溫馨提示:
本篇文章已同步至"AI專題精講" CPO:對比偏好優化—突破大型語言模型在機器翻譯中的性能邊界
摘要
中等規模的大型語言模型(LLMs),如參數量為 7B 或 13B 的模型,在機器翻譯(MT)任務中展現出良好性能。然而,它們仍未能達到最先進的傳統編碼器-解碼器翻譯模型,或是如 GPT-4(OpenAI, 2023)等更大規模 LLM 的表現。在本研究中,我們致力于彌合這一性能差距。我們首先評估了在機器翻譯任務中對 LLM 進行有監督微調的局限性,強調即便是人工生成的參考數據也存在質量問題。與模仿參考翻譯的有監督微調方式不同,我們提出了一種新方法——對比偏好優化(Contrastive Preference Optimization, CPO),其目標是訓練模型避免生成“尚可但不完美”的翻譯結果。
我們將 CPO 應用于 ALMA(Xu et al., 2023)模型,僅使用 22K 個平行句對,并僅微調 0.1% 的參數,便獲得了顯著提升。最終模型名為 ALMA-R,其在 WMT’21、WMT’22 和 WMT’23 測試集上的表現與 WMT 比賽冠軍和 GPT-4 相當,甚至更優。
1 引言
當前的機器翻譯(MT)系統主要采用 transformer 編碼器-解碼器架構(Vaswani et al., 2017),這一點在主流模型中得到了體現,例如 NLLB-200(NLLB TEAM et al., 2022)、M2M100(Fan et al., 2021)、BiBERT(Xu et al., 2021)和 MT5(Xue et al., 2021)。然而,隨著僅使用解碼器的大型語言模型(如 GPT 系列(Brown et al., 2020;OpenAI, 2023)、Mistral(Jiang et al., 2023)、LLaMA 系列(Touvron et al., 2023a; b)、Falcon(Almazrouei et al., 2023)等)在各類 NLP 任務中表現出卓越性能,也引發了人們對使用這類模型進行機器翻譯的興趣。
近期研究(Zhu et al., 2023a;Jiao et al., 2023b;Hendy et al., 2023;Kocmi et al., 2023;Freitag et al., 2023)表明,大型 LLM(如 GPT-3.5(175B)和 GPT-4)具有很強的翻譯能力。然而,較小規模的 LLM(7B 或 13B)在性能上仍落后于傳統翻譯模型(Zhu et al., 2023a)。
因此,已有一些研究致力于提升中等規模 LLM 的翻譯能力(Yang et al., 2023;Zeng et al., 2023;Chen et al., 2023;Zhu et al., 2023b;Li et al., 2023;Jiao et al., 2023a;Zhang et al., 2023),但改進幅度相對有限,主要原因在于主流 LLM 的預訓練數據大多以英語為中心,語言多樣性受限(Xu et al., 2023)。為了解決這一問題,Xu 等人(2023)首先使用大規模非英文的單語數據對 LLaMA-2(Touvron et al., 2023b)進行初步微調,以增強其多語言能力,隨后又使用高質量的平行數據進行有監督微調(SFT),指導模型生成翻譯。他們所提出的模型 ALMA,在翻譯任務中超越了此前所有中等規模的 LLM,甚至優于 GPT-3.5。但其性能仍略遜于 GPT-4 和 WMT 比賽的冠軍系統。
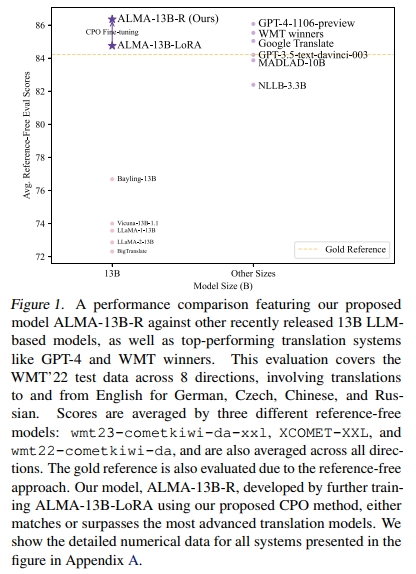
本研究通過我們提出的新訓練方法 對比偏好優化(CPO),在極低成本的基礎上(僅需 12M 個可學習參數,相當于原模型的 0.1%,以及一個包含 10 個翻譯方向的 22K 數據集),進一步對 ALMA 模型進行微調,從而成功彌合了這一差距。該微調模型被稱為 ALMA-R,其詳細性能比較如圖 1 所示。
CPO 旨在緩解有監督微調(SFT)中的兩個根本性缺陷。首先,SFT 的訓練目標是最小化預測輸出與黃金參考之間的差距,這從根本上將模型性能限制在訓練數據的質量水平之下。即便是傳統上被視為高質量的人工數據,也不可避免地存在問題(詳見第 2 節)。例如,如圖 1 所示,一些強大的翻譯模型有時會生成比黃金參考更優秀的譯文。第二,SFT 缺乏一種機制來抑制模型生成“差一點就對”的翻譯。當強模型在整體上能生成高質量譯文時,有時也會出現遺漏、翻譯不全等小錯誤。防止生成這種“幾乎正確但最終有誤”的譯文至關重要。
為解決上述問題,我們引入 對比偏好優化(CPO) 方法,使用精心構建的偏好數據對 ALMA 模型進行訓練。經過 CPO 微調后的模型 ALMA-R 實現了顯著性能提升,其翻譯質量達到了甚至超過 GPT-4 和 WMT 比賽冠軍的水平。
參考譯文是真正的“黃金”還是“鍍金”?
我們對 ALMA 模型使用的訓練數據(FLORES-200 數據集)進行了深入分析,仔細比較了參考譯文與強大翻譯模型生成的譯文之間的質量差異。研究發現,在許多情況下,人工編寫的平行語料的質量甚至劣于系統自動生成的譯文。這一發現揭示了一個關鍵問題:僅訓練模型去模仿參考譯文可能并非最有效的策略,依賴參考譯文進行評估也可能存在偏差。
突破有監督微調(SFT)的性能瓶頸
我們提出了一種新的訓練方法——對比偏好優化(Contrastive Preference Optimization, CPO)。該方法在內存效率、訓練速度和提升翻譯質量方面都具有顯著優勢。CPO 能夠打破 SFT 模型模仿式學習過程的性能瓶頸,進一步提升那些已經通過 SFT 達到性能飽和的模型。
偏好數據集
我們構建并公開發布了一個高質量的機器翻譯偏好數據集,為后續研究提供了可靠的基礎資源。
2. 是黃金還是鍍金?審視黃金參考譯文的質量
在機器翻譯任務中,目標參考譯文的重要性至關重要。當前模型訓練范式在很大程度上依賴參考譯文的質量,因為模型通常通過最小化預測輸出與黃金參考之間差異的損失函數進行優化。
設有數據集 DDD,包含源語言句子 xxx 及其對應的目標語言句子(黃金參考)yyy,表示為:
D={(x(i),y(i))}i=1ND = \{(x^{(i)}, y^{(i)})\}_{i=1}^{N} D={(x(i),y(i))}i=1N?
其中 NNN 是平行語句對的總數。針對這些平行語句,參數為 θ\thetaθ 的模型 πθ\pi_\thetaπθ? 的負對數似然損失定義如下:
LNLL=?E(x,y)~D[log?πθ(y∣x)].(1)\begin{array} { r } { \mathcal { L } _ { \mathrm { N L L } } = - \mathbb { E } _ { ( x , y ) \sim \mathcal { D } } [ \log \pi _ { \theta } ( y \vert x ) ] . } \end{array}\quad(1) LNLL?=?E(x,y)~D?[logπθ?(y∣x)].?(1)
因此,模型能否有效進行翻譯,依賴于高質量翻譯語句對的可用性(Xu 等,2023;Maillard 等,2023)。此外,當前常用的評估工具如 BLEU(Papineni 等,2002)和 COMET-22(Rei 等,2022)主要依賴基于參考的評估指標。然而,這些評估的準確性容易受到低質量參考譯文的影響而下降(Kocmi 等,2023;Freitag 等,2023)。近期研究(Xu 等,2023;Kocmi 等,2023;Freitag 等,2023)已開始關注平行語料質量的評估,指出目標參考譯文未必始終代表最高質量。在圖 2 中,我們從 FLORES-200 數據集中選取了一個翻譯示例,將黃金參考譯文與最優的 ALMA 模型及 GPT-4 的翻譯結果進行了對比。比較顯示該黃金參考譯文存在缺陷,遺漏了部分信息,而系統生成的譯文則體現出更高的質量。這引發了一個疑問:參考譯文(即便是人工撰寫的)是否真的等同于“黃金標準”?為了全面評估黃金參考譯文與當代高性能翻譯模型輸出的質量,我們建議采用無參考評估框架對這些譯文進行評估。

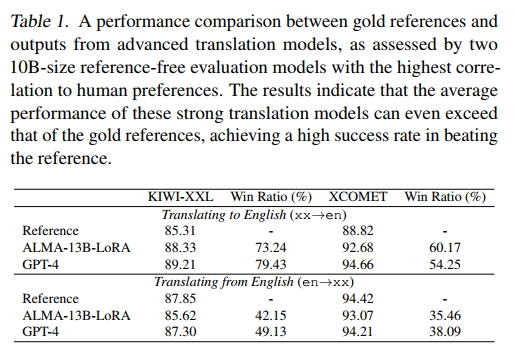
模型 我們對 ALMA-13B-LoRA2 的翻譯結果以及最新的 GPT-4(gpt-4-1106-preview)的 zero-shot 翻譯進行了深入分析。為評估這些譯文的質量,我們采用了兩種最新且規模最大的無參考評估模型,它們的參數規模均為 10B,并在與人工評價的一致性方面表現出極高的相關性(Freitag 等,2023)。這兩個模型分別是 Unbabel/wmt23-cometkiwi-da-xxl(以下簡稱 KIWI-XXL)(Rei 等,2023)和 Unbabel/XCOMET-XXL(以下簡稱 XCOMET)(Guerreiro 等,2023)。
數據 我們使用的是高質量且人工編寫的 FLORES-200 數據集(NLLB TEAM 等,2022),包括開發集和測試集,每個語言方向共計 2009 個樣本,用于對比黃金參考譯文與模型生成的譯文。我們使用 ALMA-13B-LoRA 和 GPT-4 對五個以英語為中心的語言對進行翻譯,涵蓋從英語和翻譯到英語的方向。這些語言對包括德語(de)、捷克語(cs)、冰島語(is)、中文(zh)和俄語(ru),其中冰島語(is)被歸為低資源語言,其余則為高資源語言。
提示詞 ALMA 模型生成翻譯時所用的提示詞與 Xu 等(2023)中所用的一致。GPT-4 的翻譯生成則遵循 Hendy 等(2023)提出的建議。這些提示詞的具體細節見附錄 B。
模型輸出可以成為更好的參考譯文
在表 1 中,我們展示了 KIWI-XXL 和 XCOMET 對黃金參考譯文、ALMA-13B-LoRA 輸出以及 GPT-4 輸出的評估得分。此外,我們還報告了勝率(Win Ratio),即模型輸出優于黃金參考譯文的比例。這些指標是五種語言的平均值。值得注意的是,即使是與高質量的 FLORES-200 數據集相比,在 xx→en 翻譯方向上,翻譯模型的平均表現也明顯優于參考譯文,在 KIWI-XXL 中提升約 3–4 分,在 XCOMET 中提升約 4–6 分。尤其值得一提的是,KIWI-XXL 評估中,有大量模型輸出被評分為優于參考譯文(例如 ALMA 為 73.24%),即便是使用 XCOMET 評估,仍有相當比例(如 ALMA 為 60.17%)勝出。在 en→xx 方向上,盡管整體表現與參考譯文相當,仍有約 40% 的模型輸出被視為優于參考譯文。
動機:幫助模型學會拒絕
上述發現表明,先進模型生成的翻譯有時可以超越黃金參考譯文的質量。這引發了一個問題:如何有效利用這類數據。一種直接的方法是使用源句和更優的譯文作為參考對模型進行微調。盡管這種做法可能提升模型的翻譯能力,但它并不能教會模型識別和避免生成質量較差的譯文,例如圖 2 所示那類“不錯但不完美”的譯文。因此,這種情況促使我們開發一種新的訓練目標,旨在指導模型優先生成更高質量的譯文,并拒絕較差的譯文,采用帶有困難負樣本的對比學習方式(Oord 等,2018;Chen 等,2020;He 等,2020;Robinson 等,2021;Tan 等,2023)。該目標超越了傳統僅最小化參考譯文交叉熵損失的范式。
3. 對比偏好優化
為了學習一個既能促進優質翻譯又能拒絕劣質翻譯的目標函數,獲取標注好的偏好數據是關鍵,但在機器翻譯領域中,此類數據非常稀缺。本節首先介紹我們如何構建偏好數據,然后提出一種偏好學習技術——對比偏好優化(CPO)。
3.1 三元組偏好數據
本節詳細說明我們構建偏好數據集 DDD 的方法。該數據集基于 FLORES-200 數據(包括開發集和測試集)構建,涵蓋第 2 節中提到的相同語言對。對于每一個語言對,數據集包含 2009 個平行句對。
給定一個源句 xxx(無論是從英語翻譯還是翻譯成英語),我們分別使用 GPT-4 和 ALMA-13B-LoRA 生成對應的譯文,分別記為 ygpt-4y_{\text{gpt-4}}ygpt-4? 和 yalmay_{\text{alma}}yalma?。再加上原始的參考譯文 yrefy_{\text{ref}}yref?,形成三元組 y=(yref,ygpt-4,yalma)y = (y_{\text{ref}}, y_{\text{gpt-4}}, y_{\text{alma}})y=(yref?,ygpt-4?,yalma?),表示輸入 xxx 的三個不同翻譯結果。
接著,我們使用無參考評價模型 KIWI-XXL 和 XCOMET 對這些翻譯進行打分,取平均分表示為 s=(sref,sgpt-4,salma)s = (s_{\text{ref}}, s_{\text{gpt-4}}, s_{\text{alma}})s=(sref?,sgpt-4?,salma?)。分數最高的譯文被標為偏好譯文 ywy_wyw?,分數最低的譯文標為不偏好譯文 yly_lyl?,即:
- yw=yarg?max?i(s)y_w = y_{\arg\max_i(s)}yw?=yargmaxi?(s)?
- yl=yarg?min?i(s)y_l = y_{\arg\min_i(s)}yl?=yargmini?(s)?
其中 iii 是三元組中譯文的索引。得分處于中間的譯文將不被使用。圖 3 展示了該選擇過程的一個示意例子。
值得注意的是,即便是被標記為“不偏好”的譯文也可能具有較高質量。這個標簽僅說明該譯文相較于其他候選仍有提升空間,比如缺少細節。這種使用“高質量但不完美”的譯文作為負樣本的方法,有助于模型學習如何優化細節,從而生成更完美的譯文。
3.2 CPO 目標函數的推導
我們從 Direct Preference Optimization(DPO)的分析出發推導 CPO 的目標函數。DPO 是一種直接優化目標,廣泛用于人類反饋強化學習(RLHF)任務中(Ziegler et al., 2019;Ouyang et al., 2022;Rafailov et al., 2023)。

給定一組源句 xxx,以及相應的偏好譯文 ywy_wyw? 和不偏好譯文 yly_lyl?,我們可以構建一個靜態比較數據集:
D={(x(i),yw(i),yl(i))}i=1ND = \{(x^{(i)}, y_w^{(i)}, y_l^{(i)})\}_{i=1}^{N} D={(x(i),yw(i)?,yl(i)?)}i=1N?
DPO 的損失函數以最大似然的形式定義于參數化策略 πθ\pi_\thetaπθ? 上:
L(πθ;πref)=?E(x,yw,yl)~D[log?σ(βlog?πθ(yw∣x)πref(yw∣x)?βlog?πθ(yl∣x)πref(yl∣x))],(2)\begin{array} { r l r } & { } & { \mathcal { L } ( \pi _ { \boldsymbol { \theta } } ; \pi _ { \mathrm { r e f } } ) = - \, \mathbb { E } _ { ( x , y _ { w } , y _ { l } ) \sim \mathcal { D } } \Big [ \log \sigma \Big ( \beta \log \frac { \pi _ { \boldsymbol { \theta } } ( y _ { w } | x ) } { \pi _ { \mathrm { r e f } } ( y _ { w } | x ) } \Big . } \\ & { } & { \Big . \quad \quad \quad - \, \beta \log \frac { \pi _ { \boldsymbol { \theta } } ( y _ { l } | x ) } { \pi _ { \mathrm { r e f } } ( y _ { l } | x ) } \Big ) \Big ] , \quad \quad \quad \quad \quad \quad } \end{array}\quad(2) ??L(πθ?;πref?)=?E(x,yw?,yl?)~D?[logσ(βlogπref?(yw?∣x)πθ?(yw?∣x)??βlogπref?(yl?∣x)πθ?(yl?∣x)?)],?(2)
其中,πref\pi_{\text{ref}}πref? 是一個預訓練的語言(翻譯)模型,σ\sigmaσ 是 Sigmoid 函數,β\betaβ 是一個超參數。DPO 損失函數是通過在 Proximal Policy Optimization(PPO)框架(Schulman et al., 2017)中,對真實獎勵和相應最優策略進行重參數化推導而來。因此,DPO 訓練可以采用監督微調的方式進行,因為它完全依賴于帶偏好標簽的數據,不需要智能體與環境之間的交互。
然而,與常規 SFT 相比,DPO 存在顯著缺點。首先,DPO 占用內存效率低:它需要同時存儲參數化策略和參考策略,這意味著兩倍的內存消耗。其次,它運行速度低效:需要對兩個策略分別執行模型推理,導致推理時間加倍。為了解決這些效率問題,我們提出了對比偏好優化(Contrastive Preference Optimization, CPO)。
當將 πref\pi_{\text{ref}}πref? 設置為均勻先驗 UUU 時,可以解決內存和速度上的低效問題,因為此時 πref(yw∣x)\pi_{\text{ref}}(y_w|x)πref?(yw?∣x) 和 πref(yl∣x)\pi_{\text{ref}}(y_l|x)πref?(yl?∣x) 兩項相互抵消。這樣就無需在策略模型之外進行額外的計算和存儲。因此,我們首先展示,DPO 損失函數可以使用均勻參考模型進行有效近似:
L(πθ;U)=?E?(x,yw,yl)~D[log?σ(βlog?πθ(yw∣x)?βlog?πθ(yl∣x))].(3)\begin{array} { r l } & { \mathcal { L } ( \pi _ { \theta } ; U ) = - \operatorname { \mathbb { E } } _ { ( x , y _ { w } , y _ { l } ) \sim \mathcal { D } } \Big [ \log \sigma \Big ( \beta \log \pi _ { \theta } ( y _ { w } | x ) } \\ & { \quad \quad \quad \quad \quad - \beta \log \pi _ { \theta } ( y _ { l } | x ) \Big ) \Big ] . } \end{array}\quad(3) ?L(πθ?;U)=?E(x,yw?,yl?)~D?[logσ(βlogπθ?(yw?∣x)?βlogπθ?(yl?∣x))].?(3)
具體來說,我們在附錄 C 中證明了以下定理:
定理 1. 當 πref\pi_{\text{ref}}πref? 定義為 πw\pi_wπw?,即精確符合真實優選數據分布的理想策略時,DPO 損失 L(πθ;πw)+CL(\pi_\theta; \pi_w) + CL(πθ?;πw?)+C (其中 CCC 為常數)被 L(πθ;U)L(\pi_\theta; U)L(πθ?;U) 上界約束。
式(3)中的近似有效,因為它最小化了 DPO 損失的上界。證明依賴于 πref=πw\pi_{\text{ref}} = \pi_wπref?=πw? 的重要假設。與通常將 π_ref\pi\_{\text{ref}}π_ref 設為初始 SFT 檢查點的做法不同,我們的方法將其視為希望達到的理想策略。雖然理想策略 πw\pi_wπw? 在模型訓練過程中是未知且不可達的,但經過近似后,πw\pi_wπw? 不再參與損失計算。
此外,我們還引入了行為克隆(Behavior Cloning, BC)正則項(Hejna et al., 2023),以確保 πθ\pi_\thetaπθ? 不偏離優選數據的分布:
min?θL(πθ,U)s.t.E(x,yw)~D[KL(πw(yw∣x)∣∣πθ(yw∣x))]<?,(4)\begin{array} { r l } & { \underset { \theta } { \operatorname* { m i n } } \, \mathcal { L } ( \pi _ { \theta } , U ) } \\ & { \mathrm { s . t . } \; \mathbb { E } _ { ( x , y _ { w } ) \sim \mathcal { D } } \Big [ \mathbb { K } \mathbb { L } ( \pi _ { w } ( y _ { w } | x ) | | \pi _ { \theta } ( y _ { w } | x ) ) \Big ] < \epsilon , } \end{array}\quad(4) ?θmin?L(πθ?,U)s.t.E(x,yw?)~D?[KL(πw?(yw?∣x)∣∣πθ?(yw?∣x))]<?,?(4)
溫馨提示:
閱讀全文請訪問"AI深語解構" CPO:對比偏好優化—突破大型語言模型在機器翻譯中的性能邊界

















+Gitee實現自動化部署)

