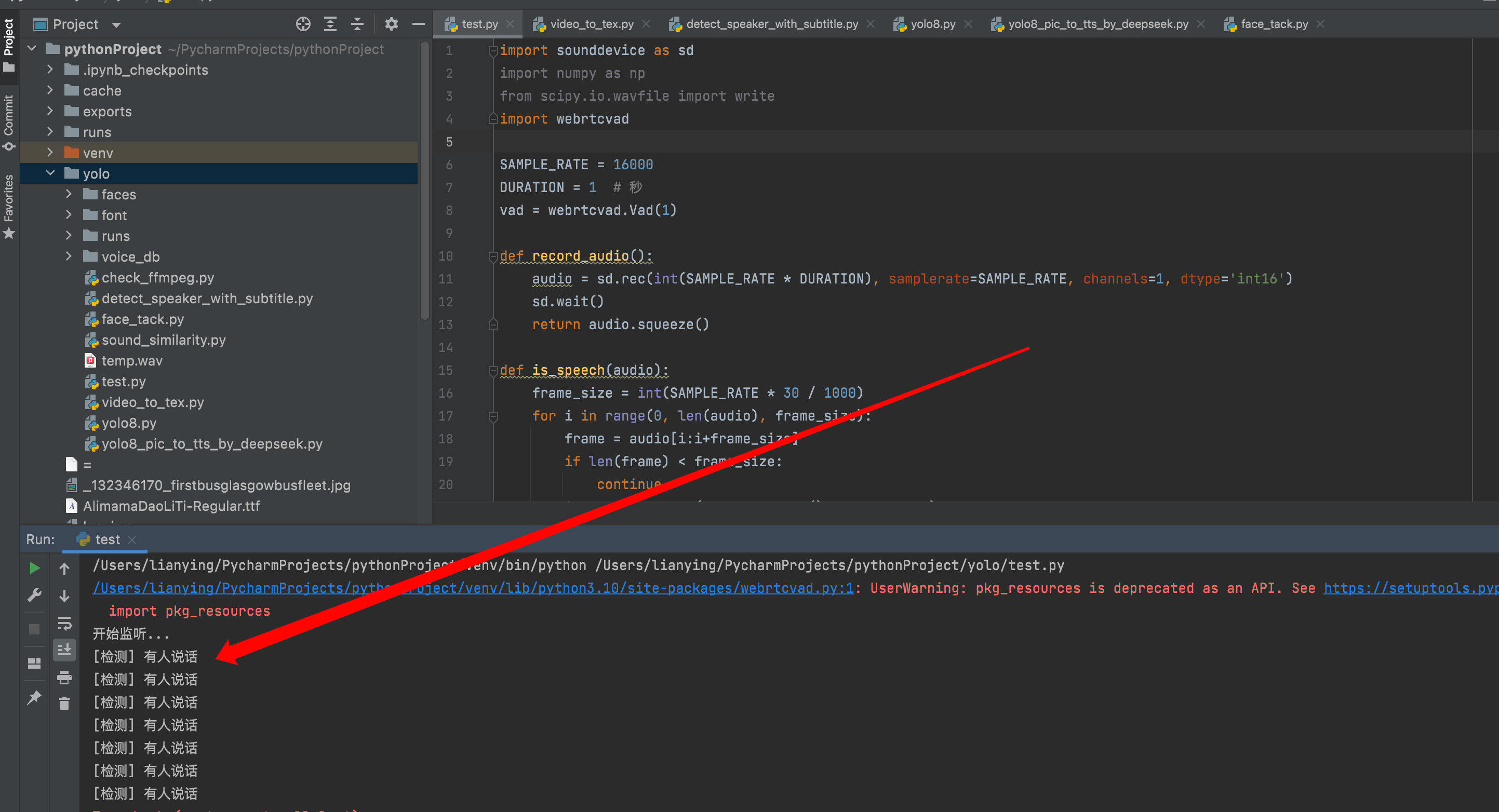
? 模塊①:麥克風錄音 + 說話檢測(VAD)
🔧 安裝依賴:
pip install sounddevice webrtcvad numpy scipy?? 示例代碼
import sounddevice as sd
import numpy as np
from scipy.io.wavfile import write
import webrtcvadSAMPLE_RATE = 16000
DURATION = 1 # 秒
vad = webrtcvad.Vad(1)def record_audio():audio = sd.rec(int(SAMPLE_RATE * DURATION), samplerate=SAMPLE_RATE, channels=1, dtype='int16')sd.wait()return audio.squeeze()def is_speech(audio):frame_size = int(SAMPLE_RATE * 30 / 1000)for i in range(0, len(audio), frame_size):frame = audio[i:i+frame_size]if len(frame) < frame_size:continueif vad.is_speech(frame.tobytes(), SAMPLE_RATE):return Truereturn Falseif __name__ == "__main__":print("開始監聽...")while True:audio = record_audio()if is_speech(audio):print("[檢測] 有人說話")else:print("[檢測] 安靜")
? 模塊②:使用 Whisper 識別中文語音
🔧 安裝:
openai-whisper和ffmpeg已經在【yolo8+聲紋識別(實時字幕)】介紹如何安裝
? 示例代碼
import whisper
from scipy.io.wavfile import writemodel = whisper.load_model("base") # 支持中文def save_audio(audio, path="temp.wav"):write(path, 16000, audio)def transcribe(path):result = model.transcribe(path, language="zh")return result["text"]if __name__ == "__main__":from module1 import record_audioaudio = record_audio()save_audio(audio)print("識別結果:", transcribe("temp.wav"))
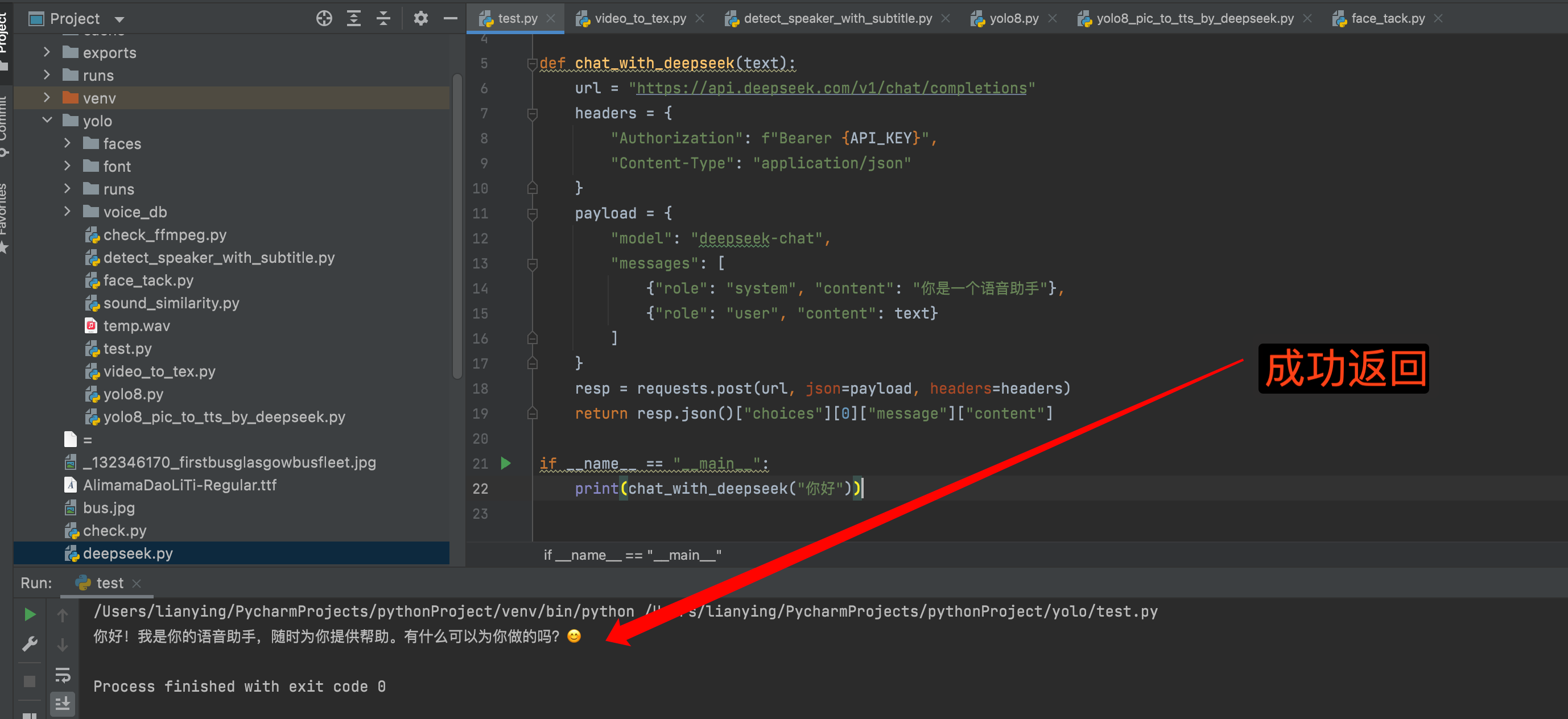
? 模塊③:調用 DeepSeek 接口進行對話
🔧 安裝:
pip install requests?? 示例代碼
import requestsAPI_KEY = "你的DeepSeek_API_Key"def chat_with_deepseek(text):url = "https://api.deepseek.com/v1/chat/completions"headers = {"Authorization": f"Bearer {API_KEY}","Content-Type": "application/json"}payload = {"model": "deepseek-chat","messages": [{"role": "system", "content": "你是一個語音助手"},{"role": "user", "content": text}]}resp = requests.post(url, json=payload, headers=headers)return resp.json()["choices"][0]["message"]["content"]if __name__ == "__main__":print(chat_with_deepseek("你好"))
? 模塊④:使用TTS 朗讀語音回答
🗣? 主流 Python 文本轉語音(TTS)庫/方案對比
| 方案名稱 | 是否聯網 | 中文支持 | 安裝難度 | 聲音自然度 | 可自定義聲音 | 跨平臺 | 朗讀延遲 | 備注說明 |
|---|---|---|---|---|---|---|---|---|
? edge-tts | ? 是 | ? 強 | 中等 | ???? | 部分支持(系統語音) | ? 是 | ?? | 接口調用微軟 Edge 瀏覽器 TTS,效果好 |
? pyttsx3 | ? 否 | ? 弱(Windows 支持) | 簡單 | ?? | ? 支持本地語音合成器 | ? 是 | ??? | 離線,本地語音引擎(如 SAPI5, NSSpeech) |
? gTTS | ? 是 | ? 支持 | 簡單 | ???? | ? 不支持 | ? 是 | ??? | Google 接口,不穩定,有速率限制 |
? Bark | ? 否 | ? 無中文 | 非常復雜 | ????? | ? 可訓練音色 | ? 是 | ?? | 需 GPU,強大但重型 |
? TTS by Coqui | ? 否 | ? 支持 | 較復雜 | ???? | ? 可微調 | ? 是 |
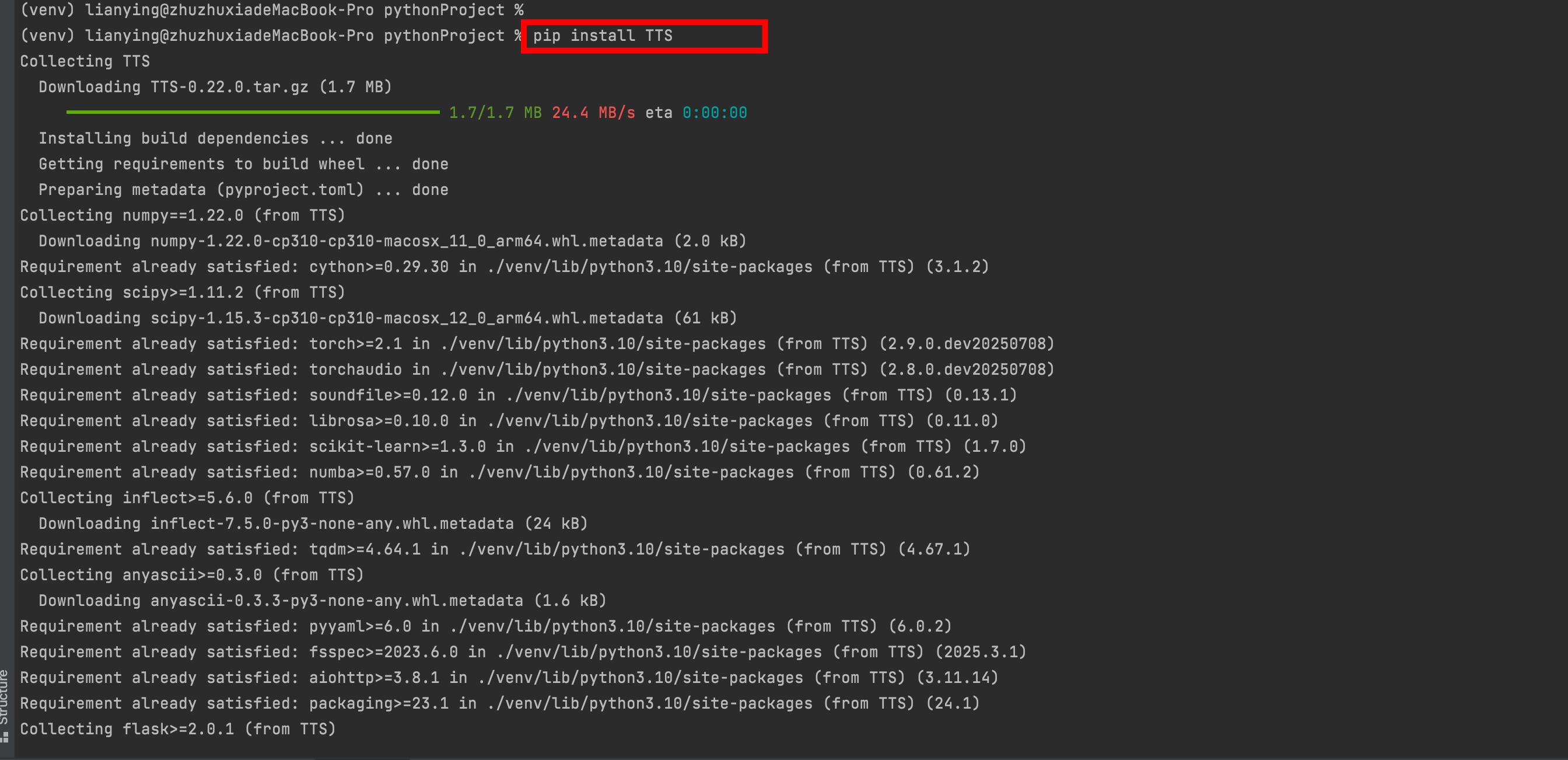
?使用TTS by Coqui 是一個強大、開源且支持中文的 TTS 引擎,適合本地部署,音質優秀。
pip install TTS
如果安裝太慢,建議使用清華鏡像:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple TTS
?
? 下載語音模型:使用 Python 手動下載模型(推薦)
from TTS.utils.manage import ModelManagermodel_name = "tts_models/zh-CN/baker/tacotron2-DDC-GST"
manager = ModelManager()
paths = manager.download_model(model_name)
print("模型下載完成,路徑為:", paths)
?
先擱置,后面在寫


:選項集合的數據庫擴展類)
)








|SVM基礎概念-超平面)

與可視化)




