? 今日目標
- 使用 Pandas + Matplotlib/Seaborn 對簡歷數據進行探索性分析
- 分析不同字段與目標變量的相關性
- 通過可視化呈現簡歷篩選的潛在規律
🧾 一、建議分析內容
🔹 分類字段分析
| 字段 | 圖表建議 | 說明 |
|---|---|---|
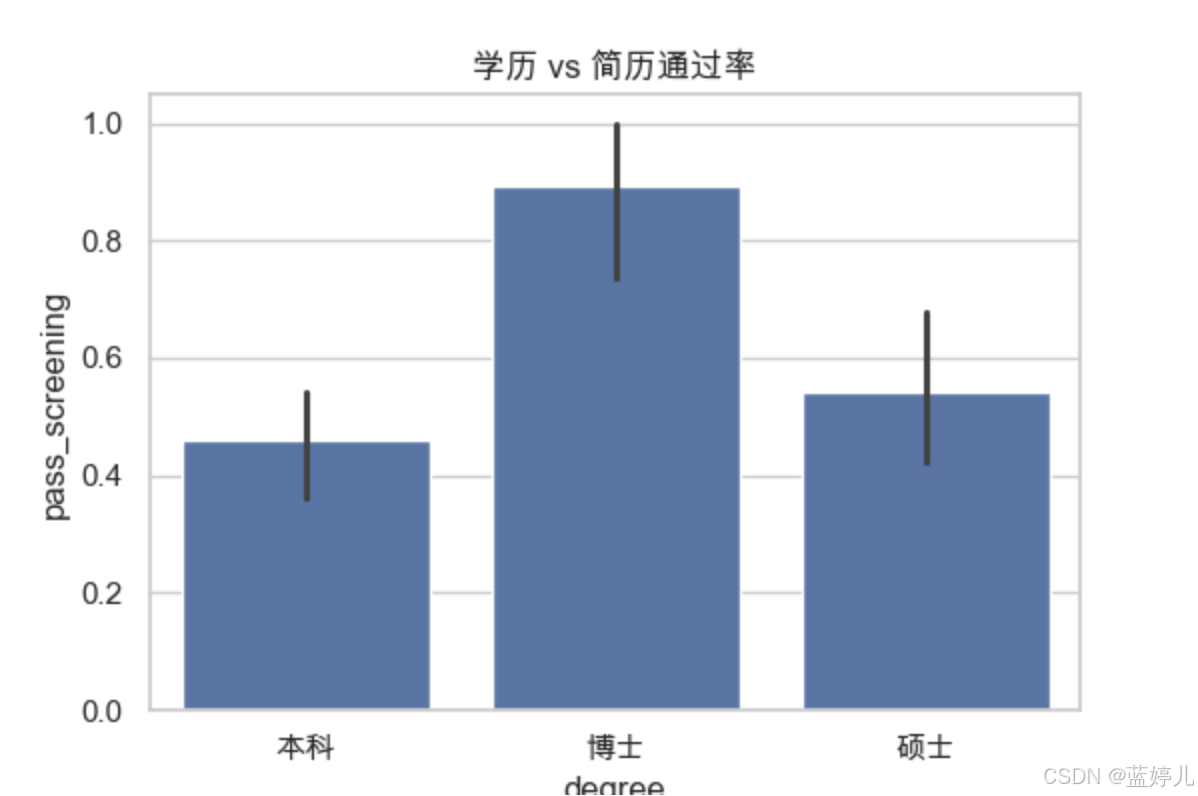
degree | 柱狀圖(分組通過率) | 分析學歷與通過率關系 |
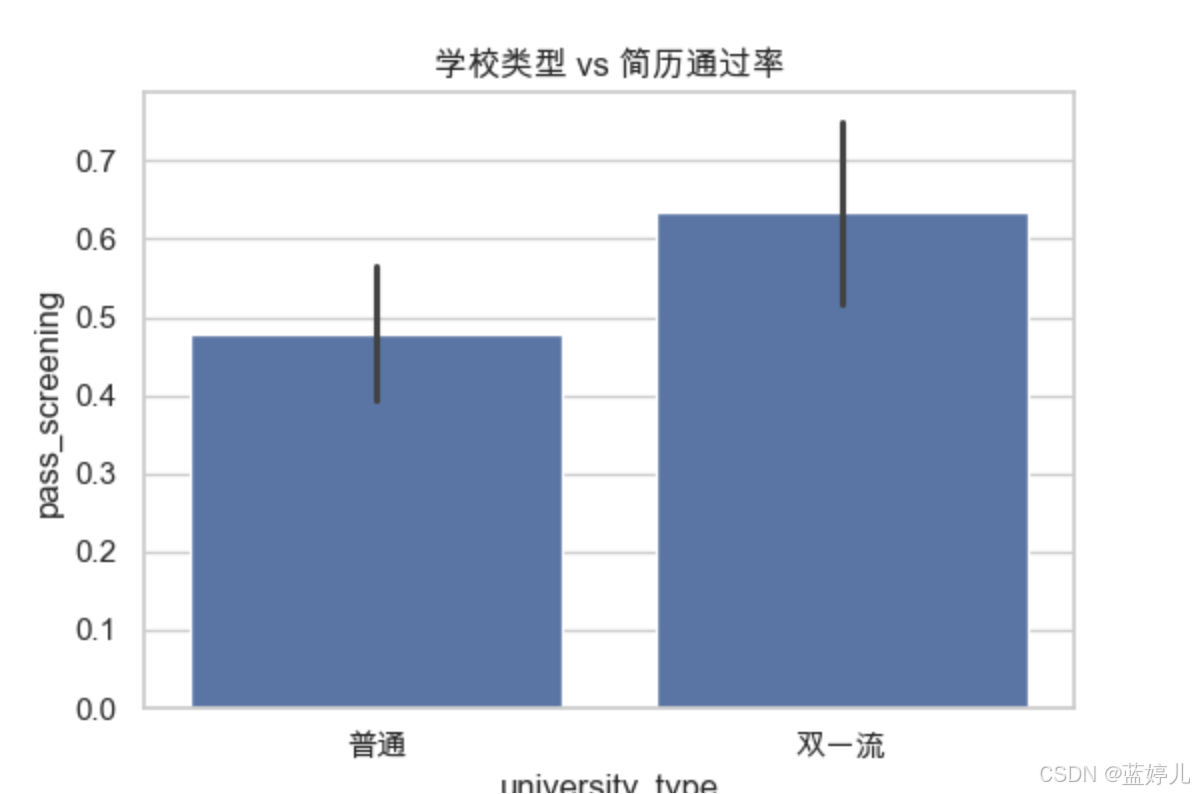
university_type | 條形圖 | 是否為雙一流影響篩選? |
🔹 數值字段分析
| 字段 | 圖表建議 | 說明 |
|---|---|---|
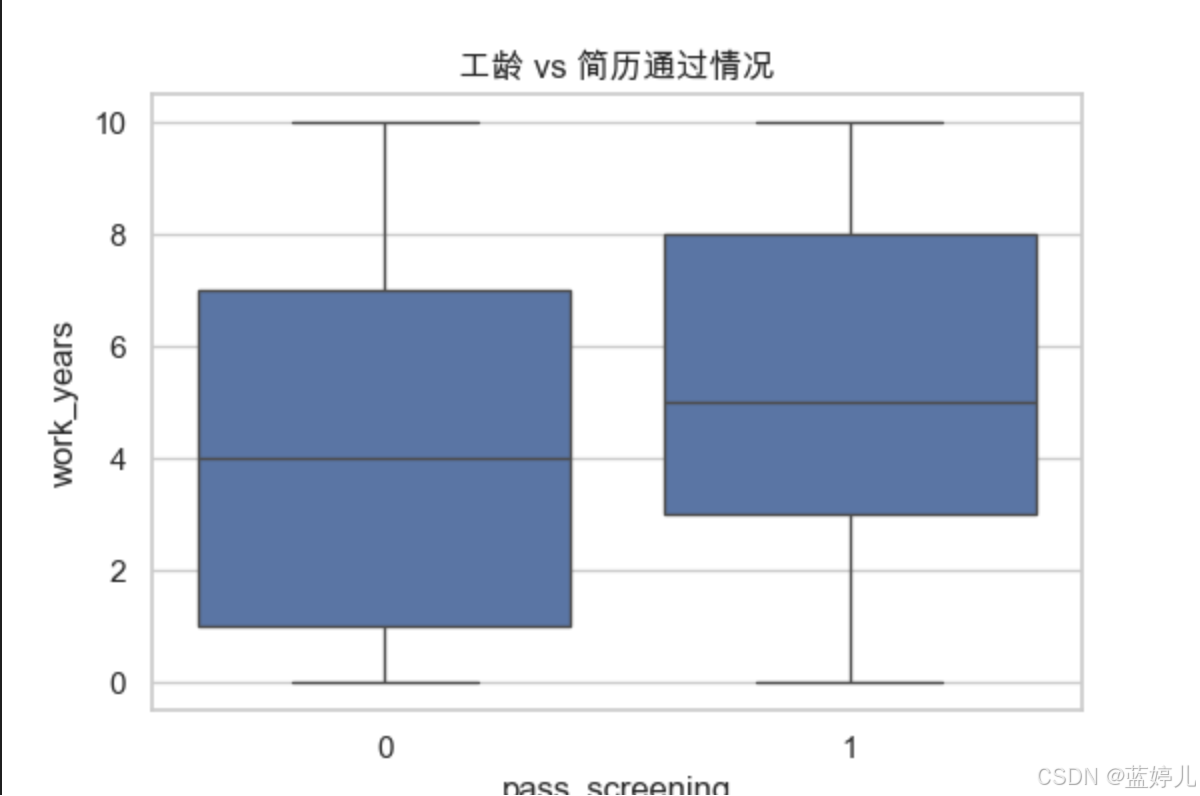
work_years | 箱型圖 / 小提琴圖 | 工齡 vs 通過率分布 |
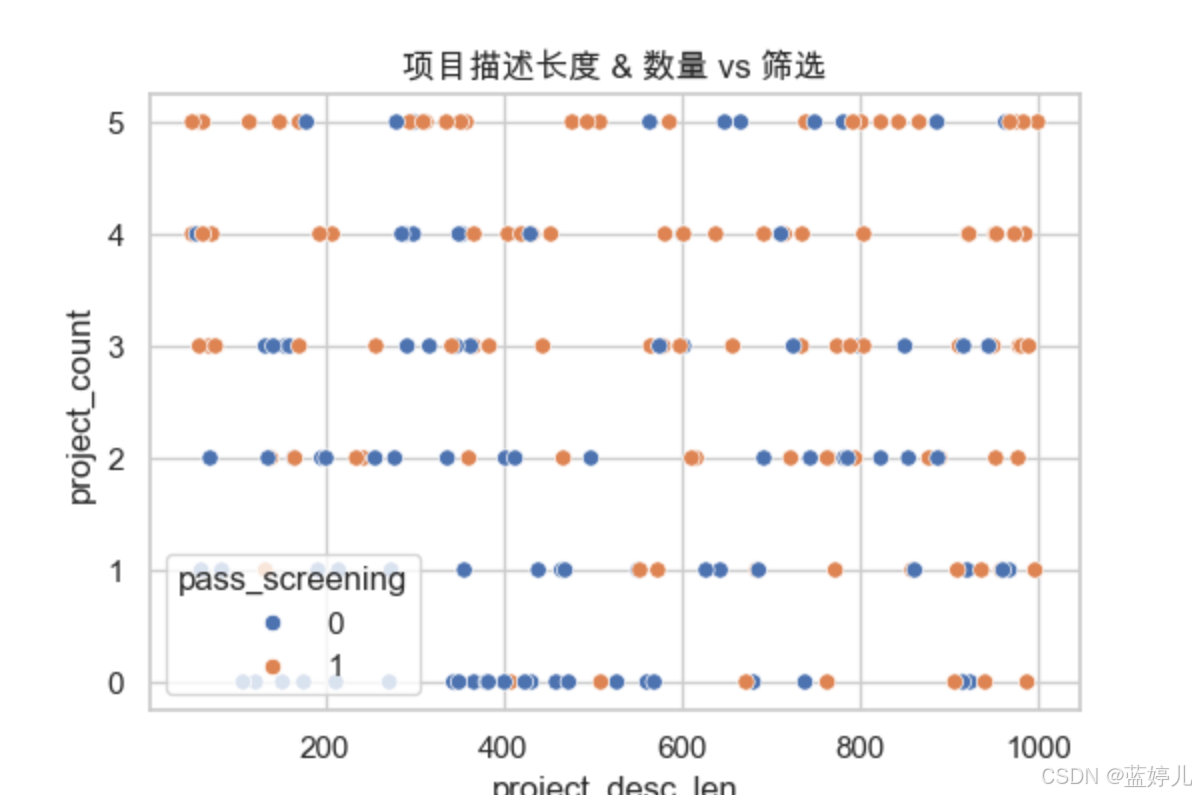
project_count, desc_len | 散點圖 | 項目數量/質量是否有利篩選 |
🔹 多變量交叉分析
- 使用
hue="pass_screening"對比不同特征組合 - 相關系數熱力圖
sns.heatmap(df.corr())
📦 所需工具
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
?? 今日練習任務
編寫 eda_visualize.py 實現以下內容:
-
讀取原始數據
resume_data.csv -
繪制多個字段與通過率之間的圖表
-
可輸出為本地圖片或顯示圖形窗口
# eda_visualize.py - 簡歷數據可視化分析腳本import pandas as pd import seaborn as sns import matplotlib.pyplot as pltplt.rcParams['font.family'] = 'Arial Unicode MS' # Mac 用戶可用 plt.rcParams['axes.unicode_minus'] = False# 設置風格 sns.set(style="whitegrid")# 讀取數據 df = pd.read_csv("./data/resume_data.csv")# 設置字體顯示中文(可選) plt.rcParams['font.family'] = ['Arial Unicode MS'] # macOS # plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows # plt.rcParams['axes.unicode_minus'] = False# 學歷 vs 通過率 plt.figure(figsize=(6, 4)) sns.barplot(x="degree", y="pass_screening", data=df) plt.title("學歷 vs 簡歷通過率") plt.savefig("plot_degree_pass.png")# 學校類型 vs 通過率 plt.figure(figsize=(6, 4)) sns.barplot(x="university_type", y="pass_screening", data=df) plt.title("學校類型 vs 簡歷通過率") plt.savefig("plot_univ_pass.png")# 工齡分布對通過率影響 plt.figure(figsize=(6, 4)) sns.boxplot(x="pass_screening", y="work_years", data=df) plt.title("工齡 vs 簡歷通過情況") plt.savefig("plot_work_years_pass.png")# 項目描述長度 vs 篩選通過(散點圖) plt.figure(figsize=(6, 4)) sns.scatterplot(x="project_desc_len", y="project_count", hue="pass_screening", data=df) plt.title("項目描述長度 & 數量 vs 篩選") plt.savefig("plot_project_scatter.png")# 相關系數熱力圖 plt.figure(figsize=(10, 6)) corr = df.corr(numeric_only=True) sns.heatmap(corr, annot=True, cmap="YlGnBu") plt.title("字段相關系數熱力圖") plt.savefig("plot_corr_heatmap.png")print("? 圖表已生成并保存為 PNG 文件。")





Kubernetes基礎介紹)











)

